Google’s dedicated ASIC for machine learning is tens of times faster than a GPU

Four years ago, Google realized the real potential of using neural networks in its applications. Then she began to implement them everywhere - in the translation of texts, voice search with speech recognition, etc. But it immediately became clear that the use of neural networks greatly increases the load on Google servers. Roughly speaking, if each person performed a voice search on Android (or dictated text with speech recognition) only three minutes a day, then Google would have to double the number of data centers (!) Just for the neural networks to process this amount of voice traffic.
We had to do something - and Google found a solution. In 2015, it developed its own hardware learning architecture (Tensor Processing Unit, TPU), which is up to 70 times higher than traditional GPUs and CPUs in performance and up to 196 times in number of calculations per watt. The traditional GPU / CPU refers to general-purpose Xeon E5 v3 (Haswell) processors and Nvidia Tesla K80 graphics processors.
The TPU architecture is described for the first time this week in scientific work (pdf) , which will be presented at the 44th International Symposium on Computer Architectures (ISCA), June 26, 2017 in Toronto. The lead author of more than 70 authors of this scientific work, distinguished engineer Norman Juppi (Norman Jouppi), known as one of the creators of the MIPS processor, in an interview with The Next Platform explained in his own words the unique features of the TPU architecture, which in fact is a specialized ASIC, that is integrated circuit special purpose.
')
Unlike conventional FPGAs or highly specialized ASICs, TPU modules are programmed in the same way as a GPU or CPU; this is not a narrow-purpose hardware for a single neural network. Norman Yuppi says that TPU supports CISC instructions for different types of neural networks: convolutional neural networks, LSTM models and large, fully connected models. So it still remains programmable, only using the matrix as a primitive, and not vector or scalar primitives.
Google stresses that while other developers optimize their microchips for convolutional neural networks, such neural networks provide only 5% of the load in Google data centers. The main part of Google applications uses Rumelhart's multi-layer perceptrons , which is why it was so important to create a more universal architecture, not “sharpened” just for convolutional neural networks.

One of the elements of the architecture is the systolic engine of the data stream, a 256 × 256 array, into which activations (weights) from the neurons to the left arrive, and then everything moves step by step, multiplying by the weights in the cell. It turns out that the systolic matrix performs 65,536 calculations per cycle. This architecture is ideal for neural networks.
According to Yuppi, the TPU architecture is more like an FPU co-processor than a regular GPU, although numerous multiplication matrices do not store any programs, they simply execute instructions received from the host.
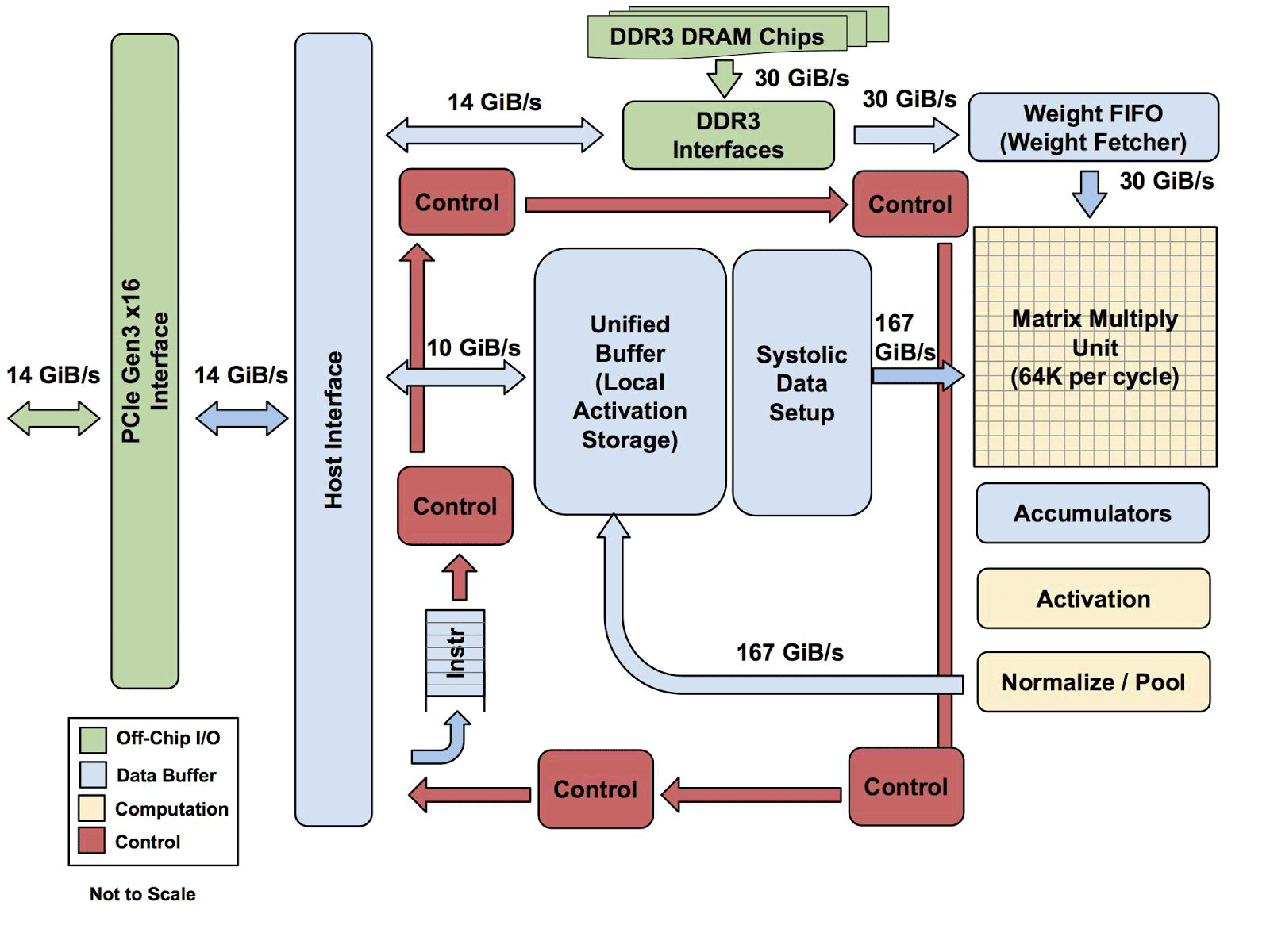
All TPU architecture except DDR3 memory. Instructions are sent from the host (left) to the queue. Then, the control logic, depending on the instruction, can repeatedly run each of them.
It is not yet known how this architecture scales. Yuppi says that in a system with this kind of host there will always be some kind of bottle neck.
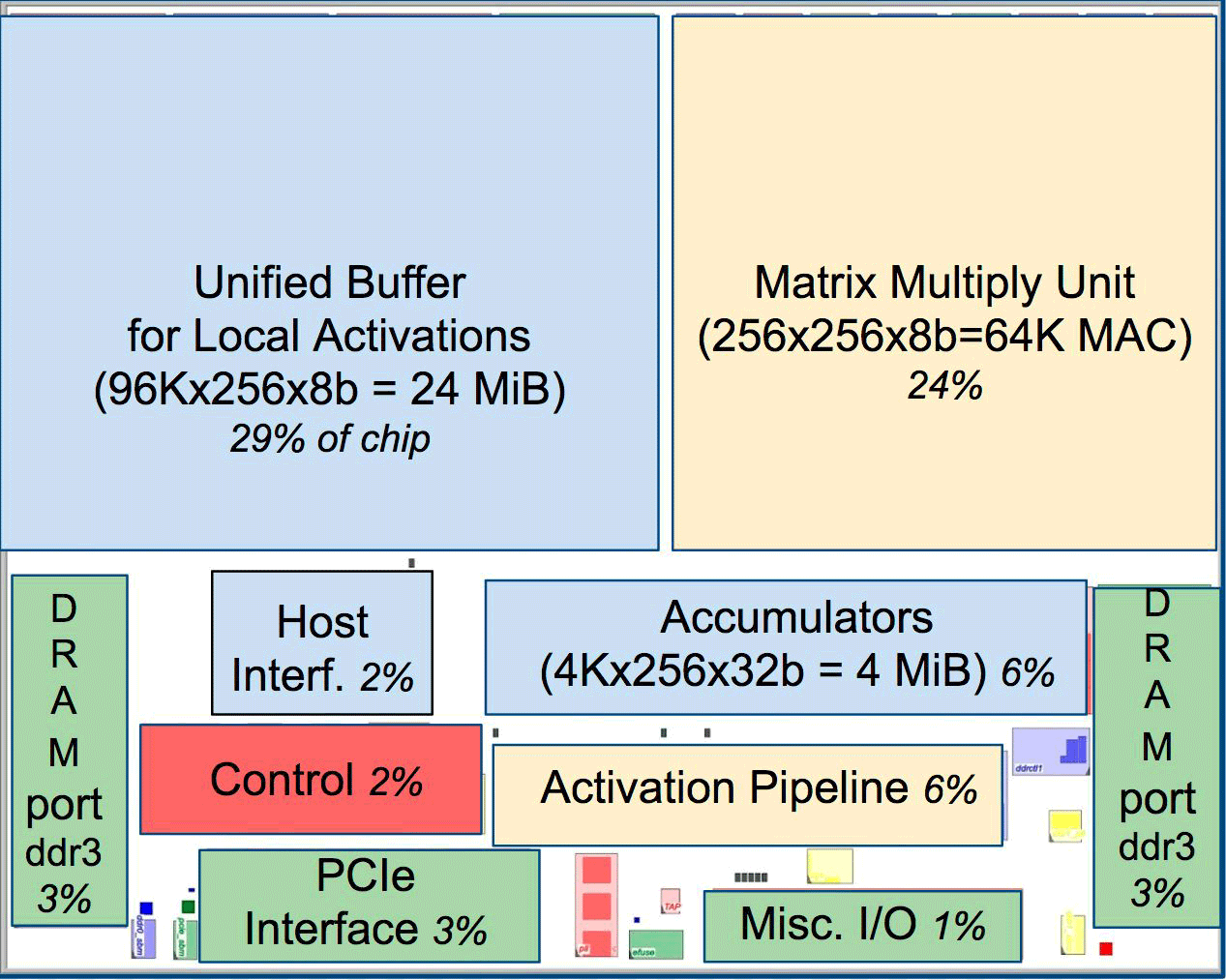
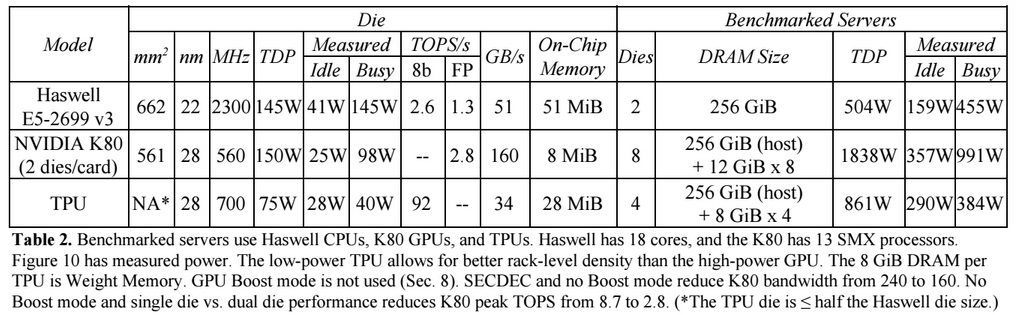
Compared to conventional CPUs and GPUs, Google’s machine architecture is dozens of times more powerful. For example, the Haswell Xeon E5-2699 v3 processor with 18 cores at a clock frequency of 2.3 GHz with 64-bit floating point performs 1.3 tera-operations per second (TOPS) and shows the exchange rate with a memory of 51 GB / s. In this case, the chip itself consumes 145 watts, and the entire system on it with 256 GB of memory - 455 watts.
For comparison, TPU on 8-bit operations with 256 GB of external memory and 32 GB of internal memory shows an exchange rate with memory of 34 GB / s, but the card performs 92 TOPS, that is, approximately 71 times more than the Haswell processor. The server's power consumption on the TPU is 384 watts.
The following graph compares the relative performance per watt of the server with the GPU (blue column), the server on the TPU (red) relative to the server on the CPU. It also compares the relative performance per watt of the server with the TPU in relation to the server on the GPU (orange) and the improved version of the TPU in relation to the server on the CPU (green) and the server on the GPU (purple).

It should be noted that Google conducted comparisons in tests of applications on TensorFlow with the relative old version of Haswell Xeon, while in the newer version of Broadwell Xeon E5 v4 the number of instructions per cycle increased by 5% due to architectural improvements, and in the version of Skylake Xeon E5 v5 which is expected in summer, the number of instructions per cycle may increase by another 9-10%. And with the increase in the number of cores from 18 to 28 in Skylake, the overall performance of Intel processors in Google tests can improve by 80%. But even so, there will be a huge difference in performance with TPU. In the 32-bit floating-point version of the test, the TPU difference with the CPU is reduced to about 3.5 times. But most models are perfectly quantized to 8 bits.
Google thought about how to use GPU, FPGA and ASIC in its data centers since 2006, but it did not find use for them until recently when it introduced machine learning for a number of practical tasks, and the load with billions of requests from users began to grow on these neural networks. Now the company has no choice but to move away from traditional CPUs.
The company does not plan to sell its processors to anyone, but it hopes that the scientific work with the ASIC sample of 2015 will allow others to improve the architecture and create improved versions of ASIC that "raise the bar even higher." Google itself is probably working on a new version of ASIC.
Source: https://habr.com/ru/post/402955/
All Articles