Is artificial intelligence incomprehensible?

Dmitry Malyutov can tell little about his creation.
He works in the IBM research department, and devotes part of his time to creating machine learning systems that solve the problems of corporate clients of the company. One such program was developed for a large insurance company. The task was not easy, it required a complex algorithm. When it came time to explain the results to the client, there was a hitch. "We could not explain this model to them, because they did not understand machine learning."
')
And even if they understood, it could not help them. Because the model was an artificial neural network, a program that accepts data of the desired type — in our case, the affairs of the insurance company's clients — and found patterns in them. Such networks have been used in practice for already half a century, but they have recently experienced a rebirth, and help make breakthroughs everywhere, from speech recognition and translations to playing Go and robotic mobiles.

And despite all the successes of neural networks, they also have one problem: no one, in fact, knows exactly how they work. So, no one can predict when they will be wrong.
Take, for example, the situation that Rich Caruana, a researcher in machine learning, recently told [Rich Caruana] with her colleagues. They described the experience of a team from the University of Pittsburgh Medical Center, which used the MO to predict the occurrence of complications in patients with pneumonia. They sought to send patients with little risk to outpatient treatment, and save space in hospitals. They tried various methods, including various neural networks, as well as decision trees created by programs that gave clear human-readable rules.
Neural networks were right more often than other methods. But when researchers and doctors turned to human-readable rules, they noticed something unpleasant: one of the rules prescribed doctors to send patients with pneumonia home who had asthma, despite the fact that patients with asthma very poorly tolerate complications.
The model did what it was asked to do: it found patterns in the data. Bad advice was the result of inaccuracies in the data. The rules of the hospital prescribed the sending of asthmatics with pneumonia to the intensive care unit, and this rule worked so well that asthmatics almost did not experience complications. And without much care, the results of their treatment would be completely different.
This incident shows the great importance of the possibility of interpreting the results. “If the rules-based system found out that asthma lowers the risks, of course, it also learned the neural network,” wrote Caruana and colleagues — but people could not interpret the work of the neural network, and it would be difficult to explain its strange conclusions about asthmatics ( one). If they didn’t have an interpretable model, Malyutov warns, “one could accidentally kill people”.
Therefore, many are in no hurry to put on the mysterious neural networks. When Malyutov presented his exact but incomprehensible neural network model to his corporate client, he offered them an alternative rule-based system, the work of which he could simply explain. The second model worked less accurately than the first, but the client decided to use it - despite the fact that any percentage of accuracy was important for the insurance company working with mathematics and accurate data. “They understood it better,” says Malyutov. “They appreciate intuition.”
Even governments are beginning to worry about the growing influence of incomprehensible prophets from neural networks. The EU recently proposed the introduction of a “right to explain,” which would allow citizens to demand transparency of algorithmic decisions (2). But such a law will be difficult to introduce, since registrars have not given a clear definition of "transparency". It is unclear whether this miscalculation is the result of not understanding the problem or recognizing its complexity.
In fact, some believe that this definition is impossible to give. So far, although we know everything about what neural networks do - after all, these are, in fact, just computer programs - we can say very little about why they do it. Networks consist of many, sometimes millions, of individual elements called neurons. Each neuron converts a set of numbers to the inputs into a single number at the output, which is then passed on to one or several neurons. As in the brain, neurons are divided into "layers", groups of cells that receive data from the lower layer and send it to the upper one.
Neural networks are trained by feeding them data, and then adjusting the connections between layers until the output of the network begins to best match the calculated one. The incredible results of recent years have come about thanks to a series of new techniques that made it possible to quickly train deep networks, with many layers between the first input and the final conclusion. One of the popular AlexNet deep networks is used to categorize photos - and, marking them, is able to recognize such subtle moments as the differences between the Pomeranian and Shih Tzu breeds. It contains more than 60 million "weights", each of which tells each neuron how much attention should be paid to each piece of input data. "To talk about understanding the network," said Jason Josinski, a programmer at Cornell University working at Geometric Intelligence, "you need to have an understanding of these 60 million numbers."
And even if it would be possible to understand the work of a neural network so much, it is not always necessary. The requirement of an accurate understanding of its work can be viewed as another set of constraints that prevents the model from generating “clean” solutions, depending only on the input and output, potentially capable of reducing the accuracy of the model. At the DARPA conference, program manager David Gunning [David Gunning] outlined the current position of neural networks on a graph that demonstrates that deep networks are the least understood from modern methods. At the other end of the spectrum are decision trees based on the rules of the system, which value explicability above efficiency.
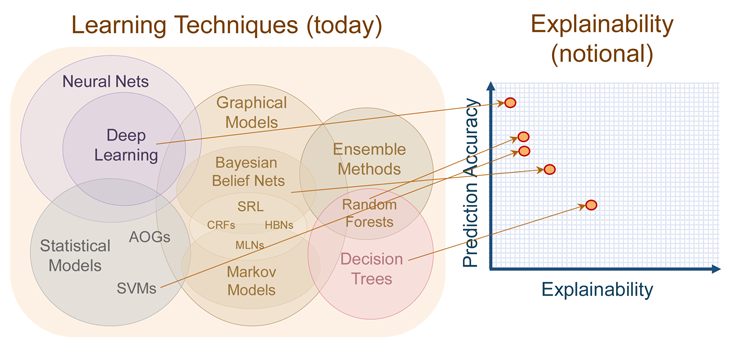
The most accurate and least understandable methods are deep nets. Then, to increase comprehensibility and decrease accuracy, the “random forest” algorithm, statistical models, Bayesian networks, and decision trees are used.
As a result, modern machine learning plays the role of an oracle: to get an exact answer about what will happen, or a clear, but inaccurate explanation of what will happen? Explanation helps us strategize and adapt, as well as know when the model will stop working. Knowing what will happen helps us react accordingly in the near future.
Such a choice can be difficult. Some researchers hope to eliminate the need for choice - so that we have both a layered cake and its understanding. Interestingly, the most promising studies relate to neural networks as objects of experiment - in the manner of biological research - instead of considering them as purely mathematical objects. Yosinsky, for example, says that he is trying to understand deep networks “how we understand animals, or even people.” He and other programmers borrow technology research from biological areas, and look into the inside of neural networks like neurologists in the brain: trying individual parts, compiling catalogs of how the insides of networks react to small changes in input, and even removing pieces and watching others compensate for their absence.
Having built a new type of intellect from scratch, scientists now take it apart, applying digital microscopes and scalpels to these virtual organisms.
Yosinsky is sitting at a computer and talking to a webcam. Camera data is fed to deep neural networks, while the network itself is analyzed in real time using the Deep Visualization program developed by Yoshinsky and his colleagues. Switching between screens, Yosinsky increases one of the neurons of the network. “This neuron appears to be responding to faces,” he says in interaction videotapes (3). In the brain of people, there are also such neurons, many of which accumulate in the brain region called “spindle-shaped facial region”. This area, discovered in various studies that began in 1992 (4, 5), has become the most experienced observation in neurology. But if those studies required the use of such complex things as positron emission tomography, Yosinsky only needs one code.
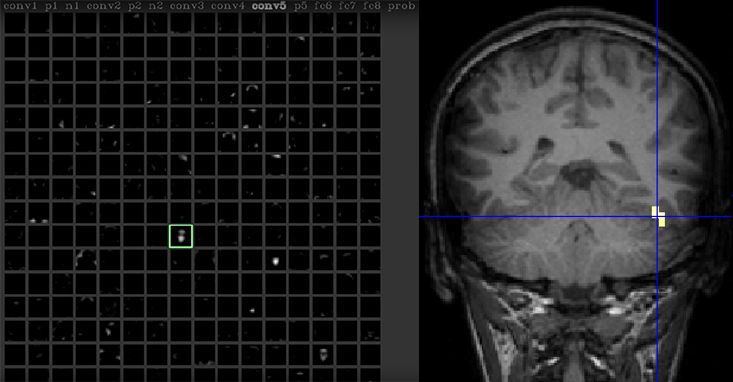
One neuron in a neural network responds to Yosinsky's face just as one of the areas of the brain responds to faces.
This approach allows it to connect artificial neurons with ideas or objects that are understandable to humans, such as individuals, which as a result can turn neural networks into understandable tools. His program can indicate which of the picture properties stimulates the facial neuron more than others. “We can see that he would have reacted even more if, for example, his eyes were darker and his lips were pinker,” he says.
For Cynthia Rudin, a professor of computer science and electronics at Duke University, these interpretations are disliked by the results. Her research focuses on building MO systems based on rules applicable to areas such as prison sentences or medical diagnoses, where human-readable interpretations are not only possible, but also critically important. But in areas related to vision, she says, “interpretations depend solely on the observer.” We can simplify the network response by determining the facial neuron, but how to make sure that we are not mistaken? Doubts Rudin reflects a well-known aphorism, stating that a model for a vision system may not exist simpler than the vision system itself. “You can come up with many explanations for what makes a complex model,” she says. “And what about us, just choose one of them and recognize it as the right one?”
Yosinsky's tool can partially disprove these doubts, working backwards and discovering that the network itself “wants” to be true — something like an artificial ideal. The program starts with raw statics, then refines it pix-by-pixel by processing the image using the reverse process of learning. As a result, she finds a picture that causes the highest possible response from the selected neuron. When applied to AlexNet's neurons, the method produces cartoon images for the marked categories.

Ideal cat versions created by Deep Visualization.
This, apparently, confirms Yosinsky’s statements that facial neurons are looking for faces, in a certain general sense. But there is a problem - to create such images, the procedure relies on statistical limitations (natural ancestors of an image), which limit it to creating only images containing structures found in images of the real world. If you remove these restrictions, the tool still manages to find a picture that causes the maximum response, but this picture looks like noise. Yosinsky showed that in many cases the preferred AlexNet looks to people like noise. He admits that “it’s pretty easy to figure out how to make neural networks produce something extreme.”
To avoid these pitfalls, Druv Batra, an assistant professor of electronics and computers at Virginia University of Technology, uses a higher-level experimental approach to interpreting the work of deep networks. Instead of searching for patterns in their internal structure, “people worked smarter than me on this,” he doubts — he explores the behavior of networks through a robotized version of eye movement tracking. His group in the project, led by graduate students Abhishek Das and Harsh Agrawal [Harsh Agrawal], asks the neural networks about the image, for example, whether there are curtains in the picture on the window (6). Unlike systems like AlexNet, the Das network is designed to work with a small portion of the picture. She moves the virtual eyes through the image until she decides that she has gathered enough information to answer. After training, such a network works very well, and answers questions no worse than the best people.
Das, Batra and colleagues then wanted to understand how the network makes decisions, studying which parts of the images the network paid attention to. Surprisingly, they found that in response to a question about curtains, the network does not even look at the window. She first looks at the bottom of the picture, and stops looking if she finds a bed. Apparently, in the set of initial data for training networks, windows with curtains were present in the bedrooms.
And although this approach reveals some aspects of the work of neural networks, it even complicates the problem of interpreting their work. “Machines do not learn the facts about the world,” says Batra. “They learn the facts about the dataset presented.” The fact that they are so strongly tied to the data provided to them makes it difficult to draw up general rules for their work. Moreover, if you do not know how it works, you do not know when it will be mistaken. And when they make a mistake, then, according to the experience of Batra, "they will make it terribly shameful."
Some of the obstacles encountered by researchers are familiar to scientists studying the human brain. Issues of interpretation of images of the brain is now very popular, although not so well known. In a review from 2014, cognitive neurologist Martha Farah [Martha Farah] wrote that “it is disturbing that the images of the working brain are more similar to the inventions of researchers than to observations” (7). The appearance of these problems in very different types of intellectual systems may indicate that these problems are obstacles not in the study of a particular type of brain, but in the study of the very concept of intelligence.
Are searching for an understanding of the work of networks a futile idea? In a blog post from 2015, “The Myth of Model Interpretability”, Zachary Lipton of the University of California at San Diego offered a critical look at both the motivation behind trying to understand the work of neural networks and the value of creating interpretable MO models on large data arrays . He submitted his work to a symposium on the subject of human “interpretability” (organized by Malyutov and his colleagues) at the machine learning conference (ICML) held this year. (eight)
Lipton points out that many scientists disagree with the very concept of interpretability, which, in his opinion, means that either interpretability is poorly understood, or that this concept has many different meanings. In any case, the search for interpretability may not give us a simple and direct explanation of why the neural network produced such a result. On a blog post, Lipton argues that in the case of giant datasets, researchers can suppress their desire to interpret the results and simply "believe in an empirical process." He believes that one of the goals of this area is “to build models that can be trained in more parameters that a person can ever handle,” and the requirement of interpretability can limit the models and prevent them from developing their full potential.
But this possibility will be both an advantage and a disadvantage: if we do not understand how the network creates output data, we do not know which features of the input data were important, or what can be considered as input data in general. For example, in 1996, Adrian Thompson of the University of Sussex used a program to develop an electronic circuit based on principles similar to the work of neural networks. The contour was simply to distinguish between two different key sounds. After thousands of iterations on the placement and relocation of radio components, the program found a solution that works almost perfectly.
But Thompson was surprised to learn that the circuit used fewer components than a human engineer would need. At the same time, several of them were not connected with the others, but, somehow, they were still needed for the proper operation of the circuit.
He began to disassemble the contour into parts, and after several experiments he realized that his work used small interferences in the neighboring components. Components not involved in the circuit influenced it, leading to small fluctuations in local electric fields. Engineers tend to get rid of such interactions due to their unpredictability. Naturally, when trying to copy this circuit with the participation of another batch of the same components, or even when the ambient temperature changed, the circuit stopped working.
This circuit showed a typical sign of the result of the work of trained machines: it is compact and the most simplified, very well adapted to its environment, and completely inoperable in other conditions. They choose properties invisible to engineers, but they cannot know whether these properties exist anywhere else. MO researchers are trying to avoid such phenomena, which they call “super-specialization,” but with an increase in the use of such algorithms in their life tasks, their vulnerability will become visible.
[Sanjeev Arora], , , . , . – , ( ), , . « - , , , »,- . , .
– « », , , , . , . , , , . , , , , .
. ? , , « » , (9). , «». - , . ?
, , , - , (, , ) , " " , , . [Massimo Pigliucci], - , – – , [Ludwig Wittgenstein] « », , . «» , , . «» " ".
, , , . , . , . , . , - «», - .
At the ICML conference, some speakers called for “interpretability”. There were as many options as the speakers. Having discussed, the participants agreed that for the model to be interpretable it should be simple. But when trying to define “simplicity,” the group again split. Is that the simplest model that relies on the minimum set of properties? The one that makes the clearest separation? Smallest of programs? The symposium was closed without the consent of the participants who replaced one nascent concept with another.
As Malyutov says, "simplicity is not so simple."
Links
1. Caruana, R., et. al Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 1721-1730 (2015).
2. Metz, C. Artificial Intelligence Is Setting Up the Internet for a Huge Clash with Europe. Wired.com (2016).
3. Yosinski, J., Clune, J., Nguyen, A., Fuchs, T., & Lipson, H. Understanding neural networks through deep visualization. arXiv:1506.06579 (2015).
4. Sergent, J., Ohta, S., & MacDonald, B. Functional neuroanatomy of face and object processing. A positron emission tomography study. Brain 115, 15–36 (1992).
5. Kanwisher. N., McDermott, J., & Chun, MM The fusiform face area: A module in human extrastriate cortex specialized for face perception. The Journal of Neuroscience 17, 4302–4311 (1997).
6. Das, A., Agrawal, H., Zitnick, CL, Parikh, D., & Batra, D. Human attention in visual question answering: Do humans and deep networks look at the same regions? Conference on Empirical Methods in Natural Language Processing (2016).
7. Farah, MJ Brain images, babies, and bathwater: Critiquing critiques of functional neuroimaging. Interpreting Neuroimages: An Introduction to the Technology and Its Limits 45, S19-S30 (2014).
8. Lipton, ZC The mythos of model interpretability. arXiv:1606.03490 (2016).
9. Brockman, J. Consciousness Is a Big Suitcase: A talk with Marvin Minsky. Edge.org (1998).
Source: https://habr.com/ru/post/372673/
All Articles