OmegaT: translate by computer
How to translate a document in Word and not to bathe with formatting ? How not to translate the same thing? How to maintain uniformity? How not to buy expensive programs? How to work efficiently and quickly?
If you are familiar with Trados, MemoQ or CrowdIn, go directly to the installation instructions. If these are new words for you - welcome to the wonderful world of Computer Aided Translation.
- About translation using a computer
- What are CAT programs?
- What can OmegaT do?
- Installation
- Spell checker
- How to create a project
- What are these folders?
- How to add files
- Interface
- How to translate
- Fuzzy Matches
- Automatic translation of identical segments
- Glossary
- How to save files
- We connect the machine translation
- Check for errors
- Open and edit TMX
- We create TMX
- We consider the volume of the project
- We merge and divide segments
About translation using a computer
Google Translate - machine translation, computer translate for you. CAT - the principle of operation, when the computer only helps in the work, automating routine processes.
')
CAT programs divide the source text into segments — lines, sentences, paragraphs, or paragraphs. The person translates the segment one by one, and the translation is stored in a special database - translation memory (translation memory, TM ). If the translator encounters a similar segment , the program will display a hint or a possible translation. And the program can translate identical segments by itself .
CAT helps especially well in translating instructions , legal documents , program interfaces - where similar language is found very often . Help in literary translation will not be so obvious, but more on that later.
The more texts on similar topics you translate, the more translations accumulate in the database , and more often hints appear. Over the years, such a base may accumulate that in the new document half of the translation will be ready “by itself”.
When the translation is completed, the program creates a document that is identical to the original - preserving the structure and formatting, but replacing the source text with your translation.
CAT-programs do not change the original document, therefore it is impossible to irreversibly spoil the document. The output will be a fully translated file.
What are CAT programs?
Various. Trados , MemoQ - expensive corporate complexes, installed on the computer. CrowdIn , Tolmach and others work directly in the browser. As a rule, everything costs money, or there are restrictions on the volume of projects.
But not everything is so bad: for eight years now I have been using OmegaT , a free open source program that runs on Windows, Mac and Linux systems and is constantly being improved by the community. I work in it with Chinese , English and Russian.
What can OmegaT do?
 OmegaT
OmegaTwww.omegat.org
Freeware (GPLv3), open source
Windows, macOS, Linux
He knows how everything described in the first chapter - to help the translator in his work, and various other trifles.
File formats
- Microsoft Word, Excel, PowerPoint (only new .xlsx, .docx and * .pptx, you must first convert old ones)
- OpenOffice .ods, .odt, and others
- Text Files .txt, .rtf
- Text files of the key = value structure (* .ini and the like)
- HTML
- Files with XML structure (you can customize it yourself)
- And many others.
Languages
Any. Almost everything that is in Unicode. For rare languages it may be necessary to adjust the segmentation rules, but everything is solved.
I will not retell the instruction . It is complete and informative, and it is very important to read it. Then there will be only basic operations with the program that will help you get started.
Installation
Download the distribution from the site omegat.org . I will use the English version 4.1.1 Branch Latest for Windows. Java is required to run. If you are not sure if you have one, download the version marked JRE. Do not be intimidated by Beta, the program is more than stable.
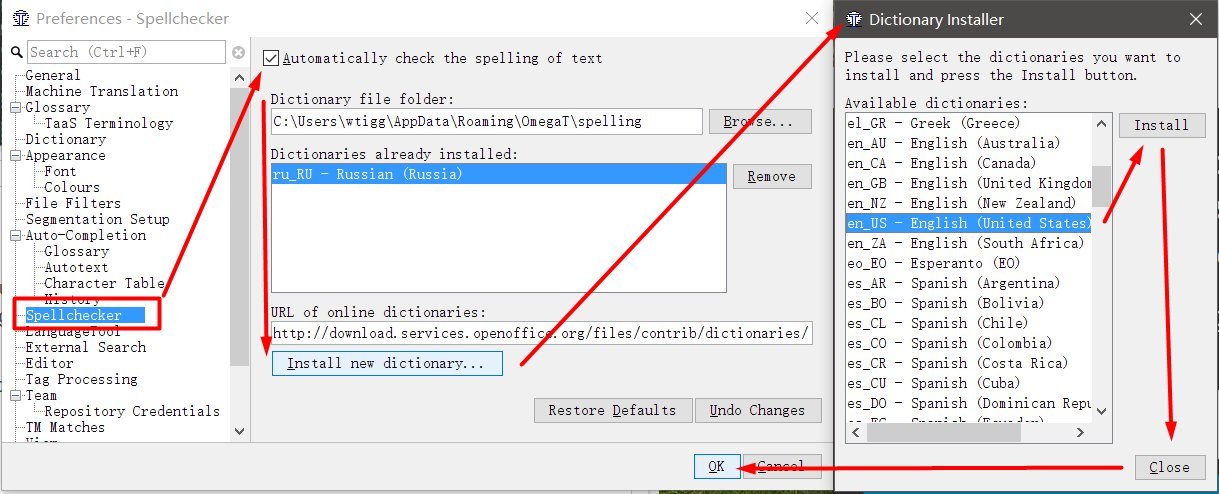
Spell checker
After installation, the program is ready to work, but by default there is not enough spell checking.
- Run OmegaT
- Go to Options → Preferences → Spellchecker
- Put a checkbox Automatically check the spelling of text
- Click Install new dictionary
- We select language (for example, ru_RU for Russian), we click Install
- Click Close . In the list we see the Russian language.
- Exit the settings.
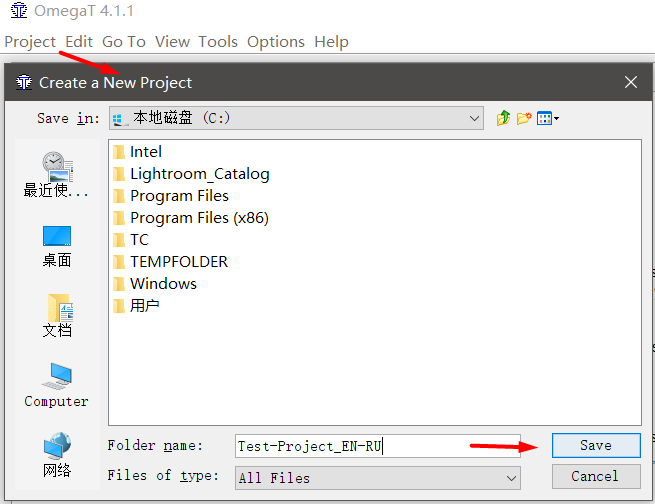
How to create a project
OmegaT does not work with individual files, but with “projects”. A project is a set of folders with a specific structure. To translate a file, you need to create a project, and then add the file there.
- Run OmegaT
- Project → New , choose a place to save and the name of the project. I recommend giving projects meaningful names and indicating the language pair in them. For example, Test-Project_EN-RU .
- In the window that appears, specify the language pair
Source Files Language - the language from which you translate; Target Files Language - the language you translate. Specify the need in two-or four-letter code. For example, RU is Russian, and RU-RU and RU-BY are clarification that this is Russian from the Russian Federation and Russian from Belarus. In order for the spelling checker to work, the code must match the code specified in the spelling settings (if RU-RU is set in the spelling and RU is in the project, then the check will not work). - Check the box below Enable Sentence-level Segmenting (divide segments by sentences, not paragraphs) and Auto-propagation of Translations (substitute translations automatically). Checkmark Remove Tags (remove tags) is better to remove, I will explain her work later.
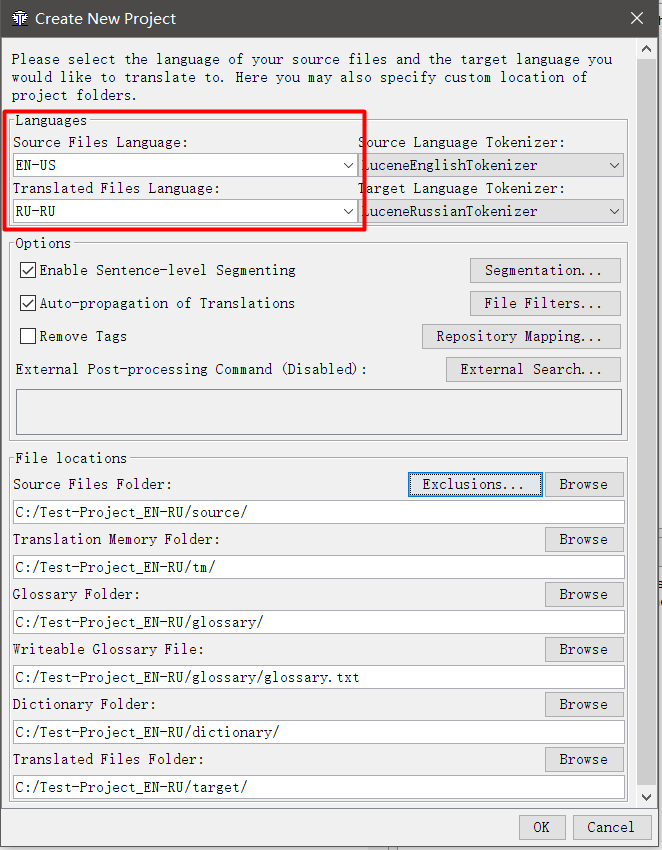
- Click OK .
What are these folders?
Inside the project folder there are several sub-directories:
- dictionary - you can add dictionaries in StarDict format; the function is pretty useless.
- glossary - base terms for the project, more on that later;
- omegat - translation memory and backup project;
- source - folder with the source files;
- target - the folder in which the translations will appear;
- tm - a folder for additional translation memories, more on that later.
As well as the omegat.project file with the configuration of the current project.
How to add files
Having created the project, you will see the following window:
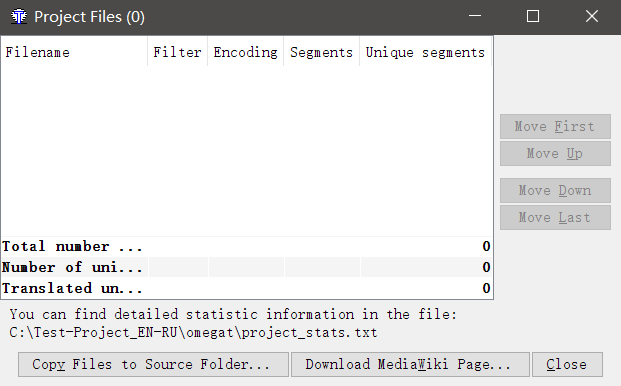
Click Copy Files to Source Folder and select the files you want to transfer. Files will be copied to the \ source \ folder of the newly created project. You can add files there manually. Just copy the files to \ source \ via explorer.
For example, I created two files - Excel and Word, on which I will show the work of OmegaT.
Interface
OmegaT is running, files are added. Let's see how they look in the program.
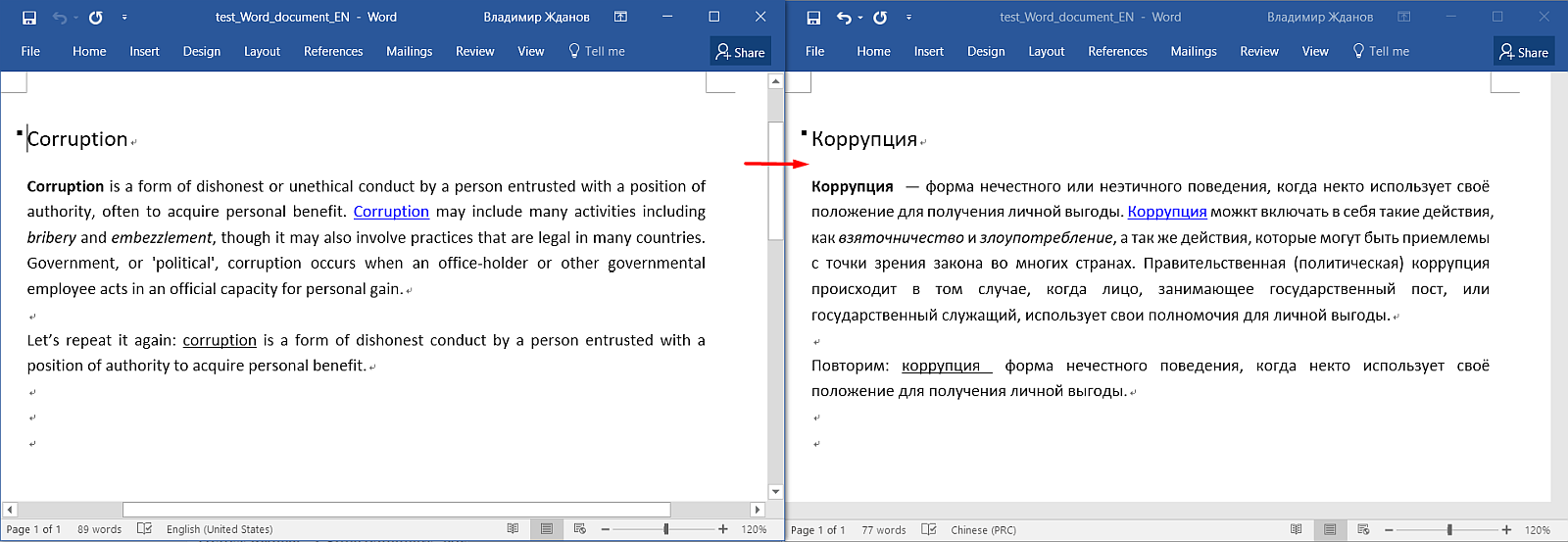
Here is the original document in Word. Here you can see the title, paragraphs, formatting (bold, links, underscores).

And this is how it looks in OmegaT:
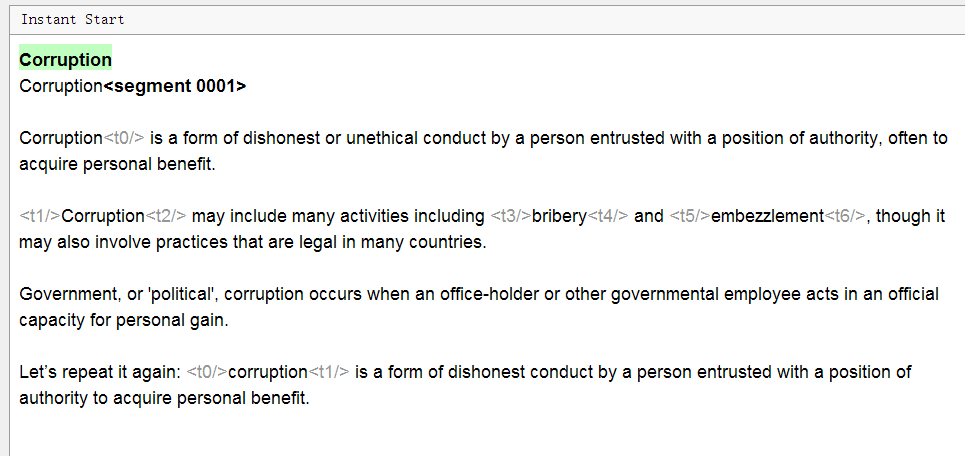
Please note: all text is divided into sentences, formatting is not visible, some gray tags have appeared, and the title is duplicated. What's the matter?
- The text is divided into segments
Each offer stood out in a separate segment. The segmentation rules can be configured independently if necessary. - Formatting in OmegaT is not visible, it is replaced by tags
They are shortcuts for tags from Word that might otherwise look like <t>. To keep the original formatting, you need to leave these tags as they are, inscribing the translation between the tags according to the same logic as in the original.
The option Remove tags in the project settings removes tags along with formatting. It is not recommended to use if it is important to keep the original formatting. - The title is not duplicated.
In fact, the text in the source language is always displayed on top (in green); it cannot be changed. Below it is a text field where the same text is copied by default. It needs to be removed and the translation entered.
In addition, on the right side of the program there are two more sectors: Fuzzy Matches and Glossary (project dictionary).
Fuzzy Matches (fuzzy matches) - search results for the project database. There will be translation tips based on your previous translations.
Glossary (project dictionary) - the search result in the glossary, which you make yourself. Unlike translation memory, this is not a finished text, but only hints on certain terms. It is a powerful tool that helps maintain consistency in terminology.
How to translate
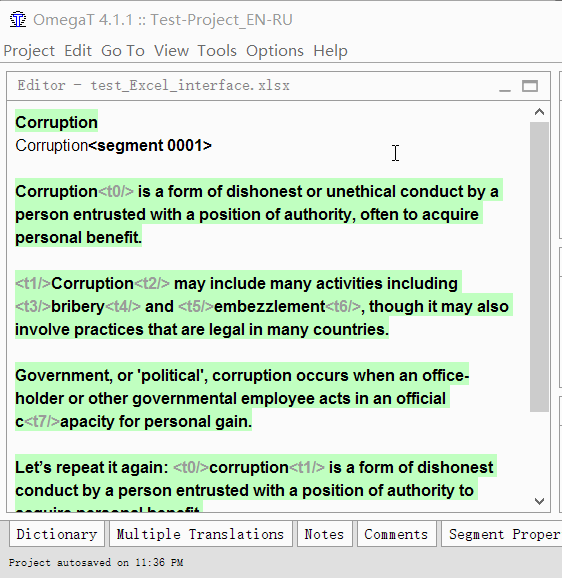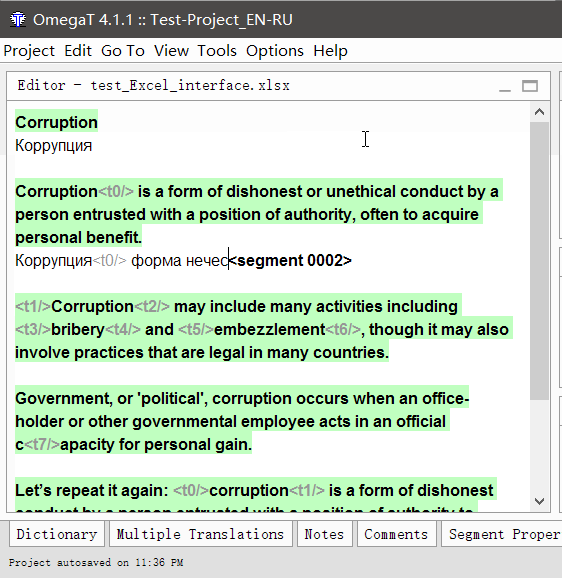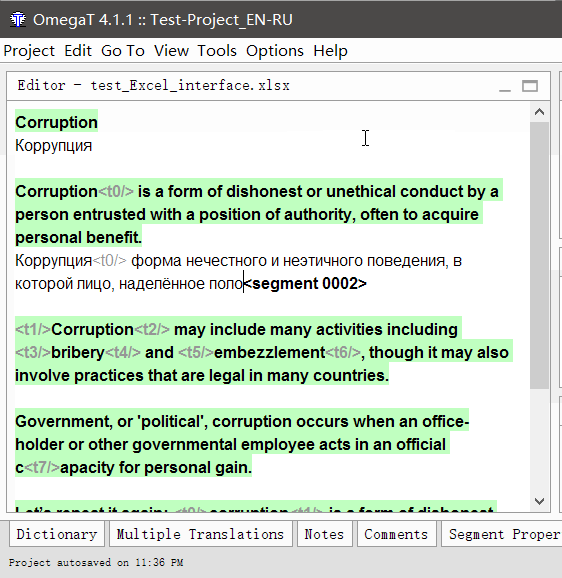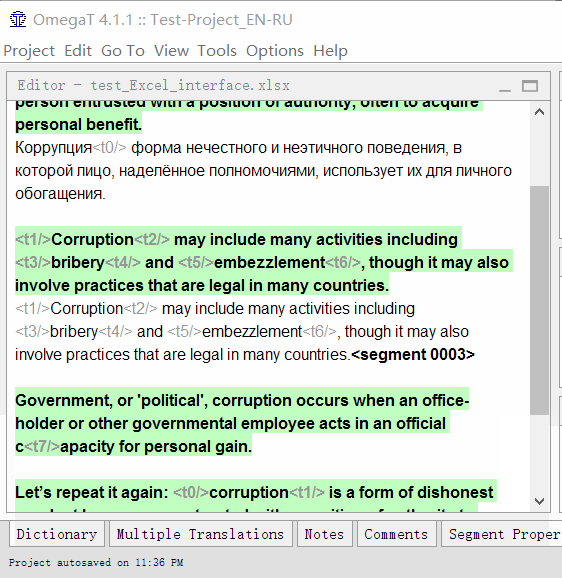
- Double click on a segment to translate.
An editable text line will appear under the original text, the cursor will be at its beginning, and the original text will be duplicated in the line. - Enter your translation
- Press enter
When pressed, the translation is saved, and the cursor moves to the next segment.
Repeat until you finish the document. At any time, you can return to the previous segment by simply double clicking on it.
In the lower right corner there is a convenient progress indicator . Click on it to switch view mode.
 Current file:% of segments translated (segments left) / Project:% of segments translated (segments left), total number of segments. [/ Caption]
Current file:% of segments translated (segments left) / Project:% of segments translated (segments left), total number of segments. [/ Caption]This line indicates that 5.8% of unique segments were translated in the current file, 1382 remained to be translated. In total, 63% of segments were translated in the project, 1756 remained, and their total number in the project is 5979.
 File: translated unique segments / total number of unique segments (project: translated unique segments / total unique segments, total segments in the project) [/ caption]
File: translated unique segments / total number of unique segments (project: translated unique segments / total unique segments, total segments in the project) [/ caption]In the second mode, the illustration says that 146 of 1592 unique segments were translated in the file, and 2992 were translated from 4748 unique segments in the project. The total number of segments (including repetitions) is 5979.
The numbers 14/14 at the end do not apply to the project counter. This is an indicator of the length of the segment you are working with. He says that there were 14 characters in the original, and there were also 14 in translation. This function is useful in cases where you need to strictly observe the length of the string, for example, when translating the program interface.
Fuzzy Matches
The main tool of any CAT-application, for this they exist.
I will explain with an example:
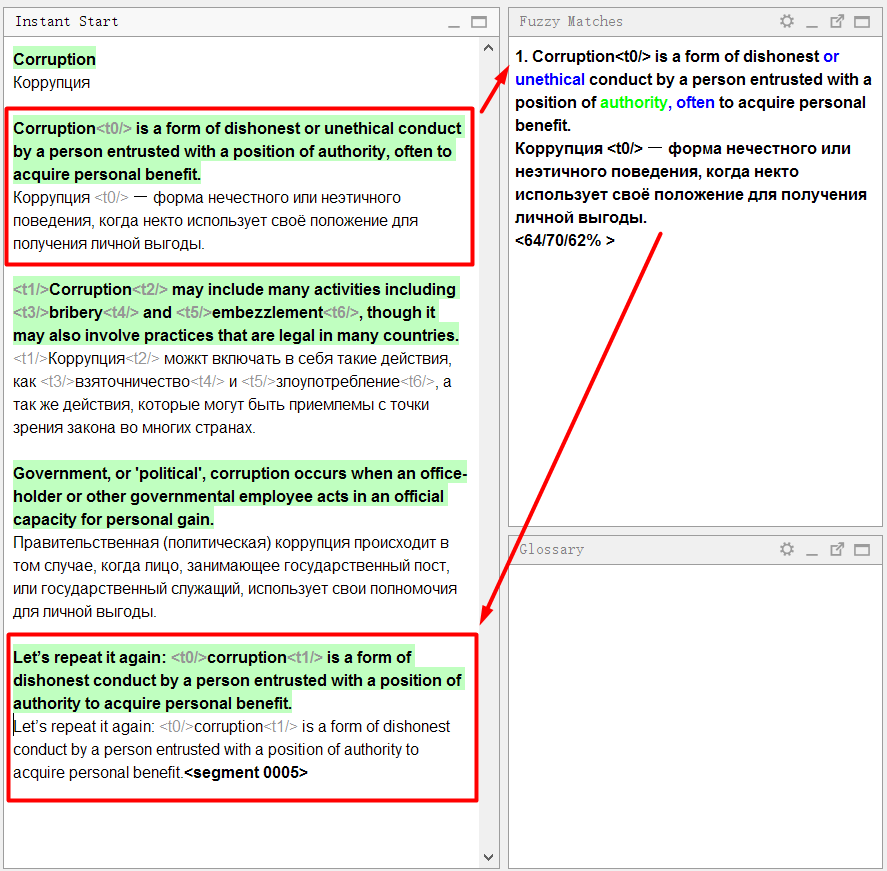
In the sample document, the first sentence is very similar to the fourth . I went in order and translated the first sentence. When I got to the fourth, the program immediately showed a fuzzy coincidence :
Look closely at the matches panel:
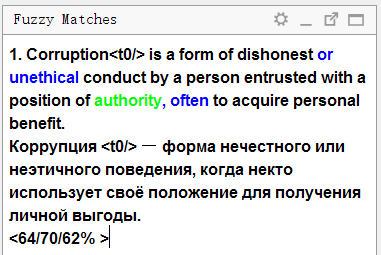
The upper part displays the text in the source language that was stored in the translation memory . The blue color highlights words that are present in the translation memory, but are missing in the current sentence (with which a match is compared), in green - words located next to the missing parts.
Below is the translation stored in memory. If you press Ctrl + R , it will be copied into the field for translation.
Below are three numbers in percent. They indicate the degree of coincidence between the sentence and the translation memory. More information about the calculation mechanism can be found in the OmegaT Help .
Automatic translation of identical segments
Of course, if the Fuzzy Match mechanism finds a 100% match , it can insert it by itself . For example, take another file, this time in Excel. Approximately in this form, an order often comes to translate the interface of a website or program.
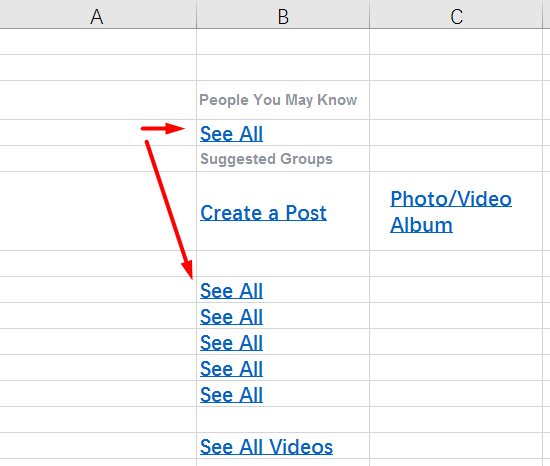
And this is how the file looks in OmegaT:
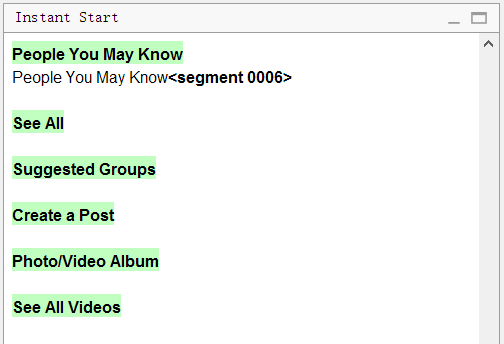
Please note that there were six See All lines in the original. The program removed all duplicates, leaving only one line. It is enough to translate it alone, and the remaining segments will also be translated.
Glossary
The glossary works very simply. First you add words to it (original and translation). Now, when the word is found in the text, a hint will immediately appear in the Glossary window.
Thus, when a term appears in a new sentence, you will immediately know exactly how to translate it. For example, if you always need to write “OK” instead of “OK” when translating the program interface, you only need to add the word “OK” to the dictionary with the translation “Ok”. Adding a few hundred words to the project will make your life much easier.
To add a word to the glossary , select it, right-click and select Add Glossary Entry .
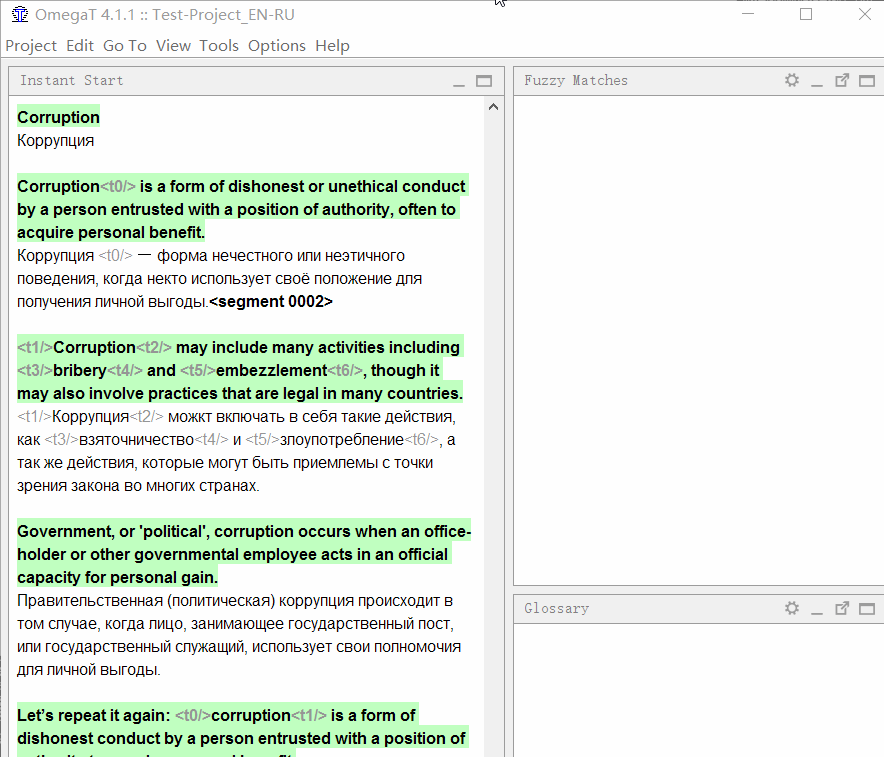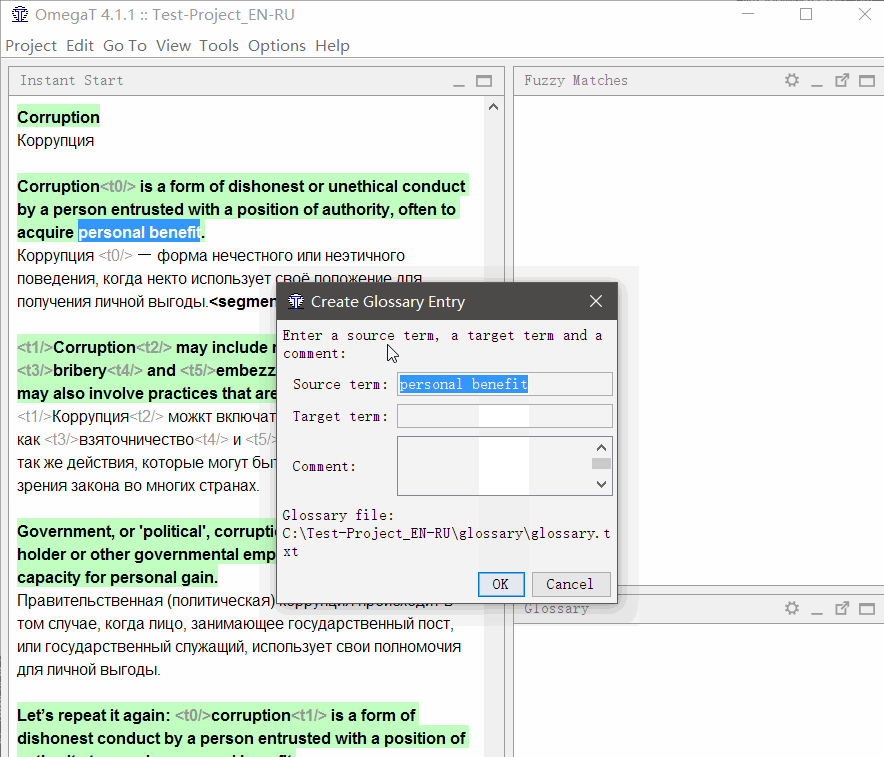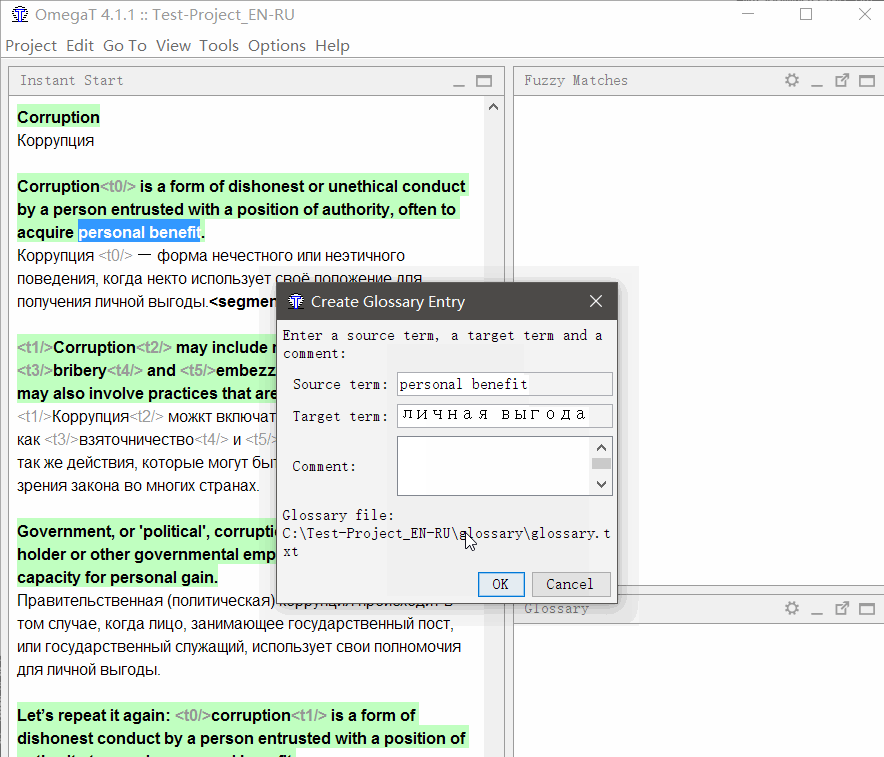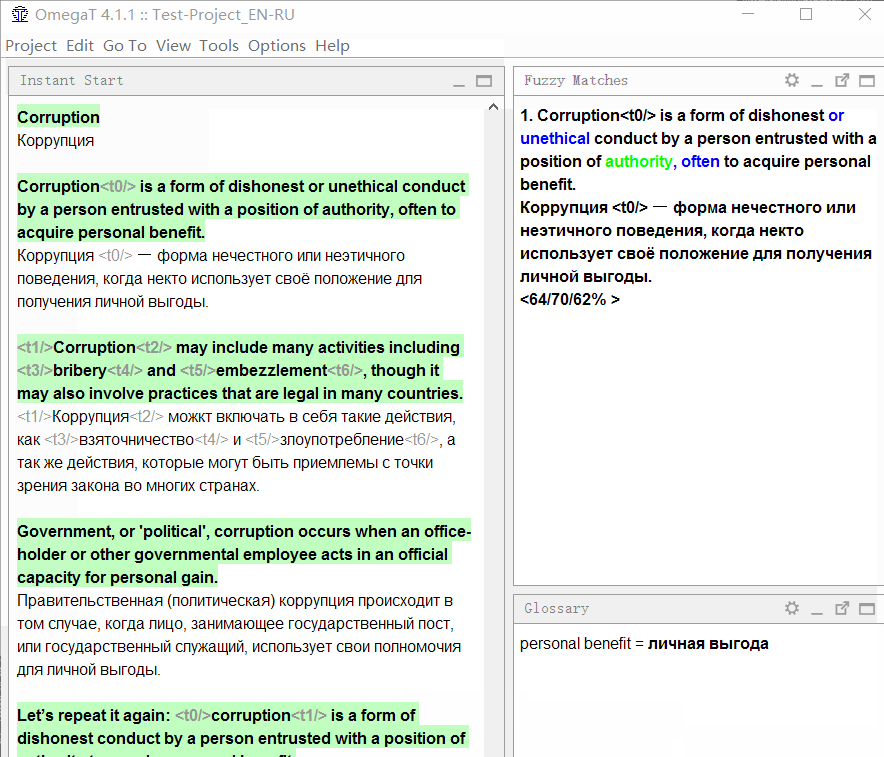
In addition, words can be added en masse to the file \ glossary \ glossary.txt in the format “original tabulation translation” (an Excel spreadsheet saved in tab-delimited * .csv format will do)
How to save
Item Project → Save means “save project”, i.e. write all translations to a database file. And to get the finished file , select Project → Create translated documents .
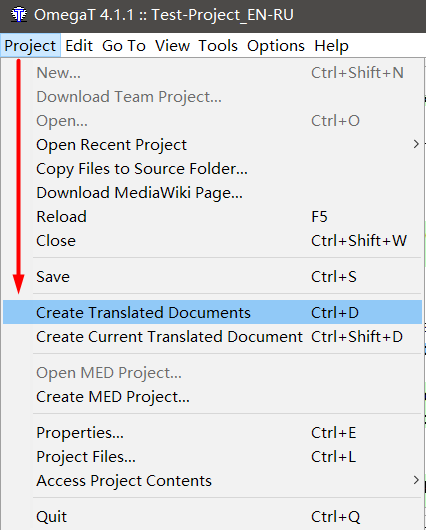
Using this command, OmegaT will create a new file in the \ target \ folder with the same name as the original, and change all text to translation . If you have not translated any segments, then the original text will be in their place in the file.
How to add machine translation
In some situations, machine translation (such as Google Translate ) can help translate faster. OmegaT can be configured in such a way that right in its interface the machine translation of the segment is displayed, which you can use directly or very quickly edit.
In OmegaT you can connect such systems as Google Translate , Microsoft Translator and Yandex . Translator . You will have to pay for the first two, and Yandex.Translator provides its services for free (within reasonable limits of use). Now I will tell you how to do it.
- Register an account in Yandex.
For example, get mail. - Go to the developer page in the section "Translator" at this link .
- Click Create a new key , enter a description (for yourself), click Create.
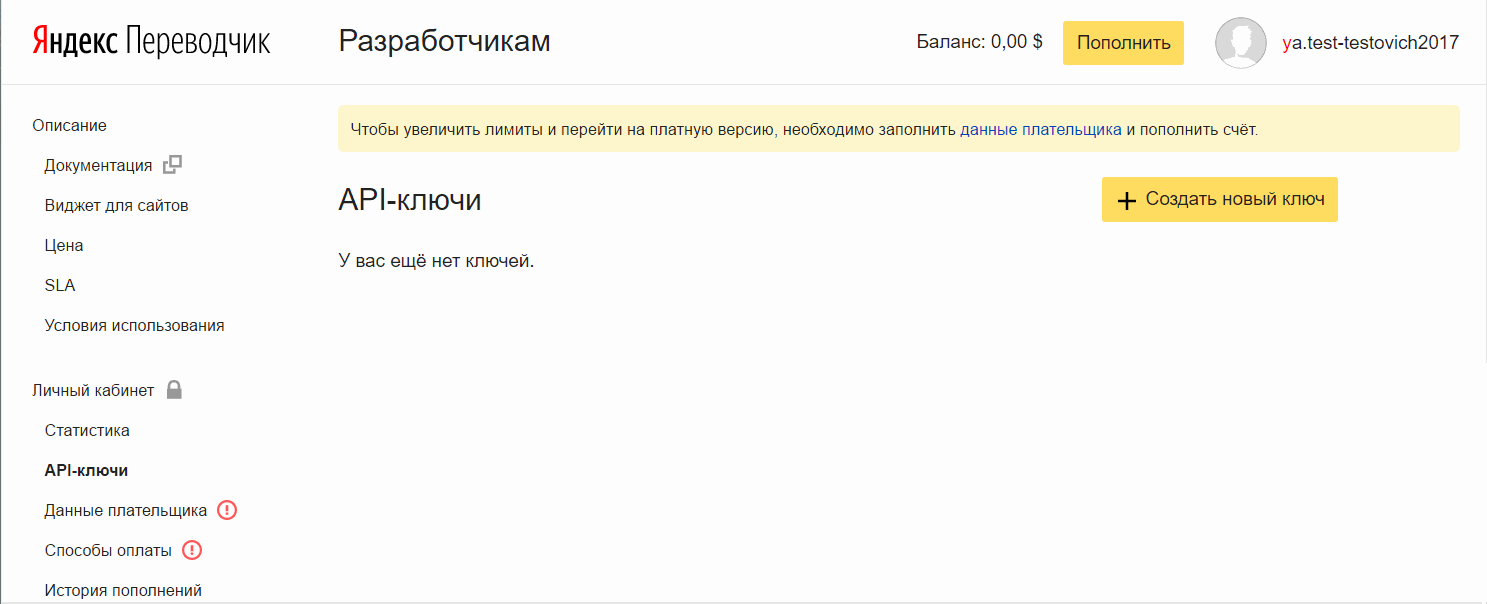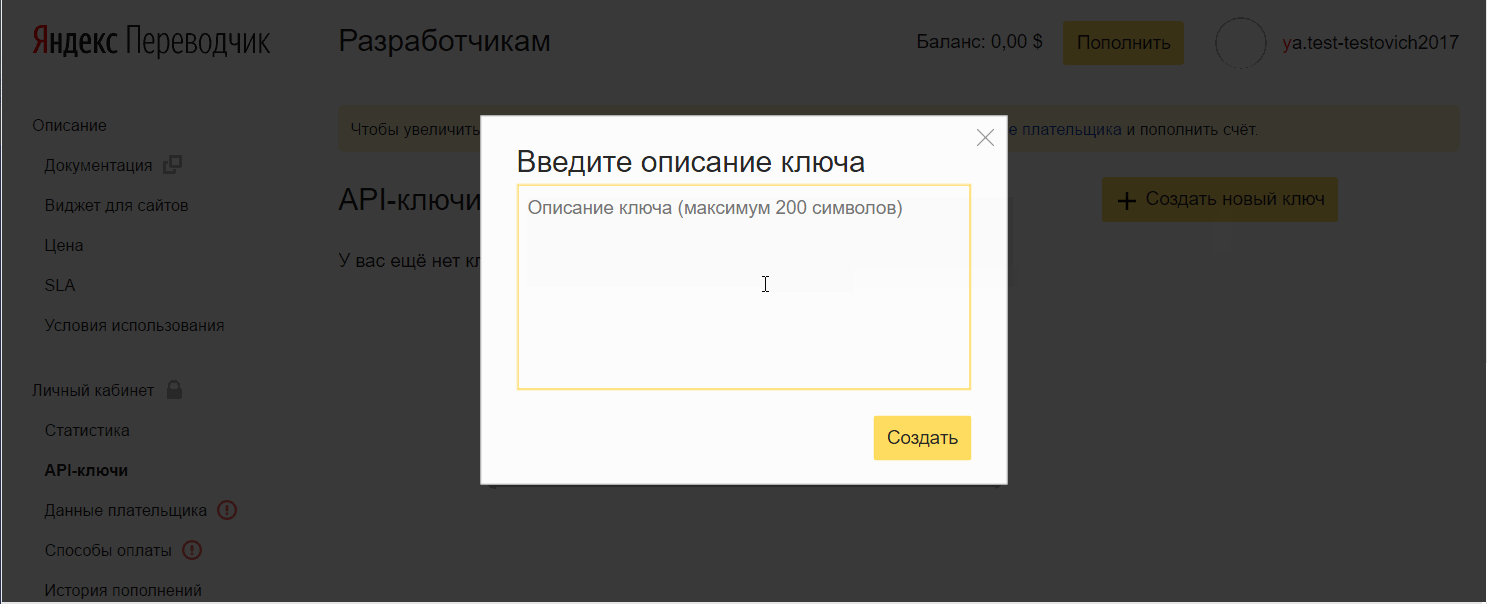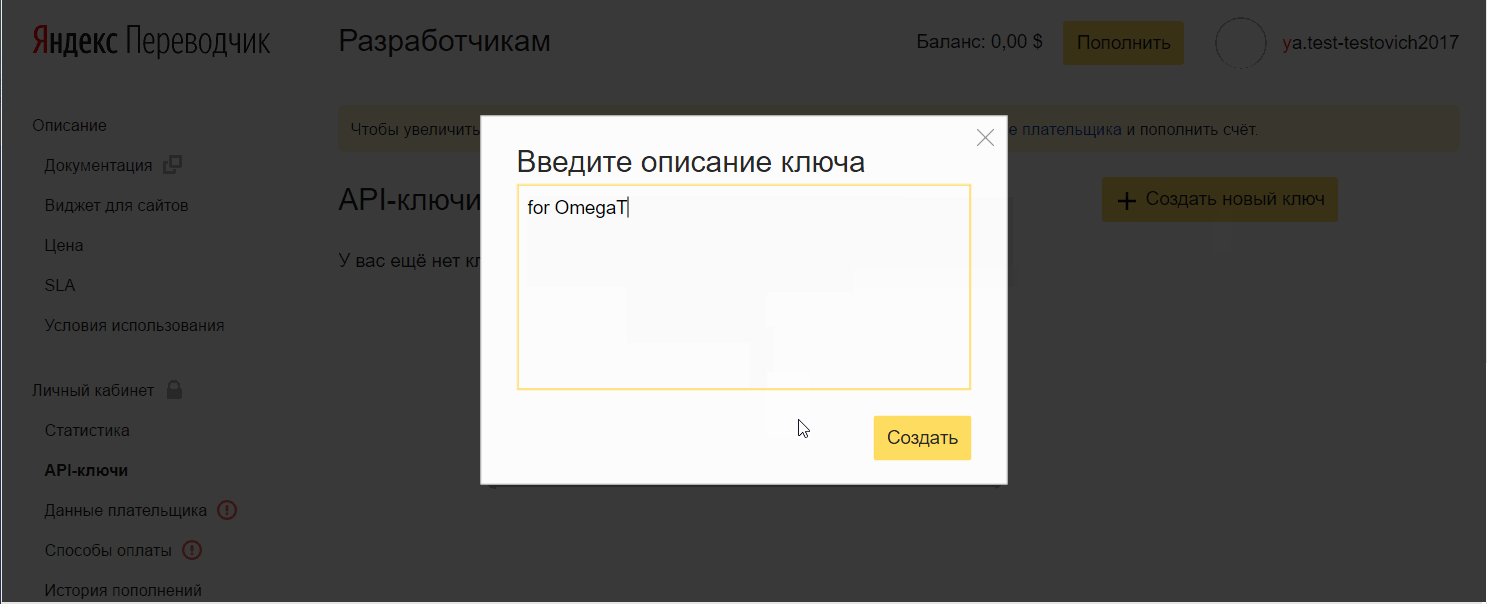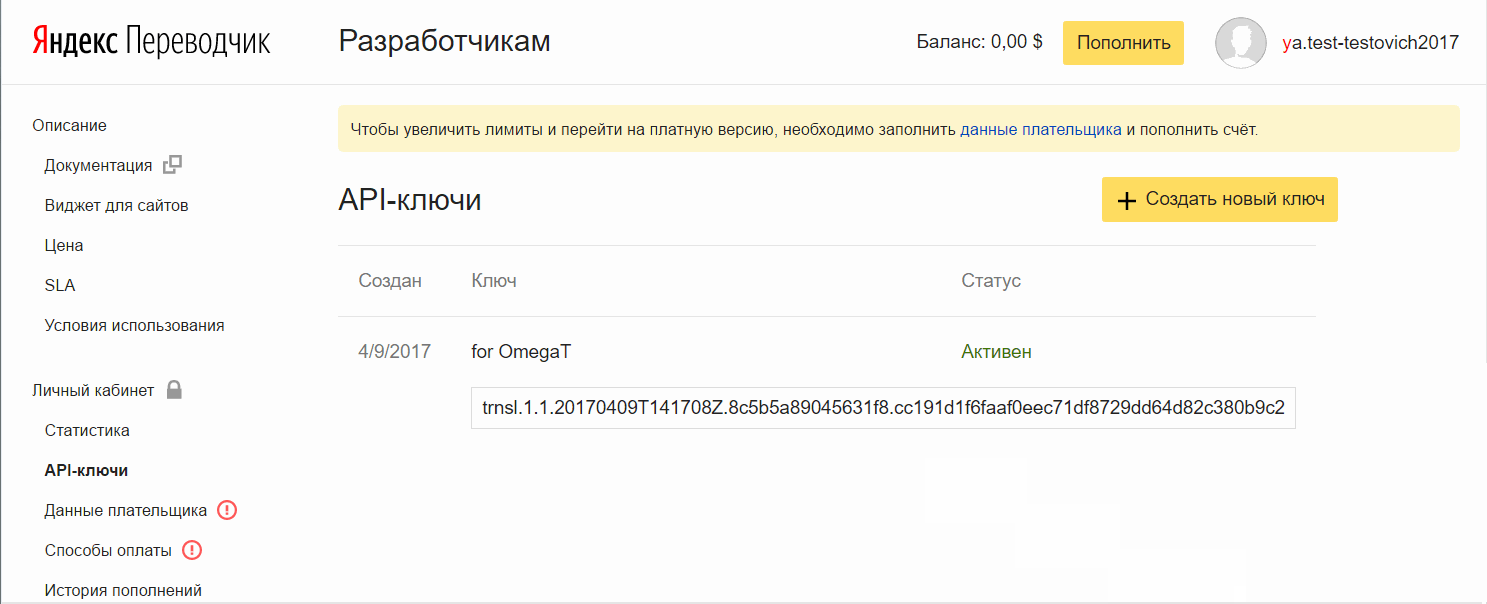
Add a key to OmegaT:
- In OmegaT, go to Options → Preferences → Machine Translation
- Select Yandex Translate , check it and click Configure.
- Copy the API key in the field that appears, click OK
- In the window that appears, you can set a password or skip this action.
A password is needed to protect your API key. Actual for paid translation systems.
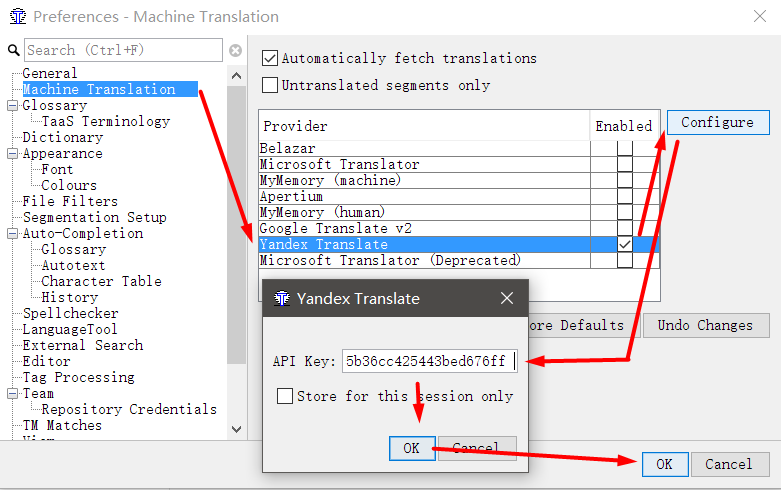
Close the settings. Now in the main program window you can click on the Machine Translations tab at the bottom of the window. To keep the window with machine translation always visible, click on the small icon with two windows.
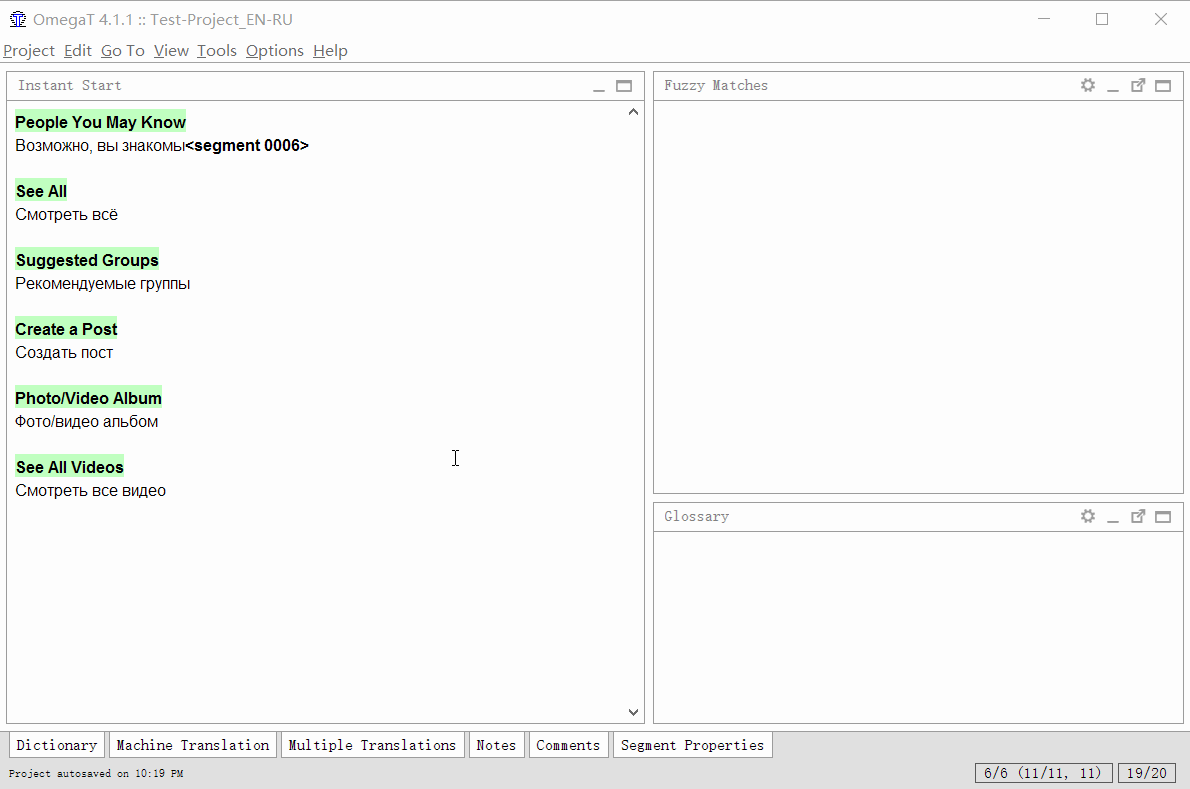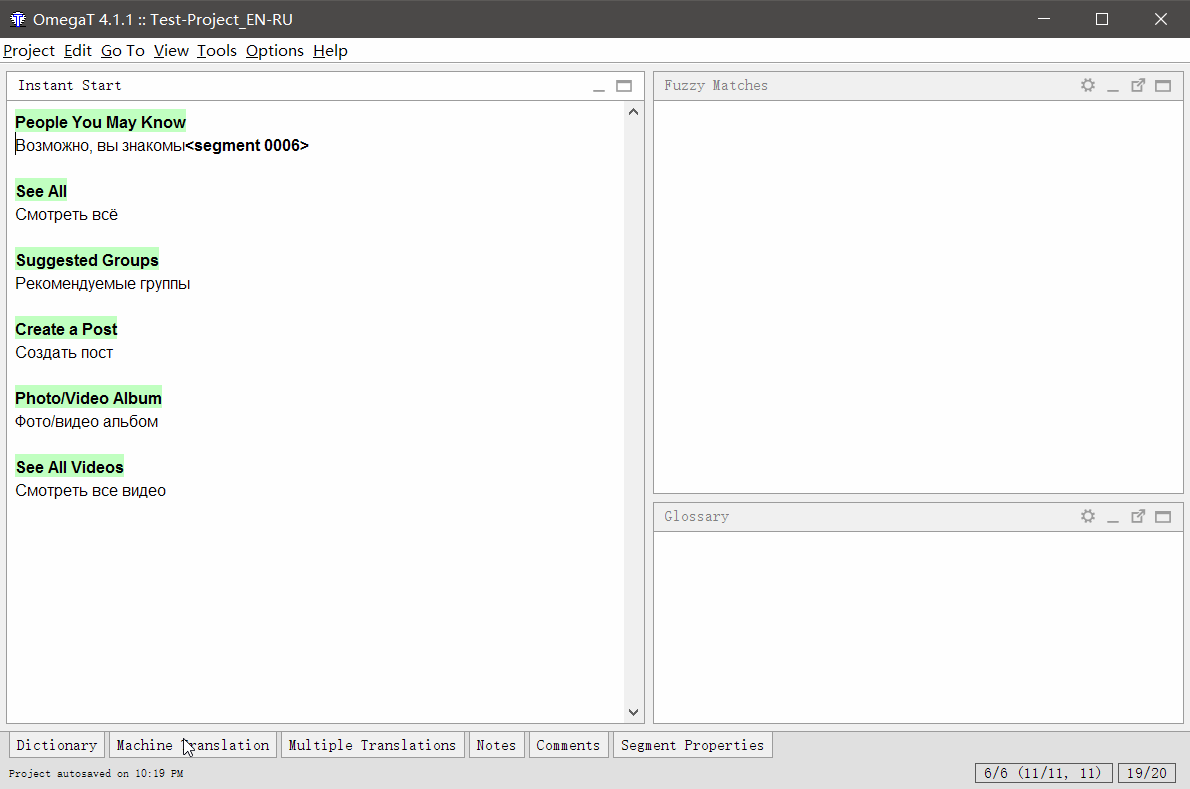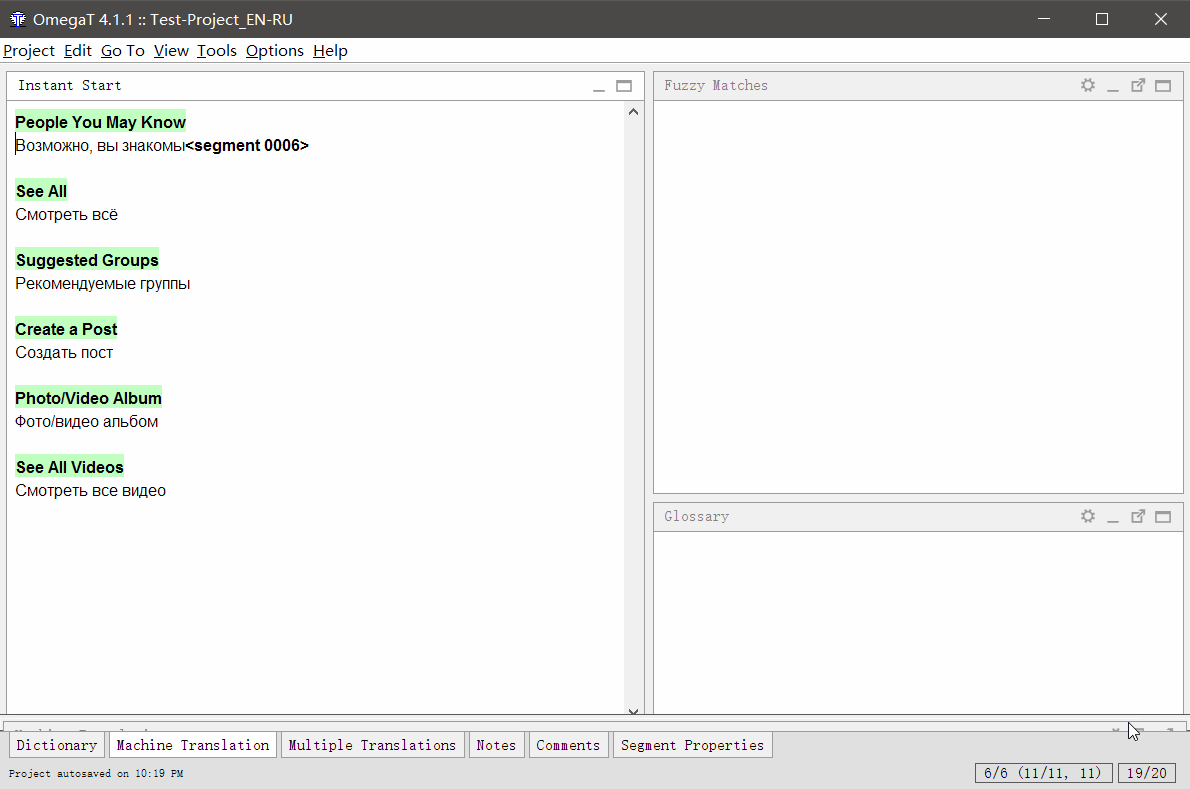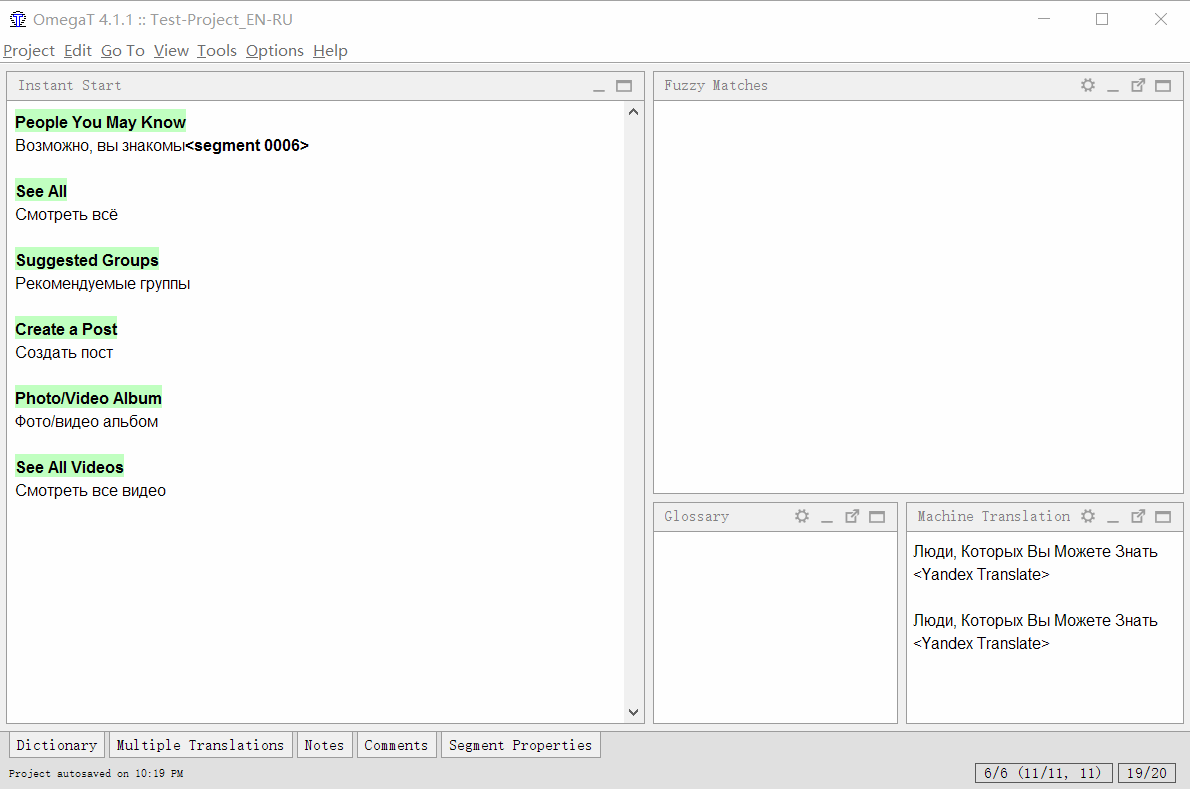
Now, when moving to a new segment, the program will make a request to Yandex.Translator, receive an answer and show it in the window. Using the Ctrl + M hot key, you can paste the result into the translation field.
How to check the text for errors?
In addition to the simple spell checker that we set up earlier, you can check for more complex errors, from stylistics to missing tags. To do this, OmegaT uses the open source Language Tool . It comes bundled with OmegaT, then you can install it separately, or connect to a remote server.
- Tools → Check issues (or Ctrl + Shift + V )
- Double click on the error from the list to go to the segment for editing.
On the right click you can add a word to the dictionary, or disable the check for this type of errors.
On the left, in the Check issues window, you can select the Tags filter. It is useful in translating documents with a large number of tags, which are very important to save - for example, when localizing software.
Tip: If you want to save tags at any cost, you can prohibit OmegaT from creating final documents if there are errors in the tags. This is done in Tools → Preferences → Tag Processing → Do not allow creating documents with tag issues .
Language Tool tweaking is available via Tools → Preferences → LanguageTool. Here you can choose whether to use the built-in Language Tool, or connect to a local / remote server. Below you can choose the type of errors to which the program will react, for example, " Punctuation " → "A comma is missed before the preposition" and "in a complex sentence ", or " Style " → " Speaking words ".
How to open TMX translation memory?
It happens that you need to look in the * .tmx file, or even edit it. The structure of the file is quite simple, and in extreme cases, you can do with a notebook, but this is not very convenient. OmegaT cannot open TMX itself for editing: translation memory can only be added to a project, but not opened by itself.
For Windows users, the free Olifant utility from the Okapi package is suitable; you can download it here .
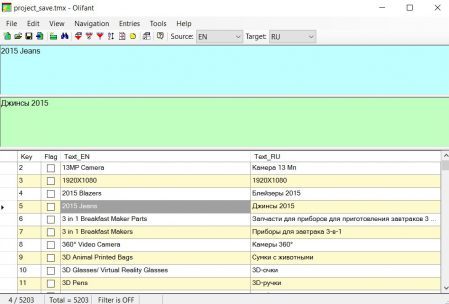
I see no reason to write step-by-step instructions for this program, everything is intuitively clear: File → Open , select the translation memory. At the top of the program, the original and translation, at the bottom - a list of all segments.
Via File → TM Properties, you can change the properties of the translation memory, such as language pairs, encoding, and so on.
How to create your TM?
Suppose you already have a quality bilingual file, and you want to use it in your project as reference material. If the file is in Excel format, where the original text is in one column and the corresponding translation is in the opposite cells, it is very easy to make a TM.
There are three ways that I use:
Olifant
The program, which we talked about in the previous chapter, can not only open finished TMX , but also create new ones, as well as combine several * .tmx into one memory.
Install and run Olifant , click File → New and select the source language and the translation language. Now add to the new memory bilingual segments: File → Import . You can add Wordfast files , other * .tmx or Tab-delimited files — in other words, a text file, where the source fragment and its translation are separated by tabulation.
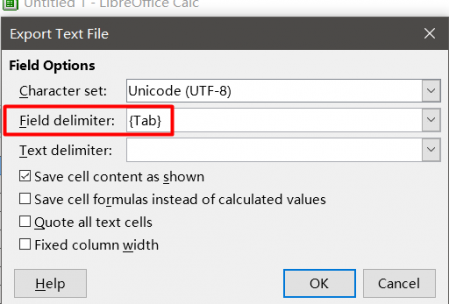
Tab-delimited file can be created in MS Excel or Libre Office Calc . To do this, create a table with two columns. In the first one, insert the source text, in the cells opposite in the second column - the translation.
Save the file in Tab-delimited text format (in Microsoft Office ), or in Text CSV with Field delimiter = Tab, Character set = UTF-8, and Text delimiter = * blank * if you are using Office Libre .
When importing all the necessary fragments, simply save via File → Save As in TMX format .
OmegaT Aligner
Unlike Olifant, the source is not a table with two columns, but two independent files with identical structure, but in different languages. The more complicated the formatting and the more differences, the worse the result of the automatic matching will be, but it can be corrected manually inside the Aligner .
Launch OmegaT , open Tools → Align Files . Specify the languages of the original and translation, attach files.
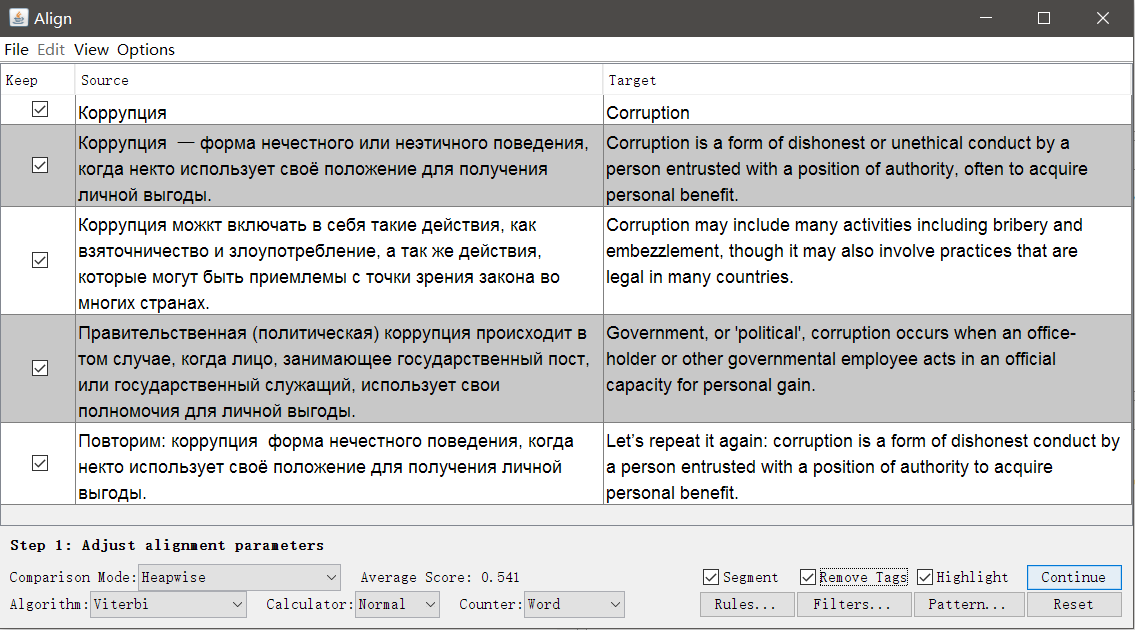
If necessary, you can remove the tags and change the segmentation parameters. Click Continue , and you will go to the window with manual adjustment of segments: you can split, merge or move the segments up or down.
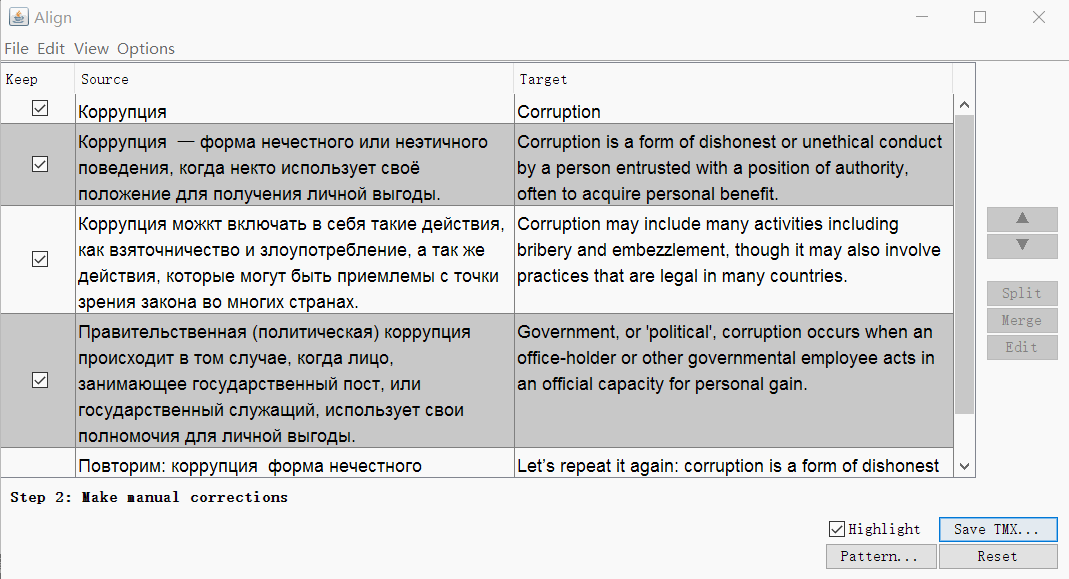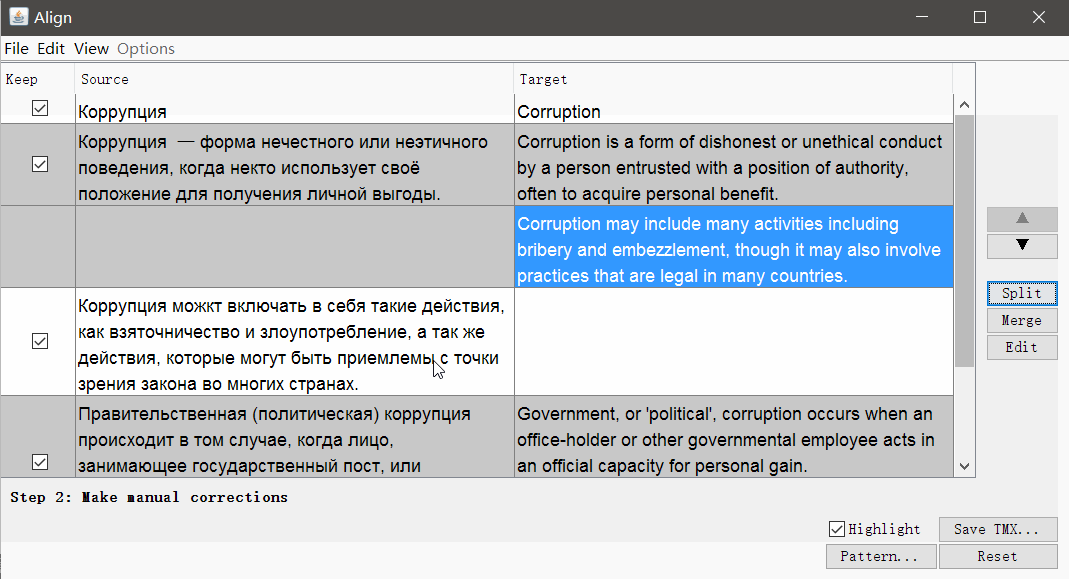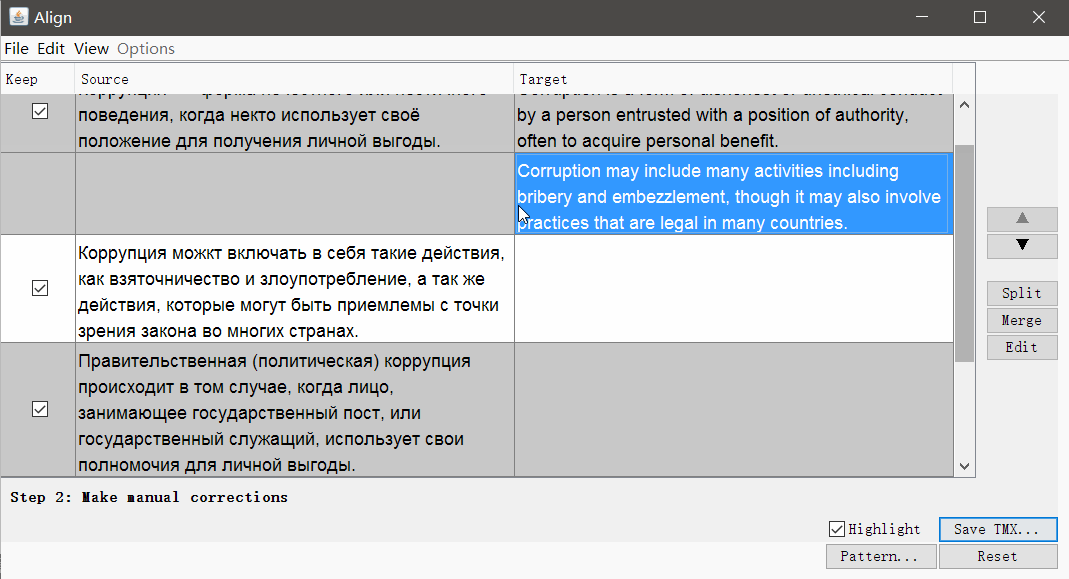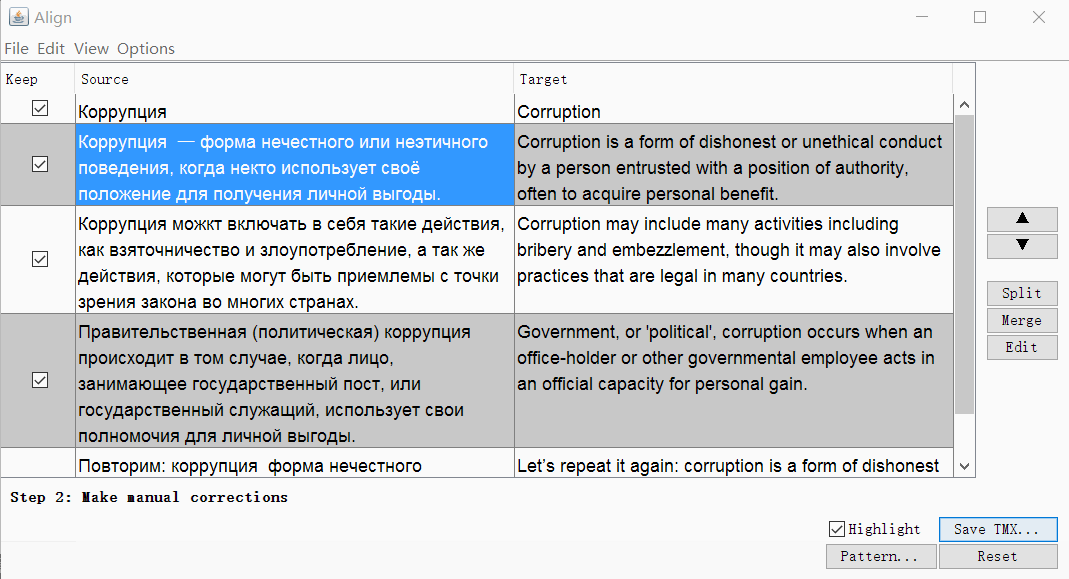
When everything looks good, save the result with the Save TMX button.
Translatum.gr
It works similarly to Olifant , at the entrance you need to submit an Excel file with two columns of text.
- Create a new Excel file (* .xlsx is required)
- Insert the original text in the first column , translation into the second
Do not use formatting, it will not be saved - Follow the converter link
- Select created file
- Specify source and target language codes.
For example, if you have an English-Russian text, it will be EN-US and RU-RU - Click Submit
- A page will open with which you can download an archive with translation memory.
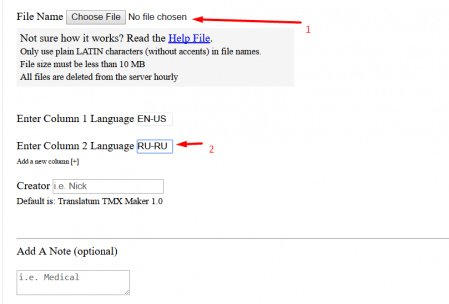
To use the translation memory in the project, unpack the archive and place the file in the project folder, subdirectory \ tm \ (to display fuzzy matches) or \ tm \ auto \ (to force the use of 100% matches).
Attention!
There is a rather unpleasant bug in creating translation memory, where special characters like ">", "<" and even apostrophes are used. TMX is an XML structure, so special characters used in the document structure are converted into “safe” chunks of text. For example, the apostrophe 'will turn into & pos; (ampersand, pos and semicolon).
In some situations, this can trash translation memory. In truth, I have not yet found a solution to this problem.
How to calculate the volume of the project
We must tell the customers how much you will charge for the translation!
In fact, nothing is easier. Open the project in OmegaT , go to Tools → Statistics .
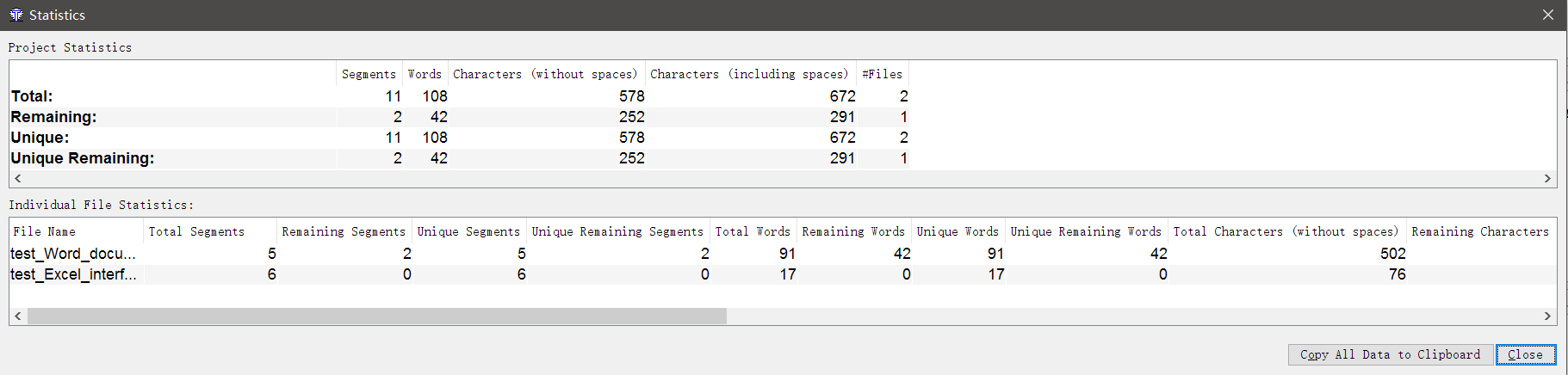
Here you will find comprehensive information on how many words and characters are in the files, how many repetitions are there, how many have already been translated and how much is left to translate, and so on.
Unfortunately, there is no calculator of the cost of translation in OmegaT, you will have to calculate everything yourself.
How to merge and split segments?
It happens that you want to combine two segments into one, or vice versa, to force a particular segment to split into two parts. If the problem is encountered with a large number of segments in the project, then it is worth reconfiguring the segmentation rules. If you need to point or merge segments, use the special Merge or split segments script :
- Install the script
Download here , unpack to the \ scripts folder (on Windows, this could be C: \ Program Files (x86) \ OmegaT \ scripts \) - Make Project Specific Segmentation Rules
Project → Properties → Segmentation → tick the checkbox Make the segmentation rules project specific - Set the script button
Tools → Scripting, in the left part of the window, find Merge or split segments, select it with a mouse click, and then right-click on one of the numbers at the bottom of the window. For example, by one. And click Add script.
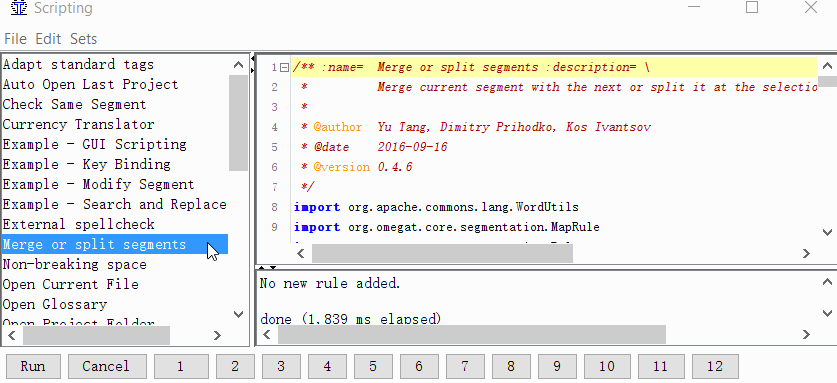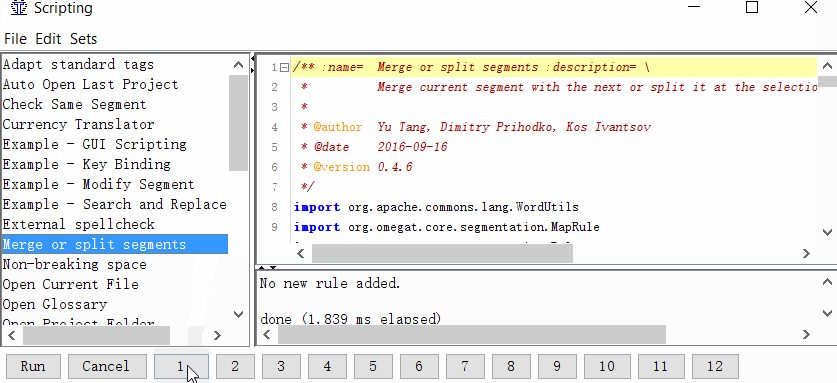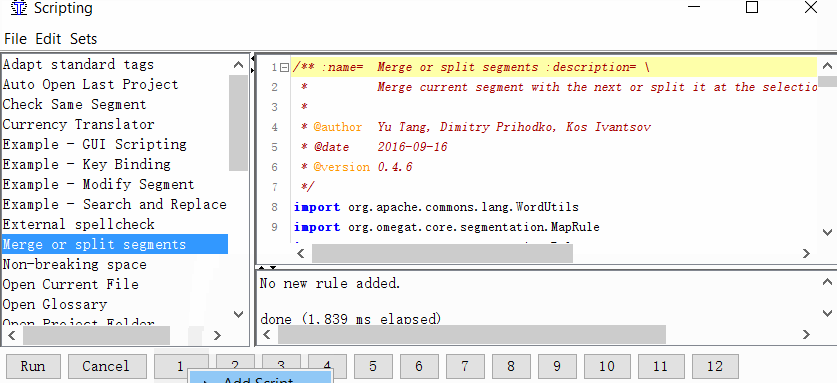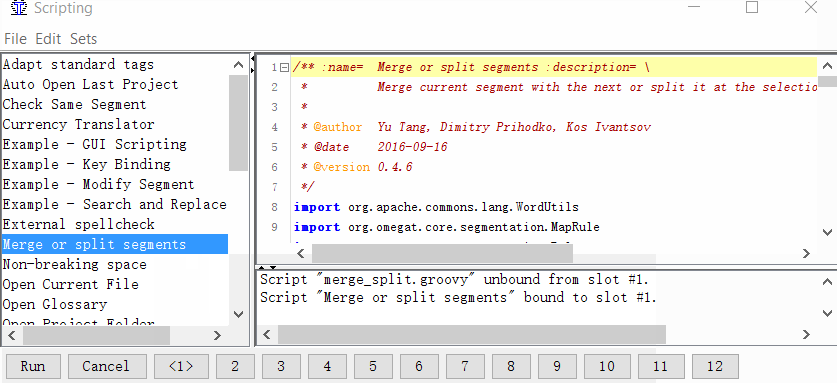
Now you can merge or split segments.
Union
- Find two segments following each other that you want to merge;
- Go to the first segment;
- Click Tools → 1. Merge or split segments
The program will display a warning with the result of the combination. You can click OK to merge, or cancel the action.
Separation
- Find the segment you want to divide;
- In the source text of the segment (above the translation), select the second half of the text (from the middle to the very end) that you want to make separate segments;
- Click Tools → 1. Merge or split segments
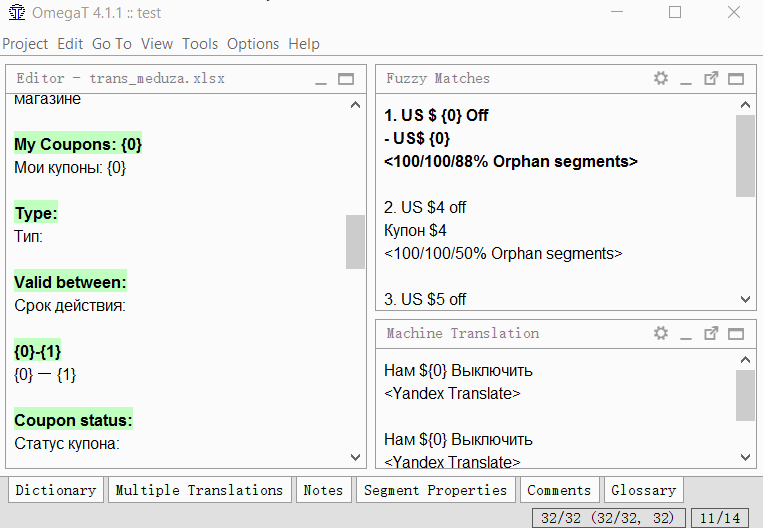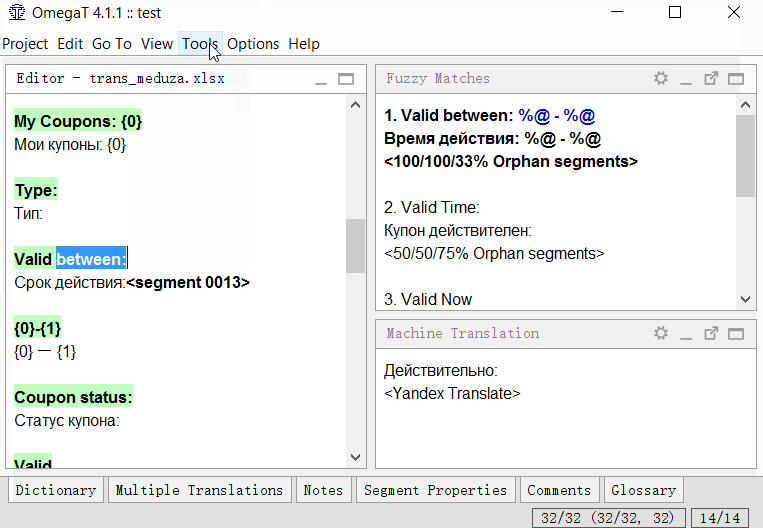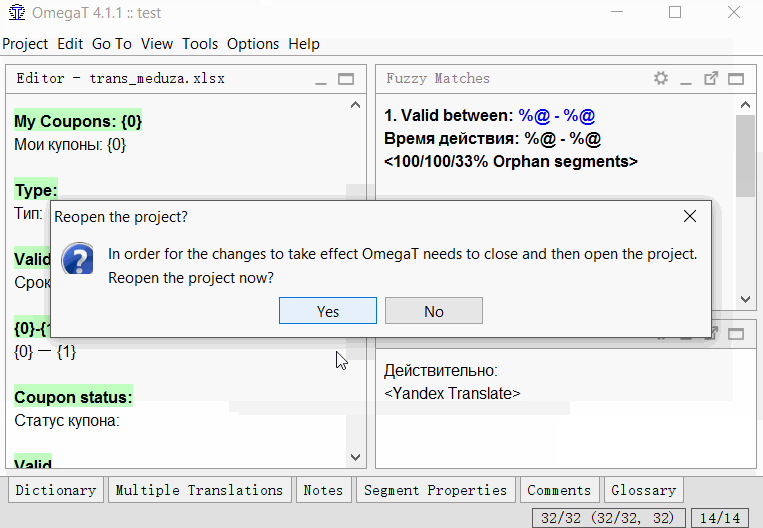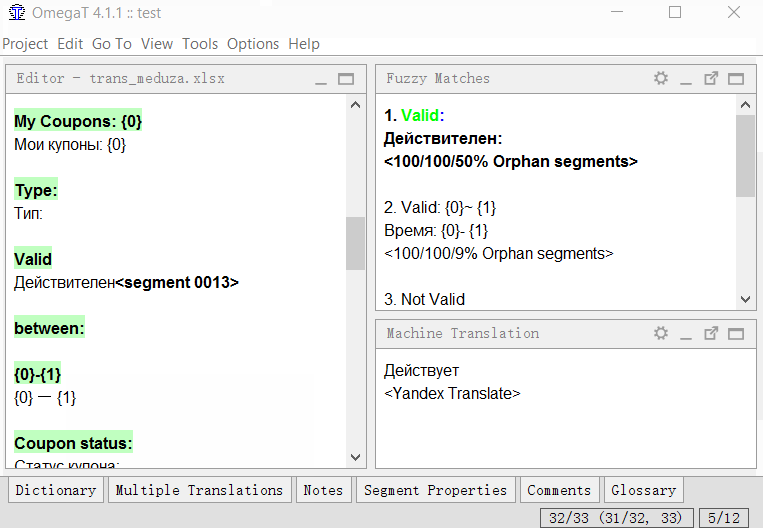
The program will display a warning with the result of the split. You can click OK to split, or cancel the action.
The script creates a new segmentation rule and applies it to the project. The script is very far from ideal, and does not always work, but so far in OmegaT it is the only way to pinpoint segment division / merging.
Instead of conclusion
I combined two notes from my cozy bedlock into one huge sheet about OmegaT. I tried to reveal all its main features, which I use regularly. Be sure to write in the comments why the article is dumb and in which hub it actually has a place.
Professional translators should criticize my English-Russian translation and take part in the survey on normal CAT programs.
PS: Does anyone know why the GT engine does not understand the html links inside the page?
Source: https://habr.com/ru/post/404061/
All Articles