One model for learning everything. Google has opened the library Tensor2Tensor
 Recent advances in depth learning and neural networks have spread to a wide range of applications and continue to spread further: from machine vision to speech recognition and many other tasks. Convolutional neural networks best of all manifest themselves in vision tasks, and recurrent neural networks have shown success in natural language processing tasks, including machine translation applications. But in each case, a specific neural network is designed for each specific task. This approach limits the use of in-depth training, because the design must be performed again and again for each new task. It is also different from the way the human brain works, which can learn several tasks at the same time, and it also benefits from the transfer of experience between tasks. The authors of the scientific work “ One Model for Learning Everything ” from the Google Brain Team asked a natural question: “Can we create a unified depth learning model that will solve problems from different areas?”
Recent advances in depth learning and neural networks have spread to a wide range of applications and continue to spread further: from machine vision to speech recognition and many other tasks. Convolutional neural networks best of all manifest themselves in vision tasks, and recurrent neural networks have shown success in natural language processing tasks, including machine translation applications. But in each case, a specific neural network is designed for each specific task. This approach limits the use of in-depth training, because the design must be performed again and again for each new task. It is also different from the way the human brain works, which can learn several tasks at the same time, and it also benefits from the transfer of experience between tasks. The authors of the scientific work “ One Model for Learning Everything ” from the Google Brain Team asked a natural question: “Can we create a unified depth learning model that will solve problems from different areas?”It turned out that we can. Google did it - and opened the Tensor2Tensor for public use, the code is published on GitHub.
The issue of creating multi-tasking models has been the subject of many scientific papers and has been raised in the literature on depth learning. Natural language processing models have long shown an improvement in quality using a multi-tasking approach, and recently machine translation models have shown complete learning without training (zero-shot learning, when a problem is solved without providing materials for learning to solve this problem) when learning simultaneously in many languages . Speech recognition also increased the quality of learning in such a multi-tasking mode, as well as some tasks in the field of machine vision, such as face type recognition. But in all cases, all these models were trained on tasks from the same domain: translation tasks — on other translation tasks (albeit from other languages), machine vision tasks — on other computer vision tasks, speech processing tasks — on other speech processing tasks. But no truly multi-tasking multi- model model has been proposed.
Specialists from Google managed to develop this. In a scientific article, they describe the MultiModel architecture - a unified universal model of deep learning, which can simultaneously be trained in tasks from different domains.
')

MultiModel Architecture
In particular, the researchers trained MultiModel to test simultaneously on eight data sets:
- WSJ Speech Recognition Body
- ImageNet Image Base
- Base of common objects in the context of COCO
- WSJ parsing database
- English to German translation body
- Reverse previous: German to English translation corps
- Translation from English to French
- Reverse the previous: the case of translation from French to English
The model successfully studied all the listed tasks and showed a good quality of work: not outstanding at the moment, but higher than that of many specific neural networks designed for one task.

The illustration shows some examples of how the model works. Obviously, she is able to describe the text that is shown in the photograph, to categorize objects and translate.
Scientists emphasize that this is only the first step in this direction, but at the same time they draw attention to two key innovations that made it possible to create such a model in principle and what they consider their main achievement:
- Small subnets with limited modality that turn into a unified view and back. In order for a multimodal universal model to be trained on input data of different formats - text, sound, images, video, etc. - all of them must be transferred to a common universal space of representations of variable size.
- Computing blocks of various kinds are critical to getting good results on various problems. For example, the Sparsely-Gated Mixture-of-Experts block was inserted for natural language processing tasks, but it did not interfere with the performance of other tasks. The same is true of other computational units.
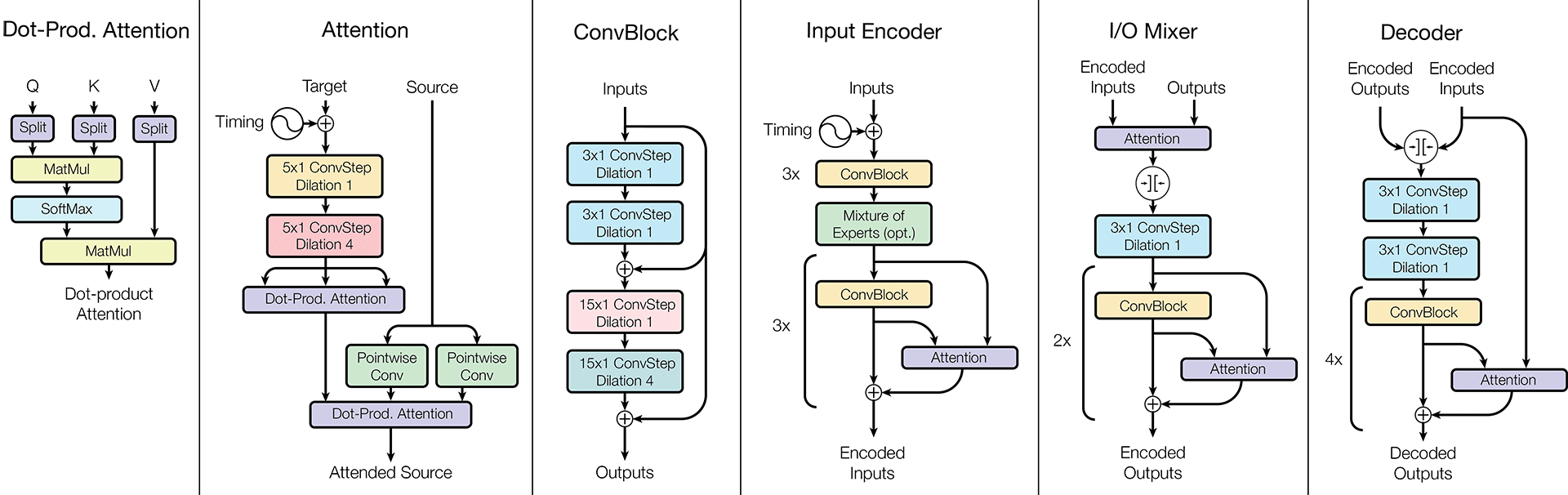
The more detailed architecture of the MultiModel is shown in the illustration above.
MultiModel learns many data and many tasks at once. Experiments have shown that such an approach gives a huge advantage in improving the quality of work on tasks with a small amount of data. At the same time, for problems with a large amount of data, there is only a slight deterioration, if any.
The scientific work is published on the site of preprints arXiv.org (arXiv: 1706.05137).
Source: https://habr.com/ru/post/373559/
All Articles