RabbitMQ vs. Kafka: Kafka application in event-oriented applications
In the previous article, we looked at patterns and topologies used in RabbitMQ. In this section, we turn to Kafka and compare it with RabbitMQ to get some insight into their differences. It should be borne in mind that the architecture of event-oriented applications will be compared rather than the data processing pipelines, although the line between these two concepts will be rather blurred in this case. In general, this is more of a spectrum than a clear separation. Simply, our comparison will focus on the part of this spectrum associated with event-driven applications.

The first difference that comes to mind is that the replay and snooze mechanisms used in RabbitMQ to work with undelivered messages in Kafka do not make sense. In RabbitMQ messages are temporary, they are transmitted and disappear. Therefore, their re-addition is absolutely real juz-case. And in Kafka the magazine takes the central place. Solving problems of delivery through re-sending a message to the queue does not make sense and only hurts the magazine. One of the advantages lies in the guaranteed clear distribution of messages by the log partitions, repeated messages confuse a coherent scheme. In RabbitMQ, you can send already sent messages to a queue with which one recipient works, and on the Kafka platform there is one journal for all recipients. Delay in delivery and problems with the delivery of messages do not represent a great harm to the work of the magazine, but Kafka does not contain any built-in delay mechanisms.
How to re-deliver messages on the Kafka platform will be discussed in the section on messaging schemes.
The second big difference affecting possible messaging schemes is that messages are stored in RabbitMQ significantly less than in Kafka. When a message has already been delivered to the recipient in RabbitMQ, it is deleted, leaving no trace of its existence. In Kafka, every message is kept in a log until it is cleared. The frequency of cleanings depends on the amount of data available, the amount of disk space that is planned for them to allocate, and the messaging schemes that need to be provided. You can use the time window in which we store messages for a specified period of time: the last few days / weeks / months.
Thus, Kafka allows the recipient to review or re-receive the old messages again. It looks like a technology of re-sending messages, although it does not work quite like in RabbitMQ.
If RabbitMQ moves messages and gives powerful elements to create complex routing schemes, Kafka retains the current and previous state of the system. This platform can be used as a source of reliable historical data because RabbitMQ cannot.
Sample messaging scheme on the Kafka platform
The simplest example of the use of both RabbitMQ and Kafka is the dissemination of information under the publisher-subscriber scheme. One or several publishers add messages to a partinged log, and these messages are received by the subscriber of one or several groups of subscribers.

Figure 1. Several publishers send messages to a partitioned log, and they are received by several groups of recipients.
If you don’t go into details about how the publisher sends messages to the right sections of the journal, and how the recipient groups are coordinated among themselves, this scheme does not differ from the fanout topology (branching exchange), which is used in RabbitMQ.
In the previous article, all RabbitMQ messaging topologies and messaging topologies were reviewed. Perhaps at some point you thought “I don’t need all these difficulties, I just want to send and receive messages in the queue,” and the fact that it was possible to rewind the magazine to previous positions spoke about the obvious advantages of Kafka.
People who are accustomed to the traditional features of the queue systems, the fact that it is possible to turn the clock back and wind the event log into the past is shocking. This property (made available by using the log instead of the queue) is very useful for recovering from failures. I (the author of the English article) started working for my current client 4 years ago as a technical leader of the server system support group. We had more than 50 applications that received information about business events in real time via MSMQ, and the usual thing was that when an error occurred in the application, the system only detected it the next day. Unfortunately, the messages often disappeared as a result, but usually we managed to get the source data from a third-party system and send messages only to the “subscriber” who had a problem. This required us to create a messaging infrastructure for recipients. And if we had the Kafka platform, it would have been no more difficult to do this work than to change the link to the location of the last message received for the application in which the error occurred.
Data Integration in Event-Oriented Applications and Systems
This scheme is largely a means of generating events, although not related to one application. There are two levels of event generation: software and system. This scheme is associated with the latter.
Program level of event generation
The application manages its own state through an immutable sequence of change events that are stored in the event store. In order to get the current state of the application, you must play or combine its events in the correct sequence. Usually in such a model, the CQRS Kafka model can be used as this system.
Interaction between applications at the system level.
Applications or services can manage their state in any way that their developer wishes to manage, for example, in a regular relational database.
But applications often need data about each other, which leads to non-optimal architectures, for example, common databases, blurred entity boundaries or inconvenient REST APIs.
I (the author of the English article) listened to the podcast “ Software Engineering Daily ”, which describes an event-oriented script for a social media profile service. There are a number of related services in the system, such as a search, a system of social graphs, a recommendation engine, etc., all of them need to know about the change in the status of a user profile. When I (the author of the English articles) worked as an architect for the air transport system, we had two large software systems with a myriad of associated small services. Auxiliary services required data on orders and flights. Every time an order was created or changed, when a flight was delayed or canceled, these services had to be activated.
Here the technique of generating events was required. But first we will look at some common problems that arise in large software systems, and see how event generation can solve them.
A large integrated corporate system usually develops organically; there are migrations to new technologies and new architectures that may not affect 100% of the system. Data is distributed across different parts of an institution, applications open databases for public use so that integration happens as quickly as possible, and no one can predict with certainty how all elements of the system will interact.
Out of order data distribution
Data is distributed in different places and managed in different places, so it is difficult to understand:
- how data moves in business processes;
- how changes in one part of the system may affect other parts;
- what to do with data conflicts, which arise from the fact that there are many copies of data that spread slowly.
If there are no clear boundaries of domain entities, the changes will be expensive and risky, since they affect many systems at once.
Centralized Distributed Database
An open database can cause several problems:
- It is not optimized enough for each application separately. Most likely, this database stores an unnecessarily complete data set for the application, moreover, it is normalized in such a way that applications will have to run very complex queries to get them.
- Using a common database application can affect each other's work.
- Changes in the logical structure of the database require large-scale approvals and work on data migration, and the development of individual services will be stopped for the entire process.
- No one wants to change the storage structure. The changes that everyone is waiting for are too painful.
Using inconvenient REST API
Getting data from other systems through the REST API on the one hand adds convenience and isolation, but still may not always be successful. Each such interface can have its own particular style and its own conventions. Obtaining the necessary data may require a lot of HTTP requests and be quite complex.
We are moving more and more towards API centricity, and such architectures offer many advantages, especially when the services themselves are beyond our control. There are currently so many convenient ways to create an API that we should not write as much code as was required before. But it’s still not the only available tool, and there are alternatives to the internal system architecture.
Kafka as an event store
Let's give an example. There is a system that manages bookings in a relational database. The system uses all the guarantees of atomicity, consistency, isolation and durability offered by the database in order to effectively manage its characteristics and everyone is satisfied. The division of responsibility into teams and requests, the generation of events, microservices are absent, in general a traditionally constructed monolith. But there are a myriad of support services (possibly microservices) associated with the booking: push notifications, e-mail sending, anti-fraud system, loyalty program, billing, reservation cancellation system, etc. The list goes on and on. All of these services require booking information, and there are many ways to get it. These services themselves produce data that may be useful to other applications.

Figure 2. Different types of data integration.
Alternative architecture based on Kafka. With each new reservation or change of previous reservation, the system sends the full data on the current status of this reservation to Kafka. By compacting the log, you can shorten the messages so that only information on the latest reservation status is left in it. In this case, the size of the journal will be under control.
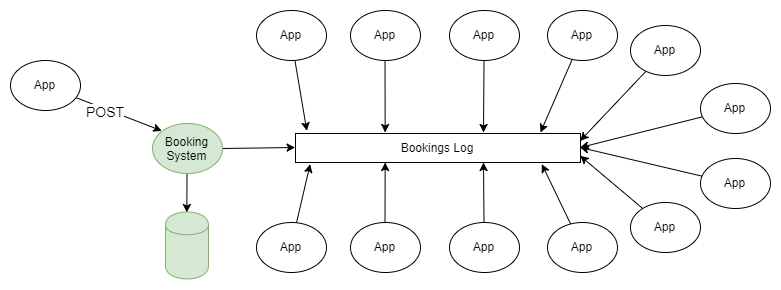
Figure 3. Kafka-based data integration as the basis for event generation.
For all applications for which this information is necessary, this is the source of truth and the only source of data. Suddenly, we are moving from a complex network of dependencies and technologies to sending and receiving data to / from Kafka topics.
Kafka as an event store:
- If there are no problems with disk space, Kafka can store the entire event history, that is, a new application can be deployed and download all the necessary information from the log. Records of events that fully reflect the characteristics of objects can be compressed by condensing the journal, which will make this approach more justified for many scenarios.
- What if events need to be played in the correct order? As long as the event records are properly distributed, you can set the order of their playback and apply filters, conversion tools, etc., so that the data will always end with the necessary information. Depending on the possibility of data distribution, it is possible to ensure their highly parallel processing in the correct order.
- It may be necessary to change the data model. When creating a new filter / transforming function, it may be necessary to play back the recordings of all events or events in the last week.
Messages can come to Kafka not only from applications of your organization that send messages about all changes in their characteristics (or the results of these changes), but also from third-party services integrated with your system. This happens in the following ways:
- Periodic export, transfer, import of data received from third-party services, and their loading on Kafka.
- Download data from third-party services in Kafka.
- Data from CSV and other formats downloaded from third-party services are loaded into Kafka.
Let us return to the questions that we considered earlier. Kafka-based architecture simplifies data distribution. We know where the source of truth is, we know where its data sources are, and all target applications work with copies that are derived from this data. The data goes from the sender to the recipients. The source data belong only to the sender, but others are free to work with their projections. They can filter them, transform them, supplement them with data from other sources, and store them in their own databases.
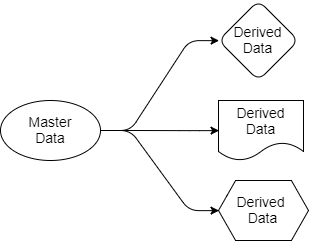
Figure 4. Source and Output
Each application that requires booking data and flights will receive it itself, because it is “subscribed” to those sections of Kafka that contain this data. For this, applications can use SQL, Cypher, JSON, or any other query language. The application can then save the data in its system as it is convenient for it. The data distribution scheme can be changed without affecting the operation of other applications.
The question may arise: why all this can not be done with the help of RabbitMQ? The answer is that RabbitMQ can be used to process events in real time, but not as a basis for generating events. RabbitMQ is a complete solution only to respond to events that are happening now. When a new application is added that requires its own portion of the reservation data presented in a format optimized for the tasks of this application, RabbitMQ will not be able to help. With RabbitMQ, we return to shared databases or the REST API.
Secondly, the order of event handling is important. If you work with RabbitMQ, if you add a second recipient to the queue, the order of observance of the order is lost. Thus, the correct order of sending messages is observed only for one recipient, but this, of course, is not enough.
Kafka, by contrast, can provide all the data that this application requires in order to create its own copy of the data and keep the data up-to-date, and at the same time Kafka respects the order of sending messages.
Now back to API-centric architectures. Are these interfaces always the best choice? When I want to share data read-only, I would prefer an event-generating architecture. It will prevent cascading failures and a reduction in service life, coupled with an increase in the number of dependencies on other services. There will be more opportunities for creative and efficient organization of data within systems. But sometimes it is required to synchronously change the data in one's own, and in another system, and in such a situation API-centric systems will be useful. Many prefer them to other asynchronous methods. I think this is a matter of taste.
Applications that are sensitive to high traffic and event processing.
Not so long ago, a problem arose with one of the recipients of RabbitMQ, who received the files queued up from a third-party service. The total file size was large, and the application was specifically configured to receive this amount of data. The problem was that the data were inconsistent, it created many problems.
In addition, sometimes there was a problem that sometimes two files were meant for one addressee, and their arrival time was different for a few seconds. Both of them were processed and had to be uploaded to one server. And after the second message was recorded on the server, the first message following it overwritten the second one. Thus, it all ended in the preservation of incorrect data. RabbitMQ performed its role and sent messages in the correct order, but all the same, everything ended in the wrong order in the application itself.
This problem was solved by reading the timestamp from the existing records and the lack of response in case the message was old. In addition, during data exchange, consistent hashing was applied, and the queue was split, as with the same partitioning on the Kafka platform.
As part of the partition, Kafka stores messages in the order in which they were sent to it. The order of messages exists only within the limits of a partition. Kafka id , . , , . , . Simple and effective.
Kafka RabbitMQ , . RabbitMQ , , . RabbitMQ , . Kafka . , , .
Kafka . , id 1001 3. 1001 3, 3 , , . , .. . — - .
Kafka ? , Kafka . , : 10, 9 . , , . 1, , , . Kafka , .
, . , . , . 1001 4 ( 1001 ).
. , .
')
Source: https://habr.com/ru/post/418389/
All Articles