Some algorithms under the hood of the brain
 Some time ago I wanted to study modern materials on neuroscience from the point of view of a programmer. That is, to pull out of them the basic algorithms, clearing them from unnecessary chemical / biological details.
Some time ago I wanted to study modern materials on neuroscience from the point of view of a programmer. That is, to pull out of them the basic algorithms, clearing them from unnecessary chemical / biological details.So, if someone loves artificial neural networks and wants to look for inspiration in the natural, this article may be suitable. Obviously, it was not possible to cover everything with one article - there are already a lot of data.
First, a brief description of the work of the bio-neuron, so that the further is clear. Who already knows the basics - feel free to skip.
Biological neuron: catfish, dendrites, synapses, spike, EPSP, membrane potential
The neuron consists of three parts: the soma (that is, the body), the axon with its branches, and the dendritic tree. It is a tree where one branch can grow from another, and so on. The input signal is received on the dendritic tree and the soma. Output - sent to the axon. The junction of one neuron with another is called a synapse. Neurons communicate through synapses. Communication through the synapse unidirectional.
')
So it turned out that inside the neuron electrolyte, and outside too. The ion concentrations in them are different, and therefore a potential difference arises on the neuron membrane. It is also referred to in the literature as “membrane potential”, “voltage” or simply “U”. Scientists quickly learned to measure it with electrodes and found that it lives an eventful life. The highlight is the spike . It looks like a pulse on the U chart.
The decision to generate a spike is made in the place on the soma from where the axon grows. The decision is made when U on the soma reaches the threshold value. An input message from one neuron to another is a set of chemicals. It can be different. When a neuron generates a spike into its axon, the axon throws these substances into synapses, and they are caught by the receiving neurons in these synapses. When these chemicals are caught by the receiving neuron, they trigger a chain of events on its membrane, and in this place a local potential perturbation forms on it. It can be either with a “+” sign and called EPSP (excitatory). Or with the sign “-” and called IPSP (brake).
Further, this disturbance spreads through the dendritic tree and reaches the soma. There, the EPSPs and IPSPs are added up with a sign, and if the threshold is reached, a spike is generated. If not achieved, then everything just fades away.
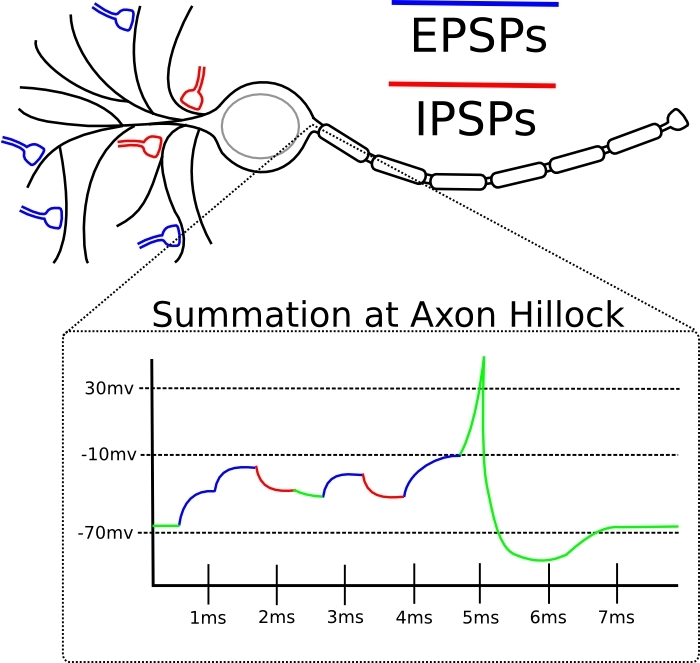
In principle, any disturbances traveling along the membrane are damped out like waves on the water. Unless the membrane generates a spike to reinforce this disturbance. Not only soma can generate spikes, but dendrites too. This happens, for example, when several synapses on this dendrite were simultaneously activated. Then the dendrite membrane generates a local spike. If the dendrites did not know how to generate spikes, from the distant dendrites the EPSP would not reach the soma, fading along the way.
The effectiveness of the synapse is different in magnitude. In response to the same incoming chemical message, there may be either a small amplitude voltage perturbation on the membrane, or a larger one. This is equivalent to the notion of “synapse weight” from artificial neural networks. This is exactly the parameter to be trained. The difference from an artificial neuron here is that the summation of disturbances on a neuron occurs not only in space, but also in time (see picture).
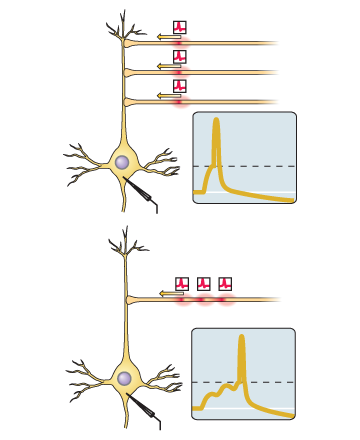
The spike here is a sharp peak. The dotted line is the threshold voltage of the membrane for soma. At the bottom of the picture, the EPSP is subliminal “mounds”. Two, as we see, was not enough, but the third brought the potential to the threshold. If the same three EPSPs (from any picture) came with a big time difference, then there would be no spike, since their effect on soma would fade out in time, and effective summation would not occur.
')
So it turned out that inside the neuron electrolyte, and outside too. The ion concentrations in them are different, and therefore a potential difference arises on the neuron membrane. It is also referred to in the literature as “membrane potential”, “voltage” or simply “U”. Scientists quickly learned to measure it with electrodes and found that it lives an eventful life. The highlight is the spike . It looks like a pulse on the U chart.
The decision to generate a spike is made in the place on the soma from where the axon grows. The decision is made when U on the soma reaches the threshold value. An input message from one neuron to another is a set of chemicals. It can be different. When a neuron generates a spike into its axon, the axon throws these substances into synapses, and they are caught by the receiving neurons in these synapses. When these chemicals are caught by the receiving neuron, they trigger a chain of events on its membrane, and in this place a local potential perturbation forms on it. It can be either with a “+” sign and called EPSP (excitatory). Or with the sign “-” and called IPSP (brake).
Further, this disturbance spreads through the dendritic tree and reaches the soma. There, the EPSPs and IPSPs are added up with a sign, and if the threshold is reached, a spike is generated. If not achieved, then everything just fades away.
In principle, any disturbances traveling along the membrane are damped out like waves on the water. Unless the membrane generates a spike to reinforce this disturbance. Not only soma can generate spikes, but dendrites too. This happens, for example, when several synapses on this dendrite were simultaneously activated. Then the dendrite membrane generates a local spike. If the dendrites did not know how to generate spikes, from the distant dendrites the EPSP would not reach the soma, fading along the way.
The effectiveness of the synapse is different in magnitude. In response to the same incoming chemical message, there may be either a small amplitude voltage perturbation on the membrane, or a larger one. This is equivalent to the notion of “synapse weight” from artificial neural networks. This is exactly the parameter to be trained. The difference from an artificial neuron here is that the summation of disturbances on a neuron occurs not only in space, but also in time (see picture).
The spike here is a sharp peak. The dotted line is the threshold voltage of the membrane for soma. At the bottom of the picture, the EPSP is subliminal “mounds”. Two, as we see, was not enough, but the third brought the potential to the threshold. If the same three EPSPs (from any picture) came with a big time difference, then there would be no spike, since their effect on soma would fade out in time, and effective summation would not occur.
STDP
It is assumed that the basis of long-term memory is how efficiency is distributed across the neuron synapses. Some synapses are weakened, some are strengthened. This is called plasticity. But what algorithm is used to decide which synapses and how they will change weights? The most famous principle in live neural networks is Spike-timing-dependent plasticity .
It is observed from insects to humans and is formulated as follows:
If the input spike at this synapse tends to come just before the neuron itself generates the spike, then the synapse is amplified.
If the input spike at this synapse tends to come immediately after the spike generation by the neuron itself, then the synapse is weakened.
Those entrances that are attributable to the spike are made more important in the future, and those that are not contributing to it are less. The process continues until a certain subset of the original weights remain, and the rest will be reduced to zero. We take into account the fact that a neuron generates a spike, when many of its inputs are activated at once in a short time window. From this we can assume that the remaining non-zero inputs had correlations in time.
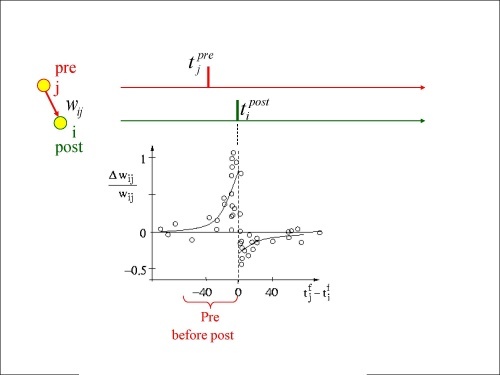
Dependence of the increase / decrease in the weight of the synapse on the Δt honey input (pre) and output (post) spike
This phenomenon is very well known and confirmed in many experiments, but it should be noted that by going through different experimental protocols, you can still achieve distortion / violation of this law, without violating the formal requirements for pre-post spikes [0] .
Spike back distribution
The pyramidal neuron (perhaps the most well-known type of cortex neurons) has thousands of synapses, with which its dendritic tree is strewn (in fact, it has two dendritic trees). If we choose several synapses - close to the soma, far away, and very far from it - and see what kind of STDP charts are obtained for them, then the charts will be different.
For synapses close to a soma, the graph will look classically - as a variation on Hebbian learning. That is, as in the picture above. The farther away from the soma, the smaller the amplitude of this training. And if you take distant synapses, then you can see very strange things. For example, if the input spike (which came to the synapse) preceded the holiday, then in the experiment it was observed not the strengthening, but the weakening of this synapse. Anti-hebbie training, Karl! However, he was able to return to the Hebbov channel if dendritic spikes were generated on far dendrites. In general, with the training of synapses closest to the soma, everything is quite clear, and at distant it looks as if there is a
Let's see where their legs grow from. So, for the STDP iteration, it is necessary that a spike be generated in the soma. After that, synapses should quickly find out about it. To do this, it is desirable that the spike spread to them from the axonal mound. The good news is that it does. A neuron sends a spike not only to other neurons, but also back to its dendrites. The “bad” news is that during the back distribution, this spike fades out. Too fast to reach distant dendrites. Now it is clear why learning near and far synapses differs. It remains to figure out what is happening in distant synapses.
Here it is important to remember that dendrites are not passive conductors of disturbances. They themselves are able to generate spikes when they "consider it necessary." If for some reason the dendrite generated the spike, and at the same time a damped spike from the soma came to this zone, then, having formed with the dendritic spike, it (maybe) would get
Interesting effects in dendrites - for plasticity enough dendritic spikes
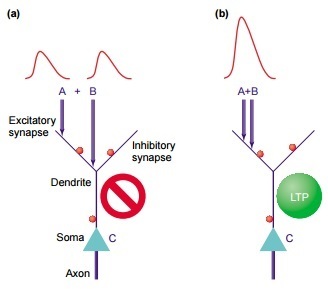
So, what do you really need for the synapse to increase in weight? It is necessary that in this place of the neuron the appropriate chemical machinery is involved. For this, in turn, it is necessary that the potential on the membrane in this place be shifted by some sufficiently large perturbation . How can it be created? The usual average EPSP is too small for this. But the sum of the EPSP and the backward propagating somatic spike may already be appropriate. For some time it was believed that this is the main way to cause plasticity.
Then in experiments it turned out that it is possible to artificially suppress somatic spikes in a neuron and still register an increase in weights in its synapses in response to their stimulation (not any). It turned out that plasticity occurs when synapse stimulation is strong enough for dendritic spikes to occur in this place. They are a strong enough disturbance to trigger plasticity in this place. [2] Yes, yes, without the participation of the rest of the neuron. That is, the “minimal element” of information processing can be considered not even a neuron, but a separate dendritic branch.
Interesting effects in dendrites - clustering
In the hippocampal neurons, it was found that LTP (long-term weight gain) of one synapse reduces the threshold for the occurrence of LTP on adjacent synapses. Then, a study was conducted for mouse sensory cortex neurons, in which neurons processed data from whiskers. And it was found that synaptic plasticity has a tendency to clustering.
A specific neuron was taken, and 15% of the synapses that were most intensively subjected to plasticity were selected. Their distribution along the neuron was not accidental: a significant part turned out to be neighbors - 50 out of 161. Then the neuron was taken from the sensory cortex of the mouse from which the whiskers were cut off (that is, the neuron suffered from a lack of information). The effect of clustering in such a neuron was absent. But he was globally more sensitive to input signals [3] .
Interesting effects in dendrites - everything changes from the rearrangement of the components
So, let two EPSPs come to us on the dendrite, as in the picture above. The disturbance they cause in soma depends not only on the size of these EPSPs, but also on:
1) their distance to soma
2) their distances from each other
Consider in order. If an EPSP has come from the synapse to the dendrite, then it will spread to the soma and fade along the way. That is, the further it was, the more it would die out. And if on his way an activated brake synapse gets caught, the EPSP will immediately stop. Thus, if we had two fairly distant EPSPs, they would bring two small disturbances to the soma - and that if they were lucky.
But if they are next to each other, then dedritis can generate a spike in this place. This is a disturbance whose amplitude is greater than just the sum of the EPSPs. The dendritic spike is much more likely to run to the soma, and the contribution will be greater. [4] .
Linking sync features
(synchronization encodes relation, feature binding)
From the preceding paragraphs it follows that the relative timing of the spikes is important for the plasticity processes in the synapses. And in this light, the time synchronization of neurons cannot be circumvented. This phenomenon is omnipresent and, apparently, very fundamental, since is at all levels of the brain. Consider a specific example.
Electrodes are implanted into the kitten in the visual cortex, and then show him different visual stimuli. The records from the electrodes show that some groups of neurons are involved in oscillatory activity synchronous in phase. These neurons can be in different places. Neurons tend to synchronize if they are activated by contours in the image that are either continuous or move at the same speed and in the same direction (the principle of a common fate). For the visual cortex, the likelihood of synchronization correlates with the extent to which input stimuli satisfy the Gestalt criterion .

All the green points here are not perceived separately, but as a whole.
The working hypothesis assumes that the cortex uses the synchronization of discharges in neurons to encode the “one-piece” relationship about those signal regions to which these neurons respond. Those. then their answers will be processed as a single whole by the upstream neural networks, because it is these adherents that will come there simultaneously, which means that I will add up without failing to fade.
Synchronization of activity in the cortex over long distances is a prerequisite to ensure that the signal that caused this activity (for example, the word seen) gains access to the zone of conscious perception. A similar signal, when processed unconsciously, will cause only local synchronization [5] .
How neuron populations synchronize is the subject of investigation [6] .
Non-synaptic plasticity
In addition to the weights of synapses, other characteristics of the neuron may also be altered during training. Its overall excitability may change (read, threshold for spike generation). If many scales are strengthened, then it makes sense for the neuron to lower its excitability. And if on the contrary - a low level of change in the scales, it makes sense to increase.
Another example is that an axon can change the time it takes for the spike to reach its recipients. Still - if for a long time to stimulate a neuron at a low frequency, it reduces its excitability, and this is a long-term effect.
Replay
In the hippocampus, there are neurons that respond to a specific place in space. Called cells of the place . That is, if a rat is in one place of the maze, then one cell of the place reacts as much as possible, if in the other - the other. When a rat is sleeping or resting, in the hippocampus those sequences of the cells of the place that correspond to the routes actually passed before begin to play at an accelerated pace. For the remaining cells of the place of this is not observed, that is, these sequences are not random.
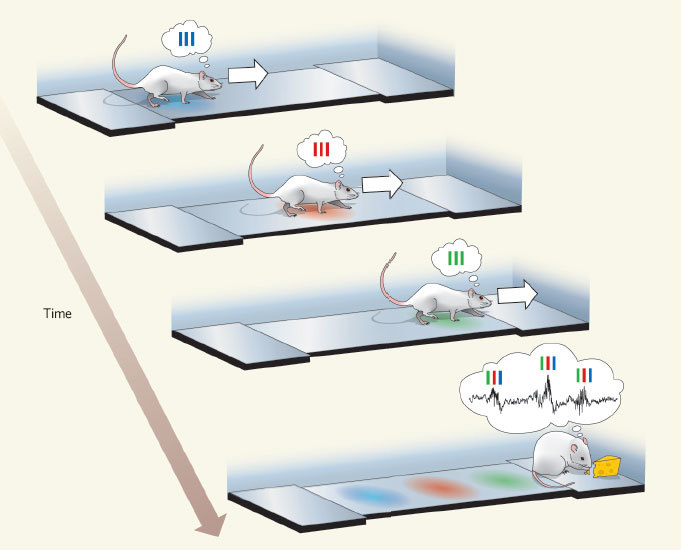
In the picture: the rat goes on a straight track, and first the “blue” cell of the place is activated, then the “red” one and then the “green” one. Then she gets reinforcements, and the accelerated play of this sequence begins in the reverse order of “blue red green”.
In addition, the hippocampus can play future places before the rat actually visits (preplay).
No less interesting - the process of replay in a dream also affects the cerebral cortex. That is, at the same time in the cortex and in the hippocampus, what is connected with one and the same experience experienced during the previous wakefulness [7] is replicated. There is a hypothesis that the hippocampus is a module of quick memorization, and the core is of slow deep learning. It is possible that the hippocampus memorizes the events-episodes in the order in which they are followed, and then “loses” them bark over and over again at an accelerated pace so that it pulls out the hidden patterns from these sequences. Then it is clear why a patient with a remote hippocampus loses the ability to create new long-term memories, but does not lose those that were made before the operation.
L-LTP (late-phase LTP )
The longevity of changes in the weights of synapses depends not only on the initial stimulus that caused them, but also on the events that occur before and after that. Experiments show that a short-term memory of a stimulus can be consolidated into a longer one if the animal survives a strong event within a certain time window around this stimulus. This is recorded at the level of individual neurons. Let some stimulation protocol succeed in causing a short-term synapse enhancement. It can be made long-term, if a strong stimulus (tetanically) is excited by some other path converging on the same neuron (inside the correct time window, of course).
Lateral braking
(lateral inhibition, surround inhibition, surround suppression)
This simple principle is known to scientists from cave times. You may have seen illusions like this:

At the dawn of neuroscience, it was believed that a neuron was looking for a stimulus in its receptive field, and if the desired stimulus was found there, then the neuron intensively generates spikes. If there was not quite that, but it looks like it also generates spikes, but not so intensely. And then it turned out that the activity of the neuron can be suppressed by activities from outside its receptive field .
In addition to the excitatory network (which is also the main one), there is another in the brain - a network of inhibitory interneurons. “Major” neurons provide excitation in the network, and interneurons tend to inhibit it. Interneurons have a local domain of action. There are more main neurons than interneurons, but interneurons are more diverse. The specifically mentioned visual illusion is supposedly taken due to the interaction of excitatory neurons with inhibitory ones. The process logic is this: the more a neuron is activated, the more it slows down (using interneurons) the activity in the neighborhood. Excitatory neurons compete with each other for the right to make the greatest contribution to the signal for the next layer of neurons. If you have been strongly activated, then you will severely slow down your neighbors. If the neighbors were weakly activated, then they will slow you down. As a result, all nonlinearities in the input data will “bulge out” even more, and the next layer will work with this.
A very clear illustration of the principle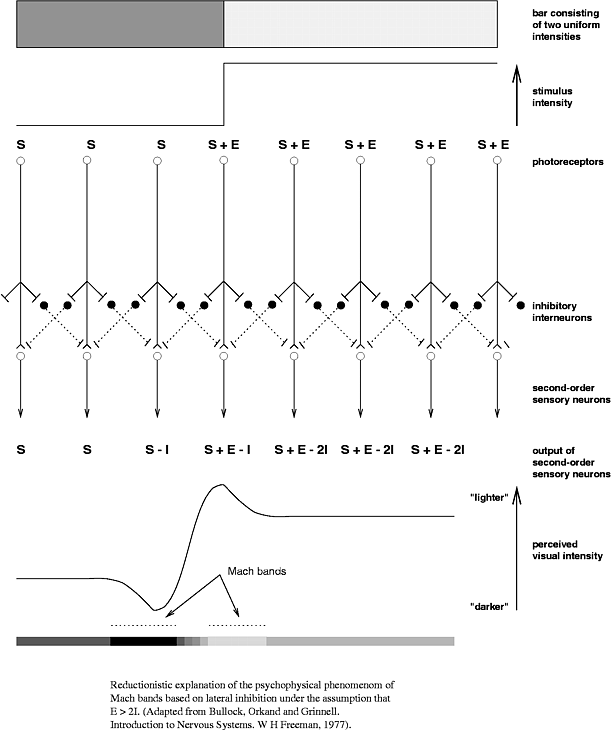
Something is observed in the retina. The real connection is not so simple, of course, but the fundamental principle of lateral inhibition is there.
Something is observed in the retina. The real connection is not so simple, of course, but the fundamental principle of lateral inhibition is there.
Prediction Error Detectors [8]
Dopamine neurons learn to associate some “keys” in the input signal with receiving an award. The following algorithm is used:
(1) If an unpredicted reward occurred, then the neurons respond by increasing the frequency of the spikes ( we have a positive error ).
(2) After training, they are already responding to a “key event,” and not to the award itself. Those. On the predecessor of the award, they give an increase in frequency. And the reward, if it comes on schedule, no longer has a reaction ( we have no error ).
(3) If a trained neuron predicted a reward, but it did not happen - it responds by decreasing the frequency of spikes ( we have a negative error )
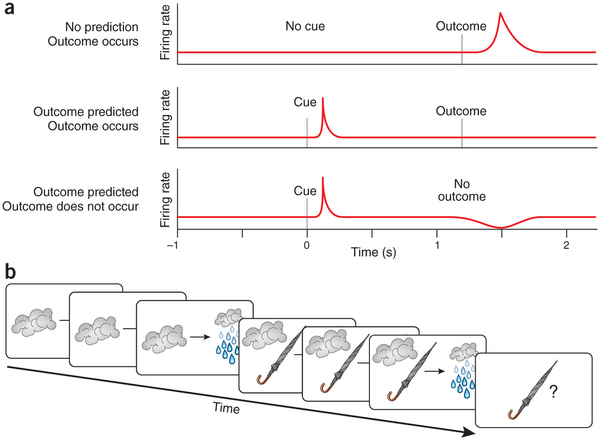
There is an opinion that there is not just associative learning, but the establishment of a “cause – effect” relationship. That is, for example, thunderclouds correlate with rain, because it often happens that way - you see clouds, and then you see rain. The same thing happens with an umbrella: you see people with umbrellas, and then you see rain. But if even once the rain started without umbrellas, then it is already clear that umbrellas are not the cause of rain.
Bonus for those who read: the appearance of a conditioned reflex on a specific neuron
Suppose we go to teach an animal to blink its eyes in response to some conditional stimulus. This is done in the following way: first, the experimental one demonstrates our conditioned stimulus, and then (after a certain time interval) we blow into his eyes, causing an unconditioned reflex. Repeat as needed. The formation of a new conditioned reflex can be traced to a specific neural network.
In our case, the scene is the cerebellum. He, almost like a real brain, has its own cortex and subcortical nuclei. In its cortex there is a layer of neurons called “Purkinje cells”. They send brake synapses to their addressees. That is, the more often Purkinje cells generate adhesions, the more oppressed the recipient neurons are. In the absence of an input signal, the Purkinje cell continuously generates spikes at some frequency. Each Purkinje cell (among other things) receives two interesting input signals:
1) approximately 100,000 weak inputs from parallel fibers (these are axons of granular neurons)
2) one very strong input from a curly fiber (this is an axon from some neuron from inferior olive)
Information about our conditional stimulus goes to Purkinje cells through parallel fibers (those that are thousands), and about triggering an unconditioned reflex through a curling fiber. Learning itself, if we measure it with an electrode inserted into the Purkinje cell, looks like this:

The figure shows how the not yet trained Purkinje cell (above) and the trained (below) respond to the conditioned stimulus. The horizontal line is the presentation of a conditional stimulus, and the length of the line is the time interval (ISI) between the conditional (CS) and the unconditional (US) stimulus used in training.
It can be assumed that the cell has learned to recognize our conditional stimulus in the input context stream and, in response to this, remove permanent inhibition from the neurons triggering the blink. For a time, of course. Well defined time. At the same time, the curly fiber may supply something like a training signal to it. [9] .
It is worth noting that in other parts of the brain no equally bright candidates for learning with a teacher (supervised learning) were found, it is assumed that the crust is trained without a teacher (unsupervised learning), and the basal ganglion with reinforcement (reinforcement).
In our case, the scene is the cerebellum. He, almost like a real brain, has its own cortex and subcortical nuclei. In its cortex there is a layer of neurons called “Purkinje cells”. They send brake synapses to their addressees. That is, the more often Purkinje cells generate adhesions, the more oppressed the recipient neurons are. In the absence of an input signal, the Purkinje cell continuously generates spikes at some frequency. Each Purkinje cell (among other things) receives two interesting input signals:
1) approximately 100,000 weak inputs from parallel fibers (these are axons of granular neurons)
2) one very strong input from a curly fiber (this is an axon from some neuron from inferior olive)
Information about our conditional stimulus goes to Purkinje cells through parallel fibers (those that are thousands), and about triggering an unconditioned reflex through a curling fiber. Learning itself, if we measure it with an electrode inserted into the Purkinje cell, looks like this:
The figure shows how the not yet trained Purkinje cell (above) and the trained (below) respond to the conditioned stimulus. The horizontal line is the presentation of a conditional stimulus, and the length of the line is the time interval (ISI) between the conditional (CS) and the unconditional (US) stimulus used in training.
It can be assumed that the cell has learned to recognize our conditional stimulus in the input context stream and, in response to this, remove permanent inhibition from the neurons triggering the blink. For a time, of course. Well defined time. At the same time, the curly fiber may supply something like a training signal to it. [9] .
It is worth noting that in other parts of the brain no equally bright candidates for learning with a teacher (supervised learning) were found, it is assumed that the crust is trained without a teacher (unsupervised learning), and the basal ganglion with reinforcement (reinforcement).
Conclusion
At first glance, the same STDP may seem like a solid learning algorithm for networks of spike neurons. But in reality now there are no effectively trained artificial spike models. That is, something they can - for example, issue 95% on the MNIST benchmark - but the more non-trivial tasks for them are still not very good.
Much more progress in recent years has occurred in such networks, where adhesions are absent as a class. The learning algorithms there are based on the gradient descent over the surface of the error, where the error is a function of the weights of the synapses. Work with the time dimension is achieved through feedbacks in the topology. Attention and reinforcement have been successfully introduced into these networks. Against this background, the spike models still look “poor”.
What is the conclusion? It is difficult to say for sure. Perhaps we are still waiting for breakthroughs in spike networks: it’s not for nothing that the brain consists of spike neurons. Or perhaps the current spike models simply lack the computing power of our hardware to "show themselves." Finally, it is possible that spikes are a low-level feature of bio-iron, on top of which the brain implements the same gradient descent by mistake in some form. However, this is not included in the current working hypothesis of neurobiology due to the absence of grounds.
Source: https://habr.com/ru/post/390385/
All Articles