Overview of text entry binding methods
Introduction
Some time ago, I became a participant in a project to develop a software product designed to analyze patient records and data on health status received from medical organizations with the aim of forming a single medical card. For a long time, the team could not develop an approach to combining patient data. The starting point was the study of the source codes of the Open EMPI (Open Enterprise Master Patient Index) solution, which pushed us to the string-like analysis algorithms. From this point on, a more in-depth study of the materials began, which made it possible to create a layout first and then a working solution.
So far, at various presentations, one has to hear a lot of questions about the logic of the work of such products, from which I conclude that a review of methods for linking text records will be interesting to a wide circle of readers.
The material is a translation of the wikipedia article “ Record linkage ” with copyright amendments.
What is text linking?
The term “linking text records” (record linkage) describes the process of attaching text records from one data source to records from another, provided that they describe the same object. In computer science, this is called “data matching” or “object identity problem . ” Sometimes alternative definitions are used, such as “identification” , “binding , “ duplicate detection ” , “ deduplication ” , “ record mapping ” , “ object identification ” , which describe the same concept. This terminological abundance led to the separation of approaches for processing and structuring information - linking records and linking data . Although they both define the identification of matching objects by different sets of parameters, the term “linking text records” is commonly used when it comes to “essence” of a person, while “data binding” means the possibility of linking any web resource between data sets, using accordingly the broader concept of the identifier, namely the URI.
Why do you need it?
When developing software products for building automated systems used in various fields related to the processing of human personal data (health care, history, statistics, education, etc.), it is necessary to identify data on accounting subjects coming from various sources.
However, when collecting descriptions from a large number of sources, problems arise that make it difficult for them to identify unambiguously. These problems include:
- typos;
- field permutations (for example, in the patronymic name);
- the use of abbreviations and abbreviations;
- the use of different formats of identifiers (dates, document numbers, etc.).
- phonetic distortions;
- etc.
The quality of the primary data directly affects the outcome of the binding process. Because of these problems, often data sets are sent to processing, which, although they describe the same object, these records look different. Therefore, on the one hand, all transferred record identifiers are evaluated for applicability to use in the identification process, and on the other hand, the records themselves are normalized or standardized in order to bring them into a single format.
History tour
The initial idea of linking records was expressed by Gilbert Dunn (Halbert L. Dunn), publishing in 1946 an article in the American Journal of Public Health entitled “Record Linkage”.
Later, in 1959, the article "Automatic Linkage of Vital Records" in the journal Science, Howard B. Newcombe laid the probabilistic basis of the modern theory of string binding, which in 1969 was developed and consolidated by Ivan Fellegi and Alan Santer (Alan Sunter). Their work “A Theory For Record Linkage” is still a mathematical rationale for many binding algorithms.
The main development of the algorithms received in the 90s of the last century. Then from different areas (statistics, archives, epidemiology, history, and others) algorithms that are now used in software products, such as the Jaro-Winkler (Jaro-Winkler distance) similarity ( distance) and Levenshtein distance, came to us. However, some solutions, such as the Soundex phonetic algorithm, appeared much earlier - in the 20s of the last century.
Text entry comparison algorithms
There are deterministic and probabilistic algorithms for comparing text entries. The deterministic algorithms are based on the complete coincidence of the attributes of the records. Probabilistic algorithms allow one to calculate the degree of correspondence of the attributes of records and on the basis of this to decide on the possibility of their connection.
Deterministic Algorithms
The easiest way to compare strings is based on clear rules, when links between objects are generated based on the number of matching attributes of data sets. That is, two entries match each other through a deterministic algorithm if all or some of their attributes are identical. Deterministic algorithms are suitable for comparing subjects described by a data set that are identified by a common identifier (for example, the Insurance number of an individual personal account in the Pension Fund - SNILS) or have several representative identifiers (date of birth, gender, etc.) that can be trusted.
It is possible to apply deterministic algorithms when clearly structured (standardized) data sets are passed to processing.
For example, it has the following set of text entries:
| No | SNILS | Name | Date of Birth | Floor |
|---|---|---|---|---|
| A1 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M |
| A2 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M |
| A3 | 126-029-036 24 | Ilchenko Victor | 01/02/1937 | M |
| A4 | Novikova Clara | 12.26.1946 | F |
| No | SNILS | Name | Date of Birth | Floor |
|---|---|---|---|---|
| B1 | 126-029-036 24 | Ilyichenko Victor | 01/02/1937 | M |
| B2 | Zhivanetsky Mikhail | 03/06/1934 | M | |
| B3 | Zerchaninova Klara | 12.26.1946 | 2 |
It was said earlier that the simplest deterministic algorithm is the use of a unique identifier, which is supposed to uniquely identify a person. For example, we will assume that all records that have the same identifier value (SNILS) are described by the same subject, otherwise they are different subjects. The deterministic connection in this case will generate the following pairs: A1 and A2, A3 and B1. B2 will not be associated with A1 and A2, since it does not have an identifier value, although it coincides in content with the indicated entries.
These exceptions lead to the need to supplement the deterministic algorithm with new rules. For example, in the absence of a unique identifier, you can use other attributes such as name, date of birth and gender. In the above example, this additional rule again does not give a match B2 and A1 / A2, because now the names differ - there is a phonetic distortion of the last name.
This problem can be solved using the methods of phonetic analysis, but when changing the name (for example, in the case of marriage), you will need to resort to applying the new rule, for example, comparing the date of birth or allow differences in the available attributes of the record (for example, gender).
The example clearly illustrates that the deterministic algorithm is very sensitive to the quality of the data, and an increase in the number of attributes of records can lead to a significant increase in the number of applied rules, which greatly complicates the use of deterministic algorithms.
Moreover, the use of deterministic algorithms is possible, if there is a verified data set (master directory) with which the incoming information is compared. However, in the case of a constant replenishment of the master directory itself, it may be necessary to completely restructure existing links, which makes the use of deterministic algorithms time-consuming or simply impossible.
Probabilistic algorithms
Probabilistic algorithms for linking string records use a wider set of attributes than deterministic ones, and for each attribute a weighting factor is calculated that determines the ability to influence the connection in the final assessment of the probability of conformity of the estimated records. Entries with a final weight above a certain threshold are considered linked, records with a final weight below the threshold are considered unrelated. Couples that score the value of the total weight from the middle of the range are considered candidates for binding and can be considered later (for example, by the operator), who will decide to merge (link) or leave unrelated. Thus, unlike deterministic algorithms, which are a set of a large number of clear (programmed) rules, probabilistic algorithms can be adapted to the quality of data by selecting threshold values and do not require reprogramming.
So, probabilistic algorithms assign weight coefficients ( u and m ) to attributes of the record, with the help of which their conformity or non-conformity with each other will be determined.
The coefficient u determines the probability that the identifiers of two independent entries coincide randomly. For example, the u-probability of the month of birth (when there are twelve equally distributed values) will be 1 \ 12 = 0.083. Identifiers with values that are unevenly distributed will have different probabilities for different values (sometimes including missing values).
The coefficient m is the probability that the identifiers in the compared pairs match each other or are quite similar - for example, in the case of high probability using the Jaro-Winkler algorithm or low probability using the Lowenstein algorithm. In the case of full compliance of attributes of records, this value should be set to 1.0, but given the low probability of this, the coefficient should be estimated differently. This assessment can be made on the basis of a preliminary analysis of a data set, for example, by manually “learning” a probabilistic algorithm when identifying a large number of matching and mismatching pairs or by iteratively launching an algorithm to select the most appropriate m-coefficient value.
If the m-probability is defined as 0.95, then the correspondence coefficients \ discrepancies for the month of birth will look like this:
| Metrics | Share links | Percentage of values, not references | Frequency | Weight |
|---|---|---|---|---|
| Conformity | m = 0.95 | u = 0.083 | m \ u = 11.4 | ln (m / u) / ln (2) ≈ 3.51 |
| Mismatch | 1-m = 0.05 | 1-u = 0.917 | (1-m) / (1-u) ≈ 0.0545 | ln ((1-m) / (1-u)) / ln (2) ≈ -4.20 |
Similar calculations should be made for other record identifiers in order to determine their compliance and non-compliance rates. Then, each identifier of one record is compared with the corresponding identifier of another record to determine the total weight of the pair: the weight of the corresponding pair is added to the total result with a cumulative total, while the weight of the non-corresponding pair is subtracted from the total result. The resulting amount is compared with the identified thresholds to determine whether to bind or not bind the analyzed pair automatically or pass it on to the operator.
Blocking
Determining the compliance \ mismatch thresholds is the balance between obtaining acceptable sensitivity (the proportion of related records detected by the algorithm) and the predictive value of the result (i.e. accuracy, as measures of the actually matching each other's records related by the algorithm). Since the determination of thresholds can be a very difficult task, especially for large data sets, a method known as blocking is often used to increase the efficiency of calculations. Attempts to perform a comparison between records for which significant discrepancies ( discrimination ) in the values of basic attributes are detected are blocked. This leads to an increase in accuracy due to a decrease in sensitivity.
For example, locking based on phonetic coding of the last name reduces the total number of comparisons required and increases the likelihood that the links between the records will be correct, since the two attributes are already consistent, but could potentially miss the entries related to the same person whose last name is changed (for example, as a result of marriage). The month of birth lock is a more stable indicator that can be adjusted only if there is an error in the source data, but provides a more modest benefit in positive predictive value and loss of sensitivity, since it creates twelve different groups of extremely large data sets and does not increase the speed calculations
Thus, the most effective systems for linking text records often use several blocking passes to group data in various ways in order to prepare groups of records that must later be passed on for analysis.
Machine learning
Recently, various methods of machine learning have been used to link text entries. In his work, published in 2011, Randall Wilson showed that the classical algorithm for the probabilistic linking of text records is equivalent to the naive Bayes algorithm and experiences the same problems from the assumption of independence of classification features. To improve the accuracy of the analysis, the author proposes to use the basic model of a neural network called a single-layer perceptron, the use of which allows one to substantially exceed the results obtained using traditional probabilistic algorithms.
Phonetic coding
Phonetic algorithms match the same codes to two words that are similar in pronunciation, which allows comparison of such words based on their phonetic similarity.
Most phonetic algorithms are designed to analyze words of the English language, although recently some algorithms have been modified for use with other languages, or were originally created as national solutions (for example, Caverphone).
Soundex
The classic algorithm for comparing two strings by their sound is Soundex (short for Sound index). It sets the same code for strings that have similar sound in English. Soundex was originally used by the National Archives Administration in the 1930s to retrospectively analyze population censuses from 1890 to 1920.
The authors of the algorithms are Robert Russell (Robert C. Russel) and Margaret King Odell (Margaret King Odell), who patented it in the 20s of the last century. The algorithm itself became popular in the second half of the last century when it became the subject of several articles in popular science journals in the USA and was published in D. Knut's monograph “The Art of Programming”.
Daitch-Mokotoff Soundex
Since Soundex is only suitable for English, some researchers have attempted to modify it. In 1985, Gary Mokotoff and Randy Daitch proposed a variant of the Soundex algorithm, designed to match Eastern European (including Russian) surnames with a fairly high quality.
Metaphone
In the 90s, Lawrence Philips (Lawrence Philips) proposed an alternative variant of the Soundex algorithm, which was called Metaphone. The new algorithm used a larger set of English pronunciation rules due to which it was more accurate. Later, the algorithm was modified to be used in other languages based on transcription using the letters of the Latin alphabet.
Russian Metaphone
In 2002, an article by Pyotr Kankowski was published in the 8th edition of the Programmer magazine, telling about his adaptation of the English version of the Metaphone algorithm. This version of the algorithm transforms the original words in accordance with the rules and norms of the Russian language, taking into account the phonetic sound of unstressed vowels and possible “mergers” of consonants in pronunciation.
Instead of conclusion
As a result of several iterations, the project team for the development of a software product, which was mentioned in the introduction, produced an architectural solution, the scheme of which is shown in the figure.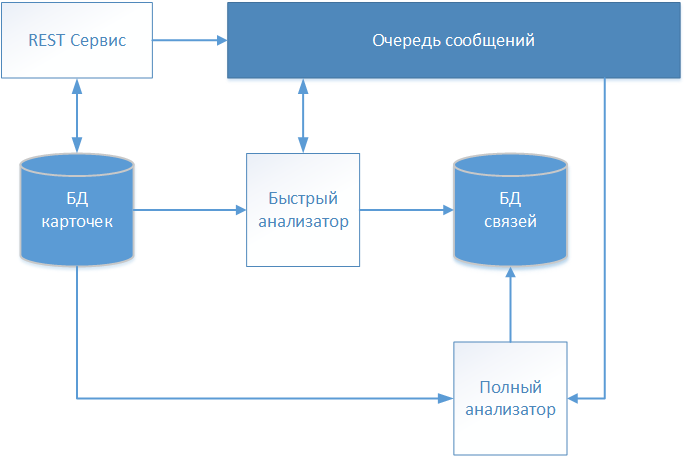
Textual descriptions of patients are accepted through the REST service and stored in the repository (card database) without any changes. Since our system works with medical data, the FHIR (Fast Healthcare Interoperability Resources) standard was chosen for information exchange. Information about the received patient card is transferred to the message queue for further analysis and decision making about establishing a connection.
The first card is processed by the “Fast Analyzer” operating according to a deterministic algorithm. If all the rules of the deterministic algorithm have worked, then it creates a record in a separate storage (DB of links) with reference to the card being processed. The record contains, in addition to the identifier of the analyzed card, the date of connection and a conditional identifier that identifies the globally-identified patient. Other cards are further referenced to this global identifier, thereby forming an array describing a specific individual.
If the deterministic algorithm has not found a match, then the card information is transmitted via the message queue to the “Full analyzer”.
The full analyzer implements a mixed comparison algorithm (probabilistic and deterministic). The work of the complete analyzer consists of a series of successive stages. In some simplification, the stages can be represented as follows:

Stage 1. Selection of candidate cards
At this stage, using phonetic algorithms from the database of cards, those in which names similar in sound are found are selected. An array of selected cards after normalization is transferred to the processing stage 2.
Stage 2. Name Analysis
Using the Jaro-Winkler algorithm, we determine the probability of specifying names in the compared cards that refer to the same individual (patient).
Stage 3. Identifier Analysis
Next, the matching of other attributes of the patient record, such as passport numbers, MHI (compulsory health insurance) and SNILS, as well as gender and date of birth, is analyzed.
Stage 4. Final similarity score
At the final step, the points obtained during the analysis at each of the stages are summed up. The total value is compared with the empirically obtained boundary values. If the sum of points is higher than the bounding bound, then a record is created in the link store, similar to the logic of the fast analyzer. If the sum of points is lower than the bounding limit, but higher than the limit that uniquely determines the difference between cards, then the analyzed card is transferred to a visual assessment by the system operator.
')
Source: https://habr.com/ru/post/417465/
All Articles