True and False Face Recognition Systems
Perhaps there is no other technology today, around which there would be so many myths, lies and incompetences. Journalists who talk about technology are lying, politicians who talk about successful implementation are lying, most technology sellers are lying. Every month I see the consequences of how people try to incorporate face recognition into systems that cannot work with it.

The topic of this article has long been sore, but it was somehow too lazy to write it. A lot of text that I have twenty times repeated to different people. But, after reading the next pack of trash, I decided it was time. I will give a link to this article.
')
So. In the article I will answer a few simple questions:
Most of the answers will be evidence, with a link to the research where the key parameters of the algorithms + with calculation mathematics are shown. A small part will be based on the experience of implementing and operating various biometric systems.
I will not go into details of how facial recognition is now implemented. On Habré there are many good articles on this topic: a , b , c (they are much more, of course, it pops up in memory). But still some points that affect different decisions - I will describe. So reading at least one of the articles above will simplify the understanding of this article. Let's start!
Biometrics is an exact science. There is no place for the phrase "always works" and "perfect." Everything is very well considered. And to calculate you need to know only two values:
These errors may have a number of features and application criteria. We will talk about them below. In the meantime, I'll tell you where to get them.
The first option . Once upon a time, manufacturers themselves published mistakes. But here is the thing: you can not trust the manufacturer. In what conditions and how he measured these errors - no one knows. And whether it measured at all, or the marketing department drew.
The second option. There were open bases. Manufacturers began to indicate errors in the databases. The algorithm can be sharpened under known bases, so that they show an awesome quality for them. But in reality, such an algorithm may not work.
The third option is open contests with a closed decision. The organizer checks the decision. Essentially kaggle. The most famous such competition is MegaFace . The first places in this competition were once given great popularity and fame. For example, N-Tech and Vocord have largely made a name for themselves on MegaFace.
All is good, but to be honest. Customized solution can be here. It is much harder, longer. But you can calculate people, you can manually mark the base, etc. And the main thing - it will not have any relation to how the system will work on real data. You can see who is now the leader on MegaFace, and then look for solutions of these guys in the next paragraph.
Fourth option . To date, the most honest. I don’t know how to cheat there. Although I do not exclude them.
A large and world-renowned institution agrees to deploy an independent solution testing system. From manufacturers comes the SDK which is subjected to closed testing, in which the manufacturer does not participate. Testing has many parameters, which are then officially published.
Now such testing is produced by NIST - the American National Institute of Standards and Technology. Such testing is the most honest and interesting.
It must be said that NIST does a great job. They have developed five case studies, release new updates every couple of months, are constantly improving and include new manufacturers. Here you can see the latest release of the study.
It would seem that this option is ideal for analysis. But no! The main disadvantage of this approach is that we do not know what is in the database. Look at this chart here:

This is the data of two companies for which testing was conducted. On the x axis is the month, y is the percentage of errors. I took the test "Wild faces" (just below the description).
A sudden increase in accuracy by 10 times for two independent companies (in general, everyone there took off). From where
In the NIST log, there is a note “the base was too complicated, we simplified it”. And there are no examples of either the old base or the new one. In my opinion this is a serious mistake. It was on the old base that the difference in vendor algorithms was visible. On the new 4-8% of all passes. And the old was 29-90%. My communication with face recognition on video surveillance systems says that 30% before - this was the real result of the master algorithms. It is difficult to recognize by such photos:

And of course, accuracy of 4% does not shine on them. But without seeing the NIST database, it is impossible to make such statements 100%. But it is NIST that is the main independent data source.
In the article, I describe the situation relevant for July 2018. At the same time, I rely on accuracy, based on the old database of persons for tests related to the “Faces in the wild” task.
It is quite possible that in half a year everything will change completely. Or maybe it will be stable over the next ten years.
So, we need this table:
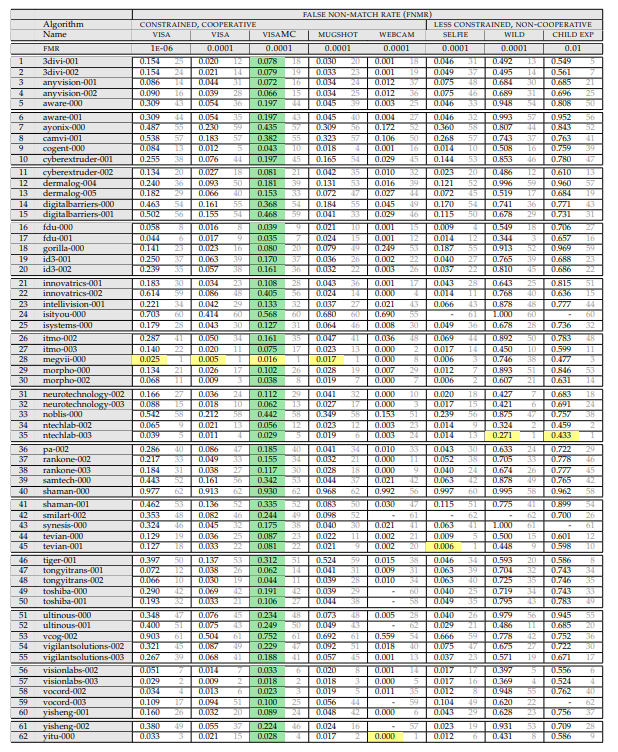
(April 2018, because wild is more adequate here)
Let's look at what is written in it, and how it is measured.
Above there is a listing of experiments. The experiment consists of:
The one on which the set is frozen. Sets are:
Togo at what level of errors of the first kind is measured (this parameter is considered only for passport photo images):
The result of the experiment is the value of FRR. The probability that we missed the person who is in the database.
And here the attentive reader might have noticed the first interesting point. “What does FAR 10 ^ -4 mean?”. And this is the most interesting moment!
What does such a mistake mean in practice? This means that at the base of 10,000 people there will be one mistaken coincidence when checking on it any average person. That is, if we have a base of 1000 criminals, and we compare 10,000 people a day with it, then we will have an average of 1000 false positives. Does anyone need this?
In reality, everything is not so bad.
If you look at plotting the dependence of the first kind of error on the second kind of error, you get such a cool picture (here at once for a dozen different companies, for the Wild option, this is what will happen at the metro station, if you put the camera somewhere so that people will not see it) :
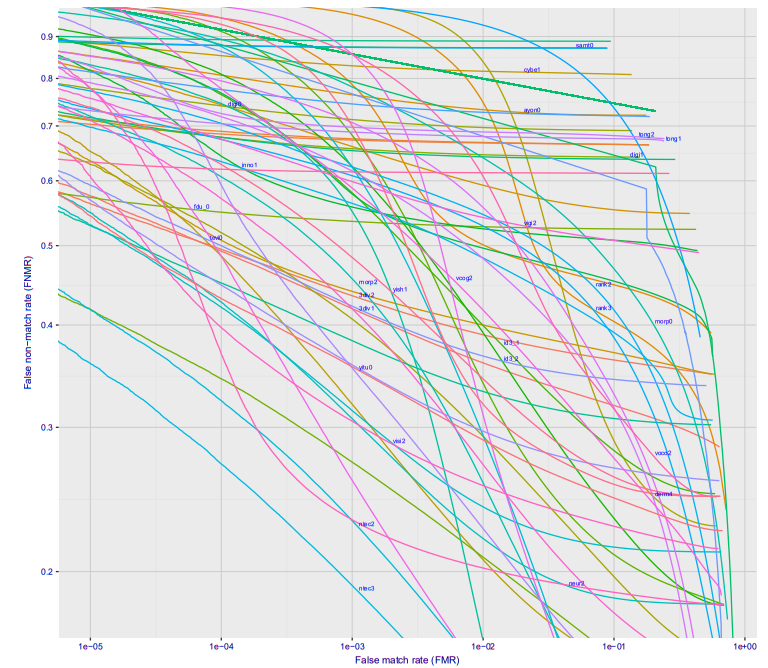
With an error of 10 ^ -4, 27% of the people are not recognized. At 10 ^ -5 approximately 40%. Most likely on 10 ^ -6 losses will be approximately 50%
So what does this mean in real numbers?
It is best to go from the paradigm of "how many mistakes a day can make." We have a flow of people at the station, if every 20-30 minutes the system gives a false positive, then no one will take it seriously. We fix the permissible number of false alarms at the metro station 10 people per day (for good, so that the system is not turned off as annoying - you need even less). The flow of one station of the Moscow metro is 20-120 thousand passengers per day. Average - 60 thousand.
Let the fixed FAR value be 10 ^ -6 (it cannot be set below, we will lose 50% of criminals with an optimistic estimate). This means that we can allow 10 false alarms with a base of 160 people.
Is it a lot or a little? The size of the base in the federal wanted list is ~ 300,000 people . Interpol 35 thousand. It is logical to assume that about 30 thousand Muscovites are wanted.
This will give an unrealistic number of false alarms.
It is worth noting that 160 people can be a sufficient base if the system is working on-line. If you look for those who committed a crime in the last 24 hours, this is already a completely working volume. In this case, wearing black glasses / caps, etc., you can disguise yourself. But how many wears them in the subway?
The second important point. It is easy to do in the subway system giving a photo of a higher quality. For example, put on the framework of the turnstile camera. There will not be a 50% loss by 10 ^ -6, but only 2-3%. And on 10 ^ -7 5-10%. There is accuracy from the graph on Visa, everything will certainly be much worse on real cameras, but I think you can leave this 10% loss by 10 ^ -6:

Again, the system will not pull the base of 30 thousand, but everything that happens in real time will allow detection.
It seems time to answer the first part of the questions:
Liksutov said that 22 wanted persons had been identified. Is it true?
Here the main question is what these people did, how many people who were not wanted were checked, how much the facial recognition helped in apprehending these 22 people.
Most likely, if these are people who were looking for an interception plan, they are really detainees. And this is a good result. But my modest assumptions allow us to say that in order to achieve this result, at least 2-3 thousand people were tested, but rather about ten thousand.
It fights very well with the numbers they called in London . Only there these numbers are honestly published, as people protest . And they keep silence ...
Yesterday on Habré there was an article about false characters on face recognition. But this is an example of manipulation in the opposite direction. Amazon has never had a good face recognition system. Plus the question of how to set the thresholds. I can do at least 100% of false stories, tweaking the settings;)
About the Chinese, who recognize everyone on the street - an obvious fake. Although, if they made competent tracking, then there can be done some more adequate analysis. But, honestly, I do not believe that as long as it is achievable. Rather a set of gags.
Let's go further. Let's rate another point. Search for a person with a well-known biography and a good profile in social networks.
NIST checks face to face recognition. It takes two faces of one / different people and compares how close they are to each other. If proximity is greater than the threshold, then this is one person. If further - different. But there is another approach.
If you read articles that I advised at the beginning, then you know that when a face is recognized, a hash code of a face is formed, which reflects its position in the N-dimensional space. This is usually 256/512 dimensional space, although all systems are different.
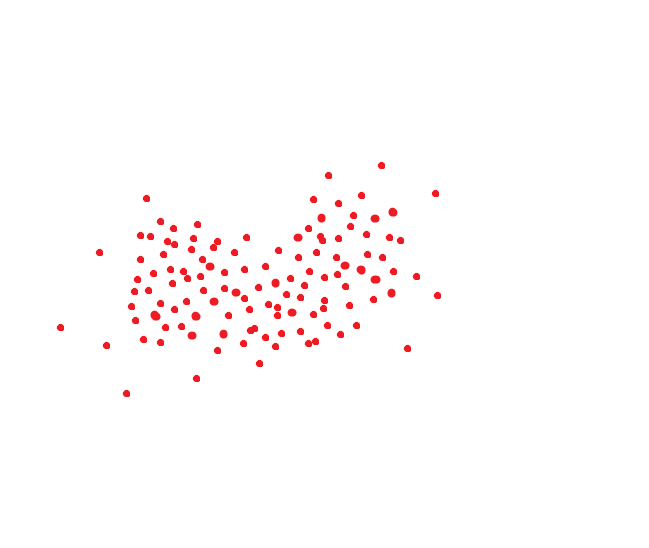
An ideal face recognition system translates the same person into the same code. But there are no perfect systems. The same person usually takes up some area of space. Well, for example, if the code were two-dimensional, then it could be something like this:
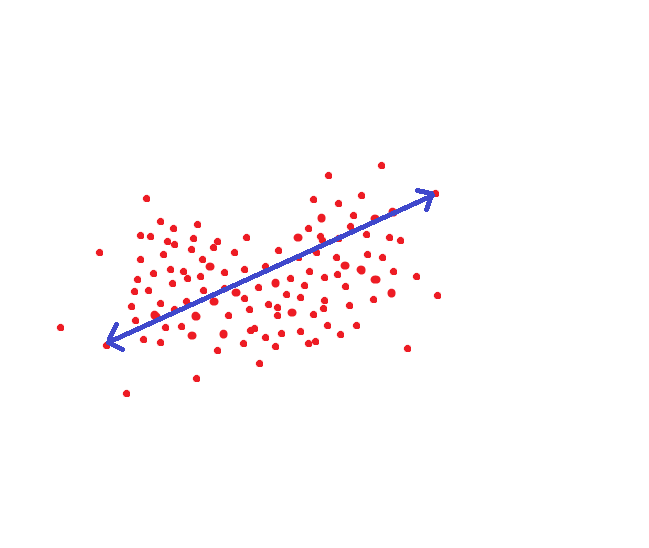
If we are guided by the method adopted in NIST, then this distance would be a target threshold, so that we could recognize a person as the same individual with 95% probability:
But you can do differently. For each person, set up the area of hyperspace where values are stored for him:

Then the threshold distance while maintaining accuracy decreases several times.
Only we need a lot of photos for each person.
If a person has a profile in social networks / the base of his pictures of different ages, then the recognition accuracy can be improved very much. I don’t know the exact assessment of how FAR | FRR grows. And it is already incorrect to estimate such values. Someone in this database has 2 photos, someone has 100. A lot of wrapping logic. It seems to me that the maximum estimate is one / one and a half orders. That allows you to shoot up to errors 10 ^ -7 with a probability of not recognizing 20-30%. But this is speculative and optimistic.
In general, of course, the management of this space is not a few problems (age chips, image editors, noise chips, sharpness chips), but as I understand, most of them have already been successfully solved by large companies who needed a solution.
What is it for me? To the fact that the use of profiles allows to increase the accuracy of recognition algorithms several times. But it is far from absolute. With profiles requires a lot of manual work. There are many similar people. But if you start to set limits on age, location, etc., then this method allows you to get a good solution. To give an example of how a person was found according to the principle “find a profile by photo” -> “use a profile to search for a person” I gave a link at the beginning.
But, in my opinion, this is a complex scalable process. And, again, people with a large number of pictures in the profile, God forbid, 40-50% in our country. And many of them are children, for which everything is not working well.
But, again - this is an estimate.
So here. About your safety. The smaller your profile picture, the better. The more numerous the meeting where you go - the better. No one will disassemble 20 thousand photos by hand. For those who care about their security and privacy - I would advise you not to make profiles with your pictures.
At a rally in a city with a population of 100 thousand, you can easily find it by looking at 1-2 matches. In Moscow - zadolbayutsya. About half a year ago, Vasyutka , with whom we work together, gave narrated on this topic:
Here I will allow myself to make a small excursion to the side. The quality of learning facial recognition algorithm depends on three factors:
According to claim 2, it seems that the limit has now been reached. In principle, mathematics develops on such things very quickly. And after the triplet loss, the remaining loss functions did not give a dramatic increase, only a smooth improvement and a decrease in the size of the base.
Selecting a face is difficult if you need to find faces at all angles, losing fractions of a percent. But the creation of such an algorithm is a fairly predictable and well-managed process. The more everything is blue, the better, large corners are correctly processed:

Six months ago it was like this:

It can be seen that more and more companies are slowly moving this way, the algorithms begin to recognize more and more faces.
But with the size of the base - all the more interesting. Open bases are small. Good base maximum for a couple of tens of thousands of people. Those that are big are oddly structured / bad ( megaface , MS-Celeb-1M ).
How do you think, where did the creators of the algorithms take these bases?
Little hint. The first product of NTech, which they are now folding - Find Face, search for people on VKontakte. I think explanations are not needed. Of course, VKontakte fights bots that pump out all open profiles. But as far as I heard, the people still shakes. And classmates. And instagramm.
It seems like with Facebook - everything is more complicated there. But I am almost sure that they have come up with something too.
So yes, if your profile is open, then you can be proud, it was used to train algorithms;)
Here you can be proud. Of the 5 leading companies in the world, two are now Russian. These are N-Tech and VisionLabs. Half a year ago, the leaders were NTech and Vocord, the first worked much better on turned faces, the second on the front ones.
Now the rest of the leaders are 1-2 Chinese companies and 1 American, Vocord has passed something in the ratings.
Another Russian in the rating itmo, 3divi, intellivision. Synesis is a Belarusian company, although some were once in Moscow, about 3 years ago they had a blog on Habré. I also know about several solutions that they belong to foreign companies, but development offices are also in Russia. There are also a few Russian companies that are not in the competition, but which seem to have good solutions. For example, there is a MDG. Obviously, Odnoklassniki and Vkontakte also have their own good ones, but they are for internal use.
In short, yes, we and the Chinese are mainly shifted on their faces.
NTech generally the first in the world showed good parameters of the new level. Somewhere at the end of 2015 . VisionLabs caught up with NTech only. In 2015, they were market leaders. But their decision was the last generation, and they began to try to catch up with NTech only at the end of 2016.
To be honest, I do not like both of these companies. Very aggressive marketing. I saw people to whom a clearly inappropriate solution was put in place that did not solve their problems.
From this side, I liked Vocord much more. Somehow I consulted to whom Vocord said very honestly that “your project will not work with such cameras and installation points”. NTech and VisionLabs happily tried to sell. But something Vocord recently disappeared.
In the conclusions I want to say the following. Face recognition is a very good and powerful tool. It really allows you to find criminals today. But its implementation requires a very accurate analysis of all parameters. There are applications where there is enough OpenSource solution. There are applications (recognition at the stadiums in the crowd) where only VisionLabs | Ntech need to be installed, and also keep a team of service, analysis and decision-making. And OpenSource will not help you here.
To date, you can not believe all the fairy tales that you can catch all the criminals, or watch all in the city. But it is important to remember that such things can help catch criminals. For example, to stop in the subway not everyone, but only those whom the system considers similar. Put the camera so that people are better recognized and create the appropriate infrastructure for it. Although, for example, I am against it. For the cost of a mistake if you recognize as someone else may be too high.
The topic of this article has long been sore, but it was somehow too lazy to write it. A lot of text that I have twenty times repeated to different people. But, after reading the next pack of trash, I decided it was time. I will give a link to this article.
')
So. In the article I will answer a few simple questions:
- Is it possible to recognize you on the street? And how automatically / reliably?
- The day before yesterday they wrote that criminals were being detained in the Moscow metro, and yesterday they wrote that they could not do it in London. And in China, recognize all-all on the street. And here they say that 28 US congressmen are criminals. Or, they caught the thief.
- Who is now producing recognition solutions on the faces of what is the difference between solutions, technology features?
Most of the answers will be evidence, with a link to the research where the key parameters of the algorithms + with calculation mathematics are shown. A small part will be based on the experience of implementing and operating various biometric systems.
I will not go into details of how facial recognition is now implemented. On Habré there are many good articles on this topic: a , b , c (they are much more, of course, it pops up in memory). But still some points that affect different decisions - I will describe. So reading at least one of the articles above will simplify the understanding of this article. Let's start!
Introduction, basis
Biometrics is an exact science. There is no place for the phrase "always works" and "perfect." Everything is very well considered. And to calculate you need to know only two values:
- Errors of the first kind - a situation when a person is not in our database, but we identify him as a person present in the database (in FAR biometrics (false access rate))
- Errors of the second kind are situations when a person is in the database, but we missed it. (In FRR biometrics (false reject rate))
These errors may have a number of features and application criteria. We will talk about them below. In the meantime, I'll tell you where to get them.
Specifications
The first option . Once upon a time, manufacturers themselves published mistakes. But here is the thing: you can not trust the manufacturer. In what conditions and how he measured these errors - no one knows. And whether it measured at all, or the marketing department drew.
The second option. There were open bases. Manufacturers began to indicate errors in the databases. The algorithm can be sharpened under known bases, so that they show an awesome quality for them. But in reality, such an algorithm may not work.
The third option is open contests with a closed decision. The organizer checks the decision. Essentially kaggle. The most famous such competition is MegaFace . The first places in this competition were once given great popularity and fame. For example, N-Tech and Vocord have largely made a name for themselves on MegaFace.
All is good, but to be honest. Customized solution can be here. It is much harder, longer. But you can calculate people, you can manually mark the base, etc. And the main thing - it will not have any relation to how the system will work on real data. You can see who is now the leader on MegaFace, and then look for solutions of these guys in the next paragraph.
Fourth option . To date, the most honest. I don’t know how to cheat there. Although I do not exclude them.
A large and world-renowned institution agrees to deploy an independent solution testing system. From manufacturers comes the SDK which is subjected to closed testing, in which the manufacturer does not participate. Testing has many parameters, which are then officially published.
Now such testing is produced by NIST - the American National Institute of Standards and Technology. Such testing is the most honest and interesting.
It must be said that NIST does a great job. They have developed five case studies, release new updates every couple of months, are constantly improving and include new manufacturers. Here you can see the latest release of the study.
It would seem that this option is ideal for analysis. But no! The main disadvantage of this approach is that we do not know what is in the database. Look at this chart here:
This is the data of two companies for which testing was conducted. On the x axis is the month, y is the percentage of errors. I took the test "Wild faces" (just below the description).
A sudden increase in accuracy by 10 times for two independent companies (in general, everyone there took off). From where
In the NIST log, there is a note “the base was too complicated, we simplified it”. And there are no examples of either the old base or the new one. In my opinion this is a serious mistake. It was on the old base that the difference in vendor algorithms was visible. On the new 4-8% of all passes. And the old was 29-90%. My communication with face recognition on video surveillance systems says that 30% before - this was the real result of the master algorithms. It is difficult to recognize by such photos:
And of course, accuracy of 4% does not shine on them. But without seeing the NIST database, it is impossible to make such statements 100%. But it is NIST that is the main independent data source.
In the article, I describe the situation relevant for July 2018. At the same time, I rely on accuracy, based on the old database of persons for tests related to the “Faces in the wild” task.
It is quite possible that in half a year everything will change completely. Or maybe it will be stable over the next ten years.
So, we need this table:
(April 2018, because wild is more adequate here)
Let's look at what is written in it, and how it is measured.
Above there is a listing of experiments. The experiment consists of:
The one on which the set is frozen. Sets are:
- Passport photo (perfect, front). The background is white, perfect shooting systems. This can sometimes be found at the entrance, but very rarely. Usually such tasks are a comparison of a person at an airport with a base.

- Photography is a good system, but without top quality. There are backdrops, a person may not even stand / look a bit past the camera, etc.

- Selfie with a smartphone / computer camera. When the user provides cooperation, but poor shooting conditions. There are two subsets, but they have a lot of photos only in the "selfie"

- "Faces in the wild" - shooting from almost any side / hidden photography. The maximum angles of rotation of the face to the camera - 90 degrees. This is where NIST sooo simplified the database.

- Children. All algorithms work poorly for children.
Togo at what level of errors of the first kind is measured (this parameter is considered only for passport photo images):
- 10 ^ -4 - FAR (one false positive of the first kind) for 10 thousand comparisons with the base
- 10 ^ -6 - FAR (one false positive of the first kind) per million comparisons with the base
The result of the experiment is the value of FRR. The probability that we missed the person who is in the database.
And here the attentive reader might have noticed the first interesting point. “What does FAR 10 ^ -4 mean?”. And this is the most interesting moment!
Main setup
What does such a mistake mean in practice? This means that at the base of 10,000 people there will be one mistaken coincidence when checking on it any average person. That is, if we have a base of 1000 criminals, and we compare 10,000 people a day with it, then we will have an average of 1000 false positives. Does anyone need this?
In reality, everything is not so bad.
If you look at plotting the dependence of the first kind of error on the second kind of error, you get such a cool picture (here at once for a dozen different companies, for the Wild option, this is what will happen at the metro station, if you put the camera somewhere so that people will not see it) :
With an error of 10 ^ -4, 27% of the people are not recognized. At 10 ^ -5 approximately 40%. Most likely on 10 ^ -6 losses will be approximately 50%
So what does this mean in real numbers?
It is best to go from the paradigm of "how many mistakes a day can make." We have a flow of people at the station, if every 20-30 minutes the system gives a false positive, then no one will take it seriously. We fix the permissible number of false alarms at the metro station 10 people per day (for good, so that the system is not turned off as annoying - you need even less). The flow of one station of the Moscow metro is 20-120 thousand passengers per day. Average - 60 thousand.
Let the fixed FAR value be 10 ^ -6 (it cannot be set below, we will lose 50% of criminals with an optimistic estimate). This means that we can allow 10 false alarms with a base of 160 people.
Is it a lot or a little? The size of the base in the federal wanted list is ~ 300,000 people . Interpol 35 thousand. It is logical to assume that about 30 thousand Muscovites are wanted.
This will give an unrealistic number of false alarms.
It is worth noting that 160 people can be a sufficient base if the system is working on-line. If you look for those who committed a crime in the last 24 hours, this is already a completely working volume. In this case, wearing black glasses / caps, etc., you can disguise yourself. But how many wears them in the subway?
The second important point. It is easy to do in the subway system giving a photo of a higher quality. For example, put on the framework of the turnstile camera. There will not be a 50% loss by 10 ^ -6, but only 2-3%. And on 10 ^ -7 5-10%. There is accuracy from the graph on Visa, everything will certainly be much worse on real cameras, but I think you can leave this 10% loss by 10 ^ -6:
Again, the system will not pull the base of 30 thousand, but everything that happens in real time will allow detection.
First questions
It seems time to answer the first part of the questions:
Liksutov said that 22 wanted persons had been identified. Is it true?
Here the main question is what these people did, how many people who were not wanted were checked, how much the facial recognition helped in apprehending these 22 people.
Most likely, if these are people who were looking for an interception plan, they are really detainees. And this is a good result. But my modest assumptions allow us to say that in order to achieve this result, at least 2-3 thousand people were tested, but rather about ten thousand.
It fights very well with the numbers they called in London . Only there these numbers are honestly published, as people protest . And they keep silence ...
Yesterday on Habré there was an article about false characters on face recognition. But this is an example of manipulation in the opposite direction. Amazon has never had a good face recognition system. Plus the question of how to set the thresholds. I can do at least 100% of false stories, tweaking the settings;)
About the Chinese, who recognize everyone on the street - an obvious fake. Although, if they made competent tracking, then there can be done some more adequate analysis. But, honestly, I do not believe that as long as it is achievable. Rather a set of gags.
And what about my safety? On the street, at the rally?
Let's go further. Let's rate another point. Search for a person with a well-known biography and a good profile in social networks.
NIST checks face to face recognition. It takes two faces of one / different people and compares how close they are to each other. If proximity is greater than the threshold, then this is one person. If further - different. But there is another approach.
If you read articles that I advised at the beginning, then you know that when a face is recognized, a hash code of a face is formed, which reflects its position in the N-dimensional space. This is usually 256/512 dimensional space, although all systems are different.
An ideal face recognition system translates the same person into the same code. But there are no perfect systems. The same person usually takes up some area of space. Well, for example, if the code were two-dimensional, then it could be something like this:
If we are guided by the method adopted in NIST, then this distance would be a target threshold, so that we could recognize a person as the same individual with 95% probability:
But you can do differently. For each person, set up the area of hyperspace where values are stored for him:
Then the threshold distance while maintaining accuracy decreases several times.
Only we need a lot of photos for each person.
If a person has a profile in social networks / the base of his pictures of different ages, then the recognition accuracy can be improved very much. I don’t know the exact assessment of how FAR | FRR grows. And it is already incorrect to estimate such values. Someone in this database has 2 photos, someone has 100. A lot of wrapping logic. It seems to me that the maximum estimate is one / one and a half orders. That allows you to shoot up to errors 10 ^ -7 with a probability of not recognizing 20-30%. But this is speculative and optimistic.
In general, of course, the management of this space is not a few problems (age chips, image editors, noise chips, sharpness chips), but as I understand, most of them have already been successfully solved by large companies who needed a solution.
What is it for me? To the fact that the use of profiles allows to increase the accuracy of recognition algorithms several times. But it is far from absolute. With profiles requires a lot of manual work. There are many similar people. But if you start to set limits on age, location, etc., then this method allows you to get a good solution. To give an example of how a person was found according to the principle “find a profile by photo” -> “use a profile to search for a person” I gave a link at the beginning.
But, in my opinion, this is a complex scalable process. And, again, people with a large number of pictures in the profile, God forbid, 40-50% in our country. And many of them are children, for which everything is not working well.
But, again - this is an estimate.
So here. About your safety. The smaller your profile picture, the better. The more numerous the meeting where you go - the better. No one will disassemble 20 thousand photos by hand. For those who care about their security and privacy - I would advise you not to make profiles with your pictures.
At a rally in a city with a population of 100 thousand, you can easily find it by looking at 1-2 matches. In Moscow - zadolbayutsya. About half a year ago, Vasyutka , with whom we work together, gave narrated on this topic:
By the way, about social networks
Here I will allow myself to make a small excursion to the side. The quality of learning facial recognition algorithm depends on three factors:
- The quality of the face selection.
- The metric of persons' proximity used when training Triplet Loss, Center Loss, spherical loss, etc.
- Base size
According to claim 2, it seems that the limit has now been reached. In principle, mathematics develops on such things very quickly. And after the triplet loss, the remaining loss functions did not give a dramatic increase, only a smooth improvement and a decrease in the size of the base.
Selecting a face is difficult if you need to find faces at all angles, losing fractions of a percent. But the creation of such an algorithm is a fairly predictable and well-managed process. The more everything is blue, the better, large corners are correctly processed:
Six months ago it was like this:
It can be seen that more and more companies are slowly moving this way, the algorithms begin to recognize more and more faces.
But with the size of the base - all the more interesting. Open bases are small. Good base maximum for a couple of tens of thousands of people. Those that are big are oddly structured / bad ( megaface , MS-Celeb-1M ).
How do you think, where did the creators of the algorithms take these bases?
Little hint. The first product of NTech, which they are now folding - Find Face, search for people on VKontakte. I think explanations are not needed. Of course, VKontakte fights bots that pump out all open profiles. But as far as I heard, the people still shakes. And classmates. And instagramm.
It seems like with Facebook - everything is more complicated there. But I am almost sure that they have come up with something too.
So yes, if your profile is open, then you can be proud, it was used to train algorithms;)
About solutions and companies
Here you can be proud. Of the 5 leading companies in the world, two are now Russian. These are N-Tech and VisionLabs. Half a year ago, the leaders were NTech and Vocord, the first worked much better on turned faces, the second on the front ones.
Now the rest of the leaders are 1-2 Chinese companies and 1 American, Vocord has passed something in the ratings.
Another Russian in the rating itmo, 3divi, intellivision. Synesis is a Belarusian company, although some were once in Moscow, about 3 years ago they had a blog on Habré. I also know about several solutions that they belong to foreign companies, but development offices are also in Russia. There are also a few Russian companies that are not in the competition, but which seem to have good solutions. For example, there is a MDG. Obviously, Odnoklassniki and Vkontakte also have their own good ones, but they are for internal use.
In short, yes, we and the Chinese are mainly shifted on their faces.
NTech generally the first in the world showed good parameters of the new level. Somewhere at the end of 2015 . VisionLabs caught up with NTech only. In 2015, they were market leaders. But their decision was the last generation, and they began to try to catch up with NTech only at the end of 2016.
To be honest, I do not like both of these companies. Very aggressive marketing. I saw people to whom a clearly inappropriate solution was put in place that did not solve their problems.
From this side, I liked Vocord much more. Somehow I consulted to whom Vocord said very honestly that “your project will not work with such cameras and installation points”. NTech and VisionLabs happily tried to sell. But something Vocord recently disappeared.
findings
In the conclusions I want to say the following. Face recognition is a very good and powerful tool. It really allows you to find criminals today. But its implementation requires a very accurate analysis of all parameters. There are applications where there is enough OpenSource solution. There are applications (recognition at the stadiums in the crowd) where only VisionLabs | Ntech need to be installed, and also keep a team of service, analysis and decision-making. And OpenSource will not help you here.
To date, you can not believe all the fairy tales that you can catch all the criminals, or watch all in the city. But it is important to remember that such things can help catch criminals. For example, to stop in the subway not everyone, but only those whom the system considers similar. Put the camera so that people are better recognized and create the appropriate infrastructure for it. Although, for example, I am against it. For the cost of a mistake if you recognize as someone else may be too high.
Source: https://habr.com/ru/post/418127/
All Articles