Poor research gets more and more money.

Viktor Petrik demonstrates his nanofilter (Source: rusphysics.ru)
In 1963, Jacob Ken, a psychologist from New York University, analyzed about 70 articles published in the Journal of Abnormal and Social Psychology and discovered an interesting fact. Only a small number of scientists recognized the failure of their research in the works. For these materials, he performed a calculation of their “statistical power”. The term “statistical power” means the probability of rejecting the null hypothesis if it is in fact incorrect.
According to statistics , the confirmation of the result expected by the researcher is manifested in the course of only 20% of the experiments performed. As it turned out, in almost all the works studied by Cohen, the authors indicated a positive expected result of the research. It turns out that the authors simply do not report failures. Moreover, some authors distort the results of their research, indicating a positive effect even in the case when it does not exist.
The magnitude of the power when checking the statistical hypothesis depends on the following factors :
- the magnitude of the level of significance, denoted by the Greek letter α (alpha), on the basis of which the decision is made to reject or accept an alternative hypothesis;
- the magnitude of the effect (i.e. the difference between the compared average);
- sample size required to confirm the statistical hypothesis.
More than half a century has passed since the publication of the work of Jacob Cohen, but the authors of scientific studies still talk about their successes, concealing defeats. This is proved by the results of another work published recently in the Royal Society Open Science. The authors of this work are Paul Smaldino of the University of California and Richard Mac Elres of the Max Planck Society for the Evolutionary Anthropology Institute . According to the researchers, modern articles have not become better. At the very least, articles that relate to psychology, neurology and medical science.
')
Having studied several dozen articles published in the period from 1960 to 2011, scientists determined that the average statistical power in this case is 24%. This is only slightly higher than the parameter that was calculated by Cohen. And this is despite the fact that in recent years the methods of scientific research have become more accurate, and more and more books and articles are published for researchers describing the principles and methods of scientific work.
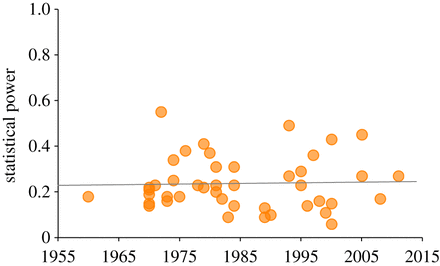
The average statistical power of publications published in scientific journals from 1960 to 2011
Having received such a result, scientists thought about what could change the current state of affairs, so that the authors of scientific works become more conscientious. To do this, Mac Elres and Smaldino created a computer evolutionary model. Within this model, about 100 virtual laboratories competed for the right to receive remuneration. It was paid in the event that, within the framework of the study, the laboratory team received a truly significant result. To determine the amount of remuneration, scientists used such an indicator as the volume of publications.
As it turned out , some labs worked more efficiently than others, showing more results. At the same time, these laboratories often gave what was expected to be true. In this case, the results were adjusted worse, and the results were interpreted as positive. If the results of the work were verified more carefully, then fewer works were published.
In each simulation cycle, all simulated laboratories performed experiments and published the results. After that, scientists removed the oldest laboratory from a number of randomly selected ones. And the laboratories from another random list (the selection criterion is the maximum amount of remuneration received) made it possible to create their own division that was active in publishing scientific materials. The preliminary results of the analysis of the computer model showed that the labs that published the most work devoted only a small amount of time to checking the results and became the most authoritative, spreading their research methods in the scientific community.
But there was something else. As it turned out, the repetition of the results of the work of one laboratory by a team of another leads to an improvement in the reputation of the first laboratory. But failure to repeat the results of any experiment leads to problems and lowers the reputation of the laboratory that conducted the experiment first. In this case, the filter is triggered, which prevents the appearance of fake research in the scientific community with modified research results.
The stronger the punishment was for those who published unverified results, the more powerful the low-quality research filter turned out to be. With a maximum penalty of 100 laboratories with fake data, the number of publications with real results increased sharply. In addition, the number of repeated experiments conducted by other laboratories with the intention of repeating someone’s results also increased.
Let me remind you that everything said above is a situation modeled on a PC. The authors of the study make the following conclusion: as before, now scientific organizations that publish more works than others are considered the most authoritative. Unfortunately, the filter of substandard publications that worked in the virtual world does not work very well in the real world. The fact is that research institutes and individual researchers do not often check each other’s results. If such checks with the intention to repeat the result obtained by the partner were carried out more often, then the “false results” in the world of science would be much less.
The authors of the study believe that the computer model has shown the possibility of changing the current state of affairs. If the foundations and scientific organizations did not give money to those scientists and laboratories who published the unverified results of their research, giving them a positive result, then there would be fewer deceivers. But to implement such a model in the real world is quite difficult. “Easier said than done,” says Smaldino.
So while in the positive are those organizations who publish many articles. But organizations that carefully verify their results are published less frequently.
DOI: 10.1098 / rsos.160384
Source: https://habr.com/ru/post/397897/
All Articles