NewSQL = NoSQL + ACID

Until recently, about 50 TB of data processed in real time were stored in SQL Server in Odnoklassniki. For such a volume, it is almost impossible to provide fast and reliable, and even fault tolerant to the data center access using SQL DBMS. Usually in such cases one of the NoSQL-storages is used, but not everything can be transferred to NoSQL: some entities require ACID transaction guarantees.
This brought us to the use of NewSQL-storage, that is, a DBMS that provides fault tolerance, scalability and performance of NoSQL-systems, but at the same time retains the traditional ACID-guarantee. There are few operating industrial systems of this class, therefore we implemented such a system ourselves and launched it into commercial operation.
How it works and what happened - read under the cut.
Today, Odnoklassniki’s monthly audience amounts to more than 70 million unique visitors. We are among the top five largest social networks in the world, and in the top twenty sites where users spend the most time. The “OK” infrastructure handles very high loads: over a million HTTP requests / sec to the fronts. Parts of the fleet of servers in the amount of more than 8,000 units are located close to each other - in four Moscow data centers, which allows for a network delay of less than 1 ms between them.
')
We have been using Cassandra since 2010, starting with version 0.6. Today there are several dozen clusters in operation. The fastest cluster processes more than 4 million operations per second, and the largest stores 260 TB.
However, all this is the usual NoSQL-clusters used to store poorly consistent data. We also wanted to replace the main consistent storage, Microsoft SQL Server, which has been used since the founding of Odnoklassniki. The repository consisted of more than 300 SQL Server Standard Edition machines that contained 50 TB of data — business entities. These data are modified as part of ACID transactions and require high consistency .
To distribute data among SQL Server nodes, we used both vertical and horizontal partitioning (sharding). Historically, we used a simple data sharding scheme: each entity was associated with a token - a function of the entity ID. Entities with the same token were placed on a single SQL server. The master-detail type relationship was implemented so that the tokens of the main and child records always coincide and reside on the same server. In a social network, almost all entries are generated on behalf of the user, which means that all user data within the same functional subsystem is stored on the same server. That is, tables of a single SQL server were almost always involved in a business transaction, which made it possible to ensure data consistency using local ACID transactions, without the need for slow and unreliable distributed ACID transactions.
Thanks to sharding and to speed up SQL:
- We do not use Foreign key constraints, as when sharding an entity ID it may be located on another server.
- We do not use stored procedures and triggers due to the additional load on the DBMS CPU.
- We do not use JOINs because of all the above and many random reads from the disk.
- Outside the transaction, we use the Read Uncommitted isolation level to reduce deadlocks.
- We perform only short transactions (on average shorter than 100 ms).
- We do not use multi-row UPDATE and DELETE due to the large number of deadlocks - we update only one record.
- Inquiries are always performed only by indexes - a query with a full table view plan for us means overloading the database and its failure.
These steps made it possible to squeeze almost the maximum performance out of SQL servers. However, the problems became more and more. Let's consider them.
SQL issues
- Since we used samopisny sharding, adding new shards was done by administrators manually. All this time, scalable data replicas have not served requests.
- As the number of records in the table grows, the insertion and modification speed decreases, when adding indexes to an existing table, the speed drops multiple, the creation and re-creation of indexes comes with downtime.
- Having a small number of Windows for SQL Server production complicates infrastructure management
But the main problem is
fault tolerance
The classic SQL server has poor resiliency. Suppose you have only one database server, and it fails every three years. At this time, the site does not work for 20 minutes, this is acceptable. If you have 64 servers, the site does not work once every three weeks. And if you have 200 servers, the site does not work every week. This is problem.
What can be done to improve SQL server resiliency? Wikipedia offers us to build a highly accessible cluster : where in case of failure of any of the components there is a duplicate.
This requires a fleet of expensive equipment: numerous redundancy, optical fiber, shared storage, and the inclusion of the reserve works unreliably: about 10% of the inclusions result in the failure of the backup node by the engine behind the main node.
But the main drawback of such a highly accessible cluster is zero availability in case of failure of the data center in which it is located. Odnoklassniki has four data centers, and we need to ensure work in case of a complete accident in one of them.
To this end, Multi-Master replication built into SQL Server could be applied. This solution is much more expensive due to the cost of software and suffers from well-known replication problems — unpredictable transaction delays with synchronous replication and delays in the use of replications (and, as a result, lost modifications) with asynchronous. The implied manual resolution of conflicts makes this option completely inapplicable to us.
All these problems required a cardinal solution and we began to analyze them in detail. Here we need to get acquainted with what SQL Server basically does - transactions.
Simple transaction
Consider the simplest transaction from the point of view of an applied SQL programmer: adding a photo to an album. Albums and photos are stored in different tablets. The album has a count of public photos. Then such a transaction is divided into the following steps:
- Lock the album by key.
- Create an entry in the photo table.
- If a photo has a public status, then we wind up a counter of public photos in the album, update the record and commit the transaction.
Or in the form of pseudocode:
TX.start("Albums", id); Album album = albums.lock(id); Photo photo = photos.create(…); if (photo.status == PUBLIC ) { album.incPublicPhotosCount(); } album.update(); TX.commit(); We see that the most common business transaction scenario is to read data from the database into the memory of the application server, change something, and save the new values back to the database. Usually in such a transaction we update several entities, several tables.
When performing a transaction, competitive modification of the same data from another system may occur. For example, Antispam may decide that a user is suspicious and therefore all user photos should no longer be public, they need to be sent for moderation, which means changing photo.status to some other value and unscrewing the corresponding counters. Obviously, if this operation takes place without guarantees of atomicity of application and isolation of competing modifications, as in ACID , the result will not be what is necessary - or the photo counter will show the wrong value, or not all photos will be sent for moderation.
There is a lot written about such code, which manipulates various business entities in the framework of a single transaction, during the entire existence of Odnoklassniki. From the experience of migrations to NoSQL with Eventual Consistency, we know that the greatest difficulties (and time costs) make it necessary to develop code aimed at maintaining consistency of data. Therefore, we considered the provision of real ACID transactions for the application logic to be the main requirement for the new storage.
Other equally important requirements were:
- If the data center fails, both reading and writing to the new storage should be available.
- Maintain current development speed. That is, when working with a new repository, the amount of code should be approximately the same, there should be no need to add something to the repository, develop conflict resolution algorithms, maintain secondary indexes, etc.
- The speed of the new storage should be sufficiently high, both when reading data and processing transactions, which effectively meant the inapplicability of academically rigorous, universal, but slow solutions, such as two-phase commits .
- Automatic scaling on the fly.
- Use of ordinary cheap servers, without the need to buy exotic pieces of iron.
- The possibility of developing storage by the developers of the company. In other words, priority was given to its or open source-based solutions, preferably in Java.
Decisions
Analyzing possible solutions, we came to two possible choices of architecture:
The first is to take any SQL server and implement the required fault tolerance, scaling mechanism, failover cluster, conflict resolution, and distributed, reliable, and fast ACID transactions. We appreciated this option as very non-trivial and time consuming.
The second option is to take ready NoSQL storage with implemented scaling, failover cluster, conflict resolution and implement transactions and SQL by yourself. At first glance, even the task of implementing SQL, not to mention the ACID transaction, looks like a year task. But then we realized that the set of SQL capabilities that we use in practice is far from ANSI SQL as far as Cassandra CQL is far from ANSI SQL. Looking more closely at CQL, we realized that it was close enough to what we needed.
Cassandra and CQL
So, what makes Cassandra interesting, what capabilities does it have?
First, here you can create tables with support for various data types, you can make a SELECT or UPDATE by the primary key.
CREATE TABLE photos (id bigint KEY, owner bigint,…); SELECT * FROM photos WHERE id=?; UPDATE photos SET … WHERE id=?; To ensure consistency of replica data, Cassandra uses a quorum approach . In the simplest case, this means that when placing three replicas of the same row on different nodes of the cluster, the recording is considered successful if most of the nodes (ie, two of the three) have confirmed the success of this write operation. The data of the series is considered consistent if, while reading, the majority of the nodes were interrogated and confirmed. Thus, if there are three replicas, complete and instant data consistency is guaranteed in case of failure of one node. This approach allowed us to implement an even more reliable scheme: always send requests for all three replicas, waiting for a response from the two fastest. The late response of the third replica in this case is discarded. A node that was late with the response can have serious problems - brakes, garbage collection in JVM, direct memory reclaim in linux kernel, hardware failure, disconnection from the network. However, this does not affect the client’s operations and data.
The approach, when we turn to three nodes, and get a response from two, is called speculation : a request for extra replicas is sent before it “falls off”.
Another advantage of Cassandra is Batchlog - a mechanism that guarantees either full use or complete non-use of the package of changes you make. This allows us to solve A in ACID - atomicity out of the box.
Closest to transactions in Cassandra are the so-called " lightweight transactions ". But they are far from “real” ACID transactions: in fact, it is possible to make CAS on the data of only one record, using the consensus on the Paxos heavy protocol. Therefore, the speed of such transactions is low.
What we lacked in Cassandra
So, we had to implement real ACID transactions in Cassandra. Using which we could easily implement two other convenient features of classic DBMS: consistent fast indexes, which would allow us to perform data sampling not only on the primary key and the usual monotone auto-increment ID generator.
C * One
Thus was born the new C * One DBMS, consisting of three types of server nodes:
- Storage - (almost) standard servers Cassandra, responsible for storing data on local drives. As the load and data volume grows, their number can be easily scaled to tens and hundreds.
- Transaction Coordinators - ensure the execution of transactions.
- Clients are application servers that implement business operations and initiate transactions. There may be thousands of such customers.
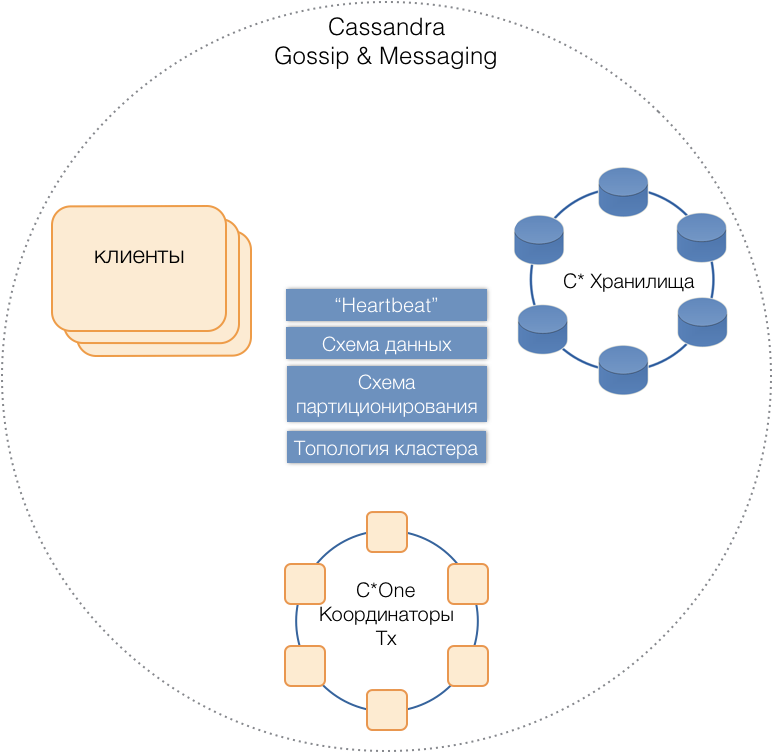
Servers of all types are in a common cluster, use the internal Cassandra message protocol to communicate with each other and gossip to exchange cluster information. With the help of Heartbeat, servers learn about mutual failures, support a single data scheme — tables, their structure and replication; partition scheme, cluster topology, etc.
Customers
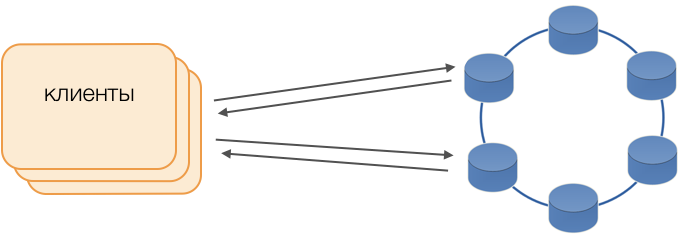
Fat lient mode is used instead of standard drivers. Such a node does not store data, but can act as a coordinator for the execution of requests, that is, the Client himself acts as a coordinator for his requests: he polls the replicas of the repository and resolves conflicts. This is not only safer and faster than the standard driver, which requires communication with the remote coordinator, but also allows you to control the transmission of requests. Outside the transaction opened on the client, requests are sent to the repositories. If the client has opened a transaction, then all requests within the transaction are sent to the transaction coordinator.

C * One Transaction Coordinator
The coordinator is what we implemented for C * One from scratch. He is responsible for managing transactions, locks, and the order in which transactions are applied.
For each accepted transaction, the coordinator generates a timestamp: each subsequent one is larger than the previous transaction. Since in Cassandra the conflict resolution system is based on timestamps (out of two conflicting entries, the current one is considered to be with the latest timestamp), the conflict will always be resolved in favor of the subsequent transaction. Thus, we implemented a Lamport watch - a cheap way to resolve conflicts in a distributed system.
Locks
To ensure isolation, we decided to use the easiest way - pessimistic locks on the primary key of the record. In other words, in a transaction, you must first block the record, only then read, modify and save. Only after a successful commit can a record be unlocked so that competing transactions can use it.
The implementation of such a lock is simple in an unallocated environment. In a distributed system, there are two main ways: either to implement distributed locking on a cluster, or to distribute transactions so that transactions with the same record are always serviced by the same coordinator.
Since, in our case, the data is already distributed into local transaction groups in SQL, it was decided to assign the local transaction groups to the coordinators: one coordinator performs all transactions with a token from 0 to 9, the second with a token from 10 to 19, and so on. As a result, each of the instances of the coordinator becomes a transaction group master.
Then locks can be implemented as a banal HashMap in the memory of the coordinator.
Failures of coordinators
Since one coordinator exclusively serves a group of transactions, it is very important to quickly determine that he was rejected so that a retry of execution of the transaction will be timed out. To make it fast and reliable, we used a fully connected quorum hearbeat protocol:
Each data center hosts at least two nodes of the coordinator. Periodically, each coordinator sends a heartbeat message to the other coordinators and informs them about his functioning, as well as about the heartbeat messages from which coordinators in the cluster he received last time.

Receiving similar information from the rest of their heartbeat messages, each coordinator decides for himself which cluster nodes are functioning and which are not, guided by the quorum principle: if node X received information from the majority of nodes in the cluster about normal receiving messages from node Y, then , Y is working. And vice versa, as soon as the majority reports about the loss of messages from node Y, it means that Y has failed. It is curious that if a quorum informs node X that it does not receive more messages from it, then node X itself will consider itself refused.
Heartbeat messages are sent with a high frequency, about 20 times per second, with a period of 50 ms. In Java, it is difficult to guarantee an application response for 50 ms due to the comparable length of pauses caused by the garbage collector. We managed to achieve such a response time using the G1 garbage collector, which allows you to specify a target for the duration of GC pauses. However, sometimes, quite rarely, the pause of the collector goes beyond 50 ms, which can lead to a false failure detection. To prevent this from happening, the coordinator does not report the failure of the remote node when the first heartbeat message disappears from it only if it disappears several consecutively. So we managed to detect the failure of the coordinator node within 200 ms.
But it is not enough to quickly understand which node has ceased to function. Need something to do with it.
Reservation
The classical scheme assumes, in the event of a master's failure, to launch a new election using one of the trendy universal algorithms. However, such algorithms have well-known problems with the convergence in time and duration of the election process itself. We managed to avoid such additional delays using the equivalent circuit of coordinators in a fully meshed network:
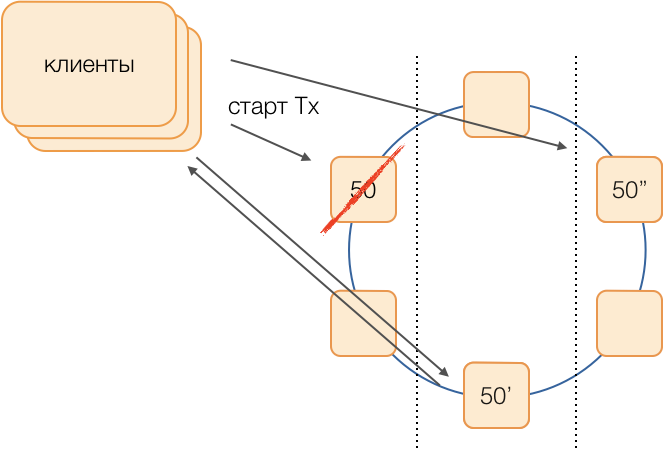
Suppose we want to perform a transaction in group 50. We will define the replacement scheme in advance, that is, which nodes will execute group 50 transactions in the event of a failure of the main coordinator. Our goal is to keep the system working in case of a data center failure. We define that the first reserve will be a node from another data center, and the second reserve will be a node from the third. This scheme is selected once and does not change until the cluster topology changes, that is, until new nodes enter it (which happens very rarely). The procedure for selecting a new active master if the old one fails will always be like this: the first reserve will become the active master, and if it also ceases to function, the second reserve will become.
Such a scheme is more reliable than the universal algorithm, since to activate the new wizard, it is enough to determine if the old one has failed.
But how will clients understand which of the masters is working now? For 50 ms, it is impossible to send information to thousands of clients. It is possible that the client sends a request to open a transaction, not knowing that this wizard is no longer functioning, and the request will hang on a timeout. To prevent this from happening, clients speculatively send a request to open a transaction immediately to the group master and both of his reserves, but only the one who is currently the active master is responding to this request. All subsequent communication within the framework of the transaction the client will produce only with the active master.
Backup masters receive requests for non-own transactions in a queue of unborn transactions, where they are stored for some time. If the active master dies, the new master processes requests to open transactions from its turn and responds to the client. If the client has already managed to open a transaction with the old master, then the second answer is ignored (and, obviously, such a transaction will not end and will be repeated by the client).
How a transaction works
Suppose the client sent a request to the coordinator to open a transaction for such and such an entity with such and such a primary key. The coordinator blocks this entity and places it in the table of locks in memory. If necessary, the coordinator reads this entity from the repository and stores the received data in the transaction state in the coordinator's memory.
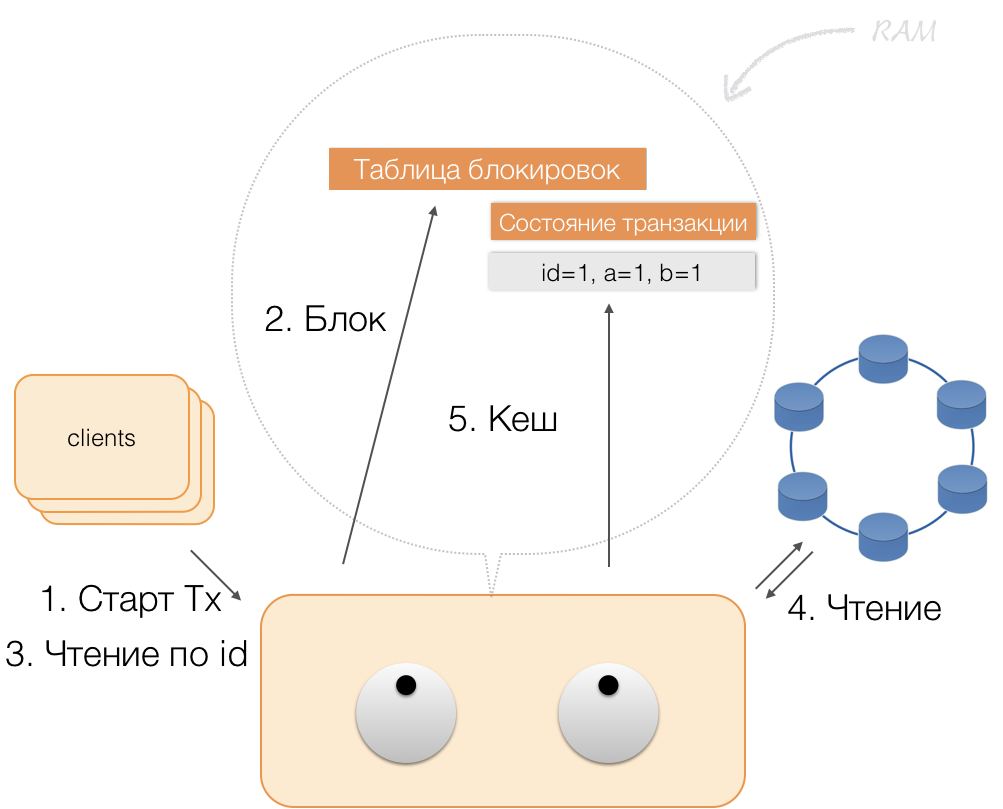
When a client wants to change data in a transaction, he sends a request to modify the entity to the coordinator, who then places the new data in the transaction status table in memory. At this point, the recording is completed - no entry is made to the storage.
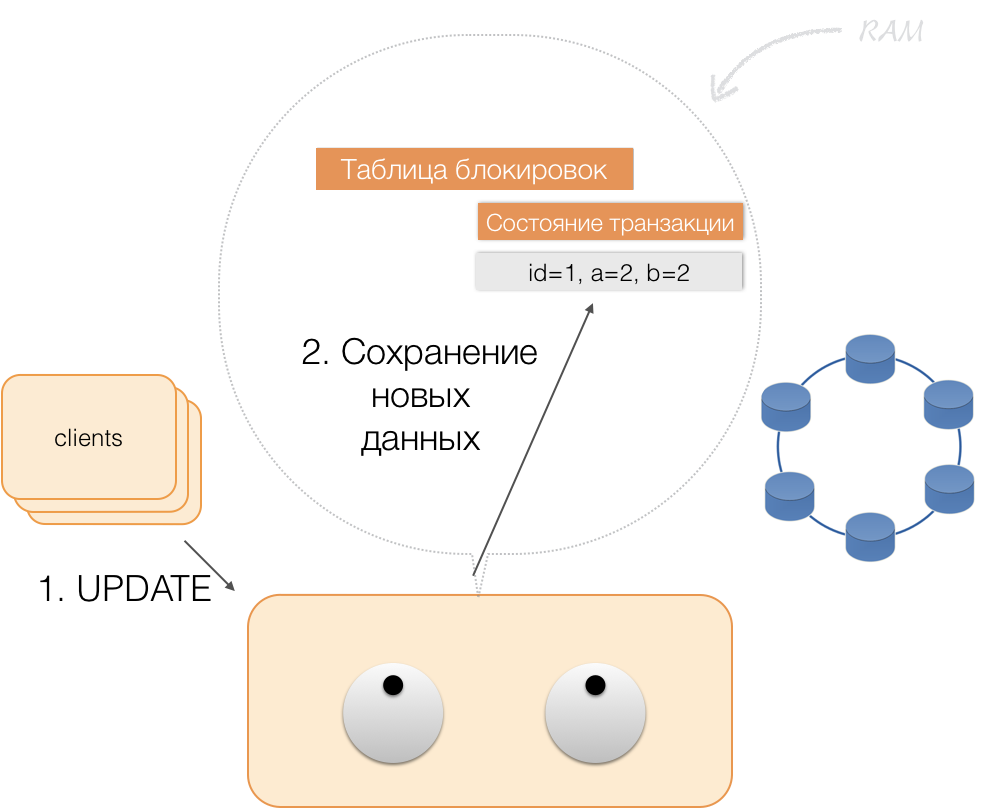
When a client requests its own changed data as part of an active transaction, the coordinator acts like this:
- if the ID is already in the transaction, then the data is taken from memory;
- if the ID is not in memory, then the missing data is read from the node-storages, combined with those already in memory, and the result is given to the client.
Thus, the client can read his own changes, and other clients do not see these changes, because they are stored only in the coordinator's memory, they are not yet in the Cassandra nodes.
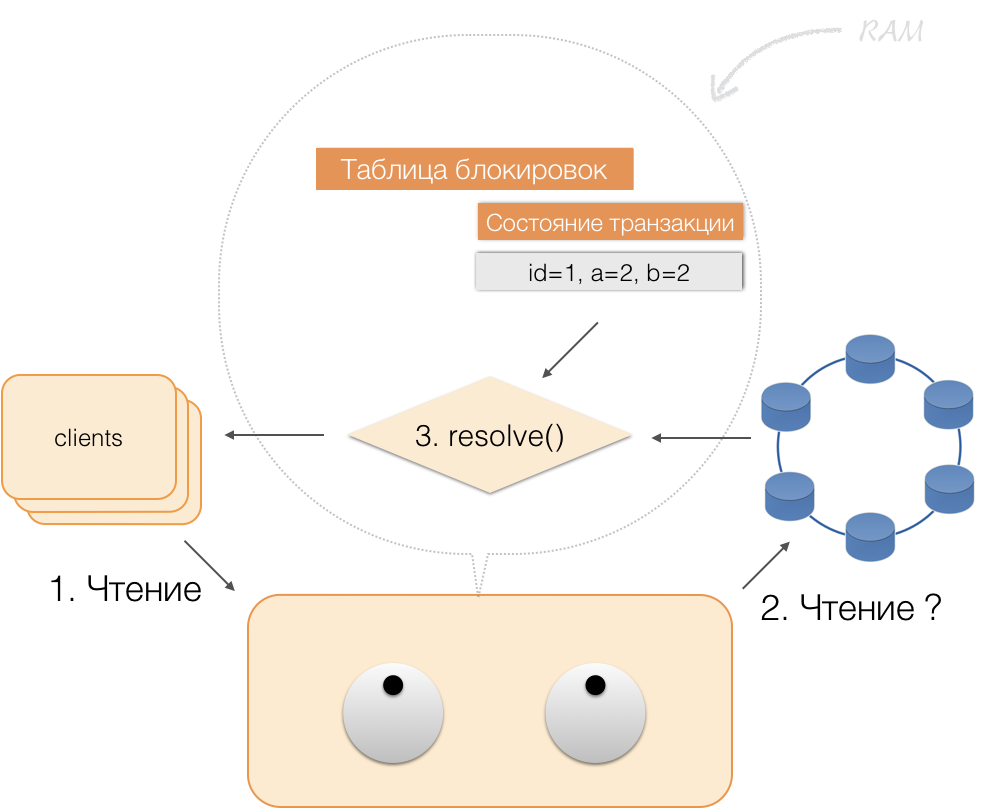
When the client sends a commit, the state stored in the memory of the service is saved by the coordinator at the logged batch, and already in the form of a logged batch is sent to the Cassandra repositories. The repositories do everything necessary to ensure that this package is atomically (fully) applied, and returns a response to the coordinator, which releases the locks and confirms the success of the transaction to the client.

And for a rollback, the coordinator need only free up the memory occupied by the state of the transaction.
As a result of the above improvements, we implemented the principles of ACID:
- Atomicity This is a guarantee that no transaction will be fixed in the system partially, either all its suboperations will be executed, or none will be executed. We have this principle respected by logged batch in Cassandra.
- Consistency Each successful transaction by definition captures only valid results. If, after opening a transaction and performing part of the operation, it is found that the result is invalid, it is rolled back.
- Isolation When performing a transaction, parallel transactions should not affect its result. Competing transactions are isolated using pessimistic locks on the coordinator. For readings out of transaction, the principle of isolation at the Read Committed level is observed.
- Sustainability . Regardless of the problems at the lower levels - system de-energization, equipment failure, - changes made by a successfully completed transaction should remain saved after the resumption of operation.
Reading by Index
Take a simple table:
CREATE TABLE photos ( id bigint primary key, owner bigint, modified timestamp, …) She has the ID (primary key), the owner and the date of the change. It is necessary to make a very simple request - select data by owner with the date of change “for the last 24 hours”.
SELECT * WHERE owner=? AND modified>? In order to process such a query quickly, it is necessary to build an index in columns (owner, modified) in a classical SQL DBMS. We can do this quite simply, as we now have ACID guarantees!
Indices in C * One
There is a source table with photos in which the record ID is the primary key.

For the index, C * One creates a new table that is a copy of the original one. The key coincides with the index expression, while it also includes the primary key of the record from the source table:
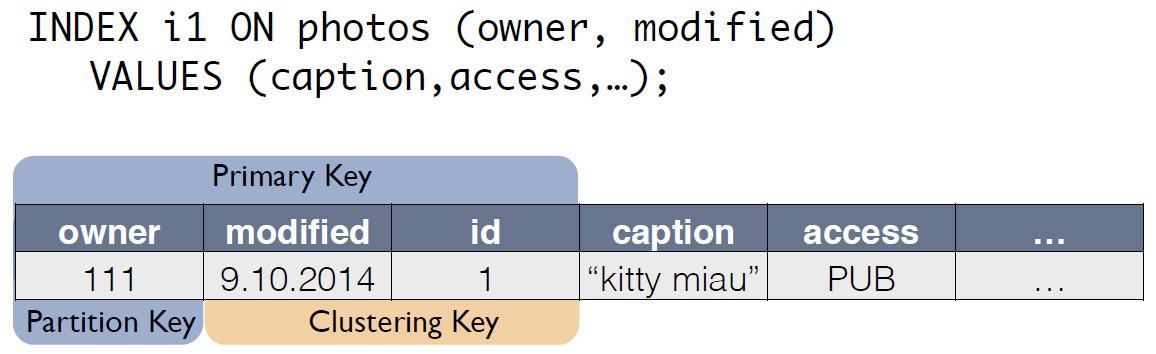
Now the query by “owner in the last 24 hours” can be rewritten as a select from another table:
SELECT * FROM i1_test WHERE owner=? AND modified>? The consistency of the data in the source table photos and the index i1 is maintained by the coordinator automatically. Based on the data scheme alone, upon receipt of a change, the coordinator generates and remembers the change not only of the main table, but also changes of copies. No additional actions are performed on the index table, logs are not read, and locks are not used. That is, adding indexes almost does not consume resources and practically does not affect the speed of application of modifications.
With the help of ACID, we were able to implement indices “as in SQL”. They have consistency, can scale, work quickly, can be composite, and are built into the CQL query language. To support indexes, you do not need to make changes to the application code. Everything is simple, as in SQL. , .
What happened
C*One .
? , . , . «» 20 , 80 . , 8 . ACID- , .
SQL replication factor = 1 ( RAID 10), 32 Microsoft SQL Server ( 11 ). 10 . 50 . , .
replication factor = 3 — -. 63 Cassandra 6 , 69 . , 30 % SQL. 30 %.
C*One : SQL 4,5 . C*One — 1,6 . 40 , 2 , — 2 . 99- — 3-3,1 , 100 — .
SQL Server, c C*One. C*One one-cloud , , . .
— .
Source: https://habr.com/ru/post/417593/
All Articles