Introduction to the task of recognizing emotions
Recognizing emotions is a hot topic in artificial intelligence. The most interesting areas of application of such technologies include: driver status recognition, marketing research, video analytics systems for smart cities, human-machine interaction, monitoring of students taking online courses, wearable devices, etc.
This year, MDG has dedicated its machine learning summer school to this topic. In this article I will try to give a brief excursion into the problem of recognizing the emotional state of a person and tell you about the approaches to its solution.

What are emotions?
Emotion is a special kind of mental processes that express the human experience of his relationship to the world around him and himself. According to one of the theories, the author of which is the Russian physiologist PK Anokhin, the ability to experience emotions was developed in the process of evolution as a means of more successful adaptation of living beings to the conditions of existence. Emotion proved to be useful for survival and allowed living beings to respond quickly and economically to external influences.
Emotions play a huge role in human life and interpersonal communication. They can be expressed in various ways: facial expressions, posture, motor responses, voice and autonomic responses (heart rate, blood pressure, respiration rate). However, the person’s face is most expressive.
Each person expresses emotions in several different ways. The famous American psychologist Paul Ekman , exploring the non-verbal behavior of isolated tribes in Papua New Guinea in the 70s of the last century, found that a number of emotions, namely: anger, fear, sadness, disgust, scorn, surprise and joy are universal and can be understood by man regardless of his culture.
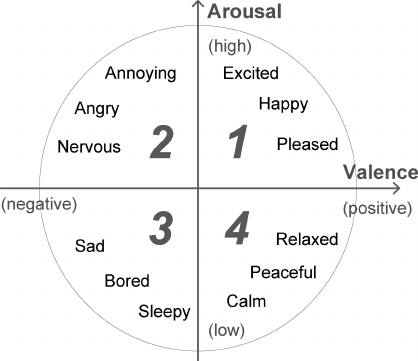
People are able to express a wide range of emotions. It is believed that they can be described as a combination of basic emotions (for example, nostalgia is something between a sadness and joy). But such a categorical approach is not always convenient, since does not allow quantitatively characterize the power of emotion. Therefore, along with discrete models of emotions, a series of continuous ones were developed. In the model of J. Russell, a two-dimensional basis is found, in which each emotion is characterized by a sign (valence) and intensity (arousal). Due to its simplicity, the Russell model has recently become increasingly popular in the context of the task of automatic classification of facial expressions.
So, we found out that if you are not trying to hide emotional arousal, then your current state can be assessed by facial expressions. Moreover, using modern achievements in the field of deep learning it is even possible to build a lie detector, based on the series “Lie to me”, the scientific basis of which was directly the work of Paul Ekman. However, this task is not so simple. As studies of neurobiologist Liza Feldman Barrett have shown, in recognizing emotions a person actively uses contextual information: voice, actions, situation. Take a look at the pictures below, this is true. Using only the face area, correct prediction cannot be done. In this regard, to solve this problem, it is necessary to use both additional modalities and information about signal changes over time.

Here we consider approaches to the analysis of only two modalities: audio and video, since these signals can be obtained in a contactless way. To get to the task in the first place you need to get the data. Here is a list of the largest publicly accessible bases of emotions known to me. Images and videos in these bases were manually tagged, some using Amazon Mechanical Turk.
| Title | Data | Markup | Year of issue |
|---|---|---|---|
| OMG-Emotion challenge | audio / video | 7 categories, valence / arousal | 2018 |
| EmotiW challenge | audio / video | 6 categories | 2018 |
| AffectNet | Images | 7 categories, valence / arousal | 2017 |
| AFEW-VA | video | valence / arousal | 2017 |
| EmotioNet challenge | Images | 16 categories | 2017 |
| EmoReact | audio / video | 17 categories | 2016 |
The classic approach to the task of classifying emotions
The easiest way to determine emotions by face is based on the classification of key points (facial landmarks), the coordinates of which can be obtained using various PDM , CML , AAM , DPM or CNN algorithms. Usually mark up from 5 to 68 points, tying them to the position of the eyebrows, eyes, lips, nose, jaw, which allows you to partially capture facial expressions. The normalized coordinates of points can be directly submitted to the classifier (for example, SVM or Random Forest) and get a basic solution. Naturally, the position of persons should be aligned.

Simple use of coordinates without a visual component leads to a significant loss of useful information, therefore, various descriptors are computed at these points to improve the system: LBP , HOG , SIFT , LATCH , etc. After concatenating the descriptors and reducing the dimension using PCA, the resulting feature vector can be used to classify of emotions.
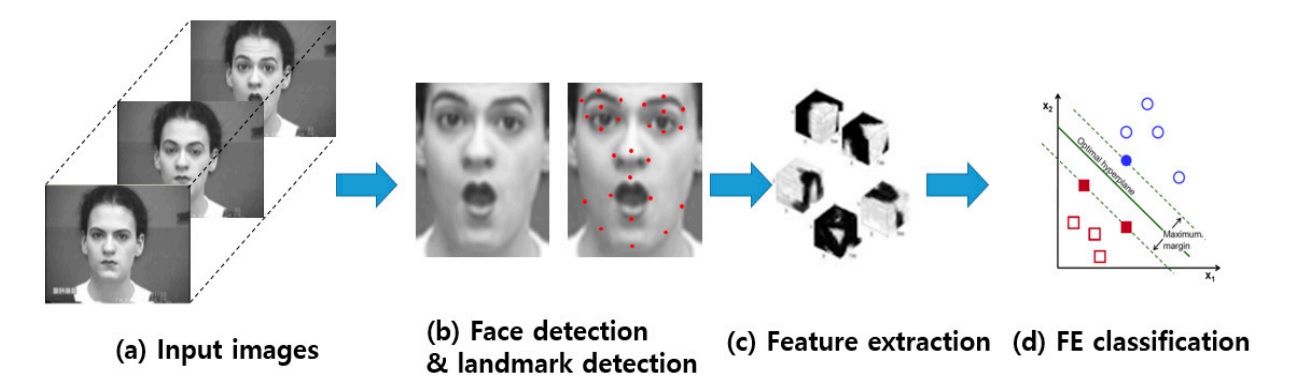
However, this approach is already considered obsolete, since it is well known that deep convolutional networks are the best choice for analyzing visual data.
Emotion classification using deep learning
In order to build a neural network classifier, it is enough to take some kind of network with the basic architecture, previously trained on ImageNet, and retrain the last few layers. So you can get a good basic solution for classifying various data, but given the specifics of the problem, the neural networks used for large-scale face recognition tasks will be more suitable.
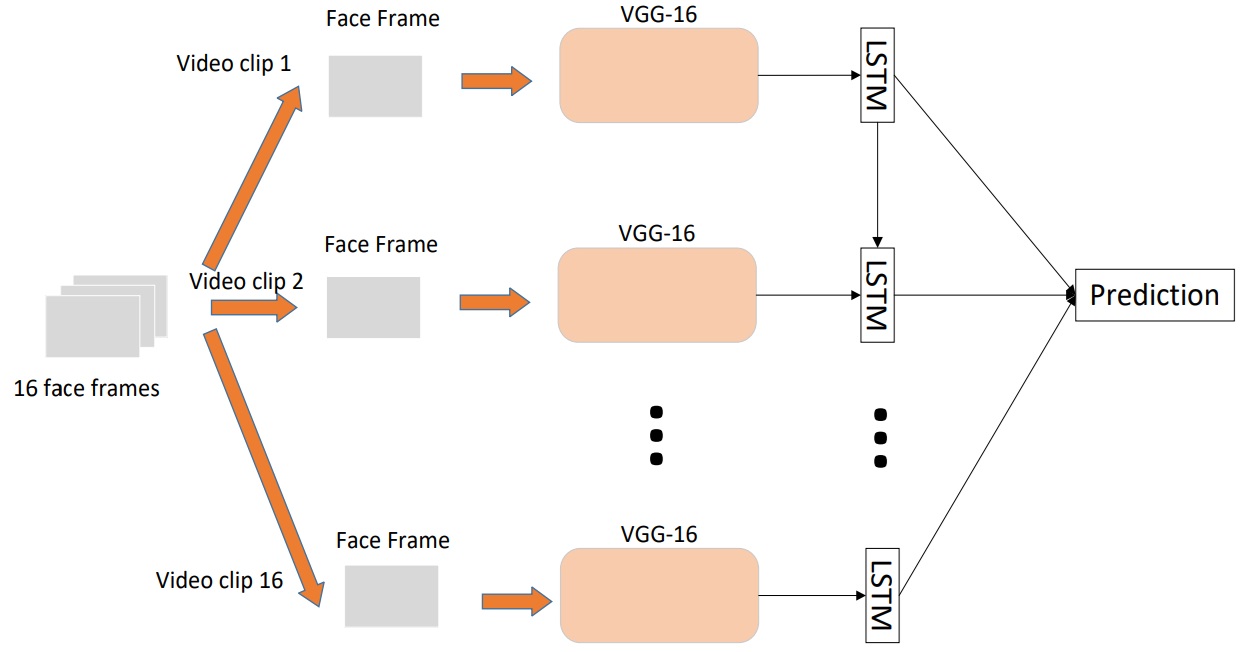
So, to build a classifier of emotions for individual images is quite simple, but as we found out, the snapshots do not quite accurately reflect the true emotions that a person experiences in this situation. Therefore, to improve the accuracy of the system, it is necessary to analyze the sequence of frames. This can be done in two ways. The first way is to feed the high-level features received from CNN, which classify each individual frame, into a recurrent network (for example, LSTM) to capture the time component.
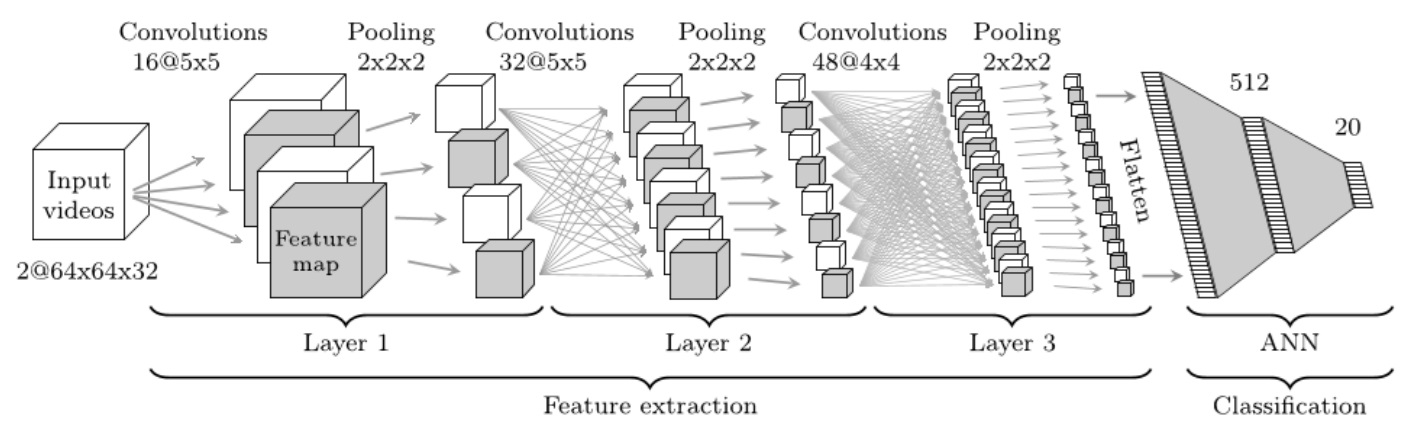
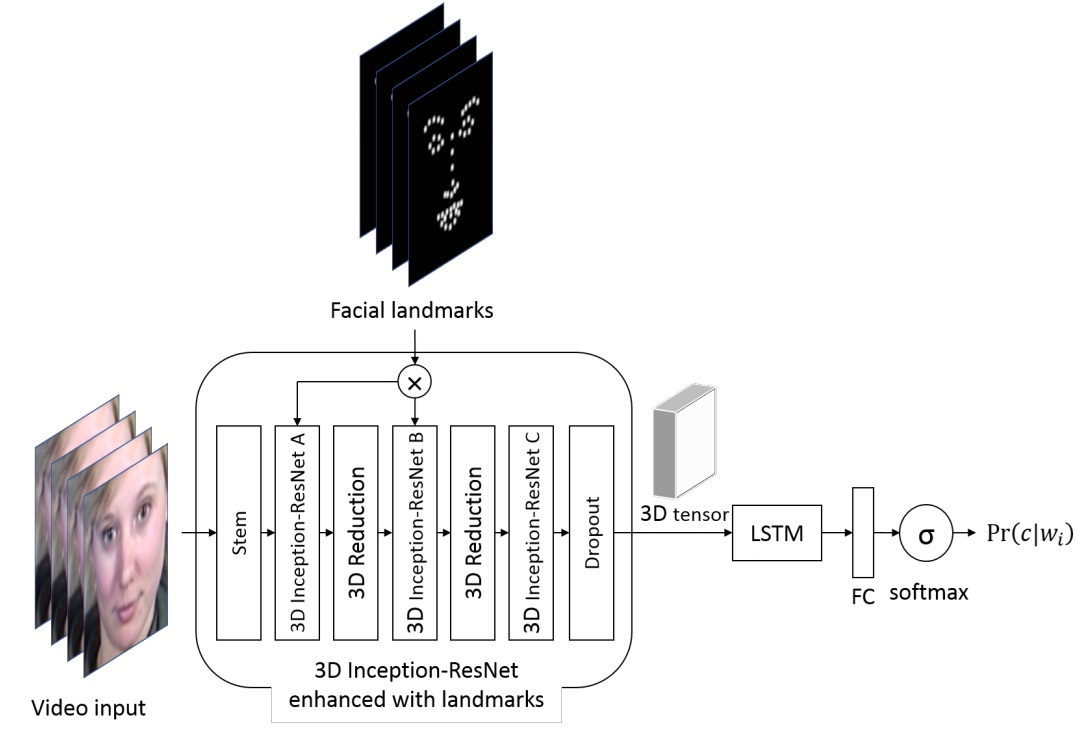
The second way is to directly feed a sequence of frames taken from the video with a certain step to the input of the 3D-CNN. CNN-like convolutions use three degrees of freedom convolutions that convert a four-dimensional entry into three-dimensional feature maps.
In fact, in general, these two approaches can be combined by constructing such a monster.
Classification of emotions by speech
Based on the visual data, it is possible to predict the sign of emotion with high accuracy, but when determining the intensity, it is preferable to use speech signals . It is a bit more difficult to analyze audio due to the strong variability of speech duration and the voices of speakers. Usually, they do not use the original sound wave, but various sets of features , for example: F0, MFCC, LPC, i-vectors, etc. In the problem of recognizing emotions through speech, the OpenSMILE open library, which contains a rich set of algorithms for analyzing speech and music signals. After extraction, tags can be submitted to SVM or LSTM for classification.
Recently, however, convolutional neural networks have begun to penetrate into the field of sound analysis, displacing established approaches. In order to apply them, the sound is presented in the form of spectrograms in a linear or mel scale, after which it is operated with the obtained spectrograms as with ordinary two-dimensional images. At the same time, the problem of an arbitrary spectrogram size along the time axis is elegantly solved with the help of statistical pooling or by including a recurrent network in the architecture.

Audiovisual recognition of emotions
So, we considered a number of approaches to the analysis of audio and video modalities, the final stage remained - the unification of classifiers for the conclusion of the final decision. The simplest way is to directly combine their ratings. In this case, it is enough to take a maximum or average. A more difficult option is to combine at the embedding level for each modality. SVM is often used for this, but this is not always correct, since embeddings can have different norms. In this regard, more advanced algorithms have been developed, for example: Multiple Kernel Learning and ModDrop .
And of course it is worth mentioning the class of so-called end-to-end solutions that can be trained directly on raw data from several sensors without any preprocessing.
In general, the task of automatic recognition of emotions is far from a solution. Judging by the results of last year's Emotion Recognition in the Wild contest, the best solutions reach an accuracy of about 60%. I hope that the information presented in this article will be enough to try to build your own system of recognition of emotions.
')
Source: https://habr.com/ru/post/418151/
All Articles