AI: imitation of intelligence, deception and real achievements

Since when did programs learn to impersonate people? How to understand if we are adept at us snag or really strong AI? When will the program cope with machine translation or write its first novel? Sergei oulenspiegel Markov, author of the game “ Play at God’s Level: How AI Learned to Win a Man, ” returns to the topic of smart machines in our new neural article.
Do programs know how to pretend to be people?
In the late 30s of the last century, when the first electronic computers had not yet been created, computer science experts began asking themselves about the "rationality" of machines. If something looks like a cat, meows like a cat, behaves like a cat, in any experiment it manifests itself like a cat, then probably this is a cat. This idea was formulated by Alfred Ayer - an English neo-positivist philosopher, a representative of analytical philosophy.
All of us beloved Alan Turing was more socialized than Iyer. Turing liked to go to parties, and at that time an interesting game was spread among the intellectual public - “Imitation game”. The game consisted in the fact that the girl and the guy were locked in two different rooms, leaving a wide gap under the door into which the participants of the game could send notes with questions. The person who was in the room wrote some answers to the questions. The task of the game was to guess which room the guy is in, and which one the girl is in. Turing suggested the following: "And let us use a similar procedure in order to understand whether we created the same universal AI."
')

The first program that could communicate with a person through a certain correspondence is ELIZA , created in 1966. The program tried to impersonate itself in an experiment not just for a person, but for a psychiatrist. Her style of communication is parody. That is, she speaks in a specific psychiatric jargon, asks the appropriate model questions. In principle, this program is a large set of rules according to which it found certain patterns in a person’s speech. In response to the presence of the corresponding input information pattern, ELIZA transformed it in a certain way and provided information on the output.
The program could fool people in some situations. The AOLiza experiment was conducted, when the program communicated through the America Online network with randomly selected users, and many of them did not realize that in this case the machine communicated with them. It is clear that this experiment cannot be considered as at least some serious approximation to the passing of the Turing test.
The name of the program ELIZA came from the name of the heroine Bernard Shaw from the play “Pygmalion”, which tells how London phonetics professor Henry Higgins tries to make a real lady from the public lower classes, teaching her the rules of behavior and the language of high society.
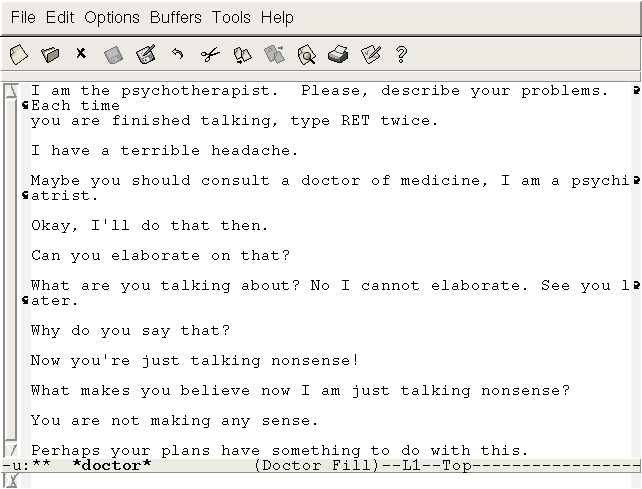
Interestingly, the second program of this kind (chat bot), created in 1972 by Kenneth Kolbay of Stanford University, was a kind of comic discussion with the authors of the ELIZA program. She was called PARRY. If ELIZA tried to pretend to be a doctor, then PARRY tried to impersonate a patient. PARRY considered herself a paranoid schizophrenic.
Interestingly, the program is well deceived professional psychiatrists. In the experiments, it turned out that 48% of psychiatrists are unable to understand whether they are dealing with a person or a program. But here, again, there was no purity of the experiment. If a person has certain dysfunctions, then his behavior can be quite automatic in some situations.

An interesting development of those times that made a very big impression is the SHRDLU program. The name SHRDLU is derived from ETAOIN SHRDLU - this is how the alphabetical keys on the linotypes are located (in accordance with the decrease in the frequency of occurrence of letters in English). As, for example, now YTSUKEN and FYVAPROLDZH.
SHRDLU had a small world in which a limited number of objects were represented. These were pyramids, various cubes, a box. And SHRDLU was able to communicate in a natural language with a person, discussing what is happening in this world, and knew how to execute commands that were given in a natural language by a person. At the same time, the vocabulary was not limited at all, that is, a person could say anything, and the program could respond fairly freely. Here is an example of how SHRDLU works:
Man : What is in the box?
Computer : Blue pyramid and blue block.
Man : What is the pyramid on?
Computer : On the box.
Man : How many blocks are there in the box?
Computer : Four.
Man : At least one of them is thinner than the one I told you about? Is it worth something?
Computer : Yes, it is on the table.
Man : Can the table collect blocks?
Computer : No
Man : Can a pyramid stand on a block?
Computer : Yes.
Man : Can a pyramid stand on a pyramid?
Computer : I don't know.
Man : Good. Put the pyramid one on another.
Computer : It does not work.
Man : Please put two red blocks on top of each other. Either a green cube or a pyramid. Can you? ”And SHRDLU takes these blocks, starts to operate with them.
Even now, this kind of demonstration looks impressive. Interestingly, the SHRDLU source can be downloaded , the program is written in LISP, there is even some modern visualizer for Windows. If you open its source code, you will see that the program consists of a huge number of ingenious rules.
When you read these rules, you understand how sophisticated logic is incorporated into the program. Terry Grape, apparently, conducted many experiments, allowing different people to communicate with this system. The SHRDLU world is very small: it can be described in about 50 different words. And within such a small space, you can create an impression of intellectual behavior in the system.
What programs can now
Once Turing was cornered to the wall and directly asked: "When will the programs pass the tests?" Turing suggested that in 2000 there will appear machines using 10 9 bits of memory, capable of deceiving a person in 30% of cases.

It is interesting to check whether the Turing forecast in 2016 came true. The program “ Eugene Goostman ” is a boy from Odessa. In the first test, held in 2012, the program was able to deceive the judges in 20.2% of cases. In 2014, in the test, the same program, already modernized, in tests organized by the University of Reading, was able to deceive the judges in 33% of cases. Roughly speaking, with an error of plus or minus 10 years, Turing approximately fell into the forecast.
Then came the Sonya Guseva program, and in 2015 she was able to deceive the judges in 47% of cases. It is worth noting that the testing procedure involves limiting the time for experts to communicate with the program (usually about 5 minutes), and in the light of this limitation, the results no longer look so clear. However, to solve many practical problems, for example, in the field of SMM automation, this is more than enough. Most likely, users of social networks will not be able to distinguish an advanced advertising bot from a person in practice.
Perhaps the most famous and serious objection to these successes is the response of the philosopher John Searle, who proposed a mental experiment called the Chinese Room . Imagine that there is a closed room, a person is sitting in it. We know that a person does not understand Chinese, cannot read what is written in Chinese characters on paper. But our experimental has a book with rules, in which the following is written: “If you have such hieroglyphs at the entrance, then you should take these hieroglyphs, and make them in that order.” He opens this book, it is written in English, looks at what they gave him at the entrance, and then, in accordance with these rules, forms the answer, and throws it at the exit. In a certain situation, it may seem that there is a person inside the room, actually understanding Chinese. But after all, the individual inside the room does not know the Chinese language on the formulation of the problem. It turns out that when the experiment was set up according to the Turing canons, it actually does not indicate that someone who understands Chinese is sitting inside. A great controversy has developed around this argument. There are typical objections to it. For example, the argument that if John himself does not understand Chinese, then the whole system, composed of John and a set of rules, already has this very understanding. Till now articles in a scientific press on this subject are written. However, most computer science experts believe that the Turing experiment is sufficient to draw certain conclusions.
Machine translate

From the machines that only pretend to be AI, let's move on to programs that really exceed human capabilities. One of the tasks directly related to the creation of AI is the task of automated translation. In principle, automated translation appeared long before the appearance of the first electronic machines. Already in the 1920s, the first mechanical machines were built, based on photographic equipment and fancy electrical mechanics, which were designed to speed up the search for words in dictionaries.
The idea to use a computer for translation was expressed in 1946, immediately after the appearance of the first such machines. The first public demonstration of machine translation (the so-called Georgetown experiment) took place in 1954. The first serious entry with serious money for the solution of this problem was carried out in the early 1960s, when systems were created in the United States for translation from Russian to English. These were the MARK and GAT programs. And in 1966 an interesting document was published on the evaluation of existing machine translation technologies and prospects. The content of this document can be summarized as follows: everything is very, very, very bad. But, nevertheless, no need to throw, we must continue to gnaw granite.
In the Soviet Union there were also such studies, for example, the group “Speech statistics”, headed by Raimund Piotrovsky . The employees of his laboratory founded the well-known company PROMT, which developed the first domestic commercial machine translation program based, among other things, on the ideas of Piotrovsky. Somewhere else by 1989, it was estimated that the automated translation system would speed up the translator’s work about 8 times. Now these figures are probably still a little improved. Of course, no system can match the translator, but it can speed up his work many times over. And every year the indicator of influence on the work of translators is growing.
The most important milestone in recent decades has been the arrival of systems on the stage, which emphasize purely statistical methods. As early as 1960-1970, it was clear that approaches based on the compilation of manual semantic maps of the language and syntactic structures appear to lead to a dead end, since the scale of the work is incredibly large. As it was believed, it is impossible in principle to keep up with the changing living language.
Forty years ago, linguists dealt with rather small language corpuses. Linguists could either manually process the data — take and count the number of such-and-such words in War and Peace, compile frequency tables, and do a primary statistical analysis, but the labor costs for performing such operations were tremendous. And here the situation drastically changed exactly when the Internet appeared, because along with the Internet a huge number of buildings in natural languages appeared. The question arose of how to make a system, which ideally would not know anything or almost nothing about the language, but at the same time receive giant corps at the entrance. Analyzing these shells, the system will automatically translate texts from one language to another quite well. This approach is implemented, for example, in Google Translate, that is, it is a system, behind the work of which there is very little work of linguists. So far, the translation quality of the previous generation systems - LEC, Babylon, PROMT - is higher than that of Google Translate.
Here, the problem rests on what kind of preprocessing we need for natural language, so that the results can be pushed into good predictive models such as convolutional neural networks, and the output will be what we need. How should preprocessing be constructed, what specific knowledge about natural language should it have in order to solve the further task of learning the system?

Recall the story of sausage in the dough (sausage in the father-in-law). That is, there is a sausage in the dough, but “in the dough” means not the dough, but the test. AI must understand a range of human cultural characteristics. He should understand that, most likely, in this context, the practice of wrapping dough in the preparation of sausages is supposed, and not the practice of putting sausages in the test. This does not mean that the second practice does not exist. Perhaps, in some context, an adequate translation would be to insert a sausage in the test. And here, only by understanding these most cultural references, which are present in natural language at every step, can one achieve a successful translation. Or maybe this is some kind of statistics related to the fact that, based on a statistical analysis of the shells, we simply see that in the texts of such subjects the most often used translation is about “sausage placed in dough”.
Another example is related to a cat that gave birth to three kittens: two whites, one African American. Again, what a huge cultural stratum floats here under the translation. In fact, the fact that an African American got here is a kind of approach towards understanding the cultural characteristics of modern society. While these problems are solved by different crutches such as setting the subject of the text. That is, we can say that we translate text in algebra. And then the program should understand that “Lie algebra” is “Lie algebra” and not “Lie algebra”. One way or another, this may work, but in universal terms we are still very far from a system that is truly comparable in quality to a human translator.
In recent years, neural network technologies have actively come into the field of machine translation. The specific topology of recurrent neural networks - the so-called Long-term-short-term memory (LSTM) architecture used for analyzing statements, turned out to be well applicable for solving translation problems. Modern tests show that the use of LSTM networks makes it possible to achieve a translation quality comparable to the level of quality of conventional technologies with a little effort.
Another fun task is writing poems. If you look at the purely technical side of the question, how to rhyme the words and put them in a certain poetic size, then this task was very simple as early as the 1970s, when Piotrovsky began to deal with it. We have a dictionary of words with accents, there are rhythmic maps of poetic sizes — we took and put words into this size. But here I would like to write something meaningful. As the first flies-Drosophila was taken the poetry of the skalds, because there is a very simple and clearly formulated canon.
Gudrun from revenge
Gore maiden together
Khar was skilled
Hamdir was brave
Sons killed.
Nierdom is not nice.
Conciliator.
Spear destructor.
- Tord son of Sjarek, translated by S.V. Petrova
A skald poem consists of so-called kennings, and each kenning is just a combination of several words that has an absolutely clear emotional and semantic coloring. The whole poem is made up of a sequence of Kenning. The task for a poetry writing program can be worded as follows: write an abusive poem about a crow. Accordingly, according to these criteria, the program selects suitable ones from its library of Kenning, and then adds a poem from them. This experiment is similar to the experiment of Terry Winograd with SHRDLU, because here is also a very simple model space, and in it primitive approaches can work, helping to get good results.
Machine translation for scientific articles

This is a machine uplift. Now we will explain why he is needed here. SCIgen program generates science-like nonsense. In general, she does it in English, but here you can make a combo - take the program-translator and science-like nonsense with the correct dictionaries translate into Russian. The result is a second order nonsense.
What do we lead to? There is such a problem: a mandatory requirement for a person who is going to defend a dissertation, to have several publications on the topics of his dissertation in journals from the list of the Higher Attestation Commission (HAC). Accordingly, a certain streaming business has developed around this requirement, namely, magazines have appeared that accept anything for publication. Formally, there should be a reviewer in the WAK journal who should read your text and say “yes, we accept this article for publication” or “no, we do not accept”. « », « X, ». , .
SCIgen , , , «: ». , , - , , , , .

2013 « », . -, , . 2016 , «, ». 1450 , . , 2865 . , 2016 - . , .
. , , . , - , , . . , , ( . , , ).
, . , , , . , , , , .
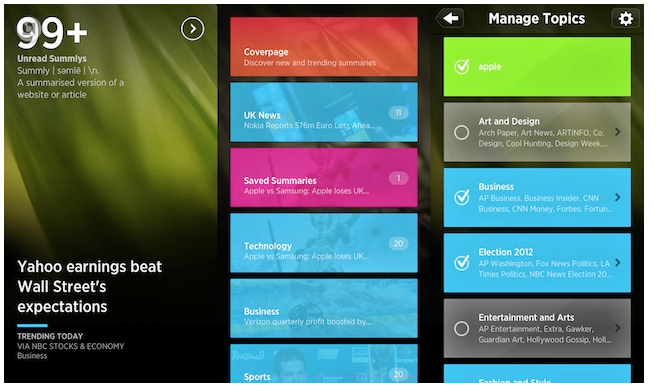
Summly, . Summly , , summary, 400 , «». , , «». , , 30 Yahoo.
Civil Science, , , . .
- . , , , , , , . , , , , 200 . . -, , . , . , , , . . , , .
— . , , , , , , , , .
. , , Prisma, .
:

, 2045 , 2029 .
. . Blue Brain , , , . 2022 . , — 1000 . , — () , . . BioRXiv.
, , . , . . , , , , ( ), - , . , Microsoft , FPGA . , CNTK, TensorFlow, Caffe, .
TrueNorth, IBM DARPA SyNapse, . IBM , . , , N . TrueNorth , - community .
. , . , , , . , . , , .
, : , ? , : . . -, , 20% , 2% . , , . , . , , . ́ , ́ . . , , . .
« » «» . , . , , - XX . , , . , - , : «, , , . , , . ». - , - , - . ? , - , , , , . , , .
. . , , computer science . , «», «» , , « » . , . , reverse engineering . , , , , opensource-. . !
Source: https://habr.com/ru/post/396671/
All Articles