What is differential privacy?
The sophisticated randomized response technique was first used by Google to collect Chrome statistics. Will Apple follow suit?
About the author. Matthew Green: cryptographer, professor at Johns Hopkins University, author of a blog about the development of cryptographic systems
Published June 14, 2016
 Yesterday at the WWDC's speech, Apple introduced a number of new features to secure and protect sensitive data, including one feature that caused particular attention ... and confusion. Namely, Apple announced the use of a new technology called "Differential Privacy" (abbreviated: DP) to improve the protection of privacy when collecting confidential user data.
Yesterday at the WWDC's speech, Apple introduced a number of new features to secure and protect sensitive data, including one feature that caused particular attention ... and confusion. Namely, Apple announced the use of a new technology called "Differential Privacy" (abbreviated: DP) to improve the protection of privacy when collecting confidential user data.For most people, this caused a dumb question: "what the ... ???", because very few people have heard of differential privacy before, and even more they understand what it means. Unfortunately, Apple is not crystal clear when it comes to the secret ingredients on which their platform operates, so it’s hoped that in the future it will decide to publish more information. Everything that we know at the moment is contained in the manual for Apple iOS 10 Preview.
“Starting with iOS 10, Apple uses differential privacy technology to help identify patterns of user behavior for a large number of users without jeopardizing the privacy of each. To hide a person’s personality, differential privacy adds a mathematical noise to a small sample of an individual pattern of user-specific user behavior. When more people display the same pattern, common patterns begin to emerge that can inform us and improve the overall user experience. In iOS 10, this technology will help improve QuickType and Emoji tips, Spotlight tips, and Lookup Hints in Notes. ”
')
In short, it seems that Apple wants to collect much more data from your phone.
Basically, they do this in order to improve their services, and not to collect information about the individual habits and characteristics of each user. To ensure this, Apple intends to use sophisticated statistical techniques to ensure that the aggregate base — the result of calculating the statistical function after processing all of your information — does not return individual participants. In principle, it sounds quite good. But of course, the devil is always in the details.
Although we do not have these details, it seems now is the time to at least talk about what differential privacy is, how it can be implemented and what it can mean for Apple — and for your iPhone.
Motivation
In the past few years, the “ordinary user” has become accustomed to the idea that a huge amount of personal information is sent from his device to various services that he uses. Opinion polls also show that citizens are beginning to feel discomfort for this reason .
This discomfort makes sense if you think about those companies that use our personal information to make money on us. However, sometimes there are decent reasons to collect information about user actions. For example, Microsoft recently introduced a tool that can diagnose pancreatic cancer by analyzing your search queries in Bing. Google supports the work of the well-known Google Flu Trends service for predicting the spread of infectious diseases by the frequency of search queries in various areas. And of course, we all benefit from crowdsourcing data that improves the quality of the services we use - from map applications to restaurant reviews.
Unfortunately, even collecting data for good purposes can be harmful. For example, in the late 2000s, Netflix announced a competition to develop a better recommendation algorithm for feature films. To help the participants in the competition, they published an “anonymized” data set with statistics of users watching movies, deleting all personal information from there. Unfortunately, this “de-identification” was not enough. In the well-known scientific work, Narayan and Shmatikov showed that such data sets can be used to de-anonymize specific users - and even to predict their political views! - just if you know some additional information about these users.
Such things should bother us. Not just because commercial companies routinely exchange collected information about users among themselves (although they do), but because hacks occur, and because even statistics on the collected database can somehow clarify the details of the specific individual records that were used. to compile an aggregated sample. Differential privacy is a toolkit designed to solve this problem.
What is differential privacy?
Differential privacy is the definition of user data protection originally proposed by Cynthia Dwork in 2006. Roughly speaking, it can be briefly described as follows:
Imagine that you have two otherwise identical databases, one with your information inside and one without it. Differential privacy ensures that a statistical query to one and a second database will produce a certain result with (almost) the same probability.
This can be represented as follows: DP allows you to understand whether your data have any statistically significant effect on the query result. If not, they can be safely added to the database, because this will cause almost no harm. Consider such a stupid example:
Imagine that you activated on your iPhone the option to report to Apple that you often use emoji
 in their iMessage chat sessions. This report consists of one bit of information: 1 means you like , and 0 - what is not. Apple can receive these reports and put them in a giant database. As a result, the company wants to be able to find out the number of users who like a particular emoji.
in their iMessage chat sessions. This report consists of one bit of information: 1 means you like , and 0 - what is not. Apple can receive these reports and put them in a giant database. As a result, the company wants to be able to find out the number of users who like a particular emoji.It goes without saying that a simple process of summing up results and publishing them does not satisfy the definition of DP, because the arithmetic operation of summing values in a database that contains your information will potentially yield a different result than summing values from a database where your information is missing. Therefore, although such amounts will give out some information about you, but still a piece of personal information will leak. The main conclusion of the differential privacy study is that in many cases the DP principle can be achieved by adding random noise to the result. For example, instead of a simple message of the final result, the reporting side can implement the Gauss or Laplace distribution, so the result will not be as accurate - but it will mask each specific value in the database. (There are many other techniques for other interesting features).
Even more valuable, the calculation of the amount of added noise can be done without knowing the contents of the database itself (or even its size) . That is, a noise calculation can be carried out based only on the knowledge of the function itself that is being performed and the acceptable level of data leakage.
The trade-off between privacy and accuracy
Now it’s obvious that counting the number of lovers
among users, a rather unfortunate example. In the case of DP, it is important that the same general approach can be applied to much more interesting functions, including complex statistical calculations, like those used in machine learning systems. It can be applied even if many different functions are calculated on the same database.But there is one catch. The fact is that the size of the “information leakage” from a single request can be minimized within small limits, but it will not be zero. Every time you send a database request with a function, the total “leakage” increases - and can never be reduced. Over time, as the number of requests increases, the leakage may start to grow.
This is one of the most difficult aspects of DP. It manifests itself in two main ways:
- The more you intend to "ask" the database, the more noise you have to add to minimize information leakage . This means that DP, in fact, represents a fundamental compromise between accuracy and the protection of personal data, which can be a big problem when training complex machine learning models.
- As soon as the data leaked, they disappeared . When a leak of information goes beyond the calculated limits, which say that you are safe, then you can’t continue any further - at least without risking your privacy. In such a situation, the best solution may simply be to destroy the database and start over. If this is possible.
The total amount of leakage allowed is often referred to as the “privacy budget,” and it determines how many requests are allowed to be made (and how accurate the results will be). The main lesson of DP is that the devil is hiding in a budget. Set it too high and important data will leak. Set it too low, and the results of the queries may be useless.
Now in some applications, like most applications in our iPhones, insufficient accuracy will not become a particular problem. We are used to our mistakes making mistakes. But at times, when DP is used in complex applications, such as training machine learning models, this is really important.
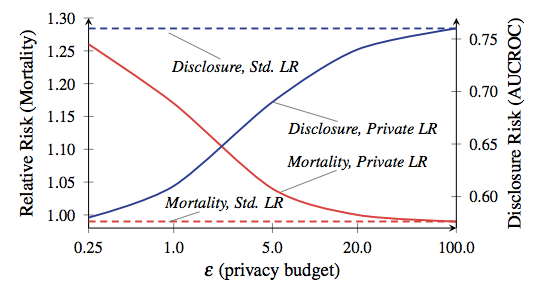
The ratio of mortality and disclosure, from the work of Frederickson et al from 2014 . The red line corresponds to the mortality of patients.
To give you an absolutely crazy example of how important a compromise between privacy and accuracy can be, take a look at this scientific work by Frederickson et al. From 2014 . The authors began by associating data on the dosages of drugs from the Warfarin open database with specific genetic markers. Then they applied machine learning techniques to develop a model for calculating dosages based on data from the database - but applied DP with different parameters of the privacy budget during the model training. They then assessed the level of information leakage and the success of using the model for treating virtual “patients”.
The results showed that the accuracy of the model strongly depends on the privacy budget established during its training. If the budget is set too high, a significant amount of confidential patient information is leaked from the database - but the resulting model makes dosage decisions as safe as standard clinical practice. On the other hand, when the budget is reduced to a level meaning acceptable privacy, the model trained on noisy data tends to kill its “patients”.
Before you start to panic, let me explain: your iPhone is not going to kill you . No one says that this example is even remotely similar to what Apple is going to do on smartphones. The conclusion from this study is simply that there is an interesting trade-off between efficiency and privacy protection in each DP-based system — this trade-off largely depends on the specific decisions that the system designers made, the chosen operating parameters, etc. let's hope that Apple will soon tell us what these options were.
In any case, how to collect data?
You noticed that in all the examples above, I assumed that the queries are made by a trusted database operator who has access to all the raw raw underlying data. I chose this model because it is a traditional version of the model that is used in almost all the literature, and not because it is a good idea.
In fact, there will be grounds for alarm if Apple really implements its system in this way. This will require Apple to collect all the source information about user actions into a massive centralized database, and then (“trust us!”) Calculate statistics on it in a secure way, protecting users' privacy. At a minimum, this method makes information available for obtaining on subpoenas, as well as for foreign hackers, curious top-managers of Apple and so on.
Fortunately, this is not the only way to implement a system of differential privacy. Theoretically, statistics can be computed using fancy cryptographic techniques (such as the confidential calculation protocol or fully homomorphic encryption ). Unfortunately, these techniques are probably too inefficient for use on the scale Apple needs.
A much more promising approach seems to be not to collect “raw” data at all . This approach was recently the first among all used by Google to collect statistics in the Chrome browser . Their system, called RAPPOR, is based on the implementation of a 50-year-old randomized response technique. The randomized response works as follows:
- When a user wants to send a piece of potentially sensitive information (an example invented: the answer to the question “Are you using Bing?”), They first flip a coin, and if the coin falls out as an “eagle”, then a random answer is returned - calculated by flip of another coin. Otherwise, an honest response is sent.
- The server collects responses from the entire sample of users and (knowing the probability with which the coin drops out "eagle"), adjusts to the existing level of "noise" to calculate an approximate answer for a truthful response.
On an intuitive level, a randomized response protects the privacy of individual user reports, because the answer “yes” may mean either “Yes, I use Bing”, or simply be the result of a random coin falling. At the formal level, a randomized response does provide differentiated privacy , with specific guarantees that can be customized by adjusting the characteristics of the coins.
RAPPOR takes this relatively old technique and turns it into something much more powerful. Instead of a simple answer to one question, the system can generate a report on a complex vector of questions and even return complex answers, such as strings — for example, what is your home page in the browser. The latter is achieved so that the string is first passed through the Bloom filter , a sequence of bits generated using hash functions in a very specific way. The received bits are then mixed with noise and summed, and the responses are restored using the (content complex) decoding process.
 Although there is no clear evidence that Apple is using a system like RAPPOR, a few small hints indicate this. For example, Craig Federigi (Craig Federighi, in life he looks exactly like in the photo) describes differentiated privacy as "using hashing, sub-sampling and noise to activate ... crowdsourcing training while keeping individual users' data completely private . " This is a rather weak proof of anything, probably, but the presence of “hashing” in this quotation at least suggests the use of RAPPOR filters.
Although there is no clear evidence that Apple is using a system like RAPPOR, a few small hints indicate this. For example, Craig Federigi (Craig Federighi, in life he looks exactly like in the photo) describes differentiated privacy as "using hashing, sub-sampling and noise to activate ... crowdsourcing training while keeping individual users' data completely private . " This is a rather weak proof of anything, probably, but the presence of “hashing” in this quotation at least suggests the use of RAPPOR filters.The main difficulty with randomized response systems is that they can produce sensitive data if the user answers the same question several times. RAPPOR tries to solve this problem in several ways. One of them is to determine the static part of the information and so calculate the “permanent answer” instead of re-randomizing it each time. But it is possible to imagine situations where such protection does not work. Once again, the devil very often hides in the details - you just need to see them. I am sure a lot of exciting scientific papers will be published anyway.
So is Apple's use of DP by the company good or bad?
As a scientist and information security specialist, I have mixed feelings about this. On the one hand, as a scientist, I understand how interesting it is to observe the implementation of advanced scientific developments in a real product. And Apple provides a very large platform for such experiments.
On the other hand, as a practical security specialist, my duty is to maintain skepticism - the company should show the code that is crucial for security (as Google did with RAPPOR ) at the slightest questions, or at least frankly state what it implements. If Apple plans to collect massive amounts of new data from the devices on which we depend so much, then we need to be really sure that they are doing everything right - and not applauding them vigorously for the implementation of such cool ideas. (I have already made such a mistake once, and still feel like a fool because of this).
But perhaps all this is too deep details. In the end, it definitely looks like Apple is honestly trying to do something to protect the confidential information of users , and given the alternatives, this may be the most important thing.
Source: https://habr.com/ru/post/395313/
All Articles