LipNet neural network reads lips with 93.4% accuracy

Commander Dave Bowman and co-pilot Frank Poole, not trusting the computer, decided to disconnect it from controlling the ship. To do this, they confer in a soundproofed room, but HAL 9000 reads their lips-talk. Frame from the film "Space Odyssey 2001"
Reading lips plays an important role in communication. The experiments of 1976 showed that people “hear” completely different phonemes if you put the wrong sound on the lip movement (see “Hearing lips and seeing voices” , Nature 264, 746-748, 23 December 1976, doi: 10.1038 / 264746a0) .
From a practical point of view, lip reading is an important and useful skill. You can understand the interlocutor without turning off the music in the headphones, read the conversations of all people in sight (for example, all passengers in the waiting room), listen to people with binoculars or a telescope. The scope of the skill is very wide. The professional who mastered it will easily find a highly paid job. For example, in the field of security or competitive intelligence.
Automatic lip reading systems also have a rich practical potential. These are medical hearing aids of a new generation with speech recognition, systems for silent lectures in public places, biometric identification, systems of hidden information transmission for espionage, speech recognition by video from surveillance cameras, etc. In the end, the computers of the future, too, will read lips, like HAL 9000 .
')
Therefore, scientists for many years trying to develop automatic lip reading, but without much success. Even for relatively simple English, in which the number of phonemes is much less than in Russian, the recognition accuracy is low.
To understand speech on the basis of a person’s mimicry is a most difficult task. People who have mastered this skill are trying to recognize dozens of consonant phonemes, many of which are very similar in appearance. It is especially difficult for an unprepared person to distinguish between five categories of visual phonemes (that is, a visa) of English. In other words, it is almost impossible to distinguish the pronunciation of certain consonant sounds in the lips. It is not surprising that people do very poorly with accurate lip reading. Even the best among hearing impaired people demonstrate an accuracy of only 17 ± 12% of 30 monosyllabic words or 21 ± 11% of polysyllabic words (hereinafter, the results for the English language).
Automatic lip reading is one of the tasks of machine vision, which comes down to the frame-by-frame processing of a video sequence. The task is greatly complicated by the low quality of most practical video materials, which do not allow accurate reading of the spatiotemporal, that is, spatial-temporal characteristics of a person during a conversation. Persons move and turn in different directions. Recent developments in computer vision are trying to track the movement of faces in the frame to solve this problem. Despite successes, until recently they were able to recognize only single words, but not sentences.
Significant breakthroughs in this area have been made by the developers at Oxford University. The LipNet neural network trained by them became the first in the world to successfully recognize lip-level speech at the level of entire sentences while processing the video sequence.
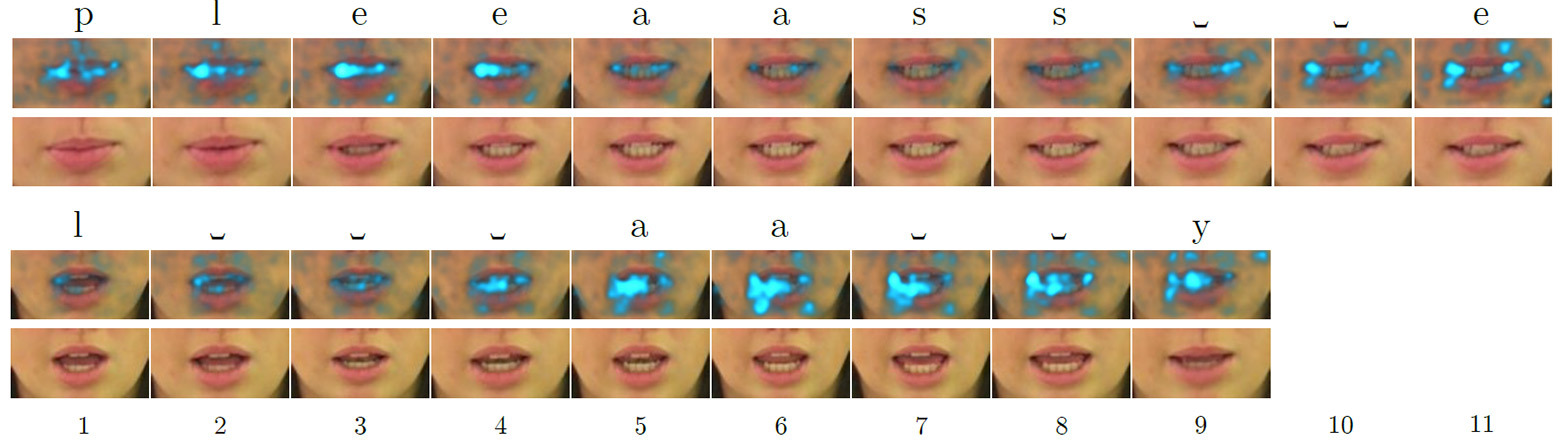
Single- card salinity cards for the English words "please" (above) and "lay" (below) when processed by a neural network that reads lips, highlighting the most attention-grabbing (salient) features
LipNet - recurrent neural network of type LSTM (long short-term memory). The architecture is shown in the illustration. The neural network was trained using the neural network temporal classification method (Connectionist Temporal Classification, CTC), which is widely used in modern speech recognition systems, since it eliminates the need for training in input data that is synchronized with the correct result.
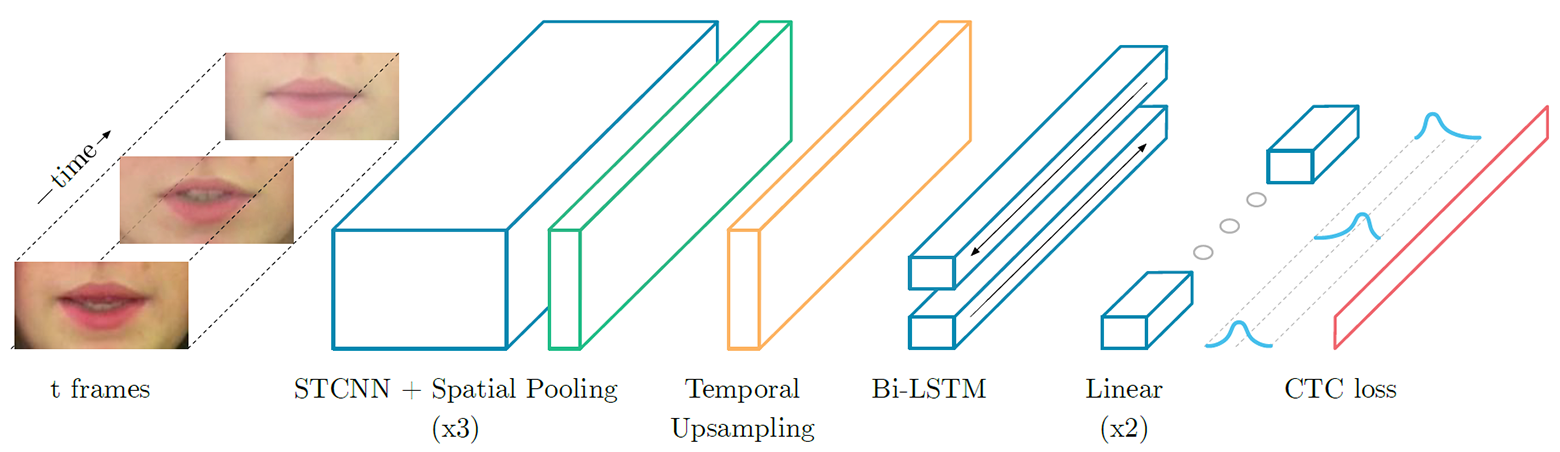
LipNet neural network architecture. The input is a sequence of frames T, which are then processed by three layers of the space-time (spatiotemporal) convolutional neural network (STCNN), each of which is accompanied by a layer of spatial sampling. For extracted features, the sampling rate on the timeline increases (upsampling), and then they are processed with dual LTSM. Each time step at the LTSM output is processed by a two-layer network of direct distribution and the last layer of SoftMax
On a special package of GRID sentences, the neural network shows recognition accuracy of 93.4%. This not only exceeds the recognition accuracy of other software developments (which are listed in the table below), but also exceeds the lip-reading performance of specially trained people.
| Method | Data set | The size | Extradition | Accuracy |
|---|---|---|---|---|
| Fu et al. (2008) | AVICAR | 851 | Numbers | 37.9% |
| Zhao et al. (2009) | AVLetter | 78 | Alphabet | 43.5% |
| Papandreou et al. (2009) | CUAVE | 1800 | Numbers | 83.0% |
| Chung & Zisserman (2016a) | OuluVS1 | 200 | Phrases | 91.4% |
| Chung & Zisserman (2016b) | OuluVS2 | 520 | Phrases | 94.1% |
| Chung & Zisserman (2016a) | BBC TV | > 400,000 | The words | 65.4% |
| Wand et al. (2016) | GRID | 9000 | The words | 79.6% |
| Lipnet | GRID | 28853 | suggestions | 93.4% |
The special GRID package is composed of the following pattern:
command (4) + color (4) + preposition (4) + letter (25) + digit (10) + adverb (4),
where the number corresponds to the number of variants of words for each of the six verbal categories.
In other words, the accuracy of 93.4% is still a result obtained in greenhouse laboratory conditions. Of course, when recognizing arbitrary human speech, the result will be much worse. Not to mention the analysis of data from a real video, where a person's face is not taken close-up in excellent lighting and with high resolution.
The operation of the LipNet neural network is shown in a demo video.
The scientific article was prepared for the ICLR 2017 conference and was published on November 4, 2016 in open access.
Source: https://habr.com/ru/post/398901/
All Articles