Genetic engineering of bacteria: how it all began and how it works in the laboratory today
 Despite the existence of obvious obstacles and difficulties that sometimes stand in the way of the development and introduction of products of genetic engineering (GI), the XXI century can no longer be imagined without the fruits of this important and diverse technology in the arsenal of a modern biologist. The most commonly used organism in GI are bacteria.
Despite the existence of obvious obstacles and difficulties that sometimes stand in the way of the development and introduction of products of genetic engineering (GI), the XXI century can no longer be imagined without the fruits of this important and diverse technology in the arsenal of a modern biologist. The most commonly used organism in GI are bacteria.What is GI and why do we need it? Why are bacteria so popular with genetic engineers? What is the easiest way to insert the gene into the bacterium? What difficulties can you encounter when working with these organisms? What happened before: the creation of the first genetically engineered bacteria or the discovery of the structure of DNA and the genome? Read about this and many other things under the cut.
0. Brief educational program in biology
This paragraph provides a brief description of the so-called Central dogma of molecular biology . If you have basic knowledge of molecular biology, feel free to skip to step 1.

The central dogma of molecular biology in one picture
')
So, let's begin. All information on all stages of development and properties of any organism, whether prokaryotes (bacteria), archaea or eukaryotes (all other single and multicellular), is encoded in genomic DNA, which is a complex of two polynucleotide chains complementary to each other ( complementary DNA nucleotides: AT and GC). Eukaryotic chromosomes are linear double-stranded DNA molecules, and prokaryotic chromosomes are looped. Often genes make up only a small part of the entire genome (about 1.5% in humans).
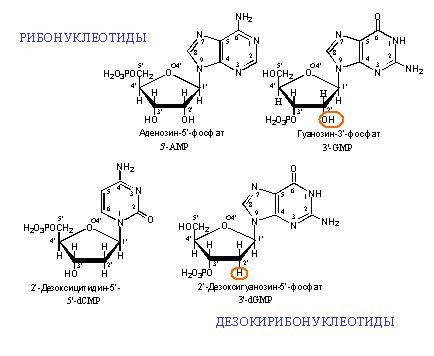
Examples of DNA and RNA monomers. "Deoxy" in the name of DNA means the absence of an oxygen atom in position 2 '(in the figure position 2' is circled in red).
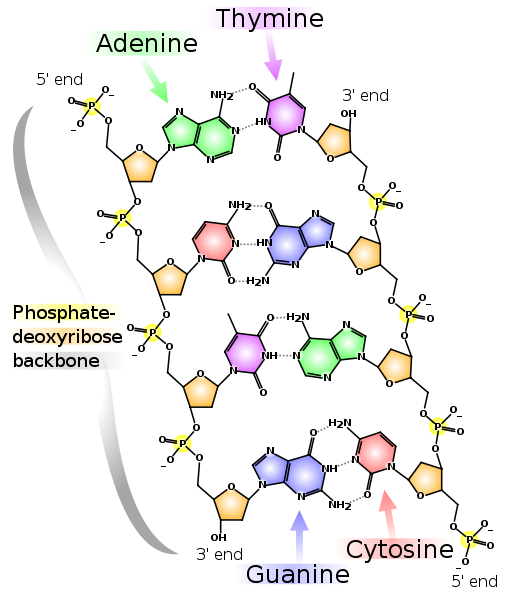
Two complementary strands of DNA. Dotted lines indicate hydrogen bonds between the bases. As can be seen, adenine and thymine form between themselves two hydrogen bonds, and guanine and cytosine - three. Therefore, the GC bond is stronger and the GC-rich regions of double-stranded DNA are more difficult to divide into two chains.
Please note that each of the chains has a 5'-end and 3'-end. It can be seen that about the 5'-end of the left chain is the 3'-end of the right and vice versa, therefore the chains are called "anti-parallel". Also, the 5'- and 3'-end is in RNA. The positions 5 'and 3' are chosen to designate the beginning and the end because it is through them that covalent bonds are formed in the DNA and RNA chains.
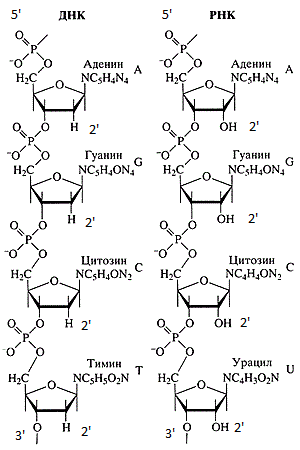
DNA and RNA chains.
DNA and RNA sequences are always recorded from the 5'-end to the 3'-end. There are several reasons for this:
- The synthesis of new DNA and RNA chains starts from the 5'-end ( DNA polymerases (enzymes that synthesize the complementary DNA strand on a DNA or RNA template) and RNA polymerases (enzymes that synthesize a complementary RNA strand on the DNA or RNA template) go through the template in direction 3 '-> 5', therefore, the new chain is synthesized in the direction 5 '-> 3');
- The ribosome reads codons, moving along the mRNA in the direction of 5 '-> 3';
- The amino acid sequence is written in the coding chain of DNA in the direction of 5 '-> 3' (a significant part of the mRNA is an exact copy of the region of the coding DNA chain with the replacement of thymine by uracil and with a hydroxyl group (-OH) instead of hydrogen in position 2 ', of course);
- Finally, it’s just convenient to have a generally accepted write rule.
A gene is a region of genomic DNA that defines the sequence of nucleotides of an RNA molecule:
- Encoding RNA: messenger RNA (mRNA), in which the amino acid sequences of the corresponding protein are encoded as codons. You can also find the name "informational RNA", then the abbreviation looks like "mRNA";
- Non-coding RNA: transport RNA, ribosomal RNA, and others.
The role of tRNA is to deliver an amino acid mRNA-ribosome to the complex. In addition, it is tRNA that is responsible for the recognition of mRNA codons; for this, each tRNA contains a so-called “anticodon” - a triplet complementary to the mRNA codon.
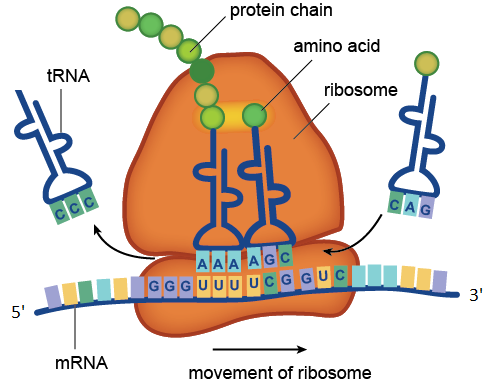
The process of translation, catalyzed by the ribosome. In the figure, the codons UUU and UCG contained in the mRNA are recognized by the AAA and AGC anticodons contained in the tRNA molecules. Transport RNA with the CCC anticodon has already given its amino acid to the growing protein chain, and tRNA with the CAG anticodon is waiting for its turn. The section of an mRNA molecule shown in the figure consists of four codons: GGGUUUUCGGUC. The codon GGG corresponds to the amino acid glycine, UUU to phenylalanine, UCG to serine, GUC to valine. So this region of mRNA encodes a fragment of a protein with the amino acid sequence glycine-phenylalanine-serine-valine.
Ribosomal RNAs are indispensable components of the ribosome. The main function of rRNA is to provide the translation process: it participates in reading information from mRNA using tRNA adapter molecules and catalyzing the formation of peptide bonds between the amino acids attached to tRNA and the growing protein chain.
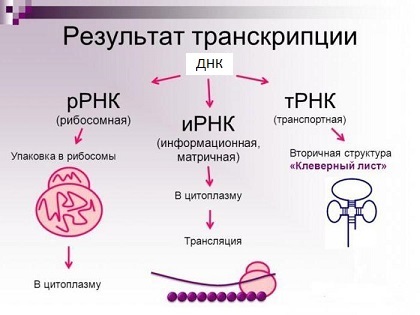
The main types of RNA molecules (in fact, they are much larger).
The protein is a chain of amino acids covalently linked to each other through a peptide bond (the fact that it is this can be seen in the spoiler a little further). After synthesis, a chain of amino acids must adopt a certain spatial structure - the " conformation " (about the spatial structure of proteins on Geektimes already told before me ). In addition, many large proteins actually consist of several proteins combined by hydrophobic interactions and hydrogen bonds into a single stable structure. In this case, each of the “building proteins” is called a “subunit”, and the resulting large protein is called a “multi-subunit”.
20 amino acids that make up proteins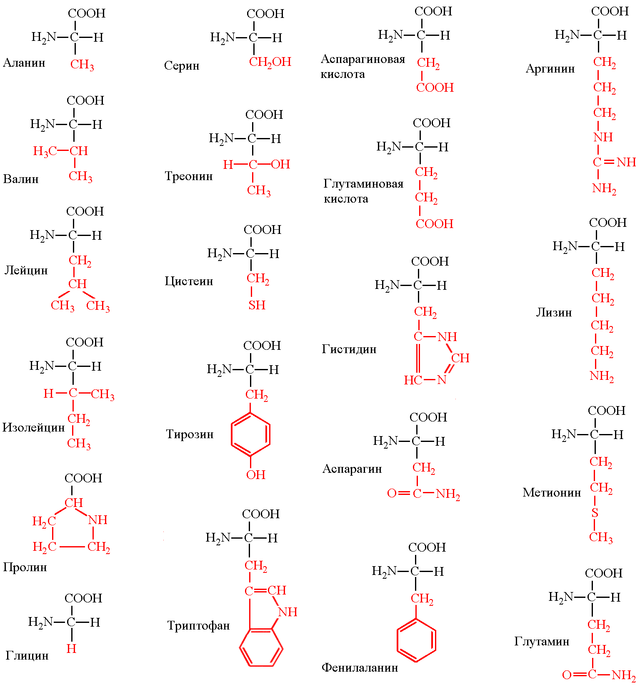
Peptide bond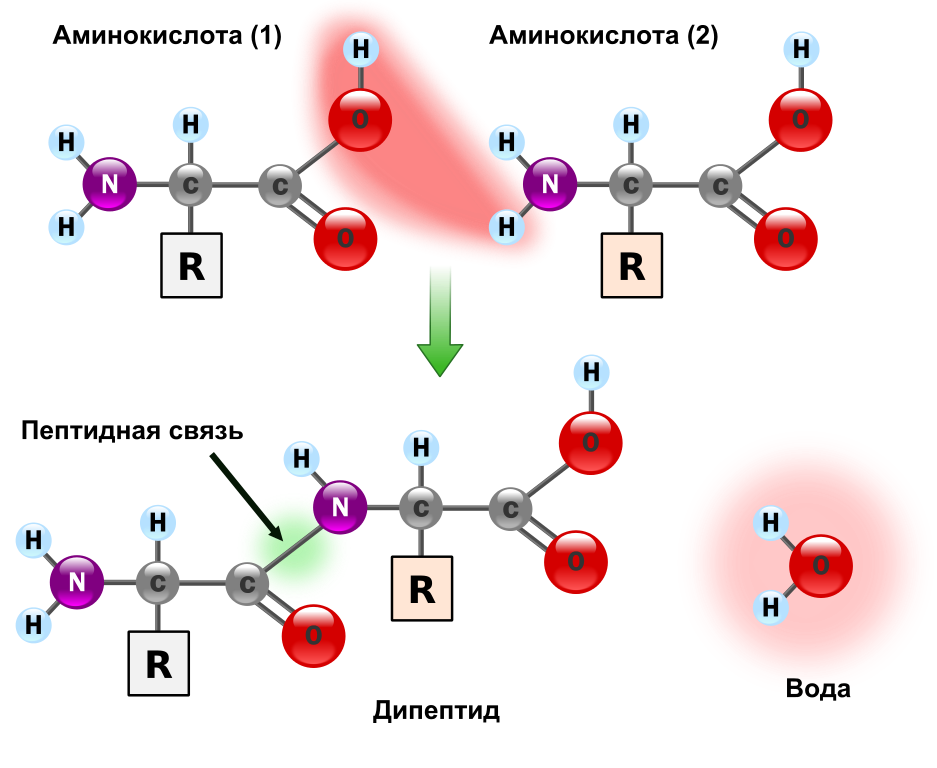

Ribosome complex. The picture is taken from the OlegKovalevskiy publication “3D printing of protein molecule models” .
In the case of genes encoding a protein, the process of decoding genetic information looks like this:
- RNA polymerase recognizes the promoter and binds to it (if it is “open,” we will go further on the regulation of promoter activity);
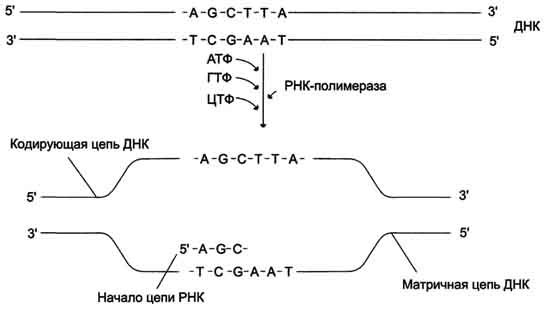
- On the DNA template, the enzyme RNA polymerase synthesizes according to the principle of complementarity and synthesizes a “preform” of messenger RNA (pre-mRNA, in eukaryotes) or ready-made functional mRNA (in prokaryotes). This process is called “transcription” ;
- (only in eukaryotes) The pre-mRNA molecule undergoes modifications ("ripens") and becomes functional mRNA;
- mRNA is recognized by the ribosome , an enzyme that decodes the triplet code of mRNA and synthesizes peptide / protein based on it. The amino acids from which the ribosome builds a protein are delivered in combination with transport RNA ( tRNA ). This process is called “translation” ;
- The peptide / protein can undergo posttranslational modifications (“maturation” by analogy with mRNA) and become functional. An important factor is that the system of posttranslational modification of eukaryotes is much more complicated and diverse than in prokaryotes, therefore not every eukaryotic protein can be correctly synthesized by bacteria.
In addition to the coding regions in the genome, there are numerous fragments that are also somehow involved in transcription. The sites located close to the gene and called promoters are recognized by RNA polymerases (they say that the gene is under the control of this promoter). Different promoters are recognized by different RNA polymerases. For example, a gene under the control of a bacteriophage promoter will not be transcribed into bacteria unless RNA polymerase of the corresponding bacteriophage is synthesized in it. Generally .
Also, each gene can have several regulatory sequences, which can be located either directly near the promoter (or even overlap with it), or at a distance of tens of thousands of base pairs from it. Elements that enhance transcription are called “enhancers” , suppressing transcription are called “silencers”, and the proteins interacting with them are called “transcription factors” . Although it is also accepted to call transcription factors necessary components of the transcription initiation complex, without which transcription is impossible in principle. The fact is that only to start the synthesis of an RNA molecule on the DNA template in eukaryotes and archaea, an assembly of the whole supramolecular complex is necessary. The simplest such complex includes a holoenzyme RNA polymerase and six so-called “common transcription factors” (TFIIA, TFIIB, TFIID, TFIIE, TFIIF, and TFIIH). The complex itself is called the “Transcription preinitiation complex” ( video , each component of the complex is highlighted in one color or another).
The prokaryotic transcriptional complex is completely different, so there is no point in inserting a eukaryotic gene into a bacterium together with a eukaryotic promoter. A prokaryotic analogue of common transcription factors of eukaryotes and archaea can be called a protein, called the “sigma factor” .

Prokaryotic transcriptive complex. The letters indicated in the figure are the generally accepted designations of the corresponding subunits. σ70 - sigma factor genes household E. coli
The genomes of prokaryotes and eukaryotes have many similarities, and the previously mentioned Central Dogma of Molecular Biology is fair for both kingdoms. However, there are also many significant differences. For example, for bacteria, a system of operons is typical - genes grouped together that participate in the same process and are not transcribed individually, but as part of one long mRNA. In eukaryotes, everything is completely different: the genes involved in the same process are scattered across different chromosomes, and the genes themselves are divided into coding fragments "exons" by non-coding regions "introns" . In this case, first, the gene is transcribed completely, and then, at the RNA stage, the introns are cut out, and the exons are stitched to form the coding mRNA. This process is called "splicing . " At the same time, not all of the available exons can be inserted into the finished mRNA, but only some of them, in this case they speak of “alternative splicing” . Thus, a eukaryotic cell can synthesize several proteins, transcribing one and the same gene. Among other things, this gives a very important consequence: inserting the eukaryote gene into the bacterium “as it is in the chromosome” often does not make sense, since the bacterium is simply not able to produce splicing.
There is another important difference. For prokaryotes, the presence of DNA-genetic material outside the circular "chromosome", the so-called "plasmid" - small circular double-stranded DNA molecules is characteristic. In addition, prokaryotes do not have organoids, including the nucleus: all components of the bacterial cell are free to travel throughout the entire intracellular space. In eukaryotes, there are no plasmids, but there are plastids and mitochondria , whose genome includes plasmids (according to the most reasonable hypothesis, plastids and mitochondria are “descendants” of the prokaryotic architecture of the genome of cyanobacteria and bacteria captured by ancient single-cell proto-eukaryotes inside). In addition, for eukaryotes, the presence of the nucleus and other intracellular compartments surrounded by its own membrane is typical. Therefore, genetic engineering of a eukaryotic cell requires different approaches than genetic engineering of bacteria.
The genetic code itself is organized as follows. Each gene / exon consists of a set of triplets / codons - sequences of three nucleotides, between which there are no gaps. Triplet organization is valid for both genes in the composition of DNA, and for the coding part of mRNA. In the process of translation, transport RNA (tRNA) carrying a certain amino acid will “recognize” the corresponding three-letter triplets. The ribosome detaches the amino acid from tRNA and attaches it to the growing amino acid chain, which, at the end of the broadcast, will either immediately become a mature, full-featured protein, or before that it will additionally undergo a number of modifications. In this case, only one amino acid corresponds to each triplet, but several different codons can correspond to one amino acid. This is understandable, because the standard genetic code has 61 coding codons, and only 20 proteinogenic amino acids (of all codons, of course, 4 * 4 * 4 = 64, but three of them are non-coding, instead they serve as a signal to stop translation and are called " stop codons ").

Codons in the standard genetic code. Thank you for wikipedia picture.
So proteins - these are the very elements that are the last link in the chain between genomic DNA and the properties of the organism, the so-called “phenotype” . Therefore, in order to somehow change the characteristic we need for an organism important to us, we need to change its DNA in such a way so that certain proteins appear in its cells, which will provide us with a target result. This is the main idea of all genetic engineering.
1) For what purposes are bacteria used in genetic engineering and why they
So, we figured out how and why the sequence of genomic DNA affects the properties and characteristics of the organism. Of course, it will be very good if the trait is completely determined by just one gene - the insertion of a small fragment is no longer a serious problem. For example, often the resistance of a plant to a herbicide or pest is determined by a single gene, therefore creating varieties with the desired resistance in such cases is not difficult (as opposed to bringing such a plant to the market). The same is true for many bacterial resistances to antibiotics (in fact, bacteria have many defense mechanisms against antibiotics, but they work in an independent manner). The opposite example is, for example, the attempt of scientists to teach plants to assimilate nitrogen from the atmosphere. The fact is that the only source of nitrogen for plants is soil, in which nitrogen-containing compounds suitable for plant absorption are synthesized by microorganisms (either introduced as fertilizer by a careful gardener or a passing dog). Obviously, the creation of plants with an alternative mechanism of nutrition would be very useful for agriculture. But, unfortunately, this process is so complicated that the problem of its “transfer” from the microorganism to the plant could not be solved until now.
Finally, if our goal is to obtain a protein for some specific purposes (the study of the structure and functions of the protein, the creation of medical drugs or laboratory reagents based on it, etc.), then we are obviously also quite happy with the insertion of a single gene into the cell, which in this case, it is customary to call the “organism-producer”.
Genetic engineering bacterium is a potential source material for creating:
- producer of the protein we need on a laboratory or industrial scale;
- an active agent in some kind of chemical transformation of one compound into another, be it a fermentation process in the food industry, the creation of more favorable conditions for plant growth due to the introduction of a “bacterial fertilizer manufacturer” into the soil or the utilization of steel scrap;
- clone libraries of genes (a topic whose good description will increase the size of the article to indecent);
- medically significant drug, for example, to restore the microflora of the gastrointestinal tract;
- Agrobacterium tumefaciens bacteria strains for subsequent genetic modification of plants.
* could forget something, so additions in the comments are welcome.
An interesting fact is that the first successful experiments in the field of genetic engineering of bacteria occurred long before the epochal work of Watson and Crick. Moreover, on the basis of these experiments, the very fact that the information is contained in DNA was proved, after which scientists could not waste their time on hypotheses about RNA and protein.
This work, carried out in 1944, is known as the Experiment of Avery, MacLeod and McCarthy , the basis for which was the work of Frederick Griffith , in the course of which it was found that infection with killed pathogenic and live non-pathogenic pneumococcal strains causes the development of the disease, while separately, they do not cause significant symptoms. From this experiment it was concluded that the killed bacteria are capable of transmitting something to a non-pathogenic "colleague", as a result of which it becomes dangerous. But what do they pass on to each other? By 1944, there were three main candidates: DNA, RNA, and protein. In order to establish a carrier, an elegant experiment was carried out: at that time, enzymes were available that could destroy DNA separately (DNase), separate RNA (RNAse) and proteins (proteinase) separately. It was shown that the transfer of pathogenic properties did not occur only in those cases when the preparation of a dead pathogenic strain was treated with DNAse and was not dependent on the treatment of the preparation with RNase and proteinase.
Thus, it was proved that the carrier of information about the trait is DNA. In addition, it was clearly shown that spontaneous penetration of a foreign DNA molecule into a bacterial cell is possible.
Why are bacteria so popular with obvious flaws (for example, the absence of eukaryotic post-translational modifications)? It's simple. They are unpretentious in work, easy to use and do not require expensive nutrient media.
2) How to create a genetic construct that is introduced into the bacterium
Modern genetic engineering of bacteria is mainly the introduction of a plasmid vector (modified bacterial plasmid containing the target gene and a set of other necessary elements, which are discussed below). The change in the chromosome of the bacterium is less typical, but this procedure is also not something outlandish: for example, the bacteriophage T7 RNA polymerase gene was introduced into the chromosome of E. coli using a vector based on the prophage λ in the process of creating one of the most popular strains in the laboratory. There are three reasons why a researcher will often choose to insert a gene into a plasmid vector:
- first, it is cheaper to insert a plasmid vector into a bacterium than to embed something into the chromosome;
- secondly, the methodology for ensuring the stability and inheritance of a plasmid vector in a bacterial cell, as well as the procedure for creating the desired genetic structure is well developed and simple to implement;
- thirdly, everything works fine with plasmid vectors.
A typical plasmid vector for working with bacteria is a small circular double-stranded DNA molecule carrying the target protein gene under the control of a specific promoter and a number of necessary genes and regulatory elements, the presence of which provides a constant amount of plasmid in the cell (“copy number control”). Obviously, even in the case of ultra-efficient synthesis of mRNA from a vector, there is little sense if it exists in the bacteria in the number of pairs: during the division process, the probability of forming a daughter cell without the desired plasmid is high.
In addition to the gene and promoter, the main elements of the plasmid vector are:
- ori - plasmid replication start region. Need to maintain a constant amount of the plasmid and its inheritance by daughter cells;
- marker gene - a gene that gives bacteria carrying a plasmid vector a certain property that allows them to be distinguished from unmodified bacteria. Most often, antibiotic resistance is used as a marker, then the transformed cell is able to live and divide into a medium containing an antibiotic (“selective medium”). In addition, the presence of an antibiotic in a nutrient medium helps to protect the cell culture from infection by unwanted organisms that may accidentally enter the nutrient medium. Often, there is one resistance gene in the work, but it is quite typical to use two resistance genes at once.
Another example is the use of the β-glucuronidase gene (GUS). This enzyme turns certain compounds into colored or fluorescent, which can be detected visually by colony coloration. Naturally, these compounds need to be added to a selective nutrient medium. Another example is the use of the green fluorescent protein (GFP) gene (although the use of GUS and GFP is more typical for working with plant and animal cells); - the site responsible for the copy number control (there are few plasmids in the cell - it’s bad, a lot - it’s too bad);
- polylinker is a nucleotide sequence containing several unique overlapping restriction endonuclease recognition sites (cutting double-stranded DNA at a specific location). The polylinker is needed in order to embed the target gene in an “empty” vector.
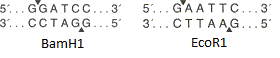
The figure shows the restriction sites of the endonuclease BamH1 and EcoR1 . Both enzymes recognize a certain portion of six base pairs and introduce single-stranded breaks in different places (in the figure they are indicated by arrow-triangles). , « » ( , « »).
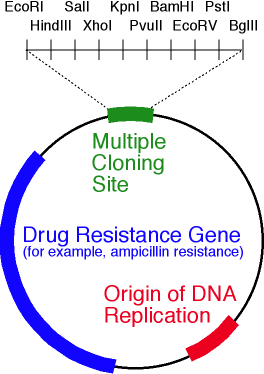
. ori, , 10 .
, . ? , ?
, . :
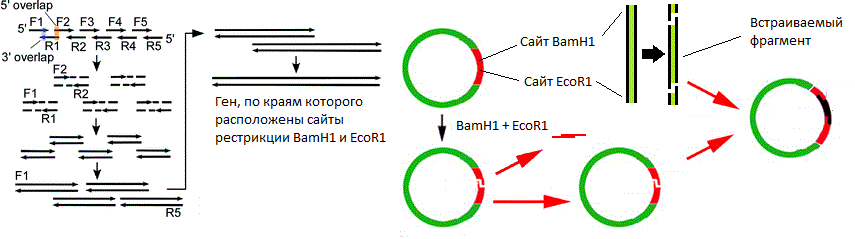
( ). .
F1 R1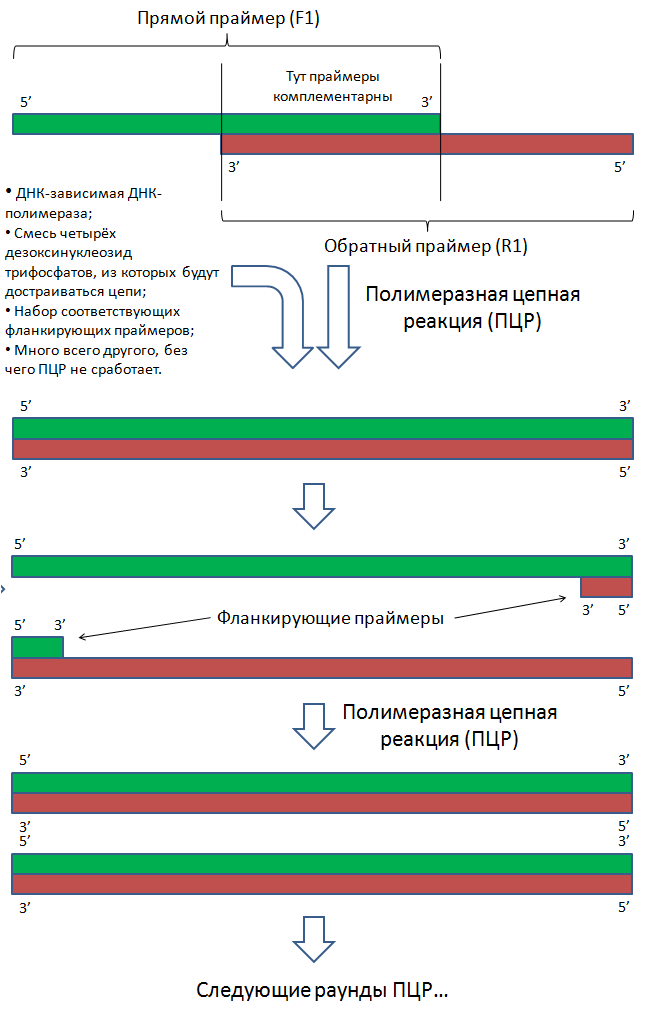
, , , . , ( BamH1 EcoR1 ) , , « » . , . , - , .
, , , «» . , , . , , «» .
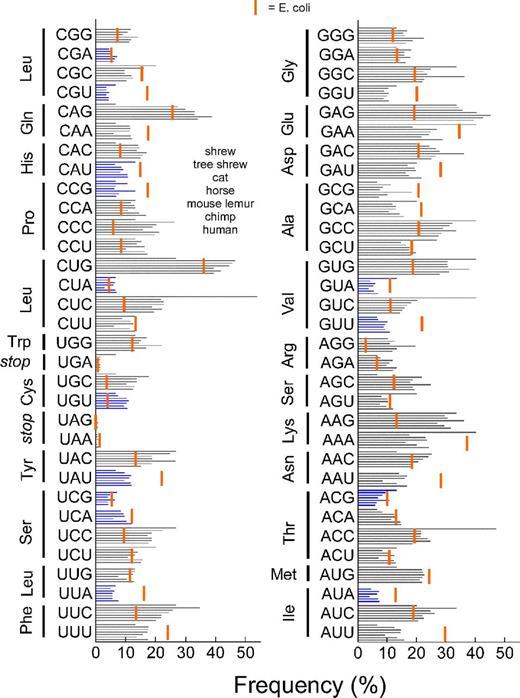
, , , , , . E. coli .
. , . , . «» , : , . , , . (, ) , . , .
. . , ( 10% ), - ! . , «» « ». :
- E. coli ( lac -) .
, . -, lac -, , . : , ? .
, lac -. , , lac -. , lac - , . , . . — . , 7.
, , , .
, E. coli -, , - .
E. coli - 7 -, lac -. , « 7 + lac -», .
. , . , , . «».
-: , , , , , . . - pL λ .
- cI. , cI857: 30⁰ 42⁰. 30⁰, 42⁰, .
, . — . But that's another story.
Source: https://habr.com/ru/post/402025/
All Articles