How the CPU Manager in Kubernetes works
Note trans. : This article was published on the official Kubernetes blog and was written by two Intel employees who are directly involved in the development of the CPU Manager — a new feature in Kubernetes, which we wrote about in the release 1.8 review. At the moment (ie, for K8s 1.11), this feature has the status of a beta version, and read more about its purpose later in the article.
The publication is about the CPU Manager - a beta feature in Kubernetes. CPU Manager allows you to better distribute workloads in Kubelet, i.e. on the Kubernetes node agent, by assigning the allocated CPUs to the specific hearth containers.
')
Depends on workload. A single compute node in a Kubernetes cluster can run multiple hearths, and some of them can run loads that are active in CPU consumption. In this scenario, hearths can compete for the process resources available on this node. When this competition escalates, the workload may move to other CPUs depending on whether it was throttled under and what CPUs are available at the time of planning. In addition, there may be cases where the workload is sensitive to context switches. In all of these scenarios, workload performance may suffer.
If your workload is sensitive to such scenarios, you can enable CPU Manager to provide better performance isolation by allocating specific CPUs to the load.
CPU Manager can help loads with the following characteristics:
Using CPU Manager is easy. First, turn it on using the Kubelet Static Policy running on the cluster's compute nodes. Then set the guaranteed Guaranteed Quality of Service (QoS) class for the hearth. Request an integer number of CPU cores (for example,
BOM specification requesting 2 dedicated CPUs.
We consider three types of control of CPU resources available in most Linux distributions, which will be relevant in relation to Kubernetes and the actual purposes of this publication. The first two are CFS shares (what is my weighted "fair" share of CPU time in the system) and CFS quota (what is the maximum CPU time allocated to me for the period). CPU Manager also uses the third one, which is called CPU affinity (on which logical CPUs I am allowed to perform calculations).
By default, all runs and containers running on the Kubernetes cluster node can run on any available system kernels. The total number of shares to be assigned and quota are limited by the CPU resources reserved for Kubernetes and system daemons . However, the limits on the CPU time used can be determined using the limits on the CPU in the heart rate specification . Kubernetes uses the CFS quota to enforce CPU limits on the pod containers.
When you turn on the CPU Manager with the Static policy, it manages the allocated CPU pool. Initially this pool contains all the CPUs of the compute node. When Kubelet creates a container in the hearth with a guaranteed number of dedicated processor cores, the CPUs assigned to this container are allocated to it for the duration of its life and removed from the shared pool. The loads from the remaining containers are transferred from these dedicated cores to others.
All containers without dedicated CPUs ( Burstable , BestEffort, and Guaranteed with non-integer CPUs ) run on the cores remaining in the shared pool. When a container with a dedicated CPU stops working, its cores are returned to the shared pool.

The above diagram demonstrates the anatomy of the CPU Manager. It uses the
The CPU Manager uses Policies to decide whether to assign CPU cores. Implemented two policies: None and Static . By default, starting with Kubernetes 1.10, it is included with the None policy.
The Static policy assigns dedicated pods to pod containers with a guaranteed QoS class that requests an integer number of cores. The Static policy attempts to assign the CPU in the best topological manner and in the following sequence:
With Static policy enabled in CPU Manager, workloads may show better performance for one of the following reasons:
In order to see the performance improvements and isolation provided by the inclusion of the CPU Manager in Kubelet, we conducted experiments on a compute node with two sockets (Intel Xeon CPU E5-2680 v3) and hyperthreading turned on. A node consists of 48 logical CPUs (24 physical cores, each with hyperthreading). The following shows the benefits of CPU Manager in performance and isolation, fixed by benchmarks and real-world workloads in three different scenarios.
For each scenario, graphs ( span diagrams , box plots) are shown illustrating the normalized execution time and its variability when starting the benchmark or the real load with the CPU Manager turned on and off. Executable time is normalized to best performance starts (1.00 on the Y axis represents the best start time: the smaller the graph value, the better). The height of the plot on the graph shows the variation in performance. For example, if a segment is a line, then there is no performance variation for these launches. At these sites themselves, the median line is the median, the upper one is the 75th percentile, and the lower one is the 25th percentile. The height of the segment (i.e., the difference between the 75th and 25th percentiles) is defined as the interquartile interval (IQR). "Whiskers" show data outside this interval, and the points show the outliers. Emissions are defined as any data that is 1.5 times different from IQR - less or more than the corresponding quartile. Each experiment was conducted 10 times.
We launched six benchmarks from the PARSEC suite (workloads “victims”) [for more details about victim workloads, you can read, for example, here - approx. trans. ] adjacent to the CPU-loading container (“aggressor” workload) with the CPU Manager on and off.
The aggressor container was launched as a Burstable QoS class, requesting 23 CPUs with the

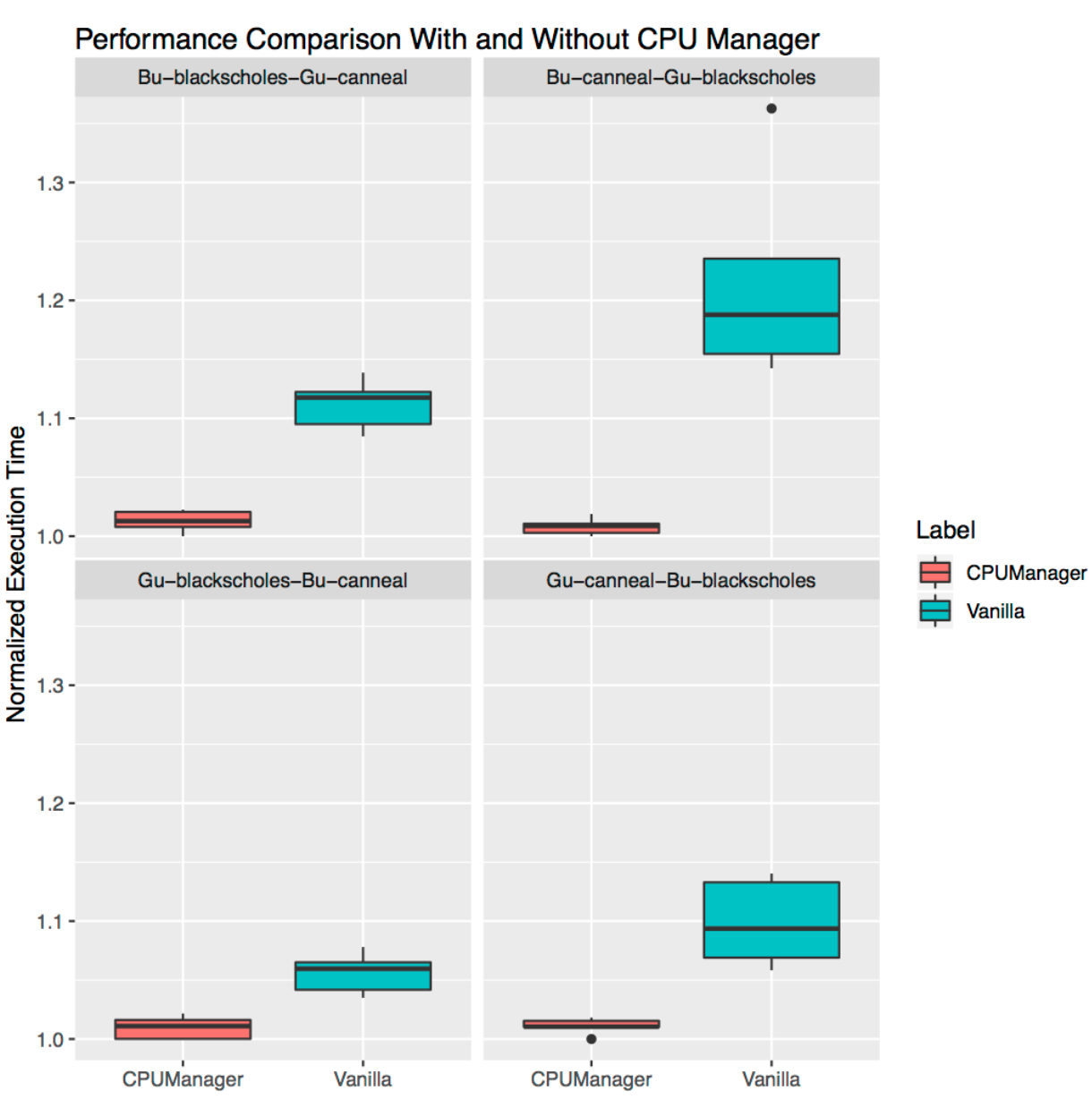
This demonstrates how CPU Manager can be useful in the case of many co-located workloads. The span diagrams below show the performance of two benchmarks from the PARSEC suite ( Blackscholes and Canneal ) running for the QoS classes Guaranteed (Gu) and Burstable (Bu), adjacent to each other, with Static turned on and off.
Following clockwise from the top left chart, we see Blackscholes performance for Bu QoS (top left), Canneal for Bu QoS (top right), Canneal for Gu QoS (bottom right), and Blackscholes for Gu QoS (bottom left). On each of the graphs, they are located (again we go clockwise) together with Canneal for Gu QoS (upper left), Blackscholes for Gu QoS (upper right), Blackscholes for Bu QoS (lower right) and Canneal for Bu QoS (lower left) respectively. For example, a Bu-blackscholes-Gu-canneal (top left) chart shows performance for Blackscholes running from Bu QoS and located next to Canneal with a Gu QoS class. In each case, the Gu QoS class requires a full socket core (that is, 24 CPUs), while the Bu QoS class requires 23 CPUs.
There is better performance and less variation in performance for both adjacent workloads in all tests. For example, look at the Bu-blackscholes-Gu-canneal (top left) and Gu-canneal-Bu-blackscholes (bottom right). They show the performance of simultaneously running Blackscholes and Canneal with the CPU Manager turned on and off. In this case, Canneal receives more dedicated cores from the CPU Manager, since it belongs to the Gu QoS class and requests an integer number of CPU cores. However, Blackscholes also gets a dedicated set of CPUs, since this is the only workload in the shared pool. As a result, both Blackscholes and Canneal take advantage of the isolation of loads in the case of CPU Manager.
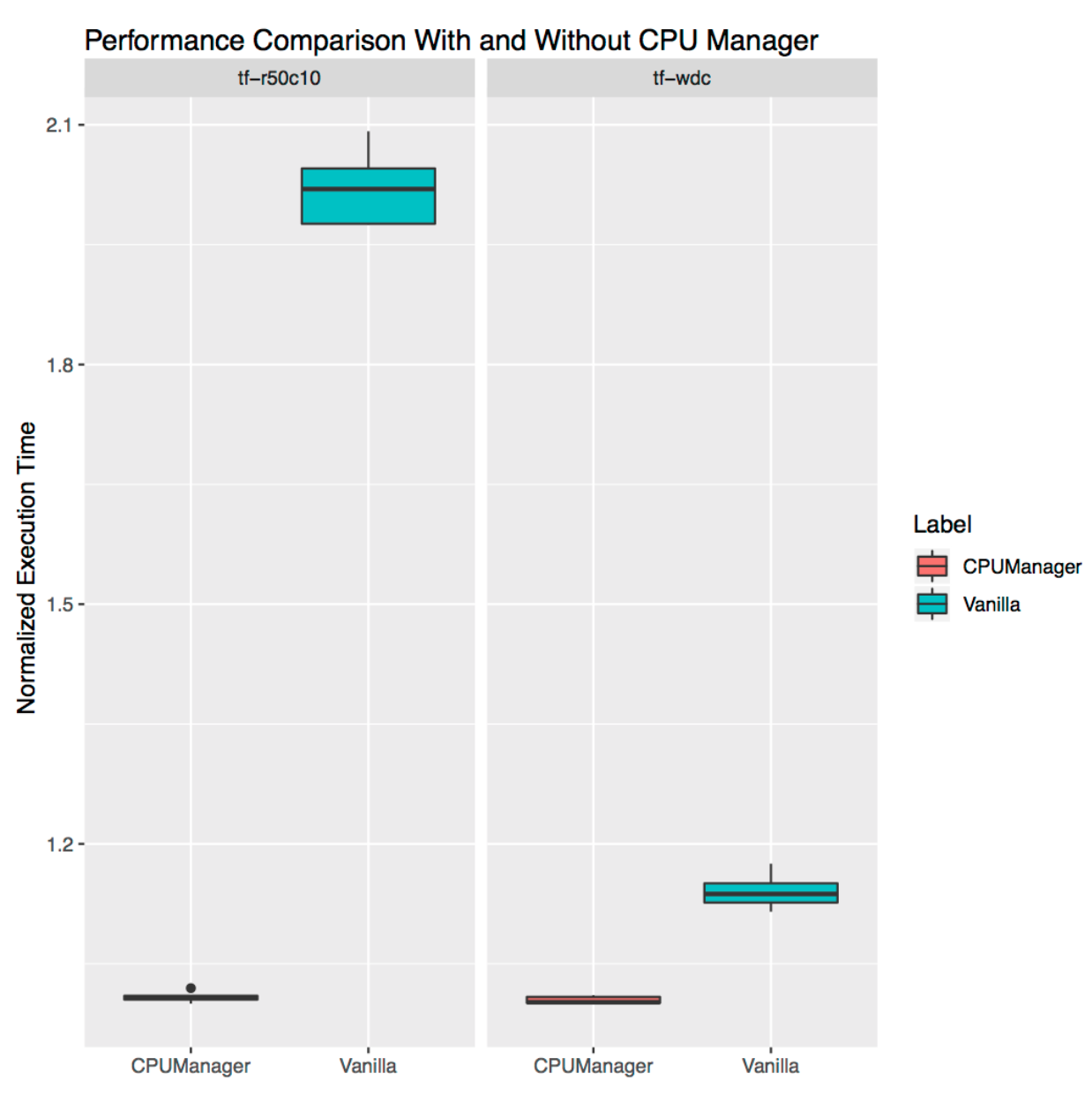
This demonstrates how CPU Manager can be useful for freestanding real-life workloads. We took two loads from the official TensorFlow models : wide and deep and ResNet . For them, typical data sets are used (census and CIFAR10, respectively). In both cases, pods ( wide and deep , ResNet ) require 24 CPUs, which corresponds to a full socket. As shown in the graphs, in both cases, the CPU Manager provides better isolation.
Users may want to get CPUs allocated on a socket close to the bus connecting to an external device such as an accelerator or high-performance network card in order to avoid traffic between the sockets. This type of configuration is not yet supported in the CPU Manager. Since the CPU Manager provides the best possible distribution of CPUs belonging to a socket or physical core, it is sensitive to extreme cases and can lead to fragmentation. The CPU Manager does not take into account the
Read also in our blog:
The publication is about the CPU Manager - a beta feature in Kubernetes. CPU Manager allows you to better distribute workloads in Kubelet, i.e. on the Kubernetes node agent, by assigning the allocated CPUs to the specific hearth containers.
')
Sounds great! But will the CPU Manager help me?
Depends on workload. A single compute node in a Kubernetes cluster can run multiple hearths, and some of them can run loads that are active in CPU consumption. In this scenario, hearths can compete for the process resources available on this node. When this competition escalates, the workload may move to other CPUs depending on whether it was throttled under and what CPUs are available at the time of planning. In addition, there may be cases where the workload is sensitive to context switches. In all of these scenarios, workload performance may suffer.
If your workload is sensitive to such scenarios, you can enable CPU Manager to provide better performance isolation by allocating specific CPUs to the load.
CPU Manager can help loads with the following characteristics:
- CPU-sensitive throttling;
- context sensitive;
- CPU-sensitive cache miss;
- benefit from the sharing of processor resources (for example, data and instruction caches);
- memory sensitive traffic between processor sockets (a detailed explanation of what the authors mean is given on the Unix Stack Exchange - approx. transl. ) ;
- hyperthreads sensitive to or requiring the same physical core of the CPU.
OK! How to use it?
Using CPU Manager is easy. First, turn it on using the Kubelet Static Policy running on the cluster's compute nodes. Then set the guaranteed Guaranteed Quality of Service (QoS) class for the hearth. Request an integer number of CPU cores (for example,
1000m or 4000m ) for containers that need dedicated cores. Create under the previous method (for example, kubectl create -f pod.yaml ) ... and voila - the CPU Manager will assign the dedicated processor cores to each sub-container in accordance with their needs for the CPU. apiVersion: v1 kind: Pod metadata: name: exclusive-2 spec: containers: - image: quay.io/connordoyle/cpuset-visualizer name: exclusive-2 resources: # Pod is in the Guaranteed QoS class because requests == limits requests: # CPU request is an integer cpu: 2 memory: "256M" limits: cpu: 2 memory: "256M" BOM specification requesting 2 dedicated CPUs.
How does the CPU Manager work?
We consider three types of control of CPU resources available in most Linux distributions, which will be relevant in relation to Kubernetes and the actual purposes of this publication. The first two are CFS shares (what is my weighted "fair" share of CPU time in the system) and CFS quota (what is the maximum CPU time allocated to me for the period). CPU Manager also uses the third one, which is called CPU affinity (on which logical CPUs I am allowed to perform calculations).
By default, all runs and containers running on the Kubernetes cluster node can run on any available system kernels. The total number of shares to be assigned and quota are limited by the CPU resources reserved for Kubernetes and system daemons . However, the limits on the CPU time used can be determined using the limits on the CPU in the heart rate specification . Kubernetes uses the CFS quota to enforce CPU limits on the pod containers.
When you turn on the CPU Manager with the Static policy, it manages the allocated CPU pool. Initially this pool contains all the CPUs of the compute node. When Kubelet creates a container in the hearth with a guaranteed number of dedicated processor cores, the CPUs assigned to this container are allocated to it for the duration of its life and removed from the shared pool. The loads from the remaining containers are transferred from these dedicated cores to others.
All containers without dedicated CPUs ( Burstable , BestEffort, and Guaranteed with non-integer CPUs ) run on the cores remaining in the shared pool. When a container with a dedicated CPU stops working, its cores are returned to the shared pool.
More detail, please ...
The above diagram demonstrates the anatomy of the CPU Manager. It uses the
UpdateContainerResources method from the Container Runtime Interface (CRI) interface to change the CPUs on which the containers run. The manager periodically cgroupfs to cgroupfs current state ( State ) of the CPU resources for each running container.The CPU Manager uses Policies to decide whether to assign CPU cores. Implemented two policies: None and Static . By default, starting with Kubernetes 1.10, it is included with the None policy.
The Static policy assigns dedicated pods to pod containers with a guaranteed QoS class that requests an integer number of cores. The Static policy attempts to assign the CPU in the best topological manner and in the following sequence:
- Assign all CPUs of a single processor socket, if available, and the container requires a CPU of at least the entire CPU socket.
- Assign all logical CPUs (hyperthreads) of a single physical CPU core, if they are available and the container requires a CPU of at least the entire core.
- Assign any available logical CPUs with a preference for CPUs from a single socket.
How does the CPU Manager improve the isolation of computing?
With Static policy enabled in CPU Manager, workloads may show better performance for one of the following reasons:
- Dedicated CPUs can be assigned to a container with a workload, but not other containers. These (other) containers do not use the same CPU resources. As a result, we expect better performance due to isolation in cases of an “aggressor” (demanding of CPU resources - approx. Transl. ) Or an adjacent workload.
- The competition for the resources used by the workload is reduced, since we can divide the CPU by the load itself. These resources can include not only the CPU, but also cache hierarchies, and memory bandwidth. This improves the overall performance of the workloads.
- CPU Manager assigns CPUs in topological order based on the best available options. If the whole socket is free, it will assign all of its CPUs to the workload. This improves the performance of the workload due to the absence of traffic between the sockets.
- Containers in sills with guaranteed QoS are subject to CFS quota restrictions. Workloads that are prone to sudden surges can be planned and exceed their quota before the end of their allotted period, as a result of which they are repaid (throttled) . The CPUs involved at this time can have both significant and not very useful work. However, such containers will not be subject to CFS throttling, when the CPU quota is supplemented by the allocation policy of the allocated CPUs.
OK! Do you have any results?
In order to see the performance improvements and isolation provided by the inclusion of the CPU Manager in Kubelet, we conducted experiments on a compute node with two sockets (Intel Xeon CPU E5-2680 v3) and hyperthreading turned on. A node consists of 48 logical CPUs (24 physical cores, each with hyperthreading). The following shows the benefits of CPU Manager in performance and isolation, fixed by benchmarks and real-world workloads in three different scenarios.
How to interpret graphics?
For each scenario, graphs ( span diagrams , box plots) are shown illustrating the normalized execution time and its variability when starting the benchmark or the real load with the CPU Manager turned on and off. Executable time is normalized to best performance starts (1.00 on the Y axis represents the best start time: the smaller the graph value, the better). The height of the plot on the graph shows the variation in performance. For example, if a segment is a line, then there is no performance variation for these launches. At these sites themselves, the median line is the median, the upper one is the 75th percentile, and the lower one is the 25th percentile. The height of the segment (i.e., the difference between the 75th and 25th percentiles) is defined as the interquartile interval (IQR). "Whiskers" show data outside this interval, and the points show the outliers. Emissions are defined as any data that is 1.5 times different from IQR - less or more than the corresponding quartile. Each experiment was conducted 10 times.
Protection against load aggressors
We launched six benchmarks from the PARSEC suite (workloads “victims”) [for more details about victim workloads, you can read, for example, here - approx. trans. ] adjacent to the CPU-loading container (“aggressor” workload) with the CPU Manager on and off.
The aggressor container was launched as a Burstable QoS class, requesting 23 CPUs with the
--cpus 48 flag. Benchmarks are run as pods with the QoS class Guaranteed , requiring a set of CPUs from a full socket (that is, 24 CPUs on this system). The graphs below show the normalized launch time for the poda with the benchmark next to the aggressor hearth, with and without the Static policy of the CPU Manager. In all test cases, you can see improved performance and reduced variability in performance when policies are enabled.Isolation for adjacent loads
This demonstrates how CPU Manager can be useful in the case of many co-located workloads. The span diagrams below show the performance of two benchmarks from the PARSEC suite ( Blackscholes and Canneal ) running for the QoS classes Guaranteed (Gu) and Burstable (Bu), adjacent to each other, with Static turned on and off.
Following clockwise from the top left chart, we see Blackscholes performance for Bu QoS (top left), Canneal for Bu QoS (top right), Canneal for Gu QoS (bottom right), and Blackscholes for Gu QoS (bottom left). On each of the graphs, they are located (again we go clockwise) together with Canneal for Gu QoS (upper left), Blackscholes for Gu QoS (upper right), Blackscholes for Bu QoS (lower right) and Canneal for Bu QoS (lower left) respectively. For example, a Bu-blackscholes-Gu-canneal (top left) chart shows performance for Blackscholes running from Bu QoS and located next to Canneal with a Gu QoS class. In each case, the Gu QoS class requires a full socket core (that is, 24 CPUs), while the Bu QoS class requires 23 CPUs.
There is better performance and less variation in performance for both adjacent workloads in all tests. For example, look at the Bu-blackscholes-Gu-canneal (top left) and Gu-canneal-Bu-blackscholes (bottom right). They show the performance of simultaneously running Blackscholes and Canneal with the CPU Manager turned on and off. In this case, Canneal receives more dedicated cores from the CPU Manager, since it belongs to the Gu QoS class and requests an integer number of CPU cores. However, Blackscholes also gets a dedicated set of CPUs, since this is the only workload in the shared pool. As a result, both Blackscholes and Canneal take advantage of the isolation of loads in the case of CPU Manager.
Insulation for separately standing loads
This demonstrates how CPU Manager can be useful for freestanding real-life workloads. We took two loads from the official TensorFlow models : wide and deep and ResNet . For them, typical data sets are used (census and CIFAR10, respectively). In both cases, pods ( wide and deep , ResNet ) require 24 CPUs, which corresponds to a full socket. As shown in the graphs, in both cases, the CPU Manager provides better isolation.
Restrictions
Users may want to get CPUs allocated on a socket close to the bus connecting to an external device such as an accelerator or high-performance network card in order to avoid traffic between the sockets. This type of configuration is not yet supported in the CPU Manager. Since the CPU Manager provides the best possible distribution of CPUs belonging to a socket or physical core, it is sensitive to extreme cases and can lead to fragmentation. The CPU Manager does not take into account the
isolcpus Linux kernel isolcpus , although it is used as a popular practice for some cases (for more information about this parameter, see, for example, here - note transl. ) .PS from translator
Read also in our blog:
- “What happens in Kubernetes when starting the kubectl run?”: Part 1 and part 2 ;
- “ How does the Kubernetes scheduler actually work? ";
- " Kubernetes: the life of the hearth ";
- " CRI-O - Docker alternative to launch containers in Kubernetes ";
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes);
- " Infrastructure with Kubernetes as an affordable service ."
Source: https://habr.com/ru/post/418269/
All Articles