Apollo: 9 months - normal flight
Hello everyone, my name is Semyon Levenson, I work as a teamlead on the project “ Flow ” from the Rambler Group and I want to tell you about our experience in using Apollo.
Let me explain what "flow". This is an automated service for entrepreneurs that allows you to attract clients from the Internet to your business, without getting involved in advertising, and quickly create simple websites, without being an expert in layout.
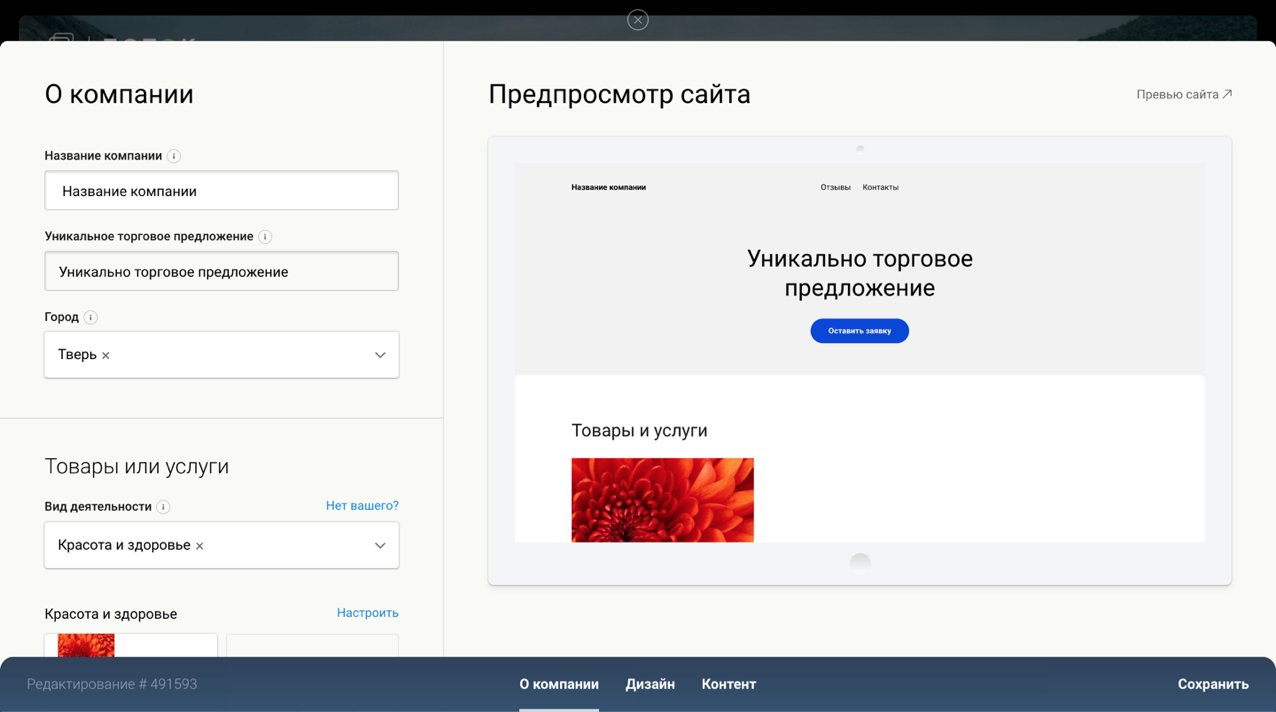
The screenshot shows one of the steps for creating a landing page.
What was at the beginning?
And in the beginning there was MVP, a lot of Twig, jQuery and very tight deadlines. But we went an unusual way and decided to make a redesign. The redesign is not in the sense of “patching styles”, but decided to revise the entire system operation. And it was for us a good stage in order to assemble the perfect frontend. After all, we, the development team, will continue to support this and implement other tasks based on this, to achieve new goals set by the product team.
Our department has already gained enough expertise in using React. I did not want to spend 2 weeks on setting up a webpack, so we decided to use the CRA (Create React App). Styles were taken for styled components , and where without typing they took Flow . For State Management they took Redux , but as a result it turned out that we don’t need it at all, but more on that later.
We gathered our perfect frontend and realized that we had forgotten about something. As it turned out, we forgot about the backend, but rather about the interaction with it. When you think about what we can use to organize this interaction, the first thing that came to mind is, of course, Rest. No, we did not go to rest (smile), but began to talk about the RESTful API. In principle, the story is familiar, it has been dragging on for a long time, but we also know problems with it. We will talk about them.
The first problem is the documentation. RESTful, of course, does not tell you how to organize the documentation. Here there is a variant of using the same swagger, but in fact it is the introduction of an additional entity and the complication of processes.
The second problem is how to organize support for versioning APIs.
The third important problem is a large number of requests or custom endpoints that we can pile on. Suppose we need to request posts, for these posts - comments and more authors of these comments. In classic Rest, we have to make 3 requests at least. Yes, we can pile up custom endpoints, and all of this is collapsed into 1 request, but this is already a complication.
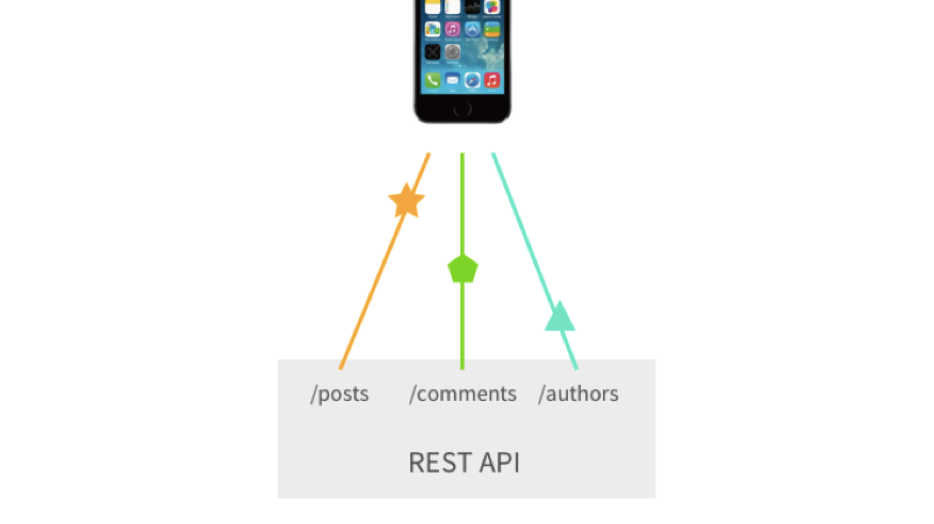
Thank you for the illustration, Sashko Stubailo
Decision
And at this moment Facebook comes to the rescue with GraphQL. What is GraphQL? This is a platform, but today we will look at one of its parts - it is Query Language for your API, just a language, and a rather primitive one. And it works as simply as possible - as we request an entity, we also get it.
Request:
{ me { id isAcceptedFreeOffer balance } } Answer:
{ "me": { "id": 1, "isAcceptedFreeOffer": false, "balance": 100000 } } But GraphQL is not only about reading, it is about changing data. For this, there are mutations in GraphQL. Mutations are notable in that we can declare the desired response from the backend, with a successful change. However, there are some nuances. For example, if our mutation affects data beyond the graph.
An example of a mutation in which we use a free offer:
mutation { acceptOffer (_type: FREE) { id isAcceptedFreeOffer } } In response, we get the same structure that was requested
{ "acceptOffer": { "id": 1, "isAcceptedFreeOffer": true } } Interaction with GraphQL backend can be accomplished using normal fetch.
fetch('/graphql', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ query: '{me { id balance } }' }) }); What are the advantages of GraphQL?
The first and very cool advantage that you can appreciate when you start working with it is that this language is strictly typed and self-documenting. When designing a GraphQL scheme on the server, we can immediately describe the types and attributes directly in the code.

As mentioned above, RESTful has a versioning problem. In GraphQL, a very elegant solution is implemented for this - deprecated.
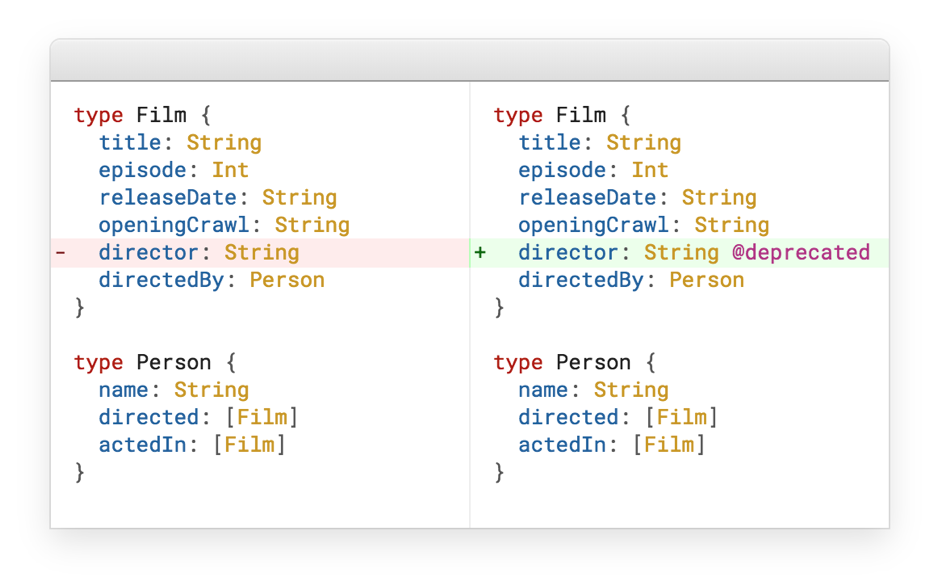
Suppose we have a Film, we expand it, so we have the director. And at some point we just take out the director in a separate type. The question arises, what to do with the last field director? There are two answers to it: either we delete this field, or we mark it deprecated, and it automatically disappears from the documentation.
Independently decide what we need.
We recall the previous picture, where everything went with us REST, here we have everything combined into one request and does not require any customization from the backend development. They once described it all, and we are already twisting, turning, juggling.
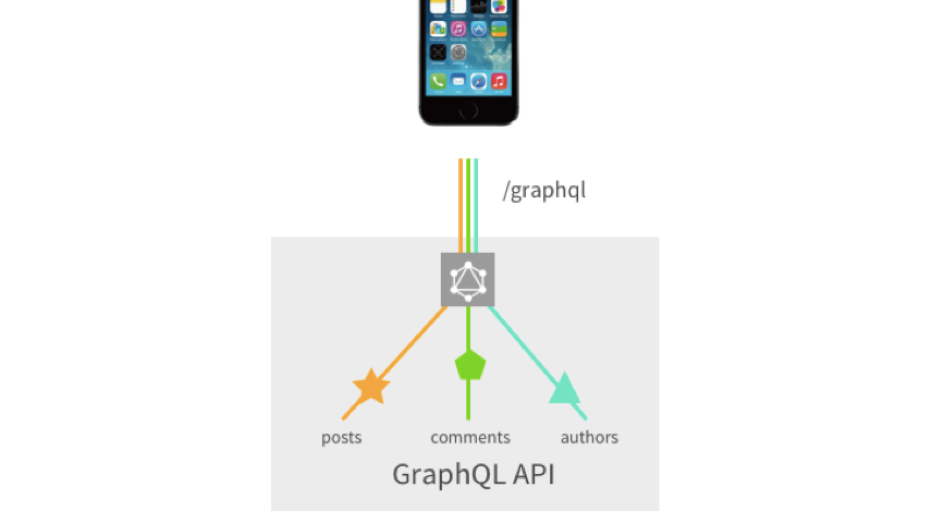
But not without a fly in the ointment. In principle, GraphQL has not so many minuses on the frontend, because it was originally designed to solve the problems of the frontend. But backend doesn't have everything as smoothly ... They have a problem like N + 1. Take for example the query:
{ landings(_page: 0, limit: 20) { nodes { id title } totalCount } } A simple request, we request 20 sites and the number of sites we have. And in the backend, this can result in 21 queries to the database. This problem is known, solved. For Node JS there is a dataloader package from Facebook. For other languages, you can find your own solutions.
There is also the problem of deep nesting. For example, we have albums, these albums have songs, and through a song we can also get albums. To do this, make the following requests:
{ album(id: 42) { songs { title artists } } } { song(id: 1337) { title album { title } } } Thus, we get a recursive query, which also elementarily lays the base for us.
query evil { album(id: 42) { songs { album { songs { album { This problem is also known, the solution for Node JS is GraphQL depth limit, for other languages there are also solutions.
Thus, we decided on GraphQL. It's time to choose a library that will work with the GraphQL API. An example of a couple of lines with the fetch shown above is only a transport. But thanks to the scheme and declarativeness, we can also cache requests on the front, and work with greater performance with the GraphQL backend.
So we have two main players - Relay and Apollo.
Relay
Relay is Facebook development, they use it themselves. Like Oculus, Circle CI, Arsti and Friday.
What are the advantages of Relay?
The immediate plus is that the developer is Facebook. React, Flow, and GraphQL are Facebook’s development, all of which are jigsaw puzzles. Where are we without stars on Github, Relay has almost 11,000, Apollo has 7600 for comparison. The cool thing Relay has is Relay-compiler, a tool that optimizes and analyzes your GraphQL queries at the build level of your project . We can assume that this uglify only for GraphQL:
# Relay-compiler foo { # type FooType id ... on FooType { # matches the parent type, so this is extraneous id } } # foo { id } What are the cons of Relay
The first minus * is the absence of SSR from the box. There is still an issue on Github. Why under the asterisk - because there are already solutions, but they are third-party, and besides, rather ambiguous.
Again, Relay is a specification. The fact is that GraphQL is already a specification, and Relay is a specification over a specification.
For example, Relay pagination is implemented differently, cursors appear here.
{ friends(first: 10, after: "opaqueCursor") { edges { cursor node { id name } } pageInfo { hasNextPage } } } We no longer use the usual offsets and limits. For feeds in the feed, this is a great topic, but when we start making all sorts of grids, then there is pain.
Facebook solved its problem by writing its own library for React. There are solutions for other libraries, for vue.js, for example - vue-relay . But if we pay attention to the number of asterisks and commit-s, then everything is also not so smooth and may be unstable. For example, the Create React App from the CRA box does not allow using Relay-compiler. But you can circumvent this limitation with the help of react-app-rewired .
Apollo
Our second candidate is Apollo . It is developed by the Meteor team. Apollo uses such well-known commands as: AirBnB, ticketmaster, Opentable, etc.
What are the advantages of Apollo
The first significant plus is that Apollo was developed as a framework agnostic library. For example, if we want to rewrite everything now on Angular, this will not be a problem, Apollo works with it. And you can even write everything on Vanilla.
Apollo has cool documentation, there are ready-made solutions for common problems.

Another plus Apollo - a powerful API. In principle, those who worked with Redux will find common approaches here: there is an ApolloProvider (as Provider for Redux), and instead of a store for Apollo, this is called a client:
import { ApolloProvider } from 'react-apollo'; import { ApolloClient } from './ApolloClient'; const App = () => ( <ApolloProvider client={ApolloClient}> ... </ApolloProvider> ); At the level of the component itself, we have provided graphql HOC, like connect. And we are already writing a GraphQL query inside, like a MapStateToProps in Redux.
import { graphql } from 'react-apollo'; import gql from 'graphql-tag'; import { Landing } from './Landing'; graphql(gql` { landing(id: 1) { id title } } `)(Landing); But when we make MapStateToProps in Redux, we take the data local. If there is no local data, then Apollo itself follows it to the server. Very convenient Props fall into the component itself.
function Landing({ data, loading, error, refetch, ...other }) { ... } It:
• data;
• download status;
• error if it occurred;
helper functions, such as refetch for reloading data or fetchMore for pagination. There is also a huge plus for both Apollo and Relay, this is the Optimistic UI. It allows you to perform undo / redo at the query level:
this.props.setNotificationStatusMutation({ variables: { … }, optimisticResponse: { … } }); For example, a user clicked the like button, and the like was immediately credited. In this case, the request to the server will be sent in the background. If some kind of error occurs during the sending process, then the changed data will return to its original state on its own.
Server side rendering is implemented well, we set one flag on the client and everything is ready.
new ApolloClient({ ssrMode: true, ... }); But here I would like to tell you about Initial State. When Apollo prepares it for himself, everything works well.
<script> window.__APOLLO_STATE__ = client.extract(); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link }); But we don’t have Server side rendering, and the backend slips a certain GraphQL query into the global variable. Here you need a small crutch, you need to write a Transform-function, which the graphQL-response from the backend will turn into the necessary format for Apollo.
<script> window.__APOLLO_STATE__ = transform({…}); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link }); Another advantage of Apollo is that it is well customized. We all remember middleware from Redux, here everything is the same, only this is called link.

I would like to separately note two links: apollo-link-state , which is needed to store the local state in the absence of Redux, and apollo-link-rest , if we want to write GraphQL queries to the Rest API. However, with the latter you need to be extremely careful, because There may be some problems.
Apollo also has disadvantages
Consider an example. There was an unexpected performance problem: they requested 2000 elements on the frontend (it was a reference book), and performance problems started. After viewing in the debugger, it turned out that Apollo ate a lot of resources on reading, the issue was basically closed, now everything is fine, but there was such a sin.
Also refetch was very unobvious ...
function Landing({ loading, refetch, ...other }) { ... } It would seem that when we do a re-request of data, especially if the previous request was completed with an error, then loading should become true. But no!
In order for this to be, you need to specify notifyOnNetworkStatusChange: true in the graphql HOC, or store the state's refetch.
Apollo vs. Relay
Thus, we got such a table, we all weighed, calculated, and we have 76% turned out for Apollo.
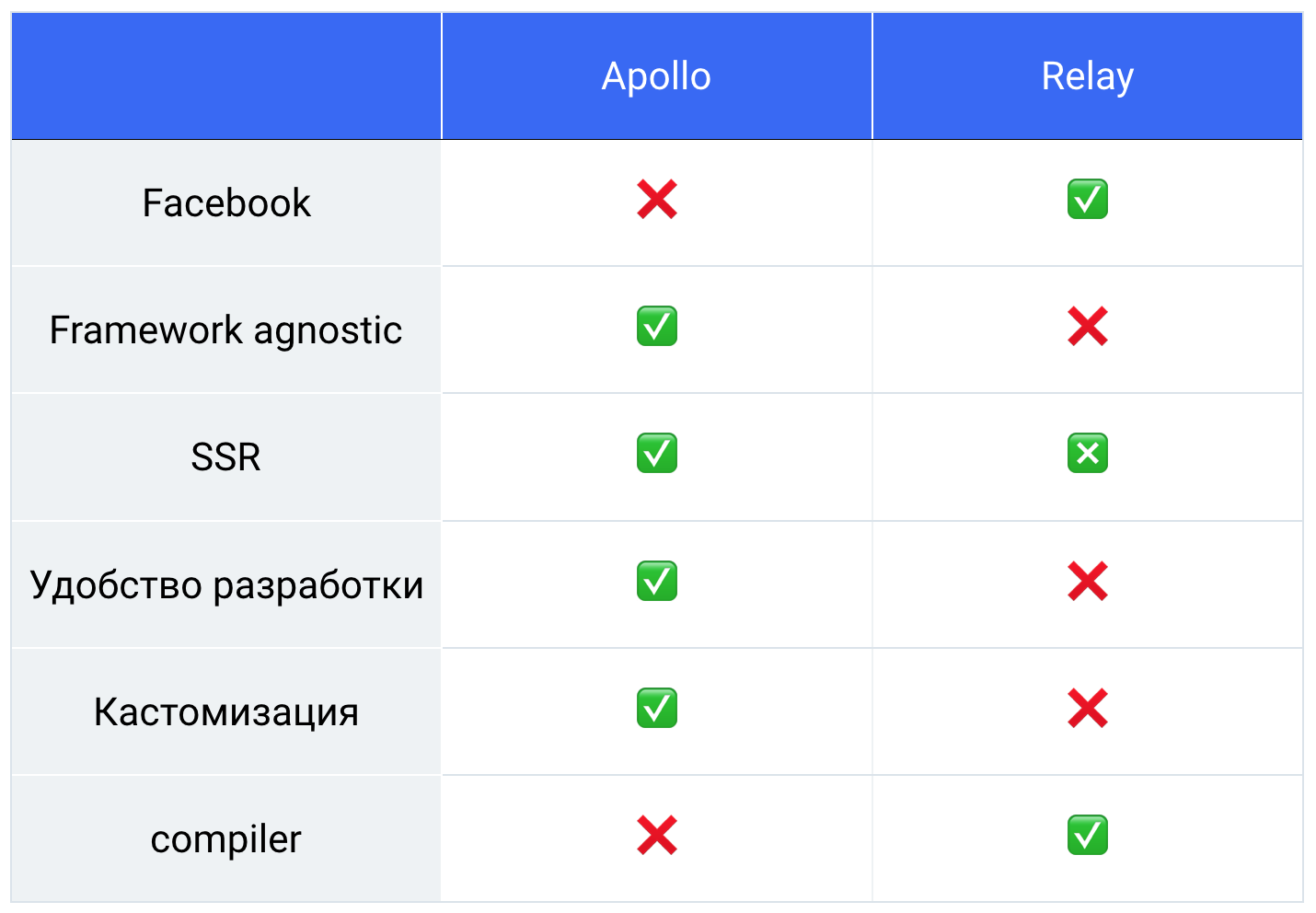
So we chose a library and went to work.
But I would like to say more about the toolchain.
Everything is very good here, there are various additions for editors, somewhere better, somewhere worse. There is also apollo-codegen, which generates useful files, for example, flow-types, and basically pulls the circuit out of the GraphQL API.
Rubric "crazy hands" or what we have done
The first thing we encountered was that, in principle, we need to somehow request data.
graphql(BalanceQuery)(BalanceItem); We have common states: loading, error handling. We wrote our hock (asyncCard), which is connected via the composition graqhql and asyncCard.
compose( graphql(BalanceQuery), AsyncCard )(BalanceItem); I would like to tell you more about the fragments. There is a LandingItem component and it knows what data it needs from the GraphQL API. We set the fragment property where we specified the fields from the Landing entity.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... } `; Now, at the component usage level, we use its fragment in the final query.
query LandingsDashboard { landings(...) { nodes { ...LandingItem } totalCount } ${LandingItem.Fragment} } And let's say a task arrives to us to add status to this landing page - not a problem. We add a property to the render and in the fragment. And everything is ready. Single responsibility principle in all its glory.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … <LandingItemStatus … /> </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... status } `; What was our problem?
We have a number of widgets on our site that made their own separate requests.
During testing, it turned out that all this slows down. We have very long security checks, and every request is very expensive. It was also not a problem, there is Apollo-link-batch-http
new BatchHttpLink({ batchMax: 10, batchInterval: 10 }); It is configured as follows: we transmit the number of requests that we can combine and how long this link will wait for the first request.
And it turned out like this: at the same time everything is loading, and at the same time everything comes. It should be noted that if during this merging one of the subqueries returns with an error, then only he will have an error, and not the entire query.
I would like to tell you separately that last autumn there was an update from the first Apollo to the second
First was Apollo and Redux
'react-apollo' 'redux' Then Apollo became more modular and expandable, these modules can be developed independently. The same apollo-cache-inmemory.
'react-apollo' 'apollo-client' 'apollo-link-batch-http' 'apollo-cache-inmemory' 'graphql-tag' It is worth noting that there is no Redux, and as it turned out, it is, in principle, not needed.
Findings:
- Feature-delivery time has decreased with us, we do not waste time on the description of action, reduce in Redux, and less touch the backend
- Appeared anti-fragility, because Static API analysis reduces problems to zero when the frontend expects one thing and the backend gives up something completely different.
- If you start working with GraphQL, try Apollo, you will not be disappointed.
PS You can also watch the video from my presentation on Rambler Front & Meet up # 4
')
Source: https://habr.com/ru/post/418417/
All Articles