Akka Streams for mere mortals
How can a few lines of code print a continuous stream of messages from Twitter, adding to it weather data in the places of residence of their authors? And how to limit the speed of requests to the weather provider so that they do not put us on the black list?
We will tell you today how to do this, but first we will get acquainted with Akka Streams technology, which allows you to work with real-time data streams as easily as programmers work with LINQ expressions, without requiring manual implementation of either individual actors or Reactive Streams interfaces .
The article is based on the transcript of the report of Vagif Abilov from our December conference DotNext 2017 Moscow.
My name is Vagif, I work for the Norwegian company Miles. Today we talk about the library Akka Streams.
')
Akka and Reactive Streams is the intersection of rather narrow sets, and it may appear that this is such a niche to enter which you need to have some great knowledge, but just the opposite. And this article is intended to show that using Akka Streams, you can avoid the low level programming that is required when working with Reactive Streams and Akka.NET. Looking ahead, I can immediately say: if at the very beginning of our project, on which we use Akka, we knew about the existence of Akka Streams, we would have written a lot differently, saved both time and code.
Using this analogy, I would like to ask the following question: if Akka Streams is aspirin, then what should be the pain that will lead you to it?
First, let's talk about data streams. Flow can be quite simple, linear.
Here we have a certain data consumer (rabbit video). It consumes data at a rate that suits him. This is the ideal consumer interaction with the stream: it sets the bandwidth, and the data is quietly coming to it. This simple data stream can be endless, and it can end.
But the flow can be more complicated. If you plant several rabbits side by side, we will already have thread parallelization. What Reactive Streams is trying to solve is how you can communicate with flows on a more conceptual level, i.e., regardless of whether it is just a matter of measuring a temperature sensor where we take linear measurements , or we have continuous measurements of thousands of temperature sensors that enter the system through RabbitMQ queues and are stored in system logs. All of the above can be considered as one composite stream. If you go further, then automated production management (for example, some online store) can also be reduced to a data flow, and it would be great if you could talk about planning such a flow regardless of how complicated it is.

Modern projects are not very good at supporting threads. If I remember correctly, Aaron Stannard, whose tweet you see in the picture, wanted to get a stream of a multi-gigabyte file containing CSV, i.e. text, and it turned out that there is nothing that you can just take and immediately use, without a heap of additional actions. And he just could not get a stream of CSV-values, which saddened him. There are few solutions (with the exception of some special areas), a lot of things are implemented by the old methods, when we open all this, we start to read, buffer, in the worst case, we get something like notepad, which says that the file is too large.
At a high conceptual level, we are all involved in processing data streams, and Akka Streams will help you if:

The first path is from actors to Akka Streams, my path.
The picture shows why we began to use the model of actors. We were exhausted by the manual flow control, the shared state, that’s all. Anyone who has worked with large systems, multi-threaded, understands how much time it takes and how easy it is to make a mistake that can be fatal for the whole process. This led us to the actor model. We do not regret the choice made, but, of course, when you start working, you program more, it’s not that the initial enthusiasm gives way to something else, but you begin to realize that something could be done even more effectively.

If you do not use any additional things, such as dependency injection, the recipient's address is sewn into the actor.

When they begin to send messages to each other, you set all this in advance by programming the actors. And without additional tweaks, such a tough system is obtained.
One of the developers of Akka, Roland Kuhn, explained what is generally understood as a bad layout. The actor's message is based on the tell method, that is, unidirectional messages: it is of type void, that is, it returns nothing (or unit, depending on the language). Therefore, it is impossible to construct a description of the process from the chain of actors. Here you send a tell, then what? Stop. We have turned void. You can compare it, for example, with LINQ expressions, where each element of the expression returns IQueryable, IEnumerable, and all this can be easily put together. Actors do not give such an opportunity. At the same time, Roland Kuhn objected that they, they say, are not assembled in principle, saying that in fact they are arranged in other ways, in the same sense in which human society is amenable to composition. Sounds like a philosophical argument, but if you think about it, the analogy makes sense - yes, the actors send one-way messages to each other, but we also communicate with each other, saying one-way messages, but we interact quite effectively, that is, we create complex systems. Nevertheless, such criticism of actors exists.
In addition, the implementation of the actor requires at least the writing of a class if working on C #, or a function if working on F #. The example above is the boilerplate code, which you will have to write anyway. Although it is not very big, but it is a certain number of lines that you will always have to write at this low level. Almost all the code that is present here is a kind of ceremony. What happens when an actor directly receives a message is not shown here at all. And all this needs to be written. This, of course, is not very much, but it is evidence that we work with actors on a low level, creating such void-methods.
What if we could go to another, higher level, to ask questions about the modeling of our process, which involves processing data from different sources, which are mixed, transformed, and transmitted further?
An analogue of this approach may be something to which we have all got used to working with LINQ for ten years. We do not ask ourselves how join works. We know that there is such a LINQ provider that will do all this for us, and we are interested at a higher level in fulfilling the request. And we, in general, can mix databases here, we can send distribution requests. What if you could describe the process in this way?
(A source)
Or, for example, functional transformations. How many people like functional programming is the fact that you can skip data through a series of transformations, and you get quite a clear compact code, regardless of what language you write it. It's easy enough to read. The code in the picture is specifically written in F #, but in general, probably, everyone understands what is happening here.
(A source)
How then about this? In the example above, we have the Source data source, which consists of integers from 1 to 10. This is the so-called graphical DSL (domain-specific language). The elements of the domain language in the example above are the symbols of unidirectional arrows — these are additional operators defined by means of the language, graphically showing the direction of flow. We skip the Source through a series of transformations — for ease of demonstration, they all simply add a ten to the number. Next comes Broadcast: we multiply the channels, i.e., each number comes in two channels. Then again we add 10, we mix our data streams, we get a new stream, we also add 10 in it, and all this goes to our data sink, in which nothing happens. This is real code written in Scala, part of Akka Streams, implemented in this language. That is, you specify the transformation phases of your data, specify what to do with it, specify the source, drain, some checkpoints, and then create such a graph using graphical DSL. This is all the code of a single program A few lines of code show what is happening in your process.
Let's forget how to write the code for identifying individual actors and learn instead the high-level layout primitives that will create and connect the required actors. When we launch such a graph, the system that provides Akka Streams itself creates the required actor, sends all this data there, processes it as it should, and eventually returns it to the final recipient.
The example above shows how this might look like in C #. The easiest way: we have one data source - these are numbers from 1 to 1000 (as you can see, in Akka Streams, any IEnumerable can be a source of data flow, which is very convenient). We do some simple calculation, say, multiply by two, and then on the data sink all this is displayed on the screen.
What is shown in the example above is called “graphical DSL in C #”. In fact, there is no graphics here, this is a port with Scala, but in C # there is no possibility to define operators in this way, so it looks a bit more cumbersome, but still compact enough to understand what is happening here. So, we create a certain graph (there are different types of graph, here it is called FlowShape) from different components, where there is a data source and there are some transformations. We release data on one channel, in which we generate count, that is, the number of the data element to be transmitted, and in the other we generate the sum and then we mix it all up. Next we will see more interesting examples than just processing integers.
This is the first way that can lead you to Akka Streams, if you have experience with the model of actors, and you are thinking about whether you need to write by hand each, even the simplest actor. The second path that Akka Streams comes to is through Reactive Streams.
What is Reactive Streams ? This is a joint initiative to develop a standard for asynchronous data stream processing. It defines the minimum set of interfaces, methods and protocols that describe the necessary operations and entities to achieve the goal - asynchronous data processing in real time with non-blocking back pressure (back pressure). Allows various implementations using different programming languages.
Reactive Streams allows you to process a potentially unlimited number of elements in a sequence and asynchronously transfer elements between components with non-blocking back pressure.
The list of initiators of the creation of Reactive Streams is quite impressive: here is Netflix, and Oracle, and Twitter.
The specification is very simple to make implementation in different languages and platforms as accessible as possible. Main components of the Reactive Streams API:
It is significant that this specification does not imply that you will manually begin to implement these interfaces. The implication is that there are some library developers who will do this for you. And Akka Streams is one of the implementations of this specification.
Interfaces, as seen in the example, are really very simple: for example, Publisher contains only one method - “subscribe”. The subscriber, Subscriber, contains only a few reactions to the event.
Finally, a subscription contains two methods - this is “start” and “refuse”. The processor does not define any new methods at all, it combines a publisher and a subscriber.
What makes Reactive Streams stand out among other thread implementations? Reactive Streams combines push and pull models. For support, this is the most efficient scenario of speed. Suppose you have a slow data subscriber. In this case, push for him can be fatal: if you send him a huge amount of data, he will not be able to process them. It is better to use pull, so that the subscriber himself pulls the data from the publisher. But if the publisher is slow, it turns out that the subscriber is blocked all the time, waiting all the time. Configuration can be an interim solution: we have a config file in which we determine which of them is faster. And if their speeds change?
So, the most elegant implementation is one in which we can dynamically change push and pull models.
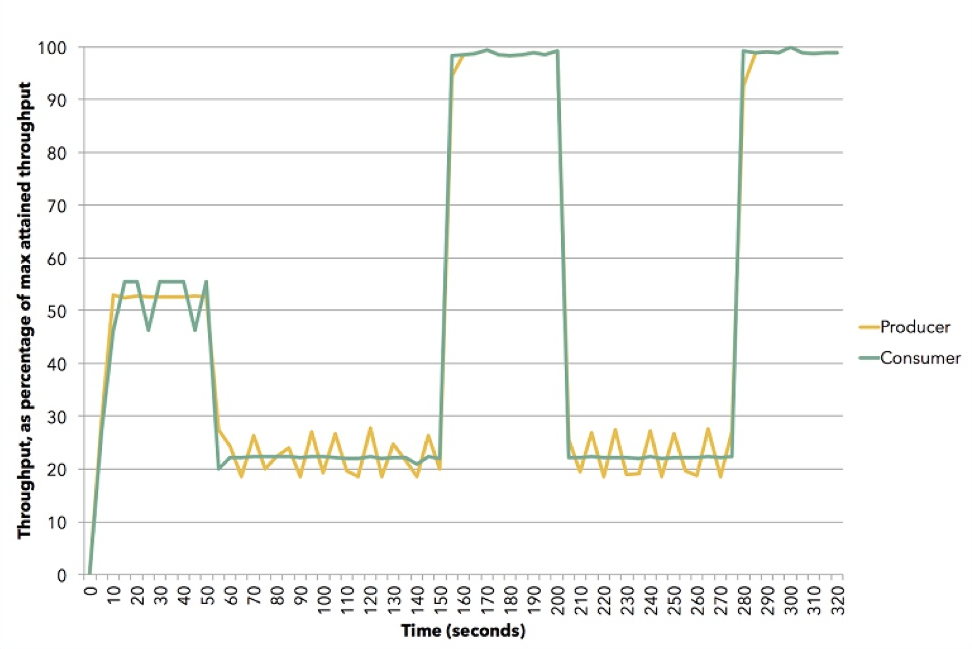
(Source (Apache Flink))
The diagram shows how this can occur. This demo uses Apache Flink. Yellow is a publisher, producer of data, it has been set at about 50% of its ability. The subscriber is trying to choose the best strategy - it turns out to be push. Then we reset the subscriber to a speed of about 20%, and he goes to pull. Then we go out 100%, again return to 20%, to the pull model, etc. All this happens in dynamics, no need to stop the service, enter something into the configuration. This is an illustration of how Akka Streams back pressure works.
Of course, Akka Streams would not be gaining popularity if there were no built-in blocks that are very easy to use. There are a lot of them. They are divided into three main groups:
From these three types it is possible to form graphs (Graph). These are already more complex processing stages, which are built from sources, sinks and checkpoints. But not every graph can be executed: if there are holes in it, i.e., open entrances and exits, then this graph is not allowed.
A graph is runnable (Runnable Graph), if it is closed, that is, there is an exit for each input: if the data is entered, they must go somewhere.

In Akka Streams there are built-in sources: in the picture you see how many of them are. About one-to-one names reflect the Scala or JVM, with the exception of some .NET-specific useful sources. The first two (FromEnumerator and From) are one of the most important: any numerator, any ienumerable can be turned into a stream source.

There are built-in sinks: some of them resemble LINQ methods, for example, First, Last, FirstOrDefault. Of course, you can drop everything that you get into files, into streams, not in Akka Streams, but in .NET streams. And again, if you have any actors in your system, you can use them both at the input and at the output of the system, i.e. if you wish, embed it in your ready-made system.

And there are a huge number of built-in checkpoints, which, perhaps, remind LINQ even more, because there are both Select, and SelectMany, and GroupBy, that is, everything that we are used to working with in LINQ.
For example, Scala's Select is called SelectAsync: it is powerful enough, because one of its arguments is the level of parallelism. That is, you can specify that, for example, Select sends data to a web service in parallel in ten streams, then they are all collected and passed on. In fact, you determine the degree of scaling of a checkpoint with a single line of code.
The declaration of the flow is its executive plan, that is, the graph, even when it is started, cannot be executed just like that - it needs to be materialized. There must be an instantiated system, actor system, you must give it a flow, this plan for execution, and then it will be executed. Moreover, at runtime, it is highly optimized, much like when you send a LINQ expression to the database: the provider can optimize your SQL for more efficient data output, in effect replacing the query command with another. The same with Akka Streams: starting from version 2.0, you can specify a certain number of checkpoints, and the system will understand that some of them can be combined to be performed by one actor (operator fusion). Checkpoints, as a rule, keep the order of processing elements.
Materialization of the stream can be compared with the last ToList element in the LINQ expression in the example above. If we do not write ToList, then we will get an immaterialized LINQ expression that will not cause the data to be transferred to SQL Server or Oracle, since most LINQ providers support the so-called deferred query execution, t . e. the request is executed only when a command is given to give some result. Depending on what is requested - the list or the first result - the most effective team will be formed. When we say ToList, we thereby request the LINQ provider to give us the finished result.
Akka Streams works in a similar way. In the picture, our startup graph consists of a source of checkpoints and a drain, and now we want to launch it.
In order for this to happen, we need to create a system of actors, in it is a materializer, give him our graph, and he will execute it. If we re-create it, it will execute it again, with other results.
In addition to the materialization of the flow, speaking of the material part of Akka Streams, it is worth mentioning the materialized values.
When we have a stream that goes from the source through checkpoints to the drain, then if we do not request any intermediate values, they are not available to us, since it will be executed in the most efficient way. It is like a black box. But it may be interesting to us to pull out some intermediate values, because at each point on the left some values come in, other values come out on the right, and you can, by setting the graph, indicate what you are interested in. In the example above, a triggered graph in which NotUsed is specified, that is, we are not interested in any materialized values. Below we create it with the indication that on the right side of the drain, that is, after performing all the transformations, we need to give the materialized values. We get the Task graph - a task that, when executed, we get an int, that is, what happens at the end of this graph. It is possible to indicate at each point that you need some materialized values, all this will gradually be collected.
To transfer data into Akka Streams streams or to pull them out from there, we need, of course, some kind of interaction with the outside world. Built-in source stages contain a wide range of reactive data streams:
As I said before, for .NET developers, using Enumerator or IEnumerable is very productive, but sometimes this is too primitive, too inefficient a way to access data. More complex and containing a large number of data sources require special connectors. Such connectors are written. There is an open source project Alpakka, which originally appeared in Scala and is now in .NET. In addition, Akka has so-called persistent actors, and they have their own streams that can be used (for example, the Akka Persistence Query forms the content stream of the Akka Event Journal).

If you work with Scala, then the easiest thing for you: there are a huge number of connectors, and you will surely find something to your taste. For information, Kafka is the so-called Reactive Kafka, not Kafka Streams. Kafka Streams, as far as I know, does not support back pressure. Reactive Kafka is a Kafka stream implementation that supports Reactive Streams.
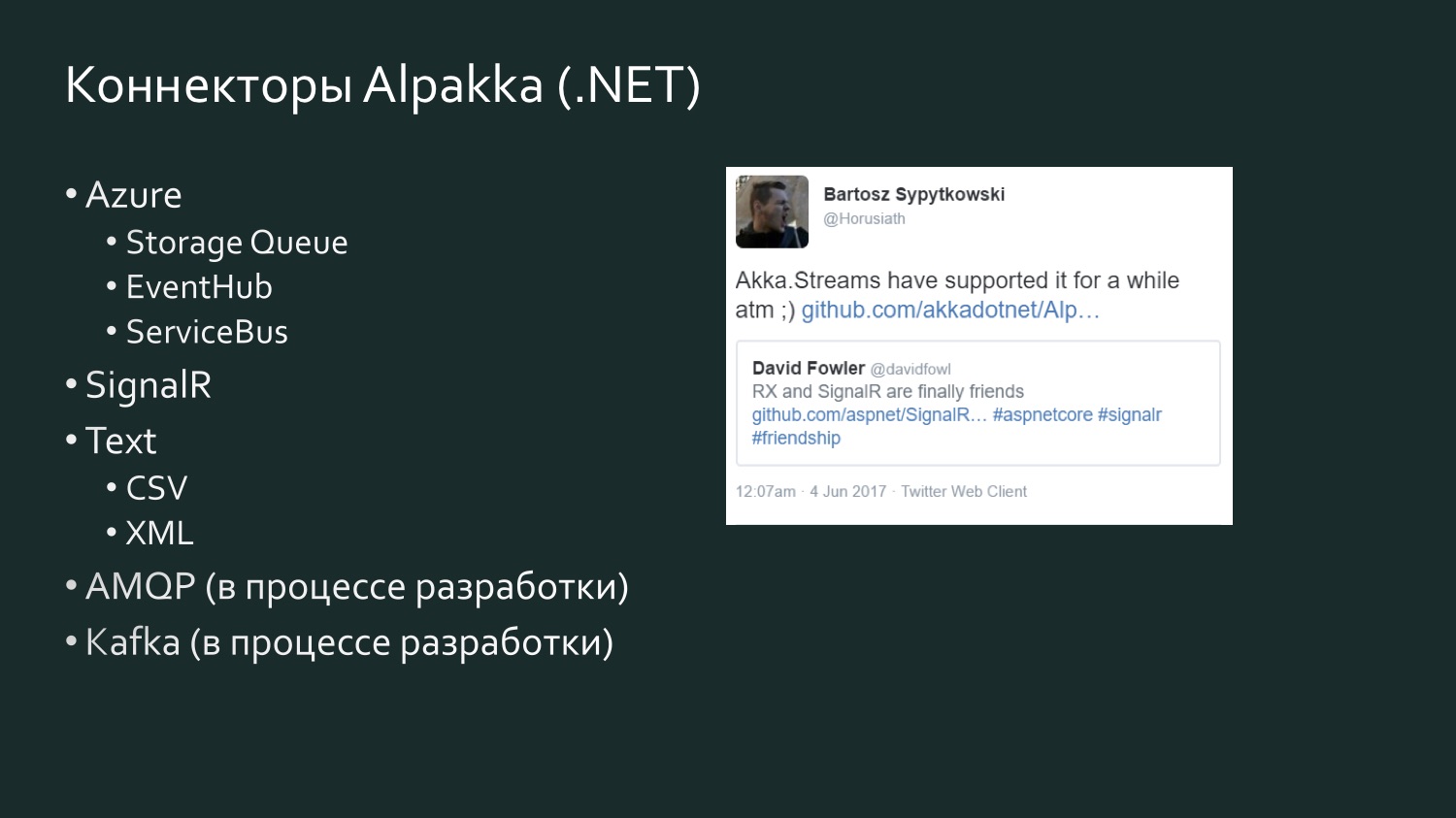
The list of Alpakka .NET connectors is more modest, but it is growing, and there is an element of competition. There is a tweet six months ago, David Fowler from Microsoft, who said that SignalR can now exchange data with Reactive Extensions, and one of the Akka developers said that in fact Akka Streams had been around for a while. Akka supports various services from Microsoft Azure. CSV is the result of Aaron Stannard’s frustration when he discovered that there is no good stream for CSV: now Akka has his own stream for CSV XML. There is AMQP (in reality RabbitMQ), it is in the development process, but is available for use, it works. Kafka is also under development. This list will continue to expand.
A few words about alternatives, because if you work with data streams, Akka Streams is, of course, not the only way to process these streams. Most likely, in your project, the choice of how to implement flows will depend on many other factors that may be key. For example, if you work a lot with Microsoft Azure and Orleans are organically built into the needs of your project with their support for virtual actors, or, as they call them, grains, then they have their own implementation that does not conform to the Reactive Streams - Orleans Streams specification, which for you will be the closest, and it makes sense for you to pay attention to it. If you work a lot with TPL, there is a TPL DataFlow - this is perhaps the closest analogy to Akka Streams: there are also primitives for linking data streams, as well as buffers and bandwidth limiting tools (BoundedCapacity, MaxMessagePerTask). If the ideas of the actor model are close to you, then Akka Streams is a way to address this and save a significant amount of time without having to write each actor manually.
Let's look at a couple of examples of implementation.The first example is not a direct flow implementation; this is how to use a flow. This was our first experience with Akka Streams, when we found that we could actually subscribe to some stream, which will simplify a lot for us.
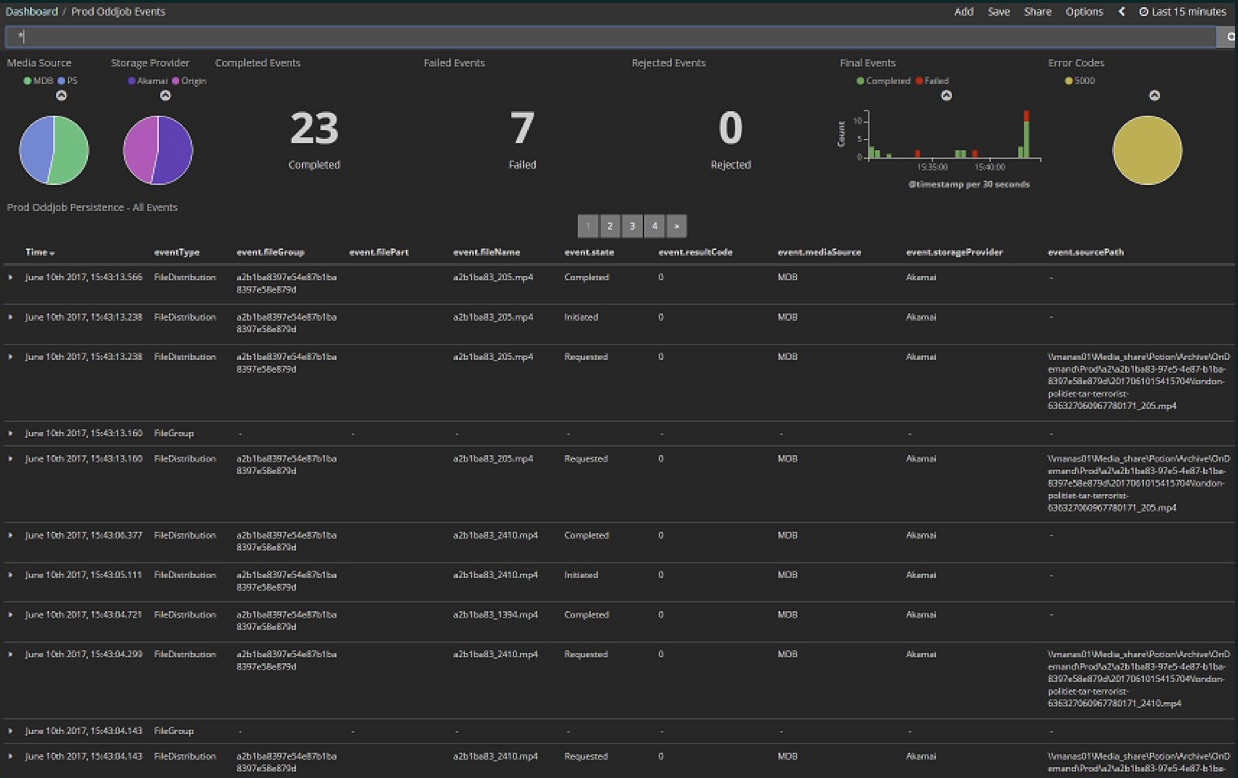
We upload different media files to the cloud. It was an early stage of the project: here in the last 15 minutes, 23 files, of which 7 errors. Now there are practically no errors and the number of files is much larger - hundreds pass through every few minutes. All this is contained in the Kibana Dashboard.
Kibana Elasticsearch , Elasticsearch , , , , . , , , . . . (event journal) Akka, Microsoft SQL Server. , .
To achieve this, we need, on the one hand, to rewrite the data taken from SQL Server, which contains a certain event store of persistent actors Akka, eventJournal. The picture shows a typical eventstore.
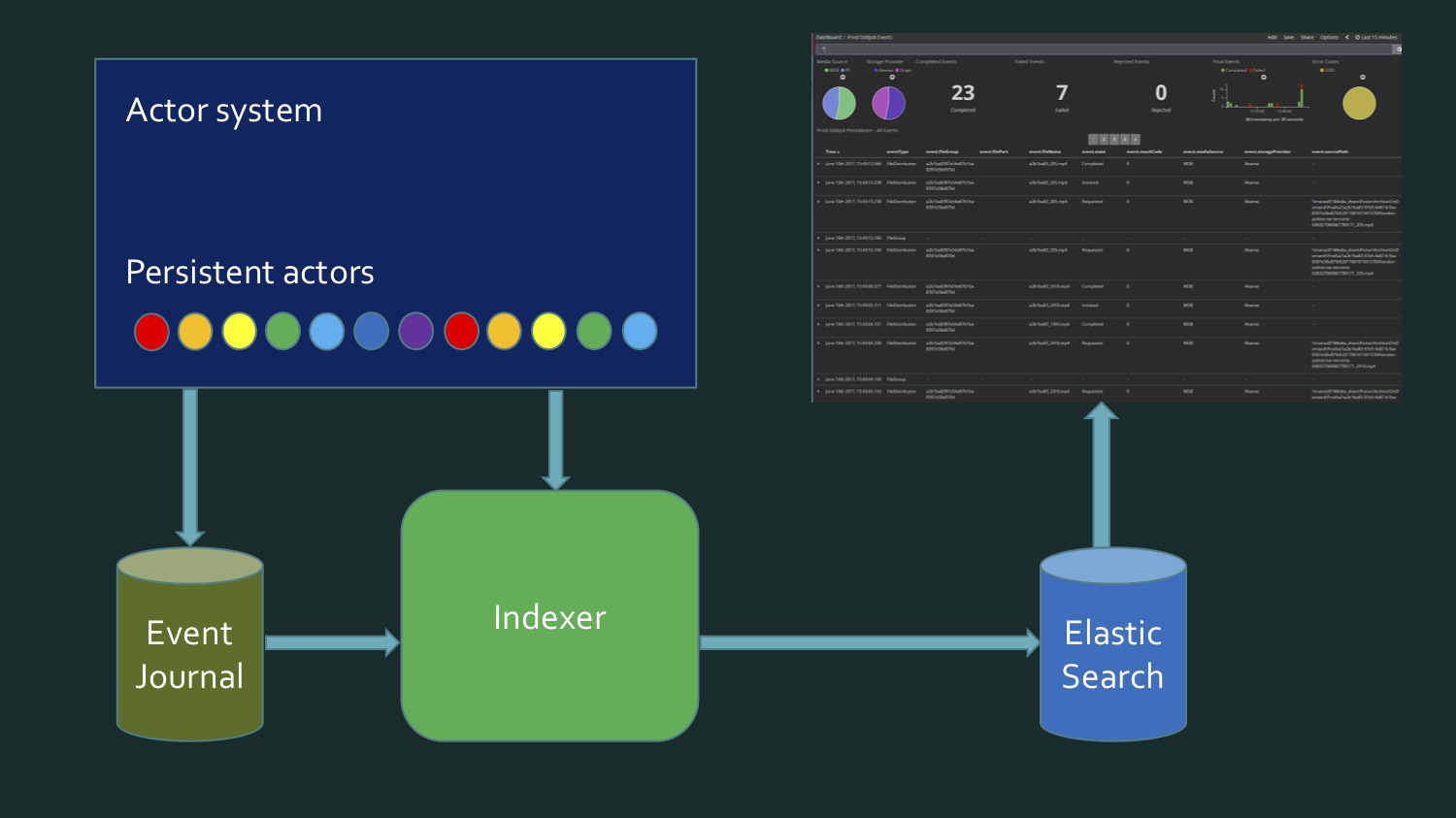
On the other hand, the data comes in real time. And it turns out that in order to write the index, we need to read data from the database, plus data comes in real time, and at some point we need to understand: here the data from here ran out, this is new. This borderline moment requires additional verification in order to not lose anything and not record anything twice. That is, it turned out somehow quite difficult. My colleague and I were not happy with what we have coming out. This is not something that is very complex code, just rather dreary. So far, we have not remembered that the persistent actors in Akka support the persistence query.
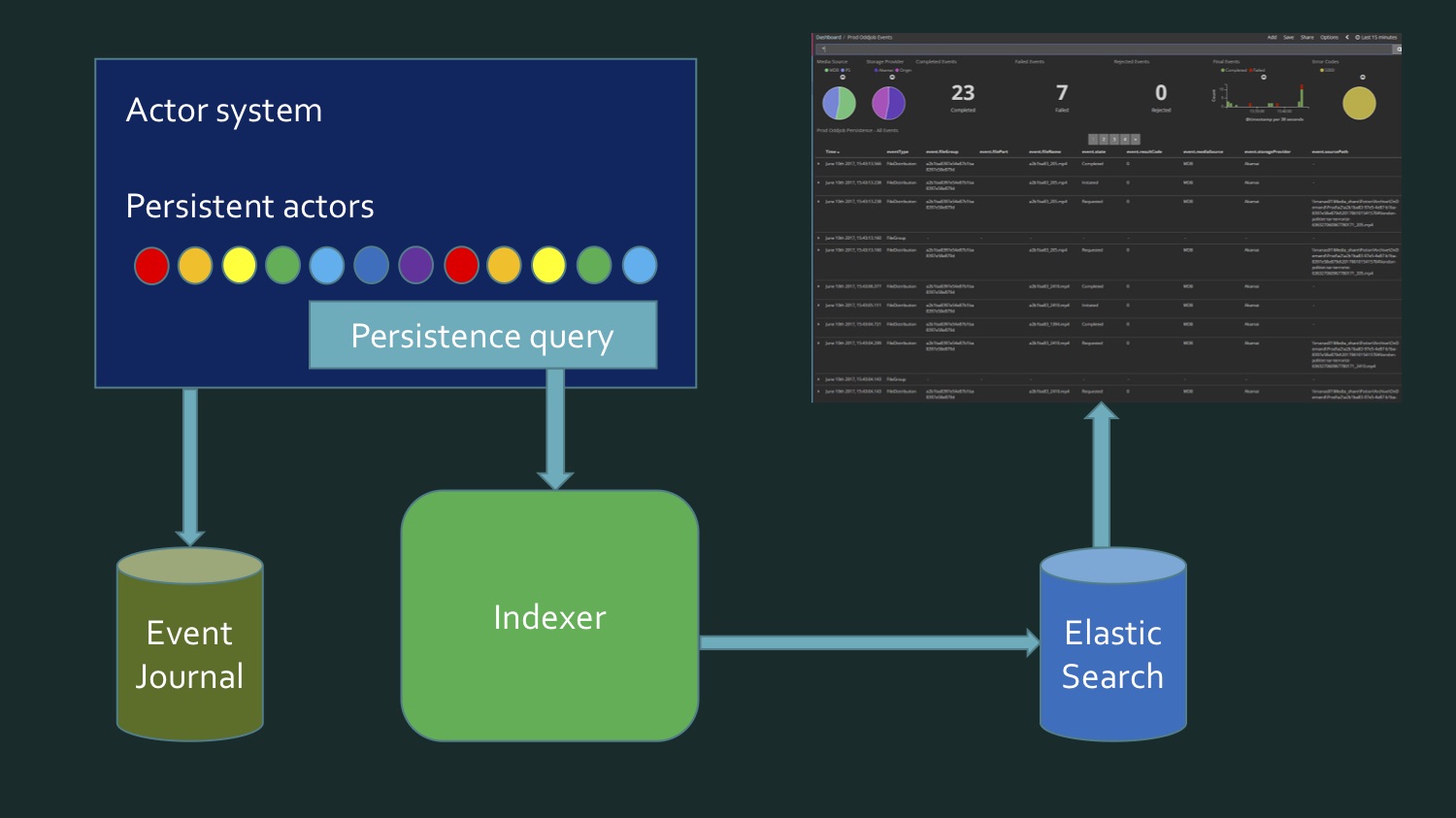
It is just the opportunity to get them in the form of a data stream abstracted from the source, they come from the database or are obtained in real time.
Inline queries (persistence queries):
And there are a number of methods that we can use, for example, there is a Current method - this is a snapshot, given historically up to a given point in time. And without this prefix - first and including real ones. We needed EventsByTag.
, . F#, C# . EventsByTag, Akka Streams, , Elasticsearch. . . - , , , — . .
. , , , , Twitter , — , , , . , Akka Streams.
Akka Scala, Akka.NET, , , , , . . - . Tweetinvi — , Twitter, . Reactive Streams, . . , , , , - Akka, , .

, , . . Broadcast-. , , . : , , , , .
GitHub-, AkkaStreamsDemo . ( ).
Let's start with the simple. Twitter: Program.cs
In case I get banned from Twitter, I have cached tweets, they are faster. For a start, we create a certain RunnableGraph.
( Source )
We have a tweet source here that comes from an actor. I’ll show you how we drag these tweets there, format them (the tweet format simply shows the author of the tweet) and then we write it on the screen.
StartTweetStream - here we will use the Tweetinvi library.
( )
CreateSampleStream , . , , , : « ». IEnumerable, .
TweetEnumerator : , Current, MoveNext, Reset, Dispose, . , . , . .
Now we change the value of useCachedTweets to true, and this is where the complications begin. CashedTweets is the same, only I have a file out of 50,000 tweets there that I have already selected, saved, we will use them. I tried to choose tweets in which there is data on the geographical coordinates of their authors, that we need. The next stage - we want to parallelize tweets. After doing this, we’ll have the owner of the tweet in the list first, and then the coordinates.
TweetsWithBroadcast:
( Source )
If it were Scala, it would really look like a graphical DSL. Here we create a Broadcast with two channels - out (0), out (1) - and in one case we print CreatedBy, in the other we print the coordinates, then we mix it all up and send it to the drain. Too simple for now.
The next stage of our demo is to make it a bit more complicated. Let's start changing bandwidth.
( Source )
10 , 10. , , , . , , Akka Streams Reactive Streams: . , , , , - . , , , . , . , , . Buffer(10, OverFlowStrategy.DropHead). , . 10 , . , , - , — - , , , , . . . , .
( Source )
Here we have the second channel, it has SelectAsync, in which we get the weather. We do not just send it to the weather service, we also say that this code is executed with a parallelization level of 5: this means that 5 parallel streams will be created if this service is slow enough that this service will request the weather. The service itself is implemented here, it also makes sense to show how simple this code looks.
( )
. -, , - , HttpClient , XML, , .
, , , . 10 10 , , .
, — , . , Akka Streams, , . , , .
, , , Akka Streams, . , , Akka Streams, C# , , , , .

What ideas about Akka Streams would I like you to take out for yourself after reading this article? On DotNext 2017 Moscow I was on the Alex Thyssen report Azure Functions. - , deployment, , ( - , , ), . , , , . , , Akka Streams, .. , . .
Akka Streams , , , , , . , , , , , . Akka Streams — , , .
, Akka Streams, «Akka Stream Rap». , .
We will tell you today how to do this, but first we will get acquainted with Akka Streams technology, which allows you to work with real-time data streams as easily as programmers work with LINQ expressions, without requiring manual implementation of either individual actors or Reactive Streams interfaces .
The article is based on the transcript of the report of Vagif Abilov from our December conference DotNext 2017 Moscow.
My name is Vagif, I work for the Norwegian company Miles. Today we talk about the library Akka Streams.
')
Akka and Reactive Streams is the intersection of rather narrow sets, and it may appear that this is such a niche to enter which you need to have some great knowledge, but just the opposite. And this article is intended to show that using Akka Streams, you can avoid the low level programming that is required when working with Reactive Streams and Akka.NET. Looking ahead, I can immediately say: if at the very beginning of our project, on which we use Akka, we knew about the existence of Akka Streams, we would have written a lot differently, saved both time and code.
“Almost the worst thing you can do is get people who are not in pain to take your aspirin”Before we get into the technical details, a little bit about what your path to Akka Streams may turn out to be, which might lead you there. Somehow, the blog of Max Kreminsky caught my eye, where he asked such a philosophical question for programmers: how or why it is impossible for a programmer to explain what monads are. He explained it this way: very often, people immediately move on to technical details, explaining how functional programming is generally beautiful and how much sense there is in a monad, without bothering to ask why the programmer needs it at all. Drawing an analogy, it's like trying to sell aspirin without bothering to find out if your patient is in pain.
Max Kreminsky
“Closed doors, headache and intellectual needs”
Using this analogy, I would like to ask the following question: if Akka Streams is aspirin, then what should be the pain that will lead you to it?
Data streams
First, let's talk about data streams. Flow can be quite simple, linear.
Here we have a certain data consumer (rabbit video). It consumes data at a rate that suits him. This is the ideal consumer interaction with the stream: it sets the bandwidth, and the data is quietly coming to it. This simple data stream can be endless, and it can end.
But the flow can be more complicated. If you plant several rabbits side by side, we will already have thread parallelization. What Reactive Streams is trying to solve is how you can communicate with flows on a more conceptual level, i.e., regardless of whether it is just a matter of measuring a temperature sensor where we take linear measurements , or we have continuous measurements of thousands of temperature sensors that enter the system through RabbitMQ queues and are stored in system logs. All of the above can be considered as one composite stream. If you go further, then automated production management (for example, some online store) can also be reduced to a data flow, and it would be great if you could talk about planning such a flow regardless of how complicated it is.
Modern projects are not very good at supporting threads. If I remember correctly, Aaron Stannard, whose tweet you see in the picture, wanted to get a stream of a multi-gigabyte file containing CSV, i.e. text, and it turned out that there is nothing that you can just take and immediately use, without a heap of additional actions. And he just could not get a stream of CSV-values, which saddened him. There are few solutions (with the exception of some special areas), a lot of things are implemented by the old methods, when we open all this, we start to read, buffer, in the worst case, we get something like notepad, which says that the file is too large.
At a high conceptual level, we are all involved in processing data streams, and Akka Streams will help you if:
- You are familiar with Akka, but you want to save yourself from the details related to the writing of the code of actors and their coordination;
- You are familiar with Reactive Streams and would like to take advantage of a ready-made implementation of their specification;
- Akka Streams block elements are suitable for modeling your process;
- You want to take advantage of Akka Streams back pressure (backpressure) to control and dynamically refine the throughput of your workflow stages.
From actors to Akka Streams
The first path is from actors to Akka Streams, my path.
The picture shows why we began to use the model of actors. We were exhausted by the manual flow control, the shared state, that’s all. Anyone who has worked with large systems, multi-threaded, understands how much time it takes and how easy it is to make a mistake that can be fatal for the whole process. This led us to the actor model. We do not regret the choice made, but, of course, when you start working, you program more, it’s not that the initial enthusiasm gives way to something else, but you begin to realize that something could be done even more effectively.
“By default, the recipients of their messages are written in the actor code. If I create actor A, which sends a message to actor B, and you want to replace the recipient with actor C, in general, this will not work for you ”Actors are criticized for not composing. One of the first people to write about this in his blog was Noel Welsh, one of the Underscore developers. He noted that the system of actors looks like this:
Noel Welch (underscore.io)
If you do not use any additional things, such as dependency injection, the recipient's address is sewn into the actor.
When they begin to send messages to each other, you set all this in advance by programming the actors. And without additional tweaks, such a tough system is obtained.
One of the developers of Akka, Roland Kuhn, explained what is generally understood as a bad layout. The actor's message is based on the tell method, that is, unidirectional messages: it is of type void, that is, it returns nothing (or unit, depending on the language). Therefore, it is impossible to construct a description of the process from the chain of actors. Here you send a tell, then what? Stop. We have turned void. You can compare it, for example, with LINQ expressions, where each element of the expression returns IQueryable, IEnumerable, and all this can be easily put together. Actors do not give such an opportunity. At the same time, Roland Kuhn objected that they, they say, are not assembled in principle, saying that in fact they are arranged in other ways, in the same sense in which human society is amenable to composition. Sounds like a philosophical argument, but if you think about it, the analogy makes sense - yes, the actors send one-way messages to each other, but we also communicate with each other, saying one-way messages, but we interact quite effectively, that is, we create complex systems. Nevertheless, such criticism of actors exists.
public class SampleActor : ReceiveActor { public SampleActor() { Idle(); } protected override void PreStart() { /* ... */ } private void Idle() { Receive<Job>(job => /* ... */); } private void Working() { Receive<Cancel>(job => /* ... */); } } In addition, the implementation of the actor requires at least the writing of a class if working on C #, or a function if working on F #. The example above is the boilerplate code, which you will have to write anyway. Although it is not very big, but it is a certain number of lines that you will always have to write at this low level. Almost all the code that is present here is a kind of ceremony. What happens when an actor directly receives a message is not shown here at all. And all this needs to be written. This, of course, is not very much, but it is evidence that we work with actors on a low level, creating such void-methods.
What if we could go to another, higher level, to ask questions about the modeling of our process, which involves processing data from different sources, which are mixed, transformed, and transmitted further?
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList(); An analogue of this approach may be something to which we have all got used to working with LINQ for ten years. We do not ask ourselves how join works. We know that there is such a LINQ provider that will do all this for us, and we are interested at a higher level in fulfilling the request. And we, in general, can mix databases here, we can send distribution requests. What if you could describe the process in this way?
HttpGet pageUrl |> fun s -> Regex.Replace(s, "[^A-Za-z']", " ") |> fun s -> Regex.Split(s, " +") |> Set.ofArray |> Set.filter (fun word -> not (Spellcheck word)) |> Set.iter (fun word -> printfn " %s" word) (A source)
Or, for example, functional transformations. How many people like functional programming is the fact that you can skip data through a series of transformations, and you get quite a clear compact code, regardless of what language you write it. It's easy enough to read. The code in the picture is specifically written in F #, but in general, probably, everyone understands what is happening here.
val in = Source(1 to 10) val out = Sink.ignore val bcast = builder.add(Broadcast[Int](2)) val merge = builder.add(Merge[Int](2)) val f1,f2,f3,f4 = Flow[Int].map(_ + 10) source ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink bcast ~> f4 ~> merge ~> (A source)
How then about this? In the example above, we have the Source data source, which consists of integers from 1 to 10. This is the so-called graphical DSL (domain-specific language). The elements of the domain language in the example above are the symbols of unidirectional arrows — these are additional operators defined by means of the language, graphically showing the direction of flow. We skip the Source through a series of transformations — for ease of demonstration, they all simply add a ten to the number. Next comes Broadcast: we multiply the channels, i.e., each number comes in two channels. Then again we add 10, we mix our data streams, we get a new stream, we also add 10 in it, and all this goes to our data sink, in which nothing happens. This is real code written in Scala, part of Akka Streams, implemented in this language. That is, you specify the transformation phases of your data, specify what to do with it, specify the source, drain, some checkpoints, and then create such a graph using graphical DSL. This is all the code of a single program A few lines of code show what is happening in your process.
Let's forget how to write the code for identifying individual actors and learn instead the high-level layout primitives that will create and connect the required actors. When we launch such a graph, the system that provides Akka Streams itself creates the required actor, sends all this data there, processes it as it should, and eventually returns it to the final recipient.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); The example above shows how this might look like in C #. The easiest way: we have one data source - these are numbers from 1 to 1000 (as you can see, in Akka Streams, any IEnumerable can be a source of data flow, which is very convenient). We do some simple calculation, say, multiply by two, and then on the data sink all this is displayed on the screen.
var graph = GraphDsl.Create(builder => { var bcast = builder.Add(new Broadcast<int>(2)); var merge = builder.Add(new Merge<int, int>(2)); var count = Flow.FromFunction(new Func<int, int>(x => 1)); var sum = Flow.Create<int>().Sum((x, y) => x + y); builder.From(bcast.Out(0)).To(merge.In(0)); builder.From(bcast.Out(1)).Via(count).Via(sum).To(merge.In(1)); return new FlowShape<int, int>(bcast.In, merge.Out); }); What is shown in the example above is called “graphical DSL in C #”. In fact, there is no graphics here, this is a port with Scala, but in C # there is no possibility to define operators in this way, so it looks a bit more cumbersome, but still compact enough to understand what is happening here. So, we create a certain graph (there are different types of graph, here it is called FlowShape) from different components, where there is a data source and there are some transformations. We release data on one channel, in which we generate count, that is, the number of the data element to be transmitted, and in the other we generate the sum and then we mix it all up. Next we will see more interesting examples than just processing integers.
This is the first way that can lead you to Akka Streams, if you have experience with the model of actors, and you are thinking about whether you need to write by hand each, even the simplest actor. The second path that Akka Streams comes to is through Reactive Streams.
From Reactive Streams to Akka Streams
What is Reactive Streams ? This is a joint initiative to develop a standard for asynchronous data stream processing. It defines the minimum set of interfaces, methods and protocols that describe the necessary operations and entities to achieve the goal - asynchronous data processing in real time with non-blocking back pressure (back pressure). Allows various implementations using different programming languages.
Reactive Streams allows you to process a potentially unlimited number of elements in a sequence and asynchronously transfer elements between components with non-blocking back pressure.
The list of initiators of the creation of Reactive Streams is quite impressive: here is Netflix, and Oracle, and Twitter.
The specification is very simple to make implementation in different languages and platforms as accessible as possible. Main components of the Reactive Streams API:
- Publisher
- Subscriber
- Subscription
- Processor
It is significant that this specification does not imply that you will manually begin to implement these interfaces. The implication is that there are some library developers who will do this for you. And Akka Streams is one of the implementations of this specification.
public interface IPublisher<out T> { void Subscribe(ISubscriber<T> subscriber); } public interface ISubscriber<in T> { void OnSubscribe(ISubscription subscription); void OnNext(T element); void OnError(Exception cause); void OnComplete(); } Interfaces, as seen in the example, are really very simple: for example, Publisher contains only one method - “subscribe”. The subscriber, Subscriber, contains only a few reactions to the event.
public interface ISubscription { void Request(long n); void Cancel(); } public interface IProcessor<in T1, out T2> : ISubscriber<T1>, IPublisher<T2> { } Finally, a subscription contains two methods - this is “start” and “refuse”. The processor does not define any new methods at all, it combines a publisher and a subscriber.
What makes Reactive Streams stand out among other thread implementations? Reactive Streams combines push and pull models. For support, this is the most efficient scenario of speed. Suppose you have a slow data subscriber. In this case, push for him can be fatal: if you send him a huge amount of data, he will not be able to process them. It is better to use pull, so that the subscriber himself pulls the data from the publisher. But if the publisher is slow, it turns out that the subscriber is blocked all the time, waiting all the time. Configuration can be an interim solution: we have a config file in which we determine which of them is faster. And if their speeds change?
So, the most elegant implementation is one in which we can dynamically change push and pull models.
(Source (Apache Flink))
The diagram shows how this can occur. This demo uses Apache Flink. Yellow is a publisher, producer of data, it has been set at about 50% of its ability. The subscriber is trying to choose the best strategy - it turns out to be push. Then we reset the subscriber to a speed of about 20%, and he goes to pull. Then we go out 100%, again return to 20%, to the pull model, etc. All this happens in dynamics, no need to stop the service, enter something into the configuration. This is an illustration of how Akka Streams back pressure works.
Akka Streams working principles
Of course, Akka Streams would not be gaining popularity if there were no built-in blocks that are very easy to use. There are a lot of them. They are divided into three main groups:
- Data source (Source) - processing stage with one output.
- Stoke (Sink) - a stage of processing with one entrance.
- Checkpoint (Flow) - processing stage with one input and one output. Here functional transformations take place, and not necessarily in memory: it can be, for example, accessing a web service, to some elements of parallelism, multi-threaded.
From these three types it is possible to form graphs (Graph). These are already more complex processing stages, which are built from sources, sinks and checkpoints. But not every graph can be executed: if there are holes in it, i.e., open entrances and exits, then this graph is not allowed.
A graph is runnable (Runnable Graph), if it is closed, that is, there is an exit for each input: if the data is entered, they must go somewhere.
In Akka Streams there are built-in sources: in the picture you see how many of them are. About one-to-one names reflect the Scala or JVM, with the exception of some .NET-specific useful sources. The first two (FromEnumerator and From) are one of the most important: any numerator, any ienumerable can be turned into a stream source.
There are built-in sinks: some of them resemble LINQ methods, for example, First, Last, FirstOrDefault. Of course, you can drop everything that you get into files, into streams, not in Akka Streams, but in .NET streams. And again, if you have any actors in your system, you can use them both at the input and at the output of the system, i.e. if you wish, embed it in your ready-made system.
And there are a huge number of built-in checkpoints, which, perhaps, remind LINQ even more, because there are both Select, and SelectMany, and GroupBy, that is, everything that we are used to working with in LINQ.
For example, Scala's Select is called SelectAsync: it is powerful enough, because one of its arguments is the level of parallelism. That is, you can specify that, for example, Select sends data to a web service in parallel in ten streams, then they are all collected and passed on. In fact, you determine the degree of scaling of a checkpoint with a single line of code.
The declaration of the flow is its executive plan, that is, the graph, even when it is started, cannot be executed just like that - it needs to be materialized. There must be an instantiated system, actor system, you must give it a flow, this plan for execution, and then it will be executed. Moreover, at runtime, it is highly optimized, much like when you send a LINQ expression to the database: the provider can optimize your SQL for more efficient data output, in effect replacing the query command with another. The same with Akka Streams: starting from version 2.0, you can specify a certain number of checkpoints, and the system will understand that some of them can be combined to be performed by one actor (operator fusion). Checkpoints, as a rule, keep the order of processing elements.
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList(); Materialization of the stream can be compared with the last ToList element in the LINQ expression in the example above. If we do not write ToList, then we will get an immaterialized LINQ expression that will not cause the data to be transferred to SQL Server or Oracle, since most LINQ providers support the so-called deferred query execution, t . e. the request is executed only when a command is given to give some result. Depending on what is requested - the list or the first result - the most effective team will be formed. When we say ToList, we thereby request the LINQ provider to give us the finished result.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); Akka Streams works in a similar way. In the picture, our startup graph consists of a source of checkpoints and a drain, and now we want to launch it.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); var system = ActorSystem.Create("MyActorSystem"); using (var materializer = ActorMaterializer.Create(system)) { await runnable.Run(materializer); } In order for this to happen, we need to create a system of actors, in it is a materializer, give him our graph, and he will execute it. If we re-create it, it will execute it again, with other results.
In addition to the materialization of the flow, speaking of the material part of Akka Streams, it is worth mentioning the materialized values.
var output = new List<int>(); var source1 = Source.From(Enumerable.Range(1, 1000)); var sink1 = Sink.ForEach<int>(output.Add); IRunnableGraph<NotUsed> runnable1 = source1.To(sink1); var source2 = Source.From(Enumerable.Range(1, 1000)); var sink2 = Sink.Sum<int>((x,y) => x + y); IRunnableGraph<Task<int>> runnable2 = source2.ToMaterialized(sink2, Keep.Right); When we have a stream that goes from the source through checkpoints to the drain, then if we do not request any intermediate values, they are not available to us, since it will be executed in the most efficient way. It is like a black box. But it may be interesting to us to pull out some intermediate values, because at each point on the left some values come in, other values come out on the right, and you can, by setting the graph, indicate what you are interested in. In the example above, a triggered graph in which NotUsed is specified, that is, we are not interested in any materialized values. Below we create it with the indication that on the right side of the drain, that is, after performing all the transformations, we need to give the materialized values. We get the Task graph - a task that, when executed, we get an int, that is, what happens at the end of this graph. It is possible to indicate at each point that you need some materialized values, all this will gradually be collected.
To transfer data into Akka Streams streams or to pull them out from there, we need, of course, some kind of interaction with the outside world. Built-in source stages contain a wide range of reactive data streams:
- Source.FromEnumerator and Source.From allow you to transfer data from any source that implements the IEnumerable;
- Unfold and UnfoldAsync form the results of the function calculations provided that it returns nonzero values;
- FromInputStream converts Stream;
- FromFile converts the contents of the file to the jet stream;
- ActorPublisher converts actor messages.
As I said before, for .NET developers, using Enumerator or IEnumerable is very productive, but sometimes this is too primitive, too inefficient a way to access data. More complex and containing a large number of data sources require special connectors. Such connectors are written. There is an open source project Alpakka, which originally appeared in Scala and is now in .NET. In addition, Akka has so-called persistent actors, and they have their own streams that can be used (for example, the Akka Persistence Query forms the content stream of the Akka Event Journal).
If you work with Scala, then the easiest thing for you: there are a huge number of connectors, and you will surely find something to your taste. For information, Kafka is the so-called Reactive Kafka, not Kafka Streams. Kafka Streams, as far as I know, does not support back pressure. Reactive Kafka is a Kafka stream implementation that supports Reactive Streams.
The list of Alpakka .NET connectors is more modest, but it is growing, and there is an element of competition. There is a tweet six months ago, David Fowler from Microsoft, who said that SignalR can now exchange data with Reactive Extensions, and one of the Akka developers said that in fact Akka Streams had been around for a while. Akka supports various services from Microsoft Azure. CSV is the result of Aaron Stannard’s frustration when he discovered that there is no good stream for CSV: now Akka has his own stream for CSV XML. There is AMQP (in reality RabbitMQ), it is in the development process, but is available for use, it works. Kafka is also under development. This list will continue to expand.
A few words about alternatives, because if you work with data streams, Akka Streams is, of course, not the only way to process these streams. Most likely, in your project, the choice of how to implement flows will depend on many other factors that may be key. For example, if you work a lot with Microsoft Azure and Orleans are organically built into the needs of your project with their support for virtual actors, or, as they call them, grains, then they have their own implementation that does not conform to the Reactive Streams - Orleans Streams specification, which for you will be the closest, and it makes sense for you to pay attention to it. If you work a lot with TPL, there is a TPL DataFlow - this is perhaps the closest analogy to Akka Streams: there are also primitives for linking data streams, as well as buffers and bandwidth limiting tools (BoundedCapacity, MaxMessagePerTask). If the ideas of the actor model are close to you, then Akka Streams is a way to address this and save a significant amount of time without having to write each actor manually.
Example implementation: event log stream
Let's look at a couple of examples of implementation.The first example is not a direct flow implementation; this is how to use a flow. This was our first experience with Akka Streams, when we found that we could actually subscribe to some stream, which will simplify a lot for us.
We upload different media files to the cloud. It was an early stage of the project: here in the last 15 minutes, 23 files, of which 7 errors. Now there are practically no errors and the number of files is much larger - hundreds pass through every few minutes. All this is contained in the Kibana Dashboard.
Kibana Elasticsearch , Elasticsearch , , , , . , , , . . . (event journal) Akka, Microsoft SQL Server. , .
CREATE TABLE EventJournal ( Ordering BIGINT IDENTITY(1,1) PRIMARY KEY NOT NULL, PersistenceID NVARCHAR(255) NOT NULL, SequenceNr BIGINT NOT NULL, Timestamp BIGINT NOT NULL, IsDeleted BIT NOT NULL, Manifest NVARCHAR(500) NOT NULL, Payload VARBINARY(MAX) NOT NULL, Tags NVARCHAR(100) NULL CONSTRAINT QU_EventJournal UNIQUE (PersistenceID, SequenceNr) ) To achieve this, we need, on the one hand, to rewrite the data taken from SQL Server, which contains a certain event store of persistent actors Akka, eventJournal. The picture shows a typical eventstore.
On the other hand, the data comes in real time. And it turns out that in order to write the index, we need to read data from the database, plus data comes in real time, and at some point we need to understand: here the data from here ran out, this is new. This borderline moment requires additional verification in order to not lose anything and not record anything twice. That is, it turned out somehow quite difficult. My colleague and I were not happy with what we have coming out. This is not something that is very complex code, just rather dreary. So far, we have not remembered that the persistent actors in Akka support the persistence query.
It is just the opportunity to get them in the form of a data stream abstracted from the source, they come from the database or are obtained in real time.
Inline queries (persistence queries):
- AllPersistencelds
- CurrentPersistencelds
- EventsByPersistenceld
- CurrentEventsByPers existenceld
- EventsByTag
- CurrentEventsByTag
And there are a number of methods that we can use, for example, there is a Current method - this is a snapshot, given historically up to a given point in time. And without this prefix - first and including real ones. We needed EventsByTag.
let system = mailbox.Context.System let queries = PersistenceQuery.Get(system) .ReadJournalFor<SqlReadJournal>(SqlReadJournal.Identifier) let mat = ActorMaterializer.Create(system) let offset = getCurrentOffset client config let ks = KillSwitches.Shared "persistence-elastic" let task = queries.EventsByTag(PersistenceUtils.anyEventTag, offset) .Select(fun e -> ElasticTypes.EventEnvelope.FromAkka e) .GroupedWithin(config.BatchSize, config.BatchTimeout) .Via(ks.Flow()) .RunForeach((fun batch -> processItems client batch), mat) .ContinueWith(handleStreamError mailbox, TaskContinuationOptions.OnlyOnFaulted) |> Async.AwaitTaskVoid , . F#, C# . EventsByTag, Akka Streams, , Elasticsearch. . . - , , , — . .
. , , , , Twitter , — , , , . , Akka Streams.
:
Akka Scala, Akka.NET, , , , , . . - . Tweetinvi — , Twitter, . Reactive Streams, . . , , , , - Akka, , .
, , . . Broadcast-. , , . : , , , , .
GitHub-, AkkaStreamsDemo . ( ).
Let's start with the simple. Twitter: Program.cs
var useCachedTweets = false In case I get banned from Twitter, I have cached tweets, they are faster. For a start, we create a certain RunnableGraph.
public static IRunnableGraph<IActorRef> CreateRunnableGraph() { var tweetSource = Source.ActorRef<ITweet>(100, OverflowStrategy.DropHead); var formatFlow = Flow.Create<ITweet>().Select(Utils.FormatTweet); var writeSink = Sink.ForEach<string>(Console.WriteLine); return tweetSource.Via(formatFlow).To(writeSink); } ( Source )
We have a tweet source here that comes from an actor. I’ll show you how we drag these tweets there, format them (the tweet format simply shows the author of the tweet) and then we write it on the screen.
StartTweetStream - here we will use the Tweetinvi library.
public static void StartTweetStream(IActorRef actor) { var stream = Stream.CreateSampleStream(); stream.TweetReceived += (_, arg) => { arg.Tweet.Text = arg.Tweet.Text.Replace("\r", " ").Replace("\n", " "); var json = JsonConvert.SerializeObject(arg.Tweet); File.AppendAllText("tweets.txt", $"{json}\r\n"); actor.Tell(arg.Tweet); }; stream.StartStream(); } ( )
CreateSampleStream , . , , , : « ». IEnumerable, .
TweetEnumerator : , Current, MoveNext, Reset, Dispose, . , . , . .
Now we change the value of useCachedTweets to true, and this is where the complications begin. CashedTweets is the same, only I have a file out of 50,000 tweets there that I have already selected, saved, we will use them. I tried to choose tweets in which there is data on the geographical coordinates of their authors, that we need. The next stage - we want to parallelize tweets. After doing this, we’ll have the owner of the tweet in the list first, and then the coordinates.
TweetsWithBroadcast:
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); }); ( Source )
If it were Scala, it would really look like a graphical DSL. Here we create a Broadcast with two channels - out (0), out (1) - and in one case we print CreatedBy, in the other we print the coordinates, then we mix it all up and send it to the drain. Too simple for now.
The next stage of our demo is to make it a bit more complicated. Let's start changing bandwidth.
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });} ( Source )
10 , 10. , , , . , , Akka Streams Reactive Streams: . , , , , - . , , , . , . , , . Buffer(10, OverFlowStrategy.DropHead). , . 10 , . , , - , — - , , , , . . . , .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(Flow.Create<ICoordinates>().SelectAsync(5, Utils.GetWeatherAsync)) .Via(formatTemperature) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); }); ( Source )
Here we have the second channel, it has SelectAsync, in which we get the weather. We do not just send it to the weather service, we also say that this code is executed with a parallelization level of 5: this means that 5 parallel streams will be created if this service is slow enough that this service will request the weather. The service itself is implemented here, it also makes sense to show how simple this code looks.
public static async Task<decimal> GetWeatherAsync(ICoordinates coordinates) { var httpClient = new HttpClient(); var requestUrl = $"http://api.met.no/weatherapi/locationforecast/1.9/?lat={coordinates.Latitude};lon={coordinates.Latitude}"; var result = await httpClient.GetStringAsync(requestUrl); var doc = XDocument.Parse(result); var temp = doc.Root.Descendants("temperature").First().Attribute("value").Value; return decimal.Parse(temp); } ( )
. -, , - , HttpClient , XML, , .
, , , . 10 10 , , .
, — , . , Akka Streams, , . , , .
, , , Akka Streams, . , , Akka Streams, C# , , , , .
What ideas about Akka Streams would I like you to take out for yourself after reading this article? On DotNext 2017 Moscow I was on the Alex Thyssen report Azure Functions. - , deployment, , ( - , , ), . , , , . , , Akka Streams, .. , . .
Akka Streams , , , , , . , , , , , . Akka Streams — , , .
, Akka Streams, «Akka Stream Rap». , .
This is the Akka Stream.. — 22-23 DotNext 2018 Moscow , . ( ).
This is the Source that feeds the Akka Stream.
This is the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Streams.
This is the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the source that feeds the Akka Streams.
This is the Sink that is filled from the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
Source: https://habr.com/ru/post/418639/
All Articles