Deep Learning: Recognizing Scenes and Points of Interest in Images
Time to replenish the piggy bank of good Russian Machine Learning reports! Piggy bank itself is not replenished!
This time we will get acquainted with the fascinating story of Andrey Boyarov about the recognition of scenes. Andrei is a research programmer engaged in machine vision at Mail.Ru Group.
Scene recognition is one of the most actively used areas of machine vision. This task is more complicated than the studied object recognition: the scene is a more complex and less formalized concept; it is more difficult to isolate the signs. From the recognition of scenes follows the task of recognizing attractions: you need to highlight the known places in the photo, ensuring a low level of false positives.
')
This is 30 minutes of video from the conference Smart Data 2017. Video is convenient to watch at home and on the road. For those who are not ready to sit so much at the screen, or for whom it is more convenient to perceive information in text form, we apply a full text transcript, decorated in the form of habrostat.
I do machine vision at Mail.ru. Today I will talk about how we use deep learning to recognize images of scenes and sights.
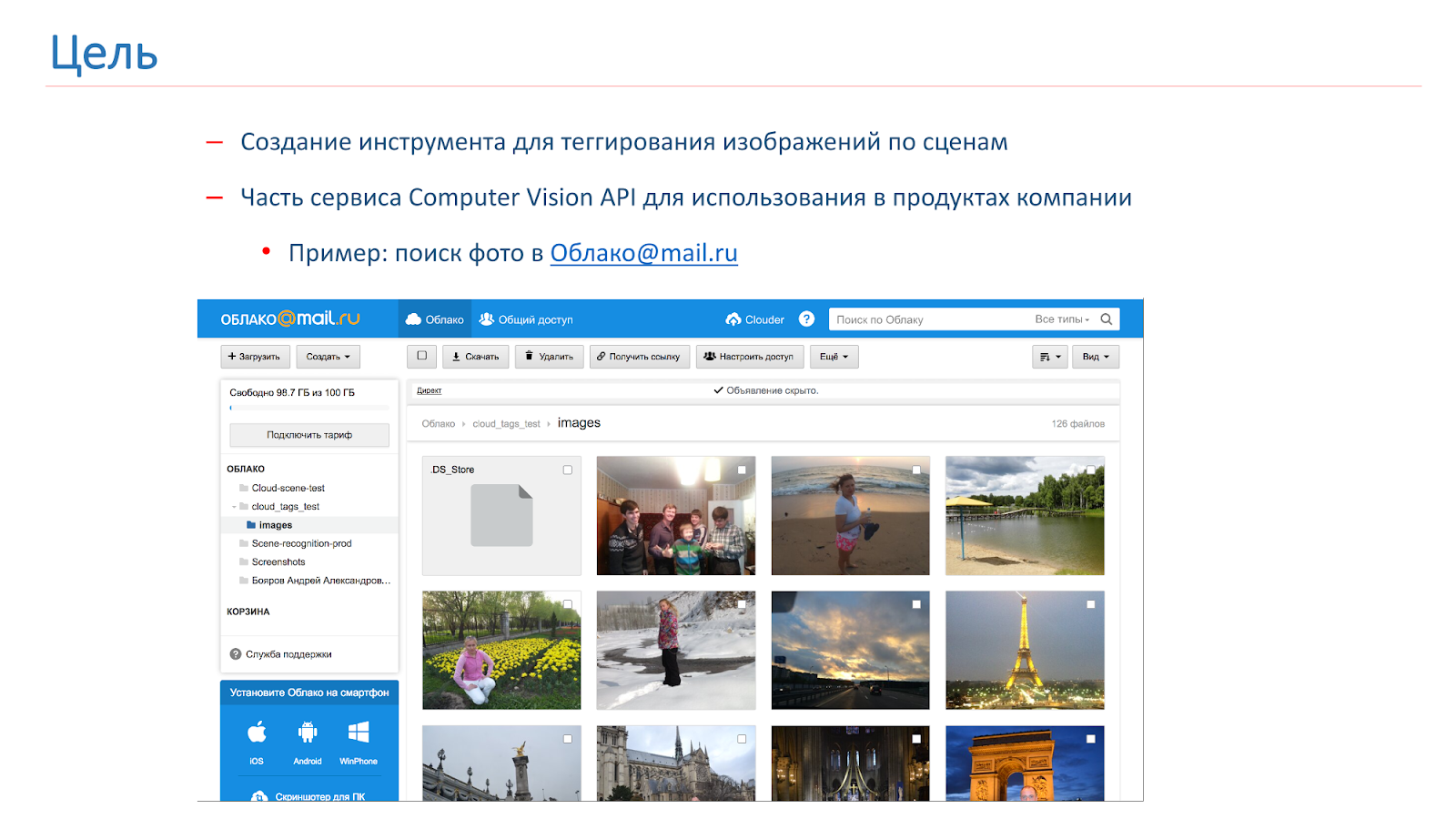
The company needed to tag and search for images of users, and for this we decided to make our Computer Vision API, of which the scene tagging tool will be a part. As a result of the work of this tool, we want to get something as shown in the picture below: the user makes a request, for example, a “cathedral”, and receives all his photos from the cathedrals.
In Computer Vision-community, the topic of object recognition in images has been studied quite well. There is a famous ImageNet contest , which has been held for several years now and the main part of which is object recognition.
We basically need to localize some object and classify it. With scenes, the task is somewhat more complicated, because the scene is a more complex object, it consists of a large number of other objects and a unifying context, so the tasks are different.

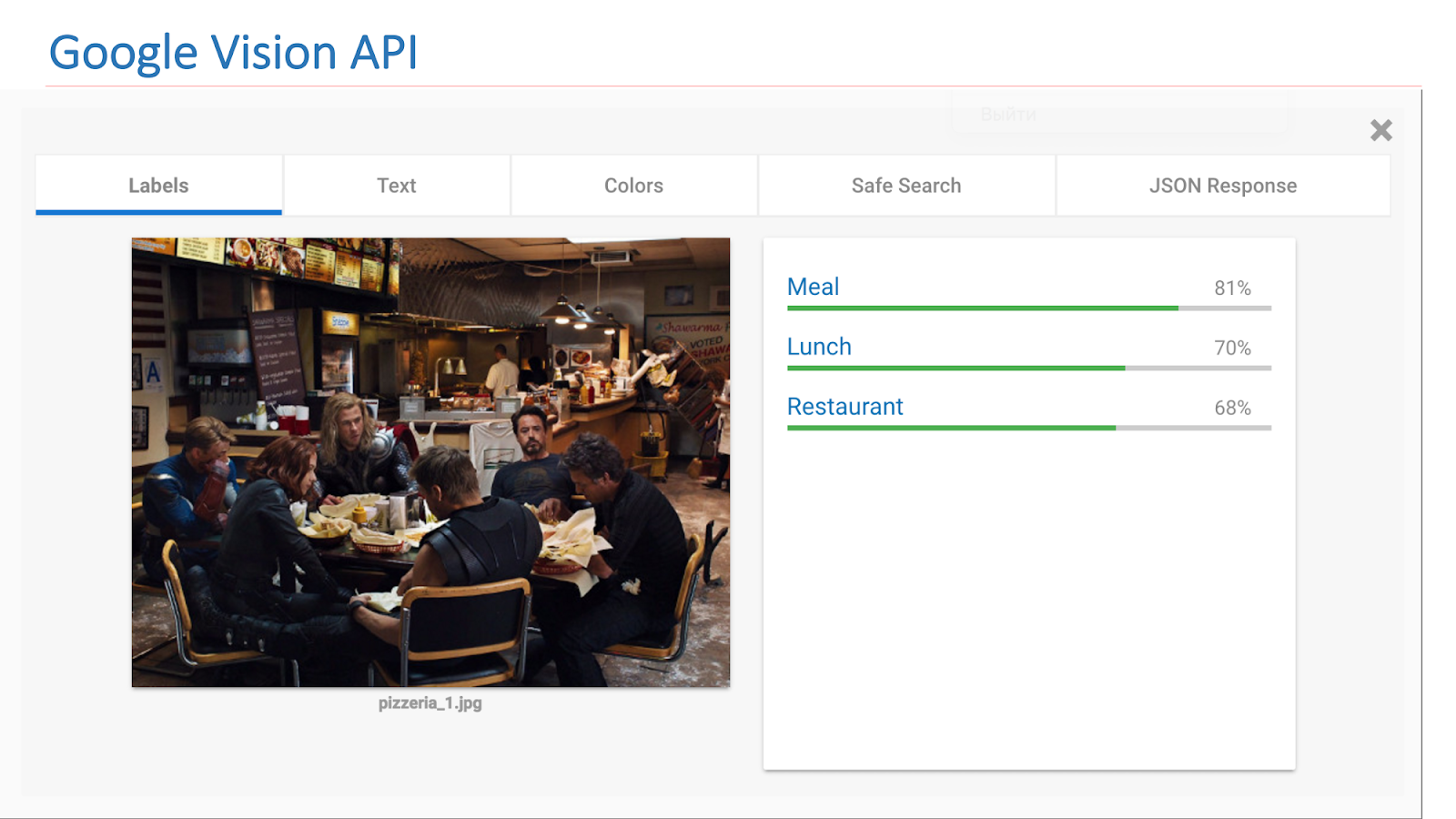
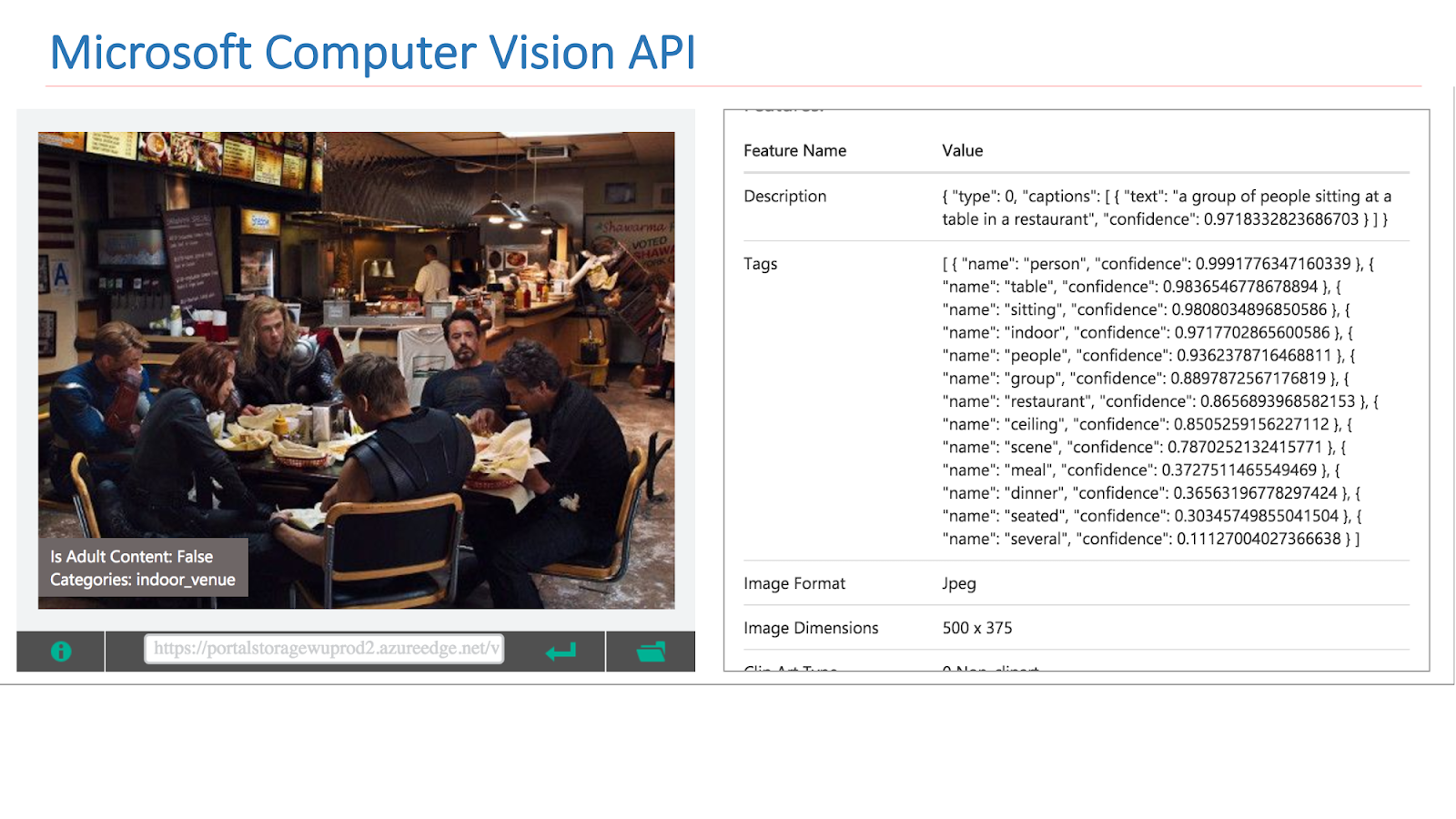
On the Internet there are available services from other companies that implement such functionality. In particular, this is the Google Vision API or Microsoft Computer Vision API, which is able to find scenes in images.
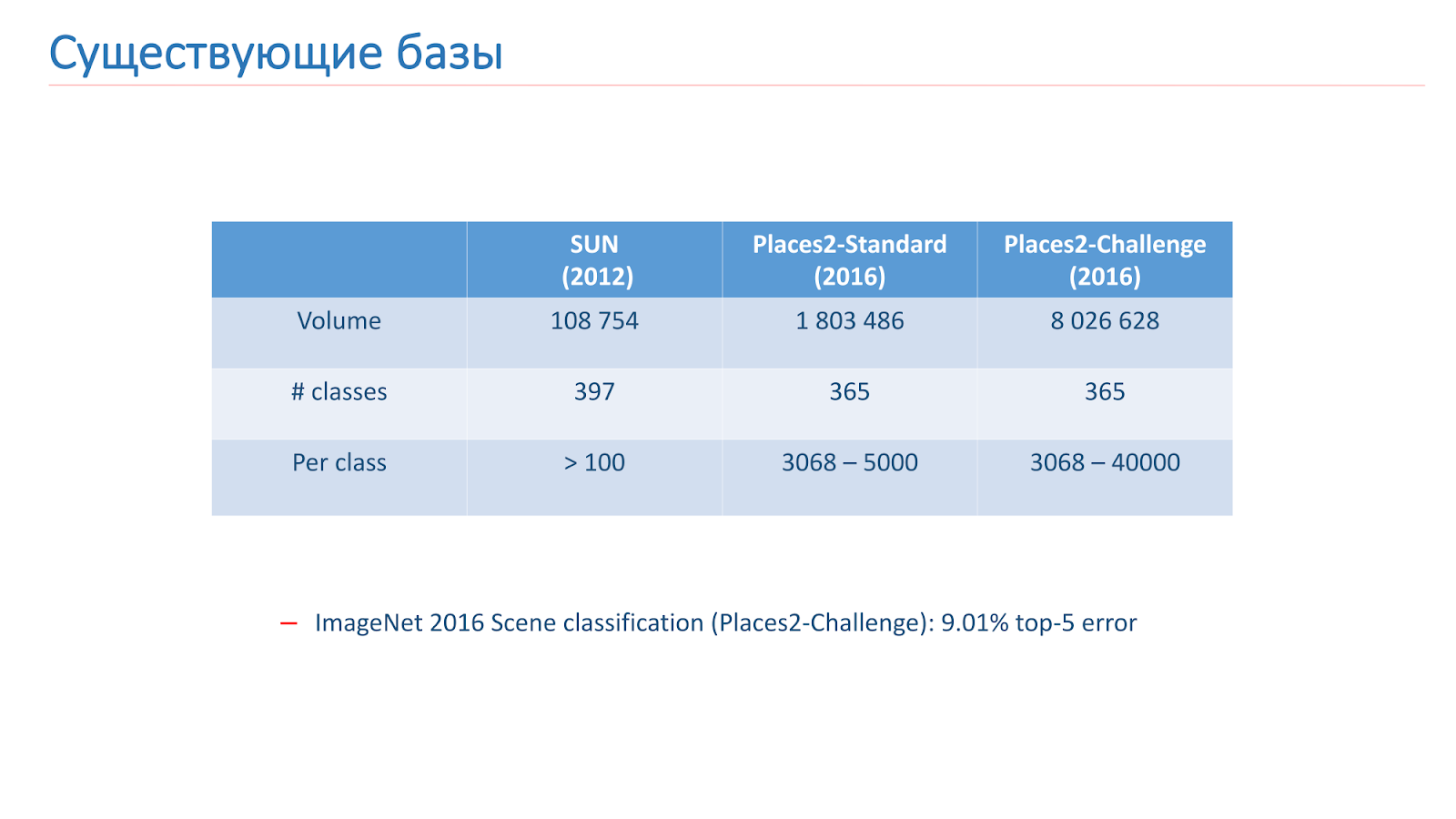
We solved this problem using machine learning, so for this we need data. In open access, there are now two main bases for scene recognition. The first of these appeared in 2013 - this is the SUN base from Princeton University. This database consists of hundreds of thousands of images and 397 classes.
The second base on which we were trained is the MIT Places2 base . She appeared in 2013 in two versions. The first is Places2-Standart, a more balanced base with 1.8 million images and 365 classes. The second option - Places2-Challenge, contains eight million images and 365 classes, but the number of images between classes is not balanced. The ImageNet 2016 contest in the Scene Recognition section included Places2-Challenge, and the winner showed the best Top-5 classification error of about 9%.
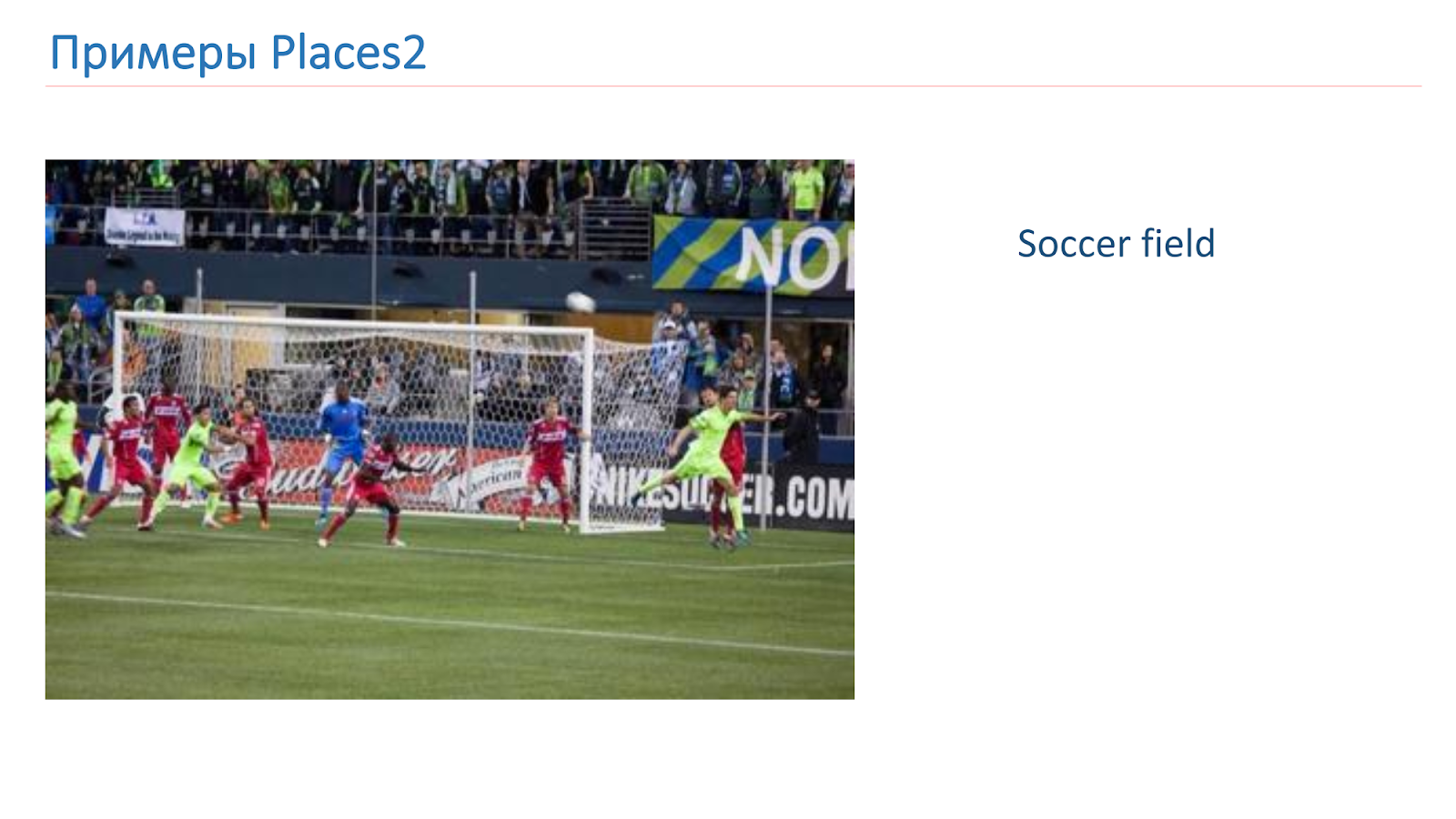
We were trained on the basis of Places2. Here is an example of an image from there: it is a canyon, a runway, a kitchen, a football field. These are completely different complex objects on which we need to learn to recognize.

Before learning, we adapted the bases that we have to fit our needs. For Object Recognition, there is a technique where models are experimented on small bases CIFAR-10 and CIFAR-100 instead of ImageNet, and only then the best are taught on ImageNet.
We decided to go the same way, took the SUN base, reduced it, got 89 classes, 50 thousand images by train and 10 thousand images for validation. As a result, before training on Places2, we set up experiments and tested our models based on SUN. Training on it takes only 6-10 hours, in contrast to several days on Places2, which made it possible to conduct much more experiments and make it more efficient.
We also looked at the Places2 base itself and realized that we didn’t need some classes. Either for production reasons, or because there is too little data on them, we cut out classes such as, for example, an aqueduct, a house on a tree, a barn door.

In the end, after all the manipulations, we got the base Places2, which contains 314 classes and one and a half million images (in its standard version), in the Challenge version about 7.5 million images. We built training on these bases.
In addition, when viewing the remaining classes, we found that there are too many of them for production, they are too detailed. And for this, we applied the Scene mapping mechanism, when some classes are combined into one general. For example, everything that is connected with forests, we have united into a forest, everything that is connected with hospitals — into a hospital, with hotels — into a hotel.
Scene mapping we use only for testing and for the end user, because it is more convenient. In training, we use all the standard 314 classes. The resulting base, we called Places Sift.
Now consider the approaches that we used to solve this problem. Actually, such tasks are connected with the classical approach - deep convolutional neural networks.
The image below shows one of the first classic networks, but it already contains the basic building blocks that are used in modern networks.

These are convolutional layers, these are pulling-layers, fully connected layers. In order to decide on the architecture, we checked the tops of the competitions ImageNet and Places2.

It can be said that the main leading architectures can be divided into two families: Inception and ResNet family (residual network). In the course of experiments, we found out that the ResNet family is better suited for our task, and we carried out a further experiment on this family.

ResNet is a deep network that consists of a large number of residual blocks. This is its main building block, which consists of several layers with scales and a shortcut connection. As a result of this design, this block learns how much the input signal x differs from the output f (x). As a result, we can build networks of such blocks, and during training the network can make weights on the last layers close to zero.
Thus, it can be said that the network itself decides how deep it needs to be to solve some of the tasks. Thanks to this architecture, it is possible to build networks of very large depth with a very large number of layers. The winner of ImageNet 2014 contained only 22 layers, ResNet surpassed this result and already contained 152 layers.
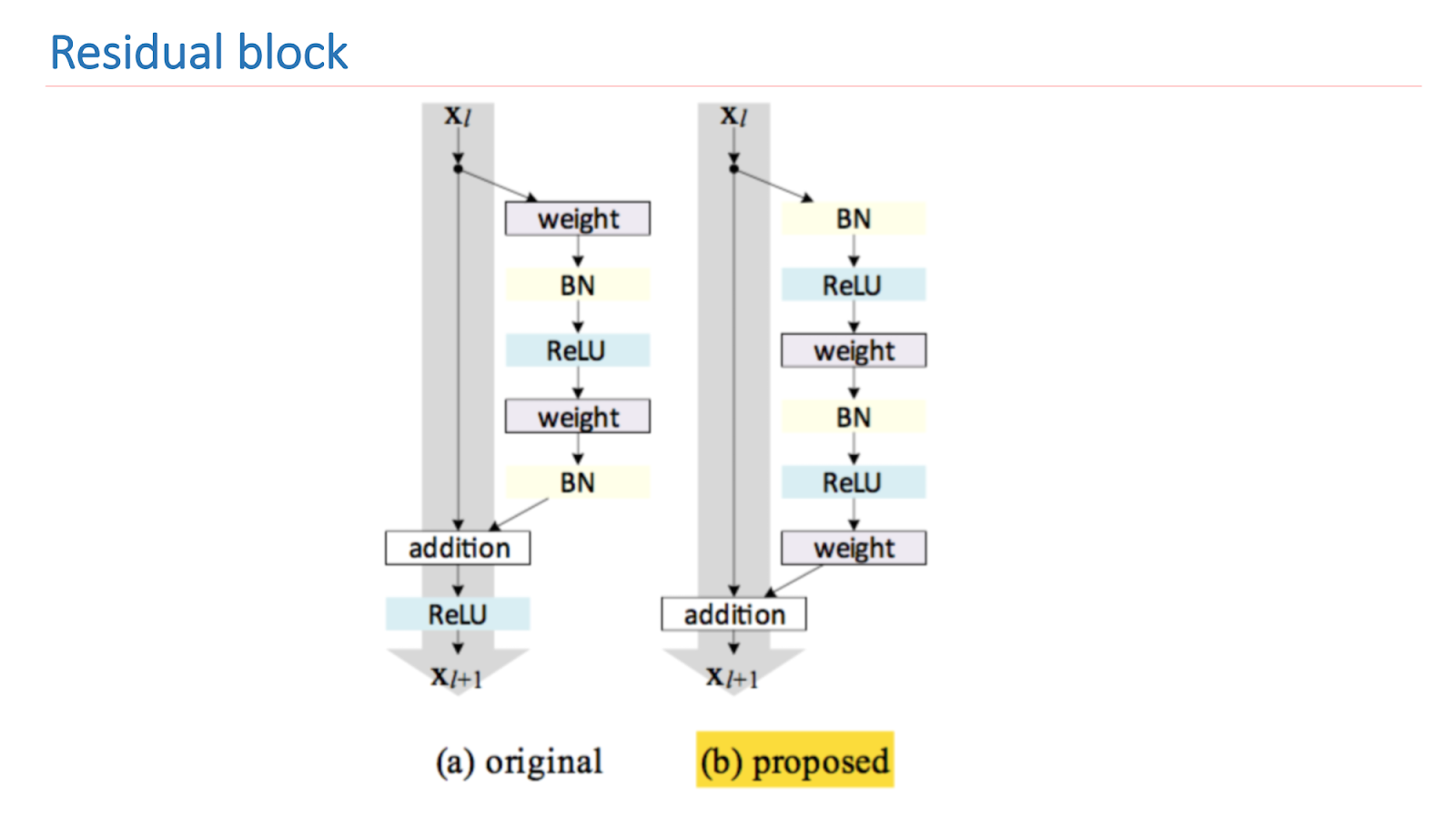
ResNet's core research is to improve and properly build a residual block. The picture below presents an empirically and mathematically sound version that gives the best result. Such a building block allows you to deal with one of the fundamental problems of deep learning - a fading gradient.
For learning our networks, we used the Torch framework written in the Lua language because of its flexibility and speed, and ResNet made a fork of the ResNet implementation from Facebook . We used three tests to validate the quality of the network.
The first Places val test is the validation of the Places Sift set. The second test is Places Sift using Scene Mapping, and the third is the closest to the combat situation, the Cloud test. Images of employees are taken from the cloud and marked up manually. In the picture below there are two examples of such images.

We began to measure and train the network, compare them with each other. The first is the ResNet-152 benchmark, which comes with Places2, the second is the ResNet-50, which was trained on ImageNet and upgraded to our base, the result was already better. Then they took ResNet-200, they also trained on ImageNet, and in the end it showed the best result.

Below are examples of work. This is the ResNet-152 benchmark. Predicted - these are the original labels, which gives the network. Mapped lables are labels that came out after Scene Mapping. It is evident that the result is not very good. That is, she seems to give something in the case, but not very well.

The next example is the work of ResNet-200. Already very adequate.

We decided to try to improve our network, and at first tried to just increase the depth of the network, but after that it became much more difficult to train it. This is a known problem. Last year there were several articles on this subject, which say that ResNet, in fact, is an ensemble of a large number of ordinary networks of different depths.
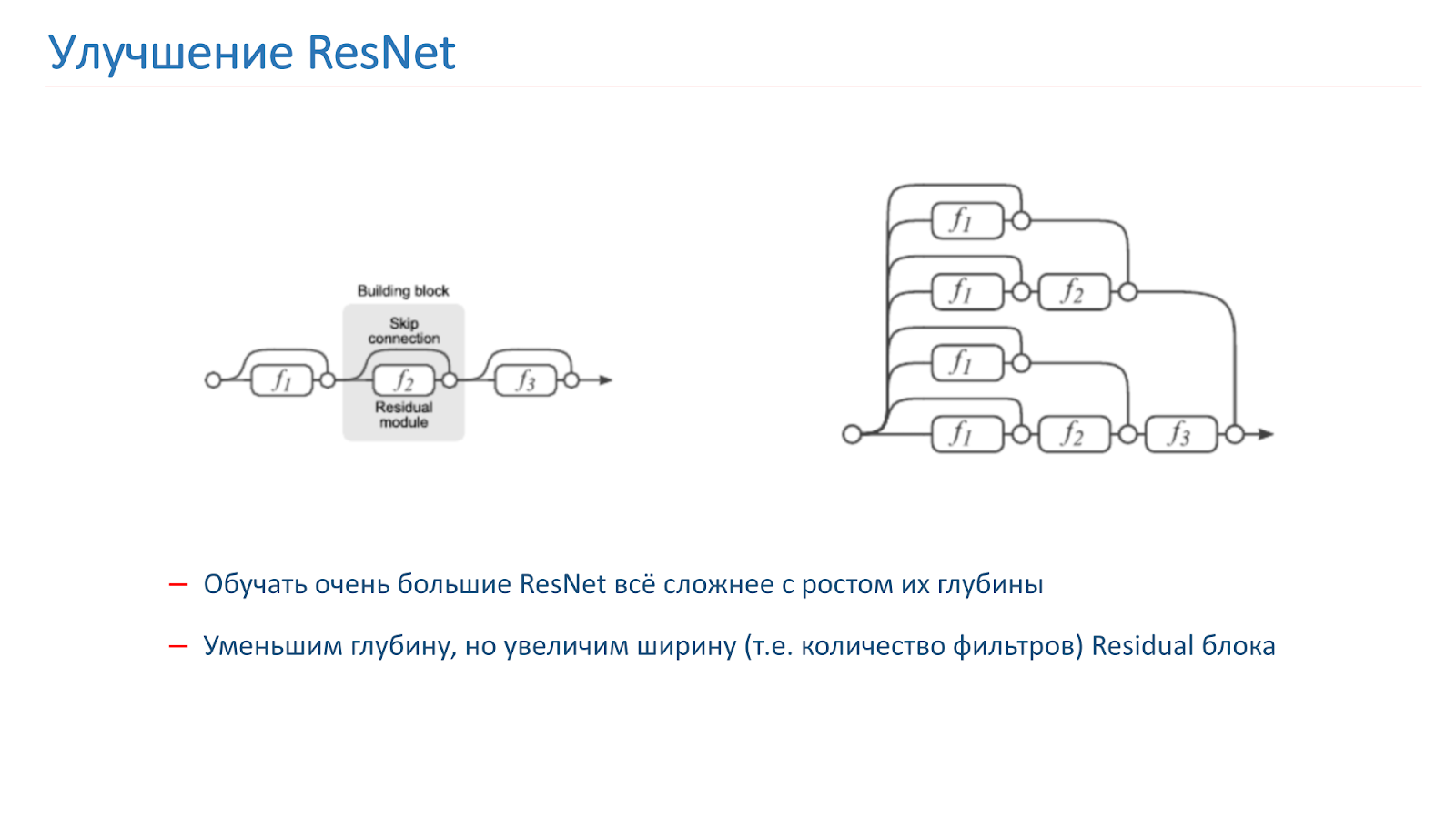
Res blocks, which are located at the end of the grid, make a small contribution to the formation of the final result. It seems more promising to increase not the depth of the network, but its width, that is, the number of filters inside the Res-block.
This idea is implemented by the Wide Residual Network, which appeared in 2016. We eventually used the WRN-50-2, which is the usual ResNet-50 with twice the number of filters in the internal 3x3 bottleneck convolution.

The network shows similar results on ImageNet with ResNet-200, which we have already used, but, importantly, it is almost twice as fast. Here are two implementations of the Residual-block on Torch, the bright parameter is highlighted, which is doubled. We are talking about the number of filters in the internal convolution.

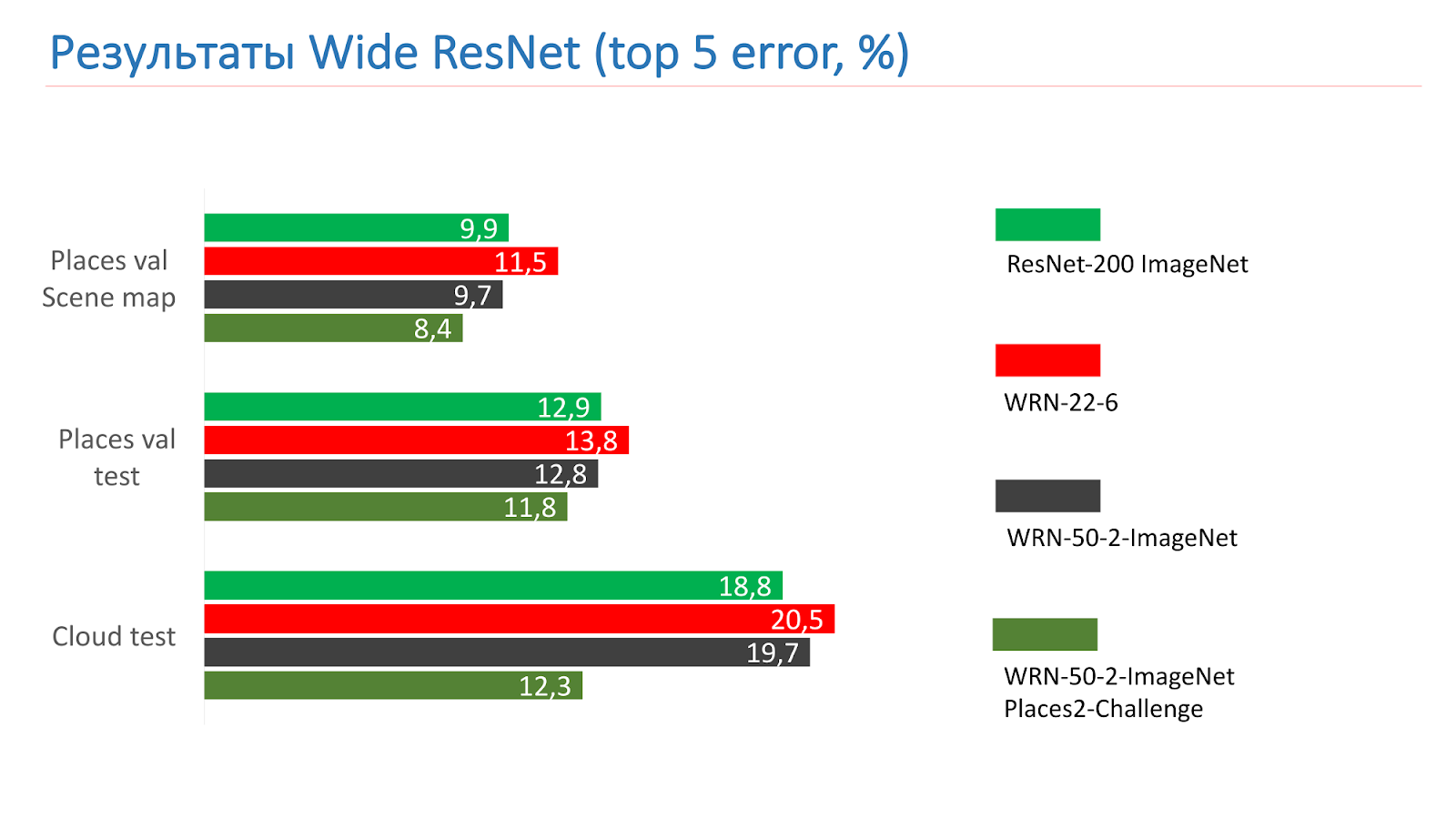
These are measurements on ImageNet ResNet-200 tests. At first we took the WRN-22-6, it showed the result worse. Then they took WRN-50-2-ImageNet, trained him, took WRN-50-2, trained on ImageNet, and retrained on Places2-challenge, he showed the best result.
Here is an example of the work of the WRN-50-2 - quite an adequate result in our pictures, which you have already seen.

And this is an example of working in combat photos, also successfully.

There are, of course, not very good work. The bridge of Alexander III in Paris was not recognized as a bridge.

We wondered how to improve this model. The ResNet family continues to improve, new articles are coming out. In particular, an interesting article by PyramidNet was published in 2016, which showed promising results on CIFAR-10/100 and ImageNet.
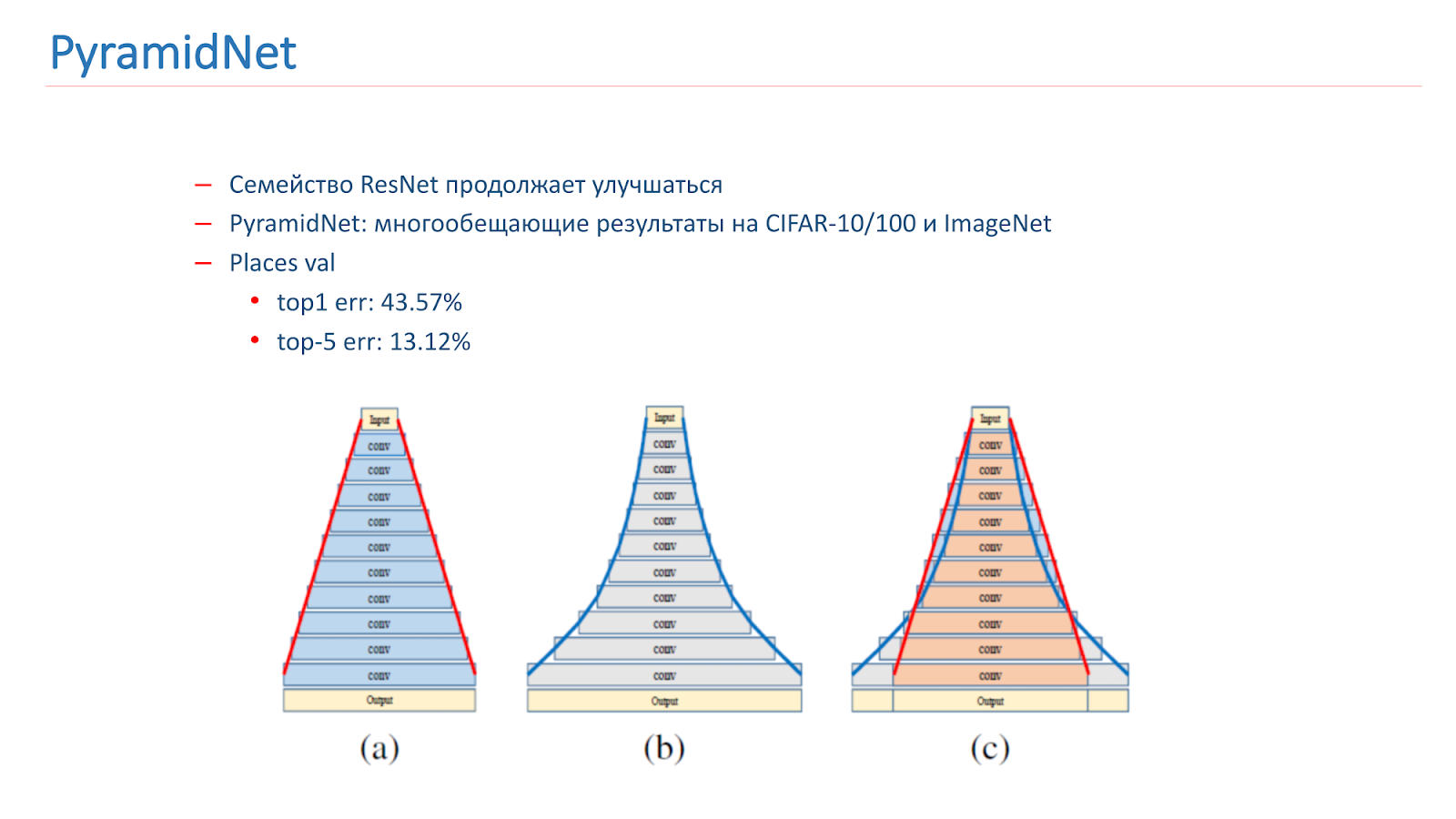
The idea is not to dramatically increase the width of the Residual-block, but to do it gradually. We have trained several variants of this network, but, unfortunately, it showed results a little worse than our combat model.
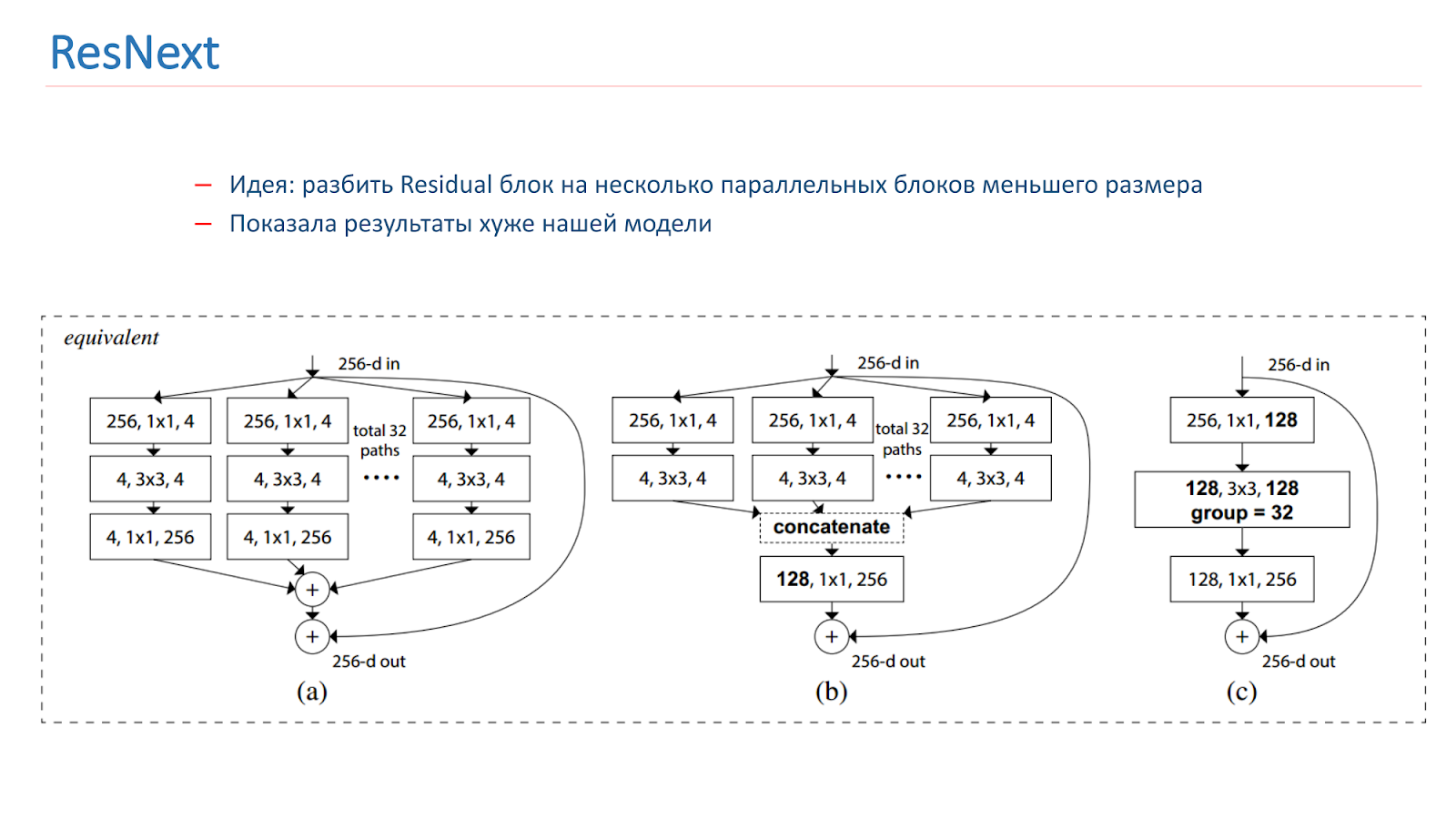
In the spring of 2018, the ResNext model was released, also a promising idea: to split the Residual-block into several parallel blocks of a smaller size and smaller width. This is similar to the idea of Inception, we also experimented with it. But, unfortunately, it showed worse results than our model.
We also experimented with various “creative” approaches to improve our models. In particular, we tried to use Class activation mapping (CAM), that is, these are the objects that the network is looking at when it classifies an image.

Our idea was that instances of the same scene should have the same or similar objects as the CAM class. We tried using this approach. First, they took two networks. One is ImageNet-trained, the second is our model we want to improve.

We take the image, run it through network 2, add CAM for the layer, then feed it to the input of network 1. Run through network 1, add the results to the loss function of network 2, continue it on the new loss functions.
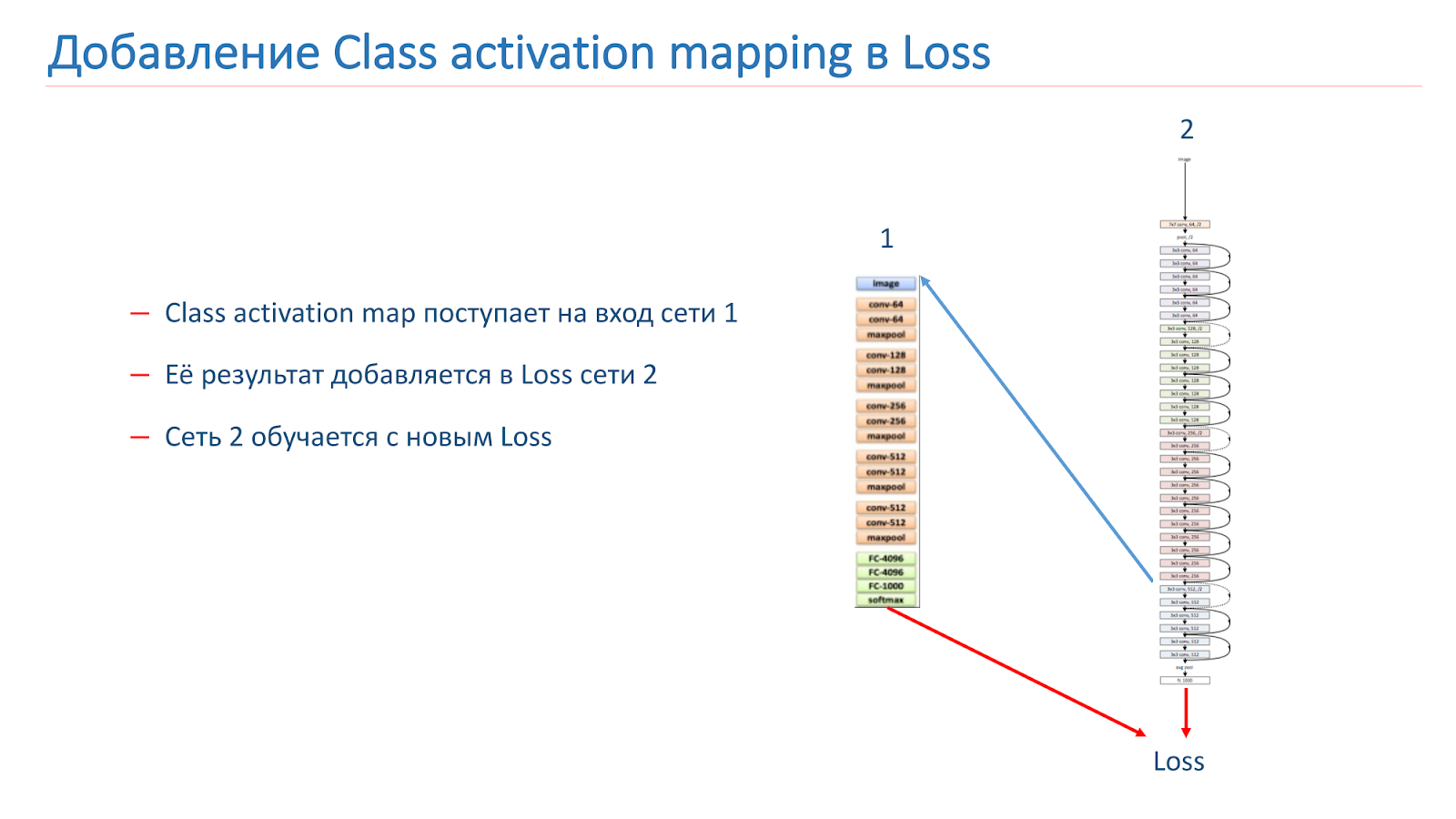
The second option is that we run the image through network 2, take CAM, feed network 1, and then use this data to simply train network 1 and use the ensemble from the results of network 1 and network 2.
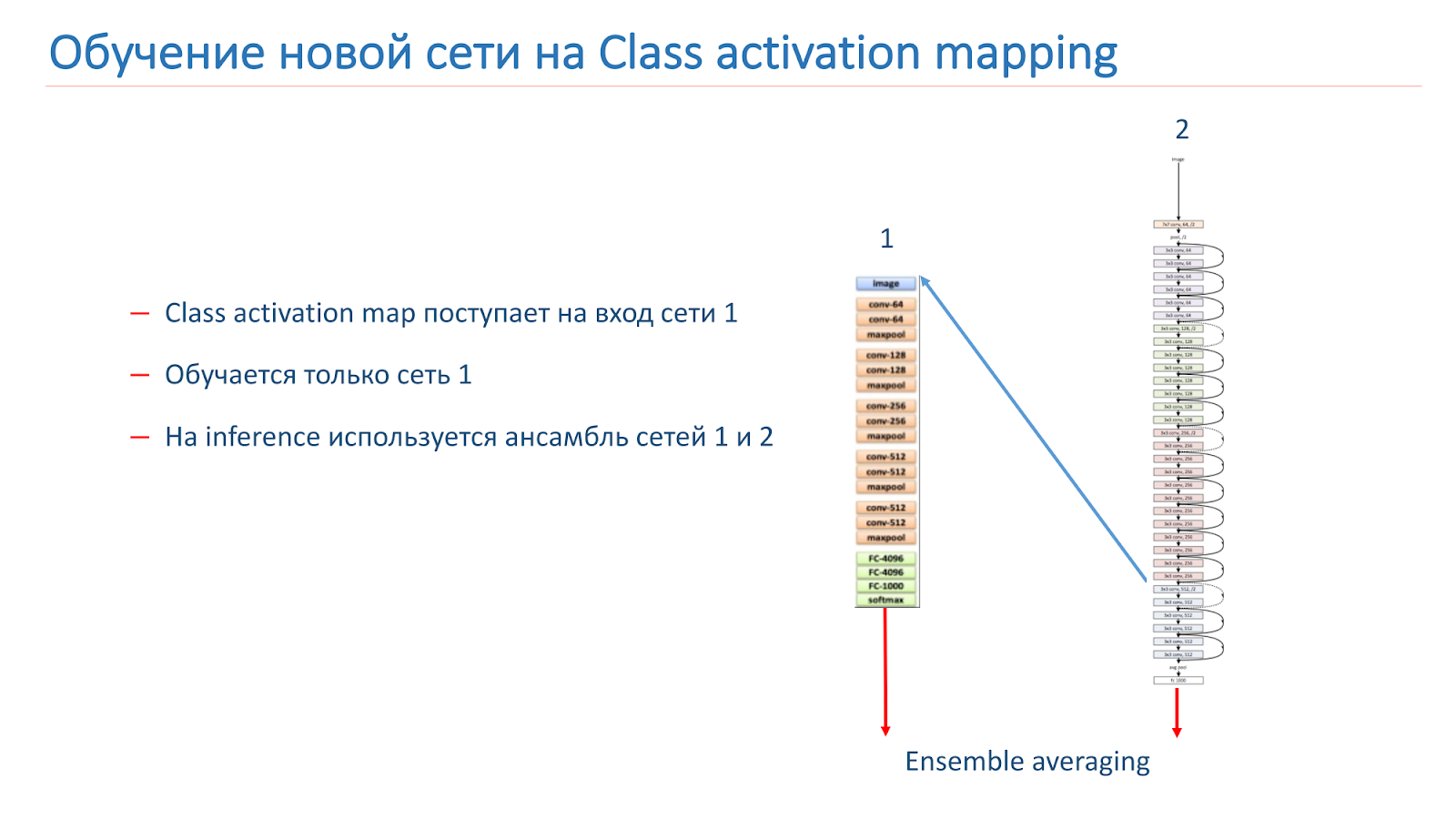
We trained our model on the WRN-50-2, ResNet-50 ImageNet was used as network 1, but it didn’t work out to significantly increase the quality of our model.
But we are continuing research on how to improve our results: we are teaching new CNN architectures, in particular, the ResNet family. We are trying to experiment with CAM and are considering different approaches with smarter image patch processing - it seems to us that this approach is quite promising.

We have a good model for recognizing scenes, but now we want to recognize some significant places, that is, sights. In addition, users often take pictures of them or take pictures on their background.
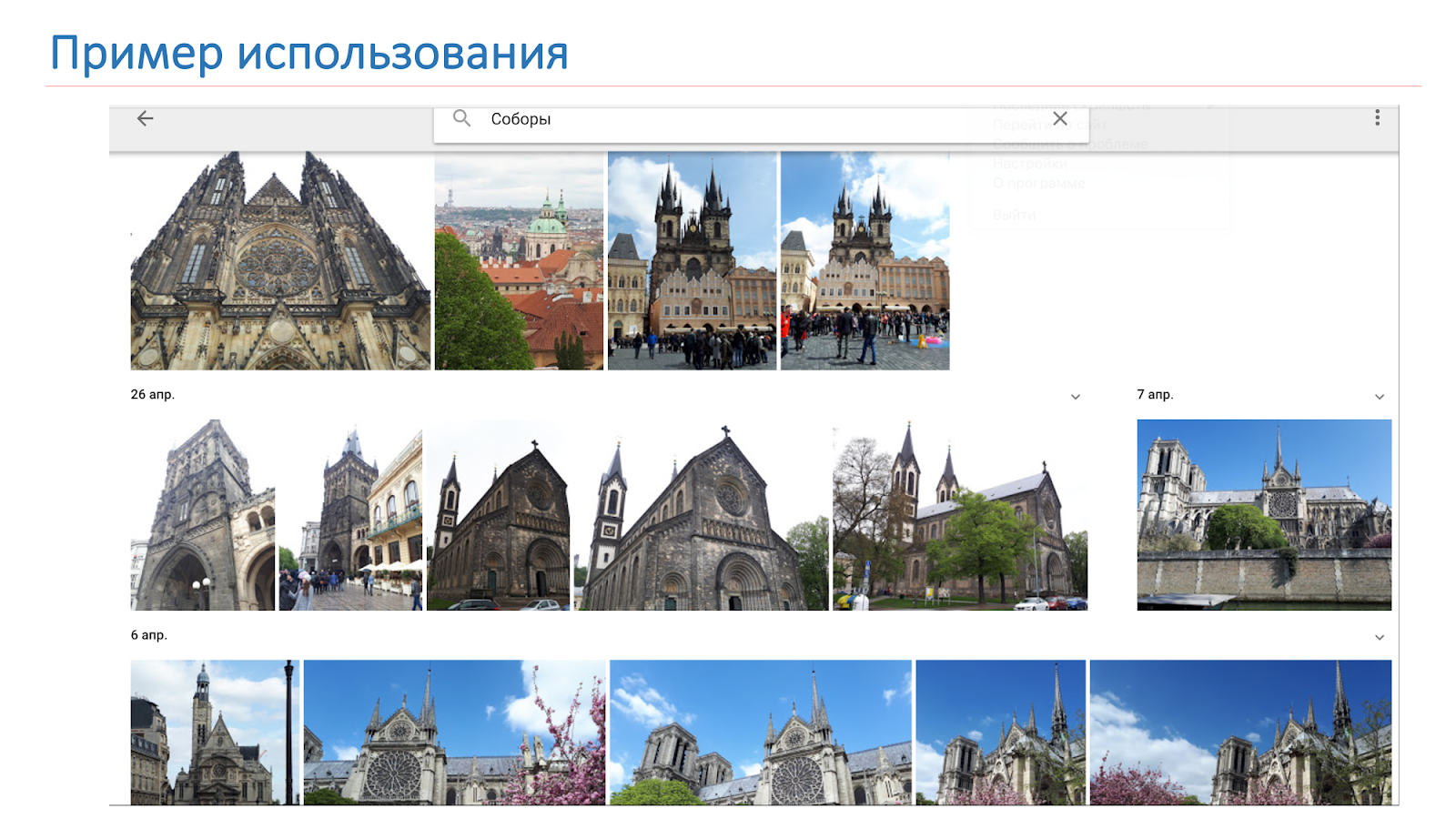
We want, as a result, to give us not just cathedrals, as in the image on the slide, but the system to say: “Here there are Notre Dame de Paris and the cathedrals in Prague.”
When we solved this problem, we faced some difficulties.
We started by collecting the database, compiled a list of 100 cities, and then used the Google Places API to download JSON data on attractions from these cities.
The data was filtered and parsili, and according to the received list, 20 images were downloaded from Google Search for each attraction. The number 20 is taken from empirical considerations. As a result, we received a database of 2827 attractions and about 56 thousand images. This is the base on which we trained our model. To validate our model, we used two tests.
Cloud test - these are images from our employees, marked up manually. It contains 200 pictures in 15 cities and 10 thousand images of no landmarks. The second is the Search test. It was built using Mail.ru search, which contains from 3 to 10 images for each landmark, but unfortunately, this test is dirty.
We trained the first models, but they showed poor results on the Cloud test in combat photos.
Here is an example of the image in which we were trained, and an example of combat photography. The problem with people is that they are often photographed against the background of attractions. On those images that we got out of the search, there were no people.
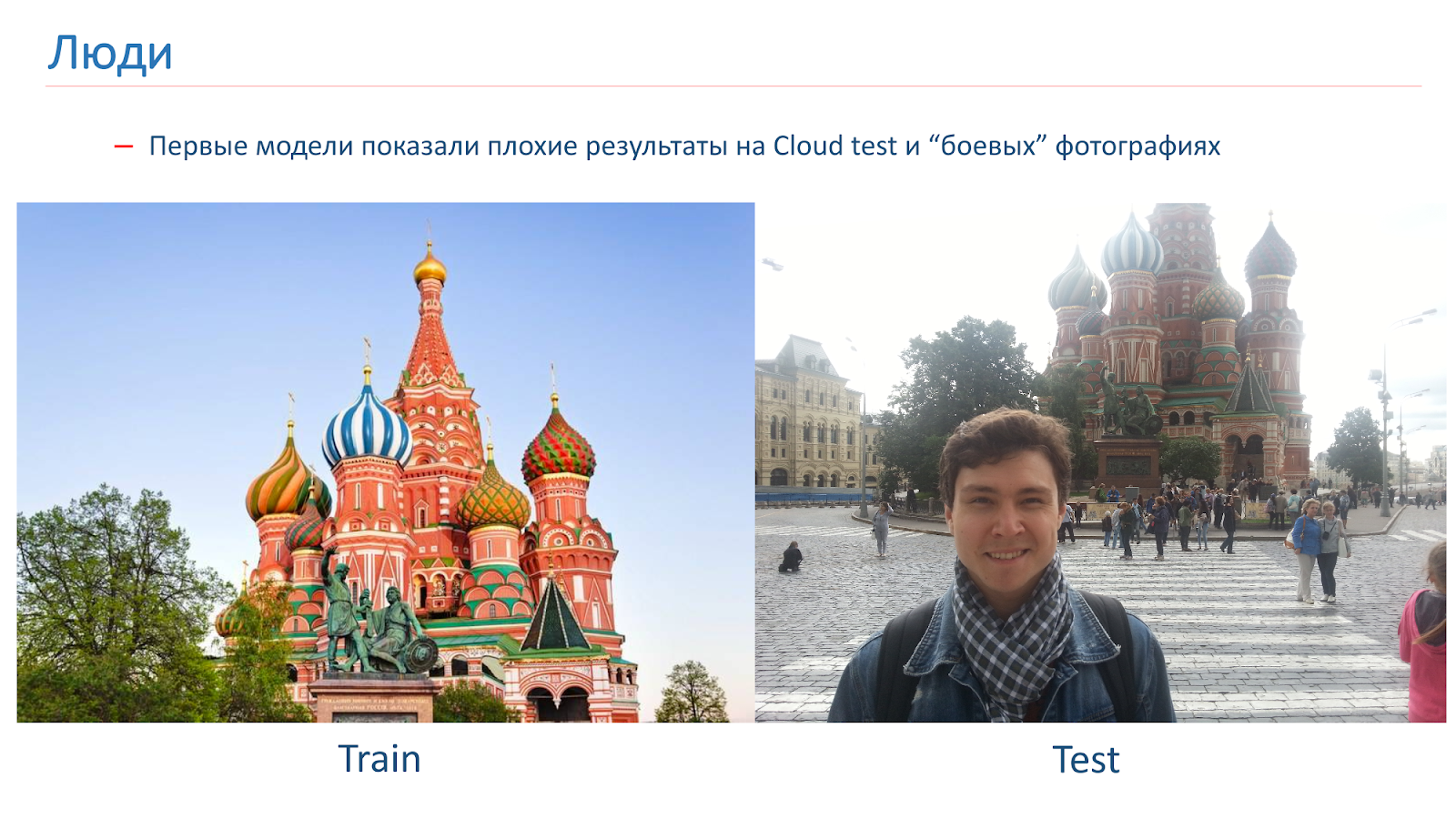
To combat this, we added a “human” augmentation while training. That is, we used the standard approaches: random turns, accidental cutting out part of the image, and so on. But also in the process of learning, we randomly added people to some images.

This approach helped us to solve the problem with people and get an acceptable quality of the model.
How we trained the model: there is a certain training base, but it is rather small. But we know that the landmark is a special case of the scene. And we have a pretty good Scene model. We decided to train her on the sights. To do this, we added several fully connected and BN layers on top of the network, and the top three Residual blocks also trained them. The rest of the network has been frozen.

In addition, for training, we use a non-standard function of loss of center loss. When training, Center loss tries to “pull apart” representatives of different classes in different clusters, as shown in the picture.

When training, we added another class "not a landmark." And no center loss was applied to this class. On such a mixed loss function, training was conducted.
After we have trained the network, we cut off the last classifying layer from it, and when the image passes through the network, it turns into a numerical vector, which is called embedding.
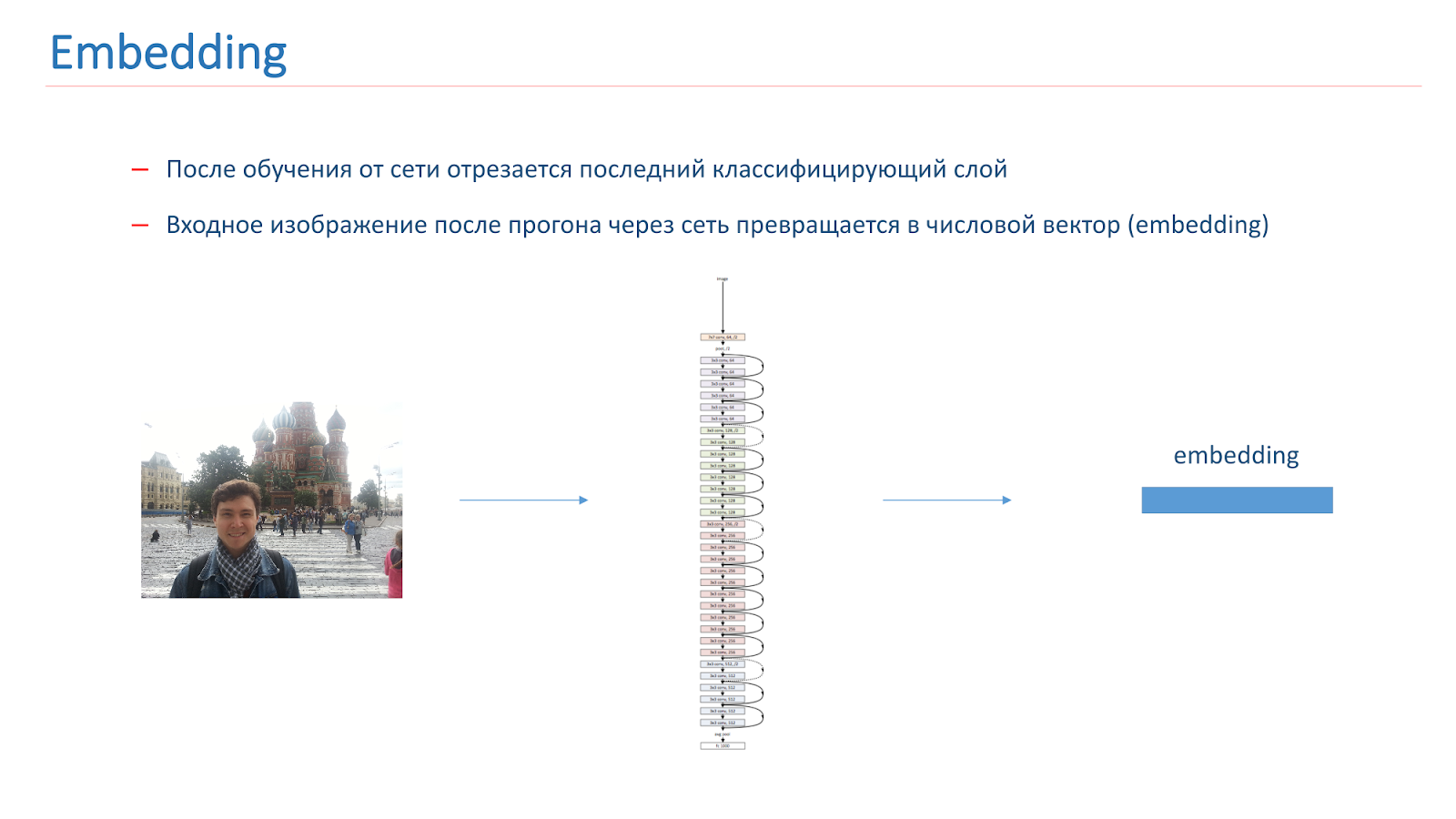
To further build the sights recognition system, we built reference vectors for each class. We took each class of attractions from the set and drove the images through the network. We received embeddings and took their average vector, which they called the class reference vector.

To determine the sights in the photo, we run the input image through the network, and its embedding is compared with the reference vector of each class. If the result of the comparison is less than the threshold, then we believe that there are no landmarks in the image. Otherwise, we take the class with the highest comparison value.
Search didn’t get very good results, but this is explained by the fact that the first one is rather “dirty”, and the second one has its peculiarities - among the sights there are different botanical gardens that are similar in all cities.
There was an idea for recognizing scenes to first train the network, which would determine the scene mask, that is, remove objects from the foreground from it, and then feed it into the model itself, which recognizes scenes of an image without these areas, where the background is obstructed. But it is not very clear what exactly needs to be removed from the front layer, which mask is needed.
It will be a rather complicated and clever thing, because not everyone understands which objects belong to the scene, and which are superfluous. For example, people in the restaurant may be needed. This is not a trivial decision, we tried to do something similar, but it did not give good results.
Here is an example of working in combat photos.
Examples of successful work:


But unsuccessful work: the sights were not found. The main problem of our model at the moment is not that the network confuses sights with each other, but that it does not find them in the photo.

In the future, we plan to assemble a base for even more cities, find new methods of network training for this task, and identify opportunities for increasing the number of classes without retraining the network.
Today we:
I can say that the tasks are interesting, but little studied in the community. They are interesting to do, because you can apply non-standard approaches that are not used in the usual recognition of objects.
This time we will get acquainted with the fascinating story of Andrey Boyarov about the recognition of scenes. Andrei is a research programmer engaged in machine vision at Mail.Ru Group.
Scene recognition is one of the most actively used areas of machine vision. This task is more complicated than the studied object recognition: the scene is a more complex and less formalized concept; it is more difficult to isolate the signs. From the recognition of scenes follows the task of recognizing attractions: you need to highlight the known places in the photo, ensuring a low level of false positives.
')
This is 30 minutes of video from the conference Smart Data 2017. Video is convenient to watch at home and on the road. For those who are not ready to sit so much at the screen, or for whom it is more convenient to perceive information in text form, we apply a full text transcript, decorated in the form of habrostat.
I do machine vision at Mail.ru. Today I will talk about how we use deep learning to recognize images of scenes and sights.
The company needed to tag and search for images of users, and for this we decided to make our Computer Vision API, of which the scene tagging tool will be a part. As a result of the work of this tool, we want to get something as shown in the picture below: the user makes a request, for example, a “cathedral”, and receives all his photos from the cathedrals.
In Computer Vision-community, the topic of object recognition in images has been studied quite well. There is a famous ImageNet contest , which has been held for several years now and the main part of which is object recognition.
We basically need to localize some object and classify it. With scenes, the task is somewhat more complicated, because the scene is a more complex object, it consists of a large number of other objects and a unifying context, so the tasks are different.
On the Internet there are available services from other companies that implement such functionality. In particular, this is the Google Vision API or Microsoft Computer Vision API, which is able to find scenes in images.
We solved this problem using machine learning, so for this we need data. In open access, there are now two main bases for scene recognition. The first of these appeared in 2013 - this is the SUN base from Princeton University. This database consists of hundreds of thousands of images and 397 classes.
The second base on which we were trained is the MIT Places2 base . She appeared in 2013 in two versions. The first is Places2-Standart, a more balanced base with 1.8 million images and 365 classes. The second option - Places2-Challenge, contains eight million images and 365 classes, but the number of images between classes is not balanced. The ImageNet 2016 contest in the Scene Recognition section included Places2-Challenge, and the winner showed the best Top-5 classification error of about 9%.
We were trained on the basis of Places2. Here is an example of an image from there: it is a canyon, a runway, a kitchen, a football field. These are completely different complex objects on which we need to learn to recognize.
Before learning, we adapted the bases that we have to fit our needs. For Object Recognition, there is a technique where models are experimented on small bases CIFAR-10 and CIFAR-100 instead of ImageNet, and only then the best are taught on ImageNet.
We decided to go the same way, took the SUN base, reduced it, got 89 classes, 50 thousand images by train and 10 thousand images for validation. As a result, before training on Places2, we set up experiments and tested our models based on SUN. Training on it takes only 6-10 hours, in contrast to several days on Places2, which made it possible to conduct much more experiments and make it more efficient.
We also looked at the Places2 base itself and realized that we didn’t need some classes. Either for production reasons, or because there is too little data on them, we cut out classes such as, for example, an aqueduct, a house on a tree, a barn door.
In the end, after all the manipulations, we got the base Places2, which contains 314 classes and one and a half million images (in its standard version), in the Challenge version about 7.5 million images. We built training on these bases.
In addition, when viewing the remaining classes, we found that there are too many of them for production, they are too detailed. And for this, we applied the Scene mapping mechanism, when some classes are combined into one general. For example, everything that is connected with forests, we have united into a forest, everything that is connected with hospitals — into a hospital, with hotels — into a hotel.
Scene mapping we use only for testing and for the end user, because it is more convenient. In training, we use all the standard 314 classes. The resulting base, we called Places Sift.
Approaches, solutions
Now consider the approaches that we used to solve this problem. Actually, such tasks are connected with the classical approach - deep convolutional neural networks.
The image below shows one of the first classic networks, but it already contains the basic building blocks that are used in modern networks.
These are convolutional layers, these are pulling-layers, fully connected layers. In order to decide on the architecture, we checked the tops of the competitions ImageNet and Places2.
It can be said that the main leading architectures can be divided into two families: Inception and ResNet family (residual network). In the course of experiments, we found out that the ResNet family is better suited for our task, and we carried out a further experiment on this family.
ResNet is a deep network that consists of a large number of residual blocks. This is its main building block, which consists of several layers with scales and a shortcut connection. As a result of this design, this block learns how much the input signal x differs from the output f (x). As a result, we can build networks of such blocks, and during training the network can make weights on the last layers close to zero.
Thus, it can be said that the network itself decides how deep it needs to be to solve some of the tasks. Thanks to this architecture, it is possible to build networks of very large depth with a very large number of layers. The winner of ImageNet 2014 contained only 22 layers, ResNet surpassed this result and already contained 152 layers.
ResNet's core research is to improve and properly build a residual block. The picture below presents an empirically and mathematically sound version that gives the best result. Such a building block allows you to deal with one of the fundamental problems of deep learning - a fading gradient.
For learning our networks, we used the Torch framework written in the Lua language because of its flexibility and speed, and ResNet made a fork of the ResNet implementation from Facebook . We used three tests to validate the quality of the network.
The first Places val test is the validation of the Places Sift set. The second test is Places Sift using Scene Mapping, and the third is the closest to the combat situation, the Cloud test. Images of employees are taken from the cloud and marked up manually. In the picture below there are two examples of such images.
We began to measure and train the network, compare them with each other. The first is the ResNet-152 benchmark, which comes with Places2, the second is the ResNet-50, which was trained on ImageNet and upgraded to our base, the result was already better. Then they took ResNet-200, they also trained on ImageNet, and in the end it showed the best result.
Below are examples of work. This is the ResNet-152 benchmark. Predicted - these are the original labels, which gives the network. Mapped lables are labels that came out after Scene Mapping. It is evident that the result is not very good. That is, she seems to give something in the case, but not very well.
The next example is the work of ResNet-200. Already very adequate.
ResNet Improvement
We decided to try to improve our network, and at first tried to just increase the depth of the network, but after that it became much more difficult to train it. This is a known problem. Last year there were several articles on this subject, which say that ResNet, in fact, is an ensemble of a large number of ordinary networks of different depths.
Res blocks, which are located at the end of the grid, make a small contribution to the formation of the final result. It seems more promising to increase not the depth of the network, but its width, that is, the number of filters inside the Res-block.
This idea is implemented by the Wide Residual Network, which appeared in 2016. We eventually used the WRN-50-2, which is the usual ResNet-50 with twice the number of filters in the internal 3x3 bottleneck convolution.
The network shows similar results on ImageNet with ResNet-200, which we have already used, but, importantly, it is almost twice as fast. Here are two implementations of the Residual-block on Torch, the bright parameter is highlighted, which is doubled. We are talking about the number of filters in the internal convolution.
These are measurements on ImageNet ResNet-200 tests. At first we took the WRN-22-6, it showed the result worse. Then they took WRN-50-2-ImageNet, trained him, took WRN-50-2, trained on ImageNet, and retrained on Places2-challenge, he showed the best result.
Here is an example of the work of the WRN-50-2 - quite an adequate result in our pictures, which you have already seen.
And this is an example of working in combat photos, also successfully.
There are, of course, not very good work. The bridge of Alexander III in Paris was not recognized as a bridge.
Model improvement
We wondered how to improve this model. The ResNet family continues to improve, new articles are coming out. In particular, an interesting article by PyramidNet was published in 2016, which showed promising results on CIFAR-10/100 and ImageNet.
The idea is not to dramatically increase the width of the Residual-block, but to do it gradually. We have trained several variants of this network, but, unfortunately, it showed results a little worse than our combat model.
In the spring of 2018, the ResNext model was released, also a promising idea: to split the Residual-block into several parallel blocks of a smaller size and smaller width. This is similar to the idea of Inception, we also experimented with it. But, unfortunately, it showed worse results than our model.
We also experimented with various “creative” approaches to improve our models. In particular, we tried to use Class activation mapping (CAM), that is, these are the objects that the network is looking at when it classifies an image.
Our idea was that instances of the same scene should have the same or similar objects as the CAM class. We tried using this approach. First, they took two networks. One is ImageNet-trained, the second is our model we want to improve.
We take the image, run it through network 2, add CAM for the layer, then feed it to the input of network 1. Run through network 1, add the results to the loss function of network 2, continue it on the new loss functions.
The second option is that we run the image through network 2, take CAM, feed network 1, and then use this data to simply train network 1 and use the ensemble from the results of network 1 and network 2.
We trained our model on the WRN-50-2, ResNet-50 ImageNet was used as network 1, but it didn’t work out to significantly increase the quality of our model.
But we are continuing research on how to improve our results: we are teaching new CNN architectures, in particular, the ResNet family. We are trying to experiment with CAM and are considering different approaches with smarter image patch processing - it seems to us that this approach is quite promising.
Sight Recognition
We have a good model for recognizing scenes, but now we want to recognize some significant places, that is, sights. In addition, users often take pictures of them or take pictures on their background.
We want, as a result, to give us not just cathedrals, as in the image on the slide, but the system to say: “Here there are Notre Dame de Paris and the cathedrals in Prague.”
When we solved this problem, we faced some difficulties.
- Virtually no research on this topic and no ready data in the public domain.
- A small number of "clean" images in the public domain for each attraction.
- It's not entirely clear that buildings are a landmark. For example, a house with towers on the square. TripAdvisor does not consider Lev Tolstoy in Petersburg to be landmarks, but Google does.
We started by collecting the database, compiled a list of 100 cities, and then used the Google Places API to download JSON data on attractions from these cities.
The data was filtered and parsili, and according to the received list, 20 images were downloaded from Google Search for each attraction. The number 20 is taken from empirical considerations. As a result, we received a database of 2827 attractions and about 56 thousand images. This is the base on which we trained our model. To validate our model, we used two tests.
Cloud test - these are images from our employees, marked up manually. It contains 200 pictures in 15 cities and 10 thousand images of no landmarks. The second is the Search test. It was built using Mail.ru search, which contains from 3 to 10 images for each landmark, but unfortunately, this test is dirty.
We trained the first models, but they showed poor results on the Cloud test in combat photos.
Here is an example of the image in which we were trained, and an example of combat photography. The problem with people is that they are often photographed against the background of attractions. On those images that we got out of the search, there were no people.
To combat this, we added a “human” augmentation while training. That is, we used the standard approaches: random turns, accidental cutting out part of the image, and so on. But also in the process of learning, we randomly added people to some images.
This approach helped us to solve the problem with people and get an acceptable quality of the model.
Fine tunning scene models
How we trained the model: there is a certain training base, but it is rather small. But we know that the landmark is a special case of the scene. And we have a pretty good Scene model. We decided to train her on the sights. To do this, we added several fully connected and BN layers on top of the network, and the top three Residual blocks also trained them. The rest of the network has been frozen.
In addition, for training, we use a non-standard function of loss of center loss. When training, Center loss tries to “pull apart” representatives of different classes in different clusters, as shown in the picture.
When training, we added another class "not a landmark." And no center loss was applied to this class. On such a mixed loss function, training was conducted.
After we have trained the network, we cut off the last classifying layer from it, and when the image passes through the network, it turns into a numerical vector, which is called embedding.
To further build the sights recognition system, we built reference vectors for each class. We took each class of attractions from the set and drove the images through the network. We received embeddings and took their average vector, which they called the class reference vector.
To determine the sights in the photo, we run the input image through the network, and its embedding is compared with the reference vector of each class. If the result of the comparison is less than the threshold, then we believe that there are no landmarks in the image. Otherwise, we take the class with the highest comparison value.
Test results
- On the cloud test, the accuracy of sights was 0.616, not sights - 0.981
- The search test received an average accuracy of 0.669, an average completeness of 0.576.
Search didn’t get very good results, but this is explained by the fact that the first one is rather “dirty”, and the second one has its peculiarities - among the sights there are different botanical gardens that are similar in all cities.
There was an idea for recognizing scenes to first train the network, which would determine the scene mask, that is, remove objects from the foreground from it, and then feed it into the model itself, which recognizes scenes of an image without these areas, where the background is obstructed. But it is not very clear what exactly needs to be removed from the front layer, which mask is needed.
It will be a rather complicated and clever thing, because not everyone understands which objects belong to the scene, and which are superfluous. For example, people in the restaurant may be needed. This is not a trivial decision, we tried to do something similar, but it did not give good results.
Here is an example of working in combat photos.
Examples of successful work:
But unsuccessful work: the sights were not found. The main problem of our model at the moment is not that the network confuses sights with each other, but that it does not find them in the photo.
In the future, we plan to assemble a base for even more cities, find new methods of network training for this task, and identify opportunities for increasing the number of classes without retraining the network.
findings
Today we:
- We looked at the data sets for Scene recognition;
- They saw that the Wide Residual Network is the best model;
- We discussed further possibilities for increasing the quality of this model;
- We looked at the problem of recognizing sights, what difficulties arise;
- Described the algorithm for collecting the base and methods of learning models for the recognition of attractions.
I can say that the tasks are interesting, but little studied in the community. They are interesting to do, because you can apply non-standard approaches that are not used in the usual recognition of objects.
Minute advertising. If you liked this report from the SmartData conference - note that SmartData 2018 will be held in St. Petersburg on October 15th - a conference for those immersed in the world of machine learning, analysis and data processing. The program will have a lot of interesting things, the site already has the first speakers and reports.
Source: https://habr.com/ru/post/419501/
All Articles