Features of using and testing C ++ code on microcontrollers
 It so happened that the main language for working with microcontrollers is C. Many large projects are written on it. But life does not stand still. Modern development tools have long allowed the use of C ++ in the development of software for embedded systems. However, this approach is still quite rare. Not so long ago, I tried to use C ++ when working on the next project. I will tell you about this experience in this article.
It so happened that the main language for working with microcontrollers is C. Many large projects are written on it. But life does not stand still. Modern development tools have long allowed the use of C ++ in the development of software for embedded systems. However, this approach is still quite rare. Not so long ago, I tried to use C ++ when working on the next project. I will tell you about this experience in this article.Introduction
')
Most of my work with microcontrollers is associated with C. At first, this was customer requirements, and then it became just a habit. At the same time, when it came to applications for Windows, C ++ was used there first, and then C # in general.
There have been no questions about C or C ++ for a long time. Even the release of the next version of Keil's MDK from Cilar C ++ for ARM didn't bother me too much. If you look at Keil demo projects, everything is written in C. At that, C ++ is moved to a separate folder along with Blinky-project. CMSIS and LPCOpen are also written in C. And if “everyone” uses C, then there are some reasons.
But a lot has changed. Net Micro Framework. If anyone does not know, then this is the implementation of .Net that allows you to write applications for C # microcontrollers in Visual Studio. More details on him can be found in these articles.
So, .Net Micro Framework is written using C ++. Impressed by this, I decided to try to write another C ++ project. I’ll say right away that I haven’t found any clear arguments in favor of C ++, but there are some interesting and useful points in this approach.
What is the difference between C and C ++ projects?
One of the biggest differences between C and C ++ is that the second is an object-oriented language. Well-known encapsulation, polymorphism and inheritance are commonplace here. C is a procedural language. There are only functions and procedures, and modules are used for the logical grouping of the code (pair .h + .c). But if you look at how C is used in microcontrollers, you can see the usual object-oriented approach.
Let's look at the code for working with LEDs from the Keil example for MCB1000 ( Keil_v5 \ ARM \ Boards \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo ):
LED.h:
#ifndef __LED_H #define __LED_H /* LED Definitions */ #define LED_NUM 8 /* Number of user LEDs */ extern void LED_init(void); extern void LED_on (uint8_t led); extern void LED_off (uint8_t led); extern void LED_out (uint8_t led); #endif LED.c:
#include "LPC11xx.h" /* LPC11xx definitions */ #include "LED.h" const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3, 1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 }; /*---------------------------------------------------------------------------- initialize LED Pins *----------------------------------------------------------------------------*/ void LED_init (void) { LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6); /* enable clock for GPIO */ /* configure GPIO as output */ LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] | led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] ); LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] | led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] ); } /*---------------------------------------------------------------------------- Function that turns on requested LED *----------------------------------------------------------------------------*/ void LED_on (uint8_t num) { LPC_GPIO2->DATA |= led_mask[num]; } /*---------------------------------------------------------------------------- Function that turns off requested LED *----------------------------------------------------------------------------*/ void LED_off (uint8_t num) { LPC_GPIO2->DATA &= ~led_mask[num]; } /*---------------------------------------------------------------------------- Output value to LEDs *----------------------------------------------------------------------------*/ void LED_out(uint8_t value) { int i; for (i = 0; i < LED_NUM; i++) { if (value & (1<<i)) { LED_on (i); } else { LED_off(i); } } } If you look closely, you can bring an analogy with the PLO. LED is an object with one public constant, constructor, 3 public methods and one private field:
class LED { private: const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3, 1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 }; public: unsigned char LED_NUM=8; public: LED(); // LED_init void on (uint8_t led); void off (uint8_t led); void out (uint8_t led); } Despite the fact that the code is written in C, it uses the paradigm of object programming. The .C file is an object that allows you to encapsulate the mechanisms for implementing public methods inside, described in the .h file. That's just not inheritance here, so polymorphism too.
Most of the code in the projects that I met was written in the same style. And if the PLO approach is used, why not use a language that fully supports it? At the same time, when switching to C ++, by and large, only the syntax will change, but not the design principles.
Consider another example. Suppose we have a device that uses a temperature sensor connected via I2C. But a new revision of the device came out and the same sensor is now connected to SPI. What to do? It is necessary to support the first and second revisions of the device, which means that the code must flexibly take into account these changes. In C, you can use the predefinement #define to avoid writing two almost identical files. for example
#ifdef REV1 #include “i2c.h” #endif #ifdef REV2 #include “spi.h” #endif void TEMPERATURE_init() { #ifdef REV1 I2C_int() #endif #ifdef REV2 SPI_int() #endif } and so on.
In C ++ you can solve this problem a little more elegantly. Make an interface
class ITemperature { public: virtual unsigned char GetValue() = 0; } and make 2 implementations
class Temperature_I2C: public ITemperature { public: virtual unsigned char GetValue(); } class Temperature_SPI: public ITemperature { public: virtual unsigned char GetValue(); } And then use this or that implementation depending on the revision:
class TemperatureGetter { private: ITemperature* _temperature; pubic: Init(ITemperature* temperature) { _temperature = temperature; } private: void GetTemperature() { _temperature->GetValue(); } #ifdef REV1 Temperature_I2C temperature; #endif #ifdef REV2 Temperature_SPI temperature; #endif TemperatureGetter tGetter; void main() { tGetter.Init(&temperature); } It seems that the difference is not very big between the code in C and C ++. The object-oriented version looks even more cumbersome. But it allows you to make a more flexible solution.
When using C, there are two main solutions:
- Use #define as shown above. This option is not very good because it “blurs” the responsibility of the module. It turns out that he is responsible for several revisions of the project. When there are many such files, it becomes rather difficult to maintain them.
- Make 2 modules, just like with C ++. There is no “blurring” here, but the use of these modules is complicated. Since they do not have a single interface, the use of each method from this pair must be framed in #ifdef. This impairs readability and, therefore, maintainability of the code. And the higher the abstraction will need to raise the place of separation, the more cumbersome the code will turn out. At the same time, it is necessary to think over the names of functions for each module so that they do not overlap, which is also fraught with a deterioration in the readability of the code.
Using polymorphism gives a more beautiful result. On the one hand, each class solves a clear atomic problem, on the other hand, the code is not littered and easy to read.
“Branching” the code on the revision will still have to be done in the first and second cases, but the use of polymorphism makes it easier to transfer the branching location between program layers, without overloading the code with unnecessary #ifdef.
Using polymorphism makes it even easier to make an even more interesting decision.
Suppose there was a new revision, in which there are both temperature sensors.
The same code with minimal changes allows you to choose your SPI and I2C implementation in real time, simply using the Init (& temperature) method.
The example is very simplified, but in a real project I used the same approach to implement the same protocol across two different physical data transfer interfaces. This made it easy to make the choice of the interface in the device settings.
However, with all the above, the difference between using C and C ++ is not very big. The advantages of C ++ related to OOP are not so obvious and are from the category of “an amateur”. But using C ++ in microcontrollers has quite serious problems.
What is dangerous about using C ++?
The second important difference between C and C ++ is memory usage. C language is mostly static. All functions and procedures have fixed addresses, and the work with the heap is carried out only when necessary. C ++ is a more dynamic language. Usually its use implies active work with the allocation and release of memory. This is C ++ and dangerous. There are very few resources in microcontrollers, so control over them is important. Uncontrolled use of RAM is fraught with damage to the data stored there and such "miracles" in the program that does not seem to anyone. Many developers faced such problems.
If you take a closer look at the examples above, it can be noted that classes do not have constructors and destructors. This is done because they are never dynamically created.
When using dynamic memory (and when using new), the malloc function is always called, which allocates the required number of bytes from the heap. Even if you think over everything (although it is very difficult) and will control the use of memory, you may face the problem of its fragmentation.
Pile can be represented as an array. For example, select 20 bytes for it:

Each time memory is allocated, the entire memory is viewed (from left to right or from right to left - this is not so important) for the presence of a specified number of unallocated bytes. And these bytes should all be located next:
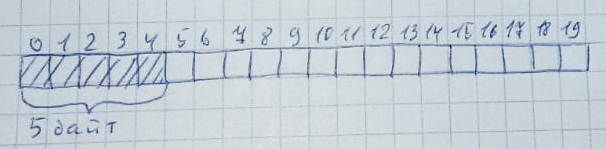
When memory is no longer needed, it returns to its original state:
It is very easy for this to happen when there are enough free bytes, but they are not located in a row. Let 10 zones with 2 bytes each be allocated:
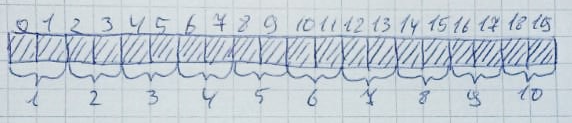
Then 2,4,6,8,10 zones will be released:
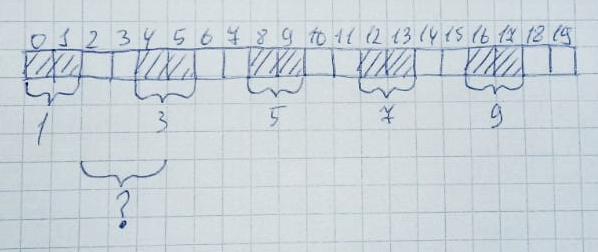
Formally, half of the entire heap remains free (10 bytes). However, it is still impossible to allocate a memory area of 3 bytes in size, since there are no 3 free cells in a row in the array. This is called memory fragmentation.
And to deal with this on systems without memory virtualization is quite difficult. Especially in large projects.
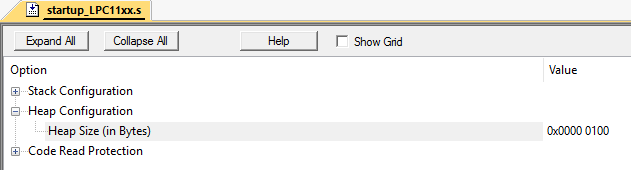
This situation can be easily emulated. I did this in Keil mVision on an LPC11C24 microcontroller.
Set the heap size to 256 bytes:
Suppose we have 2 classes:
#include <stdint.h> class foo { private: int32_t _pr1; int32_t _pr2; int32_t _pr3; int32_t _pr4; int32_t _pb1; int32_t _pb2; int32_t _pb3; int32_t _pb4; int32_t _pc1; int32_t _pc2; int32_t _pc3; int32_t _pc4; public: foo() { _pr1 = 100; _pr2 = 200; _pr3 = 300; _pr4 = 400; _pb1 = 100; _pb2 = 200; _pb3 = 300; _pb4 = 400; _pc1 = 100; _pc2 = 200; _pc3 = 300; _pc4 = 400; } ~foo(){}; int32_t F1(int32_t a) { return _pr1*a; }; int32_t F2(int32_t a) { return _pr1/a; }; int32_t F3(int32_t a) { return _pr1+a; }; int32_t F4(int32_t a) { return _pr1-a; }; }; class bar { private: int32_t _pr1; int8_t _pr2; public: bar() { _pr1 = 100; _pr2 = 10; } ~bar() {}; int32_t F1(int32_t a) { return _pr2/a; } int16_t F2(int32_t a) { return _pr2*a; } }; As you can see, the bar class will occupy more memory than foo.
14 instances of the class bar are placed in a heap and the instance of the class foo does not fit:
int main(void) { foo *f; bar *b[14]; b[0] = new bar(); b[1] = new bar(); b[2] = new bar(); b[3] = new bar(); b[4] = new bar(); b[5] = new bar(); b[6] = new bar(); b[7] = new bar(); b[8] = new bar(); b[9] = new bar(); b[10] = new bar(); b[11] = new bar(); b[12] = new bar(); b[13] = new bar(); f = new foo(); } If you create only 7 bar instances, then foo will also be created normally:
int main(void) { foo *f; bar *b[14]; //b[0] = new bar(); b[1] = new bar(); //b[2] = new bar(); b[3] = new bar(); //b[4] = new bar(); b[5] = new bar(); //b[6] = new bar(); b[7] = new bar(); //b[8] = new bar(); b[9] = new bar(); //b[10] = new bar(); b[11] = new bar(); //b[12] = new bar(); b[13] = new bar(); f = new foo(); } However, if you first create 14 instances of bar, then delete 0,2,4,6,8,10 and 12 instances, then memory cannot be allocated for foo because of heap fragmentation:
int main(void) { foo *f; bar *b[14]; b[0] = new bar(); b[1] = new bar(); b[2] = new bar(); b[3] = new bar(); b[4] = new bar(); b[5] = new bar(); b[6] = new bar(); b[7] = new bar(); b[8] = new bar(); b[9] = new bar(); b[10] = new bar(); b[11] = new bar(); b[12] = new bar(); b[13] = new bar(); delete b[0]; delete b[2]; delete b[4]; delete b[6]; delete b[8]; delete b[10]; delete b[12]; f = new foo(); } It turns out that you cannot fully use C ++, and this is a significant minus. From an architectural point of view, C ++, although superior to C, is insignificant. As a result, the transition to C ++ does not bring significant benefits (although there are no large negative points either). Thus, due to the small difference, the choice of language will remain just the personal preference of the developer.
But for myself I found one significant positive point in using C ++. The fact is that with the right approach, C ++ code for microcontrollers can be fairly easily covered by unit tests in Visual Studio.
A big plus of C ++ is the ability to use Visual Studio.
For me personally, the topic of testing code for microcontrollers has always been quite complicated. Naturally, the code was checked in various ways, but the creation of a full-fledged automatic testing system always required huge costs, since it was necessary to assemble a hardware stand and write a special firmware for it. Especially when it comes to a distributed IoT system consisting of hundreds of devices.
When I started writing a project in C ++, I immediately wanted to try to shove the code in Visual Studio and use Keil mVision only for debugging. Firstly, Visual Studio has a very powerful and convenient code editor, and secondly, Keil mVision doesn’t have a convenient integration with version control systems, and in Visual Studio it’s all worked out to automatism. Thirdly, I had a hope that at least part of the code will succeed in covering with unit tests, which are also well supported in Visual Studio. And fourthly, this is the appearance of Resharper C ++, a Visual Studio extension for working with C ++ code, thanks to which many potential errors can be avoided in advance and the code style can be monitored.
Creating a project in Visual Studio and connecting it to the version control system did not cause any problems. But with the unit tests had to tinker.
Classes that are abstracted from the hardware (for example, protocol parsers) were rather easily tested. But I wanted more! In my projects for working with peripherals, I use Keil header files. For example, for LPC11C24, this is LPC11xx.h. These files describe all the necessary registers in accordance with the CMSIS standard. Directly the definition of a specific register is made via #define:
#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000) #define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE ) It turned out that if you correctly redefine the registers and make a couple of stubs, then the code that uses the peripherals can be compiled into VisualStudio. Moreover, if you make a static class and specify its fields as addresses of registers, you get a full-fledged microcontroller emulator, which allows you to fully test even work with peripherals:
#include <LPC11xx.h> class LPC11C24Emulator { public: static class Registers { public: static LPC_ADC_TypeDef ADC; public: static void Init() { memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef)); } }; } #undef LPC_ADC #define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC) And then do this:
#if defined ( _M_IX86 ) #include "..\Emulator\LPC11C24Emulator.h" #else #include <LPC11xx.h> #endif Thus, it is possible to compile and test all the project code for microcontrollers in VisualStudio with minimal changes.
In the process of developing a project in C ++, I wrote over 300 tests covering both purely hardware aspects and code abstracted from hardware. In this case, about 20 rather serious errors were found in advance, which, due to the size of the project, it would not be easy to detect without automatic testing.
findings
To use or not to use C ++ when working with microcontrollers is a rather complicated question. Above, I showed that, on the one hand, the architectural advantages of a full-fledged OOP are not so great, and the impossibility of full-fledged work with a bunch is quite a big problem. Given these aspects, there is not much difference between C and C ++ for working with microcontrollers, the choice between them may well be justified by the personal preferences of the developer.
However, I managed to find a big positive moment of using C ++ in working with Visaul Studio. This allows you to significantly increase the reliability of development due to the full-fledged work with version control systems, the use of full-fledged unit tests (including peripheral tests) and other benefits of Visual Studio.
I hope my experience will be useful and will help someone to improve the efficiency of their work.
Update :
In the comments to the English version of this article gave useful links on this topic:
- Meeting C ++ 2015 Lightning Talks: Odin Holmes - special function register abstraction www.youtube.com/watch?v=AKAYc9ZFBhk
- Meeting C ++ 2015: John Hinke - Deeply embedded C ++ www.youtube.com/watch?v=TYqbgvHfxjM
- Meeting C ++ 2014: Wouter van Ooijen - Objects? No thanks. www.youtube.com/watch?v=k8sRQMx2qUw
Source: https://habr.com/ru/post/390837/
All Articles