The neural network reads lips on 46.8% of words on TV, man - only 12.4%

Frames of four programs for which the program was taught, as well as the word "afternoon", pronounced by two different announcers
Two weeks ago, LipNet 's neural network was told , which showed a record quality of 93.4% lip-sensing of human speech. Even then, many applications were supposed for this kind of computer systems: medical hearing aids of new generation with speech recognition, systems for silent lectures in public places, biometric identification, hidden information transmission systems for espionage, speech recognition by video from surveillance cameras, etc. And now, experts from the University of Oxford, together with a staff member of Google DeepMind, told about their own developments in this area.
A new neural network was trained on arbitrary texts of people speaking on the BBC channel. Interestingly, the training was performed automatically, without prior annotating the speech manually. The system itself recognized the speech, annotated the video, found faces in the frame, and then learned to identify the relationship between words (sounds) and lip movement.
As a result, this system effectively recognizes just arbitrary texts, and not instances from the special body of GRID sentences, as LipNet did. The GRID corpus has a strictly limited structure and vocabulary, therefore only 33,000 sentences are possible. Thus, the number of variants is reduced by orders of magnitude and the recognition is simplified.
')
The special GRID package is composed of the following pattern:
command (4) + color (4) + preposition (4) + letter (25) + digit (10) + adverb (4),
where the number corresponds to the number of variants of words for each of the six verbal categories.
Unlike LipNet, the development of the company DeepMind and specialists from the University of Oxford works on arbitrary speech streams on television picture quality. It is much more like a real system, ready for practical use.
The AI was trained on 5,000 hours of video recorded from six television shows on the British television channel BBC from January 2010 to December 2015: these are regular news bulletins (1,584 hours), morning news (1997 hours), Newsnight programs (590 hours), World News (194 hours), Question Time (323 hours) and World Today (272 hours). In total, the videos contain 118,116 sentences of consistent human speech.
After that, the program was checked on broadcasts that went on the air between March and September 2016.
An example of reading lips from the TV screen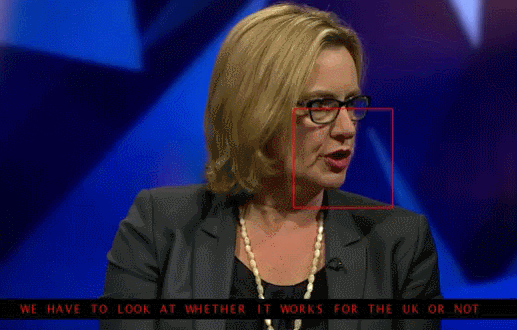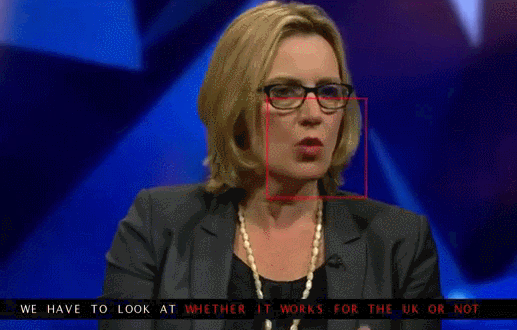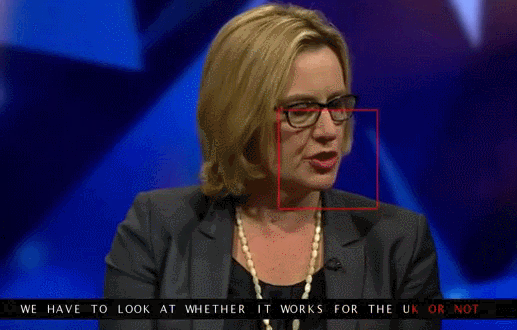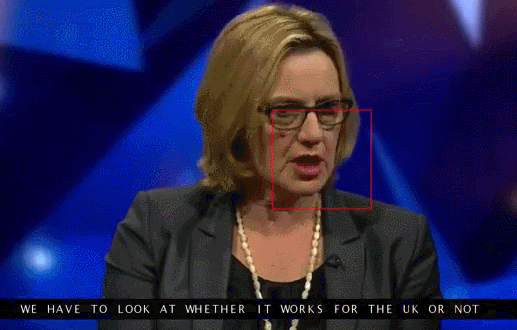
The program showed a fairly high quality of reading. She correctly recognized even very complex sentences with unusual grammatical constructions and the use of proper names. Examples of perfectly recognized sentences:
- MANY MORE PEOPLE WHO WERE INVOLVED IN THE ATTACKS
- CLOSE TO THE EUROPEAN COMMISSION'S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT'S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
The AI significantly outperformed the work of a man, a lip-reading expert, who tried to recognize 200 random video clips from a recorded video test archive.
The professional was able to annotate without a single error just 12.4% of the words, while the AI correctly recorded 46.8%. Researchers note that many errors can be called insignificant. For example, the missing "s" at the end of words. If we approach the analysis of the results less strictly, then the system actually recognized much more than half of the words on television.
With this result, DeepMind significantly surpasses all other lip-reading programs, including the aforementioned LipNet, which was also developed at Oxford University. However, it is too early to talk about final superiority, since LipNet was not trained on such a large data set.
According to experts , DeepMind is a big step towards developing a fully automatic lip reading system.
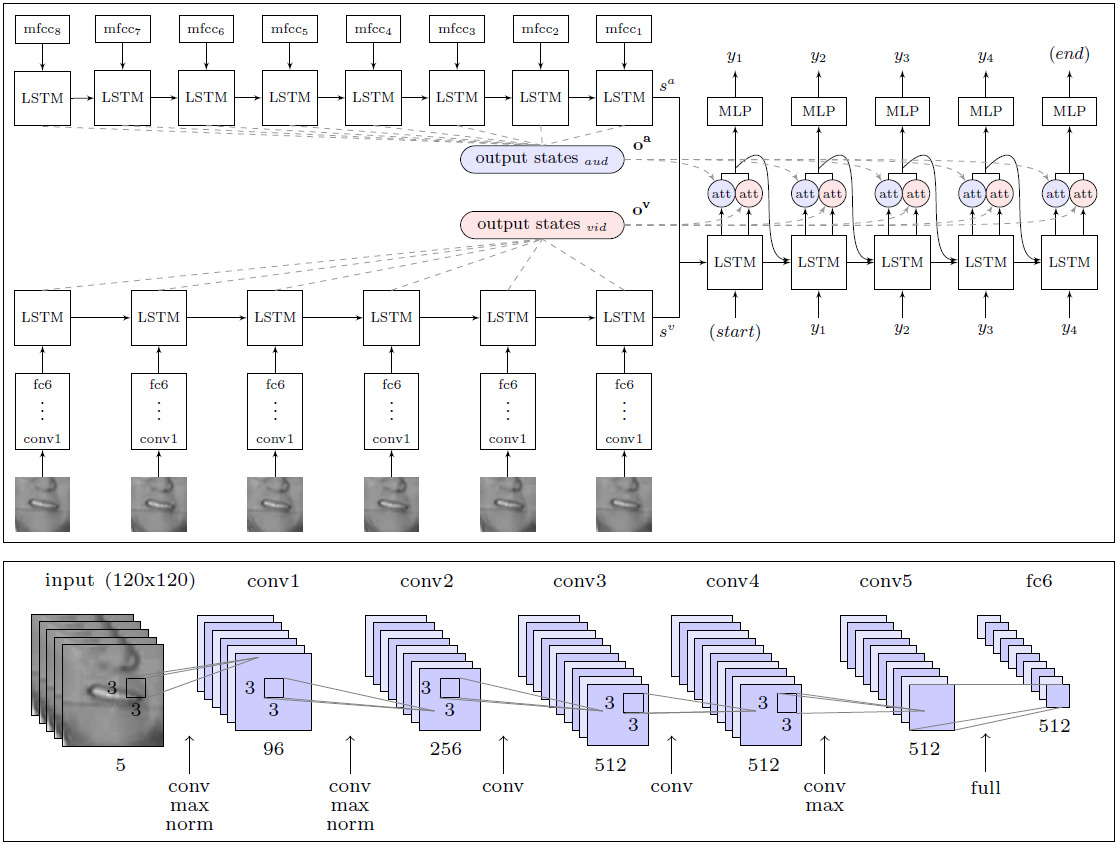
The architecture of the WLAS module (Watch, Listen, Attend and Spell) and the convolutional neural network for lip reading
The great merit of the researchers is that they have compiled a gigantic data set for learning and testing the system with 17,500 unique words. After all, this is not just five years of continuous recording of television broadcasts in competent English, but also clear synchronization of video and sound (TV often rassinhron up to 1 second, even on professional English television), as well as the development of a speech recognition module that overlaps in the video and is used in the lip-reading training system (WLAS module, see diagram above).
In the case of the slightest rassinhrona training of the system becomes almost useless, because the program can not determine the correct match of sounds and lip movements. After a thorough preparatory work, the training of the program was completely automatic - she independently processed all 5,000 videos.
Previously, such a set simply did not exist, so the same LipNet authors were forced to restrict themselves to the GRID base. To the credit of developers DeepMind, they promised to publish a data set in open access for training other AI. Colleagues from the LipNet development team have already said that they are waiting for this with impatience.
The scientific work is published in the public domain on the site arXiv (arXiv: 1611.05358v1).
If commercial lip-reading systems appear on the market, then the life of ordinary people will become much easier. It can be assumed that such systems will immediately integrate into televisions and other household appliances to improve voice control and practically unmistakable speech recognition.
Source: https://habr.com/ru/post/399429/
All Articles