Database development in Dropbox. The path from one global MySQL database to thousands of servers
When only Dropbox was launched, one user at Hacker News commented that you can implement it with several bash scripts using FTP and Git. Now this can not be said at all, it is a large cloud file storage with billions of new files every day, which are not just stored in the database somehow, but so that any database can be restored to any point in the last six days.
Under the cut is the transcript of the report of Glory Bakhmutov ( m0sth8 ) on Highload ++ 2017, how the databases in Dropbox have evolved and how they are organized now.
About the speaker: Slava Bakhmutov is a site reliability engineer on the Dropbox team, she loves Go very much and sometimes appears in the golangshow.com podcast.
')
Content
Dropbox appeared in 2008. In essence, this is a cloud file storage. When Dropbox was launched, the user at Hacker News commented that you can implement it with several bash scripts using FTP and Git. But, nevertheless, Dropbox is developing, and now it is a fairly large service with more than 1.5 billion users, 200 thousand businesses and a huge number (several billion!) Of new files every day.
What does Dropbox look like?
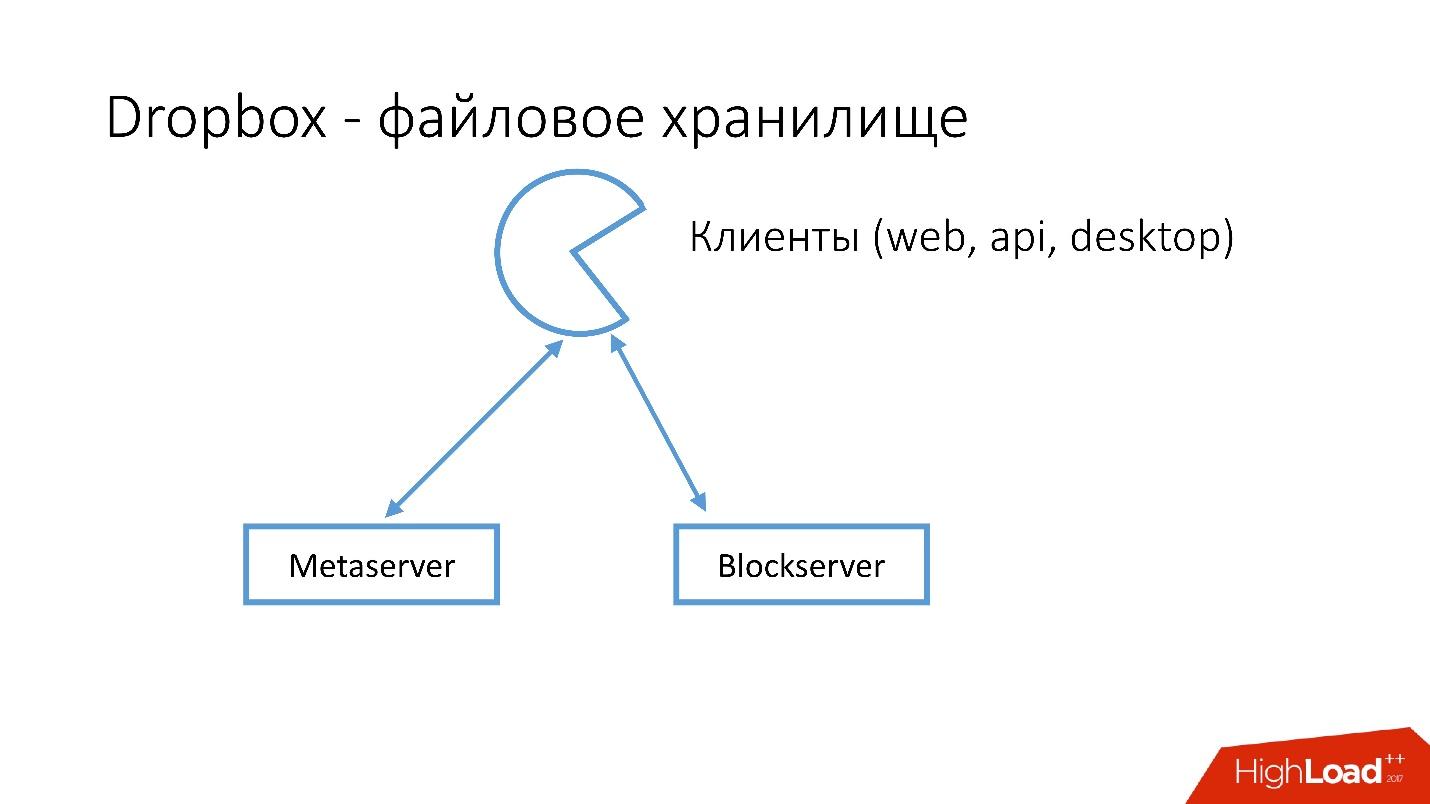
We have several clients (web interface, API for applications that use Dropbox, desktop applications). All these clients use the API and communicate with two large services, which can logically be divided into:
Metaserver stores meta information about a file: size, comments to it, links to this file in Dropbox, etc. The Blockserver stores information only about files: folders, paths, etc.
How it works?
For example, you have a video.avi file with some kind of video.
 Link from the slide
Link from the slide
 Link from the slide
Link from the slide
 Link from the slide
Link from the slide
Of course, this is a very simplified scheme, the protocol is much more complicated: there is synchronization between clients within the same network, there are kernel drivers, the ability to resolve collisions, etc. This is a rather complicated protocol, but schematically it works something like this.

When a client saves something on Metaserver, all the information goes into MySQL. Blockserver information about files, how they are structured, which blocks they consist of, also stores in MySQL. Also, the Blockserver stores the blocks themselves in Block Storage, which, in turn, also stores information about where the block is, on which server, and how it is processed at the moment, in MYSQL.
How did the database in Dropbox evolve?

In 2008, it all started with one Metaserver and one global database. All the information that Dropbox needed to be saved somewhere, it saved to a single global MySQL. This did not last long, because the number of users grew, and individual bases and tablets inside the bases swelled faster than others.

Therefore, in 2011 several tables were moved to separate servers:
But after 2012, Dropbox began to grow very much, since then we have grown by about 100 million users a year .
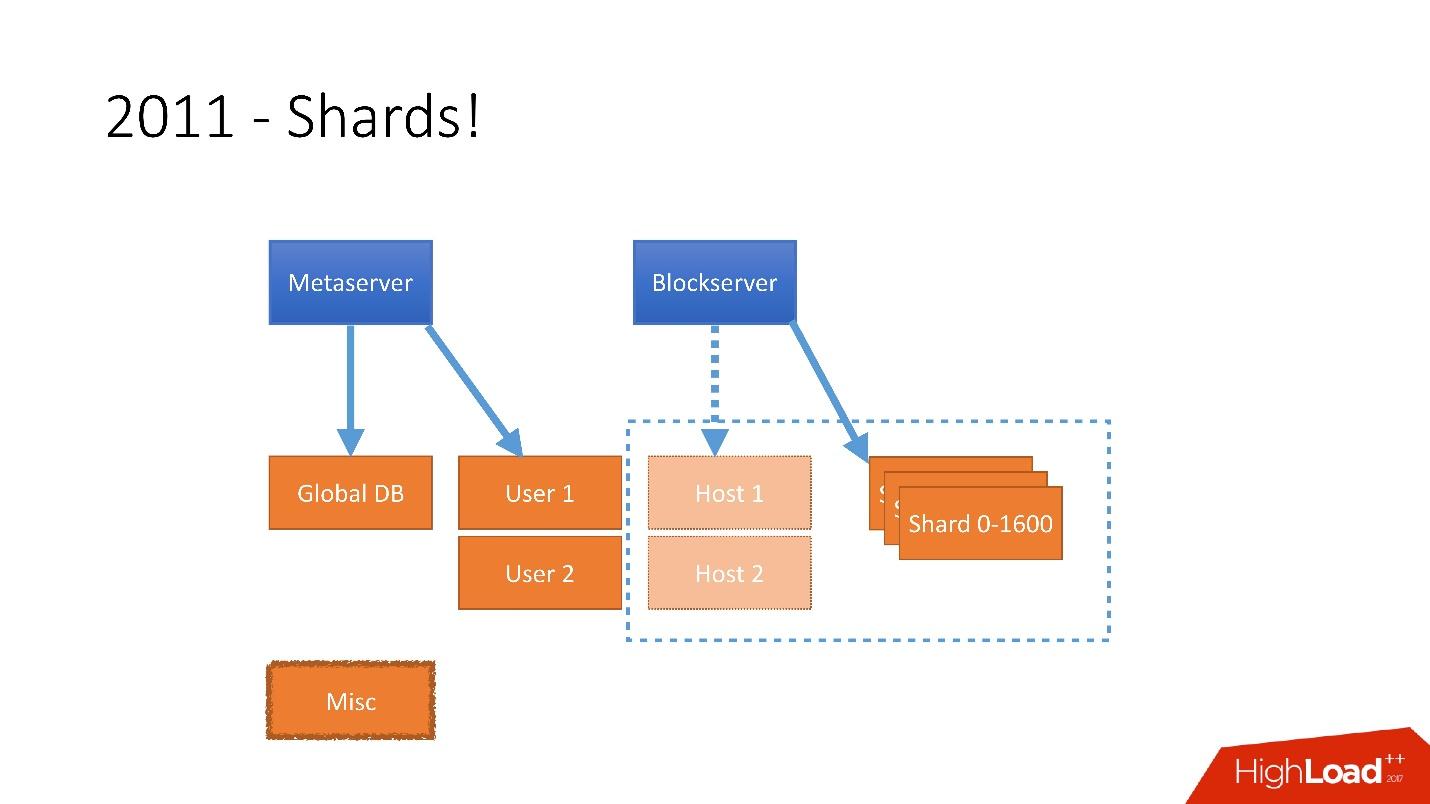
It was necessary to take into account such a huge growth, and therefore at the end of 2011 we had shards - the base consisting of 1,600 shards. Initially, only 8 servers with 200 shards each. Now it’s 400 master servers with 4 shards each.
 Link from the slide
Link from the slide
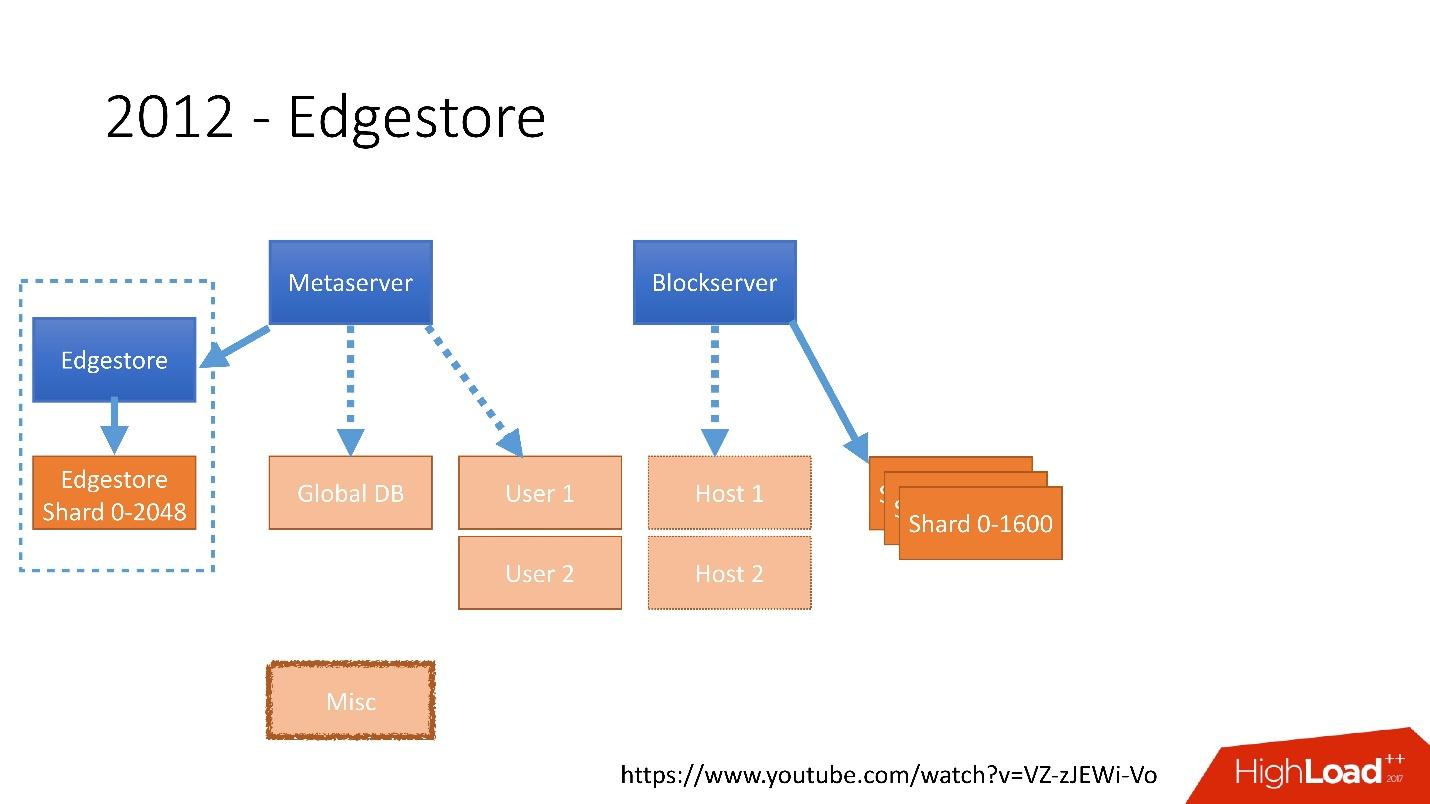
In 2012, we realized that creating tables and updating them in the database for each added business logic is very difficult, dreary and problematic. Therefore, in 2012, we invented our own graph storage, which we called Edgestore , and since then all the business logic and meta information that the application generates is stored in Edgestore.
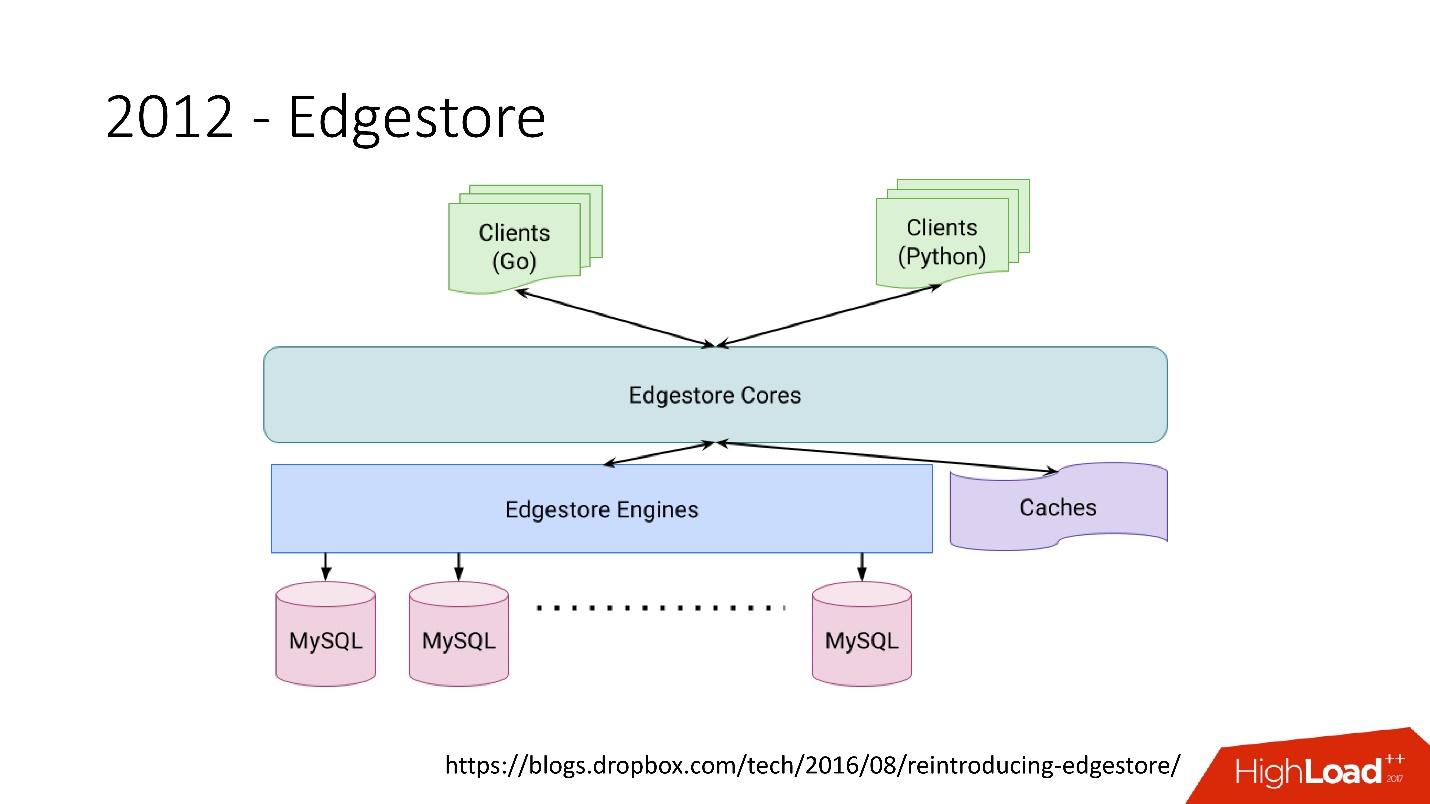
Edgestore, in fact, abstracts MySQL from clients. Clients have certain entities that are interconnected by links from the gRPC API to Edgestore Core, which converts this data to MySQL and somehow stores it there (basically it gives all this from the cache).
 Link from the slide
Link from the slide
In 2015, we left Amazon S3 , developed our own cloud storage called Magic Pocket. It contains information about where the block file is located, on which server, about the movement of these blocks between servers, is stored in MySQL.
 Link from the slide
Link from the slide
But MySQL is used in a very tricky way - in fact, as a large distributed hash table. This is a very different load, mainly on reading random entries. 90% recycling is I / O.
First, we immediately identified some principles by which we build the architecture of our database:
All principles must be verifiable and measurable , that is, they must have metrics. If we are talking about the cost of ownership, then we must calculate how many servers we have, for example, it goes under the database, how many servers it goes under the backups, and how much it costs for Dropbox. When we choose a new solution, we count all the metrics and focus on them. When choosing any solution, we are fully guided by these principles.
The database is organized approximately as follows:
This topology is chosen because if we suddenly die the first data center, then in the second data center we already have almost complete topology . We simply change all addresses in Discovery, and customers can work.
We also have specialized topologies.
Topology Magic Pocket consists of one master-server and two slave-servers. This is done because Magic Pocket itself duplicates data among the zones. If it loses one cluster, it can recover all data from other zones via erasure code.

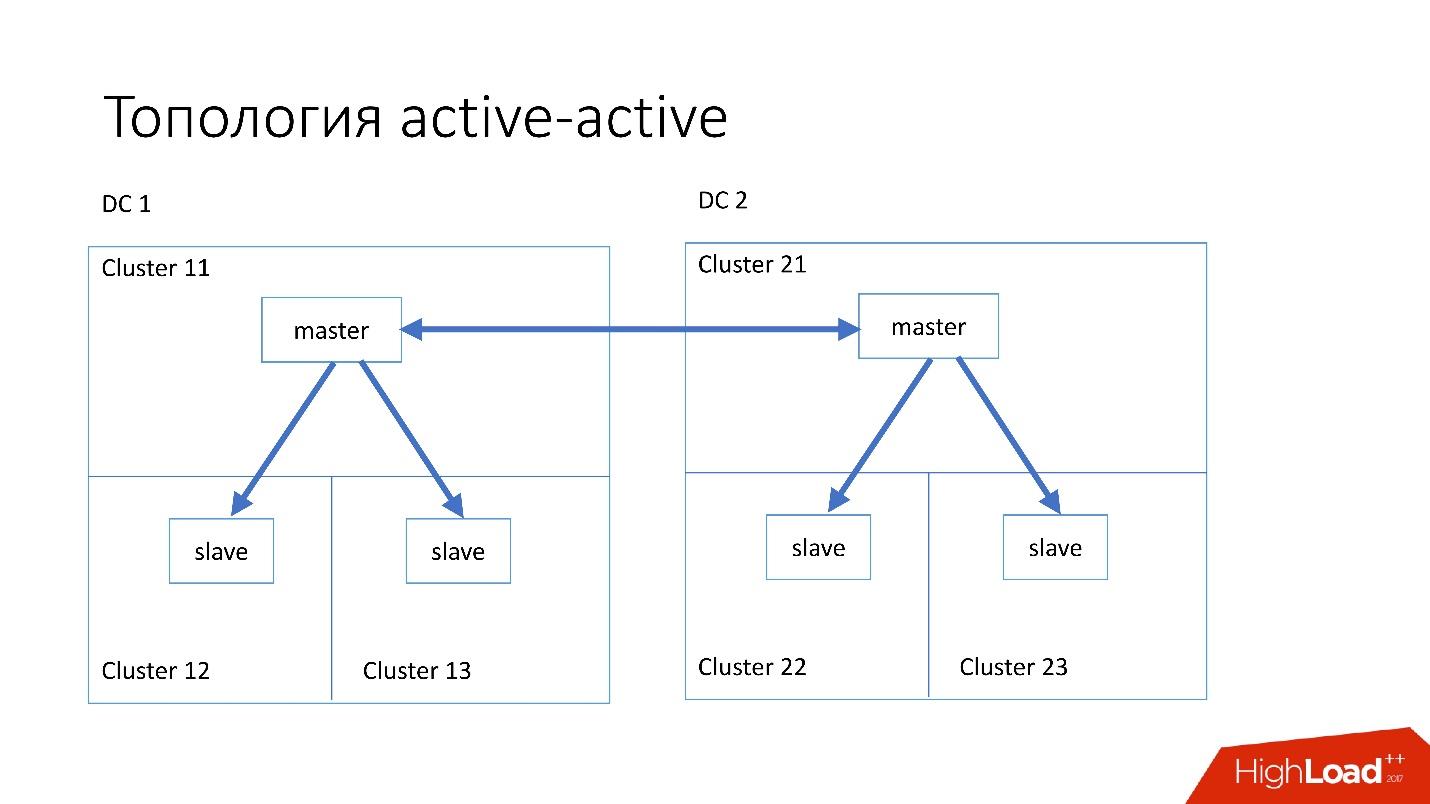
Active-active topology is a custom topology that is used in Edgestore. It has one master and two slaves in each of the two data centers, and they are slaves for each other. This is a very dangerous scheme , but Edgestore at its level knows exactly what data to which master at which range it can write. Therefore, this topology does not break.
We have installed fairly simple servers with a configuration of 4-5 years old:
* Raid 0 - because it is easier and faster for us to replace the whole server than the disks.
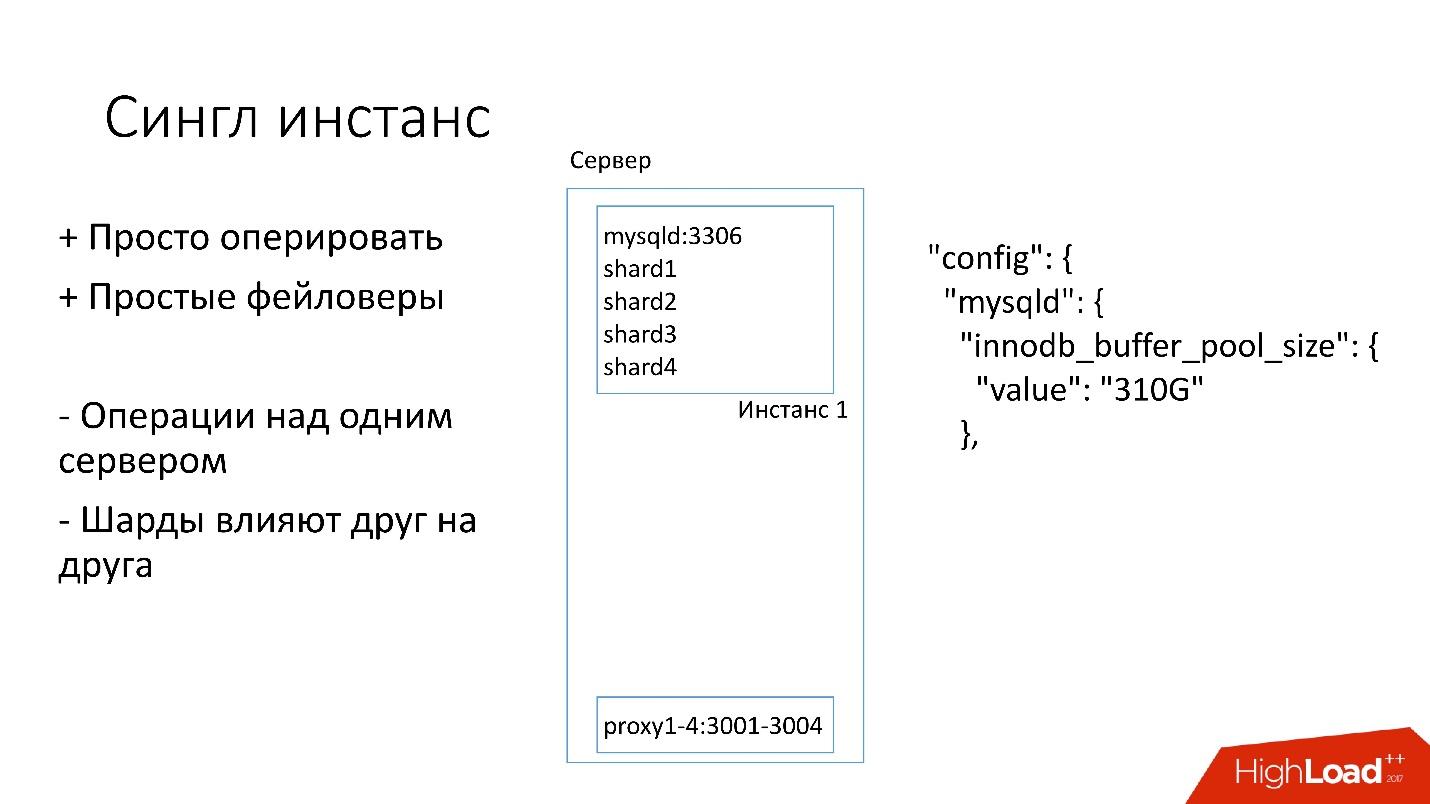
On this server, we have one big MySQL instance, on which there are several shards. This MySQL instance immediately allocates to itself almost all the memory. Other processes are running on the server: proxy, statistics collection, logs, etc.
This solution is good because:
+ It's easy to manage . If you need to replace MySQL instance, simply replace the server.
+ Just make faylover .
On the other hand:
- It is problematic that any operations occur on the whole MySQL instance and immediately on all shards. For example, if you need to make a backup, we make a backup of all shards at once. If you need to make a faylover, we make a faylover of all four shards at once. Accordingly, accessibility suffers 4 times more.
- Problems with replication of one shard affect other shards. Replication in MySQL is not parallel, and all shards work in one stream. If something happens to one shard, then the rest are also victims.
Therefore, we are now switching to another topology.

In the new version, several MySQL instances are running on the server at once, each with one shard. What is better?
+ We can carry out operations only on one particular shard . That is, if you need a faylover, switch only one shard, if you need a backup, make a backup of only one shard. This means that operations are greatly accelerated - 4 times for a four-shard server.
+ Shards almost don't affect each other .
+ Improved replication. We can mix different categories and classes of databases. Edgestore takes up a lot of space, for example, all 4 TB, and Magic Pocket only takes 1 TB, but it has 90% utilization. That is, we can combine various categories that use I / O and machine resources in different ways, and run 4 replication threads.
Of course, this solution has some disadvantages:
- The biggest minus is much harder to manage all this . We need some kind of smart planner who will understand where he can take this instance, where the optimal load will be.
- Harder faylover .
Therefore, we are only now switching to this decision.
Clients must somehow know how to connect to the right database, so we have Discovery, which should:
At first everything was simple: the address of the database in the source code in the config. When we needed to update the address, it was just that everything deployed very quickly.

Unfortunately, this does not work if there are a lot of servers.
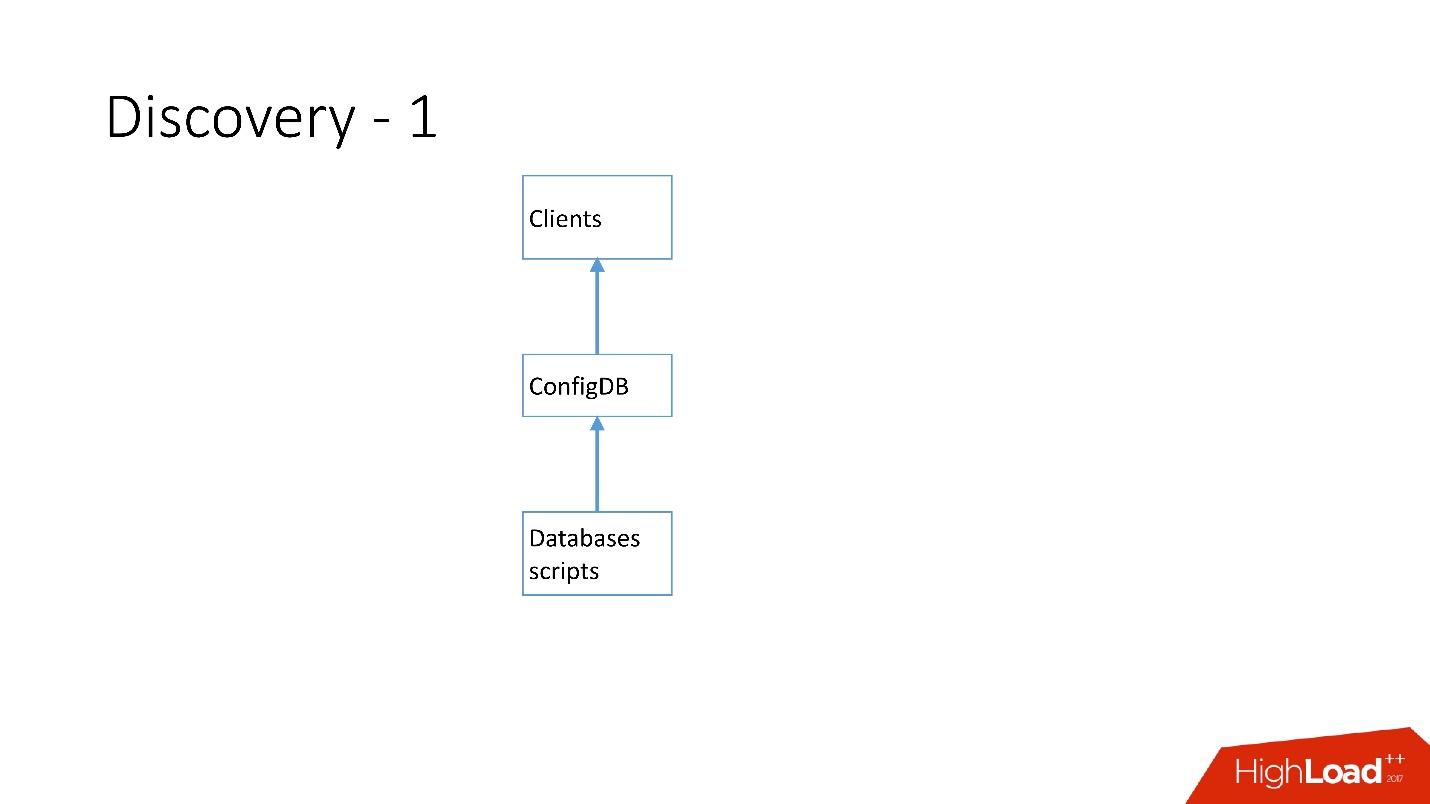
Above is the very first Discovery, which we had. There were database scripts that changed the label in ConfigDB — it was a separate MySQL table, and clients already listened to this database and periodically took data from there.

The table is very simple; there is a database category, a shard key, a master / slave database class, a proxy, and a database address. In fact, the client requested a category, database class, shard key, and he was returned a MySQL address at which he could already establish a connection.
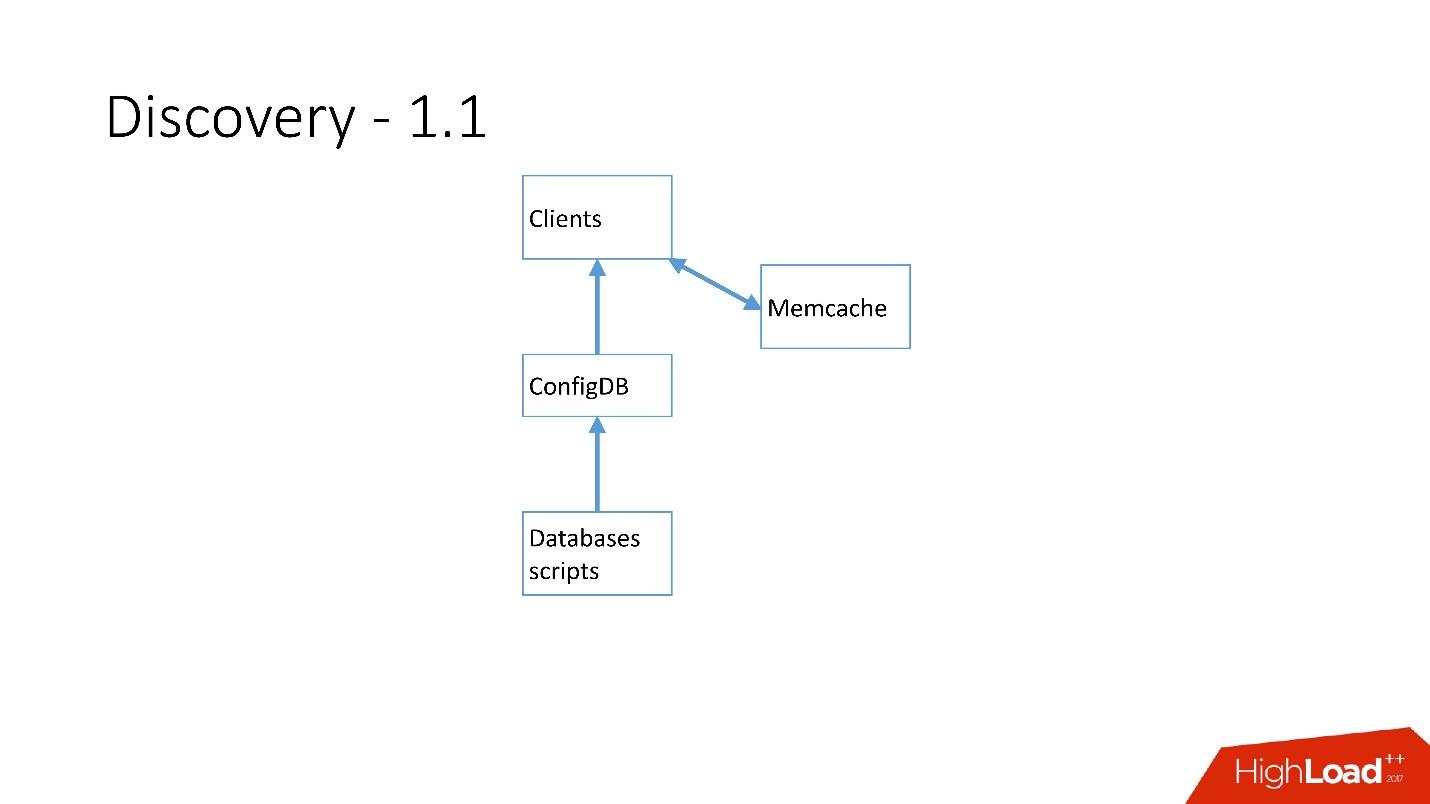
As soon as there were a lot of servers, Memcash was added and clients began to communicate with him.
But then we reworked it. MySQL scripts began to communicate through gRPC, through a thin client with a service that we called RegisterService. When some changes occurred, the RegisterService had a queue, and he understood how to apply these changes. RegisterService saved data in AFS. AFS is our internal system, built on the basis of ZooKeeper.

The second solution, which is not shown here, directly used ZooKeeper, and this created problems because every shard was a node in ZooKeeper. For example, 100 thousand clients connect to ZooKeeper, if they suddenly died because of some kind of bug all together, then 100 thousand requests will immediately come to ZooKeeper, which will simply drop it, and it will not be able to rise.
Therefore, the AFS system was developed , which is used by the entire Dropbox . In fact, it abstracts the work with ZooKeeper for all clients. The AFS daemon locally rotates on each server and provides a very simple file API of the form: create a file, delete a file, request a file, receive notification of file changes, and compare and swap operations. That is, you can try to replace the file with some version, and if this version has changed during the shift, the operation is canceled.
Essentially, such an abstraction over ZooKeeper, in which there is a local backoff and jitter algorithms. ZooKeeper no longer falls under load. With AFS, we remove backups in S3 and in GIT, then the local AFS itself notifies customers that the data has changed.

In AFS, data is stored as files, that is, it is a file system API. For example, the shard.slave_proxy file is the largest, it takes about 28 Kb, and when we change the shard category and the slave_proxy class, all clients that are subscribed to this file receive a notification. They re-read this file, which has all the necessary information. By shard key get the category and reconfigure the connection pool to the database.
We use very simple operations: promotion, clone, backups / recovery.
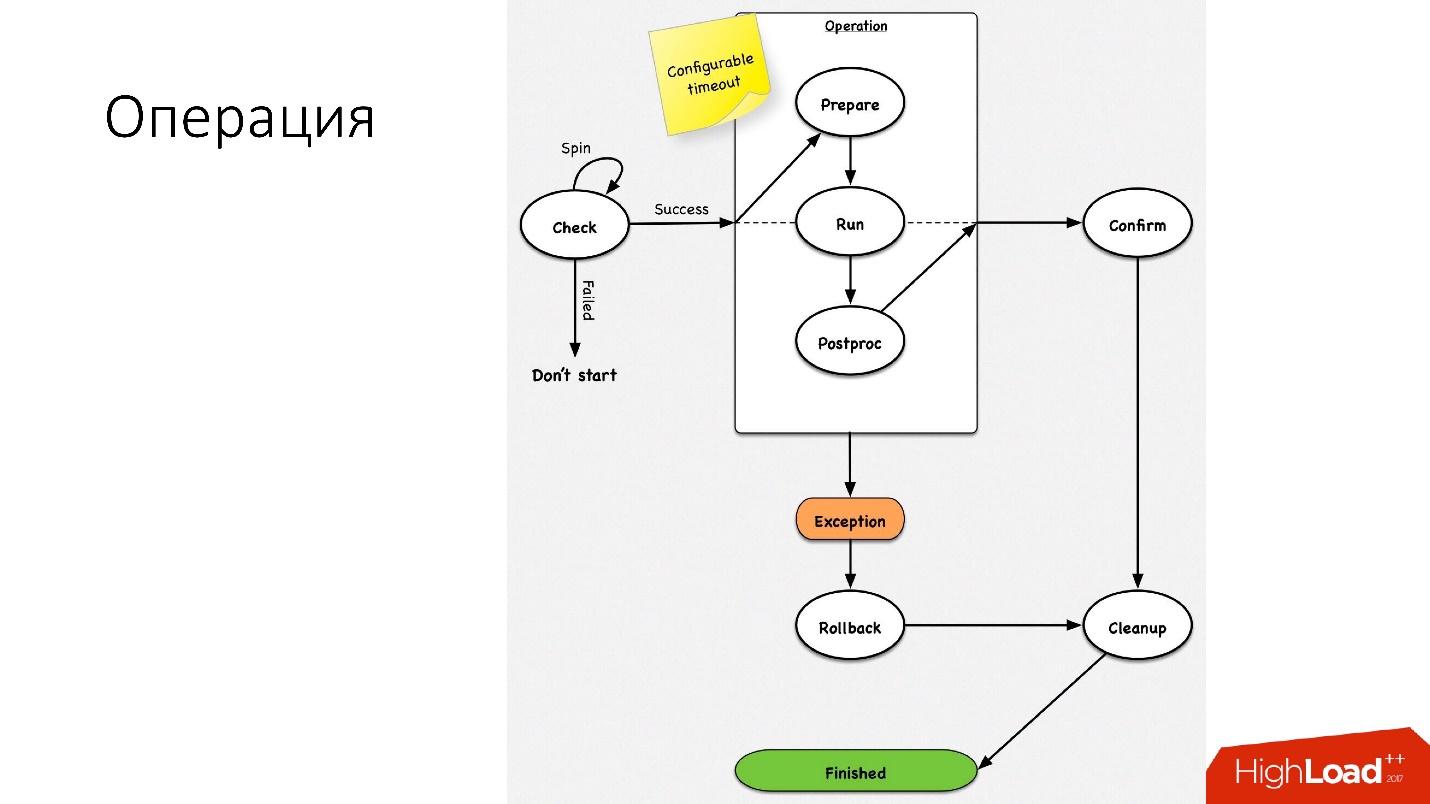
The operation is a simple state machine . When we go into an operation, we perform some checks, for example, a spin-check, which checks on timeouts several times whether we can perform this operation. After that, we do some preparatory action that does not affect external systems. The actual operation itself.
All steps inside the operation have a rollback step (undo). If there is a problem with the operation, the operation tries to restore the system to its original position. If everything is normal, then a cleanup occurs, and the operation is completed.
We have such a simple state machine for any operation.
This is a very frequent operation in the database. There were questions about how to do alter on a hot master-server that works - he will get a stake. Simply, all these operations are performed on slave-servers, and then the slave changes with master places. Therefore, the promotion operation is very frequent .

We need to update the kernel - we are doing swap, we need to update the version of MySQL - we update to the slave, we switch to master, we update there.

We have achieved a very fast promotion. For example, we have for four shards now a promotion of the order of 10-15 s. The graph above shows that when the promotion availability suffered by 0.0003%.
But normal promotion is not so interesting, because it is the usual operations that are performed every day. Faylover interesting.
Failover (replacement of a broken master)
Failover means that the database is dead.
We replace the deceased master servers about 2-3 times a day , this is a fully automated process, no human intervention is needed. The critical section takes about 30 seconds, and it has a bunch of additional checks on whether the server is actually alive, or maybe it has already died.
Below is an exemplary diagram of how filer works.

In the selected section, we reboot the master server . This is necessary because we have MySQL 5.6, and in it semisync replication is not lossless. Therefore phantom reads are possible, and we need this master, even if it is not dead, to kill it as soon as possible so that the clients disconnect from it. Therefore, we do a hard reset via Ipmi - this is the first most important operation we need to do. In MySQL version 5.7, this is not so critical.
Cluster sync. Why do we need cluster synchronization?
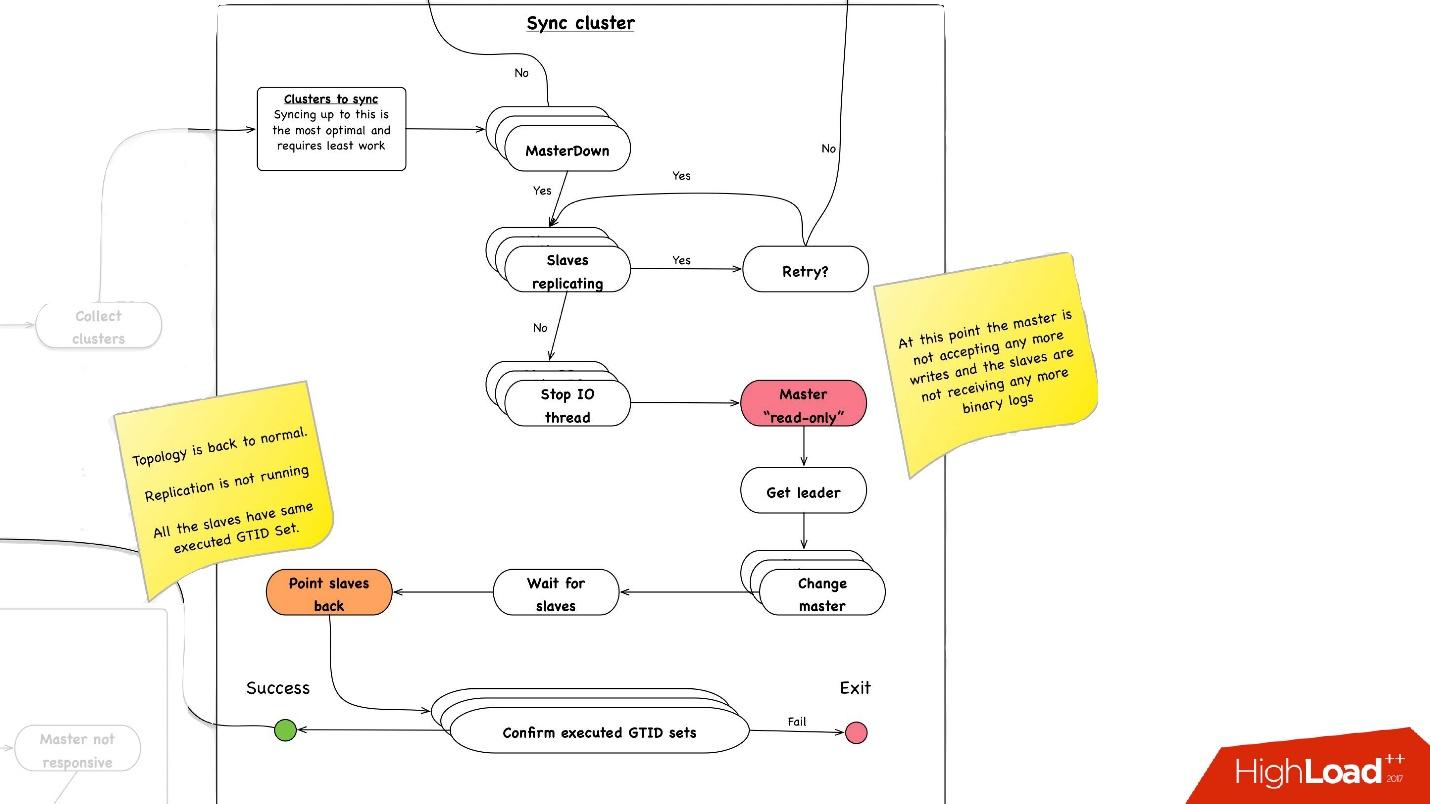
If we recall the previous picture with our topology, one master server has three slave servers: two in one data center, one in the other. With the promotion, we need the master to be in the same main data center. But sometimes, when the slave is loaded, with semisync it happens that the semisync-slave becomes a slave in another data center, because it is not loaded. Therefore, we need to synchronize the entire cluster first, and then make a promotion on the slave in the data center we need. This is done very simply:
The second important operation is cluster synchronization . Then begins the promotion , which happens as follows:
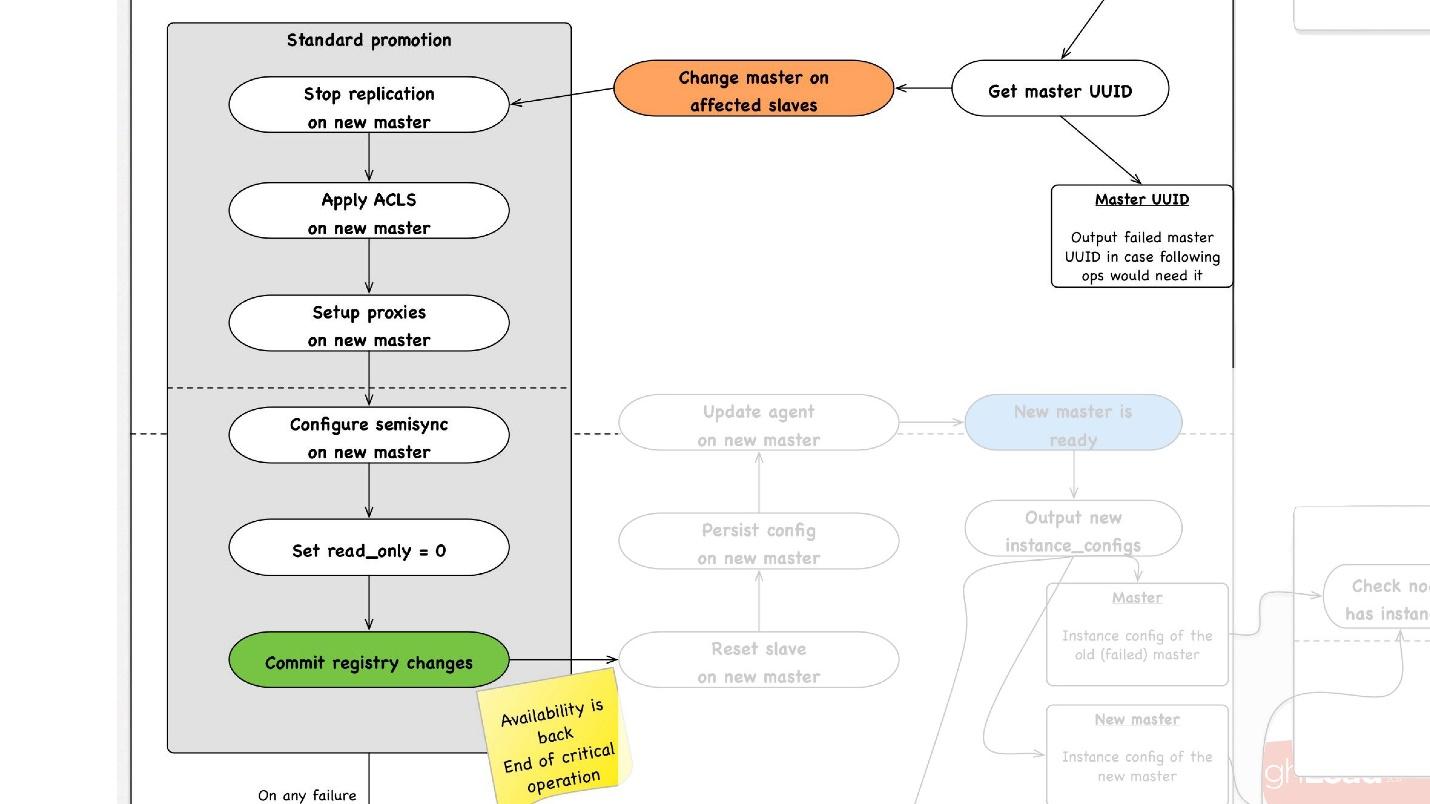
At any step, in case of an error, we are trying to rollback to the point we can. That is, we cannot rollback to reboot. But for operations for which this is possible, for example, reassignment - change master - we can return master to the previous step.
Backups are a very important topic in databases. I do not know if you are making backups, but it seems to me that everyone should do them, this is already a beaten joke.
Patterns of use
● Add a new slave
The most important pattern that we use when adding a new slave server, we just restore it from the backup. It happens all the time.
● Restore data to a point in the past
Quite often, users delete data, and then ask them to recover, including from the database. This rather frequent data recovery operation to a point in the past is automated.
● Recover the entire cluster from scratch
Everyone thinks that backups are needed in order to restore all data from scratch. In fact, this operation almost never required us. Last time we used it 3 years ago.
These are our main guarantees that we give to our customers. The speed of 1 TB in 40 minutes, because there are restrictions on the network, we are not alone on these racks, traffic is still produced on them.
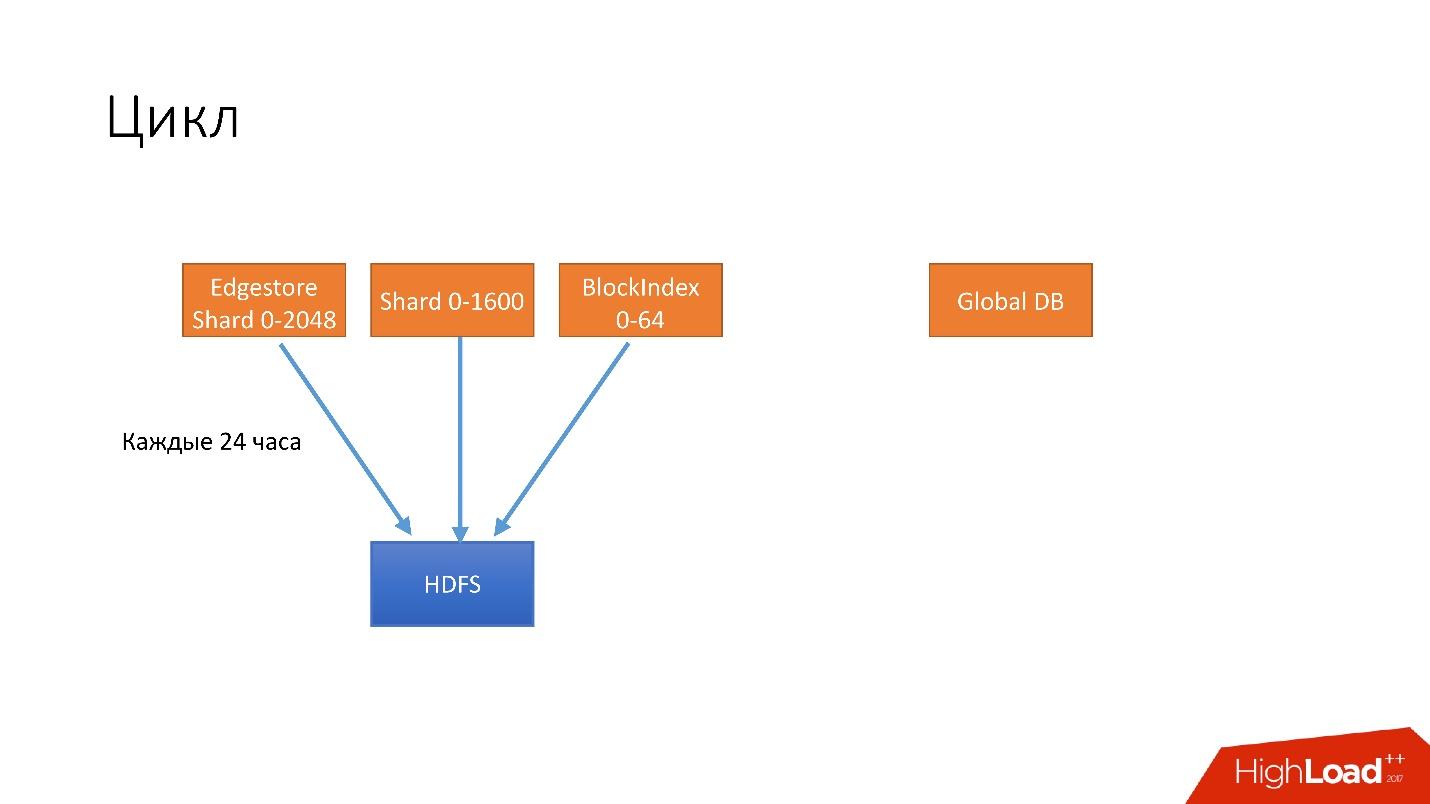
We have introduced such an abstraction as a cycle. In one cycle, we try to backup almost all of our databases. We simultaneously spin 4 different cycles.

All this is stored for several cycles. Suppose if we store 3 cycles, then in HDFS we have the last 3 days, and the last 6 days in S3. So we support our guarantee.
This is an example of how they work.

In this case, we have two long cycles running, which make backups of shardirovanny databases, and one short one. At the end of each cycle, we will necessarily verify that the backups work, that is, we do recovery on a certain percentage of the database. Unfortunately, we cannot recover all the data, but we definitely check some percentage of the data for the cycle. As a result, we will have 100 percent of backups that we restored.
We have certain shards that we always restore to watch the recovery rate, to monitor possible regressions, and there are shards that we restore just randomly to check that they have recovered and are working. Plus, when cloning, we also recover from backups.

Now we have a hot backup for which we use the Percona tool xtrabackup. We run it in the —stream = xbstream mode, and it returns us on the working database, the stream of binary data. Next we have a script-splitter, which this binary stream divides into four parts, and then we compress this stream.
MySQL stores data on a disk in a very strange way and we have more than 2x compression. If the database is 3 TB, then, as a result of compression, the backup takes approximately 1 500 GB. Next, we encrypt this data so that no one can read it, and send it to HDFS and S3.
In the opposite direction it works exactly the same.

We prepare the server, where we will install the backup, get the backup from HDFS or from S3, decode and decompress it, the splitter compresses it all and sends it to xtrabackup, which restores all data to the server. Then crash-recovery occurs.
Some time, the most important problem of hot backups was that crash-recovery takes quite a long time. In general, you need to lose all transactions during the time you make a backup. After that we lose binlog so that our server will catch up with the current master.
How do we save binlogs?
We used to save binlog files. We collected the master files, alternated them every 4 minutes, or 100 MB each, and saved to HDFS.
Now we use a new scheme: there is a certain Binlog Backuper, which is connected to replications and to all databases. He, in fact, constantly merges binlog to himself and stores them on HDFS.
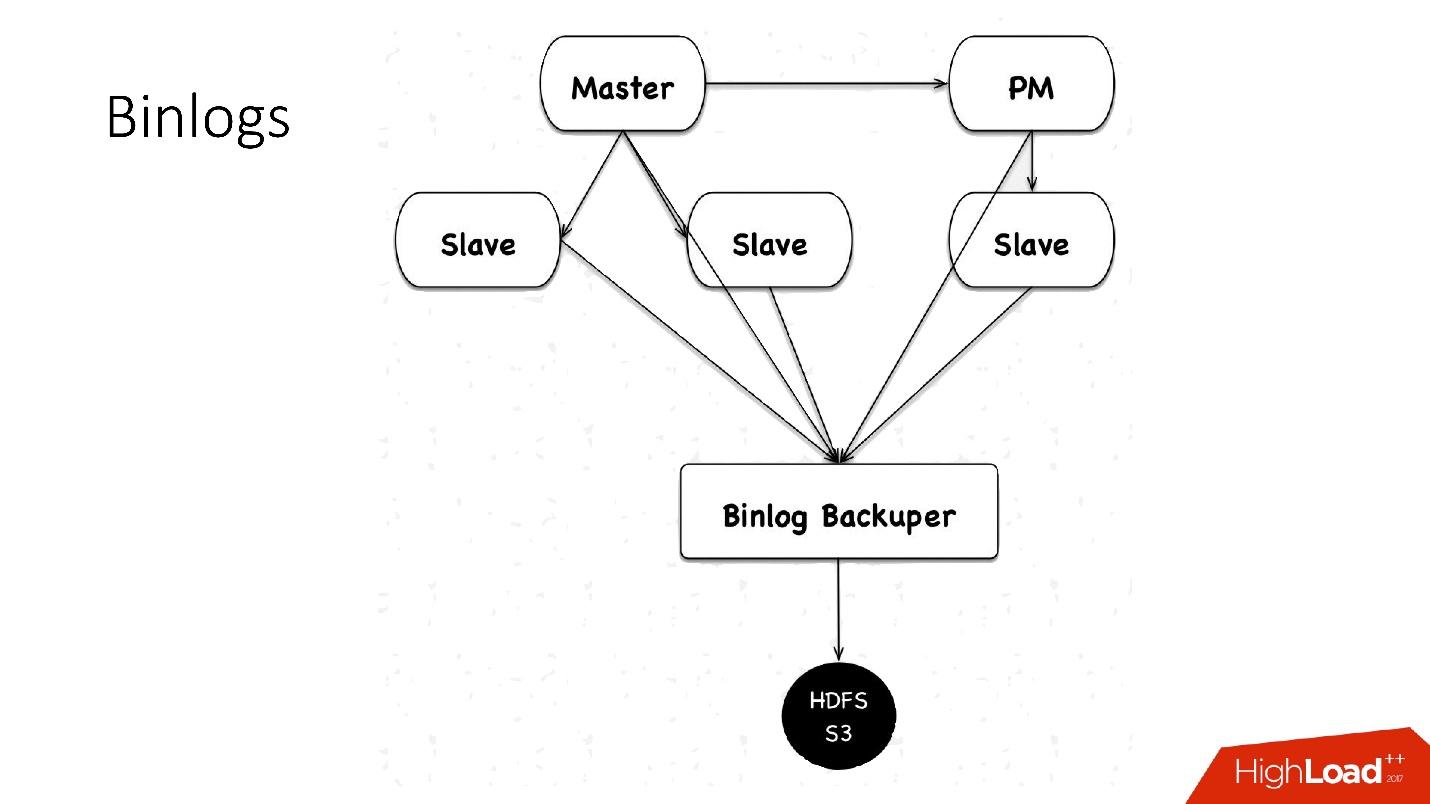
Accordingly, in the previous implementation we could lose 4 minutes of binary logs, if we lost all 5 servers, in the same implementation, depending on the load, we lose literally seconds. Everything stored in HDFS and in S3 is stored for a month.
We are thinking of switching to cold backups.
Prerequisites for this:
Warranties that were obtained with cold backups in our experiments:

In our topology, there is a slave in another data center that does almost nothing. We periodically stop it, make a cold backup and run it back. Everything is very simple.
These are plans for the distant future. When we update our Hardware Park, we want to add an additional spindle disk (HDD) of about 10 TB to each server, and make hot backups + crash recovery xtrabackup on it, and then download backups. Accordingly, we will have backups on all five servers simultaneously, at different points in time. This, of course, will complicate all the processing and operation, but will reduce the cost, because the HDD costs a penny, and a huge cluster of HDFS is expensive.
As I said, cloning is a simple operation:
In the diagram, where we copy to HDFS, the data is also simply copied to another server, where there is a receiver that receives all the data and restores it.
Of course, on 6,000 servers, no one does anything manually. Therefore, we have various scripts and automation services, there are a lot of them, but the main ones are:
This script is needed when the server is dead, and you need to understand whether it is true, and what the problem is - maybe the network is broken or something else. It needs to be resolved as quickly as possible.
Availability is a function of the time between the occurrence of errors and the time over which you can detect and repair this error. We can fix it very quickly - our recovery is very fast, so we need to determine the existence of a problem as soon as possible.

On each MySQL server, the service that heartbeat writes is running. Heartbeat is the current timestamp.
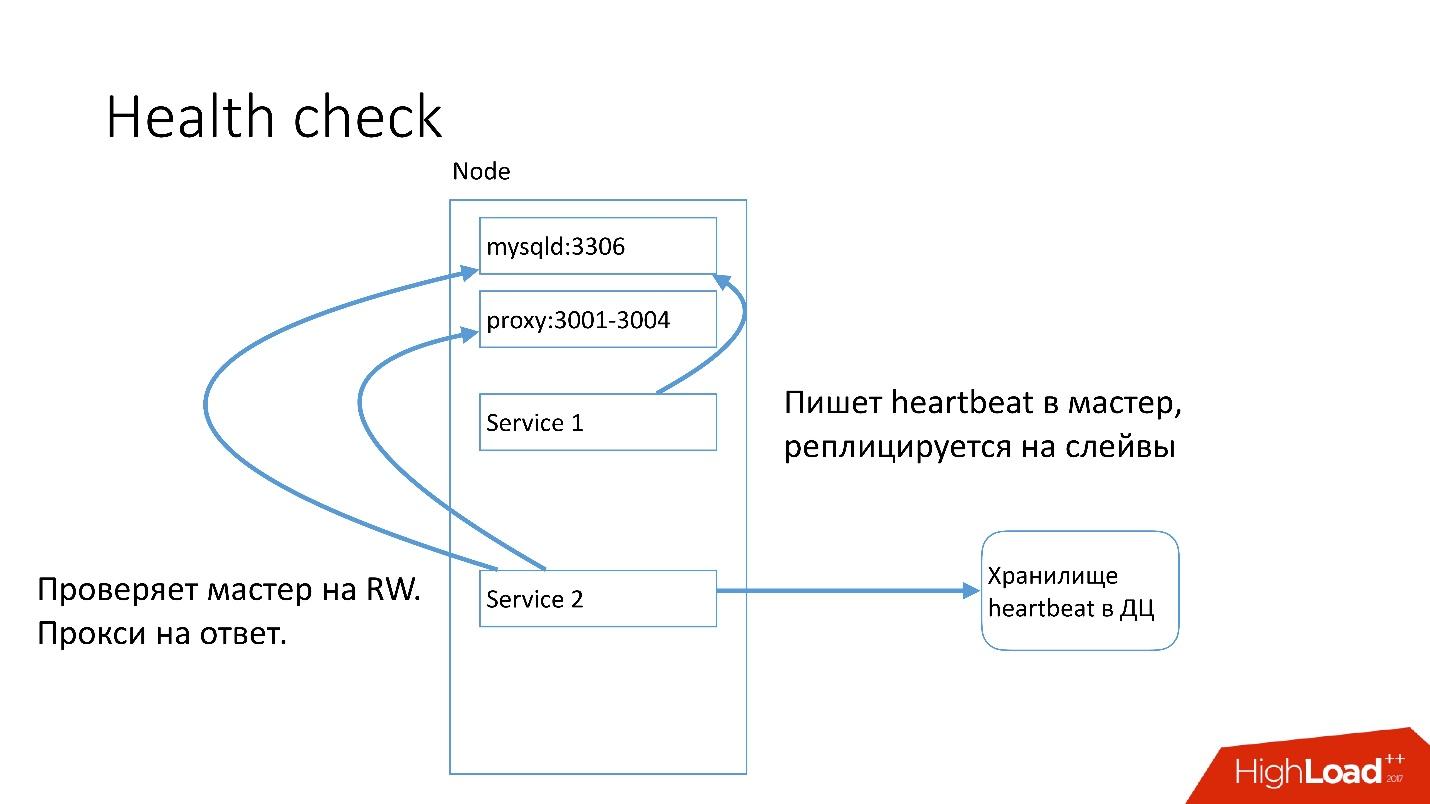
There is also another service that writes the value of some predicates, for example, that master is in read-write mode. After that, the second service sends this heartbeat to the central repository.
We have an auto-replace script that works like this.
 The scheme in the best quality and separately its enlarged fragments are in the presentation of the report, starting with 91 slides.
The scheme in the best quality and separately its enlarged fragments are in the presentation of the report, starting with 91 slides.
What's going on here?
Auto-replace is very conservative. He never wants to do a lot of automatic operations.
Therefore, we solve only one problem at a time .
Accordingly, for the slave server, we start cloning and simply remove it from the topology, and if it is master, then we launch the file shareer, the so-called emergency promotion.
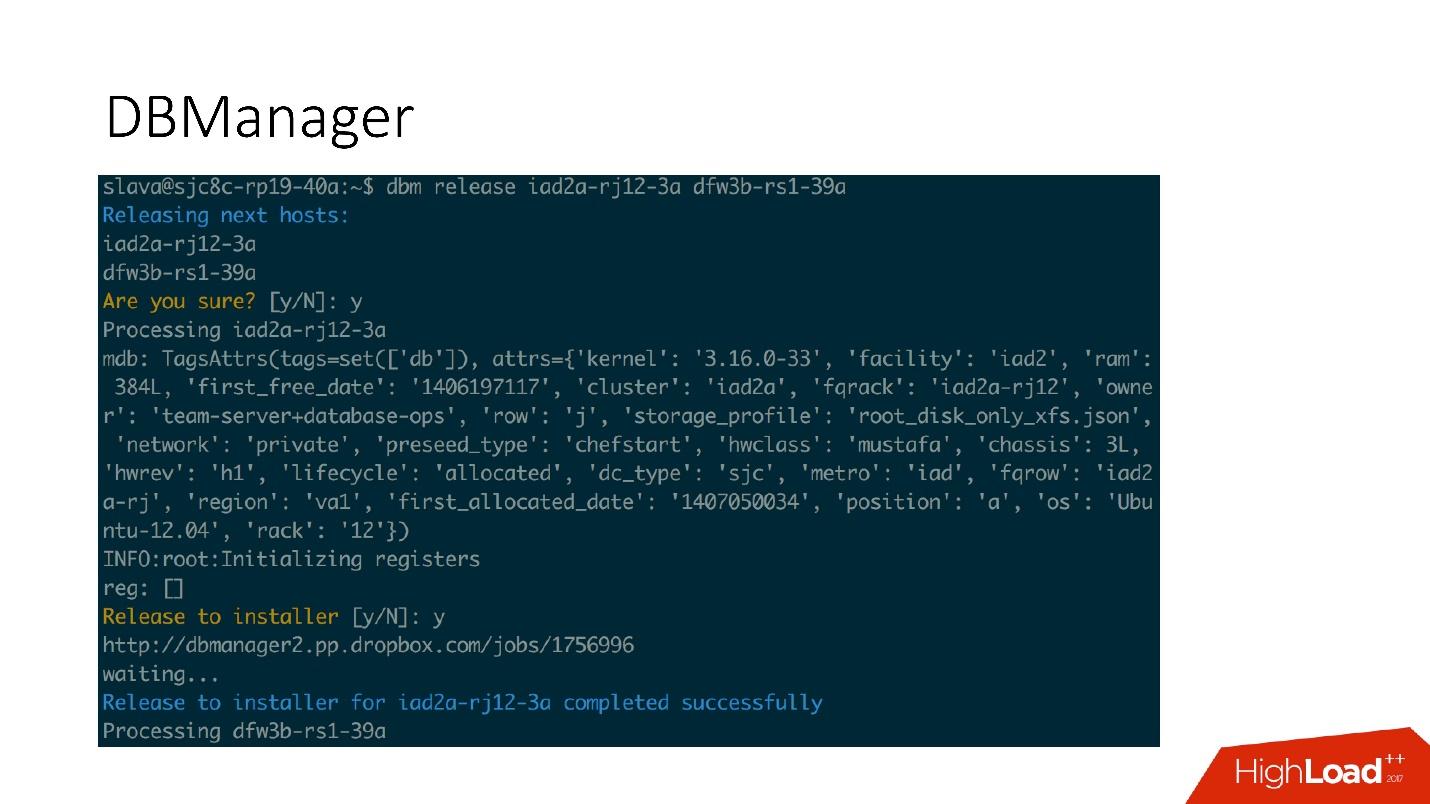
DBManager is a service for managing our databases. He has:
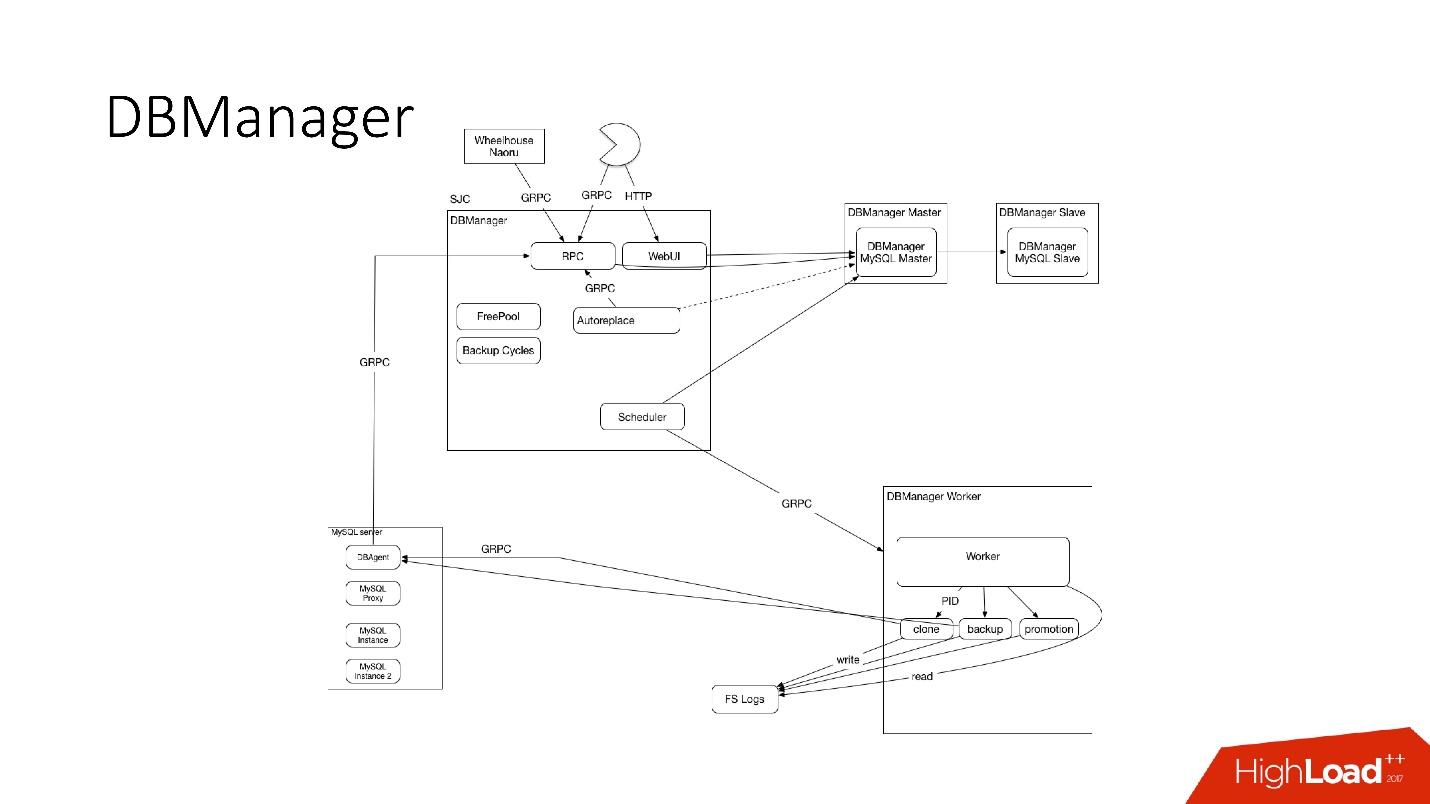
DBManager is quite simple architecturally.
web DBManager, , , , ..
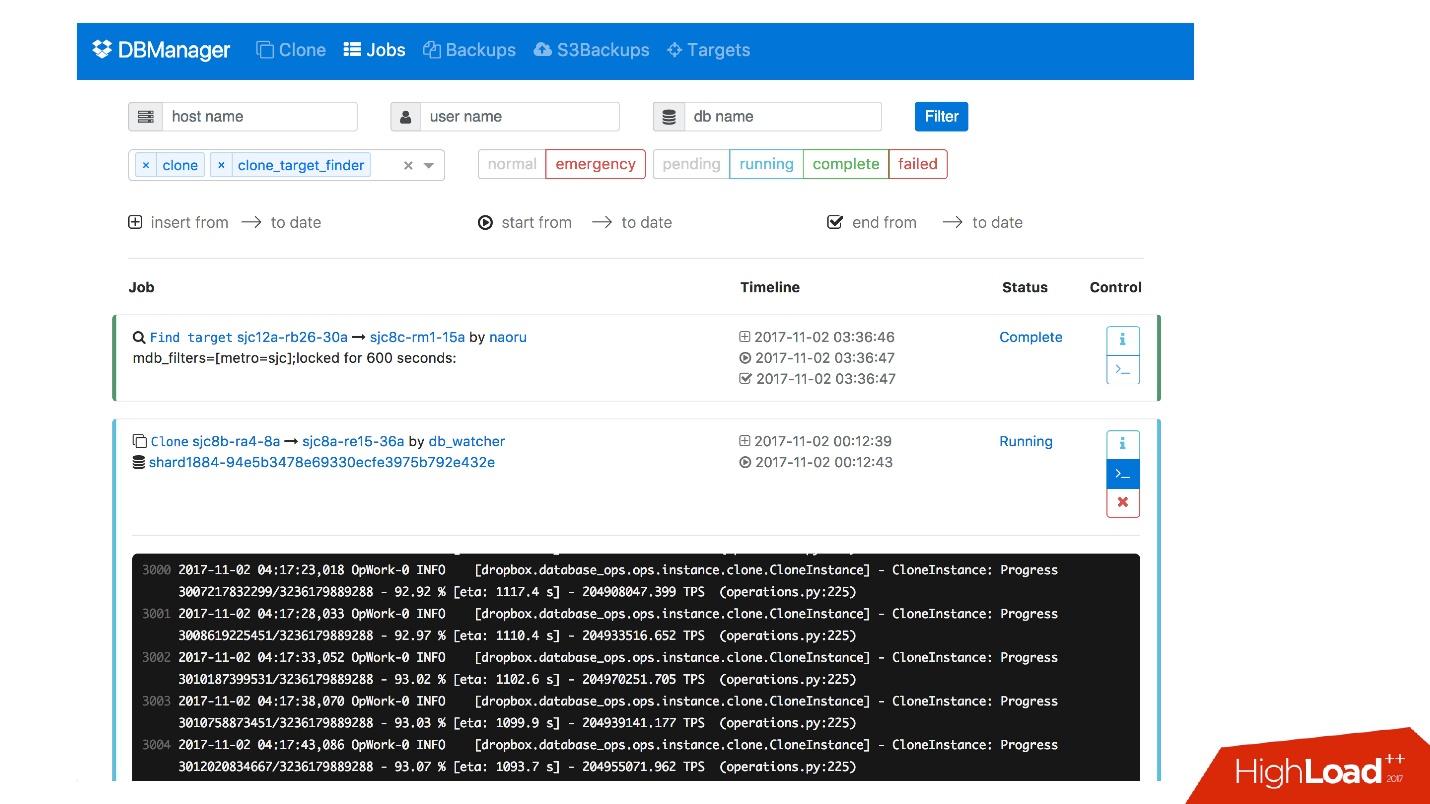
CLI , .
We also have a problem response system. When something breaks in us, for example, the disk has failed, or some service does not work, Naoru works . This is a system that works throughout Dropbox, everyone uses it, and it was built for just such small tasks. I talked about Naoru in my 2016 report .
The wheelhouse system is based on the state machine and is designed for long processes. For example, we need to update the kernel on all MySQL on our entire cluster of 6000 machines. Wheelhouse does this clearly - it updates on the slave server, launches the promotion, the slave becomes the master, it updates on the master server. This operation can take a month or even two.

It is very important.
We monitor everything in MySQL - all the information we can get from MySQL, we have somewhere saved, we can access it in time. We save information on InnoDb, statistics on requests, on transactions, on the length of transactions, on the length of the transaction, on replication, on the network - all, all - a huge number of metrics.
We have set up 992 alerts. In fact, no one looks at the metrics, it seems to me that there are no people who come to work and start looking at the metrics chart, there are more interesting tasks.

Therefore, there are alerts that are triggered when certain threshold values are reached. We have 992 alerts, no matter what happens, we will know about it .

We have PagerDuty - this is a service through which alerts are sent to those in charge who start taking action.

In this case, an error occurred in the emergency promotion and immediately after that an alert was registered that the master had fallen. After that, the duty officer checked what prevented the emergency promotion, and did the necessary manual operations.
We are sure to analyze every incident that occurred, for each incident we have a task in the task tracker. Even if this incident is a problem in our alerts, we also create a task, because if the problem is in the logic of the alert and the thresholds, they need to be changed. Alerts should not just ruin people's lives. Alert is always painful, especially at 4 am.
As with monitoring, I am sure that everyone is involved in testing. In addition to the unit tests with which we cover our code, we have integration tests in which we test:
If we have promotion operations, we test in the integration test of promotion operations. If we have cloning, we do cloning for all the topologies we have.
Sample Topology

We have a topology for all occasions: 2 data centers with multi instance, shards, no shards, clusters, one data center - in general, almost any topology - even those that we do not use, just to view .

In this file we just have the settings, which servers and with what we need to raise. For example, we need to raise the master, and we say that it is necessary to do this with such data of the instances, with such databases at such ports. We have almost everything going with the help of Bazel, which creates a topology on the basis of these files, starts the MySQL server, then the test is started.

The test looks very simple: we indicate which topology is used. In this test, we test auto_replace.
Stage environments are the same databases as in production, but they do not have user traffic, but there is some kind of synthetic traffic that is similar to production through Percona Playback, sysbench, and similar systems.
In Percona Playback, we record traffic, then lose it on the stage-environment with different intensity, we can lose 2-3 times faster. That is, it is an artificial, but very close to the real load.
This is necessary because in integration tests we cannot test our production. We cannot test the alert or that the metrics work. At testing we test alerts, metrics, operations, periodically we kill servers and see that they are normally assembled.
Plus, we test all the automations together, because in integration tests, most likely, one part of the system is tested, and in the staging all the automated systems work simultaneously. Sometimes you think that the system will behave this way and not otherwise, but it may behave differently.
We also conduct tests in production - right on real databases. This is called Disaster recovery testing. Why do we need it?
● We want to test our warranty.
This is done by many large companies. For example, Google has one service that worked so stably - 100% of the time - that all the services that used it decided that this service is really 100% stable and never drops. Therefore, Google had to drop this service specifically for users to take into account this possibility.
So we - we have a guarantee that MySQL works - and sometimes it does not work! And we have a guarantee that it may not work for a certain period of time, customers should take this into account. Periodically, we kill the production master, or, if we want to make a file share, we kill all the slave servers to see how semisync replication behaves.
● Clients are ready for these errors (replacement and death of the master)
Why is it good? We had a case when with the promotion of 4 shards from 1600, the availability dropped to 20%. It seems that something is wrong, for 4 shards out of 1600 there must be some other numbers. Faylovera for this system occurred quite rarely, about once a month, and everyone decided: "Well, this is a faylover, it happens."
At some point, when we switched to a new system, one person decided to optimize those two heartbeat recording services and merged them into one. This service did something else and, eventually, was dying and heartbeats stopped recording. It so happened that for this client we had 8 faylover per day. All lay - 20% availability.
It turned out that in this client keep-alive 6 hours. Accordingly, as soon as the master was dying, all of our connections were kept for another 6 hours. The pool could not continue to work - it keeps connections, it is limited and does not work. It repaired.
Doing a faylover again - no longer 20%, but still a lot. Something's all wrong anyway. It turned out that the bug in the implementation of the pool. The pool, when requested, addressed many shards, and then put it all together. If any shards were fake, some race condition occurred in the Go code, and the whole pool was clogged. All these shards could not work anymore.
Disaster recovery testing is very useful, because clients must be prepared for these errors, they must check their code.
● Plus Disaster recovery testing is good because it goes into business hours and everything is in place, less stress, people know what will happen now. This is not happening at night, and it's great.
1. Everything needs to be automated, never clap hands.
Each time when someone climbs into the system with our hands, everything dies and breaks in us - every single time! - even on simple operations. For example, one slave died, the person had to add a second, but decided to remove the dead slave with his hands from the topology. However, instead of the deceased, he copied the live command into the command - the master was left without a slave at all. Such operations should not be done manually.
2. Tests should be permanent and automated (and in production).
Your system is changing, your infrastructure is changing. If you checked it once and it seemed to work, it does not mean that it will work tomorrow. Therefore, it is necessary to do automated testing every day, including in production.
3. It is imperative to own clients (libraries).
Users may not know how databases work. They may not understand why they need timeouts, keep-alive. Therefore, it is better to own these customers - you will be calmer.
4. You need to define your principles for building a system and your guarantees, and always comply with them.
Thus it is possible to support 6 thousand database servers.
Under the cut is the transcript of the report of Glory Bakhmutov ( m0sth8 ) on Highload ++ 2017, how the databases in Dropbox have evolved and how they are organized now.
About the speaker: Slava Bakhmutov is a site reliability engineer on the Dropbox team, she loves Go very much and sometimes appears in the golangshow.com podcast.
')
Content
- Briefly about Dropbox architecture
- The history of database development and how the current Dropbox architecture is arranged
- Simplest database operations (file managers, backups, clones, promotions)
- Automation - which manages all databases and starts operations
- Monitoring
- Testing, staging and DRT
Simple Dropbox Architecture
Dropbox appeared in 2008. In essence, this is a cloud file storage. When Dropbox was launched, the user at Hacker News commented that you can implement it with several bash scripts using FTP and Git. But, nevertheless, Dropbox is developing, and now it is a fairly large service with more than 1.5 billion users, 200 thousand businesses and a huge number (several billion!) Of new files every day.
What does Dropbox look like?
We have several clients (web interface, API for applications that use Dropbox, desktop applications). All these clients use the API and communicate with two large services, which can logically be divided into:
- Metaserver .
- Blockserver .
Metaserver stores meta information about a file: size, comments to it, links to this file in Dropbox, etc. The Blockserver stores information only about files: folders, paths, etc.
How it works?
For example, you have a video.avi file with some kind of video.
Link from the slide- The client splits this file into several chunks (in this case 4 MB), calculates the checksum and sends a request to Metaserver: “I have an * .avi file, I want to download it, such hash sums”.
- Metaserver returns the answer: “I do not have these blocks, let's download!” Or he can answer that he has all or some of the blocks, and you need to download only the remaining ones.
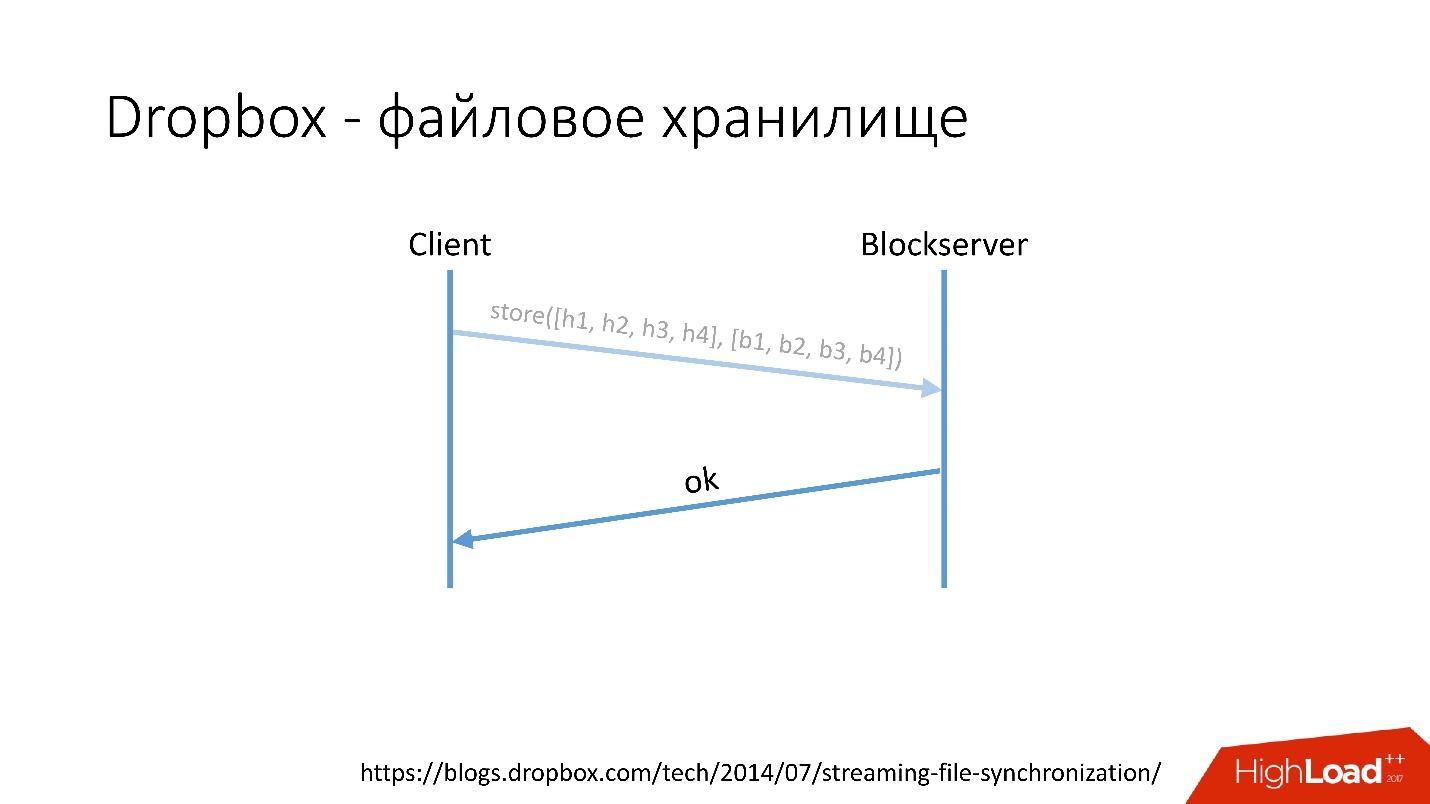
Link from the slide- After that, the client goes to the Blockserver, sends the hash sum and the data block itself, which is stored on the Blockserver.
- Blockserver confirms operation.
Link from the slideOf course, this is a very simplified scheme, the protocol is much more complicated: there is synchronization between clients within the same network, there are kernel drivers, the ability to resolve collisions, etc. This is a rather complicated protocol, but schematically it works something like this.
When a client saves something on Metaserver, all the information goes into MySQL. Blockserver information about files, how they are structured, which blocks they consist of, also stores in MySQL. Also, the Blockserver stores the blocks themselves in Block Storage, which, in turn, also stores information about where the block is, on which server, and how it is processed at the moment, in MYSQL.
In order to store exabytes of user files, we simultaneously save additional information into a database of several dozen petabytes scattered across 6 thousand servers.
The history of database development
How did the database in Dropbox evolve?
In 2008, it all started with one Metaserver and one global database. All the information that Dropbox needed to be saved somewhere, it saved to a single global MySQL. This did not last long, because the number of users grew, and individual bases and tablets inside the bases swelled faster than others.
Therefore, in 2011 several tables were moved to separate servers:
- User , with information about users, for example, logins and oAuth tokens;
- Host , with information about files from Blockserver;
- Misc , which did not participate in processing requests from production, but was used for service functions, like batch jobs.
But after 2012, Dropbox began to grow very much, since then we have grown by about 100 million users a year .
It was necessary to take into account such a huge growth, and therefore at the end of 2011 we had shards - the base consisting of 1,600 shards. Initially, only 8 servers with 200 shards each. Now it’s 400 master servers with 4 shards each.
Link from the slideIn 2012, we realized that creating tables and updating them in the database for each added business logic is very difficult, dreary and problematic. Therefore, in 2012, we invented our own graph storage, which we called Edgestore , and since then all the business logic and meta information that the application generates is stored in Edgestore.
Edgestore, in fact, abstracts MySQL from clients. Clients have certain entities that are interconnected by links from the gRPC API to Edgestore Core, which converts this data to MySQL and somehow stores it there (basically it gives all this from the cache).
Link from the slideIn 2015, we left Amazon S3 , developed our own cloud storage called Magic Pocket. It contains information about where the block file is located, on which server, about the movement of these blocks between servers, is stored in MySQL.
Link from the slideBut MySQL is used in a very tricky way - in fact, as a large distributed hash table. This is a very different load, mainly on reading random entries. 90% recycling is I / O.
Database architecture
First, we immediately identified some principles by which we build the architecture of our database:
- Reliability and durability . This is the most important principle and what customers expect from us - the data should not be lost.
- The optimal solution is an equally important principle. For example, backups should be made quickly and recovered too quickly.
- Simplicity of the solution - both architecturally and from the point of view of maintenance and further development support.
- Cost of ownership . If something optimizes the solution, but is very expensive, it does not suit us. For example, a slave that is behind the master by the day is very convenient for backups, but then you need to add another 1,000 to 6,000 servers - the cost of owning such a slave is very high.
All principles must be verifiable and measurable , that is, they must have metrics. If we are talking about the cost of ownership, then we must calculate how many servers we have, for example, it goes under the database, how many servers it goes under the backups, and how much it costs for Dropbox. When we choose a new solution, we count all the metrics and focus on them. When choosing any solution, we are fully guided by these principles.
Basic topology
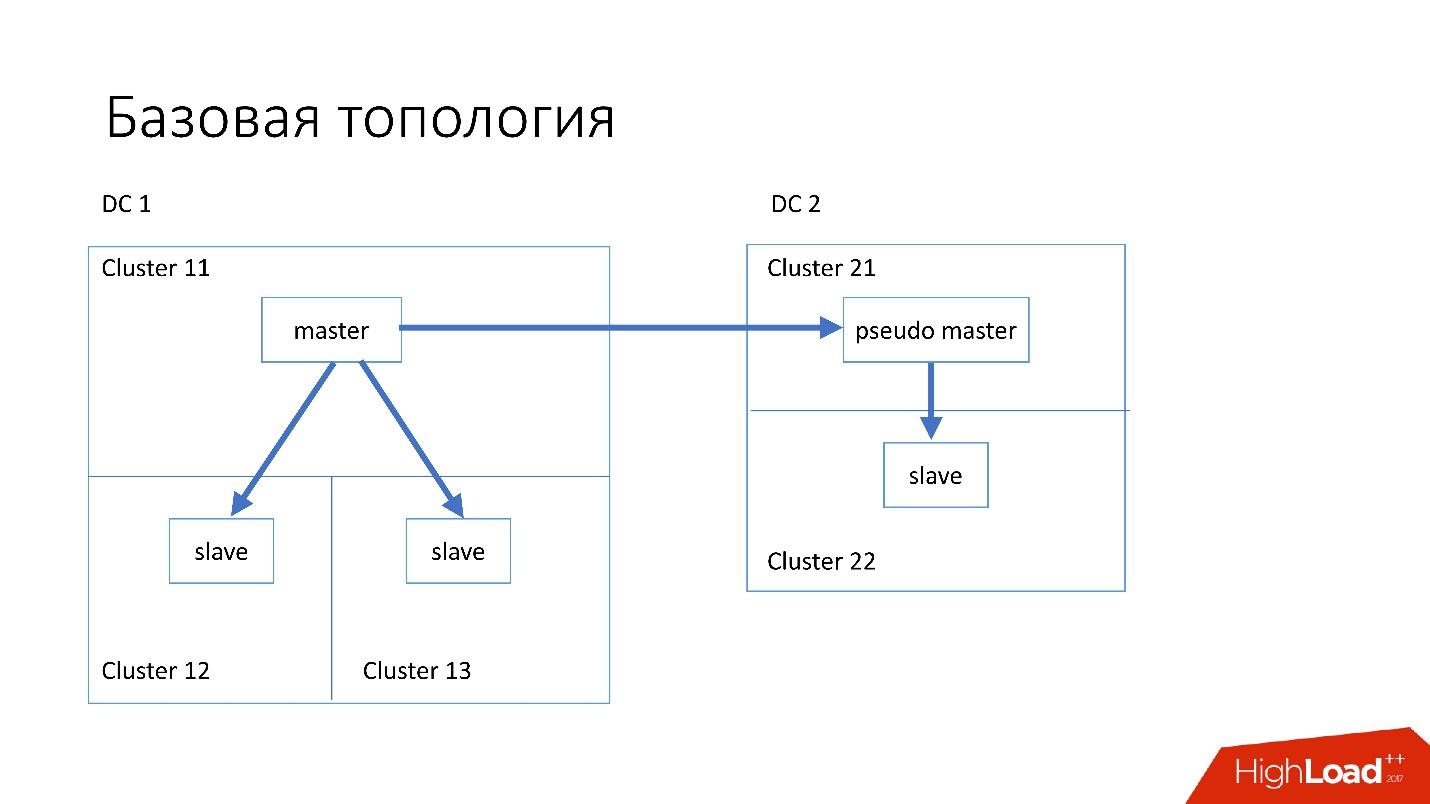
The database is organized approximately as follows:
- In the main data center we have a master, in which all the records occur.
- The master server has two slave servers for which semisync replication occurs. Servers often die (about 10 per week), so we need two slave servers.
- Slave servers are in separate clusters. Clusters are completely separate rooms in the data center that are not connected to each other. If one room burns down, the second remains quite a working one.
- Also in another data center we have a so-called pseudo master (intermediate master), which is actually just a slave, which has another slave.
This topology is chosen because if we suddenly die the first data center, then in the second data center we already have almost complete topology . We simply change all addresses in Discovery, and customers can work.
Specialized topologies
We also have specialized topologies.
Topology Magic Pocket consists of one master-server and two slave-servers. This is done because Magic Pocket itself duplicates data among the zones. If it loses one cluster, it can recover all data from other zones via erasure code.
Active-active topology is a custom topology that is used in Edgestore. It has one master and two slaves in each of the two data centers, and they are slaves for each other. This is a very dangerous scheme , but Edgestore at its level knows exactly what data to which master at which range it can write. Therefore, this topology does not break.
Instance
We have installed fairly simple servers with a configuration of 4-5 years old:
- 2x Xeon 10 cores;
- 5TB (8 SSD Raid 0 *);
- 384 GB memory.
* Raid 0 - because it is easier and faster for us to replace the whole server than the disks.
Single instance
On this server, we have one big MySQL instance, on which there are several shards. This MySQL instance immediately allocates to itself almost all the memory. Other processes are running on the server: proxy, statistics collection, logs, etc.
This solution is good because:
+ It's easy to manage . If you need to replace MySQL instance, simply replace the server.
+ Just make faylover .
On the other hand:
- It is problematic that any operations occur on the whole MySQL instance and immediately on all shards. For example, if you need to make a backup, we make a backup of all shards at once. If you need to make a faylover, we make a faylover of all four shards at once. Accordingly, accessibility suffers 4 times more.
- Problems with replication of one shard affect other shards. Replication in MySQL is not parallel, and all shards work in one stream. If something happens to one shard, then the rest are also victims.
Therefore, we are now switching to another topology.
Multi instance
In the new version, several MySQL instances are running on the server at once, each with one shard. What is better?
+ We can carry out operations only on one particular shard . That is, if you need a faylover, switch only one shard, if you need a backup, make a backup of only one shard. This means that operations are greatly accelerated - 4 times for a four-shard server.
+ Shards almost don't affect each other .
+ Improved replication. We can mix different categories and classes of databases. Edgestore takes up a lot of space, for example, all 4 TB, and Magic Pocket only takes 1 TB, but it has 90% utilization. That is, we can combine various categories that use I / O and machine resources in different ways, and run 4 replication threads.
Of course, this solution has some disadvantages:
- The biggest minus is much harder to manage all this . We need some kind of smart planner who will understand where he can take this instance, where the optimal load will be.
- Harder faylover .
Therefore, we are only now switching to this decision.
Discovery
Clients must somehow know how to connect to the right database, so we have Discovery, which should:
- Very quickly notify the client about topology changes. If we changed the master and slave, customers should know about it almost instantly.
- The topology should not depend on the MySQL replication topology, because for some operations we change the MySQL topology. For example, when we do split, at the preparatory step on the target master, where we will take some shards, some of the slave servers migrate to this target master. Customers do not need to know about it.
- It is important that there is atomicity of operations and state verification. It is impossible for two different servers of the same database to become master at the same time.
How Discovery Developed
At first everything was simple: the address of the database in the source code in the config. When we needed to update the address, it was just that everything deployed very quickly.
Unfortunately, this does not work if there are a lot of servers.
Above is the very first Discovery, which we had. There were database scripts that changed the label in ConfigDB — it was a separate MySQL table, and clients already listened to this database and periodically took data from there.
The table is very simple; there is a database category, a shard key, a master / slave database class, a proxy, and a database address. In fact, the client requested a category, database class, shard key, and he was returned a MySQL address at which he could already establish a connection.
As soon as there were a lot of servers, Memcash was added and clients began to communicate with him.
But then we reworked it. MySQL scripts began to communicate through gRPC, through a thin client with a service that we called RegisterService. When some changes occurred, the RegisterService had a queue, and he understood how to apply these changes. RegisterService saved data in AFS. AFS is our internal system, built on the basis of ZooKeeper.
The second solution, which is not shown here, directly used ZooKeeper, and this created problems because every shard was a node in ZooKeeper. For example, 100 thousand clients connect to ZooKeeper, if they suddenly died because of some kind of bug all together, then 100 thousand requests will immediately come to ZooKeeper, which will simply drop it, and it will not be able to rise.
Therefore, the AFS system was developed , which is used by the entire Dropbox . In fact, it abstracts the work with ZooKeeper for all clients. The AFS daemon locally rotates on each server and provides a very simple file API of the form: create a file, delete a file, request a file, receive notification of file changes, and compare and swap operations. That is, you can try to replace the file with some version, and if this version has changed during the shift, the operation is canceled.
Essentially, such an abstraction over ZooKeeper, in which there is a local backoff and jitter algorithms. ZooKeeper no longer falls under load. With AFS, we remove backups in S3 and in GIT, then the local AFS itself notifies customers that the data has changed.
In AFS, data is stored as files, that is, it is a file system API. For example, the shard.slave_proxy file is the largest, it takes about 28 Kb, and when we change the shard category and the slave_proxy class, all clients that are subscribed to this file receive a notification. They re-read this file, which has all the necessary information. By shard key get the category and reconfigure the connection pool to the database.
Operations
We use very simple operations: promotion, clone, backups / recovery.
The operation is a simple state machine . When we go into an operation, we perform some checks, for example, a spin-check, which checks on timeouts several times whether we can perform this operation. After that, we do some preparatory action that does not affect external systems. The actual operation itself.
All steps inside the operation have a rollback step (undo). If there is a problem with the operation, the operation tries to restore the system to its original position. If everything is normal, then a cleanup occurs, and the operation is completed.
We have such a simple state machine for any operation.
Promotion (change of master)
This is a very frequent operation in the database. There were questions about how to do alter on a hot master-server that works - he will get a stake. Simply, all these operations are performed on slave-servers, and then the slave changes with master places. Therefore, the promotion operation is very frequent .
We need to update the kernel - we are doing swap, we need to update the version of MySQL - we update to the slave, we switch to master, we update there.
We have achieved a very fast promotion. For example, we have for four shards now a promotion of the order of 10-15 s. The graph above shows that when the promotion availability suffered by 0.0003%.
But normal promotion is not so interesting, because it is the usual operations that are performed every day. Faylover interesting.
Failover (replacement of a broken master)
Failover means that the database is dead.
- If the server is really dead, this is just the perfect case.
- In fact, it happens that the servers are partially alive.
- Sometimes the server dies very slowly. He refuses raid-controllers, disk system, some requests return answers, but some threads are blocked and do not return answers.
- It happens that the master is just overloaded and does not respond to our health check. But if we make a promotion, the new master will also be overloaded, and it will only get worse.
We replace the deceased master servers about 2-3 times a day , this is a fully automated process, no human intervention is needed. The critical section takes about 30 seconds, and it has a bunch of additional checks on whether the server is actually alive, or maybe it has already died.
Below is an exemplary diagram of how filer works.
In the selected section, we reboot the master server . This is necessary because we have MySQL 5.6, and in it semisync replication is not lossless. Therefore phantom reads are possible, and we need this master, even if it is not dead, to kill it as soon as possible so that the clients disconnect from it. Therefore, we do a hard reset via Ipmi - this is the first most important operation we need to do. In MySQL version 5.7, this is not so critical.
Cluster sync. Why do we need cluster synchronization?
If we recall the previous picture with our topology, one master server has three slave servers: two in one data center, one in the other. With the promotion, we need the master to be in the same main data center. But sometimes, when the slave is loaded, with semisync it happens that the semisync-slave becomes a slave in another data center, because it is not loaded. Therefore, we need to synchronize the entire cluster first, and then make a promotion on the slave in the data center we need. This is done very simply:
- We stop all I / O thread on all slave servers.
- After that, we already know for sure that the master is “read-only”, since semisync has disconnected and no one else can write anything there.
- Then we select the slave with the largest retrieved / executed GTID Set, that is, with the largest transaction that it has either downloaded or already used.
- We migrate all slave servers to this selected slave, start the I / O thread, and they are synchronized.
- We are waiting for them to synchronize, after which we have the entire cluster becomes synchronized. At the end, we check that all of us are executed GTID set set to the same position.
The second important operation is cluster synchronization . Then begins the promotion , which happens as follows:
- We choose any slave in the data center we need, we tell it that it is master, and we launch the operation of the standard promotion.
- We reconfigure all the slave servers to this master, stop replication there, use ACLs, drive users in, stop some proxy servers, maybe reboot something.
- In the end, we do read_only = 0, that is, we say that you can now write to master and update the topology. From this point on, clients go to this master and everything works for them.
- Next we have non-critical post-processing steps. In them we restart some services on this host, redraw the configuration, do additional checks that everything works fine, for example, that the proxy allows traffic to pass.
- After that, the whole operation is completed.
At any step, in case of an error, we are trying to rollback to the point we can. That is, we cannot rollback to reboot. But for operations for which this is possible, for example, reassignment - change master - we can return master to the previous step.
Backups
Backups are a very important topic in databases. I do not know if you are making backups, but it seems to me that everyone should do them, this is already a beaten joke.
Patterns of use
● Add a new slave
The most important pattern that we use when adding a new slave server, we just restore it from the backup. It happens all the time.
● Restore data to a point in the past
Quite often, users delete data, and then ask them to recover, including from the database. This rather frequent data recovery operation to a point in the past is automated.
● Recover the entire cluster from scratch
Everyone thinks that backups are needed in order to restore all data from scratch. In fact, this operation almost never required us. Last time we used it 3 years ago.
We look at backups as a product, so we tell customers that we have guarantees:
- We can restore any database. Under normal conditions, the expected recovery rate of 1Tb in 40 minutes.
- Any base can be restored to any location in the past six days.
These are our main guarantees that we give to our customers. The speed of 1 TB in 40 minutes, because there are restrictions on the network, we are not alone on these racks, traffic is still produced on them.
Cycle
We have introduced such an abstraction as a cycle. In one cycle, we try to backup almost all of our databases. We simultaneously spin 4 different cycles.
- The first cycle is performed every 24 hours . We back up all our hijacked databases on HDFS, that's about a thousand or more hosts.
- Every 6 hours we make backups for unsharded databases, we still have some data on the Global DB. We really want to get rid of them, but, unfortunately, they still exist.
- Every 3 days we save all the information from the S3 shard database.
- Every 3 days, we completely save all information on non-chard database to S3.
All this is stored for several cycles. Suppose if we store 3 cycles, then in HDFS we have the last 3 days, and the last 6 days in S3. So we support our guarantee.
This is an example of how they work.
In this case, we have two long cycles running, which make backups of shardirovanny databases, and one short one. At the end of each cycle, we will necessarily verify that the backups work, that is, we do recovery on a certain percentage of the database. Unfortunately, we cannot recover all the data, but we definitely check some percentage of the data for the cycle. As a result, we will have 100 percent of backups that we restored.
We have certain shards that we always restore to watch the recovery rate, to monitor possible regressions, and there are shards that we restore just randomly to check that they have recovered and are working. Plus, when cloning, we also recover from backups.
Hot backups
Now we have a hot backup for which we use the Percona tool xtrabackup. We run it in the —stream = xbstream mode, and it returns us on the working database, the stream of binary data. Next we have a script-splitter, which this binary stream divides into four parts, and then we compress this stream.
MySQL stores data on a disk in a very strange way and we have more than 2x compression. If the database is 3 TB, then, as a result of compression, the backup takes approximately 1 500 GB. Next, we encrypt this data so that no one can read it, and send it to HDFS and S3.
In the opposite direction it works exactly the same.
We prepare the server, where we will install the backup, get the backup from HDFS or from S3, decode and decompress it, the splitter compresses it all and sends it to xtrabackup, which restores all data to the server. Then crash-recovery occurs.
Some time, the most important problem of hot backups was that crash-recovery takes quite a long time. In general, you need to lose all transactions during the time you make a backup. After that we lose binlog so that our server will catch up with the current master.
How do we save binlogs?
We used to save binlog files. We collected the master files, alternated them every 4 minutes, or 100 MB each, and saved to HDFS.
Now we use a new scheme: there is a certain Binlog Backuper, which is connected to replications and to all databases. He, in fact, constantly merges binlog to himself and stores them on HDFS.
Accordingly, in the previous implementation we could lose 4 minutes of binary logs, if we lost all 5 servers, in the same implementation, depending on the load, we lose literally seconds. Everything stored in HDFS and in S3 is stored for a month.
Cold backups
We are thinking of switching to cold backups.
Prerequisites for this:
- The speed of the channels on our servers has increased - it was 10 GB, it became 45 GB - you can recycle more.
- I want to restore and create clones faster, because we need a smarter scheduler for multi instances and want very often to transfer the slave and master from the server to the server.
- The most important point - with a cold backup, we can guarantee that the backup works. Because when we make a cold backup, we simply copy the file, then we start the database, and as soon as it starts up, we know that this backup works. After pt-table-checksum we know for sure that the data on the file system is consistent.
Warranties that were obtained with cold backups in our experiments:
- Under normal conditions, the expected recovery rate is 1TB in 10 minutes, because it is just copying files. No need to do a crash-recovery, but this is the most problematic place.
- Any base can be restored for any period of time for the last six days.
In our topology, there is a slave in another data center that does almost nothing. We periodically stop it, make a cold backup and run it back. Everything is very simple.
Plans ++
These are plans for the distant future. When we update our Hardware Park, we want to add an additional spindle disk (HDD) of about 10 TB to each server, and make hot backups + crash recovery xtrabackup on it, and then download backups. Accordingly, we will have backups on all five servers simultaneously, at different points in time. This, of course, will complicate all the processing and operation, but will reduce the cost, because the HDD costs a penny, and a huge cluster of HDFS is expensive.
Clone
As I said, cloning is a simple operation:
- this is either recovery from backup and playing binary logs;
- or the backup process immediately to the target server.
In the diagram, where we copy to HDFS, the data is also simply copied to another server, where there is a receiver that receives all the data and restores it.
Automation
Of course, on 6,000 servers, no one does anything manually. Therefore, we have various scripts and automation services, there are a lot of them, but the main ones are:
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
This script is needed when the server is dead, and you need to understand whether it is true, and what the problem is - maybe the network is broken or something else. It needs to be resolved as quickly as possible.
Availability is a function of the time between the occurrence of errors and the time over which you can detect and repair this error. We can fix it very quickly - our recovery is very fast, so we need to determine the existence of a problem as soon as possible.
On each MySQL server, the service that heartbeat writes is running. Heartbeat is the current timestamp.
There is also another service that writes the value of some predicates, for example, that master is in read-write mode. After that, the second service sends this heartbeat to the central repository.
We have an auto-replace script that works like this.
The scheme in the best quality and separately its enlarged fragments are in the presentation of the report, starting with 91 slides.What's going on here?
- There is a main loop in which we check heartbeat in the global database. We look, this service is registered or not. Count the heartbeats, for example, are there two heartbeats in 30 seconds?
- Further, we look, whether their quantity satisfies the threshold value. If not, then something is wrong with the server - since it did not send heartbeat.
- After that, we do reverse check just in case - suddenly these two services have died, something with the network, or the global database cannot for some reason record heartbeat. In reverse check, we connect to the broken database and check its status.
- If nothing has already helped, we look to see if the master position is progressing or not, whether recordings occur on it. If nothing happens, then this server is definitely not working.
- The last step is auto-replace itself.
Auto-replace is very conservative. He never wants to do a lot of automatic operations.
- First, we check if there have been any recent topology operations? Maybe this server has just been added and something is not yet running on it.
- We check if there were any replacements in the same cluster at some time interval.
- We check what our failure limit is. If we have many problems at once - 10, 20 - then we will not automatically solve them all, because we may inadvertently disrupt the operation of all databases.
Therefore, we solve only one problem at a time .
Accordingly, for the slave server, we start cloning and simply remove it from the topology, and if it is master, then we launch the file shareer, the so-called emergency promotion.
DBManager
DBManager is a service for managing our databases. He has:
- smart task scheduler that knows exactly when to start which job;
- logs and all information: who, when and what launched - this is the source of truth;
- synchronization point.
DBManager is quite simple architecturally.
- There are clients that are either DBAs that do something through the web interface, or scripts / services that have written DBAs that access gRPC.
- There are external systems like Wheelhouse and Naoru, which through gRPC goes to DBManager.
- , , , .
- worker, , , , PID. Worker , . worker' , , , , ACLS -.
- SQL- DBAgent — RPC . - , RPC .
web DBManager, , , , ..
CLI , .
Remediations
We also have a problem response system. When something breaks in us, for example, the disk has failed, or some service does not work, Naoru works . This is a system that works throughout Dropbox, everyone uses it, and it was built for just such small tasks. I talked about Naoru in my 2016 report .
The wheelhouse system is based on the state machine and is designed for long processes. For example, we need to update the kernel on all MySQL on our entire cluster of 6000 machines. Wheelhouse does this clearly - it updates on the slave server, launches the promotion, the slave becomes the master, it updates on the master server. This operation can take a month or even two.
Monitoring
It is very important.
If you do not monitor the system, then most likely it does not work.
We monitor everything in MySQL - all the information we can get from MySQL, we have somewhere saved, we can access it in time. We save information on InnoDb, statistics on requests, on transactions, on the length of transactions, on the length of the transaction, on replication, on the network - all, all - a huge number of metrics.
Alert
We have set up 992 alerts. In fact, no one looks at the metrics, it seems to me that there are no people who come to work and start looking at the metrics chart, there are more interesting tasks.
Therefore, there are alerts that are triggered when certain threshold values are reached. We have 992 alerts, no matter what happens, we will know about it .
Incidents
We have PagerDuty - this is a service through which alerts are sent to those in charge who start taking action.
In this case, an error occurred in the emergency promotion and immediately after that an alert was registered that the master had fallen. After that, the duty officer checked what prevented the emergency promotion, and did the necessary manual operations.
We are sure to analyze every incident that occurred, for each incident we have a task in the task tracker. Even if this incident is a problem in our alerts, we also create a task, because if the problem is in the logic of the alert and the thresholds, they need to be changed. Alerts should not just ruin people's lives. Alert is always painful, especially at 4 am.
Testing
As with monitoring, I am sure that everyone is involved in testing. In addition to the unit tests with which we cover our code, we have integration tests in which we test:
- all the topologies that we have;
- all operations on these topologies.
If we have promotion operations, we test in the integration test of promotion operations. If we have cloning, we do cloning for all the topologies we have.
Sample Topology
We have a topology for all occasions: 2 data centers with multi instance, shards, no shards, clusters, one data center - in general, almost any topology - even those that we do not use, just to view .
In this file we just have the settings, which servers and with what we need to raise. For example, we need to raise the master, and we say that it is necessary to do this with such data of the instances, with such databases at such ports. We have almost everything going with the help of Bazel, which creates a topology on the basis of these files, starts the MySQL server, then the test is started.
The test looks very simple: we indicate which topology is used. In this test, we test auto_replace.
- We create auto_replace service, we start it.
- We kill the master in our topology, wait some time and see that the target-slave has become the master. If not, the test fails.
Stages
Stage environments are the same databases as in production, but they do not have user traffic, but there is some kind of synthetic traffic that is similar to production through Percona Playback, sysbench, and similar systems.
In Percona Playback, we record traffic, then lose it on the stage-environment with different intensity, we can lose 2-3 times faster. That is, it is an artificial, but very close to the real load.
This is necessary because in integration tests we cannot test our production. We cannot test the alert or that the metrics work. At testing we test alerts, metrics, operations, periodically we kill servers and see that they are normally assembled.
Plus, we test all the automations together, because in integration tests, most likely, one part of the system is tested, and in the staging all the automated systems work simultaneously. Sometimes you think that the system will behave this way and not otherwise, but it may behave differently.
DRT (Disaster recovery testing)
We also conduct tests in production - right on real databases. This is called Disaster recovery testing. Why do we need it?
● We want to test our warranty.
This is done by many large companies. For example, Google has one service that worked so stably - 100% of the time - that all the services that used it decided that this service is really 100% stable and never drops. Therefore, Google had to drop this service specifically for users to take into account this possibility.
So we - we have a guarantee that MySQL works - and sometimes it does not work! And we have a guarantee that it may not work for a certain period of time, customers should take this into account. Periodically, we kill the production master, or, if we want to make a file share, we kill all the slave servers to see how semisync replication behaves.
● Clients are ready for these errors (replacement and death of the master)
Why is it good? We had a case when with the promotion of 4 shards from 1600, the availability dropped to 20%. It seems that something is wrong, for 4 shards out of 1600 there must be some other numbers. Faylovera for this system occurred quite rarely, about once a month, and everyone decided: "Well, this is a faylover, it happens."
At some point, when we switched to a new system, one person decided to optimize those two heartbeat recording services and merged them into one. This service did something else and, eventually, was dying and heartbeats stopped recording. It so happened that for this client we had 8 faylover per day. All lay - 20% availability.
It turned out that in this client keep-alive 6 hours. Accordingly, as soon as the master was dying, all of our connections were kept for another 6 hours. The pool could not continue to work - it keeps connections, it is limited and does not work. It repaired.
Doing a faylover again - no longer 20%, but still a lot. Something's all wrong anyway. It turned out that the bug in the implementation of the pool. The pool, when requested, addressed many shards, and then put it all together. If any shards were fake, some race condition occurred in the Go code, and the whole pool was clogged. All these shards could not work anymore.
Disaster recovery testing is very useful, because clients must be prepared for these errors, they must check their code.
● Plus Disaster recovery testing is good because it goes into business hours and everything is in place, less stress, people know what will happen now. This is not happening at night, and it's great.
Conclusion
1. Everything needs to be automated, never clap hands.
Each time when someone climbs into the system with our hands, everything dies and breaks in us - every single time! - even on simple operations. For example, one slave died, the person had to add a second, but decided to remove the dead slave with his hands from the topology. However, instead of the deceased, he copied the live command into the command - the master was left without a slave at all. Such operations should not be done manually.
2. Tests should be permanent and automated (and in production).
Your system is changing, your infrastructure is changing. If you checked it once and it seemed to work, it does not mean that it will work tomorrow. Therefore, it is necessary to do automated testing every day, including in production.
3. It is imperative to own clients (libraries).
Users may not know how databases work. They may not understand why they need timeouts, keep-alive. Therefore, it is better to own these customers - you will be calmer.
4. You need to define your principles for building a system and your guarantees, and always comply with them.
Thus it is possible to support 6 thousand database servers.
In the questions after the report, and especially the answers to them, there is also a lot of useful information.Questions and answers
It does not differ by orders of magnitude. It is almost normally distributed. We have throttling, that is, we can not overload the shard in fact, we throttle at the client level. In general, it happens that some star puts a photo, and the shard almost explodes. Then we ban this link.
This is all created manually. We have our own internal system, called Vortex, where metrics are stored, it supports alerts. There is a yaml-file in which it is written that there is a condition, for example, that backups should be performed every day, and if this condition is met, then the alert does not work. If not, then an alert comes.
This is our internal development, because few people can store as many metrics as we need.
Generally working in databases is a real pain. If the database is down, the service does not work, the entire Dropbox does not work. This is a real pain. DRT is useful in that it is a business watch. That is, I am ready, I sit at my desk, I have drunk coffee, I am fresh, I am ready to do anything.
Worse, when it happens at 4 am, and it is not DRT. For example, the last major failure we had recently. When infusing a new system, we forgot to set the OOM Score for our MySQL. There was another service that read binlog. At some point, our operator manually - again, manually! - runs a command to delete some information in Percona checksum-table. Just a normal delete, a simple operation, but this operation spawned a huge binlog. Service read this binlog in memory, OOM Killer came and thinks, who would kill? And we forgot to set the OOM Score, and it kills MySQL!
40 masters die at 4 o'clock in the morning. When 40 masters die, it's really very scary and dangerous. DRT is not scary and not dangerous. We lay for about an hour.
By the way, DRT is a good way to rehearse such moments, so that we know exactly which sequence of actions is needed if something breaks down en masse.
Do you mean something like group replication, galera cluster, etc.? It seems to me that the group application is not yet ready for life. Galera we, unfortunately, have not tried. It’s great when the file is inside your protocol, but unfortunately they have so many other problems, and it’s not so easy to switch to this solution.
We still still have 5.6 worth. I do not know when we will go to 8. Maybe we will try.
The load on the master is regulated by semisync. Semisync restricts master slave write performance. Of course, it may be that the transaction has arrived, semisync has worked, but the slaves have been losing this transaction for a very long time. You must then wait until the slave loses this transaction to the end.
When we start the promotion process, we disable I / O. After this, master cannot write anything, because semisync replication. A phantom reading may come, unfortunately, but this is another problem already.
All scripts are written in Python, all services are written in Go. This is our policy. Logic is easy to change - just in the Python code that generated the state diagram.
Yes. Testing is going with us using Bazel. There are some configuration files (json) and Bazel picks up a script that creates a topology for this test using this configuration file. Different topologies are described there.
All this works for us in docker-containers: either it works in CI, or on Devbox. We have a Devbox system. We are all developing on some kind of remote server, and this may work on it, for example. There it also runs inside a Bazel, inside a docker container or in a Bazel Sandbox. Bazel is very difficult, but cool.
Each instance has become smaller. Accordingly, the lower MySQL memory operates, the easier it is to live. It is easier for any system to operate with a small amount of memory. In this place we have not lost anything. We have the simplest C-groups that limit these instances on memory.
These are dozens of exabytes, we have poured data from Amazon over the course of the year.
Yes, it was originally 1600. This was done a little less than 10 years ago, and we still live. But we still have 4 shards - 4 times we can still increase the place.
The most important thing is that the disks fly out. Our RAID 0 drive crashed, the master died. This is the main problem, but it is easier for us to replace this server. Google is easier to replace the data center, we server yet. Corruption checksum we almost did not happen. To be honest, I do not remember when it was the last time. Simply we update wizards often enough. We have the life of a master is limited to 60 days. It cannot live longer, after that we replace it with a new server, because for some reason something constantly accumulates in MySQL, and after 60 days we see that problems start to occur. Maybe not in MySQL, maybe in Linux.
We do not know what the problem is and do not want to deal with it. We just limited the time to 60 days, and update the entire stack. No need to stick to one master.
We store information about the file, about the blocks. We can - Dropbox has the ability to recover files.
In general, Dropbox has some guarantees for how long the version is stored. This is slightly different. There is a system that can recover files, and there the files are simply not deleted immediately, they are put in some kind of recycle bin.
There is a problem when absolutely everything is removed. There are files, there are blocks, but there is no information in the database how to assemble a file from these blocks. At such a moment we can lose up to a certain point, that is, we recovered in 6 days, lost until the moment when this file was deleted, did not begin to delete it, restored it and gave it to the user.
Questions and answers
- What will happen if there is an imbalance in the load on shards - some kind of meta-information about some file turned out to be more popular? Is it possible to dissolve this shard, or is the load on shards different nowhere by orders of magnitude?
It does not differ by orders of magnitude. It is almost normally distributed. We have throttling, that is, we can not overload the shard in fact, we throttle at the client level. In general, it happens that some star puts a photo, and the shard almost explodes. Then we ban this link.
- You said you have 992 alerts. Is it possible in more detail, what is it - is it out of the box or is it being created? If it is, then is it manual labor or something like machine learning?
This is all created manually. We have our own internal system, called Vortex, where metrics are stored, it supports alerts. There is a yaml-file in which it is written that there is a condition, for example, that backups should be performed every day, and if this condition is met, then the alert does not work. If not, then an alert comes.
This is our internal development, because few people can store as many metrics as we need.
- How strong should the nerves be to do a DRT? You dropped, CODERED, does not rise, with every minute of panic more and more.
Generally working in databases is a real pain. If the database is down, the service does not work, the entire Dropbox does not work. This is a real pain. DRT is useful in that it is a business watch. That is, I am ready, I sit at my desk, I have drunk coffee, I am fresh, I am ready to do anything.
Worse, when it happens at 4 am, and it is not DRT. For example, the last major failure we had recently. When infusing a new system, we forgot to set the OOM Score for our MySQL. There was another service that read binlog. At some point, our operator manually - again, manually! - runs a command to delete some information in Percona checksum-table. Just a normal delete, a simple operation, but this operation spawned a huge binlog. Service read this binlog in memory, OOM Killer came and thinks, who would kill? And we forgot to set the OOM Score, and it kills MySQL!
40 masters die at 4 o'clock in the morning. When 40 masters die, it's really very scary and dangerous. DRT is not scary and not dangerous. We lay for about an hour.
By the way, DRT is a good way to rehearse such moments, so that we know exactly which sequence of actions is needed if something breaks down en masse.
- I would like to know more about switching master-master. First, why not use a cluster, for example? A cluster of databases, that is, not a master-slave with a switch, but a master-master application, so that if one falls, then it is not scary.
Do you mean something like group replication, galera cluster, etc.? It seems to me that the group application is not yet ready for life. Galera we, unfortunately, have not tried. It’s great when the file is inside your protocol, but unfortunately they have so many other problems, and it’s not so easy to switch to this solution.
- It seems there is something like an InnoDb cluster in MySQL 8. Did not try?
We still still have 5.6 worth. I do not know when we will go to 8. Maybe we will try.
- In this case, if you have one big master, when switching from one to another, a queue is accumulated on the slave servers with a high load. If the master is redeemed, is it necessary for the queue to run, for the slave to switch to master mode - or is it somehow done differently?
The load on the master is regulated by semisync. Semisync restricts master slave write performance. Of course, it may be that the transaction has arrived, semisync has worked, but the slaves have been losing this transaction for a very long time. You must then wait until the slave loses this transaction to the end.
- But then new data will be sent to the master, and it will be necessary ...
When we start the promotion process, we disable I / O. After this, master cannot write anything, because semisync replication. A phantom reading may come, unfortunately, but this is another problem already.
“These are all beautiful state machines — what are the scripts written on and how difficult is it to add a new step?” What should be done to the one who writes this system?
All scripts are written in Python, all services are written in Go. This is our policy. Logic is easy to change - just in the Python code that generated the state diagram.
- And you can learn more about testing. How are the tests written, how do they deploy the nodes in the virtual machine - are these containers?
Yes. Testing is going with us using Bazel. There are some configuration files (json) and Bazel picks up a script that creates a topology for this test using this configuration file. Different topologies are described there.
All this works for us in docker-containers: either it works in CI, or on Devbox. We have a Devbox system. We are all developing on some kind of remote server, and this may work on it, for example. There it also runs inside a Bazel, inside a docker container or in a Bazel Sandbox. Bazel is very difficult, but cool.
- When you made 4 instances on one server, did you lose any memory efficiency?
Each instance has become smaller. Accordingly, the lower MySQL memory operates, the easier it is to live. It is easier for any system to operate with a small amount of memory. In this place we have not lost anything. We have the simplest C-groups that limit these instances on memory.
- If you have 6,000 servers store databases, can you tell how many billions of petabytes are stored in your files?
These are dozens of exabytes, we have poured data from Amazon over the course of the year.
- It turns out that you initially had 8 servers, they each had 200 shards, then 400 servers with 4 shards each. You have 1600 shards - is this some kind of fixed value? You can never do again? Will it hurt if you need, for example, 3,200 shards?
Yes, it was originally 1600. This was done a little less than 10 years ago, and we still live. But we still have 4 shards - 4 times we can still increase the place.
- How do the servers die, mainly for what reasons? What happens more often, which is less common, and especially interesting, do spontaneous blockade blocks occur?
The most important thing is that the disks fly out. Our RAID 0 drive crashed, the master died. This is the main problem, but it is easier for us to replace this server. Google is easier to replace the data center, we server yet. Corruption checksum we almost did not happen. To be honest, I do not remember when it was the last time. Simply we update wizards often enough. We have the life of a master is limited to 60 days. It cannot live longer, after that we replace it with a new server, because for some reason something constantly accumulates in MySQL, and after 60 days we see that problems start to occur. Maybe not in MySQL, maybe in Linux.
We do not know what the problem is and do not want to deal with it. We just limited the time to 60 days, and update the entire stack. No need to stick to one master.
- You said that in the last 6 days you can recover from a backup to any state. For example, a person uploaded a JPEG with the same name, then uploaded the same JPEG, but modified, then can you get the first version? That is, it turns out, you keep the versioning of files and some metadata with versions? If a person asks - I want to get the first version of the file, can you give it to him or not?
We store information about the file, about the blocks. We can - Dropbox has the ability to recover files.
“How do you clean it all up later?” No problems with fragmentation on disks and so on? A lot of data is erased from the disk, it turns out, after some time, when the version becomes unnecessary, rotten? Suppose a person has uploaded 10 versions of files alternately. Obviously, after 7 days in the backup, you will realize that you do not need the first 6 versions, and they need to be deleted. Or are they stored forever?
In general, Dropbox has some guarantees for how long the version is stored. This is slightly different. There is a system that can recover files, and there the files are simply not deleted immediately, they are put in some kind of recycle bin.
There is a problem when absolutely everything is removed. There are files, there are blocks, but there is no information in the database how to assemble a file from these blocks. At such a moment we can lose up to a certain point, that is, we recovered in 6 days, lost until the moment when this file was deleted, did not begin to delete it, restored it and gave it to the user.
Follow the blog or subscribe to the newsletter , facebook or youtube channel - we regularly publish fresh materials and updates in the preparation of Highload ++ 2018 . In the latter, you can take an active part, by September 1, sending an application for a report .
Source: https://habr.com/ru/post/417315/
All Articles