On the way to 100% of code coverage by tests in Go using the example of sql-dumper
In this post I will talk about how I wrote the console program in the Go language for uploading data from the database to files, trying to cover all code with 100% tests. I'll start with a description of why I needed this program. I will continue the description of the first difficulties, some of which are caused by the peculiarities of the Go language. Then I’ll mention the build on Travis CI a bit, and then I’ll tell you how I wrote the tests, trying to cover the code 100%. I will touch upon the testing of work with the database and file system. And in conclusion, I’ll tell you what the desire to cover the code with tests as much as possible and what this indicator shows. I will accompany the material with references both to the documentation and to the examples of commits from my project.
Purpose of the program
The program should be launched from the command line with a list of tables and some of their columns, a range of data on the first specified column, listing the connections of the selected tables to each other, with the ability to specify a file with database connection settings. The result of the work should be a file that describes the requests to create the specified tables with the specified columns and the insert expressions of the selected data. It was assumed that the use of such a program would simplify the scenario of extracting a portion of data from a large database and deploying this portion locally. In addition, these sql files of unloading were supposed to be processed by another program, which replaces part of the data according to a specific pattern.
The same result can be achieved using any of the popular clients to the database and a sufficiently large amount of manual work. The application had to simplify this process and automate as much as possible.
This program should have been developed by my interns for the purpose of training and subsequent use in their further education. But the situation was such that they abandoned this idea. But I decided to try to write such a program in my spare time in order to practice my development in the Go language.
The solution is incomplete, has several limitations, which are described in the README. In any case, this is not a combat project.
Examples of use and source code .
First difficulties
The list of tables and their columns is passed to the program by an argument in the form of a string, that is, it is unknown in advance. Most of the examples on working with the database on Go implied that the database structure is known in advance, we simply create a struct indicating the types of each column. But in this case it will not work.
The solution for this was the use of the MapScan method from github.com/jmoiron/sqlx , which created a slice of interfaces in a size equal to the number of sample columns. The next question was how to get a real data type from these interfaces. The solution is a switch-case by type . Such a solution does not look very beautiful, because you will need to bring all types to a string: whole - as is, strings - to escape and wrap in quotes, but to describe all types that can come from the database. I did not find a more elegant way to solve this issue.
With types, another feature of the Go language was manifested - a variable of the string type cannot take the value nil , but both an empty string and NULL can come from the database. To solve this problem in the database/sql package there is a solution - to use special strut that store the value and the sign, NULL or not.
Build and calculate the percentage of code coverage tests
I use Travis CI for the build, Coveralls for getting the percentage of code coverage of the tests. The .travis.yml file for assembly is quite simple:
language: go go: - 1.9 script: - go get -t -v ./... - go get golang.org/x/tools/cmd/cover - go get github.com/mattn/goveralls - go test -v -covermode=count -coverprofile=coverage.out ./... - $HOME/gopath/bin/goveralls -coverprofile=coverage.out -service=travis-ci -repotoken $COVERALLS_TOKEN In the Travis CI settings, you only need to specify the environment variable COVERALLS_TOKEN , the value of which you need to take on the site .
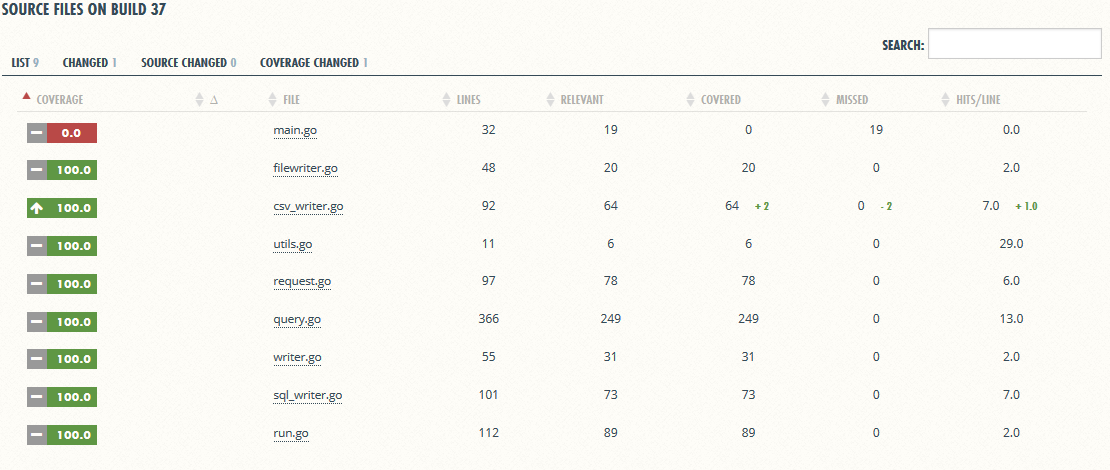
Coveralls allows you to conveniently find out what percentage of the entire project, each file, highlight a line of source code, which turned out to be an uncovered test. For example, in the first build it is clear that I did not write tests for some cases of errors when parsing a user request.
Covering code with tests for 100% means that tests are written that, among other things, execute code for each branch in if . This is the most voluminous work when writing tests, and, in general, when developing an application.
It is possible to calculate the coverage by tests locally, for example, the same go test -v -covermode=count -coverprofile=coverage.out ./... , but it is also more solid to do this in CI, you can place a plate on Github.
If we are talking about dies, then I find a dashboard from https://goreportcard.com useful, which analyzes the following indicators:
- gofmt - code formatting, including simplified constructions
- go_vet - checks for suspicious constructions
- gocyclo - shows problems in cyclomatic complexity
- golint - for me this is a check for all the necessary comments
- license - the project must have a license
- ineffassign - checks for inefficient assignments
- misspell - checks for typos
Difficulties of covering the code with tests for 100%
If parsing a small custom query into parts basically works with converting strings to some structures from strings and is fairly easily covered with tests, then for testing code that works with a database, the solution is not so obvious.
As an option, connect to a real database server, prefill data in each test, perform selections, clear. But this is a difficult decision, far from unit-testing and imposes its requirements on the environment, including the CI-server.
Another option could be to use the database in memory, for example, sqlite ( sqlx.Open("sqlite3", ":memory:") ), but this implies that the code should be tied as little as possible to the database engine, and this greatly complicates the project , but for the integration test is quite good.
For unit testing, use mock for the database. I found this one . Using this package, you can test the behavior both in the case of a normal result and in the event of errors by specifying which query should return the error.
Writing tests showed that the function that connects to the real database needs to be moved to main.go, so it can be redefined in tests for the one that will return the mock instance.
In addition to working with the database, you need to separate work with the file system. This will allow replacing the recording of real files with writing into memory for convenience of testing and will reduce the coupling. This is how the FileWriter interface appeared, and with it the interface of the file returned by it. To test scripts for errors, auxiliary implementations of these interfaces were created and placed in the filewriter_test.go file, so they do not fall into the general build, but can be used in tests.
After a while I had a question, how to cover with tests main() . At that time I had enough code there. As shown by the search results, so do not go in Go . Instead, all the code that can be removed from main() needs to be rendered. In my code, I left only the analysis of options and arguments of the command line ( flag package), connection to the database, instantiation of the object that will be responsible for writing files, and calling the method that will do the rest of the work. But these lines do not allow to get exactly 100% coverage.
In Go testing there is such a thing as " Example Functions ". These are test functions that compare the output with what is described in the commentary inside such a function. Examples of such tests can be found in the go package source code . If such files do not contain tests and benchmarks, then they are named with the prefix example_ and end in _test.go . The name of each such test function must begin with Example . At this point I wrote a test for an object that writes sql to a file, replacing the actual record in the file with a mox, from which you can get the content and output it. This conclusion is compared with the standard. Convenient, you do not need to write a comparison with your hands, and it’s convenient to write a few lines in the comments. But when it came to the test for an object that writes data to a csv file, difficulties arose. According to RFC4180, the lines in CSV should be separated by CRLF, and go fmt replaces all lines with LF, which leads to the fact that the standard from the comment does not coincide with the actual output due to different line separators. I had to write an ordinary test for this object, while also renaming the file, removing example_ from it.
The question remains, if the file, for example, query.go tested according to Example and according to normal tests, should there be two files, example_query_test.go and query_test.go ? Here, for example, there is only one example_test.go . Use the search for "go test example" something else fun.
I learned to write tests in Go according to the guides Google provides for "go writing tests". Most of those I came across ( 1 , 2 , 3 , 4 ) suggest comparing the result obtained with the expected construction of the form
if v != 1.5 { t.Error("Expected 1.5, got ", v) } But when it comes to type comparison, a familiar construct is evolutionarily reborn into a jumble of using the "reflect" or type text dissertation. Or another example when you need to check that slice or map has the necessary value. The code becomes cumbersome. I just want to write my auxiliary functions for the test. Although a good solution here is to use the library for testing. I found https://github.com/stretchr/testify . It allows you to make comparisons in one line . This solution reduces the amount of code and simplifies reading and support of tests.
Code shredding and testing
Writing a test for a high-level function that works with several objects allows one time to significantly raise the code coverage value with tests, because during this test many lines of code of individual objects are performed. If you set yourself a goal of only 100% coverage, then the motivation to write unit tests for small system components is lost, because it does not affect the code coverage value.
In addition, if the test function does not check the result, then this will also not affect the value of code coverage. You can get a high value of coverage, but it does not detect serious errors in the application.
On the other hand, if you have a code with many branches , after which a volume function is called, then it will be difficult to cover it with tests. And here you have an incentive to improve this code, for example, to take all the branches into a separate function and write a separate test for it. This will positively affect the readability of the code.
If the code has a strong coupling, then most likely you will not be able to write a test to it, which means you will have to make changes to it, which will positively affect the quality of the code.
Conclusion
Prior to this project, I did not have to set a goal for myself in 100% code coverage of tests. I could get a workable application in 10 hours of development, but it took me 20 to 30 hours to reach 95% coverage. Using a small example, I got an idea of how the value of code coverage affects its quality, how much effort goes to support it.
My conclusion is that if you see someone with a die with a high code coverage value, then it says almost nothing about how well this application has been tested. You still need to watch the tests themselves. But if you yourself headed for an honest 100%, then this will help you to write an application with better quality.
You can read more about this in the following materials and comments to them:
- The tragedy of 100% code coverage , it's on Habré
- How can you have a 100% coverage, but do not check anything
The word "coating" is used about 20 times. Sorry.
')
Source: https://habr.com/ru/post/418565/
All Articles