UI autotests: how to do not
Hello, Habr. My name is Vitaliy Kotov, I work in the testing department of Badoo. I write a lot of UI autotests, but I work even more with those who have been doing this not so long ago and have not had time to step on all the rakes.
So, adding up my own experience and observing other guys, I decided to prepare for you a collection of “how to write tests is not worth it.” I supported each example with a detailed description, code examples and screenshots.
The article will be interesting to novice authors of UI-tests, but the old-timers in this topic will surely learn something new, or just smile, remembering themselves “in youth”. :)
')
Go!

Let's start with a simple example. Since we are talking about UI tests, locators play a significant role in them. A locator is a string composed according to a certain rule and describing one or several XML (in particular, HTML) elements.
There are several types of locators. For example, css locators are used for cascading style sheets. XPath locators are used to work with XML documents. And so on.
A complete list of locator types used in Selenium can be found at seleniumhq.imtqy.com .
In UI tests, locators are used to describe the elements with which the driver must interact.
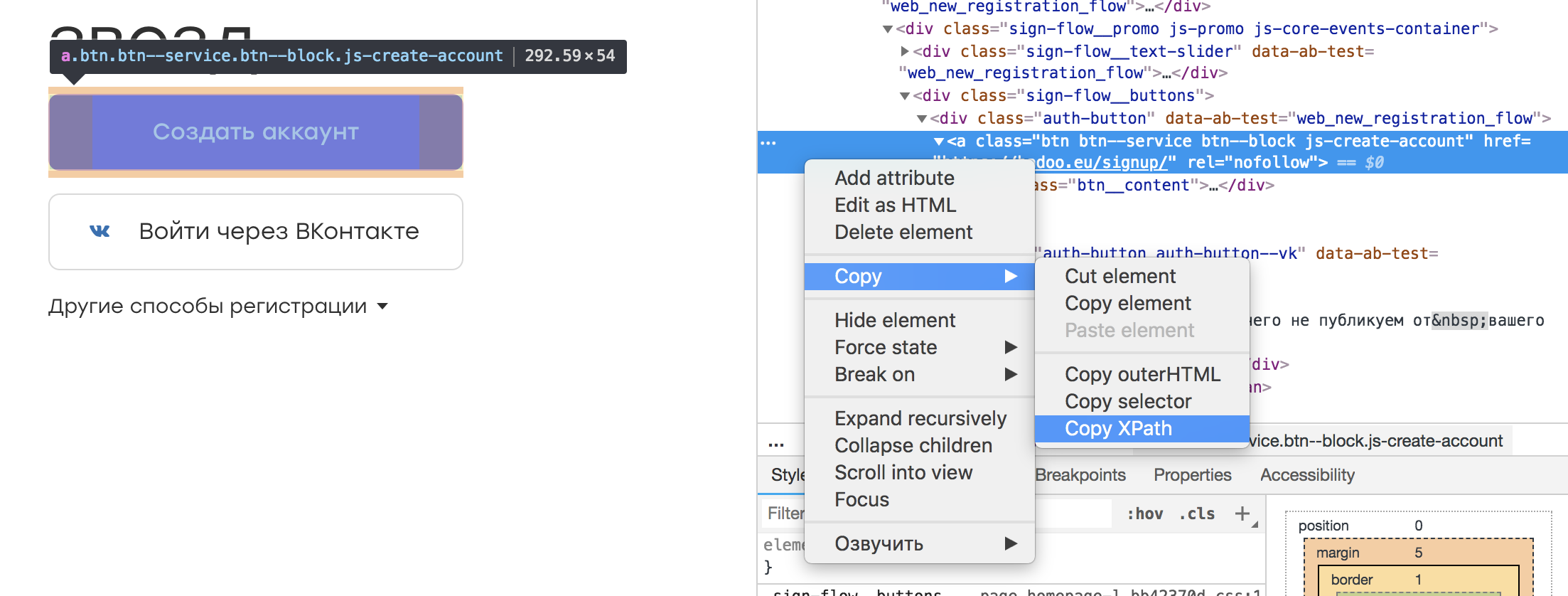
Virtually any browser inspector has the ability to select the element of interest to us and copy it to XPath. It looks like this:
It turns out such a locator:
It seems that there is nothing wrong with such a locator. After all, we can save it in some kind of constant or class field, which by its name will convey the essence of the element:
And wrap the appropriate error text in case the element is not found:
This approach has a plus: there is no need to learn XPath.
However, there are a number of disadvantages. First, when changing the layout there is no guarantee that the element on such a locator will remain the same. It is possible that another will take its place, leading to unforeseen circumstances. Secondly, the task of autotests is to search for bugs, and not to follow the changes in the layout. Therefore, adding a wrapper or some other element above the tree should not affect our tests. Otherwise, it will take us quite a lot of time to update the locators.
Conclusion: locators should be created that correctly describe the element and are resistant to changes in the layout outside the tested part of our application. For example, you can bind to one or more attributes of an element:
Such a locator is easier to perceive in the code, and it will break only if the “rel” disappears.
Another plus of this locator is the ability to search in the repository of the template with the specified attribute. And what to look for if the locator looks like in the original example? :)
If, initially, the elements have no attributes in the application or they are set automatically (for example, due to obfuscation of classes), it is worth discussing it with the developers. They should be no less interested in automating product testing and will surely meet you and offer a solution.
Every Badoo user has his own profile. It contains information about the user: (name, age, photos) and information about who the user wants to communicate with. In addition, it is possible to specify your interests.
Suppose once we had a bug (although, of course, this is not so :)). The user in his profile chose interests. Not finding a suitable interest from the list, he decided to click "More" to update the list.
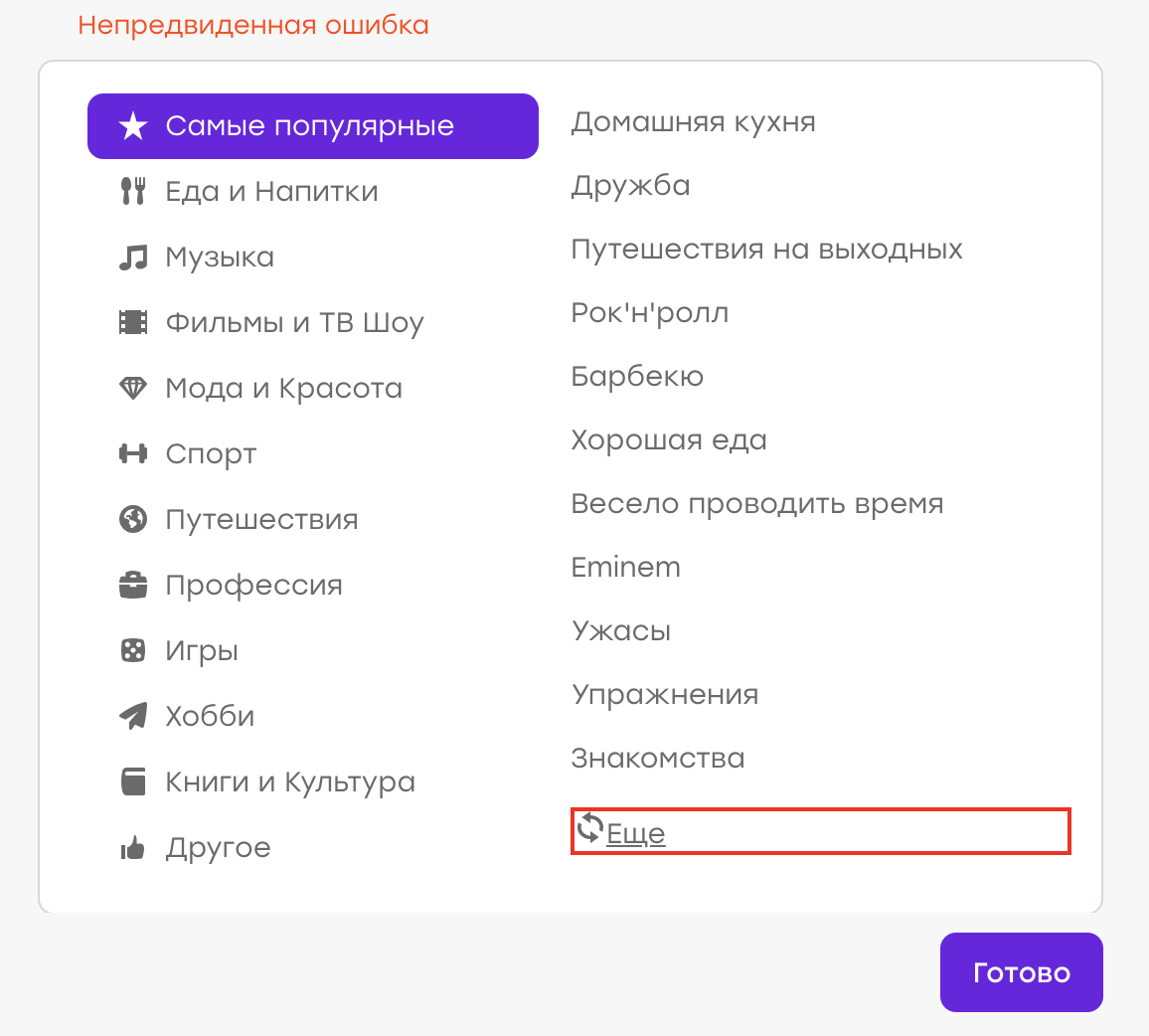
Expected behavior: old interests should disappear, new ones should appear. But instead, an “Unexpected Error” popped up:
It turned out that there was a problem on the server side, the wrong answer came, and the client processed the case, showing the corresponding notification.
Our task is to write an autotest that will check this case.
We write about the following script:
This is the test we are launching. However, the following happens: after a few days / months / years, the bug reappears, although the test does not catch anything. Why?
Everything is quite simple: during the successful passing of the test, the element locator for which we searched for the error text has changed. There was a refactoring of templates and instead of the class “error” we had a class “error_new”.
During refactoring, the test continued to work as expected. Element “div.error” did not appear, there was no reason for the fall. But now the “div.error” element does not exist at all - therefore, the test will never fall, no matter what happens in the application.
Conclusion: it is better to test the performance of the interface with positive checks. In our example, one would expect the list of interests to change.
There are situations when a negative test cannot be replaced by a positive one. For example, when interacting with an element in a “good” situation, nothing happens, and in a “bad” situation, an error occurs. In this case, it is worthwhile to think of a way to simulate a “bad” scenario and write an autotest on it too. Thus, we will verify that in the negative case an element of error appears, and thus we will monitor the relevance of the locator.
How to make sure that the interaction of the test with the interface was successful and everything works? Most often this can be seen in the changes that have occurred in this interface.
Consider an example. You must make sure that when sending a message it appears in the chat:
The script looks like this:
We describe this scenario in our test. Suppose a chat message matches a locator:
This is how we verify that the item appeared:
If our wait works, then everything is fine: messages in the chat are rendered.
As you may have guessed, after some time sending messages in the chat breaks down, but our test continues to work without interruption. Let's figure it out.
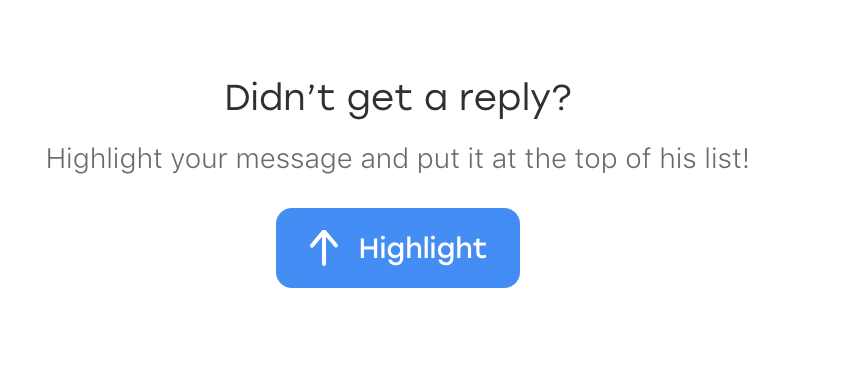
It turns out that a new element appeared in the chat the day before: some text that invites the user to highlight a message if it suddenly went unnoticed:
And, funny thing is, it also falls under our locator. Only he has an additional class that distinguishes him from the sent messages:
Our test did not break with the appearance of this unit, but the “wait for a message” check has ceased to be relevant. The element that was an indicator of a successful event is now always there.
Conclusion: if the test logic is based on checking the appearance of an element, you should definitely check that there is no such element before our interaction with the UI.
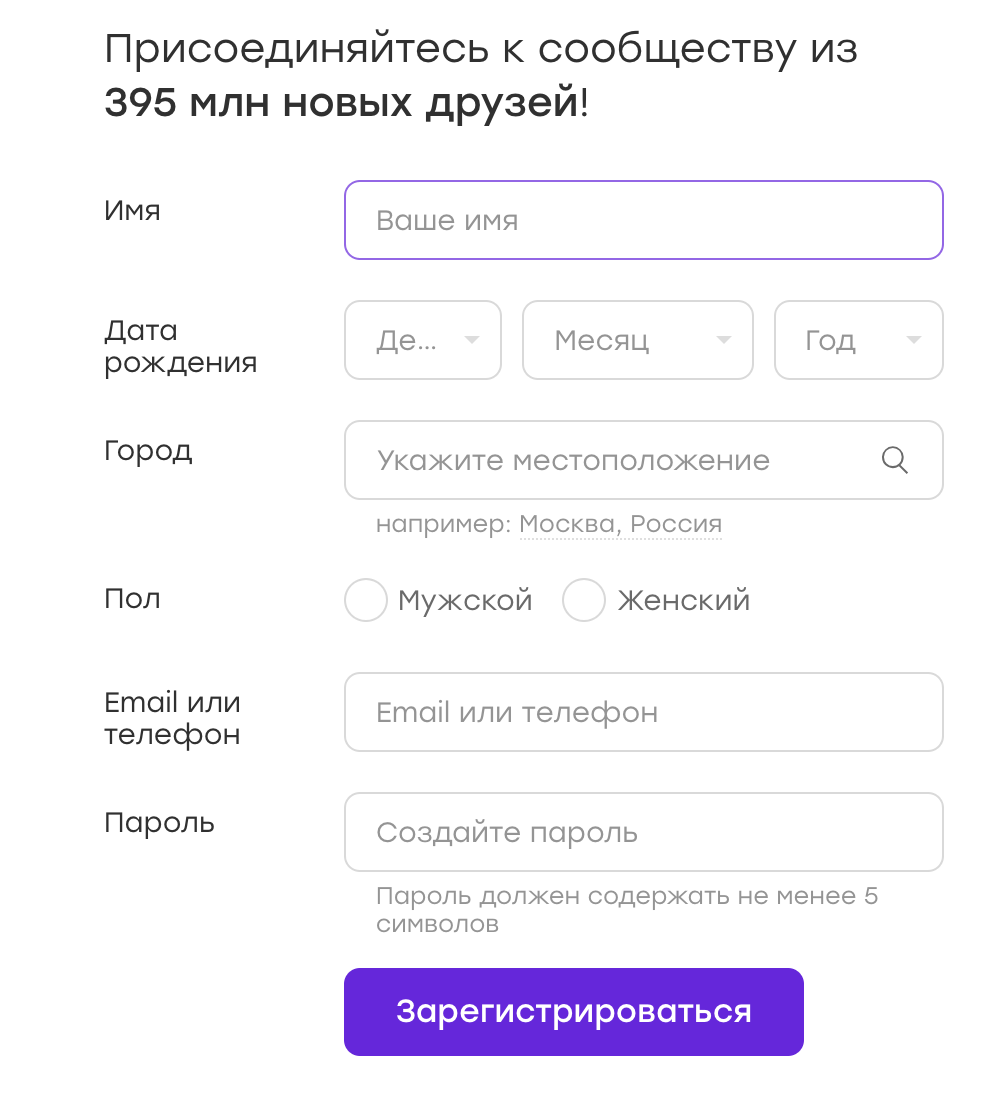
Quite often, UI tests work with the forms in which they enter certain data. For example, we have a registration form:
Data for such tests can be stored in configs or hard-coded in the test. But sometimes the thought comes to mind: why not randomize the data? This is good, we will cover more cases!
My advice: do not. And now I will tell you why.
Suppose our test is registered on Badoo. We decide that the gender of the user we will choose randomly. At the time of writing the test, the flow registration for the girl and the boy is no different, so our test passes successfully.
Now imagine that after some time the registration flow becomes different. For example, we give a girl free bonuses immediately after registration, which we notify her with a special overlay.
In the test there is no logic to close the overlay, and it, in turn, interferes with any further actions prescribed in the test. We get a test that falls 50% of the time. Any automator will confirm that UI tests are inherently not stable. And this is normal, one has to live with it, constantly tacking between redundant logic “for all occasions” (which significantly damages the readability of the code and complicates its support) and this very instability.
The next time the test falls, we may not have time to deal with it. We just restart it and see what it is. We will decide that in our application everything works as it should and the point is in an unstable test. And calm down.
Now let's go further. What if this overlay breaks? The test will continue to pass in 50% of cases, which significantly postpones the problem.
And this is good when, due to the randomization of data, we create a situation of “50 to 50”. But it happens in a different way. For example, before registering, a password of at least three characters was considered acceptable. We write code that comes up with a random password no shorter than three characters (sometimes there are three and sometimes more characters). And then the rule changes - and the password must contain at least four characters. What probability of falling will we get in this case? And, if our test will catch a real bug, how quickly will we figure this out?
It is especially difficult to work with tests where a lot of random data is entered: name, gender, password, and so on ... In this case too many different combinations, and if an error occurs in one of them, it is usually not easy to notice.
Conclusion. As I wrote above, randomizing data is bad. It is better to cover more cases at the expense of data providers, not forgetting about equivalence classes , by itself. Passing tests will take more time, but you can fight it. But we will be sure that if a problem exists, it will be detected.
Let's look at the following example. We are writing a test that checks the user count in the footer.

The script is simple:
We call this test testFooterCounter and run it. Then it becomes necessary to check that the meter does not show zero. We add this test to an existing test, why not?
But then there is a need to check that there is a link to the project description in the footer (the link “About Us”). Write a new test or add to an existing one? In the case of a new test, we will have to re-raise the application, prepare the user (if we check the footer on the authorized page), log in - in general, waste precious time. In such a situation, renaming the test to testFooterCounterAndLinks seems like a good idea.
On the one hand, this approach has advantages: saving time, storing all the checks of some part of our application (in this case, the footer) in one place.
But there is a noticeable minus. If the test fails at the first check, we will not check the rest of the component. Suppose the test fell in some branch not because of instability, but because of a bug. What to do? Return task, describing only this problem? Then we risk getting the task with fix only this bug, run the test and find that the component is also broken further, in another place. And there can be many such iterations. Kicking a ticket back and forth in this case will take a lot of time and will be ineffective.
Conclusion: it is worth if possible to atomize the checks. In this case, even having a problem in one case, we will check all the others. And, if you have to return the ticket, we can immediately describe all the problem areas.
Consider another example. We are writing a chat test that checks the following logic. If the users have a mutual sympathy, the following block appears in the chat:

The script looks like this:
For a while the test works successfully, but then the following happens ... No, this time the test does not miss any bug. :)
After some time, we learn that there is another bug not related to our test: if we open the chat, immediately close and open it again, the block disappears. Not the most obvious case, and in the test we, of course, did not foresee it. But we decide to cover it too.
The same question arises: write another test or insert a test into an existing one? It seems inexpedient to write a new one, because 99% of the time it will do the same thing as an existing one. And we decide to add the test to the test that already exists:
The problem may emerge when, for example, we refactor a test after a long time. For example, a redesign will happen on a project - and many tests will have to be rewritten.
We will open the test and will try to remember what it checks. For example, the test is called testPromoAfterMutualAttraction. Will we understand why at the end of the opening and closing of the chat? Most likely no. Especially if this test was not written by us. Will we leave this piece? Maybe yes, but if there are any problems with it, it is likely that we will simply remove it. And the test will be lost simply because its meaning will be unclear.
I see two solutions here. First, do the second test and call it testCheckBlockPresentAfterOpenAndCloseChat. With such a name it will be clear that we are not just doing some kind of set of actions, but doing a conscious check, because there was a negative experience. The second solution is to write in the code a detailed comment about why we are doing this test in this particular test. In the comments, it is also desirable to indicate the bug number.
The following example threw me a bbidox , for which he is a big plus in karma!
There is a very interesting situation when the test code becomes already ... a framework. Suppose we have this method:
At some point, something strange begins to happen with this method: the test crashes when you try to click a button. We open a screenshot taken at the moment the test crashes, and we see that the button on the screenshot is and the waitForButtonToAppear method worked successfully. Question: what is wrong with a click?
The most difficult thing in this situation is that the test can sometimes be successful. :)
Let's figure it out. Suppose that the button in the example is located on the overlay:
This is a special overlay through which a user on our site can fill out information about himself. When you click on the selected overlay button, the next block appears for filling.
For fun, let's add an extra OLOLO class for this button:
After that we click on this button. Visually, nothing has changed, and the button itself has remained in place:
What happened? In fact, when JS redrawn the block to us, the button redrawed it too. It is still available on the same locator, but this is another button. This is indicated by the absence of the OLOLO class we added.
In the code above, we store the element in the $ element variable. If during this time the element is regenerated, visually it may not be noticeable, but clicking on it will not work anymore - the click () method will fall with an error.
There are several solution options:
Finally, a simple but equally important point.
This example applies not only to UI tests, but also to them very often. Usually, when you write a test, you are in the context of what is happening: you describe the test for the test and understand their meaning. And the texts of errors you write in the same context:
What could be incomprehensible in this code? The test awaits the appearance of the button and, if it does not exist, naturally falls.
Now imagine that the author of the test at the hospital, and his colleague looks after the tests. And now the testQuestionsOnProfile test fails and writes the following message: “Cannot find button”. A colleague needs to sort things out as soon as possible, because the release is coming soon.

What will he have to do?
It makes no sense to open the page on which the test fell, and check the a.link locator - there is no element. Therefore, it is necessary to carefully study the test and understand what he is checking.
It would be much easier with a more detailed text of the error: “Cannot find the button on the questions overlay”. With this error, you can immediately open the overlay and see where the button went.
Output two. First, in any method of your test framework it is worth passing the text of the error, with the obligatory parameter so that there is no temptation to forget about it. Secondly, the text of the error is worth doing detailed. This does not always mean that it should be long - it is enough to make it clear what went wrong in the test.
How to understand that the text of the error is written well? Very simple. Imagine that your application is broken and you need to go to the developers and explain what and where it broke. If you tell them only what is written in the text of the error, they will understand?
Writing a test script is often an interesting exercise. At the same time, we pursue many goals. Our tests should:
It is especially interesting to work with tests in a constantly evolving and changing project, where they have to be constantly updated: add something and cut something. That is why it is worthwhile to think over some points in advance and not always rush into decisions. :)
I hope my advice will help you avoid some of the problems and force you to approach to the drafting of cases more thoughtfully. If the article is liked by the public, I will try to collect some more non-dull examples. And bye bye!
So, adding up my own experience and observing other guys, I decided to prepare for you a collection of “how to write tests is not worth it.” I supported each example with a detailed description, code examples and screenshots.
The article will be interesting to novice authors of UI-tests, but the old-timers in this topic will surely learn something new, or just smile, remembering themselves “in youth”. :)
')
Go!
Content
- Locators without attributes
- Check for missing item
- Check item appearance
- Random data
- Atomicity of tests (part 1)
- Atomicity of tests (part 2)
- Error clicking on an existing item
- Error text
- Total
Locators without attributes
Let's start with a simple example. Since we are talking about UI tests, locators play a significant role in them. A locator is a string composed according to a certain rule and describing one or several XML (in particular, HTML) elements.
There are several types of locators. For example, css locators are used for cascading style sheets. XPath locators are used to work with XML documents. And so on.
A complete list of locator types used in Selenium can be found at seleniumhq.imtqy.com .
In UI tests, locators are used to describe the elements with which the driver must interact.
Virtually any browser inspector has the ability to select the element of interest to us and copy it to XPath. It looks like this:
It turns out such a locator:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
It seems that there is nothing wrong with such a locator. After all, we can save it in some kind of constant or class field, which by its name will convey the essence of the element:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a") public WebElement createAccountButton; And wrap the appropriate error text in case the element is not found:
public void waitForCreateAccountButton() { By by = By.xpath(this.createAccountButton); WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds); wait .withMessage(“Cannot find Create Account button.”) .until( ExpectedConditions.presenceOfElementLocated(by) ); } This approach has a plus: there is no need to learn XPath.
However, there are a number of disadvantages. First, when changing the layout there is no guarantee that the element on such a locator will remain the same. It is possible that another will take its place, leading to unforeseen circumstances. Secondly, the task of autotests is to search for bugs, and not to follow the changes in the layout. Therefore, adding a wrapper or some other element above the tree should not affect our tests. Otherwise, it will take us quite a lot of time to update the locators.
Conclusion: locators should be created that correctly describe the element and are resistant to changes in the layout outside the tested part of our application. For example, you can bind to one or more attributes of an element:
//a[@rel=”createAccount”]
Such a locator is easier to perceive in the code, and it will break only if the “rel” disappears.
Another plus of this locator is the ability to search in the repository of the template with the specified attribute. And what to look for if the locator looks like in the original example? :)
If, initially, the elements have no attributes in the application or they are set automatically (for example, due to obfuscation of classes), it is worth discussing it with the developers. They should be no less interested in automating product testing and will surely meet you and offer a solution.
Check for missing item
Every Badoo user has his own profile. It contains information about the user: (name, age, photos) and information about who the user wants to communicate with. In addition, it is possible to specify your interests.
Suppose once we had a bug (although, of course, this is not so :)). The user in his profile chose interests. Not finding a suitable interest from the list, he decided to click "More" to update the list.
Expected behavior: old interests should disappear, new ones should appear. But instead, an “Unexpected Error” popped up:
It turned out that there was a problem on the server side, the wrong answer came, and the client processed the case, showing the corresponding notification.
Our task is to write an autotest that will check this case.
We write about the following script:
- View Profile
- View interest list
- Click the "More" button
- Verify that the error did not appear (for example, there is no div.error element)
This is the test we are launching. However, the following happens: after a few days / months / years, the bug reappears, although the test does not catch anything. Why?
Everything is quite simple: during the successful passing of the test, the element locator for which we searched for the error text has changed. There was a refactoring of templates and instead of the class “error” we had a class “error_new”.
During refactoring, the test continued to work as expected. Element “div.error” did not appear, there was no reason for the fall. But now the “div.error” element does not exist at all - therefore, the test will never fall, no matter what happens in the application.
Conclusion: it is better to test the performance of the interface with positive checks. In our example, one would expect the list of interests to change.
There are situations when a negative test cannot be replaced by a positive one. For example, when interacting with an element in a “good” situation, nothing happens, and in a “bad” situation, an error occurs. In this case, it is worthwhile to think of a way to simulate a “bad” scenario and write an autotest on it too. Thus, we will verify that in the negative case an element of error appears, and thus we will monitor the relevance of the locator.
Check item appearance
How to make sure that the interaction of the test with the interface was successful and everything works? Most often this can be seen in the changes that have occurred in this interface.
Consider an example. You must make sure that when sending a message it appears in the chat:
The script looks like this:
- View user profile
- Open chat with him
- to write a message
- To send
- Wait for the message to appear
We describe this scenario in our test. Suppose a chat message matches a locator:
p.message_text
This is how we verify that the item appeared:
this.waitForPresence(By.css('p.message_text'), "Cannot find sent message."); If our wait works, then everything is fine: messages in the chat are rendered.
As you may have guessed, after some time sending messages in the chat breaks down, but our test continues to work without interruption. Let's figure it out.
It turns out that a new element appeared in the chat the day before: some text that invites the user to highlight a message if it suddenly went unnoticed:
And, funny thing is, it also falls under our locator. Only he has an additional class that distinguishes him from the sent messages:
p.message_text.highlight
Our test did not break with the appearance of this unit, but the “wait for a message” check has ceased to be relevant. The element that was an indicator of a successful event is now always there.
Conclusion: if the test logic is based on checking the appearance of an element, you should definitely check that there is no such element before our interaction with the UI.
- View user profile
- Open chat with him
- Make sure there are no sent messages.
- to write a message
- To send
- Wait for the message to appear
Random data
Quite often, UI tests work with the forms in which they enter certain data. For example, we have a registration form:
Data for such tests can be stored in configs or hard-coded in the test. But sometimes the thought comes to mind: why not randomize the data? This is good, we will cover more cases!
My advice: do not. And now I will tell you why.
Suppose our test is registered on Badoo. We decide that the gender of the user we will choose randomly. At the time of writing the test, the flow registration for the girl and the boy is no different, so our test passes successfully.
Now imagine that after some time the registration flow becomes different. For example, we give a girl free bonuses immediately after registration, which we notify her with a special overlay.
In the test there is no logic to close the overlay, and it, in turn, interferes with any further actions prescribed in the test. We get a test that falls 50% of the time. Any automator will confirm that UI tests are inherently not stable. And this is normal, one has to live with it, constantly tacking between redundant logic “for all occasions” (which significantly damages the readability of the code and complicates its support) and this very instability.
The next time the test falls, we may not have time to deal with it. We just restart it and see what it is. We will decide that in our application everything works as it should and the point is in an unstable test. And calm down.
Now let's go further. What if this overlay breaks? The test will continue to pass in 50% of cases, which significantly postpones the problem.
And this is good when, due to the randomization of data, we create a situation of “50 to 50”. But it happens in a different way. For example, before registering, a password of at least three characters was considered acceptable. We write code that comes up with a random password no shorter than three characters (sometimes there are three and sometimes more characters). And then the rule changes - and the password must contain at least four characters. What probability of falling will we get in this case? And, if our test will catch a real bug, how quickly will we figure this out?
It is especially difficult to work with tests where a lot of random data is entered: name, gender, password, and so on ... In this case too many different combinations, and if an error occurs in one of them, it is usually not easy to notice.
Conclusion. As I wrote above, randomizing data is bad. It is better to cover more cases at the expense of data providers, not forgetting about equivalence classes , by itself. Passing tests will take more time, but you can fight it. But we will be sure that if a problem exists, it will be detected.
Atomicity of tests (part 1)
Let's look at the following example. We are writing a test that checks the user count in the footer.
The script is simple:
- Open application
- Find counter on footer
- Make sure it's visible
We call this test testFooterCounter and run it. Then it becomes necessary to check that the meter does not show zero. We add this test to an existing test, why not?
But then there is a need to check that there is a link to the project description in the footer (the link “About Us”). Write a new test or add to an existing one? In the case of a new test, we will have to re-raise the application, prepare the user (if we check the footer on the authorized page), log in - in general, waste precious time. In such a situation, renaming the test to testFooterCounterAndLinks seems like a good idea.
On the one hand, this approach has advantages: saving time, storing all the checks of some part of our application (in this case, the footer) in one place.
But there is a noticeable minus. If the test fails at the first check, we will not check the rest of the component. Suppose the test fell in some branch not because of instability, but because of a bug. What to do? Return task, describing only this problem? Then we risk getting the task with fix only this bug, run the test and find that the component is also broken further, in another place. And there can be many such iterations. Kicking a ticket back and forth in this case will take a lot of time and will be ineffective.
Conclusion: it is worth if possible to atomize the checks. In this case, even having a problem in one case, we will check all the others. And, if you have to return the ticket, we can immediately describe all the problem areas.
Atomicity of tests (part 2)
Consider another example. We are writing a chat test that checks the following logic. If the users have a mutual sympathy, the following block appears in the chat:
The script looks like this:
- Vote by user A for user B
- Vote by user B for user A
- User A open chat with user B
- Confirm that the block is in place
For a while the test works successfully, but then the following happens ... No, this time the test does not miss any bug. :)
After some time, we learn that there is another bug not related to our test: if we open the chat, immediately close and open it again, the block disappears. Not the most obvious case, and in the test we, of course, did not foresee it. But we decide to cover it too.
The same question arises: write another test or insert a test into an existing one? It seems inexpedient to write a new one, because 99% of the time it will do the same thing as an existing one. And we decide to add the test to the test that already exists:
- Vote by user A for user B
- Vote by user B for user A
- User A open chat with user B
- Confirm that the block is in place
- Close chat
- Open chat
- Confirm that the block is in place
The problem may emerge when, for example, we refactor a test after a long time. For example, a redesign will happen on a project - and many tests will have to be rewritten.
We will open the test and will try to remember what it checks. For example, the test is called testPromoAfterMutualAttraction. Will we understand why at the end of the opening and closing of the chat? Most likely no. Especially if this test was not written by us. Will we leave this piece? Maybe yes, but if there are any problems with it, it is likely that we will simply remove it. And the test will be lost simply because its meaning will be unclear.
I see two solutions here. First, do the second test and call it testCheckBlockPresentAfterOpenAndCloseChat. With such a name it will be clear that we are not just doing some kind of set of actions, but doing a conscious check, because there was a negative experience. The second solution is to write in the code a detailed comment about why we are doing this test in this particular test. In the comments, it is also desirable to indicate the bug number.
Error clicking on an existing item
The following example threw me a bbidox , for which he is a big plus in karma!
There is a very interesting situation when the test code becomes already ... a framework. Suppose we have this method:
public void clickSomeButton() { WebElement button_element = this.waitForButtonToAppear(); button_element.click(); } At some point, something strange begins to happen with this method: the test crashes when you try to click a button. We open a screenshot taken at the moment the test crashes, and we see that the button on the screenshot is and the waitForButtonToAppear method worked successfully. Question: what is wrong with a click?
The most difficult thing in this situation is that the test can sometimes be successful. :)
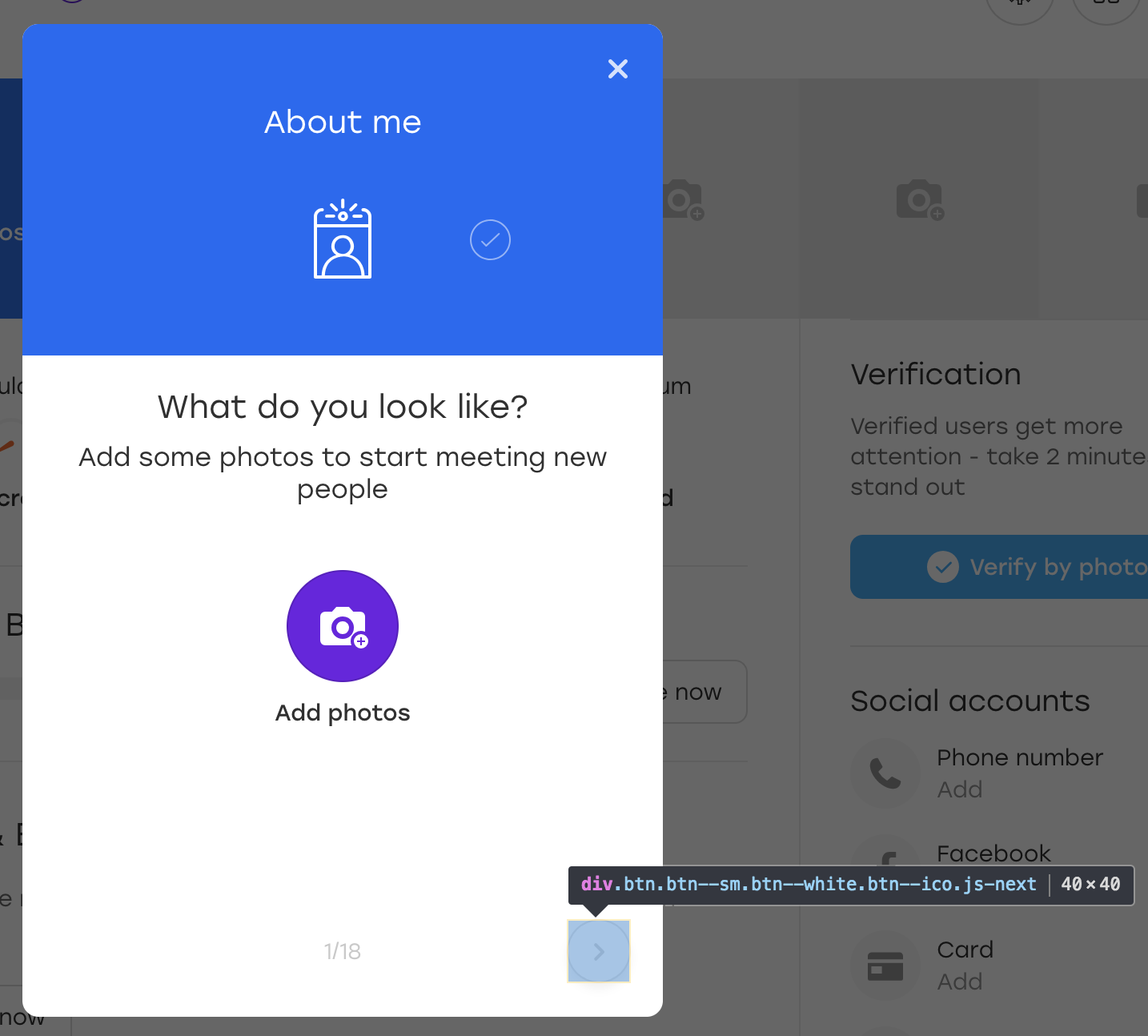
Let's figure it out. Suppose that the button in the example is located on the overlay:
This is a special overlay through which a user on our site can fill out information about himself. When you click on the selected overlay button, the next block appears for filling.
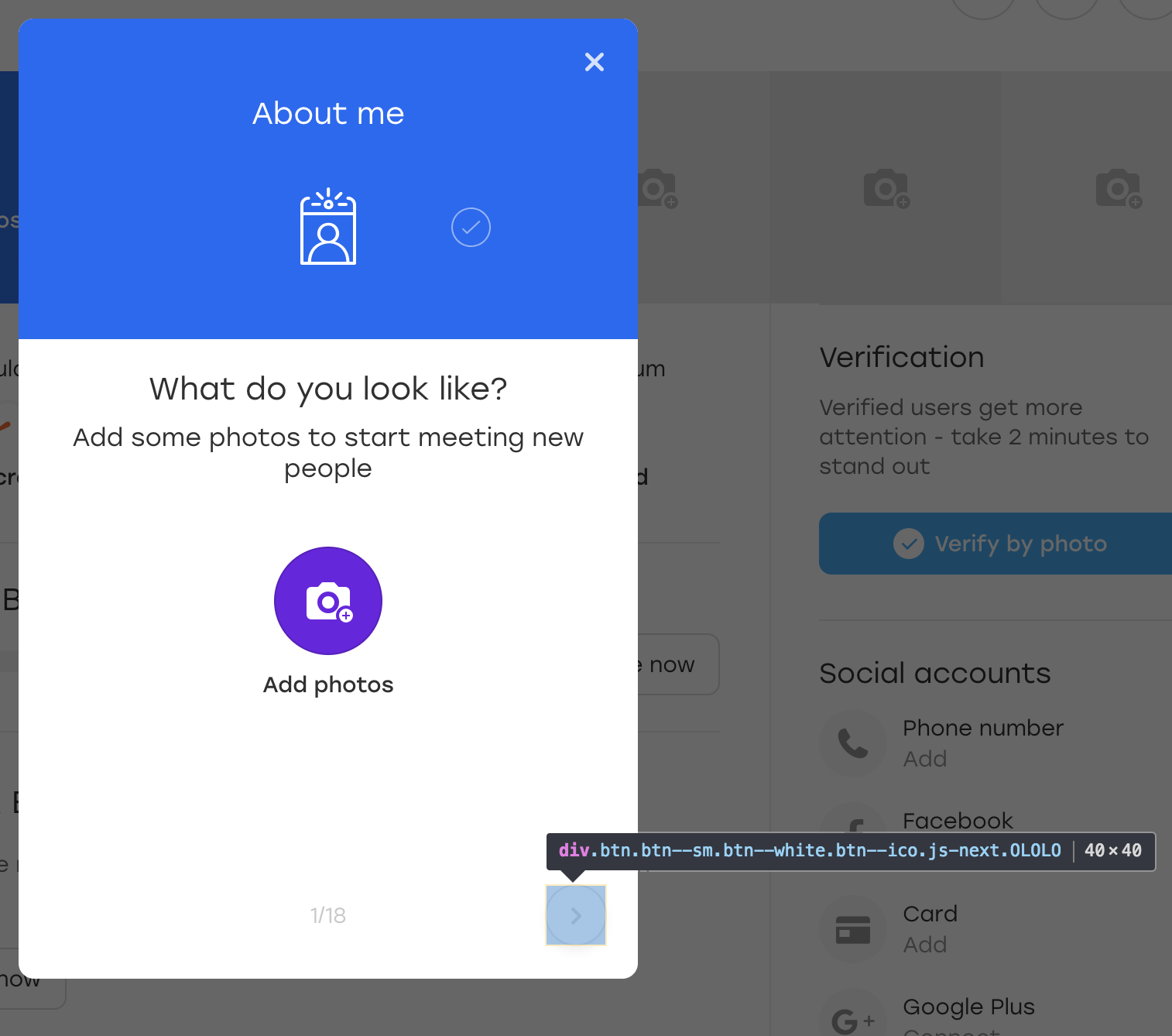
For fun, let's add an extra OLOLO class for this button:
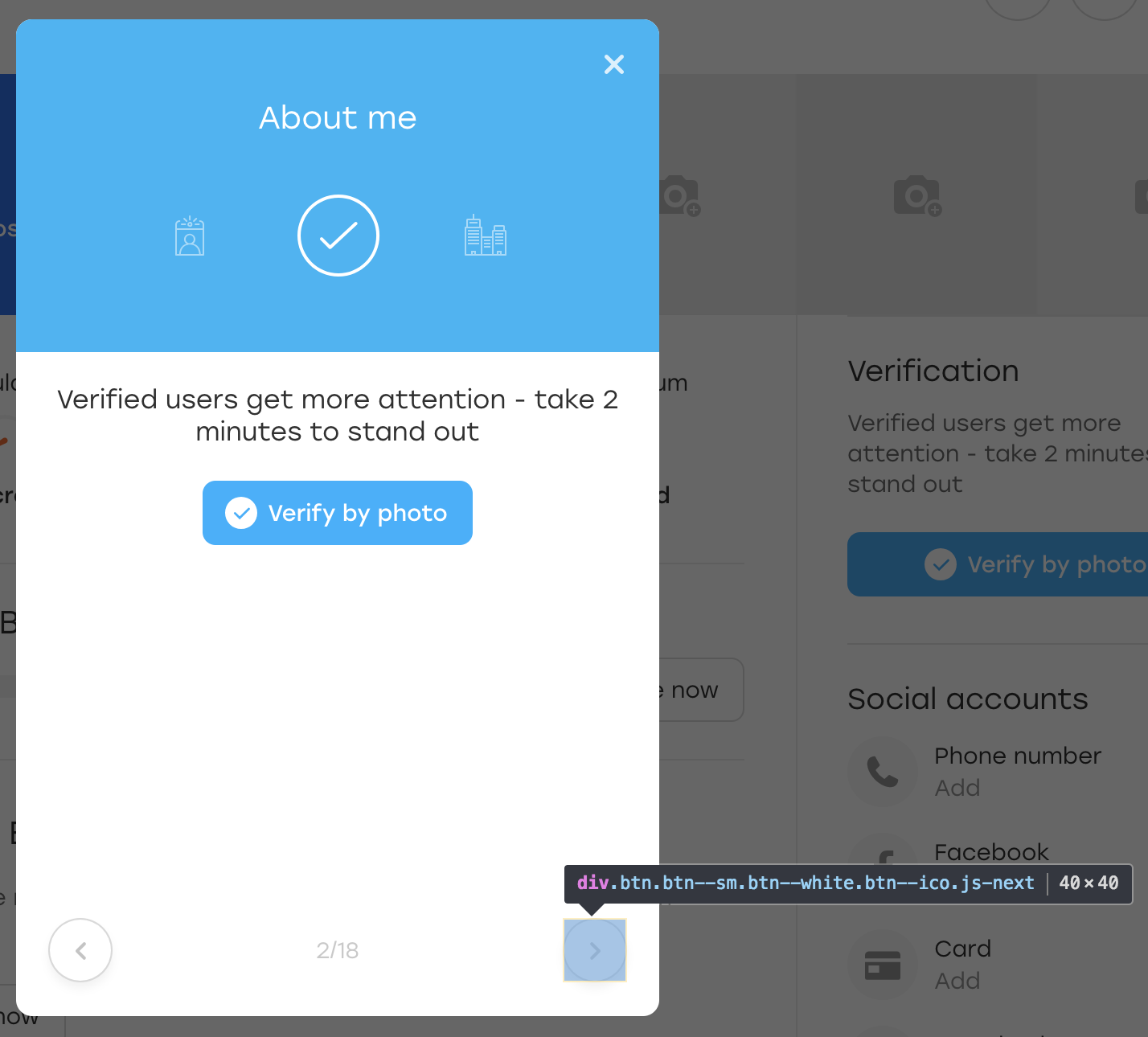
After that we click on this button. Visually, nothing has changed, and the button itself has remained in place:
What happened? In fact, when JS redrawn the block to us, the button redrawed it too. It is still available on the same locator, but this is another button. This is indicated by the absence of the OLOLO class we added.
In the code above, we store the element in the $ element variable. If during this time the element is regenerated, visually it may not be noticeable, but clicking on it will not work anymore - the click () method will fall with an error.
There are several solution options:
- Wrap the click in a try block and in catch reassemble the element
- Add some attribute to a button to signal that it has changed
Error text
Finally, a simple but equally important point.
This example applies not only to UI tests, but also to them very often. Usually, when you write a test, you are in the context of what is happening: you describe the test for the test and understand their meaning. And the texts of errors you write in the same context:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button"); What could be incomprehensible in this code? The test awaits the appearance of the button and, if it does not exist, naturally falls.
Now imagine that the author of the test at the hospital, and his colleague looks after the tests. And now the testQuestionsOnProfile test fails and writes the following message: “Cannot find button”. A colleague needs to sort things out as soon as possible, because the release is coming soon.
What will he have to do?
It makes no sense to open the page on which the test fell, and check the a.link locator - there is no element. Therefore, it is necessary to carefully study the test and understand what he is checking.
It would be much easier with a more detailed text of the error: “Cannot find the button on the questions overlay”. With this error, you can immediately open the overlay and see where the button went.
Output two. First, in any method of your test framework it is worth passing the text of the error, with the obligatory parameter so that there is no temptation to forget about it. Secondly, the text of the error is worth doing detailed. This does not always mean that it should be long - it is enough to make it clear what went wrong in the test.
How to understand that the text of the error is written well? Very simple. Imagine that your application is broken and you need to go to the developers and explain what and where it broke. If you tell them only what is written in the text of the error, they will understand?
Total
Writing a test script is often an interesting exercise. At the same time, we pursue many goals. Our tests should:
- cover as many cases as possible
- work as fast as possible
- to be clear
- just expand
- easy to maintain
- order pizza
- and so on…
It is especially interesting to work with tests in a constantly evolving and changing project, where they have to be constantly updated: add something and cut something. That is why it is worthwhile to think over some points in advance and not always rush into decisions. :)
I hope my advice will help you avoid some of the problems and force you to approach to the drafting of cases more thoughtfully. If the article is liked by the public, I will try to collect some more non-dull examples. And bye bye!
Source: https://habr.com/ru/post/419419/
All Articles