Machine Neural Network is taught on realistic computer games

Images from the computer game Grand Theft Auto V and semantic markup for learning neural network machine vision
Neural networks set new records in almost all competitions in computer vision, and are also increasingly used in other AI applications. One of the key components of such incredible efficiency of neural networks is the availability of large data sets for their training and evaluation. For example, Imagenet Large Scale Visual Recognition Challenge (ILSVRC) with more than 1 million images is used to evaluate modern neural networks. But judging by the latest results (ResNet shows the result of only 3.57% errors ), researchers will soon have to compile more extensive data sets. And then - even more extensive. By the way, annotating such photos is a lot of work, some of which have to be done manually.
Some computer vision system developers offer an alternative way to train and test such systems. Instead of manually annotating training photos, they use synthesized frames from realistic computer games.
This is quite a logical approach. In modern games, graphics have reached such a level of realism that the synthesized images are slightly different from the photos of the real world. At the same time, the game engine can generate an infinite number of such frames - this immediately fundamentally solves the problem of collecting millions of photos for training and evaluating a neural network.
')
Although the game engine uses a finite number of textures, there is a wide variety of combinations of angles of view, lighting, weather, and level of detail that provides a sufficient variety of data sets.
This year, at once, two groups of researchers have tested in practice whether it is possible to use the generated frames from computer games for teaching neural networks. A group of researchers from the Faculty of Informatics at the University of British Columbia (Canada) published a scientific article for which they collected more than 60,000 frames from a computer game with road views similar to the CamVid and Cityscapes data sets. The researchers were able to prove that the neural network after training on synthetic images shows a similar level of errors, as after training on real photos. Moreover, training on synthesized images using real photos shows an even better result.
All 60,000 frames were made in virtual sunny weather, at a virtual time of 11:00, with a resolution of 1024 × 768 and maximum graphics settings (the name of the game was not disclosed due to copyright fears). An unmanned car accidentally drove through the game streets, following the rules of the road. Frames were taken 1 time per second. Each of them is accompanied by automatic semantic segmentation (sky, pedestrian, cars, trees, the background - the segmentation is absolutely accurate and taken from the game), a deep image (depth image, a map with the marking of objects), as well as surface normals.
In addition to the basic VG dataset, the researchers made another VG + dataset with a large amount of semantic information, not limited to five labels — here the segmentation is not accurate. The markup was done automatically with SegNet .

Tightly tagged frames from the VG + set
To compare the effectiveness of neural network learning, CamVid and Cityscapes data sets (five tags), as well as CamVid + and Cityscapes + data sets with extended tag sets, were prepared.

Original CamVid photos with annotations

Two random images of Cityscapes + set with detailed annotations
For the semantic classification, the Long convolutional neural network with the simple FCN8 architecture over the 16-layer Simonyan and Zisserman VGG was used .
The researchers conducted several experiments to evaluate the efficiency of object recognition by the neural network, which was trained on different data sets. In almost all cases, a neural network trained on synthetic data showed a better result than a neural network trained on real photographs. She showed the best result even when checking on real photos.
For example, the table shows the assessment of the work of identical neural networks trained on three data sets (real photos, synthetic data from the game, mixed set) when recognizing objects on real photos from the CamVid + and Cityscapes + sets.
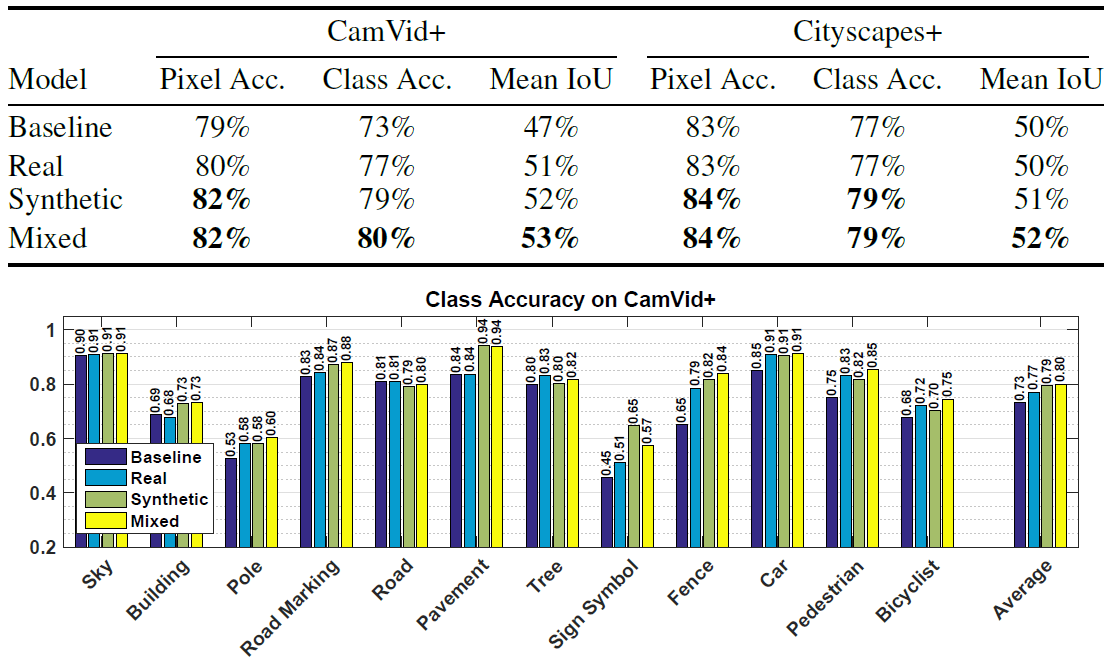
As you can see, when teaching a neural network, it is best to complement synthetic images from a computer game with real photographs.
The scientific article was published on August 5, 2016 on arXiv.org, the second version - August 15 ( pdf ).
In addition to researchers from the University of British Columbia, another group of scientists from Darmstadt Technical University (Germany) and Intel Labs did similar work almost simultaneously. They took 24,966 frames from Grand Theft Auto V, an open world computer game, for training. Researchers came up with the same result: when used for training a data set of 2/3 of synthetic images and 1/3 of CamVid photos, accuracy The recognition turns out to be higher than only when using CamVid photos.
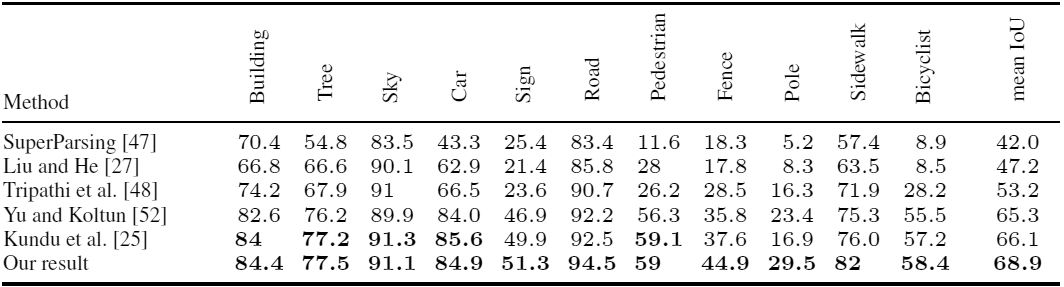
Accuracy of recognition of various objects in photos from the CamVid set when learning by conventional methods and using frames from GTA V (bottom line)
At the same time, semi-automatic annotation in a specially designed editor significantly reduces the time for preparing a dataset for training a neural network. For example, annotating one CamVid photo takes 60 minutes, one Cityscapes photo takes 90 minutes, and semi-automatic annotating a GTA V frame takes only 7 seconds, on average ( video, editor demonstration ).
The work of researchers from Darmstadt Technical University and Intel Labs prepared for the European Conference on Computer Vision ECCV'16 (October 11-14) and published on the university website. The authors have laid out the source code for reading labels and complete data sets : both source photos and deep images with semantic markup. The source code of the editor for annotating is likely to be published in the future.
Thanks to the progress in creating realistic computer games, developers of artificial intelligence systems will have at their disposal an excellent platform for learning computer vision systems. These systems will be used in unmanned vehicles and robots.
Perhaps computer games can be used not only for computer vision, but also for creating natural patterns of behavior in society. Only when learning AI should be careful to choose the game.
Source: https://habr.com/ru/post/397557/
All Articles