UNREAL agent. The neural network "fantasizes" about the future - and it learns faster

On the left, a frame from the game Labyrinth, in which the artificial intelligence agent UNREAL is trained. The program fantasizes how to take an apple (+1 point) and a pyramid (+10 points), after which a respawn will occur elsewhere on the map
Researchers from the British company DeepMind (property of Google) published yesterday an interesting scientific paper , which describes an extraordinary method of training a neural network with reinforcements. It turned out that if in the process of self-learning, a neural network begins to “dream” of various options for the future, then it learns much faster. DeepMind staff confirmed this experimentally.
The scientific article explains the work of the intellectual agent Unsupervised Reinforcement and Auxiliary Learning (UNREAL). He independently learns to go through the Labyrinth 3D maze 10 times faster than the best AI-type software today. This game vaguely resembles the levels of the first 3D shooters, only without monsters and fascists, specially designed for training neural networks.
The construction of Labyrinth was first described in a previous research paper by colleagues from the company DeepMind.
')
Labyrinth
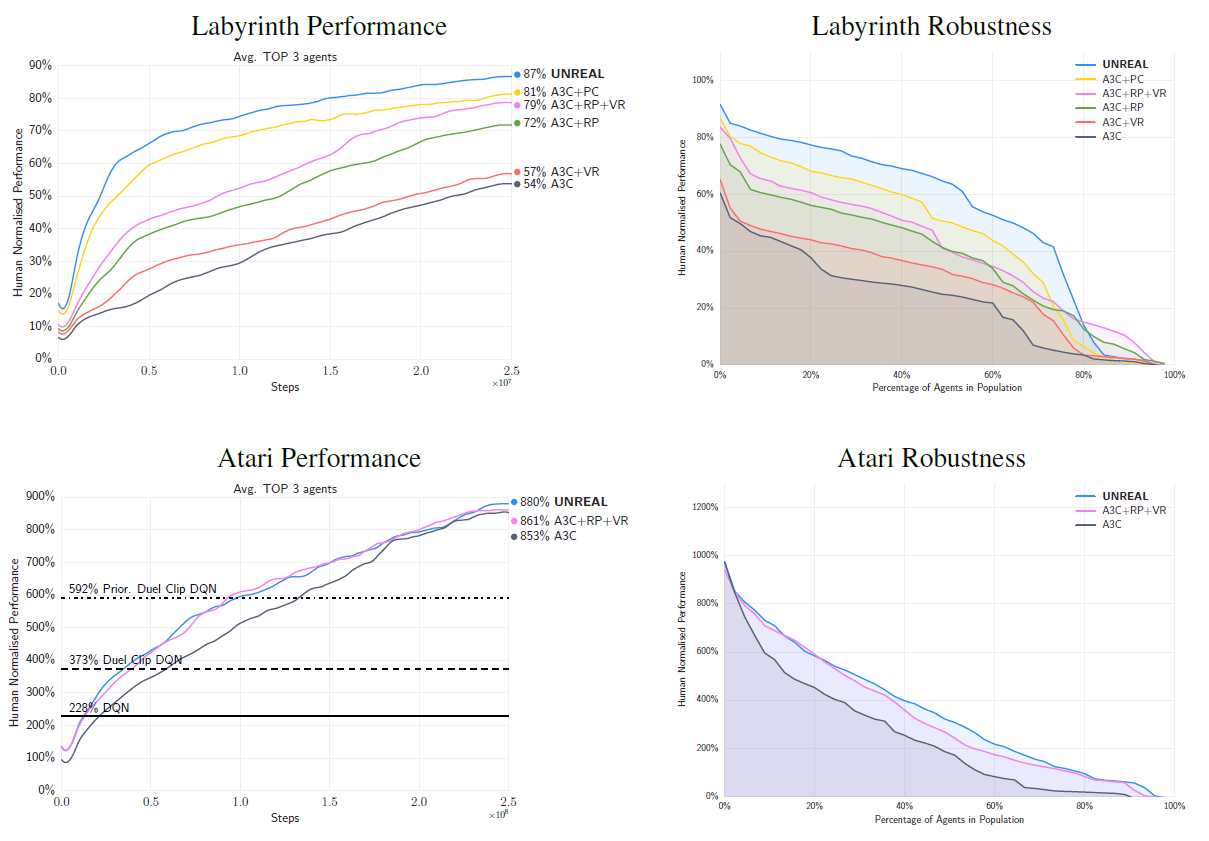
UNREAL can play this game better than 87% of human players, and this is a fairly high result.
“Our agent is much faster in training and requires much less input from the outside world for training,” explains the staff of DeepMind and the authors of the scientific work, Max Yaderberg and Volodymyr Mnih. Such a neural network can be used in different tasks, and at the expense of outstanding characteristics, it will allow faster and more efficiently to work out various ideas that researchers are working on.
Self-learning of AI in games is a common practice in the development of self-learning neural networks with reinforcement.
DeepMind AI learns to play Atari Breakout
This is understandable. If AI learns to play well in realistic computer games such as shooters or simulators of family life, then it will be easier for him to get comfortable in the real world. In the end, in life, a person also constantly receives various rewards - smiles of others, sex, money - and intellectually changes his behavior in order to maximize the number of rewards. The neuronet is also trained with reinforcements.
Fantasies about the future
The training of a neural network with reinforcement occurs due to positive feedback. Each time a reward is received (in the game its role is played by apples) a positive incentive comes into the neural network. This game differs from many others in that its frequency of rewards is relatively rare, and only a small part of the card is available to the agent.
As people know, rare rewards are precisely the circumstance that explains the positive influence of dreams and fantasies.
Here is how the developers themselves explain the work of UNREAL: “Consider a child who is learning to achieve the maximum amount of red in the world around them. In order to correctly predict the optimal amount, the child must understand how to increase the “redness” in various ways, including manipulations with the red object (bring it closer to the eyes), own movement (move closer to the red object) and communication (cry until the parents bring the red object ). These types of behavior may well be repeated in many other situations that the child will face. ”
For the agent UNREAL, they tried to implement approximately the same scheme for achieving the set goals as the child described above has. AI uses reinforcement learning to develop the optimal strategy and optimal value of the objective function for many pseudo-rewards. Other additional predictions are made to draw the agent’s attention to important aspects of the task. Among these predictions is the long-term task of predicting total remuneration and the short-term task of predicting current remuneration. In Labyrinth, this is the total number of apples harvested in the game and the receipt of one particular nearest apple. For more effective training, the agents use the mechanism of reproduction of the experience already gained . "As animals more often dream of positive or negative rewarding events, so our agents preferably replay sequences that contain rewarding events."
In other words, sometimes an AI agent does not even need to re-navigate a maze to gain new knowledge. He simply uses his memory - and applies new strategies as if in his own imagination. This is the very thing that researchers call fantasy.
The general construction of the agent UNREAL is shown in the illustration. It shows a small replay buffer (Replay Buffer), from which information is generated to generate fantasies for short-term and long-term goals (Reward Prediction and Value Function Replay).
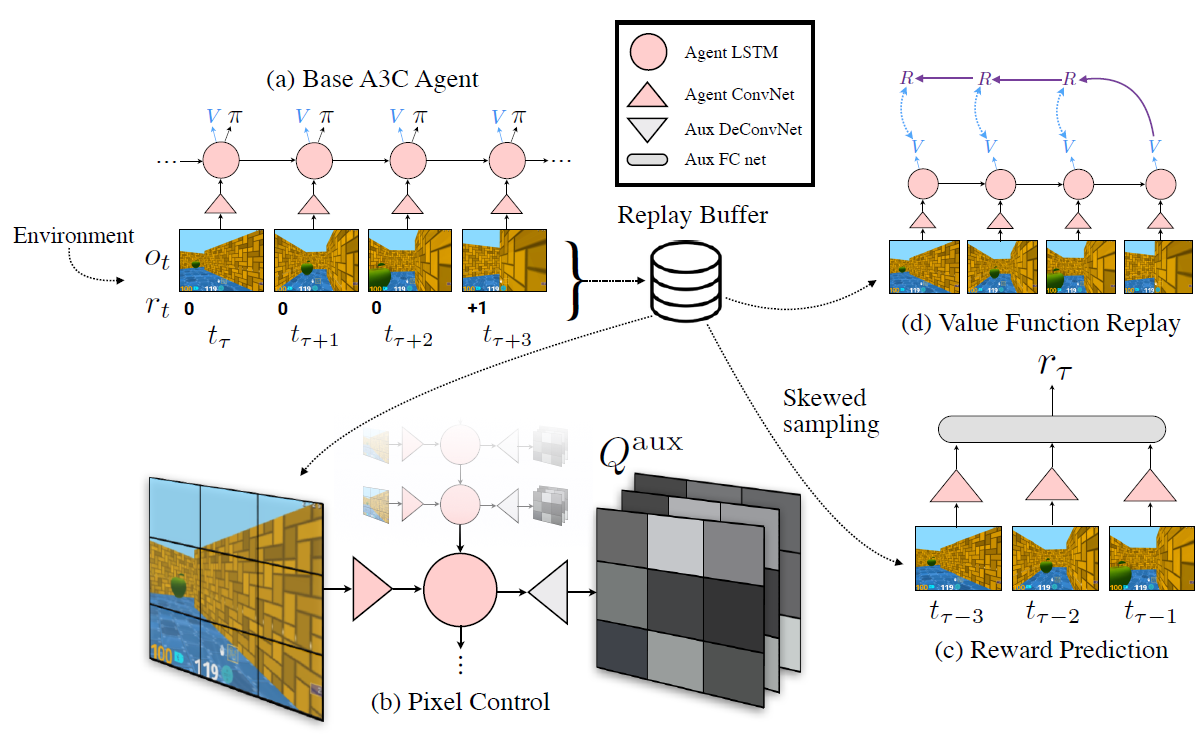
The agent's fantasy (Reward Prediction) is that for the last three known frames, the neural network must predict the reward it will receive in the fourth unknown time interval.
The following video shows the actions of the agent UNREAL in the game Labyrinth (green apple gives 1 point, and the red object - 10 points; the goal of the agent is to collect 10 points, after which he is transferred to another place).
In addition to playing Labyrinth, the agent UNREAL has learned to play 57 more Atari vintage games, such as Breakout, much faster and better than any previously created agents. Say, the last champion among AI agents showed a result about 853% better than top human players, and a new AI - 880% better.
The results of UNREAL in all levels of the game Labyrinth and Atari are presented in diagrams. The abbreviations RP and VR correspond to fantasy modules for short-term and long-term goals, and PC to the module for pixel control. UNREAL includes all three modules RP, VR and PC, and from the remaining graphs we can understand the contribution of each module to the overall success of the agent.
Skeptics
Despite numerous scientific studies and successes of in-depth training of neural networks, there are skeptics who doubt the prospects of this direction for the development of AI. For example, a former IBM employee Sergey Karelov in a telegram note “ Again about Charlatanry in the marketing of science and technology ” writes:
The approach “input data - action at output” is most likely fundamentally erroneous for any adequate scientific description of the phenomenon of human consciousness and all related concepts (intuition, etc.).
Jeff Hawkins first substantiated this in a wonderful book, On Intelligence (I highly recommend it to anyone who does not like about AI, but wants to understand its real prospects).
And today, more and more world-class scientists are focused on this conclusion, focused on the study of this multi-disciplinary field of science. Professionally and not very popular (but cool interesting) you can see about it here .
Unfortunately, Sergey Karelov did not say which approach should be used by scientists instead of the nonsense that they are doing now. Perhaps the developers of the company DeepMind also want to know.
Source: https://habr.com/ru/post/372887/
All Articles