Binary modules for Python
Python is cool. We say “pip install” and most likely the necessary library will be installed. But sometimes the answer will be: “compilation failed”, because there are binary modules. Almost all modern languages suffer from some kind of pain, because there are many architectures, something needs to be collected for a specific machine, something needs to be linked with other libraries. In general, an interesting, but little-studied question: how to make them and what problems are there? Dmitry Zhiltsov ( zaabjuda ) tried to answer this question on MoscowPython Conf last year.
Under the cut text version of the report of Dmitry. Let us briefly dwell on when binary modules are needed, and when they should be abandoned. We will discuss the rules that should be followed when writing them. Consider five possible implementation options:
About speaker : Dmitry Zhiltsov has been developing for more than 10 years. He works for CIAN as a system architect, that is, he is responsible for technical decisions and control over deadlines. In his life, he managed to try and assembler, Haskell, C, and for the last 5 years he has been actively programming in Python.
')
About company
Many who live in Moscow and rent housing, probably know about CIAN. CIAN is 7 million buyers and tenants per month. All these users every month, with the help of our service, find a place to live.
About our company know 75% of Muscovites, and this is very cool. In St. Petersburg and Moscow, we are practically considered monopolists. At the moment we are trying to reach the regions, and therefore, the development has grown 8 times over the past 3 years. This means that the teams increased 8 times, the speed of delivery of valuables to the user increased 8 times, i.e. from the product idea to how the engineer’s hand rolled out the build to production. We learned in our large team to develop very quickly, and very quickly understand what is happening at the moment, but today we will talk a little about something else.
I will talk about binary modules. Now almost 50% of the libraries in Python have some kind of binary modules. And as it turned out, many people are not familiar with them and believe that this is something transcendental, something dark and unnecessary. And other people suggest it is better to write a separate microservice, and not to use binary modules.
The article will consist of two parts.
Why do we need binary modules
We all know that Python is an interpreted language. It is almost the fastest interpreted language, but, unfortunately, its speed is not always sufficient for heavy mathematical calculations. Immediately the thought arises that C will be faster.
But Python has another pain - GIL . A huge number of articles have been written about him and reports have been made on how to get around it.
We also need binary extensions to reuse logic . For example, we found a library in which all the functionality we need is available, and why not use it. That is, do not re-write the code, we just take the ready-made code and reuse it.
Many people believe that using binary extensions, you can hide the source code . The question is very, very controversial, of course with the help of some wild perversions you can achieve this, but there is no 100% guarantee. The maximum that can be obtained is to prevent the client from decompiling and see what happens in the code that you transferred.
When are binary extensions really needed?
It’s clear about speed and Python - when some function works very slowly with us and takes up 80% of the execution time of all the code, we start thinking about writing a binary extension. But in order to make such decisions, you need to start, as one famous speaker said, to think with your brain.
In order to write extensions, you need to take into account that, firstly, it will be a long time. First you need to "lick" their algorithms, i.e. see if there are any shoals.
The second case where binary extensions are really needed is the use of multi threading for simple operations . Now it is not so important, but it still remains in a bloody enterprise, in some system integrators, where it is still written in Python 2.6. There is no asynchrony, and even for simple things, such as loading a bunch of pictures, multi-threading rises. It seems that initially it does not bear any network costs, but when we upload the image to the buffer, the ill-fated GIL comes in and some brakes start. As practice shows, such things are better solved with the help of libraries that Python knows nothing about.
If you need to implement some specific protocol, it may be convenient to make simple C / C ++ code and get rid of a lot of pain. I did this at one time in one telecom operator, since there was no ready-made library, I had to write it myself. But I repeat, now this is not very relevant, because there is asyncio, and for most tasks this is enough.
I have already said in advance about difficult operations . When you have a number of crushers, large matrices and the like, it is logical that you need to do an extension in C / C ++. I want to note that some people think that we don’t need binary extensions here, it’s better to do microservice in some “ super-fast language ” and transfer huge matrices over the network. No, it's better not to do that.
Another good example of when they can and even need to be taken is when you have a well-established logic for the operation of a module . If you have a Python module or library already in your company for 3 years, there are changes in it once a year and then 2 lines, then why not arrange it in a normal C library if there are free resources and time. At a minimum, get an increase in performance. And there will also be an understanding that if some fundamental changes are needed in the library, then it is not so easy and, perhaps, again, the brain should think about it and use this library somehow differently.
5 golden rules
I derived these rules in my practice. They concern not only Python, but also other languages for which binary extensions can be used. You can argue with them, but you can think and bring your own.
Binary extensions architecture

Actually, there is nothing difficult in the architecture of binary extensions. There is Python, there is a calling function, which lands on a wrapper, which natively calls sish code. This call in turn lands on a function that is exported to Python and which it can directly call. It is in this function that you need to bring data types to the data types of your language. And only after this function has translated everything to us, we call the native function, which does the basic logic, returns the result in the opposite direction and throws it in Python, translating the data types back.
Technologies and tools
The most famous way to write binary extensions is the Native C / C ++ extension. Just because it is standard Python technology.
Native C / C ++ extension
Python itself is implemented in C, and the methods and structures from python.h are used when writing extensions. By the way, this thing is also good because it is very easy to implement it in an already finished project. It is enough to specify xt_modules in setup.py and say that to build a project you need to compile such and such sources with such compilation flags. Below is an example.
Pros Native C / C ++ Extension
Cons Native C / C ++ Extension
On this technology, a huge amount of documentation is written, both standard and posts in all sorts of blogs. A huge plus is that we can make our own Python data types and construct our classes.
This approach has big drawbacks. First of all, this is the entry threshold - not everyone knows C enough to code for production. You need to understand that it is not enough to read the book and run to write native extensions. If you want to do this, then: first learn C; then start writing command utilities; only then proceed to writing the extensions.
Boost.Python is very good for C ++, it allows you to almost completely abstract from all these wrappers that we use in Python. But the minus I think is that to take some part of it and import it into the project, without downloading the whole Boost, you need to sweat very much.
Enumerating the difficulties in debugging in the minuses, I mean that now everyone is used to using the graphical debugger, and with binary modules such a thing will not work. Most likely you will need to put GDB with a plugin for Python.
Consider an example of how we create it.
First, we include the Python header files. After that, we describe the addList_add function that Python will use. The most important thing is to call the function correctly, in this case addList is our name of the sish module, _add is the name of the function that will be used in Python. We pass the PyObject module itself and pass arguments, too, using PyObject. After that we make standard checks. In this case, we are trying to parse the argument tuple and say that this object - the literal "O" must be explicitly specified. After this, we know that we have passed a listObj as an object, and we are trying to find out its length using standard Python methods: PyList_Size. Notice, here we still cannot use sishnye calls to find out the length of this vector, but use the Python functional. Omit the implementation, after which you must return all values back to Python. To do this, call Py_BuildValue, specify which data type we return, in this case “i” is an integer, and the variable sum itself.
In this case, everyone understands - we find the sum of all the elements of the list. Let's go a little further.
Here is the same thing, at the moment listObj is a Python object. And in this case we are trying to take list items. For this, Python.h has everything you need.
After we got temp, we try to cast it to long. And only after that you can do something in C.
Once we have implemented the entire function, you need to write documentation. Documentation is always good , and in this toolkit everything is there for easy reference. Adhering to the convention on names, we call the module addList_docs and save the description there. Now you need to register the module, for this there is a special structure PyMethodDef. When describing properties, we say that the function is exported to Python under the name “add”, that this function calls PyCFunction. METH_VARARGS means that a function can potentially accept any number of variables. We also wrote down additional lines and described a standard check, in case we just imported the module, but didn’t apply to any method so that all of us would not fall.
After we have announced all this we are trying to make a module. We create moduledef and put everything that we have already done there.
PyModuleDef_HEAD_INIT is a standard Python constant that you should always use. —1 indicates that no additional memory is required at the import stage.
When we created the module itself, we need to initialize it. Python is always looking for init, so we create PyInit_addList for addList. Now from the collected structure you can call PyModule_Create and finally create the module itself. Next, add the meta-information and return the module itself.
As you have already noticed, there is a lot to transform. We must always remember about Python when we write in C / C ++.
That is why, to make life easier for an ordinary mortal programmer, 15 years ago SWIG technology appeared.
Swig
This tool allows you to abstract Python bindings and write native sish code. It has the same pros and cons as with Native C / C ++, but there are exceptions.
SWIG advantages:
Cons SWIG:
The first minus is that while you set it up, you'll lose your mind . When I set it up for the first time, I spent a day and a half to launch it at all. Then, of course, easier. In the SWIG 3.x version it became easier.
To no longer go into the code, consider the general scheme of SWIG.
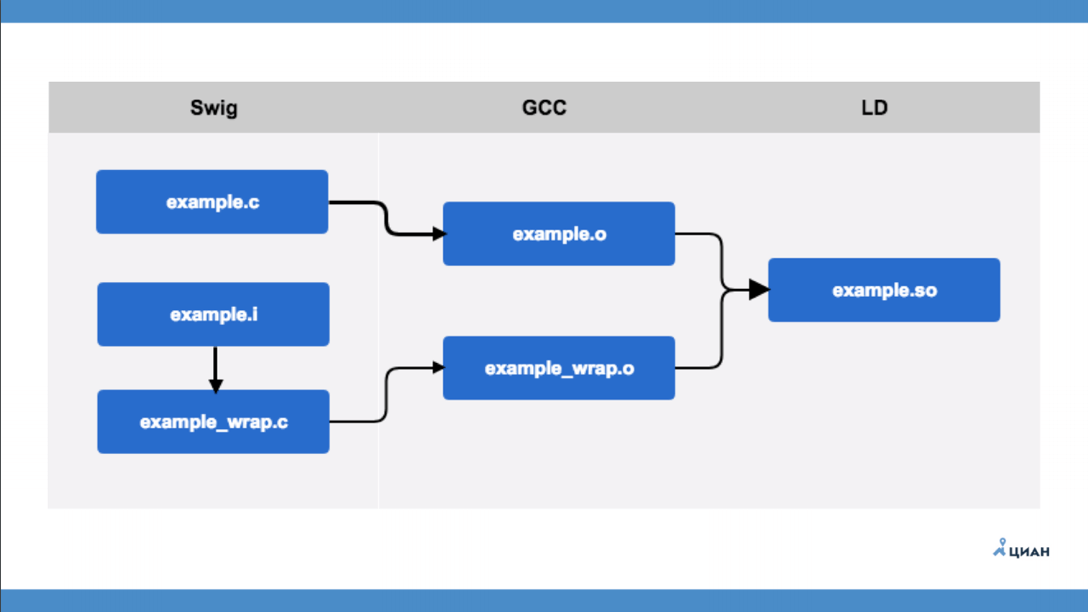
example.c is a C module that knows nothing about Python at all. There is an interface file example.i, which is described in SWIG format. After that, we run the SWIG utility, which from the interface file creates example_wrap.c - this is the same wrapper that we used to do with our hands. That is, SWIG just creates a file wrapper for us, the so-called bridge. After that, using GCC, we compile two files and get two object files (example.o and example_wrap.o) and then create our library. Everything is simple and clear.
Cython
Andrei Svetlov made an excellent report at MoscowPython Conf, so I’ll just say that this is a popular technology with good documentation.
Pros of Cython:
Cons Cython:
Cons, as always, is. The main one is its own syntax, which is similar to C / C ++, and very strongly to Python.
But I want to emphasize that Python code can be accelerated using Cython by writing native code.

As you can see a lot of decorators, and this is not very good. If you want to use Cython - refer to the report by Andrey Svetlov.
CTypes
CTypes is a standard Python library that works with the Foreign Function Interface. FFI is a low-level library. This is a native technology, it is often used to horror in the code, with its help it is easy to implement cross-platform.
But FFI carries with it large overheads, because all bridges, all handlers at runtime are dynamically created. That is, we loaded the dynamic library, and Python at this moment does not know anything at all what the library is. Only when the library is called in memory are these bridges dynamically constructed.
Pros CTypes:
Cons CTypes:
Took adder.so and at runtime natively called. We can even pass native Python types.
After all this, there is a question: “Somehow everything is difficult, everywhere C, what to do?”.
Rusty
At one time, I did not give this language due attention, but now I’m practically switching to it.
Rust Pros:
Cons Rust:
Rust is a secure language with automatic proof of work. The syntax itself and the language preprocessor itself do not allow making an explicit error. At the same time, it is sharpened for variation, that is, it is obliged to process any result of the execution of a code branch.
Thanks to the PyO3 team, there are good bindings for Python for Rust, and tools for integrating into a project.
I'll take the cons to the fact that for an unprepared programmer, it's very long to tune it. Little documentation, but in return for cons, we have no segmentation fault. In Rust, in an amicable way, in 99% of cases, a programmer can get a segmentation fault only if he explicitly specified unwrap and just scored on this case.
A small sample of the code of the same module that we considered before.
The code has a specific syntax, but you get used to it very quickly. In fact, everything is the same here. Using macros, we do modinit, which does all the extra work for us to generate all sorts of bindings for Python. Remember I said, you need to do a handler wrapper, here is the same. run_py converts types, then we call native code.
As you can see, to export a function, there is syntactic sugar. We simply say that we need the add function, and do not describe any interfaces. We accept the list, which is exactly py_list, and not Object, because Rust will set up the necessary binders at compile time. If we pass the wrong data type, as in the ssh extensions, a TypeError will occur. After we got the list, we start processing it.
Let's see in more detail what he is starting to do.
The same code that was on C / C ++ / Ctypes, but only now on Rust. There I tried to bring PyObject to some kind of long. So that it would be if to us in the list, besides numbers, would there be a string? Yes, we would get SystemEerror. In this case, through let mut sum : i32 = 0; we are also trying to get a value from list and bring it to i32. That is, we will not be able to write this code without item.extract (), and we can combine it to the necessary type. When we wrote i32, in case of a Rust error, at the compilation stage it will say: “Handle the case when not i32”. In this case, if we have i32, we return the value, if this is a mistake - we throw an exception.
What to choose
After this small excursion we will think about what to choose in the end?
The answer is really to your taste and color.
I will not promote any particular technology.

Just summarize:
Under the cut text version of the report of Dmitry. Let us briefly dwell on when binary modules are needed, and when they should be abandoned. We will discuss the rules that should be followed when writing them. Consider five possible implementation options:
- Native C / C ++ Extension
- Swig
- Cython
- Ctypes
- Rusty
About speaker : Dmitry Zhiltsov has been developing for more than 10 years. He works for CIAN as a system architect, that is, he is responsible for technical decisions and control over deadlines. In his life, he managed to try and assembler, Haskell, C, and for the last 5 years he has been actively programming in Python.
')
About company
Many who live in Moscow and rent housing, probably know about CIAN. CIAN is 7 million buyers and tenants per month. All these users every month, with the help of our service, find a place to live.
About our company know 75% of Muscovites, and this is very cool. In St. Petersburg and Moscow, we are practically considered monopolists. At the moment we are trying to reach the regions, and therefore, the development has grown 8 times over the past 3 years. This means that the teams increased 8 times, the speed of delivery of valuables to the user increased 8 times, i.e. from the product idea to how the engineer’s hand rolled out the build to production. We learned in our large team to develop very quickly, and very quickly understand what is happening at the moment, but today we will talk a little about something else.
I will talk about binary modules. Now almost 50% of the libraries in Python have some kind of binary modules. And as it turned out, many people are not familiar with them and believe that this is something transcendental, something dark and unnecessary. And other people suggest it is better to write a separate microservice, and not to use binary modules.
The article will consist of two parts.
- My experience: what are they for when it is better to use them and when not.
- Tools and technologists with which you can implement a binary module for Python.
Why do we need binary modules
We all know that Python is an interpreted language. It is almost the fastest interpreted language, but, unfortunately, its speed is not always sufficient for heavy mathematical calculations. Immediately the thought arises that C will be faster.
But Python has another pain - GIL . A huge number of articles have been written about him and reports have been made on how to get around it.
We also need binary extensions to reuse logic . For example, we found a library in which all the functionality we need is available, and why not use it. That is, do not re-write the code, we just take the ready-made code and reuse it.
Many people believe that using binary extensions, you can hide the source code . The question is very, very controversial, of course with the help of some wild perversions you can achieve this, but there is no 100% guarantee. The maximum that can be obtained is to prevent the client from decompiling and see what happens in the code that you transferred.
When are binary extensions really needed?
It’s clear about speed and Python - when some function works very slowly with us and takes up 80% of the execution time of all the code, we start thinking about writing a binary extension. But in order to make such decisions, you need to start, as one famous speaker said, to think with your brain.
In order to write extensions, you need to take into account that, firstly, it will be a long time. First you need to "lick" their algorithms, i.e. see if there are any shoals.
In 90% of cases, after a thorough check of the algorithm, there is no need to write any extensions.
The second case where binary extensions are really needed is the use of multi threading for simple operations . Now it is not so important, but it still remains in a bloody enterprise, in some system integrators, where it is still written in Python 2.6. There is no asynchrony, and even for simple things, such as loading a bunch of pictures, multi-threading rises. It seems that initially it does not bear any network costs, but when we upload the image to the buffer, the ill-fated GIL comes in and some brakes start. As practice shows, such things are better solved with the help of libraries that Python knows nothing about.
If you need to implement some specific protocol, it may be convenient to make simple C / C ++ code and get rid of a lot of pain. I did this at one time in one telecom operator, since there was no ready-made library, I had to write it myself. But I repeat, now this is not very relevant, because there is asyncio, and for most tasks this is enough.
I have already said in advance about difficult operations . When you have a number of crushers, large matrices and the like, it is logical that you need to do an extension in C / C ++. I want to note that some people think that we don’t need binary extensions here, it’s better to do microservice in some “ super-fast language ” and transfer huge matrices over the network. No, it's better not to do that.
Another good example of when they can and even need to be taken is when you have a well-established logic for the operation of a module . If you have a Python module or library already in your company for 3 years, there are changes in it once a year and then 2 lines, then why not arrange it in a normal C library if there are free resources and time. At a minimum, get an increase in performance. And there will also be an understanding that if some fundamental changes are needed in the library, then it is not so easy and, perhaps, again, the brain should think about it and use this library somehow differently.
5 golden rules
I derived these rules in my practice. They concern not only Python, but also other languages for which binary extensions can be used. You can argue with them, but you can think and bring your own.
- Export functions only . Building classes in Python in binary libraries is quite laborious: you need to describe a lot of interfaces, you need to revise a lot of referential integrations in the module itself. It's easier to write a small interface for a function.
- Use wrapper classes . Some like OOP very much and want classes very much. In any case, even if these are not classes, it is better to simply write a Python wrapper: create a class, set a class method or an ordinary method, call natively C / C ++ functions. At a minimum, this helps maintain the integrity of the data architecture. If you are using some kind of C / C ++ third-party extension that you cannot fix, then in the wrapper you can hack it so that it all works.
- You can't pass arguments from Python to an extension — it's not even a rule, but rather a requirement. In some cases this may work, but usually this is a bad idea. Therefore, in your C code, you first have to make a handler that brings the Python type to type C. And only after that call any native function that already works with caching types. The same handler accepts the response from the executable function and converts it into Python data types, and sends it to the Python code.
- Consider garbage collection . In Python, there is a well-known GC, and you should not forget about it. For example, we pass on a link a large piece of text and try to find some word in the library. We want to parallelize it, pass the link to this particular area of memory and start several threads. At this time, the GC simply takes and decides that nothing else refers to this object and removes it from the memory area. In the same code, we just get a null reference, and this is usually the segmentation fault. One should not forget about such a feature of the garbage collector and transfer the simplest data types to the library libraries: char, integer, etc.
On the other hand, the language in which the extension is written may have its own garbage collector. The combination of Python and the C # library in this sense is a pain. - Explicitly define the arguments of the exported function . By this I want to say that these functions will need to be annotated qualitatively. If we accept the PyObject function, and in any case we will accept it in our sish libraries, then we will need to explicitly indicate which arguments belong to which types. This is useful because if we pass the wrong data type, we get an error in the library library. That is necessary for your convenience.
Binary extensions architecture
Actually, there is nothing difficult in the architecture of binary extensions. There is Python, there is a calling function, which lands on a wrapper, which natively calls sish code. This call in turn lands on a function that is exported to Python and which it can directly call. It is in this function that you need to bring data types to the data types of your language. And only after this function has translated everything to us, we call the native function, which does the basic logic, returns the result in the opposite direction and throws it in Python, translating the data types back.
Technologies and tools
The most famous way to write binary extensions is the Native C / C ++ extension. Just because it is standard Python technology.
Native C / C ++ extension
Python itself is implemented in C, and the methods and structures from python.h are used when writing extensions. By the way, this thing is also good because it is very easy to implement it in an already finished project. It is enough to specify xt_modules in setup.py and say that to build a project you need to compile such and such sources with such compilation flags. Below is an example.
name = 'DateTime.mxDateTime.mxDateTime' src = 'mxDateTime/mxDateTime.c' extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra'] setup ( ... ext_modules = [(name, { 'sources': [src], 'include_dirs': ['mxDateTime'] , extra_compile_args: extra_compile_args } )] ) Pros Native C / C ++ Extension
- Native technology.
- Easily integrated into the project build.
- The greatest amount of documentation.
- Allows you to create your own data types.
Cons Native C / C ++ Extension
- High entry threshold.
- Knowledge of C is necessary.
- Boost.Python.
- Segmentation Fault.
- Difficulties in debugging.
On this technology, a huge amount of documentation is written, both standard and posts in all sorts of blogs. A huge plus is that we can make our own Python data types and construct our classes.
This approach has big drawbacks. First of all, this is the entry threshold - not everyone knows C enough to code for production. You need to understand that it is not enough to read the book and run to write native extensions. If you want to do this, then: first learn C; then start writing command utilities; only then proceed to writing the extensions.
Boost.Python is very good for C ++, it allows you to almost completely abstract from all these wrappers that we use in Python. But the minus I think is that to take some part of it and import it into the project, without downloading the whole Boost, you need to sweat very much.
Enumerating the difficulties in debugging in the minuses, I mean that now everyone is used to using the graphical debugger, and with binary modules such a thing will not work. Most likely you will need to put GDB with a plugin for Python.
Consider an example of how we create it.
#include <Python.h> static PyObject*addList_add(Pyobject* self, Pyobject* args){ PyObject * listObj; if (! PyARg_Parsetuple( args, "", &listObj)) return NULL; long length = PyList_Size(listObj) int i, sum =0; // return Py_BuildValue("i", sum); } First, we include the Python header files. After that, we describe the addList_add function that Python will use. The most important thing is to call the function correctly, in this case addList is our name of the sish module, _add is the name of the function that will be used in Python. We pass the PyObject module itself and pass arguments, too, using PyObject. After that we make standard checks. In this case, we are trying to parse the argument tuple and say that this object - the literal "O" must be explicitly specified. After this, we know that we have passed a listObj as an object, and we are trying to find out its length using standard Python methods: PyList_Size. Notice, here we still cannot use sishnye calls to find out the length of this vector, but use the Python functional. Omit the implementation, after which you must return all values back to Python. To do this, call Py_BuildValue, specify which data type we return, in this case “i” is an integer, and the variable sum itself.
In this case, everyone understands - we find the sum of all the elements of the list. Let's go a little further.
for(i = 0; i< length; i++){ // // Python- PyObject* temp = PyList_GetItem(listObj, i); // , // C long long elem= PyLong_AsLong(temp); sum += elem; } Here is the same thing, at the moment listObj is a Python object. And in this case we are trying to take list items. For this, Python.h has everything you need.
After we got temp, we try to cast it to long. And only after that you can do something in C.
// static char addList_docs[] = "add( ): add all elements of the list\n"; // static PyMethodDef addList_funcs[] = { {"add", (PyCFunction)addList_add, METH_VARARGS, addList_docs}, {NULL, NULL, 0, NULL} }; Once we have implemented the entire function, you need to write documentation. Documentation is always good , and in this toolkit everything is there for easy reference. Adhering to the convention on names, we call the module addList_docs and save the description there. Now you need to register the module, for this there is a special structure PyMethodDef. When describing properties, we say that the function is exported to Python under the name “add”, that this function calls PyCFunction. METH_VARARGS means that a function can potentially accept any number of variables. We also wrote down additional lines and described a standard check, in case we just imported the module, but didn’t apply to any method so that all of us would not fall.
After we have announced all this we are trying to make a module. We create moduledef and put everything that we have already done there.
static struct PyModuleDef moduledef = { PyModuleDef_HEAD_INIT, "addList example module", -1, adList_funcs, NULL, NULL, NULL, NULL }; PyModuleDef_HEAD_INIT is a standard Python constant that you should always use. —1 indicates that no additional memory is required at the import stage.
When we created the module itself, we need to initialize it. Python is always looking for init, so we create PyInit_addList for addList. Now from the collected structure you can call PyModule_Create and finally create the module itself. Next, add the meta-information and return the module itself.
PyInit_addList(void){ PyObject *module = PyModule_Create(&mdef); If (module == NULL) return NULL; PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:"); PyModule_addStringConstant (Module, "__version__", "1.0.0"); return module; } As you have already noticed, there is a lot to transform. We must always remember about Python when we write in C / C ++.
That is why, to make life easier for an ordinary mortal programmer, 15 years ago SWIG technology appeared.
Swig
This tool allows you to abstract Python bindings and write native sish code. It has the same pros and cons as with Native C / C ++, but there are exceptions.
SWIG advantages:
- Stable technology.
- A large amount of documentation.
- Abstracts from binding to Python.
Cons SWIG:
- Long tuning.
- Knowledge C.
- Segmentation Fault.
- Difficulties in debugging.
- The complexity of integration into the project assembly.
The first minus is that while you set it up, you'll lose your mind . When I set it up for the first time, I spent a day and a half to launch it at all. Then, of course, easier. In the SWIG 3.x version it became easier.
To no longer go into the code, consider the general scheme of SWIG.
example.c is a C module that knows nothing about Python at all. There is an interface file example.i, which is described in SWIG format. After that, we run the SWIG utility, which from the interface file creates example_wrap.c - this is the same wrapper that we used to do with our hands. That is, SWIG just creates a file wrapper for us, the so-called bridge. After that, using GCC, we compile two files and get two object files (example.o and example_wrap.o) and then create our library. Everything is simple and clear.
Cython
Andrei Svetlov made an excellent report at MoscowPython Conf, so I’ll just say that this is a popular technology with good documentation.
Pros of Cython:
- Popular technology.
- Pretty stable.
- Easily integrated into the project build.
- Good documentation.
Cons Cython:
- Its syntax.
- Knowledge C.
- Segmentation Fault.
- Difficulties in debugging.
Cons, as always, is. The main one is its own syntax, which is similar to C / C ++, and very strongly to Python.
But I want to emphasize that Python code can be accelerated using Cython by writing native code.
As you can see a lot of decorators, and this is not very good. If you want to use Cython - refer to the report by Andrey Svetlov.
CTypes
CTypes is a standard Python library that works with the Foreign Function Interface. FFI is a low-level library. This is a native technology, it is often used to horror in the code, with its help it is easy to implement cross-platform.
But FFI carries with it large overheads, because all bridges, all handlers at runtime are dynamically created. That is, we loaded the dynamic library, and Python at this moment does not know anything at all what the library is. Only when the library is called in memory are these bridges dynamically constructed.
Pros CTypes:
- Native technology.
- Easy to use in code.
- Easy to implement cross-platform.
- You can use almost any language.
Cons CTypes:
- Bears overhead.
- Difficulties in debugging.
from ctypes import * #load the shared object file Adder = CDLL('./adder.so') #Calculate factorial res_int = adder.fact(4) print("Fact of 4 = " + str(res_int)) Took adder.so and at runtime natively called. We can even pass native Python types.
After all this, there is a question: “Somehow everything is difficult, everywhere C, what to do?”.
Rusty
At one time, I did not give this language due attention, but now I’m practically switching to it.
Rust Pros:
- Safe language.
- Powerful static guarantees of correct behavior.
- Easily integrated into the project build ( PyO3 ).
Cons Rust:
- High entry threshold.
- Long tuning.
- Difficulties in debugging.
- Documentation is not enough.
- In some cases, overhead.
Rust is a secure language with automatic proof of work. The syntax itself and the language preprocessor itself do not allow making an explicit error. At the same time, it is sharpened for variation, that is, it is obliged to process any result of the execution of a code branch.
Thanks to the PyO3 team, there are good bindings for Python for Rust, and tools for integrating into a project.
I'll take the cons to the fact that for an unprepared programmer, it's very long to tune it. Little documentation, but in return for cons, we have no segmentation fault. In Rust, in an amicable way, in 99% of cases, a programmer can get a segmentation fault only if he explicitly specified unwrap and just scored on this case.
A small sample of the code of the same module that we considered before.
#![feature(proc_macro)] #[macro_use] extern crate pyo3; Use pyo3::prelude::*; /// Module documentation string 1 #[py::modinit(_addList)] fn init(py: Python, m: PyModule) -> PyResult <()>{ py_exception!(_addList, EmptyListError); /// Function documentation string 1 #[pufn(m, "run", args= "*", kwargs="**" )] fn run_py(_py: Python, args: &PyTuple, kwargs: Option<&PyDict>) -> PyResult<()> { run(args, kwargs) } #[pyfn(m, "run", args="*", kwatgs="**")] fn run_py(_py: Python, args: &PyTuple, kwargs: Option<&PyDict>) -> PyResult<()>{ run(args,kwargs) } #[pyfn(m,"add")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32>{ let mut sum : i32 = 0 match py_list.len() { /// Some code Ok(sum) } Ok(()) } The code has a specific syntax, but you get used to it very quickly. In fact, everything is the same here. Using macros, we do modinit, which does all the extra work for us to generate all sorts of bindings for Python. Remember I said, you need to do a handler wrapper, here is the same. run_py converts types, then we call native code.
As you can see, to export a function, there is syntactic sugar. We simply say that we need the add function, and do not describe any interfaces. We accept the list, which is exactly py_list, and not Object, because Rust will set up the necessary binders at compile time. If we pass the wrong data type, as in the ssh extensions, a TypeError will occur. After we got the list, we start processing it.
Let's see in more detail what he is starting to do.
#[pyfn(m, "add", py_list="*")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32> { match py_list.len() { 0 =>Err(EmptyListError::new("List is empty")), _ => { let mut sum : i32 = 0; for item in py_list.iter() { let temp:i32 = match item.extract() { Ok(v) => v, Err(_) => { let err_msg: String = format!("List item {} is not int", item); return Err(ItemListError::new(err_msg)) } }; sum += temp; } Ok(sum) } } } The same code that was on C / C ++ / Ctypes, but only now on Rust. There I tried to bring PyObject to some kind of long. So that it would be if to us in the list, besides numbers, would there be a string? Yes, we would get SystemEerror. In this case, through let mut sum : i32 = 0; we are also trying to get a value from list and bring it to i32. That is, we will not be able to write this code without item.extract (), and we can combine it to the necessary type. When we wrote i32, in case of a Rust error, at the compilation stage it will say: “Handle the case when not i32”. In this case, if we have i32, we return the value, if this is a mistake - we throw an exception.
What to choose
After this small excursion we will think about what to choose in the end?
The answer is really to your taste and color.
I will not promote any particular technology.
Just summarize:
- In the case of SWIG and C / C ++, you need to know C / C ++ very well, to understand that the development of this module will incur some additional overhead. But a minimum of tools will be used, and we will work in our native Python technology, which is supported by developers.
- In the case of Cython, we have a small entry threshold, we have a high development speed, and this is also an ordinary code generator.
- On account of CTypes, I want to caution about the relatively large overheads. Dynamic library loading, when we do not know what kind of library it is, can cause a lot of trouble.
- Rust, I would advise to take to someone who does not know C / C ++. Rust in production really has the least problems.
useful links
https://github.com/zaabjuda/moscowpythonconf2017
https://docs.python.org/3/extending/building.html
https://cython.org
https://docs.python.org/376/library/ctypes.html
https://www.swig.org
https://www.rust-land.org/en-US/
https://github.com/PyO3
https://www.youtube.com/watch?v=5-WoT4X17sk
https://packaging.python.org/tutorials/distributing-packages/#platformwheels
https://github.com/PushAMP/pamagent (combat use case)
https://docs.python.org/3/extending/building.html
https://cython.org
https://docs.python.org/376/library/ctypes.html
https://www.swig.org
https://www.rust-land.org/en-US/
https://github.com/PyO3
https://www.youtube.com/watch?v=5-WoT4X17sk
https://packaging.python.org/tutorials/distributing-packages/#platformwheels
https://github.com/PushAMP/pamagent (combat use case)
Call for Papers
We accept applications for Moscow Python Conf ++ until September 7 - write in this simple form what you know about Python that you really need to share with the community.
For those who are more interesting to listen to, I can tell you about the class reports.
- Donald Whyte loves to talk about acceleration of mathematics in Python and prepares a new story for us: how to do math 10 times faster with the help of popular libraries, cunning and cunning, and code that is understandable and supported.
- Artyom Malyshev has gathered all his many years of experience in developing Django and is presenting a report-guide on the framework! Everything that happens between receiving an HTTP request and sending a finished web page: exposing magic, a map of the internal mechanisms of the framework and a lot of useful tips for your projects.
Source: https://habr.com/ru/post/418449/
All Articles