Probabilistic improvement of photos by several pixels: Google Brain model

An example of a neural network after learning on the basis of celebrities. On the left - the original set of 8 × 8 pixels at the input of the neural network, in the center - the result of interpolation up to 32 × 32 pixels according to the model prediction. On the right, real photographs of celebrities' faces, reduced to 32 × 32, from which samples were obtained for the left column
Is it possible to increase the resolution of photos to infinity? Is it possible to generate believable pictures based on 64 pixels? Logic dictates that this is impossible. The new neural network from Google Brain thinks otherwise. It really increases the resolution of photos to an incredible level.
Such an “over-enhancement” of the resolution is not the restoration of the original image from a low-resolution copy. This is a synthesis of a believable photo that probably could have been the original image. This is a probabilistic process.
When the task is to “increase the resolution” of a photo, but there are no details for improvement, the task of the model is to generate the most believable image from a human point of view. In turn, it is impossible to generate a realistic image until the model has created contours and has not made a “volitional” decision on which textures, forms and patterns will be present in different parts of the image.
')
For example, just look at the CDRV, where in the left column are real test images for a neural network. They lack the details of the skin and hair. They can in no way be restored by traditional interpolation methods like linear or bicubic. However, if you have preliminary knowledge of the entire diversity of faces and their typical outlines (and knowing that it is necessary to increase the resolution of the faces), then the neural network is able to do a fantastic thing - and “draw” the missing parts that are most likely to be there.
The Google Brain team has published a recursive pixel super resolution research paper that describes a fully probabilistic model trained on a set of high-resolution photos and their reduced copies of 8 × 8 to generate 32 × 32 images from small 8 × 8 samples.
The model consists of two components that are being trained at the same time: the conditional neural network (conditioning network) and the prior (prior network). The first one effectively superimposes the low-resolution image to the distribution of the corresponding high-resolution images, and the second models the high-resolution details to make the final version more realistic. A conforming neural network consists of ResNet blocks, and the prior is a PixelCNN architecture.
A schematic of the model is shown in the illustration.
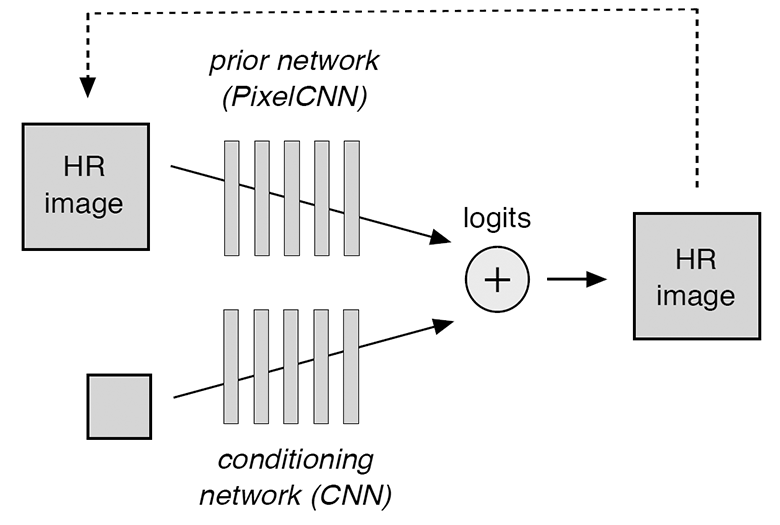
The conditioned convolutional neural network receives low-resolution images at the input and outputs logits — values that predict the conditional logit probability for each pixel of the high-resolution image. In turn, the convolutional neural network prior makes predictions based on previous random predictions (indicated by the dotted line in the diagram). The probability distribution for the entire model is calculated as a softmax-operator over the sum of two sets of logites with a conditioned neural network and a prior.
But how to evaluate the quality of work of such a network? The authors of the research work concluded that standard metrics such as peak signal-to-noise ratio (pSNR) and structural similarity (SSIM) are not able to correctly assess the quality of the prediction for such problems of a super-strong increase in resolution. According to these metrics, it turns out that the best result is blurry pictures, not photorealistic images, on which clear and believable details do not coincide in placement with clear details of the present image. That is, these pSNR and SSIM metrics are extremely conservative. Studies have shown that people easily distinguish real photos from blurry options created by regression methods, but it’s not so easy to distinguish samples from neural networks from real photos.
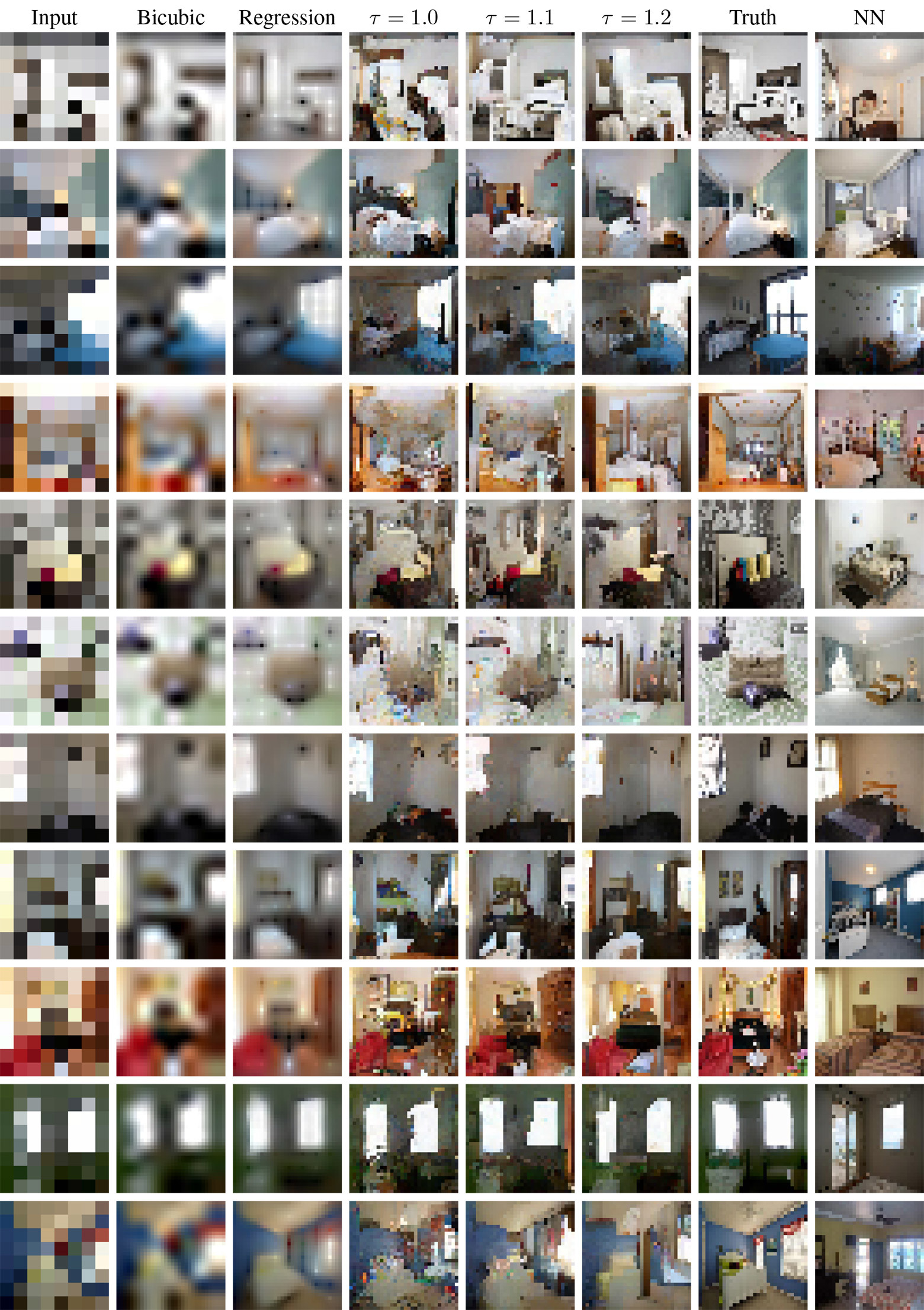
Let's see what results are shown by the model developed in Google Brain and trained on a set of 200,000 celebrities (a set of CelebA photos) and 2,000,000 bedrooms (a set of photos LSUN Bedrooms). In all cases, the photos before training the system were reduced to 32 × 32 pixels and then again to 8 × 8 using the bicubic interpolation method. Neural networks on TensorFlow were trained on 8 graphic processors.
The results were compared in two main bases: 1) independent pixel-by-regression (Regression) with the architecture similar to the SRResNet neural network, which shows outstanding results using standard metrics for assessing the quality of interpolation; 2) search for the nearest neighboring element (NN), which searches in the low-resolution training sample database for the most similar image by the proximity of pixels in the Euclidean space, and then returns the corresponding high-resolution picture from which this training sample was generated.
It should be noted that the probabilistic model produces results of different quality, depending on the temperature softmax. Manually it was found that the optimal values lie between 1.1 and 1.3. But even if you install , all the same, every time the results will be different.

Different results when starting the model with softmax temperature
You can evaluate the quality of the work of a probabilistic model by samples under a spoiler.
Bedroom Comparison

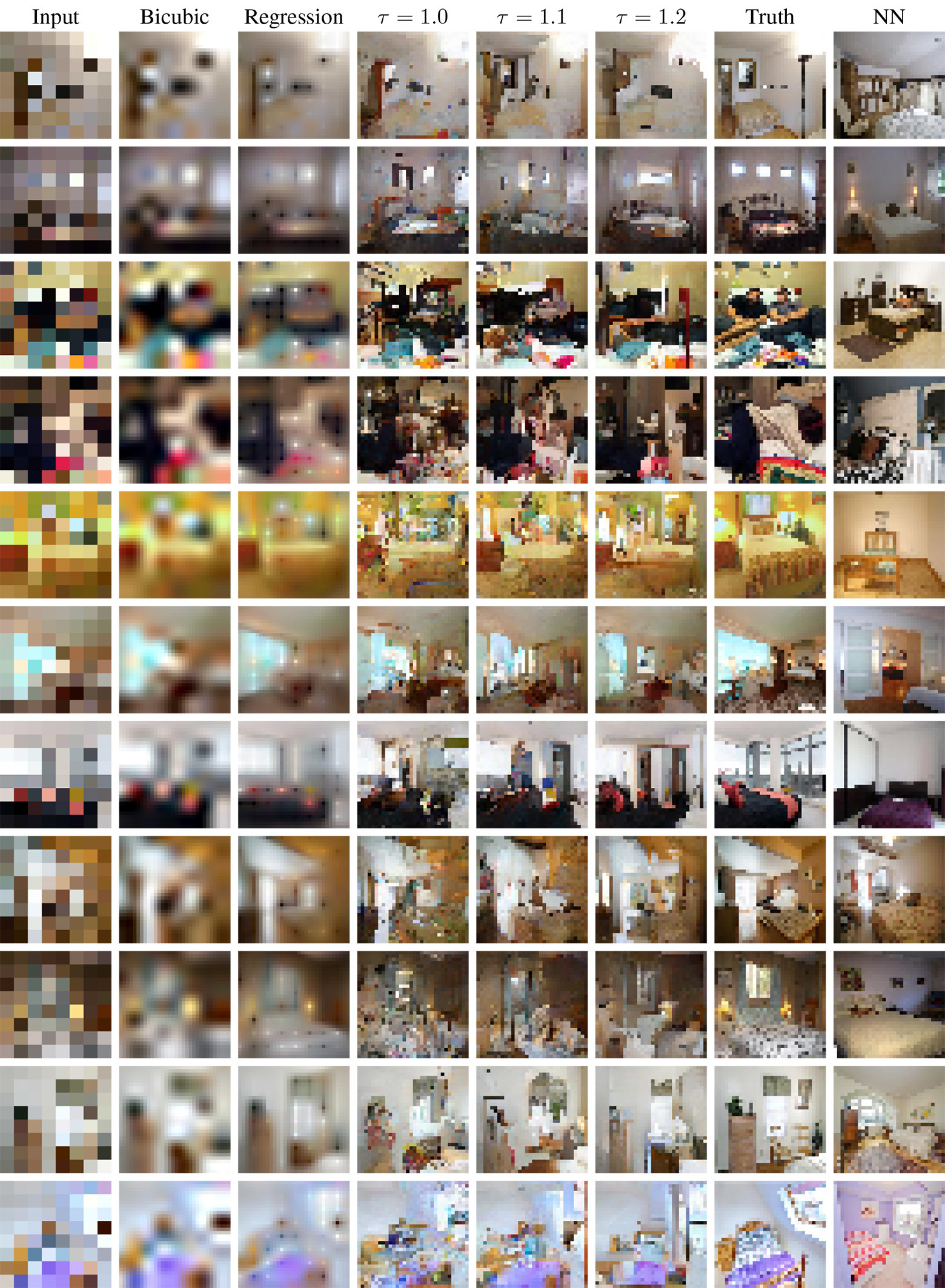

Comparison of results for celebrities




To test the realism of the results, scientists conducted a survey of crowdsourcing. Participants were shown two photos: one real, and the second generated by various methods from a reduced copy of 8 × 8 and asked to indicate which photo was taken by the camera.
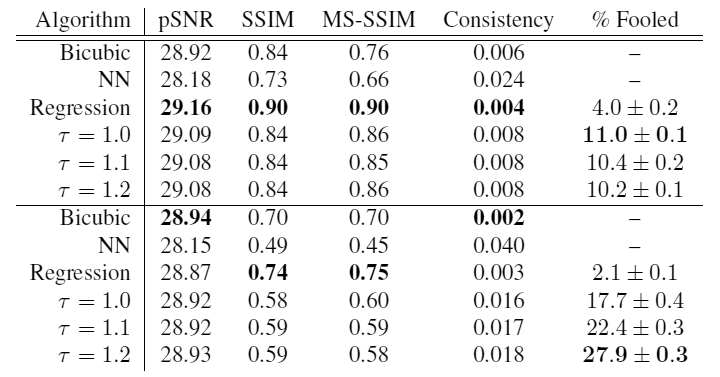
Top in the table - the results for the base of persons of celebrities, below - for bedrooms. As you can see, at a temperature the model showed the maximum result in the photos of the bedroom rooms: in 27.9% of cases, its issue was more realistic than the real image! This is a clear success.
The illustration below shows the most successful works of the neural network, in which it “beat” the originals in realism. For objectivity - and some of the worst.

In the field of generating photorealistic images using neural networks, there is now a very rapid development. In 2017, we will surely hear a lot of news on this topic.
Source: https://habr.com/ru/post/401395/
All Articles