The Pix2pix Neural Network realistically colors pencil sketches and black and white photos

Four examples of the program, whose code is published in the public domain. The source images are shown on the left, the result of automatic processing is shown on the right.
Many tasks in image processing, computer graphics and computer vision can be reduced to the problem of “broadcasting” one image (at the entrance) to another (at the output). Just as the same text can be presented in English or Russian, so the image can be presented in RGB-colors, in gradients, in the form of a map of object borders, a map of semantic labels, etc. Following a sample of automatic text translation systems, developers from the Berkeley AI Research (BAIR) laboratory at the University of California at Berkeley created an application for automatically translating images from one presentation to another. For example, from a black and white outline to a full color picture.
To an uninformed person, the work of such a program will seem like magic, but it is based on a program model of conditional generative adversarial networks (cGAN) —a variation of a known type of generative adversary networks (generative adversarial networks, GAN).
The authors of the scientific work write that most of the problems that arise during the broadcast of images are related to the broadcast or “many to one” (computer vision - the translation of photos into semantic maps, segments, borders of objects, etc.), or “one to many "(Computer graphics - translation of tags or input from the user in realistic images). Traditionally, each of these tasks is performed by a separate specialized application. In their work, the authors tried to create a single universal framework for all such problems. And they did it.
')
Convolutional neural networks, trained to minimize the loss function , that is, the measure of the discrepancy between the true value of the parameter being evaluated and the parameter estimate, are great for broadcasting images. Although the learning itself takes place automatically, it still takes considerable manual work to effectively minimize the loss function. In other words, we still need to explain and show neural networks what exactly needs to be minimized. And here lies a lot of pitfalls that negatively affect the result, if we work with the loss function at a low level such as “minimize the Euclidean distance between the predicted and real pixels” - this will lead to the generation of blurred images.

The effect of various loss functions on the result
It would be much easier for neural networks to set high-level tasks like “generate an image indistinguishable from reality”, and then automatically train the neural network to minimize the loss function that best performs the task. This is how generative competitive networks (GAN) work - one of the most promising areas in the development of neural networks today. The GAN network teaches a loss function, the task of which is to classify an image as “real” or “fake”, while simultaneously training the generative model to minimize this function. There can be no blurry output at all, because they will not pass the classification test as “real”.
The developers used conditional generative adversarial networks (cGAN), that is, GAN with a conditional parameter. Just as GAN assimilates the generative data model, cGAN assimilates the generative model according to a certain condition, which makes it suitable for broadcasting images “one to one”.

Streaming Cityscapes in realistic photos. On the left is the markup, in the center is the original, and on the right is the generated image.
In the past two years, many GAN applications have been described and the theoretical basis of their work has been well studied. But in all these works, GAN is used only for specialized tasks (for example, generating frightening images or generating porn pictures ). It was not entirely clear how GAN is suitable for efficiently broadcasting “one to one” images. The main goal of this work is to demonstrate that such a neural network is capable of performing a large list of various tasks, showing quite an acceptable result.
For example, the coloring of black and white pencil sketches (left column), on the basis of which the neural network generates photorealistic images (right column), looks very good. In some cases, the result of the neural network seems even more realistic than a real photo (central column, for comparison).

Broadcast pencil sketches into realistic photos. On the left is a pencil drawing, in the center is the original, and on the right is the generated image.


Broadcast pencil sketches into realistic photos
As in other generative networks, in this GAN neural networks are at war with each other . One of them (the generator) is trying to create a fake image to deceive the other (the discriminator). Over time, the generator learns all the better to deceive the discriminator, that is, to generate more realistic images. Unlike conventional GANs, in Pix2Pix, both a discriminator and a generator both have access to the original image.
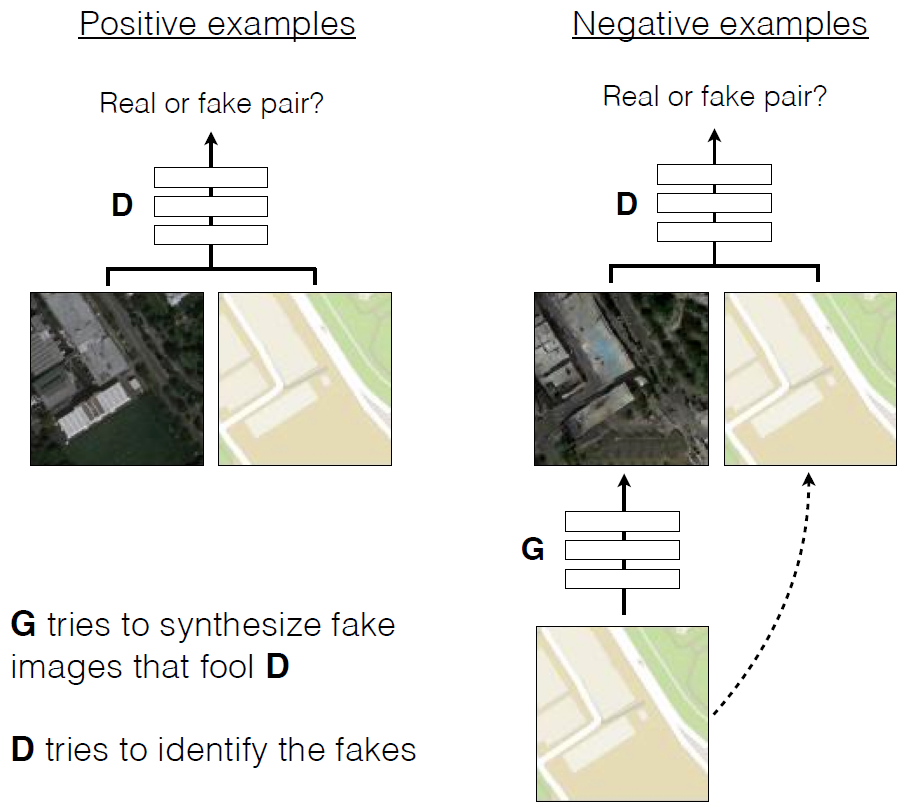
CGAN's training in predicting aerial photography using terrain maps

Examples of cGAN's work in broadcasting aerial photography to maps of the area and vice versa
The scientific article was published in open access, the source code of Pix2pix - on GitHub . The authors offer everyone to experience the program.
Source: https://habr.com/ru/post/399469/
All Articles