NVidia GPU stress test on live streaming transcoding
Below is a detailed story about how we loaded the NVidia card with video transcoding tasks for streaming it. We show that we tried what we got, and how best to use video cards for streaming online.
 For several years, our team has been developing products for processing and distributing media content online. This article has been written not so long ago, why content owners may need such solutions in this age of YouTube.
For several years, our team has been developing products for processing and distributing media content online. This article has been written not so long ago, why content owners may need such solutions in this age of YouTube.
One of our products is the Nimble Streamer media server, a server software that takes live streams and files as input and makes them accessible to a large number of viewers, allowing you to monetize content along the way. This is a native application written in C ++ and ported to all popular operating systems (Linux, Windows, MacOS) and platforms (x64, ARM). From the very beginning, low resource intensity and high productivity were the main requirements, and we manage to achieve good performance in this.
Last year, we released the Nimble Streamer add-on, a live stream transcoder . This application allows you to take a stream of video and / or audio in different formats as input and do various transformations with them in real time. The functionality includes decoding (both software and hardware), video and audio conversion using filters (resizing, overlay, etc.) and encoding (encoding) - both software and hardware.
')
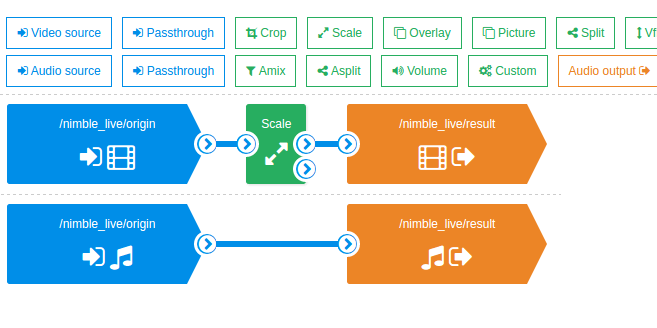
The transcoder is controlled via the WMSPanel web service, transcoding scripts are created via the drag-n-drop interface, which allows you to see the process visually. Different scenarios can be run together - with this approach, it is convenient to run test combinations, loading the server in any variations.
In these videos you can see examples of the interface.
Decoding each stream is done only once before all further conversions ... This saves resources on the expensive operation of decoding, it will be clearly seen further in the course of the tests.
One of the transformation mechanisms that can be used in our transcoder is hardware decoding and video encoding using a NVidia GPU. Graphic cards of the latest generations allow us to take on some of the typical tasks, which relieves the load from the CPU. Our transcoder is able to work with this hardware, which is actively used by our customers.

In the course of communication with representatives of the Russian office of NVidia, we were offered to try to arrange joint stress testing of our transcoder and NVidia GPU in order to understand what the economic effect of such a tandem will be compared to exclusively software transcoding, without hardware acceleration. In addition, I wanted to understand how best to use the GPU, and, if possible, give good recipes.
We needed to quickly obtain the appropriate iron and access to it, for the cycle of our experiments. We planned to meet a couple of weeks. It remains to find where to get the equipment. The best option would be to find them in the cloud and get remote access. Looking for options, it turned out that AWS does not have a VM with a Maxwell generation GPU, and in the Azure cloud it is only planned to start providing them in a short time.
With the help of NVidia, IBM has provided us with access to its cloud - the IBM Bluemix Cloud Platform (formerly Softlayer ). This is a large network of modern data centers (about 50 at the time of publication) around the world connected by a common private network and providing a large selection of cloud infrastructure services. All data centers are unified and allow renting from one to hundreds of virtual or physical servers of the required configurations for several hours, as well as balancers, storage systems, firewalls - in general, everything that is required to build a reliable IT infrastructure for the IT service being deployed.
The Russian representative office of IBM provided us with full access to the self-service portal for managing cloud services and the required server configuration, where we were able to work with different input streams and settings of our transcoder.
First, we were provided with a physical server (bare-metal) with 128 GB of RAM and 2xGPU NVidia Tesla M60 and the pre-installed OS Ubuntu 14.04. All server parameters, passwords, firmware versions, its switching, dedicated IPs, the state of the hardware components, were visible right in the personal account, allowing you to perform the required manipulations with the leased hardware, which minimized the need to interact with IBM support services. During the test run, it turned out that we could not optimally load such a configuration, due to a number of limitations in the generation of contexts.
We wanted to reduce the configuration. Since we used the cloud platform, it was necessary to request changes in the configuration through the self-service portal. After approval, this operation took about 2 hours to the approved maintenance window. During this time, the technical staff in the data center in Amsterdam, removed the extra components (RAM and 1xGPU strips) from the server provided to us earlier and returned it to the system. It should be noted that for developers this option is very convenient, since there is no need to either deal with the hardware settings, repair it, or even spend time installing the OS. Let me remind you, in this case, the hypervisor is not used because we need to squeeze the maximum out of hardware resources.
According to the results of our research, we stopped at the following server configuration:
We have 2 processors for 12 cores, and thanks to Hyper threading we get twice as much, i.e. virtually 48 cores.
In scenarios with a graphics accelerator, a card based on the GM204 - Tesla M60 chip was used:
I draw your attention to the fact that no affinity, chip tuning, overclocking, and other magic were done on the above hardware - only the overclocked CPU and GPU, and only the official driver from the NVidia site was used for the GPU. If someone has a similar experience - share in the comments.
So we got access. A quick familiarization with the web interface of the control panel (everything is simple and clear), then access to the server via SSH - and here we are in the usual command line of Ubuntu, we install Nimble Streamer, register a new transcoder license and make a small config setting.
Nimble Streamer was configured to pre-create a cache of GPU contexts. This is due to the fact that the GPU has a limit on the maximum number of created decoding and encoding contexts, and in addition, the creation of contexts on the fly can take too much time.
For more on the problem of creating contexts, see the appropriate section below.
Nimble settings on the example of the first series of tests:
More details about these settings are written in our article .
Before starting each series of tests, the cache was configured separately, taking into account the specifics of each task.
Further work went on in our WMSPanel service, where the transcoder scripting is set up.
As already mentioned, the work goes through the web interface, everything is very clear and convenient. We have created a number of scenarios combining different transcoding options (CPU / GPU), different resolution options and different encoding parameters (CPU / GPU, profile, bitrate, etc.)
The sets of scripts can be run simultaneously, which makes it possible to introduce different combinations of tests into circulation, increase the load in a different order and change it depending on the situation. Simply select the necessary scenarios and stop or resume them.
Here is a set of scripts:

Here is an example of one of the scenarios:

A decoder with a GPU looks like this:

Overlay image size filter:

But the encoder for the version with the GPU:

In general, the operation of the transcoder interface can be viewed on these videos .
To begin with, we tried the scenario with the largest loads in order to find out the limits of the possibilities of iron. At the moment, the most “difficult” resolution used in practice is FullHD 1080p.
To generate the original live streams, a file was taken in FullHD (1920 * 1080) in high profile H.264 . The content itself is a video tour of the city, i.e. This is a video with an average intensity of image change. There are no static monochrome frames that could facilitate the work of the transcoder, but there is no too fast change of types and colors. In a word - quite typical load.
At the entrance to Nimble Streamer, 36 identical streams were submitted, which were then used in the transcoder in different scenarios.
The transcoding scenario is typical - the incoming stream is 1080p high profile, 720p, 480p, 360p main profile are made from it , and then the baseline profile flows : 240p, 160p . So, at the entrance there is 1 stream, at the exit 5. Usually, the source stream is also made pass-through, so that the viewer can choose 1080p itself when viewing. We did not add it to the script, because it does not use transcoding - there is a direct transfer of data from the input to the output. This scenario is optimized in Nimble and in real conditions it will relatively slightly increase memory consumption.
Audio in generated streams is not. Adding audio to the script will not give significant load on the CPU, but for the purity of the experiment, we have excluded sound.
To begin with, we launched transcoding scripts without using a GPU, specifying software decoder and encoder in the scripts.
As a result, we managed to process only 16 input streams with issuing 80 streams of all exit permissions.
CPU load - 4600%, i.e. 46 cores were involved. RAM consumption is about 15GB.
The context cache at startup is configured as 0: 30: 15,1: 30: 15 - i.e. 30 contexts for encoding, 15 for decoding, for each GPU.
Let me remind you that we have two cores on the GPU, which allows us to parallelize tasks - this will be useful to us.
The maximum load was obtained with the following configuration of threads.
At the input of the decoder GPU0 and GPU1 - 15 streams. Thus, we get 30 decoded streams ready for further use. Each stream is decoded only once, no matter how many scenarios it is subsequently used.
Encoders GPU0 and GPU1 were fed by 15 streams to get 720p, i.e. It turned out 30 720p streams to the output.
Also on the GPU0 and GPU1 encoders, 15 streams for 480p were given - and it also turned out 30 480p streams per output.
Since the encoder contexts were exhausted, the remaining resolutions were encoded on the CPU. It turned out the following:
The load turned out to be 2600% CPU, 75% decoder, 32% encoder. Then, the CPU was loaded with 6 streams for decoding, for each of them 5 similar permissions were set, for a total of 30 streams per output.
In total, 36 streams were received at the input, 180 streams were output at the output . The final load is fixed as follows: 4400% CPU, 75% card decoder, 32% card encoder, 30GB RAM .
We decided to check the option in which we process the most difficult tasks on the GPU - decoding 1080 and encoding 720 and 480, and letting the rest be processed through the CPU.
First checked the limit of the decoder. With 22 streams on decoding, the problem with contexts affected, they simply could not be created. Reduced to 21 - the contexts were created, but the load became 100% and artifacts began to be observed in the stream. We stopped at 20 streams - we do decoding of 20 streams, encoding at 160p - everything works fine.
In addition, by experience it turned out that this card with 16GB of RAM on board can confidently work with 47 contexts - and there is no difference, these are the contexts of the encoder or decoder. I repeat - this is exactly this GPU Tesla M60, on other cards this number may be different. We believe that if the card had 24GB of RAM, the number of contexts could have been different, but this needs to be tested.
As a result, we chose the cache creation formula “15 decoder contexts and 30 encoder contexts” - which gives 30 input streams and for each allows us to create 2 resolutions. So, the top resolutions - 720 and 480 were coded onto the GPU, and the rest - 360, 240 and 160 - were sent to the CPU. And since the CPU was still free after that, we “finished off” the free cores with new threads, leaving 4 cores for utilitarian tasks.
Scenario with typical load, because most of the content is now created in HD. Even the recent SuperBowl LI - the highest rated show on the American market - was broadcast in HD , leaving FullHD for the future.
To generate the original streams, a file was taken in HD (1280 * 720) in a high profile . Content is our engineer’s favorite “The Good Wife” series, i.e. This is a video with an average intensity of image change.
At the entrance to Nimble Streamer filed 70 identical streams, which were then used in the transcoder in different scenarios.
The following transcoding scenario is used - the incoming stream is 720p high profile, 480p, 360p main profile and further 240p, 160p baseline profile streams are made from it. Total, at the input 1 stream, at the output 4. Pass-through of the original stream, as in the previous scenario, was not executed. Audio in the generated streams is not there either.
As in the previous section, we tried to transcode streams only on the CPU. As a result, it turned out to process only 22 input streams with issuing 88 streams of all exit permissions. CPU load - 4700%, i.e. 47 cores were involved. RAM consumption is about 20GB.
The context cache at startup is configured as 0: 23: 23,1: 23: 23 - i.e. 23 encoding contexts, 23 decoding for each GPU.
With the help of the GPU, 46 720p streams were decoded. There, on the GPU, 46p 480p streams were encoded. Next, on the CPU, encoding 360p, 240p and 160p was done - 46 streams each.
A load of 2100% CPU, 61% decoder, 16% of the encoder is fixed.
In addition, the encoding and decoding of 24 streams per CPU were launched, for each 1 stream - 4 outputs, as well as for the GPU.
Total turned out 70 streams on an input, 280 streams on an output .
Load: 4600%, 61% decoder, 16% encoder, 30GB RAM .
As with the last test, perhaps a larger GPU RAM would have given more contexts and we could handle more threads. But this is only in theory, it is necessary to check.
A few words about the problem that prevented us from processing more threads on the GPU.
At the end of last year, we conducted tests together with the NVidia team, with several cards. When working with several GPUs, it turned out that the creation of contexts greatly hinders the operation of the server - the creation of each new context took more and more time from the card. If the first context was created on the order of 300 ms, then each subsequent one added 200-300 ms and already in the third ten contexts the creation of a new one took 3-4 seconds each. When a transcoding script is created by the user, it is assumed that it starts working immediately and without delay, and this new circumstance nullified all the advantages in Nimble speed and gave delays in creating contexts that led to the start of encoding delays.
At first, suspicion fell upon Nimble, but then we did tests using ffmpeg, which NVidia itself provides to clients and the result turned out to be exactly the same - the GPU spends more and more time creating each new context. In conditions when the server is already transcoding and it is necessary to launch new streams for processing, this affects the overall performance and makes the server simply unsuitable for work.
The problem was described in detail by the NVidia team, but so far no standard solution has been provided. Therefore, we have implemented in our server a mechanism for caching contexts, with the preliminary creation of contexts at the start of the server. This solved the problem in terms of the end-user experience, but Nimble’s launch may take some time. Nimble setting for effective work with contexts is described in our blog .
In addition, not enough contexts are easy to create. With a large number of contexts, when any transcoding scenario is enabled, the NVENC API starts to generate the errors "
Experienced it turned out that one GPU can start up and work confidently with 47 contexts - and there is no difference, these are the contexts of the encoder or decoder. There is an assumption that this is due to the amount of memory on the GPU. Now there is 16 GB, if you put a card with 24 GB, it is likely that there will be more contexts. But this is only a theory, it is necessary to check, as mentioned earlier. The data obtained are valid for a specific GPU model, other cards must be tested separately.
It is the restriction on the number of contexts that puts the main obstacle when working with large loads.
So, the purpose of testing was to study the effectiveness of the GPU for the designated range of tasks and to develop recipes for its proper use. What was the result?
Above, we saw how the number of threads differs, which can be processed on the CPU and on the tandem CPU + GPU. Let's see what it means in terms of money. We take the same Softlayer as the basis and their prices for equipment rental.
Now let's see the test results:
For FullHD 1080p
GPU advantage: 2.25x.
Benefit from using a GPU: $ 819 * 2.25 - $ 1729 = $ 113 per month when renting a server with a GPU.
For HD 720p
GPU advantage: 3.18x.
Benefit from using a GPU: $ 819 * 3.18 - $ 1729 = $ 875 per month when renting a server with a GPU
That is, with the rental option, the savings are quite noticeable. This is without taking into account discounts - in the Russian office of IBM promise discounts on the rental of resources in the cloud compared to the prices presented here.
In the options with the purchase, we did not go deep, because Here TCO is highly dependent on the choice of supplier, the cost of service in the data center and other factors that are familiar to those who work with bare metal. However, preliminary figures also speak in favor of a GPU-based solution.
Also, do not forget about the traffic and the width of the channel - they are included in the above rates in a certain amount, but you will need to select options for your tasks based on the number of streams, the expected number of users, etc.
The variant with one graphic card per server seems to us more cost-effective than the variant with two or more cards. As we see, the GPU decoder always loaded more than the encoder, but even it remained underloaded due to problems with the use of contexts. If you add a second card, the decoder will be used even less, we will not be able to load the encoders at full capacity, and all the work on the encoding will still need to be transferred to the CPU, which will be unjustified in terms of money. We also tested the variant with two GPUs due to the support of Softlayer, but due to the weak economic effect, we do not provide details in the article.
Accordingly, to scale the load, it is preferable to add new servers with a single graphic card than to add maps to existing machines.
If the number of incoming and outgoing streams for your project is relatively small - say, a dozen HD streams with a small number of permissions at the exit, with a relatively small amount of filtering, it would be better to use a server without a GPU.
It is also worth noting that the amount of RAM for the stream conversion task is not as important as the computational power. So in some cases, you can save more by reducing the amount of memory.
The presented hardware solution - a combination of CPU and GPU Tesla M60 - perfectly suited for transcoding live streams under heavy loads. The GPU takes the most resource-intensive operations — decoding the streams and encoding them into the largest resolutions, while the medium and fine resolutions are well processed on the CPU.
If any of the readers have experience in optimizing the performance of graphics cards for live broadcasting, we will be glad to get acquainted with your experience - write in the comments.
One of our products is the Nimble Streamer media server, a server software that takes live streams and files as input and makes them accessible to a large number of viewers, allowing you to monetize content along the way. This is a native application written in C ++ and ported to all popular operating systems (Linux, Windows, MacOS) and platforms (x64, ARM). From the very beginning, low resource intensity and high productivity were the main requirements, and we manage to achieve good performance in this.
Last year, we released the Nimble Streamer add-on, a live stream transcoder . This application allows you to take a stream of video and / or audio in different formats as input and do various transformations with them in real time. The functionality includes decoding (both software and hardware), video and audio conversion using filters (resizing, overlay, etc.) and encoding (encoding) - both software and hardware.
')
The transcoder is controlled via the WMSPanel web service, transcoding scripts are created via the drag-n-drop interface, which allows you to see the process visually. Different scenarios can be run together - with this approach, it is convenient to run test combinations, loading the server in any variations.
In these videos you can see examples of the interface.
Decoding each stream is done only once before all further conversions ... This saves resources on the expensive operation of decoding, it will be clearly seen further in the course of the tests.
One of the transformation mechanisms that can be used in our transcoder is hardware decoding and video encoding using a NVidia GPU. Graphic cards of the latest generations allow us to take on some of the typical tasks, which relieves the load from the CPU. Our transcoder is able to work with this hardware, which is actively used by our customers.
In the course of communication with representatives of the Russian office of NVidia, we were offered to try to arrange joint stress testing of our transcoder and NVidia GPU in order to understand what the economic effect of such a tandem will be compared to exclusively software transcoding, without hardware acceleration. In addition, I wanted to understand how best to use the GPU, and, if possible, give good recipes.
We needed to quickly obtain the appropriate iron and access to it, for the cycle of our experiments. We planned to meet a couple of weeks. It remains to find where to get the equipment. The best option would be to find them in the cloud and get remote access. Looking for options, it turned out that AWS does not have a VM with a Maxwell generation GPU, and in the Azure cloud it is only planned to start providing them in a short time.
1. Iron from NVidia in the Softlayer cloud, setting up Nimble Streamer
With the help of NVidia, IBM has provided us with access to its cloud - the IBM Bluemix Cloud Platform (formerly Softlayer ). This is a large network of modern data centers (about 50 at the time of publication) around the world connected by a common private network and providing a large selection of cloud infrastructure services. All data centers are unified and allow renting from one to hundreds of virtual or physical servers of the required configurations for several hours, as well as balancers, storage systems, firewalls - in general, everything that is required to build a reliable IT infrastructure for the IT service being deployed.
The Russian representative office of IBM provided us with full access to the self-service portal for managing cloud services and the required server configuration, where we were able to work with different input streams and settings of our transcoder.
Iron
First, we were provided with a physical server (bare-metal) with 128 GB of RAM and 2xGPU NVidia Tesla M60 and the pre-installed OS Ubuntu 14.04. All server parameters, passwords, firmware versions, its switching, dedicated IPs, the state of the hardware components, were visible right in the personal account, allowing you to perform the required manipulations with the leased hardware, which minimized the need to interact with IBM support services. During the test run, it turned out that we could not optimally load such a configuration, due to a number of limitations in the generation of contexts.
We wanted to reduce the configuration. Since we used the cloud platform, it was necessary to request changes in the configuration through the self-service portal. After approval, this operation took about 2 hours to the approved maintenance window. During this time, the technical staff in the data center in Amsterdam, removed the extra components (RAM and 1xGPU strips) from the server provided to us earlier and returned it to the system. It should be noted that for developers this option is very convenient, since there is no need to either deal with the hardware settings, repair it, or even spend time installing the OS. Let me remind you, in this case, the hypervisor is not used because we need to squeeze the maximum out of hardware resources.
According to the results of our research, we stopped at the following server configuration:
Dual Intel Xeon E5-2690 v3 (2.60GHz)
24 Cores
64GB RAM
1TB SATA
We have 2 processors for 12 cores, and thanks to Hyper threading we get twice as much, i.e. virtually 48 cores.
In scenarios with a graphics accelerator, a card based on the GM204 - Tesla M60 chip was used:
NVIDIA Tesla M60
1xGPU: 2 x Maxwell GM204
Memory: 16GB GDDR5
Clock Speed: 2.5 GHz
NVIDIA CUDA Cores: 2 x 2048
Memory Bandwidth: 2 x 160GB / sec
I draw your attention to the fact that no affinity, chip tuning, overclocking, and other magic were done on the above hardware - only the overclocked CPU and GPU, and only the official driver from the NVidia site was used for the GPU. If someone has a similar experience - share in the comments.
So we got access. A quick familiarization with the web interface of the control panel (everything is simple and clear), then access to the server via SSH - and here we are in the usual command line of Ubuntu, we install Nimble Streamer, register a new transcoder license and make a small config setting.
Nimble Streamer Transcoder
Nimble Streamer was configured to pre-create a cache of GPU contexts. This is due to the fact that the GPU has a limit on the maximum number of created decoding and encoding contexts, and in addition, the creation of contexts on the fly can take too much time.
For more on the problem of creating contexts, see the appropriate section below.
Nimble settings on the example of the first series of tests:
nvenc_context_cache_enable = true
nvenc_context_create_lock = true
nvenc_context_cache_init = 0: 30: 15,1: 30: 15
nvenc_context_reuse_enable = true
More details about these settings are written in our article .
Before starting each series of tests, the cache was configured separately, taking into account the specifics of each task.
Creating transcoding scripts
Further work went on in our WMSPanel service, where the transcoder scripting is set up.
As already mentioned, the work goes through the web interface, everything is very clear and convenient. We have created a number of scenarios combining different transcoding options (CPU / GPU), different resolution options and different encoding parameters (CPU / GPU, profile, bitrate, etc.)
The sets of scripts can be run simultaneously, which makes it possible to introduce different combinations of tests into circulation, increase the load in a different order and change it depending on the situation. Simply select the necessary scenarios and stop or resume them.
Here is a set of scripts:
Here is an example of one of the scenarios:
A decoder with a GPU looks like this:
Overlay image size filter:
But the encoder for the version with the GPU:
In general, the operation of the transcoder interface can be viewed on these videos .
2. Transcoding FullHD 1080p Streams
To begin with, we tried the scenario with the largest loads in order to find out the limits of the possibilities of iron. At the moment, the most “difficult” resolution used in practice is FullHD 1080p.
To generate the original live streams, a file was taken in FullHD (1920 * 1080) in high profile H.264 . The content itself is a video tour of the city, i.e. This is a video with an average intensity of image change. There are no static monochrome frames that could facilitate the work of the transcoder, but there is no too fast change of types and colors. In a word - quite typical load.
At the entrance to Nimble Streamer, 36 identical streams were submitted, which were then used in the transcoder in different scenarios.
The transcoding scenario is typical - the incoming stream is 1080p high profile, 720p, 480p, 360p main profile are made from it , and then the baseline profile flows : 240p, 160p . So, at the entrance there is 1 stream, at the exit 5. Usually, the source stream is also made pass-through, so that the viewer can choose 1080p itself when viewing. We did not add it to the script, because it does not use transcoding - there is a direct transfer of data from the input to the output. This scenario is optimized in Nimble and in real conditions it will relatively slightly increase memory consumption.
Audio in generated streams is not. Adding audio to the script will not give significant load on the CPU, but for the purity of the experiment, we have excluded sound.
CPU test, no GPU
To begin with, we launched transcoding scripts without using a GPU, specifying software decoder and encoder in the scripts.
As a result, we managed to process only 16 input streams with issuing 80 streams of all exit permissions.
CPU load - 4600%, i.e. 46 cores were involved. RAM consumption is about 15GB.
CPU + GPU test
The context cache at startup is configured as 0: 30: 15,1: 30: 15 - i.e. 30 contexts for encoding, 15 for decoding, for each GPU.
Let me remind you that we have two cores on the GPU, which allows us to parallelize tasks - this will be useful to us.
The maximum load was obtained with the following configuration of threads.
At the input of the decoder GPU0 and GPU1 - 15 streams. Thus, we get 30 decoded streams ready for further use. Each stream is decoded only once, no matter how many scenarios it is subsequently used.
Encoders GPU0 and GPU1 were fed by 15 streams to get 720p, i.e. It turned out 30 720p streams to the output.
Also on the GPU0 and GPU1 encoders, 15 streams for 480p were given - and it also turned out 30 480p streams per output.
Since the encoder contexts were exhausted, the remaining resolutions were encoded on the CPU. It turned out the following:
- 30 360p threads
- 30 threads 240p
- 30 threads 160p
The load turned out to be 2600% CPU, 75% decoder, 32% encoder. Then, the CPU was loaded with 6 streams for decoding, for each of them 5 similar permissions were set, for a total of 30 streams per output.
In total, 36 streams were received at the input, 180 streams were output at the output . The final load is fixed as follows: 4400% CPU, 75% card decoder, 32% card encoder, 30GB RAM .
Few details
We decided to check the option in which we process the most difficult tasks on the GPU - decoding 1080 and encoding 720 and 480, and letting the rest be processed through the CPU.
First checked the limit of the decoder. With 22 streams on decoding, the problem with contexts affected, they simply could not be created. Reduced to 21 - the contexts were created, but the load became 100% and artifacts began to be observed in the stream. We stopped at 20 streams - we do decoding of 20 streams, encoding at 160p - everything works fine.
In addition, by experience it turned out that this card with 16GB of RAM on board can confidently work with 47 contexts - and there is no difference, these are the contexts of the encoder or decoder. I repeat - this is exactly this GPU Tesla M60, on other cards this number may be different. We believe that if the card had 24GB of RAM, the number of contexts could have been different, but this needs to be tested.
As a result, we chose the cache creation formula “15 decoder contexts and 30 encoder contexts” - which gives 30 input streams and for each allows us to create 2 resolutions. So, the top resolutions - 720 and 480 were coded onto the GPU, and the rest - 360, 240 and 160 - were sent to the CPU. And since the CPU was still free after that, we “finished off” the free cores with new threads, leaving 4 cores for utilitarian tasks.
3. Transcoding HD 720p streams
Scenario with typical load, because most of the content is now created in HD. Even the recent SuperBowl LI - the highest rated show on the American market - was broadcast in HD , leaving FullHD for the future.
To generate the original streams, a file was taken in HD (1280 * 720) in a high profile . Content is our engineer’s favorite “The Good Wife” series, i.e. This is a video with an average intensity of image change.
At the entrance to Nimble Streamer filed 70 identical streams, which were then used in the transcoder in different scenarios.
The following transcoding scenario is used - the incoming stream is 720p high profile, 480p, 360p main profile and further 240p, 160p baseline profile streams are made from it. Total, at the input 1 stream, at the output 4. Pass-through of the original stream, as in the previous scenario, was not executed. Audio in the generated streams is not there either.
CPU test, no GPU
As in the previous section, we tried to transcode streams only on the CPU. As a result, it turned out to process only 22 input streams with issuing 88 streams of all exit permissions. CPU load - 4700%, i.e. 47 cores were involved. RAM consumption is about 20GB.
CPU + GPU test
The context cache at startup is configured as 0: 23: 23,1: 23: 23 - i.e. 23 encoding contexts, 23 decoding for each GPU.
With the help of the GPU, 46 720p streams were decoded. There, on the GPU, 46p 480p streams were encoded. Next, on the CPU, encoding 360p, 240p and 160p was done - 46 streams each.
A load of 2100% CPU, 61% decoder, 16% of the encoder is fixed.
In addition, the encoding and decoding of 24 streams per CPU were launched, for each 1 stream - 4 outputs, as well as for the GPU.
Total turned out 70 streams on an input, 280 streams on an output .
Load: 4600%, 61% decoder, 16% encoder, 30GB RAM .
As with the last test, perhaps a larger GPU RAM would have given more contexts and we could handle more threads. But this is only in theory, it is necessary to check.
4. Problem with creating contexts in NVidia GPU
A few words about the problem that prevented us from processing more threads on the GPU.
At the end of last year, we conducted tests together with the NVidia team, with several cards. When working with several GPUs, it turned out that the creation of contexts greatly hinders the operation of the server - the creation of each new context took more and more time from the card. If the first context was created on the order of 300 ms, then each subsequent one added 200-300 ms and already in the third ten contexts the creation of a new one took 3-4 seconds each. When a transcoding script is created by the user, it is assumed that it starts working immediately and without delay, and this new circumstance nullified all the advantages in Nimble speed and gave delays in creating contexts that led to the start of encoding delays.
At first, suspicion fell upon Nimble, but then we did tests using ffmpeg, which NVidia itself provides to clients and the result turned out to be exactly the same - the GPU spends more and more time creating each new context. In conditions when the server is already transcoding and it is necessary to launch new streams for processing, this affects the overall performance and makes the server simply unsuitable for work.
The problem was described in detail by the NVidia team, but so far no standard solution has been provided. Therefore, we have implemented in our server a mechanism for caching contexts, with the preliminary creation of contexts at the start of the server. This solved the problem in terms of the end-user experience, but Nimble’s launch may take some time. Nimble setting for effective work with contexts is described in our blog .
In addition, not enough contexts are easy to create. With a large number of contexts, when any transcoding scenario is enabled, the NVENC API starts to generate the errors "
Experienced it turned out that one GPU can start up and work confidently with 47 contexts - and there is no difference, these are the contexts of the encoder or decoder. There is an assumption that this is due to the amount of memory on the GPU. Now there is 16 GB, if you put a card with 24 GB, it is likely that there will be more contexts. But this is only a theory, it is necessary to check, as mentioned earlier. The data obtained are valid for a specific GPU model, other cards must be tested separately.
It is the restriction on the number of contexts that puts the main obstacle when working with large loads.
5. Conclusions
So, the purpose of testing was to study the effectiveness of the GPU for the designated range of tasks and to develop recipes for its proper use. What was the result?
Economic effect
Above, we saw how the number of threads differs, which can be processed on the CPU and on the tandem CPU + GPU. Let's see what it means in terms of money. We take the same Softlayer as the basis and their prices for equipment rental.
- Configuration without a GPU will cost $ 819 per month . Here you can pick up the car.
- Configuration with a GPU will cost $ 1,729 per month for a data center in Amsterdam, prices can be found here . When using a GPU, the cost of renting a server increases slightly, since a larger form factor of 2U is used. The economic effect may be higher when purchasing equipment (but this requires a serious analysis of the TCO, taking into account the constant updating of the NVidia GPU line).
Now let's see the test results:
For FullHD 1080p
- CPU without GPU: 16 threads per input + 80 per output
- CPU + GPU: 36 threads per input + 180 per output
GPU advantage: 2.25x.
Benefit from using a GPU: $ 819 * 2.25 - $ 1729 = $ 113 per month when renting a server with a GPU.
For HD 720p
- CPU without GPU: 22 threads per input + 88 at the output
- CPU + GPU: 70 threads per input + 280 per output
GPU advantage: 3.18x.
Benefit from using a GPU: $ 819 * 3.18 - $ 1729 = $ 875 per month when renting a server with a GPU
That is, with the rental option, the savings are quite noticeable. This is without taking into account discounts - in the Russian office of IBM promise discounts on the rental of resources in the cloud compared to the prices presented here.
In the options with the purchase, we did not go deep, because Here TCO is highly dependent on the choice of supplier, the cost of service in the data center and other factors that are familiar to those who work with bare metal. However, preliminary figures also speak in favor of a GPU-based solution.
Also, do not forget about the traffic and the width of the channel - they are included in the above rates in a certain amount, but you will need to select options for your tasks based on the number of streams, the expected number of users, etc.
Scaling
The variant with one graphic card per server seems to us more cost-effective than the variant with two or more cards. As we see, the GPU decoder always loaded more than the encoder, but even it remained underloaded due to problems with the use of contexts. If you add a second card, the decoder will be used even less, we will not be able to load the encoders at full capacity, and all the work on the encoding will still need to be transferred to the CPU, which will be unjustified in terms of money. We also tested the variant with two GPUs due to the support of Softlayer, but due to the weak economic effect, we do not provide details in the article.
Accordingly, to scale the load, it is preferable to add new servers with a single graphic card than to add maps to existing machines.
If the number of incoming and outgoing streams for your project is relatively small - say, a dozen HD streams with a small number of permissions at the exit, with a relatively small amount of filtering, it would be better to use a server without a GPU.
It is also worth noting that the amount of RAM for the stream conversion task is not as important as the computational power. So in some cases, you can save more by reducing the amount of memory.
Conclusion
The presented hardware solution - a combination of CPU and GPU Tesla M60 - perfectly suited for transcoding live streams under heavy loads. The GPU takes the most resource-intensive operations — decoding the streams and encoding them into the largest resolutions, while the medium and fine resolutions are well processed on the CPU.
If any of the readers have experience in optimizing the performance of graphics cards for live broadcasting, we will be glad to get acquainted with your experience - write in the comments.
Source: https://habr.com/ru/post/401539/
All Articles