NL2API: Creating Natural Language Interfaces for the Web API
Hi, Habr! Most recently, we briefly talked about the Natural Language Interfaces (Natural Language Interfaces). Well, today we have not briefly. Under the cat you will find a full story about creating NL2API for the Web-API. Our colleagues from Research have tested a unique approach to collecting training data for the framework. Join now!

As the Internet evolves towards a service-oriented architecture, software interfaces (APIs) are becoming increasingly important as a way to provide access to data, services, and devices. We are working on the problem of creating a natural language API for the API (NL2API), focusing on web services. NL2API solutions have many potential benefits, for example, helping to simplify the integration of web services into virtual assistants.
')
We offer the first integrated platform (framework), which allows you to create NL2API for a specific web API. The key task is to collect data for training, that is, the pairs “NL command - API call”, which allow NL2API to study the semantics of both NL commands that do not have a strictly defined format, and formal API calls. We offer our own unique approach to the collection of training data for NL2API using crowdsourcing - attracting numerous remote workers to the generation of various NL teams. We optimize the crowdsourcing process itself to reduce costs.
In particular, we offer a fundamentally new hierarchical probabilistic model that will help us distribute the budget for crowdsourcing, mainly between those API calls that have a high value for learning NL2API. We apply our framework to the real API and show that it allows you to collect high-quality training data with minimal costs, as well as create high-performance NL2API from scratch. We also demonstrate that our crowdsourcing model improves the efficiency of this process, that is, the training data collected within its framework provides higher NL2API performance, far exceeding the baseline.
Application programming interfaces (APIs) are playing an increasingly important role in the virtual and physical world due to the development of technologies such as service-oriented architecture (SOA), cloud computing and the Internet of things (IoT). For example, web services hosted in the cloud (weather, sports, finance, etc.) provide data and services to end users via a web API, and IoT devices allow other network devices to use their functionality.

Figure 1. The “NL-command (left) and API call (right)” pairs, collected
our framework, and comparison with IFTTT. GET-Messages and GET-Events are two web APIs for searching emails and calendar events, respectively. The API can be called with various parameters. We concentrate on fully parameterized API calls, while IFTTT is limited to APIs with simple parameters.
APIs are commonly used in various software applications: desktop applications, websites, and mobile applications. They also serve users through a graphical user interface (GUI). The GUI made a great contribution to the popularization of computers, but, as computer technology developed, its numerous limitations increasingly manifest themselves. On the one hand, since devices are becoming smaller, more mobile and smarter, the requirements for a graphic image on the screen are constantly increasing, for example, with respect to portable devices or devices connected to IoT.
On the other hand, users have to adapt to various specialized GUIs for various services and devices. As the number of available services and devices increases, the cost of training and adapting users also grows. Natural language interfaces (NLI), such as Apple Siri and Microsoft Cortana virtual assistants, also known as conversational or conversational interfaces (CUI), demonstrate significant potential as a single intelligent tool for a wide range of server services and devices.
This paper deals with the problem of creating a natural language interface for an API (NL2API). But, unlike virtual assistants, this is not a general-purpose NLI,
we are developing approaches to creating NLIs for specific web APIs, that is, APIs for web services like the multisport service ESPN1. Such NL2APIs can solve the problem of scalability of general-purpose NLI, providing the possibility of distributed development. The usefulness of a virtual assistant largely depends on the breadth of its capabilities, that is, on the number of services it supports.
However, integrating web services into a virtual assistant one by one is incredibly hard work. If individual web services providers had an inexpensive way to create NLI for their APIs, the integration costs would be significantly reduced. A virtual assistant would not have to handle different interfaces for different web services. It would be enough for him to simply integrate the individual NL2API, which achieve uniformity due to natural language. On the other hand, NL2API can also simplify the discovery of web services and the programming of API recommendation and assistance systems, eliminating the need to memorize the large number of available web APIs and their syntax.
Example 1. Two examples are shown in Figure 1. The API can be called with different parameters. In the case of the email search API, users can filter email by specific properties or search for emails by keywords. The main task of NL2API is to match NL commands with corresponding API calls.
Task. The collection of training data is one of the most important tasks related to research in the development of NLI interfaces and their practical application. NLI interfaces use supervised training data, which in the case of NL2API consists of NL command – API call pairs, to learn semantics and uniquely match NL commands with corresponding formalized representations. Natural language is very flexible, so users can describe an API call in syntactically different ways, that is, paraphrasing takes place.
Consider the second example in Figure 1. Users can rephrase this question as follows: “Where will the next meeting take place” or “Find a venue for the next meeting”. Therefore, it is extremely important to collect sufficient training data for the system to recognize such variants in the future. Existing NLIs generally adhere to the “best of principle” principle in the data collection process. For example, the closest analogue of our methodology for comparing NL commands with API calls is using the IF-This-Then-That (IFTTT) concept - “if it is, then” (Figure 1). The training data comes directly from the IFTTT website.
However, if the API is not supported or not fully supported, there is no way to remedy the situation. In addition, the training data collected in this way is of little use for supporting extended commands with several parameters. For example, we analyzed the anonymized Microsoft API call logs to search emails for a month and found that about 90% of them use two or three parameters (approximately in equal amounts), and these parameters are quite diverse. Therefore, we strive to provide full support for API parameterization and to implement extended NL commands. The problem of deploying an active and customizable process of collecting training data for a specific API currently remains unresolved.
The use of NLI in combination with other formalized views, such as relational databases, knowledge bases and web tables, has been worked out fairly well, while the development of the NLI for the web API has received almost no attention. We offer the first comprehensive platform (framework), which allows you to create NL2API for a specific web API from scratch. In the implementation for the web API, our framework includes three steps: (1) Representation. The original HTTP Web API format contains many redundant and, therefore, distracting details from the point of view of the NLI interface.
We suggest using an intermediate semantic representation for the web API in order not to overload NLI with unnecessary information. (2) A set of training data. We propose a new approach to obtaining controlled training data based on crowdsourcing. (3) NL2API. We also offer two NL2API models: a language-based extraction model and a recurrent neural network model (Seq2Seq).
One of the key technical results of this work is a fundamentally new approach to the active collection of training data for NL2API based on crowdsourcing - we use remote performers to annotate API calls when they are compared with NL teams. This allows you to achieve three design goals by ensuring: (1) Customizability. It must be possible to specify which parameters for which API to use and how much training data to collect. (2) Low cost. The services of crowdsourcing workers are much cheaper than the services of specialized specialists, therefore, they need to be hired. (3) High quality. The quality of the training data should not be reduced.
When designing this approach, there are two main problems. First, API calls with extended parameterization, as in Figure 1, are incomprehensible to the average user, so you need to decide how to formulate the annotation problem so that crowdsourced workers can easily cope with it. We begin by developing an intermediate semantic representation for the web API (see Section 2.2), which allows us to seamlessly generate API calls with the required parameters.
Then we think up a grammar to automatically convert each API call to a canonical NL command, which can be quite cumbersome, but it will be understood by the average crowdsourced worker (see section 3.1). The performers will only have to rephrase the canonical team to make it sound more natural. This approach helps to prevent many errors in the collection of training data, since the task of rephrasing is much simpler and clearer for the average crowdsourcing worker.
Secondly, it is necessary to understand how to define and annotate only those API calls that are of real value for NL2API learning. The “combinatorial explosion” that arises during parameterization leads to the fact that the number of calls even for one API can be quite large. Annotate all calls does not make sense. We offer a fundamentally new hierarchical probabilistic model for the implementation of the crowdsourcing process (see Section 3.2). By analogy with language modeling in order to obtain information, we assume that NL commands are generated based on the corresponding API calls, so a language model should be used for each API call in order to register this “spawning” process.
Our model is based on the compositional nature of API calls or formalized representations of the semantic structure as a whole. At the intuitive level, if an API call consists of simpler calls (for example, “unread emails about the application for a candidate of science degree” = “unread emails” + “emails for an application for the degree of candidate of science”, we can build it a language model from simple API calls even without annotation, so by annotating a small number of API calls, we can calculate the language model for everyone else.
Of course, the calculated language models are far from ideal, otherwise we would have already solved the problem of creating an NL2API. Nevertheless, such an extrapolation of the language model to non-annotated API calls gives us a holistic view of the entire space of API calls, as well as the interaction of natural language and API calls, which allows us to optimize the crowdsourcing process. In Section 3.3, we describe an algorithm for selective annotation of API calls that helps to make API calls more distinct, that is, to ensure the maximum divergence of their language models.
We apply our framework to two deployed APIs from the Microsoft Graph API2 package. We demonstrate that high-quality training data can be collected at minimal cost, provided that the proposed approach is used3. We also show that our approach improves crowdsourcing efficiency. At similar costs, we collect higher-quality training data, significantly exceeding the basic indicators. As a result, our NL2API solutions provide higher accuracy.
In general, our main contribution includes three aspects:
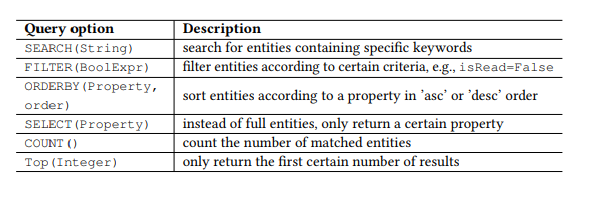
Table 1. OData request parameters.
Recently, web APIs that meet the architectural style of REST, that is, the RESTful API, have become increasingly popular due to their simplicity. RESTful APIs are also used in smartphones and IoT devices. Restful APIs work with resources that are addressed via a URI and provide access to these resources for a wide range of clients using simple HTTP commands: GET, PUT, POST, etc. We will mainly work with the RESTful API, but the basic methods can be used and other APIs.
For example, let's take the popular open data protocol (OData) for the RESTful API and two web APIs from the Microsoft Graph API (Figure 1), which, respectively, are used to search for emails and calendar events of the user. Resources in OData are entities, each of which is associated with a list of properties. For example, the Message entity — an email — has properties such as subject (subject), from (from), isRead (read), receivedDateTime (received date and time), and so on.
In addition, OData defines a set of query parameters, allowing you to perform advanced resource manipulations. For example, the FILTER parameter allows you to search for emails from a specific sender or emails received on a specific date. The request parameters that we will use are presented in Table 1. We call each combination of the HTTP command and an entity (or set of entities) as an API, for example, GET-Messages — to search for emails. Any parameterized request, for example, FILTER (isRead = False), is called a parameter, and an API call is an API with a list of parameters.
The main task of NLI is to compare statements (natural language commands) with a certain formalized representation of, for example, logical forms or SPARQL queries for knowledge bases or web API in our case. When it is necessary to focus on the semantic mapping, without being distracted by irrelevant details, an intermediate semantic representation is usually used in order not to work directly with the target one. For example, combinatorial categorical grammar is widely used to create NLI interfaces for databases and knowledge bases. A similar approach to abstraction is also very important for NL2API. Many details, including URL conventions, HTTP headers and response codes, can “distract” NL2API from solving the main task - the semantic mapping.
Therefore, we create an intermediate representation for the RESTful APIs (Figure 2) called the API frame, this representation reflects the semantics of the frame. Frame API consists of five parts. HTTP Verb (HTTP Command) and Resource (Resource) are basic elements for the RESTful API. Return Type allows you to create composite APIs, that is, combine several API calls to perform a more complex operation. Required Parameters are most often used in PUT or POST calls to the API, for example, for sending e-mail, the required parameters are the addressee, the header and the message body. Optional Parameters are often present in GET calls in the API, they help narrow down the information request.
If the required parameters are missing, we serialize the API frame, for example: GET-messages {FILTER (isRead = False), SEARCH (“PhD application”), COUNT ()}. An API frame can be deterministic and converted to a real API call. During the conversion process, the necessary contextual data will be added, including the user ID, location, date and time. In the second example (Figure 1), the now value in the FILTER parameter will be replaced with the date and time of the execution of the corresponding command during the conversion of an API frame to an actual API call. Further we will use the concepts of an API frame and an API call interchangeably.

Figure 2. Frame API. Above: team in natural language. Middle: Frame API. Below: API call.
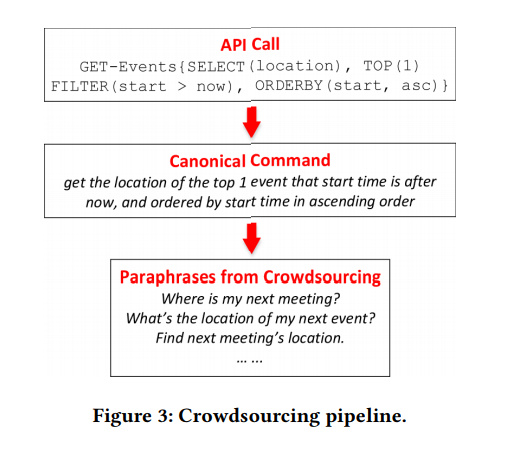
Figure 3. Crowdsourcing conveyor.
This section describes our proposed fundamentally new approach to collecting training data for NL2API solutions using crowdsourcing. First, we generate API calls and convert each of them into a canonical command, based on a simple grammar (section 3.1), and then use crowdsourcing workers to paraphrase canonical commands (Figure 3). Given the compositional nature of API calls, we proposed a hierarchical probabilistic model of crowdsourcing (section 3.2), as well as an algorithm for optimizing crowdsourcing (section 3.3).
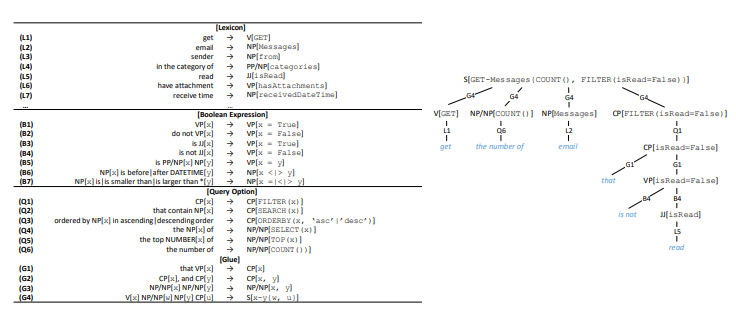
Figure 4. Generation of canonical command. Left: lexicon and grammar. Right: example of derivation.
We generate API calls based solely on the API specification. In addition to schema elements such as request parameters and entity properties, we need property values to generate API calls that are not provided by the API specification. For properties with enumerated values, such as Boolean, we list the possible values (True / False).
For properties with values of an unlimited type, such as Datetime, we will synthesize several representative values, such as today or this_week for receivedDateTime. It is necessary to understand that these are abstract values at the API frame level and they will be converted to real according to the context (for example, the actual date and time) when the API frame is converted to a real API call.
It’s easy to list all combinations of query parameters, properties, and property values to create API calls. Simple heuristics allow you to weed out not quite suitable combinations. For example, TOP is applied to a sorted list, so this parameter must be used in conjunction with ORDERBY. In addition, properties of type Boolean, for example isRead, cannot be used in ORDERBY. Nevertheless, the “combinatorial explosion” in any case determines the presence of a large number of API calls for each API.
The average user is hard to understand API calls. Similarly, we convert an API call into a canonical command. We form an API-specific lexicon and a common grammar for the API (Figure 4). Lexicon allows you to get the lexical form and syntactic category for each element (HTTP commands, entities, properties and property values). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩, , z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
API, , . , , API . , NLI, . API . , z12 = GET-Messages {COUNT(),FILTER(isRead=False)} z1 = GET- Messages{FILTER(isRead=False)} z2 = GET-Messages{COUNT()} ( ).
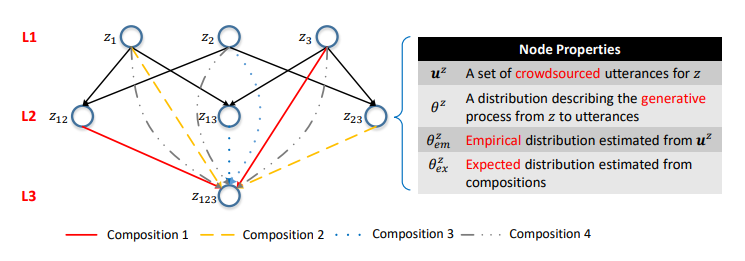
5. . i- API i . — . .
, .
API.
3.1 (). API API
 , r (z) z,
, r (z) z, 
 ,
, 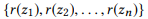
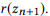
API, API . API ,
. ( SeMesh).
, , , API z, ,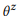 . ,
. ,  where
where 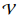 .
.
, , - (Bag of Bernoulli, BoB). W, , w , z, BoB — .
. 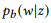
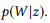 .
.
, () z,
z,
(MLE) BoB , w:

2. API z1 , u1 = «find unread emails» u2 =«emails that are not read», u = {u1, u2 }. pb («emails»|z) = 1.0, «emails» . , pb («unread»|z) = 0.5 pb («meeting»|z) = 0.0.
:
, .
ANNOTATE () z 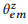 .
.
COMPOSE ()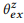 . , — z. , ,
. , — z. , ,  :
:

f . BoB :
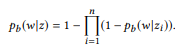
, ui zi, u —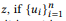 u, w u. , - ui. z , θe x , . - . , , , API, (2). BoB.
u, w u. , - ui. z , θe x , . - . , , , API, (2). BoB.
3. , API z1 z2, :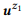 = {«find unread emails», «emails that are not read»}
= {«find unread emails», «emails that are not read»} 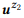 = {«how many emails do I have», «find the number of emails»}.
= {«how many emails do I have», «find the number of emails»}. 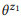 and
and 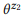 .
. 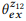 ,
, 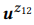 . , «emails», pb («emails»|z1) = 1.0 pb («emails»|z2) = 1.0, , (3) , pb («emails»|z12) = 1.0, , z12. , pb («find»|z1) = 0.5 pb («find»|z2) = 0.5, , pb («find»|z12) = 0.75. z1 z2, z12 .
. , «emails», pb («emails»|z1) = 1.0 pb («emails»|z2) = 1.0, , (3) , pb («emails»|z12) = 1.0, , z12. , pb («find»|z1) = 0.5 pb («find»|z2) = 0.5, , pb («find»|z12) = 0.75. z1 z2, z12 .
, . , , . 3, — TOP(1), FILTER(start>now) ORDERBY(start,asc) — «next». API, . , , API.
— . , . . - , .
INTERPOLATE () z, z , , and .
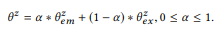
α
, , , , , , , . , , , ().  , . , , = . = .
, . , , = . = .
, z ( 1), . , . , and z. , . , .
1. Update Node Distributions of Semantic Mesh

API, . API, . .
Z. — , . state,
, . state,
policy .
.
, , , ( 2), . , , Z ( 3). ( 5),
( 6), ( 7), ( 8). , , .
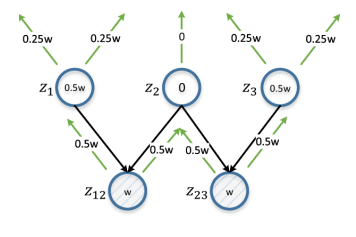
6. . z12 z23 . w — , d(z12, z23), , . z12 z23 ( ). z2 0, z12 z23; z12 z23.
, , , . , « ». , NLI, f: X → Y, X — , , Y .
, Y . -. Y, API, , X, . , . , . .
, . , , API . , . n-  , n = | | — . d ( L1)
, n = | | — . d ( L1)  , .
, .
, . , . , . , , .
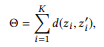
Where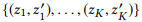 K , .
K , .
2. Iteratively Annotate a Semantic Mesh with a Policy

3. Compute Policy based on Diferential Propagation

4. Recursively Propagate a Score from a Source Node to All Its Parent Nodes

Θ. . , : , , .
, , . , «unread emails about PhD application» «how many emails are about PhD application» , «emails about PhD application» . , : «unread emails» «how many emails».
6, — 3. , ( 6), . , ( 9, 10 4). — ( 12).
, NL2API . NL2API , NLI API.
NLI , NL2API , (LM) .
u API z u. BoB API z -:
API z -:
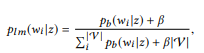
, 0 ≤ β ≤ 1 — .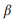 , , . API :
, , . API :
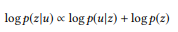
( )
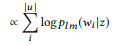
API .
Neural networks are becoming more common as models for NLI, while the Seq2Seq model is better suited for this purpose because it allows you to naturally process input and output sequences of variable length. We are adapting this model for NL2API.
For input sequence e , the model estimates the conditional probability distribution p (y | x) for all possible output sequences
, the model estimates the conditional probability distribution p (y | x) for all possible output sequences 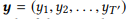 . The lengths T and T ′ can vary and take any values. In NL2API, x is an output statement. y can be a serialized API call or its canonical command. We will use canonical commands as target output sequences, which actually turns our problem into a rephrasing problem.
. The lengths T and T ′ can vary and take any values. In NL2API, x is an output statement. y can be a serialized API call or its canonical command. We will use canonical commands as target output sequences, which actually turns our problem into a rephrasing problem.
An encoder implemented as a recurrent neural network (RNN) with controlled recurrent blocks (GRU) first represents x as a fixed-size vector,

where RN N is a brief representation for applying the GRU to the entire input sequence, marker by marker, followed by the output of the last hidden state.
The decoder, which is also the RNN with the GRU, takes h0 as the initial state and processes the output sequence y, marker by marker, to generate a sequence of states,

The output layer takes each decoder state as an input value and generates a dictionary distribution. as output value. We simply use affine transformation followed by the soft variable logistic function:
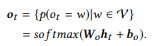
The final conditional probability, which allows you to evaluate how well the canonical command y rephrases the input statement x, -
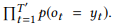 . API calls are then ranked by the conditional probability of their canonical command. We recommend to get acquainted with the source, where the process of learning the model is described in more detail.
. API calls are then ranked by the conditional probability of their canonical command. We recommend to get acquainted with the source, where the process of learning the model is described in more detail.
Experimentally, we study the following research subjects: [PI1]: Can we, using the proposed framework, collect high-quality training data at a reasonable price? [PI2]: Does the semantic network provide a more accurate assessment of language models than a maximum likelihood estimate? [PI3]: Does a differential distribution strategy allow for more efficient crowdsourcing?
We apply the proposed framework to the two Microsoft web APIs - GET-Events and GET-Messages - which provide access to advanced search services for user emails and calendar events, respectively. We create a semantic network for each API, listing all API calls (section 3.1) and up to four parameters in each. The distribution of API calls is shown in Table 2. We use an internal crowdsourcing platform, similar to Amazon Mechanical Turk. To ensure the flexibility of the experiment, we annotated all API calls with a maximum of three parameters.
However, in each particular experiment, we will use only a specific subset for learning. Each API call is annotated with 10 statements, and we pay 10 cents for each statement. 201 participants are involved in annotation, all of them have been selected using the qualification test. On average, the performer took 44 seconds to rephrase the canonical team, so we can get 82 teaching examples from each artist per hour, and the cost will be $ 8.2, which, in our opinion, is quite a bit. Regarding the quality of annotations, we manually checked 400 collected statements and found that the proportion of errors is 17.4%.
The main causes of errors are related to the absence of certain parameters (for example, the performer did not specify the ORDERBY parameter or a COUNT parameter) or incorrect interpretation of the parameters (for example, ascending ranking is indicated when ranking is in descending order). These examples account for about half of the errors. The proportion of errors is comparable to that of other crowdsourcing projects in the field of NLI. Thus, we consider the answer to [PI1] to be positive. Data quality can be improved by engaging independent crowdsourced workers for post-testing.
In addition, we received an annotated independent test set formed randomly from the entire semantic network and including, among other things, API calls with four parameters (Table 3). Each API call in the test set initially had three statements. We conducted a test and weed out statements with errors in order to improve the quality of testing. The final test set included 61 API calls and 157 statements for GET-Messages, as well as 77 API calls and 190 statements for GET-Events. Not all test statements were included in the training data, besides many test API calls (for example, calls with four parameters) were not involved in training, therefore, the test set was very complex.
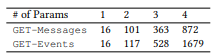
Table 2. Distribution of API calls.

Table 3. The distribution of the test set: statements (calls).
As an estimate, we use accuracy, that is, the proportion of test statements for which the maximum prediction was correct. Unless otherwise specified, the balance parameter is α = 0.3, and the smoothing parameter is LM β = 0.001. The number of pairs of vertices K used for differential propagation is 100,000. The set value for the state, size, encoder, and decoder in the Seq2Seq model is 500. Parameters are selected based on the results of a preliminary study on a separate test set (regardless of testing).
The semantic network is not only useful for optimizing crowdsourcing as the first of its kind model of the crowdsourcing process for NLI, it also has technical advantages. Therefore, we will evaluate the semantic network and the optimization algorithm separately.
Overall effectiveness. In this experiment, we evaluate the model of the semantic network and, in particular, the effectiveness of the operations of composition and interpolation from the point of view of optimizing the assessment of language models. The quality of language models can be judged by the effectiveness of the LM model: the more accurate the assessment, the higher the efficiency. We use several training sets corresponding to different sets of annotated vertices. ROOT is the root vertices. TOP2 = ROOT + all nodes of layer 2; and TOP3 = TOP2 + all nodes of layer 3. This allows the semantic network to be evaluated using different amounts of training data.
The results are shown in table 4. When working with the base model LM, we use the maximum likelihood estimate (MLE) to analyze the language model, that is, we use for all non-annotated vertices, and uniform distribution for non-annotated vertices. It is not surprising that the efficiency is rather low, especially if the number of annotated vertices is small, since the MLE cannot provide information about non-annotated vertices.
By adding the composition to the MLE, we can estimate the expected distribution for non-annotated vertices but
for non-annotated vertices but  still used for annotated vertices, i.e. no interpolation. This allows you to significantly optimize the API and a variety of training data. With just 16 annotated API calls (ROOT), a simple LM model with SeMesh can outperform a more sophisticated Seq2Seq model with more than a hundred annotated API calls (TOP2) and approach a model containing about 500 annotated API calls (TOP3).
still used for annotated vertices, i.e. no interpolation. This allows you to significantly optimize the API and a variety of training data. With just 16 annotated API calls (ROOT), a simple LM model with SeMesh can outperform a more sophisticated Seq2Seq model with more than a hundred annotated API calls (TOP2) and approach a model containing about 500 annotated API calls (TOP3).
These results clearly show that the language models evaluated using the composition operation are sufficiently accurate, the validity of the assumption that the expressiveness of the statements (Section 3.2) is proved empirically. It can be noted that working with GET-Events is generally more difficult than with GET-Messages. This is because GET-Events uses
more teams that are tied to time, and events may relate to the future or the past, whereas e-mails always refer only to the past.
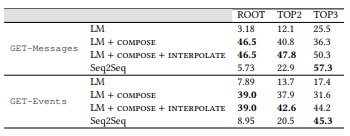
Table 4. Overall Accuracy Percentage. The operations of the semantic network greatly optimize the simple LM model, making it better for the more complex Seq2Seq model, when the amount of training data is rather small. The results prove that the semantic network provides an accurate assessment of language models.
The effectiveness of the LM + composition decreases when we use more training data, which indicates that it is inexpedient to use only and the need to combine with θem with . When we interpolate and then we achieve improvements everywhere except at the ROOT level, where none of the peaks can be simultaneously and . Unlike composition, the more training data we use for interpolation, the better the result of the operation. In general, the semantic network provides significant optimization compared to the basic MLE indicators. Thus, we consider the answer to [PI2] to be positive.
The best indicators of accuracy are in the range from 0.45 to 0.6: they are not very high, but they are on the same level as indicators of modern methods of applying NLI to knowledge bases. This reflects the complexity of the problem, as the model must exactly find the best among thousands of related API calls. By collecting additional statements for each API call (see also Figure 7) and using more advanced models, such as bidirectional RNNs with an attention mechanism, you can further improve efficiency. We will leave these questions for future work.
The impact of hyperparameters. Now consider the influence of two hyperparameters on the semantic network: the number of statements | u | and the balance parameter α. Here, we still rely on the effectiveness of the LM model (Figure 7). Sayings are randomly selected when | u | <10, and the model output is given average marks for 10 repeated runs. We show the results for GET-Events, for GET-Messages they are similar.
It is not surprising that the more statements we annotate for each vertex, the higher the efficiency, although the increment gradually decreases. Therefore, in the presence of such a possibility, it is recommended to collect additional statements. On the other hand, the model efficiency is practically independent of α, since this parameter lies in the allowable range ([0.1, 0.7]). The influence of the parameter α increases with the number of annotated vertices, which is quite expected, since interpolation affects only annotated vertices.
In this experiment, we evaluate the effectiveness of applying the proposed differential propagation strategy (DP) to optimize crowdsourcing. Various crowdsourcing strategies iteratively select API annotation calls. At each iteration, each strategy selects 50 API calls, and then they are annotated, and the two NL2API models use the accumulated annotated data for training.
Finally, models are evaluated on a test set. We use the basic LM model, which does not depend on the semantic network. The best crowdsourcing strategy should provide the best model performance for the same number of annotations. Instead of annotating vertices on the fly using crowdsourcing, we use annotations collected earlier as a pool of candidates (section 5.1), so all strategies will be selected only from existing API calls with three parameters.
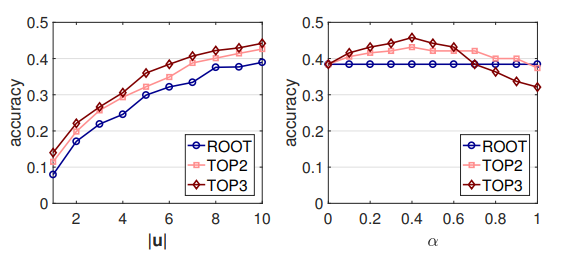
Figure 7. Effects of hyperparameters.
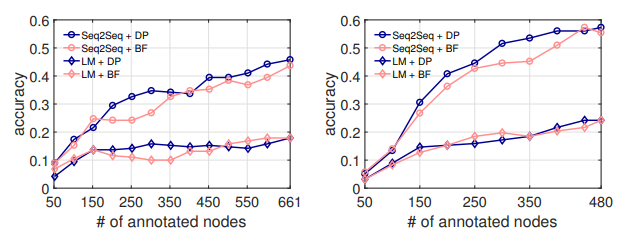
Figure 8. Crowdsourcing optimization experiment. Left: GET-Events. Right: GET-Messages
We take the breadth first strategy (BF) as a basic strategy, which in the downstream direction gradually annotates each layer of the semantic network. It resembles a strategy out. So we get the basic indicators. Calling top-level APIs is usually more important because they are compositions of low-level API calls.
The results of the experiment are shown in Figure 8. For both NL2API models and both APIs, the DP strategy generally improves efficiency. When we annotate only 300 calls for each API, as applied to the Seq2Seq model, DP provides an absolute increase in accuracy of more than 7% for both APIs. When the pool of candidates is exhausted, the two algorithms converge, which is expected. The results show that DP allows you to define API calls that are highly valuable for learning NL2API. Thus, we consider the answer to [PI3] to be positive.
Natural language interface. Over the creation of natural language interfaces (NLI) experts have been working for several decades. The first NLI mainly used the rules. Learning-based methods have firmly taken the lead in recent years. The most popular learning algorithms are based on log-line models and relatively recently developed deep neural networks.
The application of NLI to relational databases, knowledge bases and web tables has been studied fairly well, but there is almost no research on the API. NL2API developers face two major problems: the lack of a single semantic representation for the API and, in part because of this, the lack of training data. We are working on solving both problems. We offer a unified semantic representation of the API based on the REST standard and a fundamentally new approach to the collection of training data in this representation.
Collection of training data for NLI. Existing training data collection solutions for NLI generally adhere to the principle of "the best of the possible". For example, questions in natural language are collected using the Google Suggest API, and the authors receive commands and corresponding API calls from the IFTTT website. Researchers have relatively recently begun to explore approaches to creating NLI, involving the collection of training data using crowdsourcing. Crowdsourcing has become a familiar practice in various language related studies.
However, there is little study of its application to create NLI interfaces, which allow solving the unique and intriguing task of modeling the interaction between natural language representations and formalized representations of the semantic structure. Most of these studies involve the application of NLI to knowledge bases, where a formalized presentation is expressed by logical forms in a certain logical formalism. The authors propose to transform logical forms into canonical commands with the help of grammar, and in described methods for refining generated logical forms and screening out those that do not correspond to a significant question in natural language.
A semi-automatic framework is proposed for interacting with users on the fly and comparing commands in natural language with API calls on smartphones. The authors propose a similar solution based on a crowdsourcing framework, where performers interactively perform annotation tasks for the web API. But no researcher has so far dealt with the use of the compositionality of formal representations to optimize the crowdsourcing process.
Semantic methods for web API. There are a number of other semantic methods developed for the web API. For example, the semantic descriptions of the web API are retrieved in order to simplify the composition of the API, while the proposed search mechanism for the web API to compose the compositions. The NL2API technology will potentially allow to solve such problems, for example, when used as a single search engine to find an API.
We formulated the problem of creating a natural language interface for web APIs (NL2API) and proposed a comprehensive framework for developing NL2API from scratch. One of the key technical results of the work is a fundamentally new approach to the collection of training data for NL2API based on crowdsourcing. The work opens up several areas for further research: (1) The language model. How, by way of generalization, to move from individual words to more complex language units, for example, phrases? (2) Crowdsourcing optimization.
How to use the semantic network as efficiently as possible? (3) Model NL2API. For example, the framework for filling slots in voice dialogue systems is optimally suited for our presentation of API frames. (4) Composition API. How to collect training data while using multiple APIs? (5) Optimization during the interaction: how to continue to improve the NL2API in the process of user interaction after the initial training?
annotation
As the Internet evolves towards a service-oriented architecture, software interfaces (APIs) are becoming increasingly important as a way to provide access to data, services, and devices. We are working on the problem of creating a natural language API for the API (NL2API), focusing on web services. NL2API solutions have many potential benefits, for example, helping to simplify the integration of web services into virtual assistants.
')
We offer the first integrated platform (framework), which allows you to create NL2API for a specific web API. The key task is to collect data for training, that is, the pairs “NL command - API call”, which allow NL2API to study the semantics of both NL commands that do not have a strictly defined format, and formal API calls. We offer our own unique approach to the collection of training data for NL2API using crowdsourcing - attracting numerous remote workers to the generation of various NL teams. We optimize the crowdsourcing process itself to reduce costs.
In particular, we offer a fundamentally new hierarchical probabilistic model that will help us distribute the budget for crowdsourcing, mainly between those API calls that have a high value for learning NL2API. We apply our framework to the real API and show that it allows you to collect high-quality training data with minimal costs, as well as create high-performance NL2API from scratch. We also demonstrate that our crowdsourcing model improves the efficiency of this process, that is, the training data collected within its framework provides higher NL2API performance, far exceeding the baseline.
Introduction
Application programming interfaces (APIs) are playing an increasingly important role in the virtual and physical world due to the development of technologies such as service-oriented architecture (SOA), cloud computing and the Internet of things (IoT). For example, web services hosted in the cloud (weather, sports, finance, etc.) provide data and services to end users via a web API, and IoT devices allow other network devices to use their functionality.
Figure 1. The “NL-command (left) and API call (right)” pairs, collected
our framework, and comparison with IFTTT. GET-Messages and GET-Events are two web APIs for searching emails and calendar events, respectively. The API can be called with various parameters. We concentrate on fully parameterized API calls, while IFTTT is limited to APIs with simple parameters.
APIs are commonly used in various software applications: desktop applications, websites, and mobile applications. They also serve users through a graphical user interface (GUI). The GUI made a great contribution to the popularization of computers, but, as computer technology developed, its numerous limitations increasingly manifest themselves. On the one hand, since devices are becoming smaller, more mobile and smarter, the requirements for a graphic image on the screen are constantly increasing, for example, with respect to portable devices or devices connected to IoT.
On the other hand, users have to adapt to various specialized GUIs for various services and devices. As the number of available services and devices increases, the cost of training and adapting users also grows. Natural language interfaces (NLI), such as Apple Siri and Microsoft Cortana virtual assistants, also known as conversational or conversational interfaces (CUI), demonstrate significant potential as a single intelligent tool for a wide range of server services and devices.
This paper deals with the problem of creating a natural language interface for an API (NL2API). But, unlike virtual assistants, this is not a general-purpose NLI,
we are developing approaches to creating NLIs for specific web APIs, that is, APIs for web services like the multisport service ESPN1. Such NL2APIs can solve the problem of scalability of general-purpose NLI, providing the possibility of distributed development. The usefulness of a virtual assistant largely depends on the breadth of its capabilities, that is, on the number of services it supports.
However, integrating web services into a virtual assistant one by one is incredibly hard work. If individual web services providers had an inexpensive way to create NLI for their APIs, the integration costs would be significantly reduced. A virtual assistant would not have to handle different interfaces for different web services. It would be enough for him to simply integrate the individual NL2API, which achieve uniformity due to natural language. On the other hand, NL2API can also simplify the discovery of web services and the programming of API recommendation and assistance systems, eliminating the need to memorize the large number of available web APIs and their syntax.
Example 1. Two examples are shown in Figure 1. The API can be called with different parameters. In the case of the email search API, users can filter email by specific properties or search for emails by keywords. The main task of NL2API is to match NL commands with corresponding API calls.
Task. The collection of training data is one of the most important tasks related to research in the development of NLI interfaces and their practical application. NLI interfaces use supervised training data, which in the case of NL2API consists of NL command – API call pairs, to learn semantics and uniquely match NL commands with corresponding formalized representations. Natural language is very flexible, so users can describe an API call in syntactically different ways, that is, paraphrasing takes place.
Consider the second example in Figure 1. Users can rephrase this question as follows: “Where will the next meeting take place” or “Find a venue for the next meeting”. Therefore, it is extremely important to collect sufficient training data for the system to recognize such variants in the future. Existing NLIs generally adhere to the “best of principle” principle in the data collection process. For example, the closest analogue of our methodology for comparing NL commands with API calls is using the IF-This-Then-That (IFTTT) concept - “if it is, then” (Figure 1). The training data comes directly from the IFTTT website.
However, if the API is not supported or not fully supported, there is no way to remedy the situation. In addition, the training data collected in this way is of little use for supporting extended commands with several parameters. For example, we analyzed the anonymized Microsoft API call logs to search emails for a month and found that about 90% of them use two or three parameters (approximately in equal amounts), and these parameters are quite diverse. Therefore, we strive to provide full support for API parameterization and to implement extended NL commands. The problem of deploying an active and customizable process of collecting training data for a specific API currently remains unresolved.
The use of NLI in combination with other formalized views, such as relational databases, knowledge bases and web tables, has been worked out fairly well, while the development of the NLI for the web API has received almost no attention. We offer the first comprehensive platform (framework), which allows you to create NL2API for a specific web API from scratch. In the implementation for the web API, our framework includes three steps: (1) Representation. The original HTTP Web API format contains many redundant and, therefore, distracting details from the point of view of the NLI interface.
We suggest using an intermediate semantic representation for the web API in order not to overload NLI with unnecessary information. (2) A set of training data. We propose a new approach to obtaining controlled training data based on crowdsourcing. (3) NL2API. We also offer two NL2API models: a language-based extraction model and a recurrent neural network model (Seq2Seq).
One of the key technical results of this work is a fundamentally new approach to the active collection of training data for NL2API based on crowdsourcing - we use remote performers to annotate API calls when they are compared with NL teams. This allows you to achieve three design goals by ensuring: (1) Customizability. It must be possible to specify which parameters for which API to use and how much training data to collect. (2) Low cost. The services of crowdsourcing workers are much cheaper than the services of specialized specialists, therefore, they need to be hired. (3) High quality. The quality of the training data should not be reduced.
When designing this approach, there are two main problems. First, API calls with extended parameterization, as in Figure 1, are incomprehensible to the average user, so you need to decide how to formulate the annotation problem so that crowdsourced workers can easily cope with it. We begin by developing an intermediate semantic representation for the web API (see Section 2.2), which allows us to seamlessly generate API calls with the required parameters.
Then we think up a grammar to automatically convert each API call to a canonical NL command, which can be quite cumbersome, but it will be understood by the average crowdsourced worker (see section 3.1). The performers will only have to rephrase the canonical team to make it sound more natural. This approach helps to prevent many errors in the collection of training data, since the task of rephrasing is much simpler and clearer for the average crowdsourcing worker.
Secondly, it is necessary to understand how to define and annotate only those API calls that are of real value for NL2API learning. The “combinatorial explosion” that arises during parameterization leads to the fact that the number of calls even for one API can be quite large. Annotate all calls does not make sense. We offer a fundamentally new hierarchical probabilistic model for the implementation of the crowdsourcing process (see Section 3.2). By analogy with language modeling in order to obtain information, we assume that NL commands are generated based on the corresponding API calls, so a language model should be used for each API call in order to register this “spawning” process.
Our model is based on the compositional nature of API calls or formalized representations of the semantic structure as a whole. At the intuitive level, if an API call consists of simpler calls (for example, “unread emails about the application for a candidate of science degree” = “unread emails” + “emails for an application for the degree of candidate of science”, we can build it a language model from simple API calls even without annotation, so by annotating a small number of API calls, we can calculate the language model for everyone else.
Of course, the calculated language models are far from ideal, otherwise we would have already solved the problem of creating an NL2API. Nevertheless, such an extrapolation of the language model to non-annotated API calls gives us a holistic view of the entire space of API calls, as well as the interaction of natural language and API calls, which allows us to optimize the crowdsourcing process. In Section 3.3, we describe an algorithm for selective annotation of API calls that helps to make API calls more distinct, that is, to ensure the maximum divergence of their language models.
We apply our framework to two deployed APIs from the Microsoft Graph API2 package. We demonstrate that high-quality training data can be collected at minimal cost, provided that the proposed approach is used3. We also show that our approach improves crowdsourcing efficiency. At similar costs, we collect higher-quality training data, significantly exceeding the basic indicators. As a result, our NL2API solutions provide higher accuracy.
In general, our main contribution includes three aspects:
- We were one of the first to start exploring the NL2API problematics and suggested a comprehensive framework for creating NL2API from scratch.
- We proposed a unique approach to the collection of training data using crowdsourcing and a fundamentally new hierarchical probabilistic model for optimizing this process.
- We applied our framework to real web APIs and demonstrated that a sufficiently effective NL2API solution can be created from scratch.
Table 1. OData request parameters.
Preamble
RESTful API
Recently, web APIs that meet the architectural style of REST, that is, the RESTful API, have become increasingly popular due to their simplicity. RESTful APIs are also used in smartphones and IoT devices. Restful APIs work with resources that are addressed via a URI and provide access to these resources for a wide range of clients using simple HTTP commands: GET, PUT, POST, etc. We will mainly work with the RESTful API, but the basic methods can be used and other APIs.
For example, let's take the popular open data protocol (OData) for the RESTful API and two web APIs from the Microsoft Graph API (Figure 1), which, respectively, are used to search for emails and calendar events of the user. Resources in OData are entities, each of which is associated with a list of properties. For example, the Message entity — an email — has properties such as subject (subject), from (from), isRead (read), receivedDateTime (received date and time), and so on.
In addition, OData defines a set of query parameters, allowing you to perform advanced resource manipulations. For example, the FILTER parameter allows you to search for emails from a specific sender or emails received on a specific date. The request parameters that we will use are presented in Table 1. We call each combination of the HTTP command and an entity (or set of entities) as an API, for example, GET-Messages — to search for emails. Any parameterized request, for example, FILTER (isRead = False), is called a parameter, and an API call is an API with a list of parameters.
NL2API
The main task of NLI is to compare statements (natural language commands) with a certain formalized representation of, for example, logical forms or SPARQL queries for knowledge bases or web API in our case. When it is necessary to focus on the semantic mapping, without being distracted by irrelevant details, an intermediate semantic representation is usually used in order not to work directly with the target one. For example, combinatorial categorical grammar is widely used to create NLI interfaces for databases and knowledge bases. A similar approach to abstraction is also very important for NL2API. Many details, including URL conventions, HTTP headers and response codes, can “distract” NL2API from solving the main task - the semantic mapping.
Therefore, we create an intermediate representation for the RESTful APIs (Figure 2) called the API frame, this representation reflects the semantics of the frame. Frame API consists of five parts. HTTP Verb (HTTP Command) and Resource (Resource) are basic elements for the RESTful API. Return Type allows you to create composite APIs, that is, combine several API calls to perform a more complex operation. Required Parameters are most often used in PUT or POST calls to the API, for example, for sending e-mail, the required parameters are the addressee, the header and the message body. Optional Parameters are often present in GET calls in the API, they help narrow down the information request.
If the required parameters are missing, we serialize the API frame, for example: GET-messages {FILTER (isRead = False), SEARCH (“PhD application”), COUNT ()}. An API frame can be deterministic and converted to a real API call. During the conversion process, the necessary contextual data will be added, including the user ID, location, date and time. In the second example (Figure 1), the now value in the FILTER parameter will be replaced with the date and time of the execution of the corresponding command during the conversion of an API frame to an actual API call. Further we will use the concepts of an API frame and an API call interchangeably.
Figure 2. Frame API. Above: team in natural language. Middle: Frame API. Below: API call.
Figure 3. Crowdsourcing conveyor.
Collection of training data
This section describes our proposed fundamentally new approach to collecting training data for NL2API solutions using crowdsourcing. First, we generate API calls and convert each of them into a canonical command, based on a simple grammar (section 3.1), and then use crowdsourcing workers to paraphrase canonical commands (Figure 3). Given the compositional nature of API calls, we proposed a hierarchical probabilistic model of crowdsourcing (section 3.2), as well as an algorithm for optimizing crowdsourcing (section 3.3).
Figure 4. Generation of canonical command. Left: lexicon and grammar. Right: example of derivation.
API call and canonical command
We generate API calls based solely on the API specification. In addition to schema elements such as request parameters and entity properties, we need property values to generate API calls that are not provided by the API specification. For properties with enumerated values, such as Boolean, we list the possible values (True / False).
For properties with values of an unlimited type, such as Datetime, we will synthesize several representative values, such as today or this_week for receivedDateTime. It is necessary to understand that these are abstract values at the API frame level and they will be converted to real according to the context (for example, the actual date and time) when the API frame is converted to a real API call.
It’s easy to list all combinations of query parameters, properties, and property values to create API calls. Simple heuristics allow you to weed out not quite suitable combinations. For example, TOP is applied to a sorted list, so this parameter must be used in conjunction with ORDERBY. In addition, properties of type Boolean, for example isRead, cannot be used in ORDERBY. Nevertheless, the “combinatorial explosion” in any case determines the presence of a large number of API calls for each API.
The average user is hard to understand API calls. Similarly, we convert an API call into a canonical command. We form an API-specific lexicon and a common grammar for the API (Figure 4). Lexicon allows you to get the lexical form and syntactic category for each element (HTTP commands, entities, properties and property values). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩,
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read»., . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
API, , . , , API . , NLI, . API . , z12 = GET-Messages {COUNT(),FILTER(isRead=False)} z1 = GET- Messages{FILTER(isRead=False)} z2 = GET-Messages{COUNT()} ( ).
5. . i- API i . — . .
, .
API.
3.1 (). API API
, r (z) z, , API, API . API ,
. ( SeMesh).
, , , API z, ,
. , where ., , - (Bag of Bernoulli, BoB). W, , w , z, BoB —
. ., ()
z,(MLE) BoB , w:
2. API z1 , u1 = «find unread emails» u2 =«emails that are not read», u = {u1, u2 }. pb («emails»|z) = 1.0, «emails» . , pb («unread»|z) = 0.5 pb («meeting»|z) = 0.0.
:
, .
ANNOTATE ()
z .COMPOSE ()
. , — z. , , :f . BoB :
, ui zi, u —
u, w u. , - ui. z , θe x , . - . , , , API, (2). BoB.3. , API z1 z2, :
= {«find unread emails», «emails that are not read»} = {«how many emails do I have», «find the number of emails»}. and . , . , «emails», pb («emails»|z1) = 1.0 pb («emails»|z2) = 1.0, , (3) , pb («emails»|z12) = 1.0, , z12. , pb («find»|z1) = 0.5 pb («find»|z2) = 0.5, , pb («find»|z12) = 0.75. z1 z2, z12 ., . , , . 3, — TOP(1), FILTER(start>now) ORDERBY(start,asc) — «next». API, . , , API.
— . , . . - , .
INTERPOLATE () z, z , ,
and .α
, , , , , , , . ,
, , (). , . , , = . = .,
z ( 1), . , . , and z. , . , .1. Update Node Distributions of Semantic Mesh
3.3
API, . API, . .
Z. —
, . state,policy
., , , ( 2), . , , Z ( 3). ( 5),
( 6), ( 7), ( 8). , , .
6. . z12 z23 . w — , d(z12, z23), , . z12 z23 ( ). z2 0, z12 z23; z12 z23.
, , , . , « ». , NLI, f: X → Y, X — , , Y .
, Y . -. Y, API, , X, . , . , . .
, . , , API . ,
. n- , n = | | — . d ( L1) , ., . , . , . , , .
Where
K , .2. Iteratively Annotate a Semantic Mesh with a Policy
3. Compute Policy based on Diferential Propagation
4. Recursively Propagate a Score from a Source Node to All Its Parent Nodes
Θ. . , : , , .
, , . , «unread emails about PhD application» «how many emails are about PhD application» , «emails about PhD application» . , : «unread emails» «how many emails».
6, — 3. , ( 6), . , ( 9, 10 4). — ( 12).
-
, NL2API . NL2API , NLI API.
NLI , NL2API , (LM) .
u API z u. BoB
API z -:, 0 ≤ β ≤ 1 — .
, , . API :( )
API .
Seq2Seq
Neural networks are becoming more common as models for NLI, while the Seq2Seq model is better suited for this purpose because it allows you to naturally process input and output sequences of variable length. We are adapting this model for NL2API.
For input sequence e
, the model estimates the conditional probability distribution p (y | x) for all possible output sequences . The lengths T and T ′ can vary and take any values. In NL2API, x is an output statement. y can be a serialized API call or its canonical command. We will use canonical commands as target output sequences, which actually turns our problem into a rephrasing problem.An encoder implemented as a recurrent neural network (RNN) with controlled recurrent blocks (GRU) first represents x as a fixed-size vector,
where RN N is a brief representation for applying the GRU to the entire input sequence, marker by marker, followed by the output of the last hidden state.
The decoder, which is also the RNN with the GRU, takes h0 as the initial state and processes the output sequence y, marker by marker, to generate a sequence of states,
The output layer takes each decoder state as an input value and generates a dictionary distribution.
as output value. We simply use affine transformation followed by the soft variable logistic function:The final conditional probability, which allows you to evaluate how well the canonical command y rephrases the input statement x, -
. API calls are then ranked by the conditional probability of their canonical command. We recommend to get acquainted with the source, where the process of learning the model is described in more detail.Experiments
Experimentally, we study the following research subjects: [PI1]: Can we, using the proposed framework, collect high-quality training data at a reasonable price? [PI2]: Does the semantic network provide a more accurate assessment of language models than a maximum likelihood estimate? [PI3]: Does a differential distribution strategy allow for more efficient crowdsourcing?
Crowdsourcing
We apply the proposed framework to the two Microsoft web APIs - GET-Events and GET-Messages - which provide access to advanced search services for user emails and calendar events, respectively. We create a semantic network for each API, listing all API calls (section 3.1) and up to four parameters in each. The distribution of API calls is shown in Table 2. We use an internal crowdsourcing platform, similar to Amazon Mechanical Turk. To ensure the flexibility of the experiment, we annotated all API calls with a maximum of three parameters.
However, in each particular experiment, we will use only a specific subset for learning. Each API call is annotated with 10 statements, and we pay 10 cents for each statement. 201 participants are involved in annotation, all of them have been selected using the qualification test. On average, the performer took 44 seconds to rephrase the canonical team, so we can get 82 teaching examples from each artist per hour, and the cost will be $ 8.2, which, in our opinion, is quite a bit. Regarding the quality of annotations, we manually checked 400 collected statements and found that the proportion of errors is 17.4%.
The main causes of errors are related to the absence of certain parameters (for example, the performer did not specify the ORDERBY parameter or a COUNT parameter) or incorrect interpretation of the parameters (for example, ascending ranking is indicated when ranking is in descending order). These examples account for about half of the errors. The proportion of errors is comparable to that of other crowdsourcing projects in the field of NLI. Thus, we consider the answer to [PI1] to be positive. Data quality can be improved by engaging independent crowdsourced workers for post-testing.
In addition, we received an annotated independent test set formed randomly from the entire semantic network and including, among other things, API calls with four parameters (Table 3). Each API call in the test set initially had three statements. We conducted a test and weed out statements with errors in order to improve the quality of testing. The final test set included 61 API calls and 157 statements for GET-Messages, as well as 77 API calls and 190 statements for GET-Events. Not all test statements were included in the training data, besides many test API calls (for example, calls with four parameters) were not involved in training, therefore, the test set was very complex.
Table 2. Distribution of API calls.
Table 3. The distribution of the test set: statements (calls).
Staging experiment
As an estimate, we use accuracy, that is, the proportion of test statements for which the maximum prediction was correct. Unless otherwise specified, the balance parameter is α = 0.3, and the smoothing parameter is LM β = 0.001. The number of pairs of vertices K used for differential propagation is 100,000. The set value for the state, size, encoder, and decoder in the Seq2Seq model is 500. Parameters are selected based on the results of a preliminary study on a separate test set (regardless of testing).
The semantic network is not only useful for optimizing crowdsourcing as the first of its kind model of the crowdsourcing process for NLI, it also has technical advantages. Therefore, we will evaluate the semantic network and the optimization algorithm separately.
Evaluation of the semantic network
Overall effectiveness. In this experiment, we evaluate the model of the semantic network and, in particular, the effectiveness of the operations of composition and interpolation from the point of view of optimizing the assessment of language models. The quality of language models can be judged by the effectiveness of the LM model: the more accurate the assessment, the higher the efficiency. We use several training sets corresponding to different sets of annotated vertices. ROOT is the root vertices. TOP2 = ROOT + all nodes of layer 2; and TOP3 = TOP2 + all nodes of layer 3. This allows the semantic network to be evaluated using different amounts of training data.
The results are shown in table 4. When working with the base model LM, we use the maximum likelihood estimate (MLE) to analyze the language model, that is, we use
for all non-annotated vertices, and uniform distribution for non-annotated vertices. It is not surprising that the efficiency is rather low, especially if the number of annotated vertices is small, since the MLE cannot provide information about non-annotated vertices.By adding the composition to the MLE, we can estimate the expected distribution
for non-annotated vertices but still used for annotated vertices, i.e. no interpolation. This allows you to significantly optimize the API and a variety of training data. With just 16 annotated API calls (ROOT), a simple LM model with SeMesh can outperform a more sophisticated Seq2Seq model with more than a hundred annotated API calls (TOP2) and approach a model containing about 500 annotated API calls (TOP3).These results clearly show that the language models evaluated using the composition operation are sufficiently accurate, the validity of the assumption that the expressiveness of the statements (Section 3.2) is proved empirically. It can be noted that working with GET-Events is generally more difficult than with GET-Messages. This is because GET-Events uses
more teams that are tied to time, and events may relate to the future or the past, whereas e-mails always refer only to the past.
Table 4. Overall Accuracy Percentage. The operations of the semantic network greatly optimize the simple LM model, making it better for the more complex Seq2Seq model, when the amount of training data is rather small. The results prove that the semantic network provides an accurate assessment of language models.
The effectiveness of the LM + composition decreases when we use more training data, which indicates that it is inexpedient to use only
and the need to combine with θem with . When we interpolate and then we achieve improvements everywhere except at the ROOT level, where none of the peaks can be simultaneously and . Unlike composition, the more training data we use for interpolation, the better the result of the operation. In general, the semantic network provides significant optimization compared to the basic MLE indicators. Thus, we consider the answer to [PI2] to be positive.The best indicators of accuracy are in the range from 0.45 to 0.6: they are not very high, but they are on the same level as indicators of modern methods of applying NLI to knowledge bases. This reflects the complexity of the problem, as the model must exactly find the best among thousands of related API calls. By collecting additional statements for each API call (see also Figure 7) and using more advanced models, such as bidirectional RNNs with an attention mechanism, you can further improve efficiency. We will leave these questions for future work.
The impact of hyperparameters. Now consider the influence of two hyperparameters on the semantic network: the number of statements | u | and the balance parameter α. Here, we still rely on the effectiveness of the LM model (Figure 7). Sayings are randomly selected when | u | <10, and the model output is given average marks for 10 repeated runs. We show the results for GET-Events, for GET-Messages they are similar.
It is not surprising that the more statements we annotate for each vertex, the higher the efficiency, although the increment gradually decreases. Therefore, in the presence of such a possibility, it is recommended to collect additional statements. On the other hand, the model efficiency is practically independent of α, since this parameter lies in the allowable range ([0.1, 0.7]). The influence of the parameter α increases with the number of annotated vertices, which is quite expected, since interpolation affects only annotated vertices.
Crowdsourcing optimization
In this experiment, we evaluate the effectiveness of applying the proposed differential propagation strategy (DP) to optimize crowdsourcing. Various crowdsourcing strategies iteratively select API annotation calls. At each iteration, each strategy selects 50 API calls, and then they are annotated, and the two NL2API models use the accumulated annotated data for training.
Finally, models are evaluated on a test set. We use the basic LM model, which does not depend on the semantic network. The best crowdsourcing strategy should provide the best model performance for the same number of annotations. Instead of annotating vertices on the fly using crowdsourcing, we use annotations collected earlier as a pool of candidates (section 5.1), so all strategies will be selected only from existing API calls with three parameters.
Figure 7. Effects of hyperparameters.
Figure 8. Crowdsourcing optimization experiment. Left: GET-Events. Right: GET-Messages
We take the breadth first strategy (BF) as a basic strategy, which in the downstream direction gradually annotates each layer of the semantic network. It resembles a strategy out. So we get the basic indicators. Calling top-level APIs is usually more important because they are compositions of low-level API calls.
The results of the experiment are shown in Figure 8. For both NL2API models and both APIs, the DP strategy generally improves efficiency. When we annotate only 300 calls for each API, as applied to the Seq2Seq model, DP provides an absolute increase in accuracy of more than 7% for both APIs. When the pool of candidates is exhausted, the two algorithms converge, which is expected. The results show that DP allows you to define API calls that are highly valuable for learning NL2API. Thus, we consider the answer to [PI3] to be positive.
Related research areas
Natural language interface. Over the creation of natural language interfaces (NLI) experts have been working for several decades. The first NLI mainly used the rules. Learning-based methods have firmly taken the lead in recent years. The most popular learning algorithms are based on log-line models and relatively recently developed deep neural networks.
The application of NLI to relational databases, knowledge bases and web tables has been studied fairly well, but there is almost no research on the API. NL2API developers face two major problems: the lack of a single semantic representation for the API and, in part because of this, the lack of training data. We are working on solving both problems. We offer a unified semantic representation of the API based on the REST standard and a fundamentally new approach to the collection of training data in this representation.
Collection of training data for NLI. Existing training data collection solutions for NLI generally adhere to the principle of "the best of the possible". For example, questions in natural language are collected using the Google Suggest API, and the authors receive commands and corresponding API calls from the IFTTT website. Researchers have relatively recently begun to explore approaches to creating NLI, involving the collection of training data using crowdsourcing. Crowdsourcing has become a familiar practice in various language related studies.
However, there is little study of its application to create NLI interfaces, which allow solving the unique and intriguing task of modeling the interaction between natural language representations and formalized representations of the semantic structure. Most of these studies involve the application of NLI to knowledge bases, where a formalized presentation is expressed by logical forms in a certain logical formalism. The authors propose to transform logical forms into canonical commands with the help of grammar, and in described methods for refining generated logical forms and screening out those that do not correspond to a significant question in natural language.
A semi-automatic framework is proposed for interacting with users on the fly and comparing commands in natural language with API calls on smartphones. The authors propose a similar solution based on a crowdsourcing framework, where performers interactively perform annotation tasks for the web API. But no researcher has so far dealt with the use of the compositionality of formal representations to optimize the crowdsourcing process.
Semantic methods for web API. There are a number of other semantic methods developed for the web API. For example, the semantic descriptions of the web API are retrieved in order to simplify the composition of the API, while the proposed search mechanism for the web API to compose the compositions. The NL2API technology will potentially allow to solve such problems, for example, when used as a single search engine to find an API.
Conclusions and directions for further research
We formulated the problem of creating a natural language interface for web APIs (NL2API) and proposed a comprehensive framework for developing NL2API from scratch. One of the key technical results of the work is a fundamentally new approach to the collection of training data for NL2API based on crowdsourcing. The work opens up several areas for further research: (1) The language model. How, by way of generalization, to move from individual words to more complex language units, for example, phrases? (2) Crowdsourcing optimization.
How to use the semantic network as efficiently as possible? (3) Model NL2API. For example, the framework for filling slots in voice dialogue systems is optimally suited for our presentation of API frames. (4) Composition API. How to collect training data while using multiple APIs? (5) Optimization during the interaction: how to continue to improve the NL2API in the process of user interaction after the initial training?
Source: https://habr.com/ru/post/418559/
All Articles