4 years of Data Science at the Schibsted Media Group

In 2014, I joined a small team at the Schibsted Media Group as the 6th Data Science specialist for this company. Since then, I have worked on many initiatives in the field of Data Science in an organization in which there are now over 40 people. In this post I will talk about some of the things that I learned about over the past four years, first as a specialist, and then as a manager of Data Science.
This post follows the example of Robert Chang and his excellent article “ Doing Data Science in Twitter ”, which I found very valuable when I first read it in 2015. The goal of my own contribution is to convey equally useful thoughts to Data Science specialists and managers around the world.
I divided the post into two parts:
- Part I: Data Science in Real Life
- Part II: Managing the Data Science Team
In Part I, I focused on the work that Data Science experts actually do, while Part II discusses how to manage the Data Science team as efficiently as possible. I would say that both parts are important both for specialists and for managers.
I will not spend a lot of time describing who Data Science is and who is not a specialist - there are enough articles on this topic all over the Internet.
Schibsted in Brief: Media and marketplace in more than 20 countries around the world. I work mainly on our marketplace business, where millions of people buy and sell products every day. If you want to take a look at a few real-world examples of data science work at Schibsted, here’s a small selection:
With this in mind, let's dive!
Part I: Data Science in Real Life
Starting a Data Science specialist in a new company with big ambitions is really amazing, but it can also seem scary. What do people around me expect from me? What skill level will my colleagues have? How do I work to be a useful company? In a position around which there is so much hype, it is sometimes difficult not to feel like an impostor .
The fear of being simple is often prompted by a Data Science specialist to focus primarily on complexity. This leads us to the first conclusion.
1.1. The difficulty increases the cost, start with a simple
They hired a Data Science specialist, so this problem must surely be really difficult, right?

This assumption will very often mislead you as a Data Science specialist. First of all, the problems that you encounter in business are very often solved with the help of fairly simple methods. Secondly, it is important to remember that complexity adds cost. A complex model is likely to entail more work on its implementation, a higher risk of errors and more difficulty in explaining it to customers. Therefore, you should always look for the simplest approach first.
But how to understand if the simplest approach is enough?
1.2. Always have a base model.
Estimates of the quality of your model, most likely, do not make sense by themselves without comparison with the base model. Comparisons with accuracy with random selection, in most cases, are simply not enough.

At some point, we built a model to predict the likelihood that a user will return to our site — a return model. In our model, we used about 15 signs based on user behavior, and we achieved an accuracy of about ~ 0.8 ROC-AUC. Comparing with the accuracy of the random prediction (0.5), we were quite pleased with this result. But when we threw everything out of the model except for the two most important signs: recentness (number of days since last visit) and frequency (number of days of visits in the past), we found that a simple logistic regression on these two variables gave us 78% ROC-AUC ! In other words, we could achieve more than 97% of the performance, throwing more than 85% of the signs.
I have seen so many times how Data Science specialists show the results of offline experiments on complex models without any simple basic model for comparison. When you see this, you should always ask: could we achieve the same result with a much simpler model?
1.3. Use the data that you have
I once had lunch with a data engineer and another Data Science specialist. The latter's eyes lit up when he talked about all the amazing things he could have done "if only he had X, Y or Z data." At some point during the conversation, the engineer laughed: “You, Data Science experts, always talk about what you could do with data that you do not have. How about doing something with the data that you have? ”

It sounded rude, but the engineer expressed an important truth. You will never have the perfect data set and there will always be data you could use. In most cases, you can do something with what you have.
1.4 Take responsibility for the data
As mentioned above, the quality and completeness of the data is almost always a problem. But instead of sitting and waiting for someone to present you the data on a platter, you need to come forward and take responsibility for the data you need.

I'm not talking about formal ownership in terms of the data management model. I am talking about expanding my role and helping where it is possible to get the data you need.
This may mean participating in the creation of schemes and data collection formats. This may mean viewing the Javascript code running in the web application interface to ensure that events are triggered when they should. Or it could mean building data pipelines, without waiting for the data engineers to do everything for you.
1.5. Forget about data
Obviously, this is contrary to everything I said above, but it is very important not to focus too much on the data that you have.

When a new problem appears, you must first try to forget the available data. Why so? Because your existing data may limit the solution space, and this can distract you from finding the best approach. You will be stuck at a local optimum where you are trying to pull a solution to any problem onto the data set that is available to you (use is beyond study). As a result, you will never have new data sets.
1.6. Develop a detailed understanding of causality.
We all know that correlation does not imply a causal relationship. The problem is that many Data Science experts stop at this and are afraid to link the cause to the effect.

Why is this a problem? Because the product managers, the marketing team, your CEO or with whom you work there, do not care at all about the correlation. They are concerned about the causal relationship.
The product manager wants to be sure that when he decides to release this new feature, he will trigger a 10% increase in product involvement. The marketing team wants to know that increasing the number of letters from 2 per week to 4 will not make people unsubscribe. And the CEO wants to know that investing in better targeting settings will increase advertising revenue.
So is there a compromise solution? It turns out there are two of them.
The most famous online experiments. In fact, you run randomized trials, among them the most popular A / B tests. The idea is simple: since we randomly chose who would be in the target group and who would be in the control group, then if we found a statistically significant difference between the groups, the “treatment” we applied can be considered the cause. Without going into philosophical reasoning, in practice this is a reasonable assumption.
A less well-known approach to finding causal relationships is causal modeling. The idea here is that you make assumptions about the cause-and-effect structure of the world, and then use observational data (non-experimental) to check whether these assumptions are consistent with the data, or to assess the strength of various cause-effect relationships. Adam Kelleher has written a wonderful series of articles on Causal Data Science , which I advise you to read. In addition, the bible of causality is the book “ Causality ” by Judea Pearl.
In my experience, most Data Science specialists have extensive experience in creating machine learning models and their offline evaluation. Far fewer people who have experience with online assessment and experimentation. The explanation is simple: you can download a dataset from Kaggle, train a model and evaluate it offline in minutes. To evaluate this model online, on the other hand, you need access to the real world. Even if you work in an Internet company with millions of users, you often have to overcome many obstacles to put your machine learning model in front of users.
Now, if few Data Science experts have a lot of experience with online assessment, very few have experience with causal modeling. I think there are many good reasons. One of the reasons is that most of the books on causality are rather theoretical, among them there are few practical guides on how to start causal modeling in the real world. I predict that in the next few years we will see more practical causal modeling guides.
Developing a detailed understanding of causality will allow you to give practical advice to your customers and at the same time support your integrity as a Data Science specialist.
Part II: Managing the Data Science Team
In Schibsted, as in many other companies, there are two career paths: as an independent employee and as a manager. In the context of Data Science, the first is for those who really want to increase their knowledge in the field of Data Science and contribute to the company through practical work and technical leadership. The path of the leader is designed for those who are more passionate about the development of people and team management.
I was not at all sure which path was right for me, but eventually I decided to try the path of the leader. It didn't take long for me to realize that this is indeed the right way for me, but I, of course, ran into a lot of problems (and I still do this!).
The first challenge you face is that there are very few other Data Science managers in the world. If you thought that experienced Data Science specialists are rare, then experienced Data Science managers are many times less. Thus, you are to one degree or another left to yourselves.
But is it true that managing the Data Science team is so different from managing other types of teams? Yes and no.
If you have never managed a team before, you probably will be helped by the classic management reading like “ High Output Management ” by Andrew Grove. In addition, a proactive appeal for advice to senior managers (from other disciplines) is also crucial.
However, the Data Science teams have several key differences, so now we will focus on the findings, especially those related to the Data Science teams.
2.1. The Data Science team is not really a team.
When most people think of teams, they think of something like this:

What are some characteristics of a football team like FC Barcelona? At least three things:
- common goal
- Different roles in the team, each of which has different responsibilities
- Independence in achieving its goal
If you manage a team consisting only of Data Science specialists, most likely none of these characteristics is performed. Instead, your team will have:
- Multiple, changing goals
- Experts, and they are good at the same thing: Data Science
- Other teams you can work with to ultimately impact users and revenues
A more suitable analogy than a football team for a Data Science team is:
The demand for the services of Mulder and Scully changes over time. They are attracted when their experience is required. And they will never solve a case without talking to people outside the FBI.
Why is this distinction important?
Because if you have a Data Science team and manage them as a “classic” team with a common goal, different roles, and complete autonomy, you will very quickly get a frustrated team.
I’ve seen Data Science teams managed like any other product or development team, and the inevitable consequence of this is that Data Science experts start doing anything but Data Science. Instead, they end up developing, decomposing, or managing a product.
So Data Science specialists are different. But how then do you guarantee that your Data Science will not live in an ivory tower?
2.2. Embed Data Science specialists into other teams
The magic happens when you put Data Science specialists next to product managers, programmers, interface researchers, marketers, and others.
Simply, the objective function that you want to maximize is the following: fruitful interaction between Data Science experts on your team and people on other teams.
I like to think about it, using the concept of a wide channel. Let's illustrate this with the help of a product manager paired with a Data Science specialist.
Worst of all, when between them there is no channel:

This means that there is no communication between DS and PM. In other words, DS will not be aware of any problems with the product that PM faces, which makes it impossible to analyze or solve these problems.
It is a little better when we have a narrow channel between them:
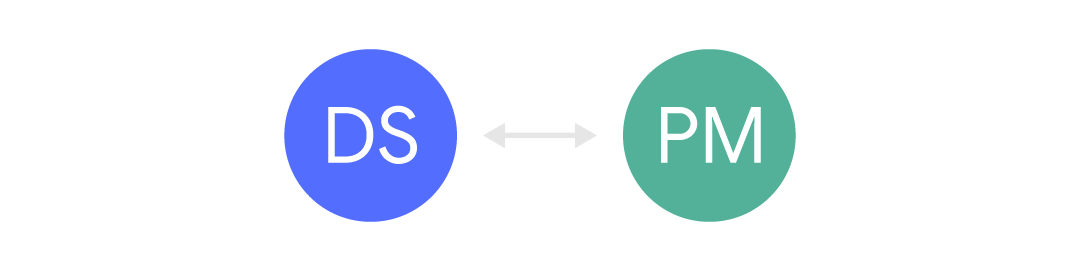
In this case, the information arrives, but is usually limited and often asynchronous. Information comes through other people (for example, another manager) or through inquiry forms, etc. This type of communication is common when it is expected that Data Science specialists will serve many different customers. But this can be frustrating, because the business context is often missing, and this can lead to misunderstandings and stupid fuss.
The most effective state is when we have a wide channel:

In the most literal sense, a wide channel is when a Data Science specialist sits next to a product manager. This, of course, allows them to communicate much more efficiently. Having people physically close is not always convenient or even possible (we are scattered across 22 different countries in Schibsted!), But there are virtual versions of this principle: from Slack to remote pair programming and Hangouts.
Naturally, you will not be able to organize a wide channel for every product manager in the company with every Data Science specialist on your team; it does not scale. Your job as a Data Science manager is to determine when broad channels should be organized. And then get out of the way!
One of the cases in Schibsted, when we were actively working to create a wide channel, was the development of our car pricing tool, which helps you set a price when selling your car ( try it on our Finn marketplace in Norway ). Initially, we had a rather thin channel, like this: “Try to build the most accurate pricing model you can.” We found that it was rather inefficient, as there were many product questions that we could not answer without experimenting with users in the early stages.
However, after a while, it was all over the fact that we embedded one of our Data Science specialists into the product team, and we got much better results. You can read about some of our early work on the car assessment tool in this post .
An example of when we had a wide channel from the very beginning is the forecast model for new digital subscriptions . The model helped increase sales conversion by 540% and was rewarded with an INMA award “Best Use of Data Analysis” in 2017.
2.3. Take responsibility for analytics performance
In the book High Output Management, Andrew Grove says that you, as a manager, own the results of your team’s work. This means that the Data Science manager must invest in creating the best possible environment for its Data Science specialists to be productive.

This is in many ways contrary to the embedding model described above. If you embed all the time, there is a high probability that you will end up with data warehouses and a non-optimal infrastructure duplicated several times.
Some development managers claim that when you become a manager, you should completely stop coding. I think that as a Data Science manager, you have to spend up to 10% of your time on independent work: training models, data visualization, etc. This puts you in the shoes of a Data Science specialist.
“I have to spend 15 minutes waiting for this cluster to load, every time I want to do an ad-hoc analysis ?! Of course, there must be a faster way to do this. ”
“This documentation on our schema formats seems outdated - how will I measure clicks on this type of button on different sites?”
And so on and so forth.
Of course, such a work with your hands should not replace the proactive receiving feedback from your team. But it certainly helps you discover key areas where you can simplify the lives of your Data Science specialists.
You can also be more methodical and use frameworks such as Lean Management to seek to eliminate losses in various Data Science processes. This post from the always brilliant XKCD will serve as a starting point:
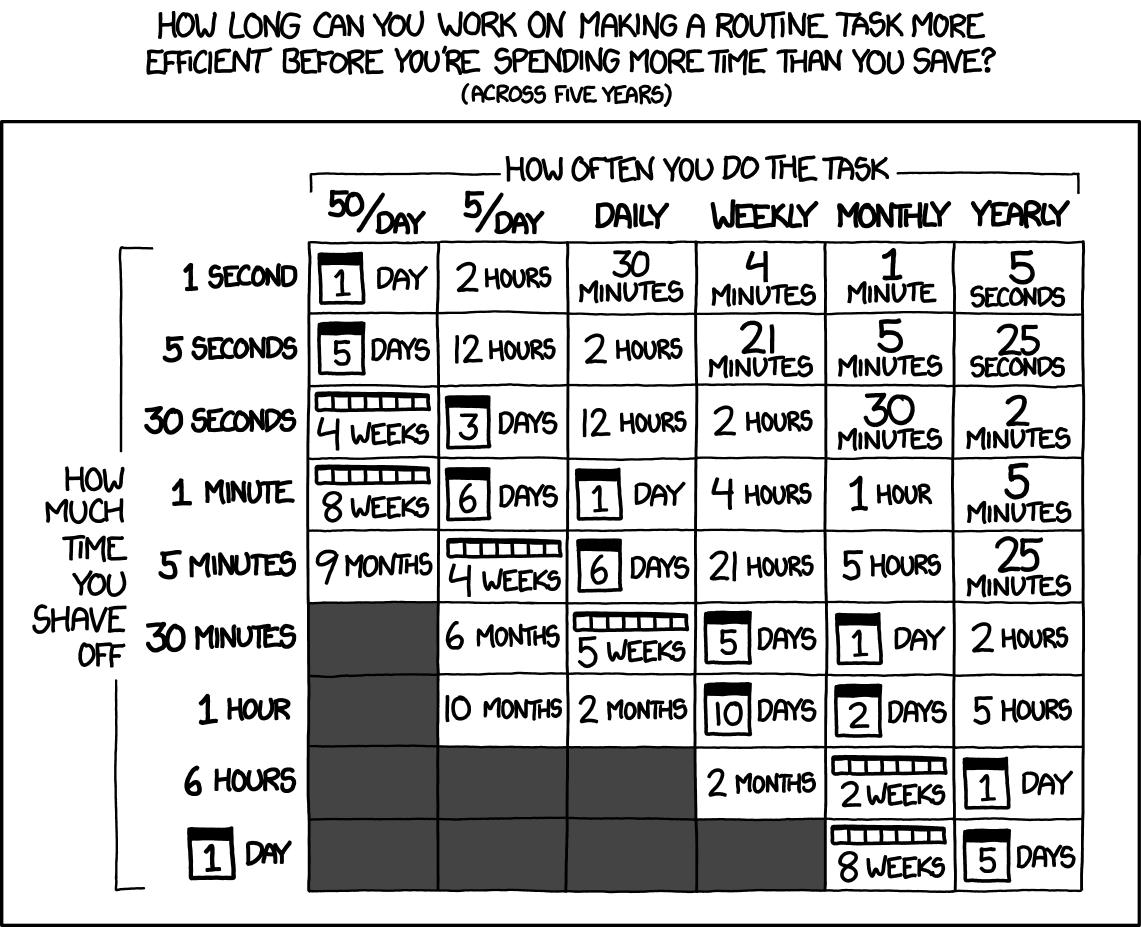
Just remember that there must be quite a lot of flexibility and opportunity for research in the work of a Data Science specialist. You do not manage the factory!
2.4. Data -> Power -> Policy
It is important to know the “political” context in which you work as a Data Science manager, especially in a large and complex organization. Managing a Data Science team means managing scarce and sought-after resources. This, in turn, means that you will sometimes have to engage in politics.

Some hypothetical examples are:
The Vice President intends to propose a new strategic initiative. She has a 98% presentation, but she wants help from your team to back up her proposal with data (... after the conclusions have already been made).
The business unit refuses to share data with your team, fearing that you will find something in the data that they do not know about.
The department insists that they need Data Science, but when you dig deeper, it turns out that there is no real need, only the motivation to increase staff.
Another team with a partly overlapping area of responsibility reluctantly shares the methodology for fear of stealing their work.
The amount of time you need to spend on such situations depends largely on the culture of your company and what incentives exist for people who behave in this way. But it's always good to know that this is happening.
My own naive belief is that transparency is the most powerful medicine. In practice, this means leading by example. All meeting notes are open to everyone in the company. All Slack channels are publicly available. The goals of the team (and individual too!) Are open to everyone in the company who wants to test them.
Transparency alone is not enough. You must actively work to build trust with your customers. It takes a lot of time to build trust, but it can be destroyed very quickly!
Now, to what extent should you immerse people in your team in politics? I would say as much as is absolutely necessary to understand the context of their work. This does not mean that you keep your people in the dark, but it does mean that they can focus on making excellent Data Science.
Do not let politics take too much of your attention. But keep in mind that when you have access to the data and the resources to gain value from it, you immediately get the power. And politics will always surround power.
2.5. Use your resources, strive for high ROI
So many companies are now hiring Data Science specialists. In many cases, these companies, in principle, have no idea why they will use them. But, of course, they can create some kind of magic, right?
If you bought a Ferrari, do not throw it in the garage.

In addition, do not use it only for the purchase of products.

Use your Ferrari for what it was built for.

Data Science Specialists are ambitious, smart, business people. This means that you have to make sure that they are working on problems that are not only complex, but have a high return on investment (ROI).
Here an important role is played by the Data Science manager. You must consistently combine the right set of business tasks with people on your team to help solve them.
Returning to our first point, there is a temptation to focus first on the problems that are associated with the greatest complexity. In my experience, you should first of all think about value when considering where to invest resources - that is, where to use people from your team. As mentioned earlier, complexity increases the cost, and you too must take this into account.
At the same time, Data Science specialists are attracted to challenging tasks. Thus, you need to remember about the balance. But the value that can be given to business, in my experience, is much more motivating than complexity itself.
2.6. OKR for focus and alignment
It is equally important to have good tools for both the manager and the Data Science specialist. And the most powerful manager tool is Objectives and Key Results (OKR). In short, OKR is the creation of several ambitious, qualitative goals and the comparison of quantitative key results with these goals. As a rule, you do this quarterly. OKR has a lot more, but the point is this.
OKR is very powerful, because in a simple way they guarantee that everyone knows exactly which direction we are going, and what we are trying to achieve.
They are also fascinating from the manager's point of view, because the OKR methodology is easy to learn, but surprisingly difficult to master. It usually takes a few quarters before you really get it right: how to install, track and check them.
There are two things that I find particularly helpful as a manager when it comes to OKR.
First: encourage everyone on your team to create personal OKR. Your personal OKR should take into account in aggregate what you, as a person, want to achieve in this quarter. When I say “in aggregate,” I mean your personal growth goals and your contribution to the organization and team around you. , . , .
LSTM ? , NLP-, , LSTM . ? . ? , .
OKR, .
, OKR . , .
-: OKR . , . , :
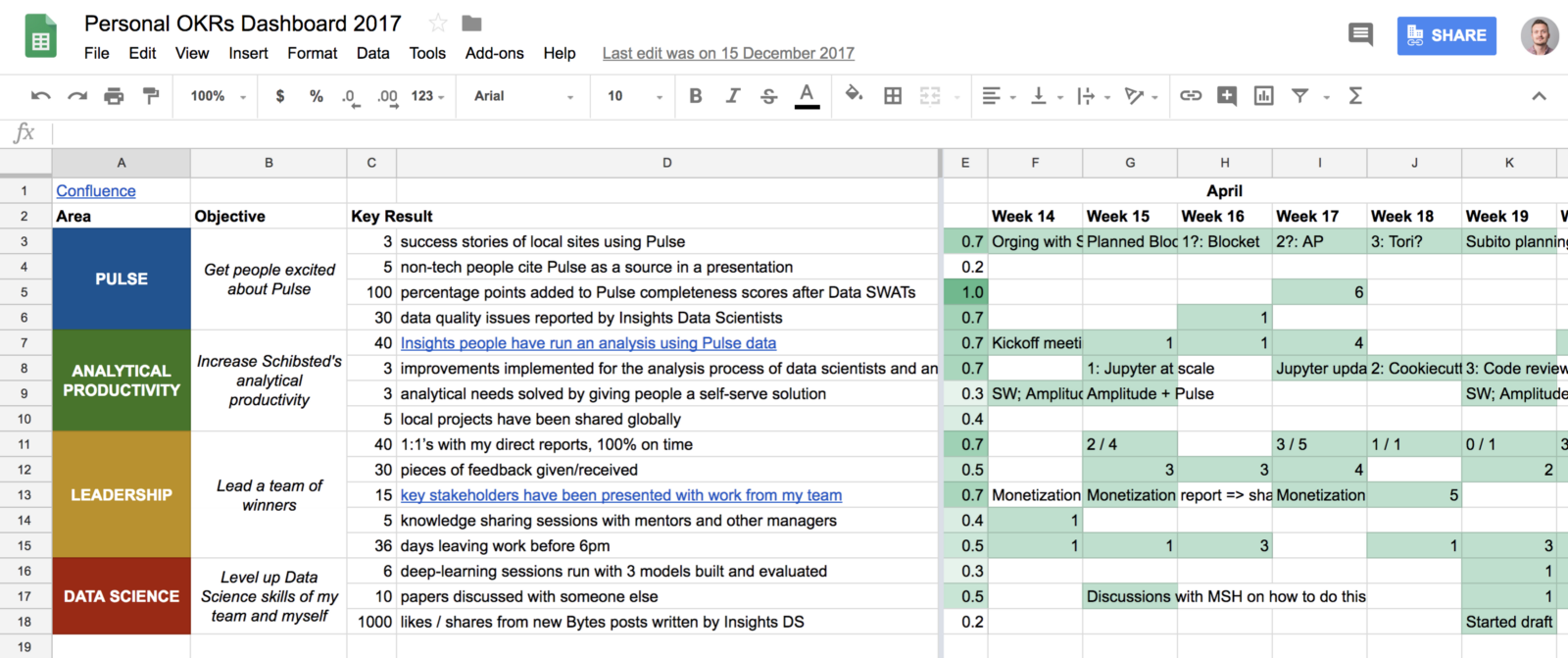
, , 10 , . , , ― . . OKR .
, , OKRs ― .
2.7.
.
Google , , , ― , , . .
, , , .
I. Data Science. , ? .
, Data Science. Schibsted , . , , , , . .
, . , , - .
«» Data Science ― .
? . , ― . , , . , :
- . , « » , . . , ! , ― .
- . , … . .
- . , . , , .
- . , ― , , .
- . , . , , , .
- . « » .
- . , . HR , Typeform , , . () , .
...
, ! , Data Science.
, :
I: Data Science
1.1. ,
1.2.
1.3. ,
1.4.
1.5.
1.6.Develop a detailed understanding of causality.
Part II: Managing the Data Science team.
2.1. The Data Science team is not really a team.
2.2. Embed Data Science specialists into other teams
2.3. Take responsibility for analytics performance
2.4. Data -> Power -> Policy
2.5. Use your resources, strive for high ROI
2.6. OKR for focus and alignment
2.7. First of all, psychological safety
...
Thanks for reading!If it was helpful, consider sharing this post with others. I hope to someday see your own thoughts about working as a Data Science specialist or manager.
')
Source: https://habr.com/ru/post/417497/
All Articles