MIT homework: writing a neural network for maneuvering in road traffic
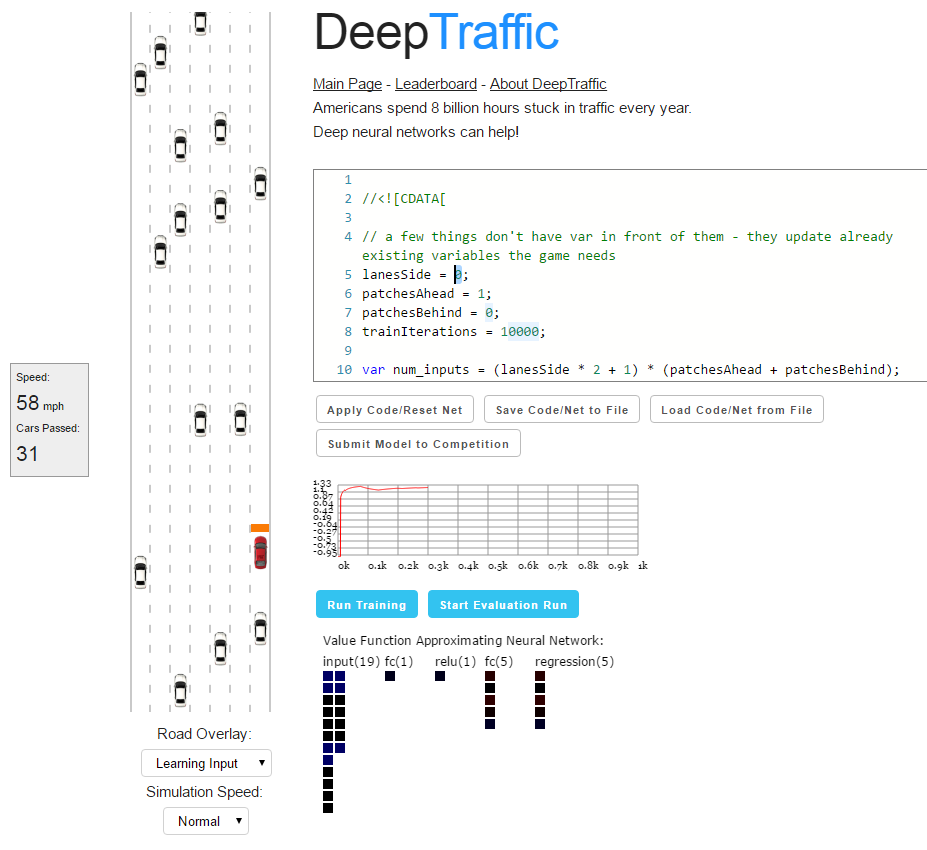
DeepTraffic is an interesting interactive game that anyone can participate in, and students at the Massachusetts Institute of Technology (MIT), who study in-depth training in unmanned vehicles, must show a good result in this game in order for them to count the completed assignment.
Participants are offered to design an AI agent, namely, to design and train a neural network that will show itself better than its competitors in dense traffic flow. The management of the agent is given one car (red). He must learn to maneuver in a stream in the most efficient way.
Under the terms of the game, a security system is initially built into the car, that is, it cannot crash or fly off the road. The task of the player is only to control the acceleration / deceleration and change of lanes. The agent will do it with maximum efficiency, but without crashing into other cars.
')
Initially, the proposed base code of the agent, which can be modified directly in the game window - and immediately run for execution, that is, for training the neural network.
Base code
//<![CDATA[ // a few things don't have var in front of them - they update already existing variables the game needs lanesSide = 0; patchesAhead = 1; patchesBehind = 0; trainIterations = 10000; var num_inputs = (lanesSide * 2 + 1) * (patchesAhead + patchesBehind); var num_actions = 5; var temporal_window = 3; var network_size = num_inputs * temporal_window + num_actions * temporal_window + num_inputs; var layer_defs = []; layer_defs.push({ type: 'input', out_sx: 1, out_sy: 1, out_depth: network_size }); layer_defs.push({ type: 'fc', num_neurons: 1, activation: 'relu' }); layer_defs.push({ type: 'regression', num_neurons: num_actions }); var tdtrainer_options = { learning_rate: 0.001, momentum: 0.0, batch_size: 64, l2_decay: 0.01 }; var opt = {}; opt.temporal_window = temporal_window; opt.experience_size = 3000; opt.start_learn_threshold = 500; opt.gamma = 0.7; opt.learning_steps_total = 10000; opt.learning_steps_burnin = 1000; opt.epsilon_min = 0.0; opt.epsilon_test_time = 0.0; opt.layer_defs = layer_defs; opt.tdtrainer_options = tdtrainer_options; brain = new deepqlearn.Brain(num_inputs, num_actions, opt); learn = function (state, lastReward) { brain.backward(lastReward); var action = brain.forward(state); draw_net(); draw_stats(); return action; } //]]> To the left of the code on the page, there is a real simulation of the road along which the agent is moving, with the current state of the neural network. There is also some basic information, like the current speed of the car and the number of other cars that it has overtaken.
When training a neural network and evaluating the result, the number of frames is measured, so that computer performance or animation speed does not affect the result.
Different Road Overlay modes allow you to understand how a neural network works and learns. In the Full Map mode, the entire road is represented as grid cells, and in the Learning Input mode, it is shown which cells are counted at the input of the neural network for the maneuver decision.
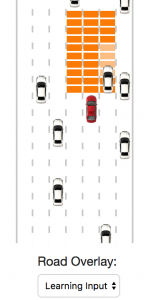
The size of the “control zone” at the input of the neural network is determined by the following variables:
lanesSide = 1; patchesAhead = 10; patchesBehind = 0; trainIterations = 10000; The larger the zone, the more information about the surrounding traffic gets the neural network. But by noisy the neural network with unnecessary data, we prevent it from learning really effective maneuvers, that is, learning the right incentives. To handle a larger area, you probably should increase the number of iterations during training (
trainIterations ).Switching to the Safety System mode you can see how the basic algorithm of our car works. If the grid cells become red, the car is forbidden to move in this direction. In front of the cars ahead the agent slows down.
The car is controlled by the
learn function, which takes into account the current state of the agent (the state argument), the reward for the previous step ( lastReward , average speed in miles / h) and returns one of the following values: var noAction = 0; var accelerateAction = 1; var decelerateAction = 2; var goLeftAction = 3; var goRightAction = 4; That is, do not take any action (0, keep your lane and speed), accelerate (1), brake (2), change lanes to the left (3), shift lanes to the right (4).
Below from the code block is some service information about the state of the neural network, buttons to start learning the neural network and to run tests.
The result of the test run will be the average speed that the agent showed on the track (in miles / hour). You can compare your result with the results of other programmers . But it should be borne in mind that the "test drive" shows only an approximate estimated speed, with a small element of randomness. During this test, the neural network is driven through ten 30-minute races with the calculation of the average speed in each race, and then the result is calculated as the average median speed of ten speeds in these races. If you send a neural network to the competition, the organizers of the competition will launch their own test and determine the true speed that the unmanned vehicle shows.
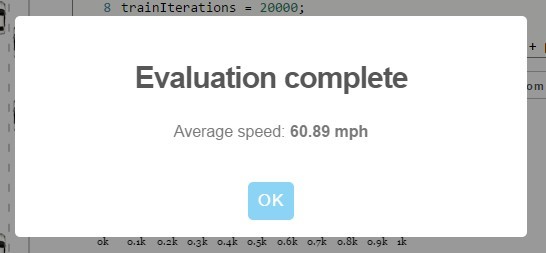
Result with 5 lanes, 10 cells in front, 3 behind, 20,000 iterations, 12 neurons
Apparently, in addition to the basic parameters, the number of neurons in the hidden layer in this code fragment must also be changed:
layer_defs.push({ type: 'fc', num_neurons: 1, activation: 'relu' }); So far, the maximum results in the competition have been shown by lecturer Lex Friedman (74.45 mph) and habrauser Anton Pechenko parilo (74.41 mph). Perhaps in the comments parilo will explain with what settings he did it. I wonder if he changed the code in some way, or limited to the selection of four basic parameters and the number of neurons in the hidden layer.
Ideas for more advanced neural network optimization can be obtained from comments in the neural network fragment code on Github .
Students of the course 6.S094: Deep Learning for Self-Driving Cars are required to show a result of at least 65 miles per hour in the game so that lecturer Lex Friedman will count this task for them.
Source: https://habr.com/ru/post/373075/
All Articles