Developing a mnemonic number memorization system
I set myself the goal for a long time to learn how to memorize numbers, mostly just as a task for self-development, I did not find obvious practical benefits. However, I want to memorize phone numbers, transport routes, dates. It was hard for me to find and start using a ready-made solution, but I wanted to work on my own.
The content of the article
- Prerequisites
- How to check if the system is good?
- We check several systems
- How to create a better system
- Link to repository and afterword
Prerequisites
- Mnemonic is a way to memorize with chains of associations. The most convenient way is to memorize word chains, imagining each word as an image and linking them together. The brain remembers such graphic-spatial information more easily. For example, you can memorize keywords from each thesis to a report. At the same time, it is important to choose images correctly, they must be of the same order and not too abstract, otherwise their interaction will not be so colorful and it will be difficult to remember.
- To memorize numbers, they use coding of numbers by letters — several numbers of vowels are assigned to each number, usually from 1 to 3. Two- and three-digit numbers are encoded in one word from, respectively, two and three syllables. Or, more precisely, two or three occurrences of vowels, a syllable may be one. For example, if 1 is D, 2 is P, then 11 is grandfather, 12 is depot, and 22 is just pop.
- Thus, in order to quickly memorize numbers, it is necessary to know by heart to which number which letters correspond and make up words, link them in chains.
- In practice, to come up with words every time slowly, so you need to learn 100 words for numbers from 0 to 99. Professionals sometimes know words to numbers up to 999.
- At the same time, for some reason, those mnemonic systems that I found use such correspondences that it is difficult to think up words, it is not very good to remember either. They use letters that look like numbers in sound or spelling to make it easier to remember the correspondence. Although it does not get any easier, because 1-2 digits are not similar, but there are a lot of "similarity" options.
- Separately, I note that I didn’t take up the use of the mnemonic system in English, because it seemed to me that I didn’t have enough knowledge of the language, I still can’t think quickly about it.
- So the question is, is it possible to choose more convenient matches? For the selection it was planned to use a full brute force or machine learning methods.
How to check if the system is good?
Since I consider the main drawback of the found systems to be the difficulty of compiling words for some numbers, I would like to consider the number of words.
Instead of using any book, I used a ready - made frequency dictionary . The dictionary is based on the national corpus of the Russian language, which, in turn, includes the analysis of many books, poems of different genres.
The frequency dictionary is available as a csv file , which I decided to analyze. Below are screenshots from Jupyter Notebook, for those who wish, at the end of the article there is a link to github.
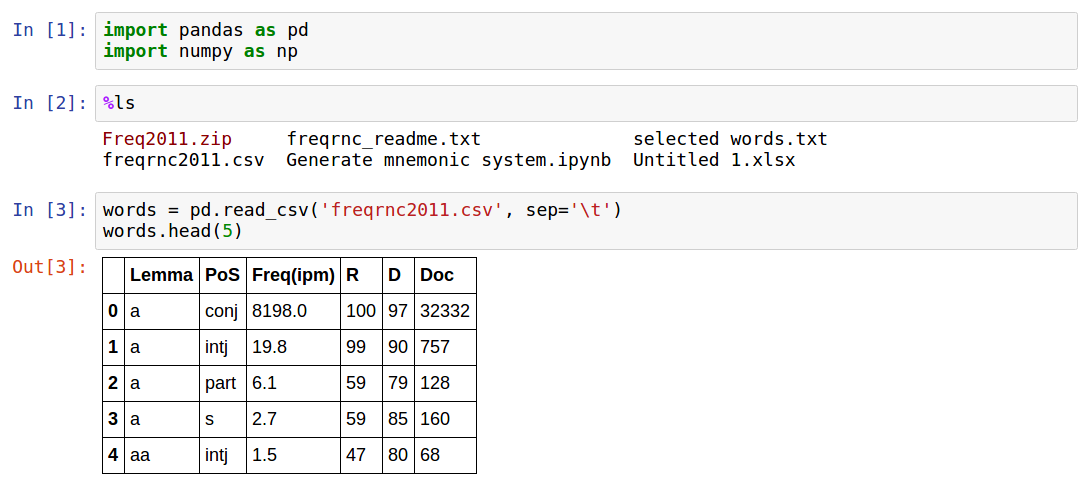
As you can see, the data contains:
- word itself (lemma)
- notation
- the four frequency metrics described in the introduction to the dictionary
I chose one measure of frequency, since only ranking is important to me. By trial and error it turned out that nouns are "s".
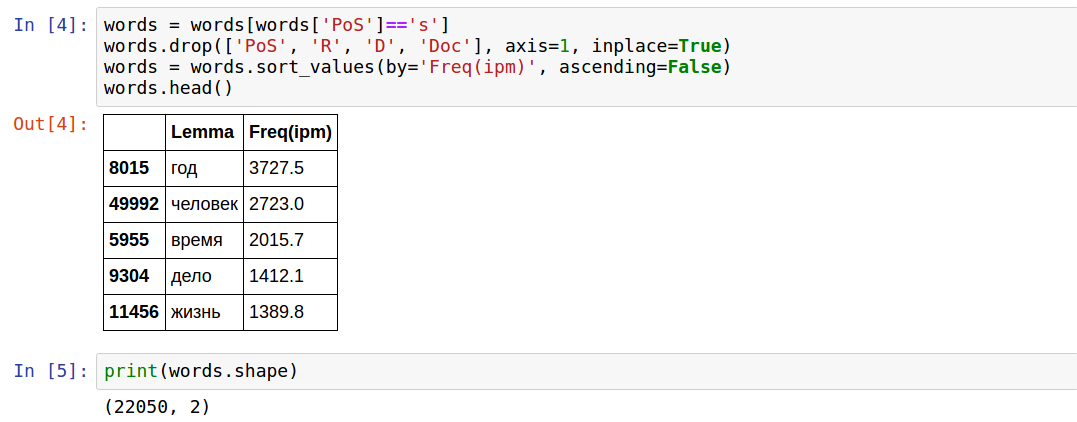
Thus, there are two columns and 22050 words.
However, among these words there are many that I do not know. In addition, I don’t want the “rare” letters to be the main ones in the code, so I decided to select words in which there are no such rare letters. As it turned out later, the idea is not very working, but nonetheless.
Choosing the "simple" and "complex" letters, we count their number. In addition, we derive the total number of consonant letters in a word.
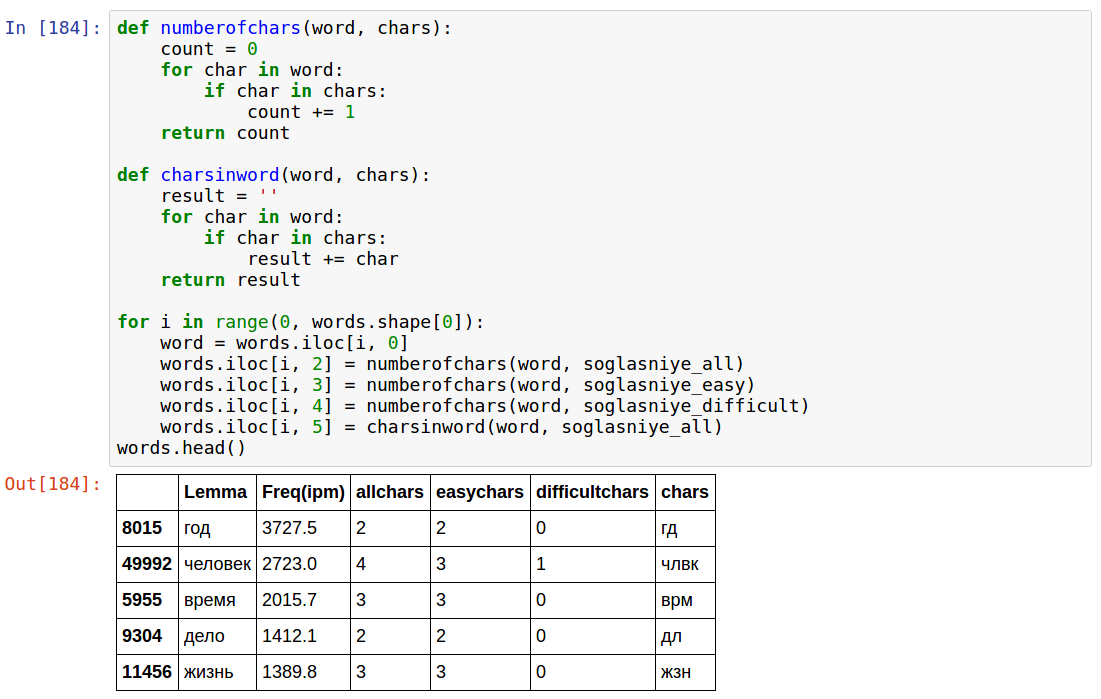
Note:
- allchars matches the number of digits that can be encrypted with this word
- chars is something that can be directly correlated with a number, if you have an appropriate match (I specifically)
- This code is the only one in this article that does not work "instantly", but takes about 10 seconds; I did not think how to make faster
Next, I thought that you need to select words with 2-3 consonants, without "complex" letters, and also choose the ones that I know. You can cut off on your own list sorted by frequency. As I later learned, this idea is also not very good, because the distribution of words is uneven: after all, there are many well-known rare words.
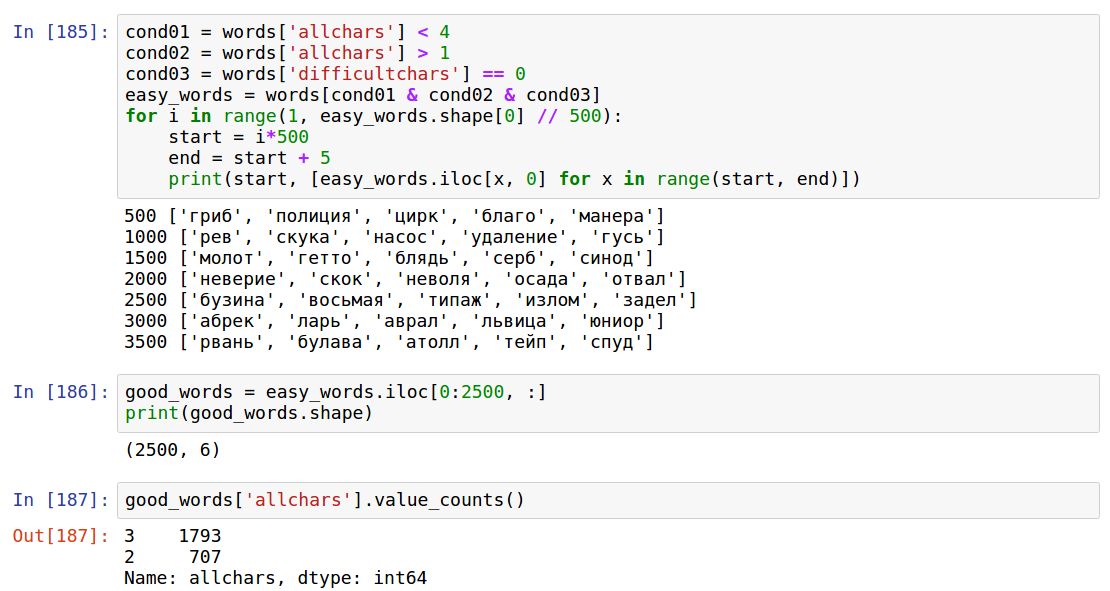
One way or another, 2500 words have fallen into the "good" words, since I don’t know what tap and box are. Of these, 707 words encoded numbers from 10 to 99 and 1793 numbers from 100 to 999. It should be noted here that 707 words are not so much for 90 numbers, less than 10 words per number, and this is together with abstract and unknown ones.
Next, I set the following functions:
- getallcombos creatively considers all combinations with which using a mapping (dictionary number: letters) you can encode a number (ns - a number as a string); returns a list of combinations
- testmaping checks how many words from words_for_test (DataFrame with our columns, including chars - only consonants) can encode numbers from 10 to 100 according to the provided mapping; List a word count for each number
- testresult prints some statistics; Considering the experience in preparation, for the article I left only the line with "0-5 words", which shows how many numbers could be encoded with 0 words, how many with only 1 word, etc.
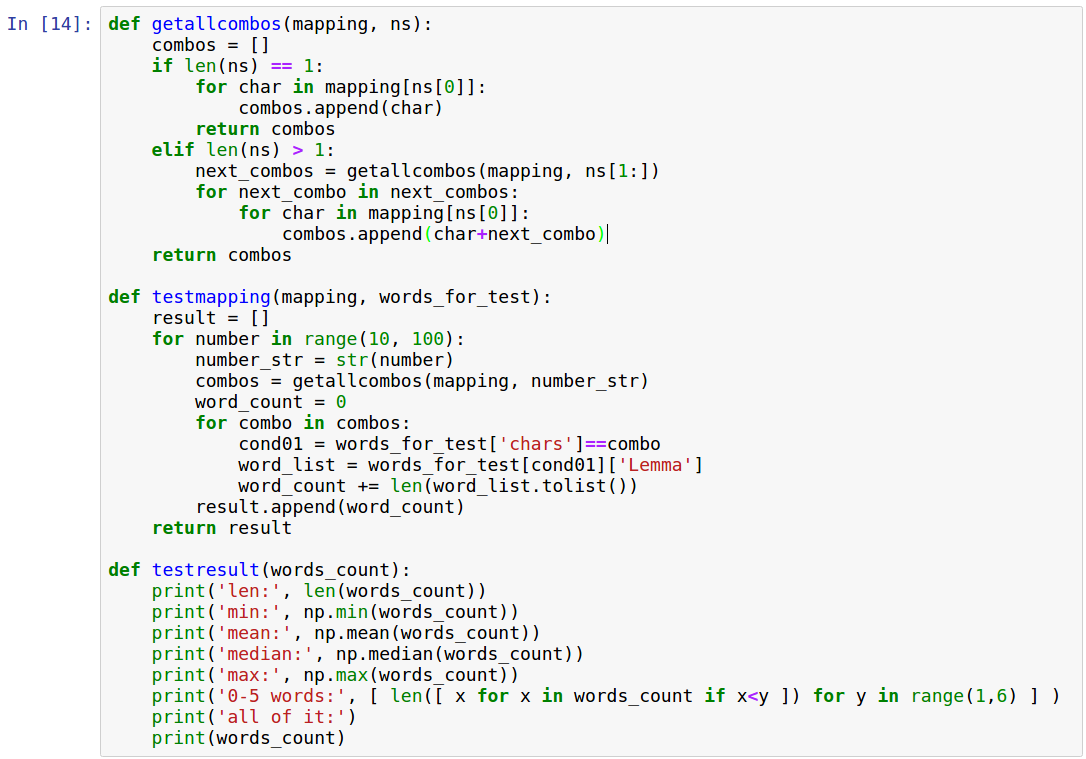
Thus, to test any mapping, it is enough to set it and call the test function.
We check several systems
I first came across the Giordano system. Many mobile applications for teaching mnemonics are based on it, it is also mentioned on the Internet, see, for example, here .
It seemed to me difficult in work. Try, for example, to come up with words for 84 or 11. I note that in the applications there are already ready images for numbers, but then you need to remember exactly them, a hundred pieces. In this case, there is another option to remember some of your own, close to yourself images.
Anyway, the test results are as follows:
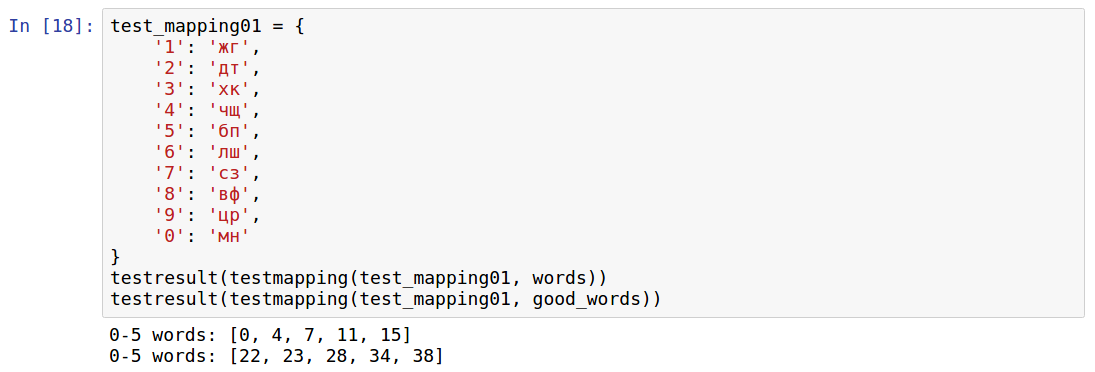
The results for all words are difficult to interpret immediately, but for “simple” words it is clear that there are no words for 22 numbers at all.
Another mapping, based on the letter from which the name of the number begins, is provided on one self-development site . Check:
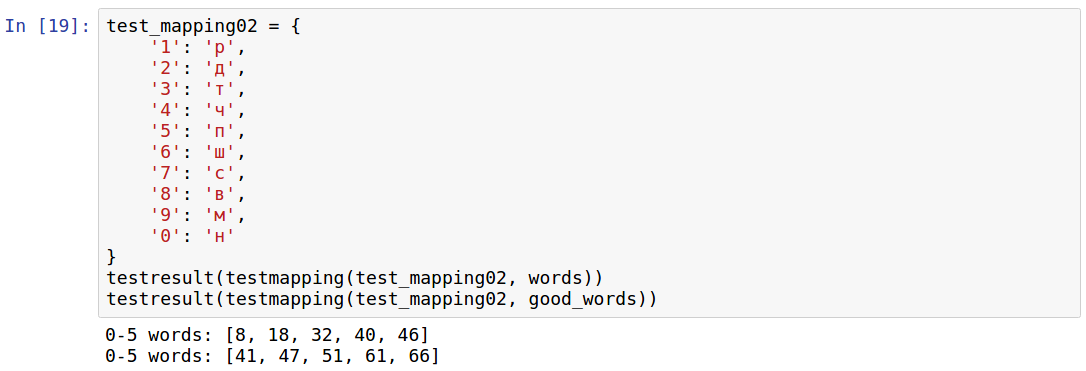
As you can see, it became much worse, for 8 digits there are no words at all. I note that, for example, there are few words where there are only two consonants of the letter R. But the more bad idea is to use for the code only rare letters like and .
How to create a better system?
In the process of selecting a system, the following steps were better:
- [0, 4, 7, 11, 15] Our baseline from the Jordano system
- Think about brute force or machine learning. I did not invent it and decided that it was better to adjust based on the frequency of occurrence of the letters.
- [4, 8, 11, 15, 19] At first I took all the popular letters and coded them. Letters FSCHSCH not used.
- [1, 1, 5, 5, 7] Added all the letters. It has already become somewhat better, but still there are numbers that cannot be encoded, this is an unacceptable deterioration.
- [1, 2, 5, 9, 16] I had previously used the frequency of letters from the Internet, and then I decided to calculate it myself in the case, put the letters, it did not become better.
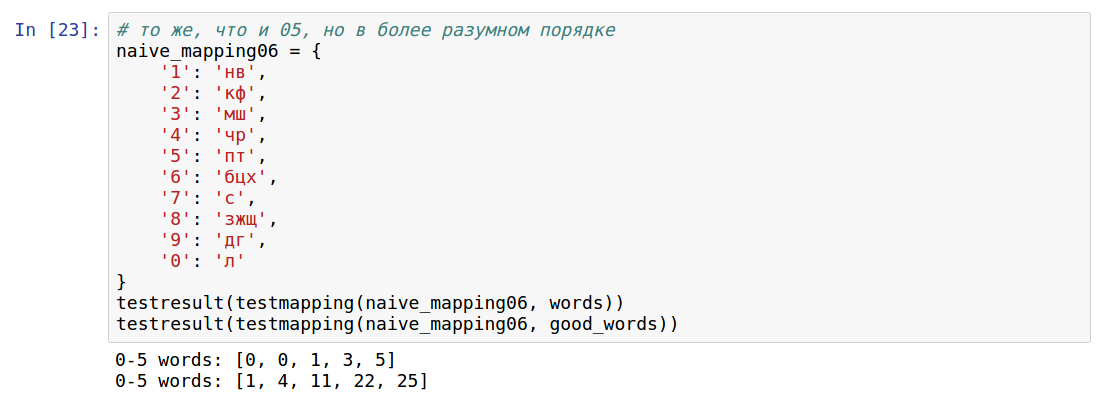
- [0, 0, 1, 3, 5] And here I understood the obvious thing now. Did you guess?
I realized that what matters is not the frequency of letters in a word as a whole, but the frequency of their location at 1 and 2 place in a word (for encoding two-digit numbers). It is necessary that for each digit there should be such letters so that the probability of finding one of these letters at the beginning or at the end of a word is the same.
We count the frequencies at 1 place, at 2 place and at 2 places at once:
It further seemed to me easier to copy the output to the spreadsheet editor and select the cipher so that the frequencies are as evenly distributed as possible between the encoded digits.
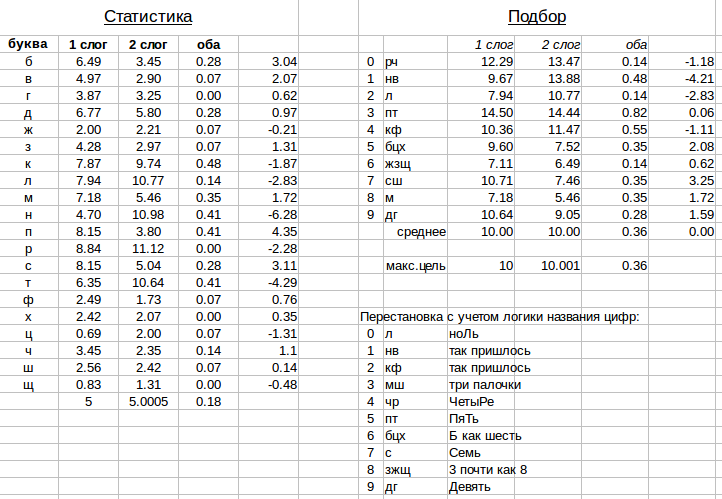
Let's look at the result:
As you can see, for the "simple" words there are still uncoded letters. For example, because no word contains PP, and the letter H was not in "simple" words. In the end, I decided that it would be more correct to count in all letters.
Let's look at the words that are included in the final list for some numbers:
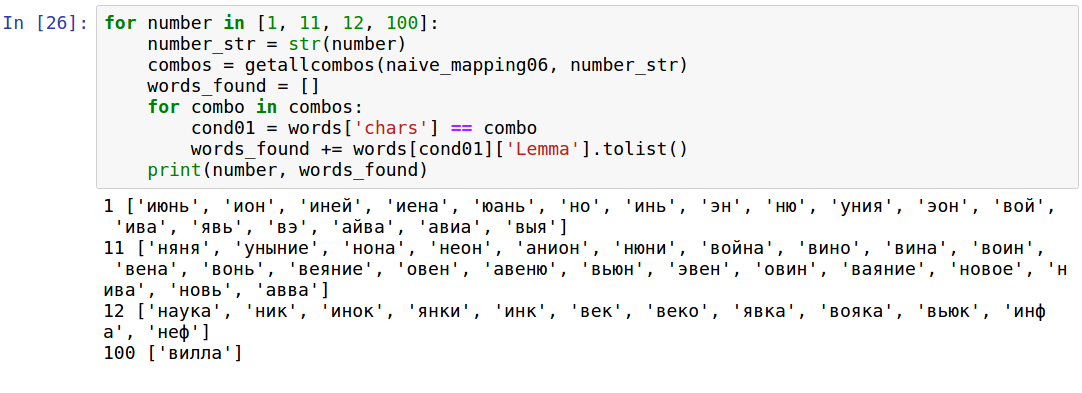
As you can see, the fact of the words fits a little less. We cannot use despondency, war, guilt, stench, spirit, new, new, and also words that we do not know. However, there are still a lot of good words for all numbers, including three-digit ones.
Link to repository and afterword
Laptop code, data and text of the article are here: Github
I hope you enjoyed it, and I will be glad to advice:
- how do you memorize numbers?
- How to do a full bust of acceptable mapping options?
- How to quickly master the method?
- about typos and possible improvements in the design of the article please write in private messages
')
Source: https://habr.com/ru/post/400525/
All Articles