Benchmarking HDFS 3 with HDFS 2
Our company SberTech (Sberbank Technology) currently uses HDFS 2.8.4 because it has a number of advantages, such as the Hadoop ecosystem, fast work with large amounts of data, it is good at analytics and much more. But in December 2017, the Apache Software Foundation released a new version of an open framework for developing and executing distributed programs - Hadoop 3.0.0, which includes a number of significant improvements over the previous main release line (hadoop-2.x). One of the most important and interesting updates is the support of redundancy codes (Erasure Coding). Therefore, the task was set to compare these versions with each other.
SberTech has allocated 10 virtual machines of 40 GB in size for this research. Since the RS (10,4) encoding policy requires a minimum of 14 machines, it will not be possible to test it.
On one of the machines will be located NameNode in addition to the DataNode. Testing will be conducted under the following encoding policies:
')
And also, using replication with a replication factor of 3.
The size of the data block was chosen to be 32 MB.
Were conducted tests on the speed of data transmission. The data was transferred from the local file system to the distributed file system. The size of the file used in this test is 292.2 MB.
The following results were obtained:
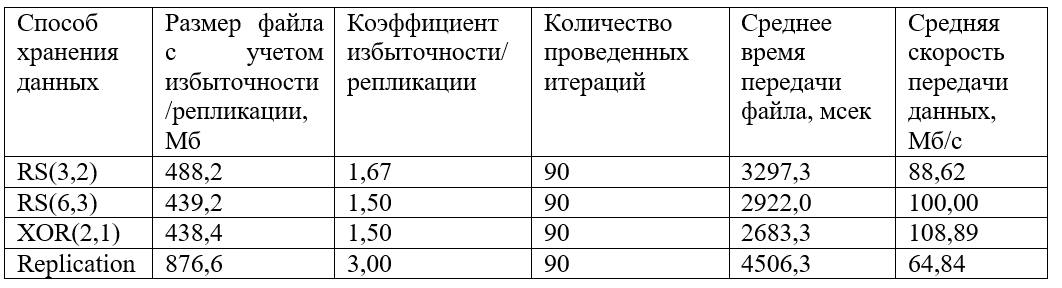
Also, a graph of grouped received values of file transfer time is plotted:

And also, a graph of the grouped received data transfer rate values:
As can be seen from the graph, the fastest data is transmitted with XOR (2.1) encoding. The RS (6.3) and RS (3.2) encodings show similar behavior, although the average speed of the RS (6.3) is slightly higher. Replication loses much speed (about 1.5 times less than XOR and 1.5 times less than RS).
With regard to storage efficiency, XOR (2.1) and RS (6.3) are the most profitable storage methods, with redundant data as low as 50%. Replication, with a replication ratio of 3, loses again, storing 200% of redundant data.
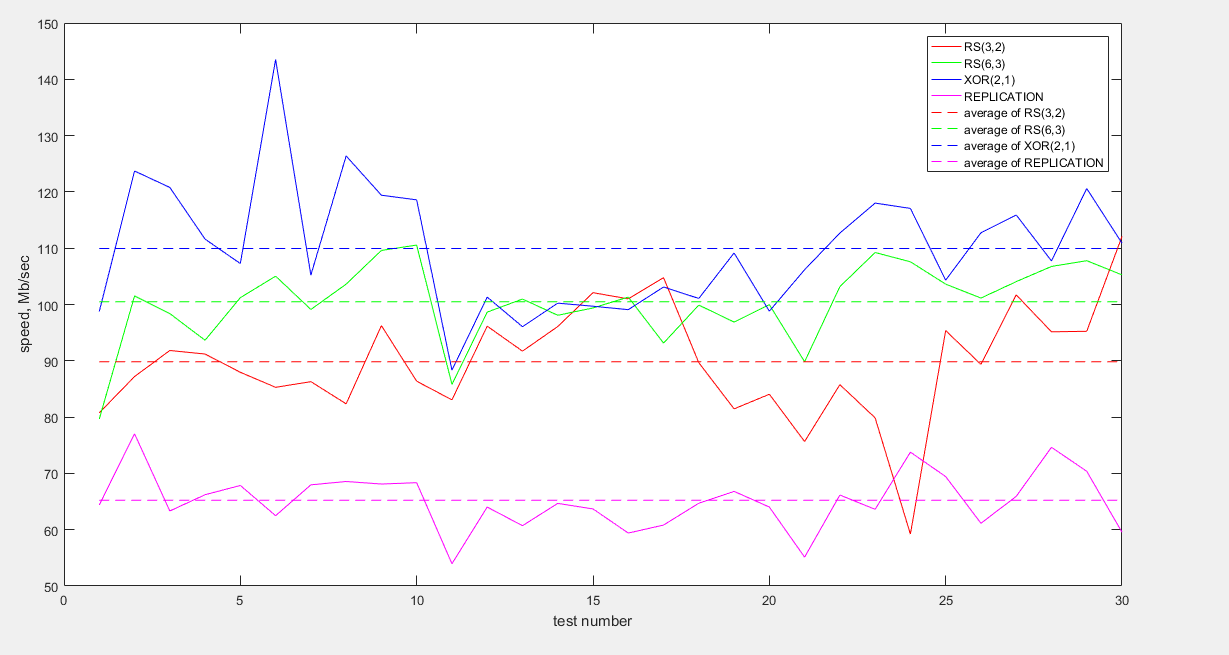
In the previous test, the status of the servers was monitored using the Grafana monitoring tool.
Below is a graph showing the CPU load during data transfer tests:
As can be seen from the graph, in this test the RS (6.3) encoding also consumes the least resources. Replication again shows the worst result.
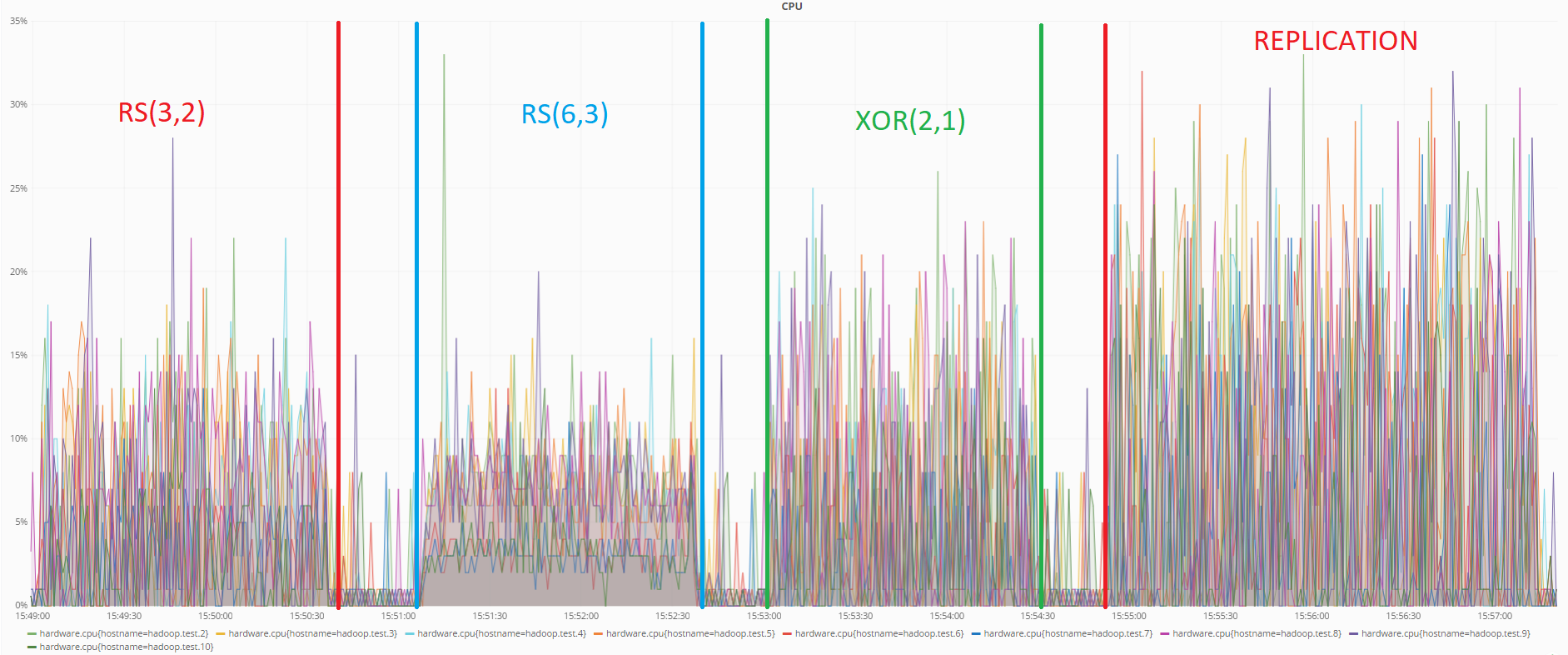
For this test, a certain amount of data was uploaded to the Hadoop distributed file system. Then two DataNode machines were dropped.
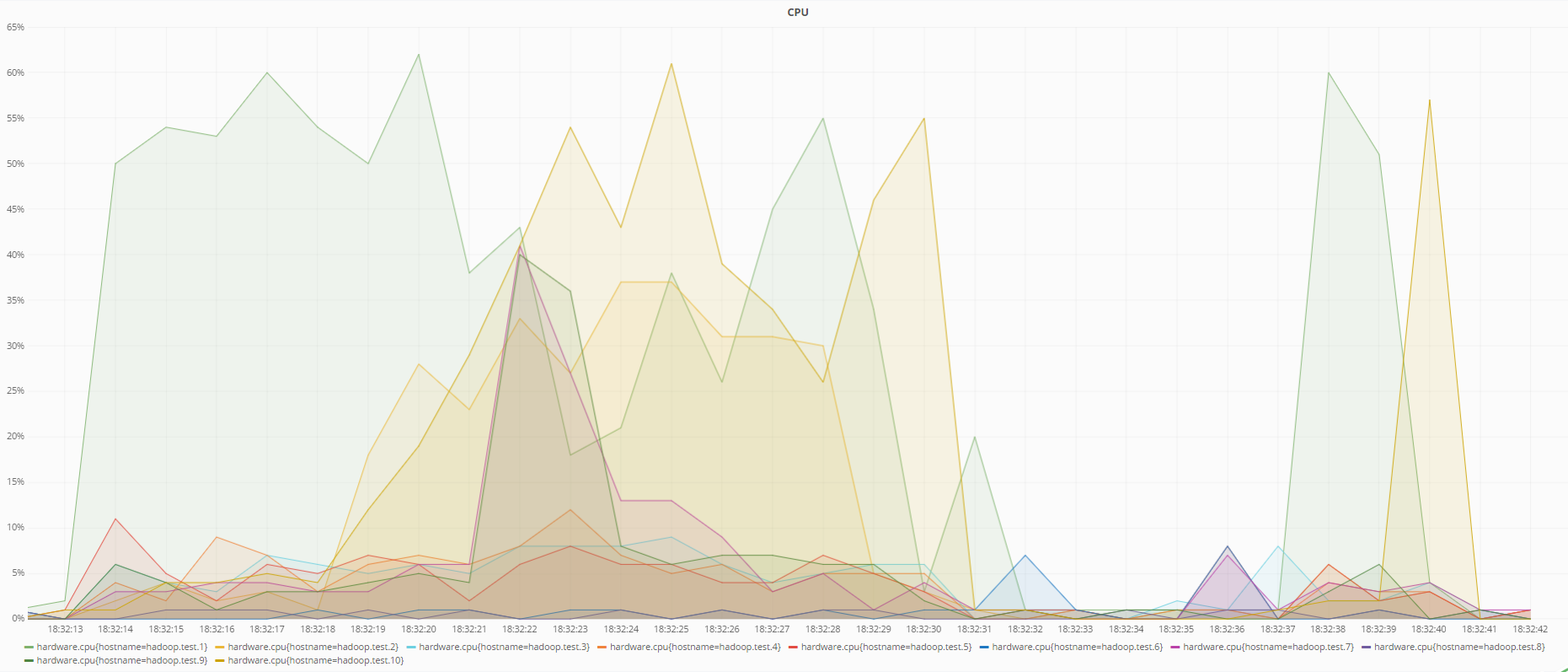
Below are graphs of the state of machines at the time of data recovery when RS (6.3) is encoded and when using replication:
Processor status when recovering data using RS (6.3) encoding

Processor status when recovering data using replication
As you can see from the graphs, RS (6.3) encoding loads the processor more than replication during data recovery, which is logical, because in order to recover lost data using redundant codes, it is necessary to calculate the inverse redundancy matrix, which consumes more resources than just overwriting data from other DataNode in case of replication.
The most reliable method of storage is RS (6.3) encoding, as it allows you to lose up to three machines without losing data, and replication with a replication rate of 3, supports failure of up to 2 machines. XOR (2, 1) is the most unreliable way to store data, as it allows you to lose a maximum of one machine.
The main purposes of using SberTech distributed file system are:
According to the results of the analysis, the following conclusions were made:
In this regard, it is concluded that HDFS 3 is a rational replacement for HDFS 2.
SberTech has allocated 10 virtual machines of 40 GB in size for this research. Since the RS (10,4) encoding policy requires a minimum of 14 machines, it will not be possible to test it.
On one of the machines will be located NameNode in addition to the DataNode. Testing will be conducted under the following encoding policies:
')
- XOR (2,1)
- RS (3.2)
- RS (6.3)
And also, using replication with a replication factor of 3.
The size of the data block was chosen to be 32 MB.
Conducting research
Data Rate Test
Were conducted tests on the speed of data transmission. The data was transferred from the local file system to the distributed file system. The size of the file used in this test is 292.2 MB.
The following results were obtained:
Also, a graph of grouped received values of file transfer time is plotted:
And also, a graph of the grouped received data transfer rate values:
As can be seen from the graph, the fastest data is transmitted with XOR (2.1) encoding. The RS (6.3) and RS (3.2) encodings show similar behavior, although the average speed of the RS (6.3) is slightly higher. Replication loses much speed (about 1.5 times less than XOR and 1.5 times less than RS).
With regard to storage efficiency, XOR (2.1) and RS (6.3) are the most profitable storage methods, with redundant data as low as 50%. Replication, with a replication ratio of 3, loses again, storing 200% of redundant data.
Performance test
In the previous test, the status of the servers was monitored using the Grafana monitoring tool.
Below is a graph showing the CPU load during data transfer tests:
As can be seen from the graph, in this test the RS (6.3) encoding also consumes the least resources. Replication again shows the worst result.
Resource consumption during data recovery
For this test, a certain amount of data was uploaded to the Hadoop distributed file system. Then two DataNode machines were dropped.
Below are graphs of the state of machines at the time of data recovery when RS (6.3) is encoded and when using replication:
Processor status when recovering data using RS (6.3) encoding
Processor status when recovering data using replication
As you can see from the graphs, RS (6.3) encoding loads the processor more than replication during data recovery, which is logical, because in order to recover lost data using redundant codes, it is necessary to calculate the inverse redundancy matrix, which consumes more resources than just overwriting data from other DataNode in case of replication.
Test results:
- In data transfer rates, XOR (2.1) or RS (6.3) encoding is best used.
- When transferring data, the processor loads the RS (6.3) and RS (3.2) encoding the least.
- When restoring data, the processor loses the use of replication
- The most compact way to store data is RS (6.3) and XOR (2.1) encodings.
The most reliable method of storage is RS (6.3) encoding, as it allows you to lose up to three machines without losing data, and replication with a replication rate of 3, supports failure of up to 2 machines. XOR (2, 1) is the most unreliable way to store data, as it allows you to lose a maximum of one machine.
Conclusion
The main purposes of using SberTech distributed file system are:
- Ensuring high reliability
- Minimizing server maintenance costs
- Providing tools for data analysis
According to the results of the analysis, the following conclusions were made:
- HDFS 3 wins in reliability over HDFS 2.
- HDFS 3 wins by minimizing server maintenance costs, as it stores data more compactly.
- HDFS 3 has the same set of data analysis tools as HDFS 2.
In this regard, it is concluded that HDFS 3 is a rational replacement for HDFS 2.
Sources used:
Source: https://habr.com/ru/post/418667/
All Articles