What deep neural networks look like and why they require so much memory

Today the graph is one of the most acceptable ways to describe the models created in the machine learning system. These computational graphs are made up of vertices-neurons connected by synapse edges, which describe the connections between the vertices.
In contrast to a scalar central or vector graphics processor, an IPU — a new type of processor designed for machine learning — allows you to construct such graphs. A computer that is designed to manage graphs is an ideal machine for computational graph models created as part of machine learning.
')
One of the easiest ways to describe the process of machine intelligence is to visualize it. The Graphcore development team has created a collection of such images displayed on an IPU. The basis lay Poplar software, which visualizes the work of artificial intelligence. Researchers from this company also found out why deep networks require so much memory, and what solutions there are.
Poplar includes a graphical compiler that was created from scratch to translate standard operations used in machine learning into highly optimized application code for IPUs. It allows you to put these graphs together on the same principle as POPNN. The library contains a set of different types of vertices for generalized primitives.
Graphs are the paradigm on which all software is based. In Poplar, graphs allow you to define a calculation process, where vertices perform operations, and edges describe the connection between them. For example, if you want to add two numbers together, you can define a vertex with two inputs (numbers that you would like to add), some calculations (the function of adding two numbers) and an output (result).
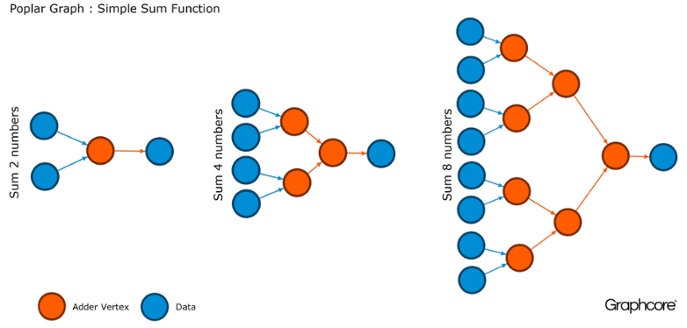
Usually, operations with vertices are much more complicated than in the example described above. Often they are defined by small programs called codelets (code names). Graphical abstraction is attractive because it does not make assumptions about the structure of the computation and breaks the computation into components that the IPU processor can use to work.
Poplar uses this simple abstraction to build very large graphs, which are represented as images. Software graphics generation means that we can adapt it to the specific calculations needed to ensure the most efficient use of IPU resources.
The compiler translates standard operations used in machine learning systems into highly optimized application code for the IPU. The graph compiler creates an intermediate image of the computation graph, which takes place on one or more IPU devices. The compiler can display this computational graph, therefore an application written at the level of the neural network structure displays an image of the computational graph that runs on the IPU.

Graph of the full cycle of training AlexNet in the forward and reverse direction
The Poplar graphics compiler turned AlexNet’s description into a computational graph of 18.7 million vertices and 115.8 million edges. Clearly visible clustering is the result of strong communication between processes in each layer of the network with easier communication between levels.
Another example is a simple, fully connected network that was trained in MNIST , a simple data set for computer vision, a kind of “Hello, world” in machine learning. A simple network to explore this dataset helps you understand the graphs that Poplar applications manage. By integrating graph libraries with environments such as TensorFlow, the company presents one of the easiest ways to use IPU in machine learning applications.
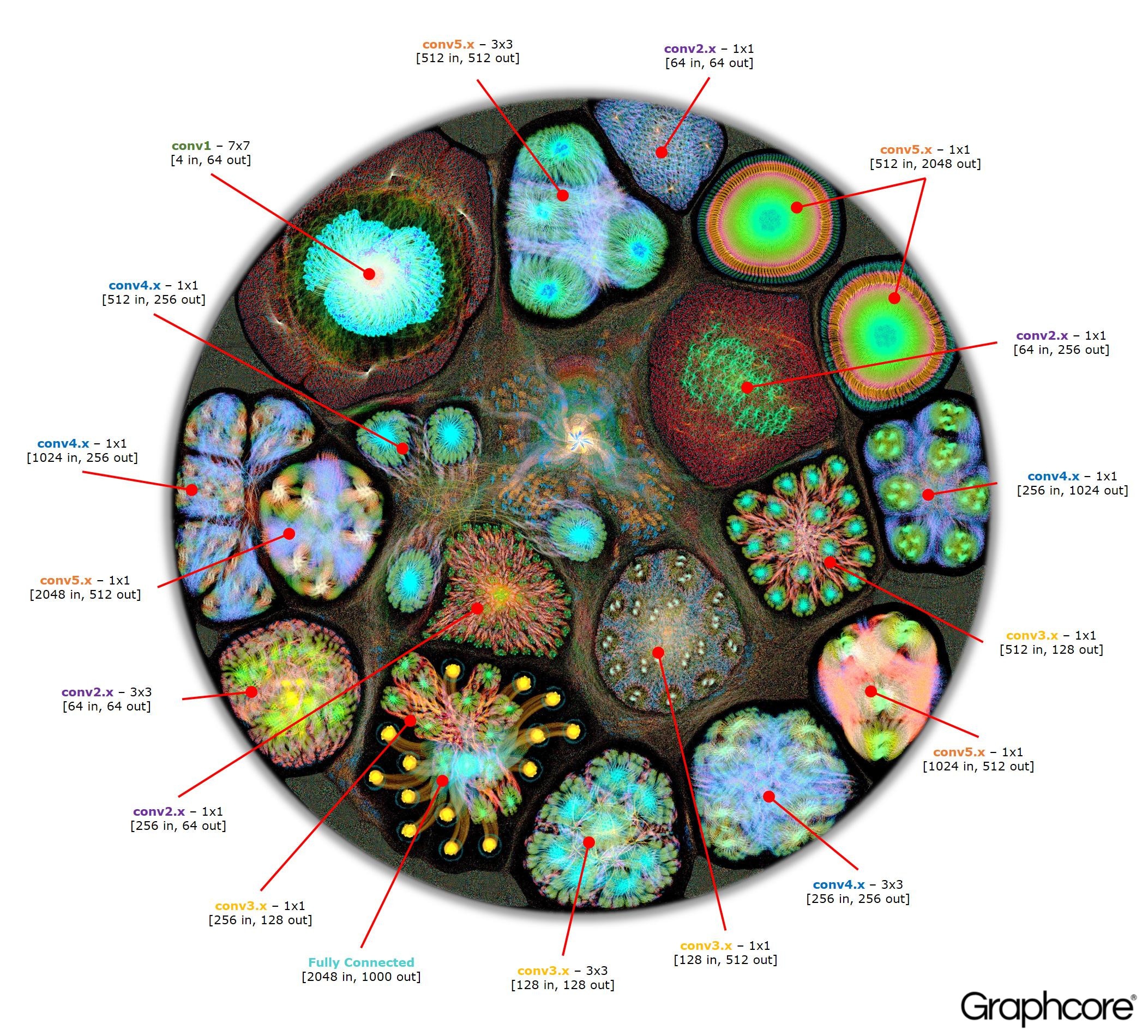
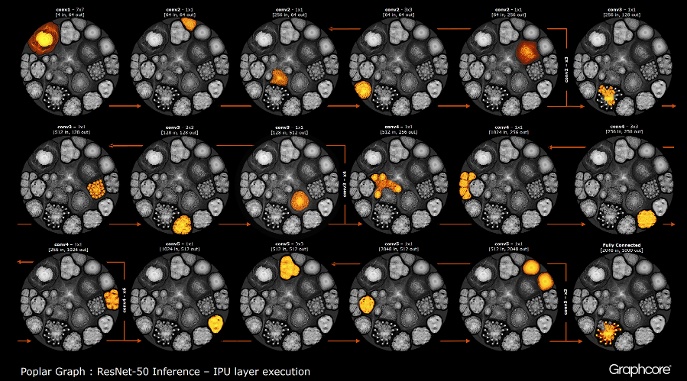
After the graph has been constructed using the compiler, it needs to be executed. This is possible using the Graph Engine. The example of ResNet-50 demonstrates his work.
ResNet-50 graph
The ResNet-50 architecture allows you to create deep networks from repetitive partitions. The processor only needs to once define these partitions and re-invoke them. For example, the conv4 level cluster is executed six times, but only once is applied to the graph. The image also demonstrates the variety of forms of convolutional layers, since each of them has a graph constructed in accordance with the natural form of the calculation.
The engine creates and manages the execution of the machine learning model using the graph created by the compiler. Once deployed, the Graph Engine monitors and responds to IPUs or devices used by applications.
Image ResNet-50 shows the entire model. At this level, it is difficult to isolate connections between individual vertices, so it’s worth looking at enlarged images. Below are a few examples of sections within layers of a neural network.


Why do deep networks need so much memory?
Large amounts of occupied memory is one of the biggest problems of deep neural networks. Researchers are trying to deal with the limited bandwidth capacity of DRAM devices, which should be used by modern systems to store a huge amount of weights and activations in a deep neural network.
The architectures were developed using processor chips designed for sequential processing and optimization of DRAM for high-density memory. The interface between these two devices is a bottleneck that imposes bandwidth limitations and adds significant overhead in power consumption.
Although we still do not have a complete understanding of the human brain and how it works, it is generally understood that there is not a large separate storage of memory. It is believed that the function of long-term and short-term memory in the human brain is built into the structure of neurons + synapses. Even simple organisms like worms with a neural structure of the brain, consisting of just over 300 neurons, have a function of memory to some degree.
Building memory in conventional processors is one of the ways to get around the problem of memory bottlenecks, opening up a huge bandwidth with much less power consumption. However, on-chip memory is an expensive thing that is not designed for really large amounts of memory that are connected to the central and graphics processors currently used to prepare and deploy deep-seated neural networks.
Therefore, it is useful to look at how memory is used today in CPUs and deep learning systems on graphics accelerators, and ask yourself: why do they need such large memory storage devices when the human brain works well without them?
Neural networks need memory in order to store input data, weight parameters and activation functions, as input is distributed through the network. In training, input activation should be maintained until it cannot be used to calculate the output gradient errors.
For example, the 50-layer ResNet network has about 26 million weight parameters and calculates 16 million activations in the forward direction. If you use a 32-bit floating point number to store each weight and activate, then this will take about 168MB of space. Using a lower accuracy value for storing these weights and activations, we could double or even quadruple this storage requirement.
A serious memory problem arises from the fact that GPUs rely on data presented in the form of dense vectors. Therefore, they can use a single command flow (SIMD) to achieve a high computation density. The central processor uses similar vector blocks for high-performance computing.
In GPUs, the synapse width is 1024 bits, so they use 32-bit floating point data, so they often break them up into parallel mini-batch of 32 samples to create data vectors of 1024 bits. This approach to the organization of vector parallelism increases the number of activations by 32 times and the need for local storage with a capacity of more than 2 GB.
Graphic processors and other machines designed for matrix algebra are also subject to memory load from the weights or neural network activations. GPUs cannot efficiently perform small convolutions used in deep neural networks. Therefore, the transformation, called “down”, is used to convert these convolutions into matrix-matrix multiplications (GEMM) that graphics accelerators can efficiently handle.
Additional memory is also required to store input data, temporary values, and program instructions. Measuring memory usage when learning ResNet-50 on a high-performance graphics processor has shown that it requires more than 7.5 GB of local DRAM.
It is possible that someone decides that lower computational accuracy may reduce the required amount of memory, but this is not the case. When you switch data to half-precision for weights and activations, you fill only half the vector width of the SIMD, spending half the available computing resources. To compensate for this, when you switch from full accuracy to half the accuracy on a GPU, then you have to double the mini-batch size to cause sufficient data parallelism to use all the available calculations. Thus, the transition to a lower accuracy of weights and activations on the graphics processor still requires more than 7.5 GB of free-access dynamic memory.
With such a large amount of data that needs to be stored, it is simply impossible to fit all this into the graphics processor. On each layer of the convolutional neural network, it is necessary to preserve the state of external DRAM, load the next layer of the network and then load the data into the system. As a result, the external memory interface already limited by bandwidth by memory latency suffers from the additional burden of constantly reloading the scales, as well as storing and retrieving activation functions. This significantly slows down the learning time and significantly increases energy consumption.
There are several ways to solve this problem. First, operations such as activation functions can be performed “on the ground,” allowing you to overwrite input data directly at the output. Thus, the existing memory can be reused. Secondly, the ability to reuse memory can be obtained by analyzing the dependence of data between operations in the network and the distribution of the same memory for operations that do not use it at this moment.
The second approach is especially effective when the entire neural network can be analyzed at the compilation stage in order to create a fixed allocated memory, since the cost of managing the memory is reduced almost to zero. It turned out that a combination of these methods reduces the memory use of a neural network by two to three times.
The third significant approach was recently discovered by the Baidu Deep Speech team. They applied various memory saving techniques to get a 16-fold reduction in memory consumption by activation functions, which allowed them to train networks with 100 layers. Previously, with the same amount of memory, they could train networks with nine layers.
Combining memory and processing resources in a single device has significant potential for improving the performance and efficiency of convolutional neural networks, as well as other forms of machine learning. You can make a trade-off between memory and computing resources in order to achieve a balance of capabilities and performance in the system.
Neural networks and knowledge models in other methods of machine learning can be viewed as mathematical graphs. In these graphs a huge amount of parallelism is concentrated. A parallel processor designed to use parallelism in graphs does not rely on mini-batch and can significantly reduce the amount of local storage required.
Modern research results have shown that all these methods can significantly improve the performance of neural networks. Modern graphics and CPUs have very limited internal memory, only a few megabytes in total. New processor architectures, specifically designed for machine learning, provide a balance between memory and on-chip computing, providing significant improvements in performance and efficiency compared to modern CPUs and graphics accelerators.
Source: https://habr.com/ru/post/402641/
All Articles