Intel will add in-depth instruction to the CPU
Some of the latest Intel processors support the AVX-512 vector instruction family. They are executed in blocks of 512 bits (64 bytes). The advantage of hardware support for such large instructions is that the processor processes more data in one clock cycle.
If the code is loaded with 64-bit words (8 bytes), then theoretically, if you do not take into account other factors, you can speed up its execution by eight times, if you use the instructions AVX-512.
The AVX-512 extension for the x86 command system supports 8 mask registers, 512-bit packed formats for integers and fractional numbers and operations on them, fine control of rounding modes (allows redefining global settings), broadcast operations, error suppression in operations with fractional numbers, gather / scatter operations, fast math operations, compact coding of large offsets.
The initial set of AVX-512 includes eight groups of instructions:
')
- AVX-512 Conflict Detection Instructions (CDI)
- AVX-512 Exponential and Reciprocal Instructions (ERI)
- AVX-512 Prefetch Instructions (PFI)
- AVX-512 Vector Length Extensions (VL)
- AVX-512 Byte and Word Instructions (BW)
- AVX-512 Doubleword and Quadword Instructions (DQ)
- AVX-512 Integer Fused Multiply Add (IFMA)
- AVX-512 Vector Byte Manipulation Instructions (VBMI)
The AVX-512 family is supported in the Intel Xeon Phi (formerly Intel MIC) Knights Landing coprocessor, some Skylake Xeon (SKX) processors, as well as future Cannonlake processors that will be available in 2017. The listed processors do not support all of the instructions. For example, Knights Landing Xeon Phi only supports CD, ER and PF. The Skylake Xeon (SKX) processor supports CD, VL, BW and DQ. Cannonlake processor - CD, VL, BW, DQ, IFMA.
Naturally, not any code can be turned into vector instructions, but you don’t need to do it with all the code, writes Daniel Lemire, professor of computer science at the University of Quebec, in his blog. According to him, it is important to optimize the “hot code”, which takes the most CPU resources. In many systems, a “hot code” is built from a series of cycles that scroll billions of times. That's it should be optimized, this is the main benefit.
For example, if such a Python code is recompiled from standard 64-bit instructions in AVX-512 using MKL Numpy , the execution time is reduced from 6-7 seconds to 1 second on the same processor.
import numpy as np np.random.seed(1234) xx = np.random.rand(1000000).reshape(1000, 1000) %timeit np.linalg.eig(xx) Hardware support for deep learning
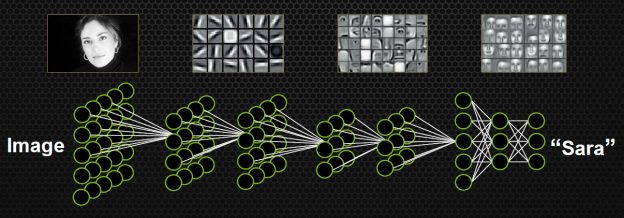
Neural networks and deep learning is one of the bright trends of recent times. Google, Facebook and other large companies are trying to apply neural networks wherever possible: in recommendation systems, face recognition, text translation, speech recognition, photo classification and even in board games like go (but this is more for PR than commercial gain). Some are trying to apply in-depth training in non-standard areas, such as automotive autopilot training .
Among venture investors, there is now an understanding that the most effective scheme to get rich quickly is to launch a start-up in the field of deep learning, which the company from the Big Five (Facebook, Google, Apple, Microsoft, Amazon) will immediately buy. These firms have recently been toughly competing in the area of talent buying, so the startup will go away instantly and for a large price of at least $ 10 million per employee. Such a business plan has now become even simpler, as companies produce open source development tools, as Google did with TensorFlow .
Unfortunately for Intel, this company is lagging behind and barely participates in the game. Professor Lemire acknowledges that Nvidia GPUs are now the industry standard. It is on them that the code for machine learning programs is run.
The point is not that Intel engineers overslept the trend. Just graphics processors themselves without any special instructions are better suited for deep learning calculations.
However, Intel is preparing a counterattack, as a result of which the situation can turn on its head. In September, the company published a new Intel Architecture Instruction Set Extensions Programming Reference, with all instructions that will be supported in future processors. If you look at this document, then we are waiting for a pleasant surprise. It turns out that the AVX-512 instruction set was divided into several groups and expanded.
In particular, two groups of instructions are specifically designed for in-depth training: AVX512_4VNNIW and AVX512_4FMAPS. Judging by the description, these instructions can be useful not only in in-depth training, but also in many other tasks.
- AVX512_4VNNIW: Vector instructions for enhanced word variable precision
- AVX512_4FMAPS: Single instructions for high precision floating-point single precision
This is very good news.
When such support appears in standard Intel processors, they can approach or even bypass the performance of in-depth training for Nvidia graphics. Of course, subject to appropriate optimization programs. Who knows, the same story will suddenly repeat as with video encoding, when, after adding hardware support for H.264 and H.265 to a CPU, Intel processors with integrated graphics began to encode and decode video faster than individual Nvidia and AMD video cards.
Source: https://habr.com/ru/post/398405/
All Articles