Google Neural Network Compresses Photos Better JPEG

A fragment of 32 × 32 pixels of the original image compressed by different methods. Illustration: Google
The developers at Google have shared their latest achievements in the application of neural networks for practical tasks. On August 18, they published on ArXiv a scientific article “ Compression of full-size images using recurrent neural networks ” ( “Full Resolution Image Compression with Recurrent Neural Networks” ). The article describes an innovative method of compressing photos using a neural network, shows the process of its learning and examples of its work.
The developers inform that this is the first neural network in the world, which on most bitrates compresses photos better than JPEG, with or without entropy coding.
The neural network for compressing Google images is based on the free TensorFlow machine learning library . Two sets of data were used for training: 1) a ready set of images of 32 × 32 pixels; 2) 6 million photos from the Kodak Internet database of 1280 × 720 pixels.
')
Each image of 1280 × 720 from the second base was divided into fragments of 32 × 32 pixels. The system then allocated 100 samples with the least effective compression, compared with PNG. The idea is that these are the most “difficult” for compressing the image area - it is on them that the neural network should be trained, and the compression of the remaining areas will be much easier. This “complex” data set is presented in the table below as the “High Entropy Data Set”.
Researchers from Google have experienced several options for the architecture. Each of the models included a coder and a decoder on a recurrent neural network, a binarization module and a neural network for entropy coding. The scientific work compares the effectiveness of several types of neural networks, and also presents new hybrid types of neural networks GRU and ResNet.
To compare the compression efficiency, standard metrics for lossy quality algorithms were used - Multi-Scale Structural Similarity (MS-SSIM, presented in 2003) and the more recent Peak Signal to Noise Ratio - Human Visual System (PSNR-HVS, 2011). The MS-SSIM metric was applied for each of the RGB channels separately, the results were averaged. In the PSNR-HVS metric, color information is initially taken into account.
MS-SSIM gives a rating on a scale from 0 to 1, and PSNR-HVS is measured in decibels. In both cases, a higher value means a better match between the compressed image and the original. To rank the models, a total estimate was used, calculated as the area of the image under the curve of the ratio of the degree of distortion and the amount of data (area under the rate-distortion curve, AUC) for all compression levels (bpp, bits per pixel).
All models were trained in approximately 1,000,000 steps. Entropy coding was not used. The real AUC will be much higher when using entropy coding. But even without it, all models showed results in MS-SSIM and PSNR-HVS better than JPEG.
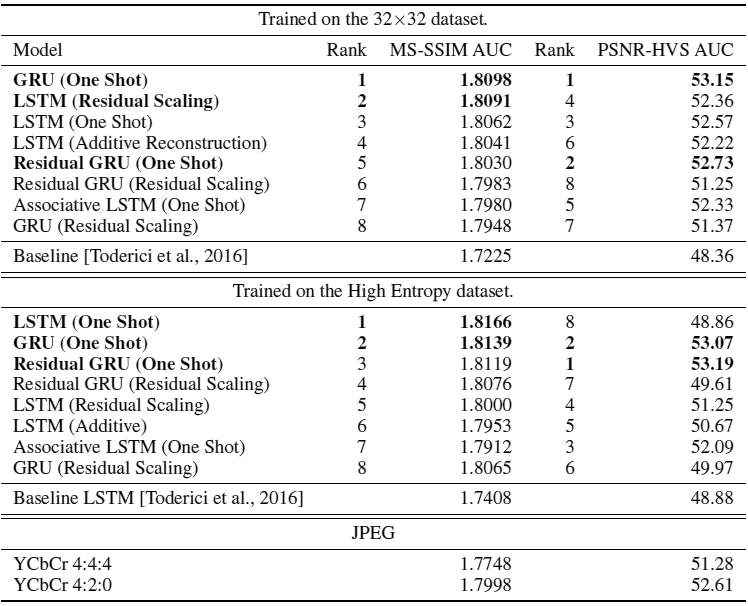
The diagrams below show that all variants of the neural network work more efficiently with the use of an additional layer of entropy coding. On relatively small 1280 × 720 images, the gain is small: between 5% at 2 bpp and 32% at 0.25 bpp. The advantage will be much more noticeable only in really big photos. In the Baseline LSTM model, the savings ranged from 25% by 2 bpp to 57% by 0.25 bpp.
The first diagram shows the curve of the ratio of the degree of distortion and the amount of data (rate-distortion curve); the MS-SSIM metrics are plotted along the ordinate axis, and they vary depending on the level of compression - the bit-per-pixel value plotted along the abscissa axis. The dashed lines correspond to the efficiency before the application of entropy coding, the solid lines after the application of entropy coding. On the left are the two best models trained on a 32 × 32 pixel image data set. On the right are the two best models trained on a high-entropy data set, that is, on real photographs that Google researchers broke into 32 × 32 fragments and identified the most difficult to compress.
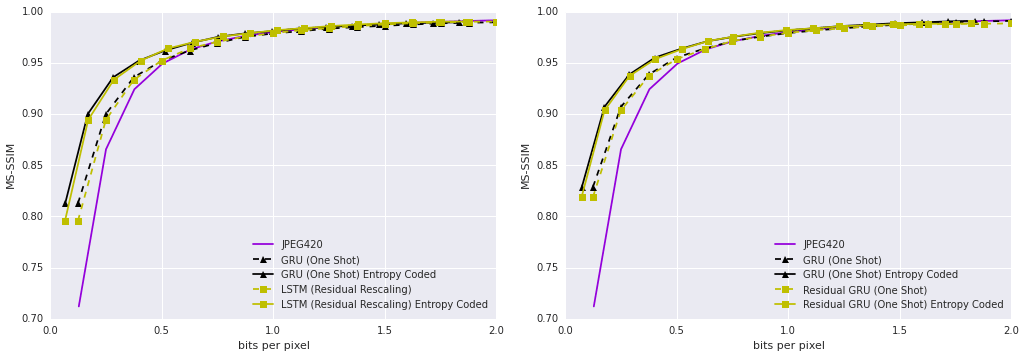
The following diagrams are the same for the PSNR-HVS metric.
The neural network still needs to be improved: some of its results do not look quite familiar to the human eye. The authors of the scientific work admit that the statistics of the effectiveness of the RD-curve does not always correspond to the subjective perception of the eye: “The visual system of human vision is more sensitive to certain types of distortion than to others,” they write.
Nevertheless, this project is an important step towards the development of more efficient algorithms that will help even better compress images. The developers are confident that it is possible to further improve efficiency on large images, if you use tricks borrowed from video codecs, as does WebP, created on the basis of the free VP8 video codec. These are methods such as reusing fragments previously encoded. In addition, they plan to conduct joint training of the entropy encoder (BinaryRNN) and the encoder in place (patch-based) on large images in order to find the optimal balance between the performance of the encoder in place and the predictive power of the entropy encoder.
A few examples of how Google's neural network works in its current state, in the compression of real images. As mentioned above, the human eye is more sensitive to certain types of distortion and less sensitive to others. Therefore, even a picture that is highly rated by MS-SSIM and PSNR-HVS may sometimes not look as good as a low rating. These are already flaws in existing metrics (or human vision).
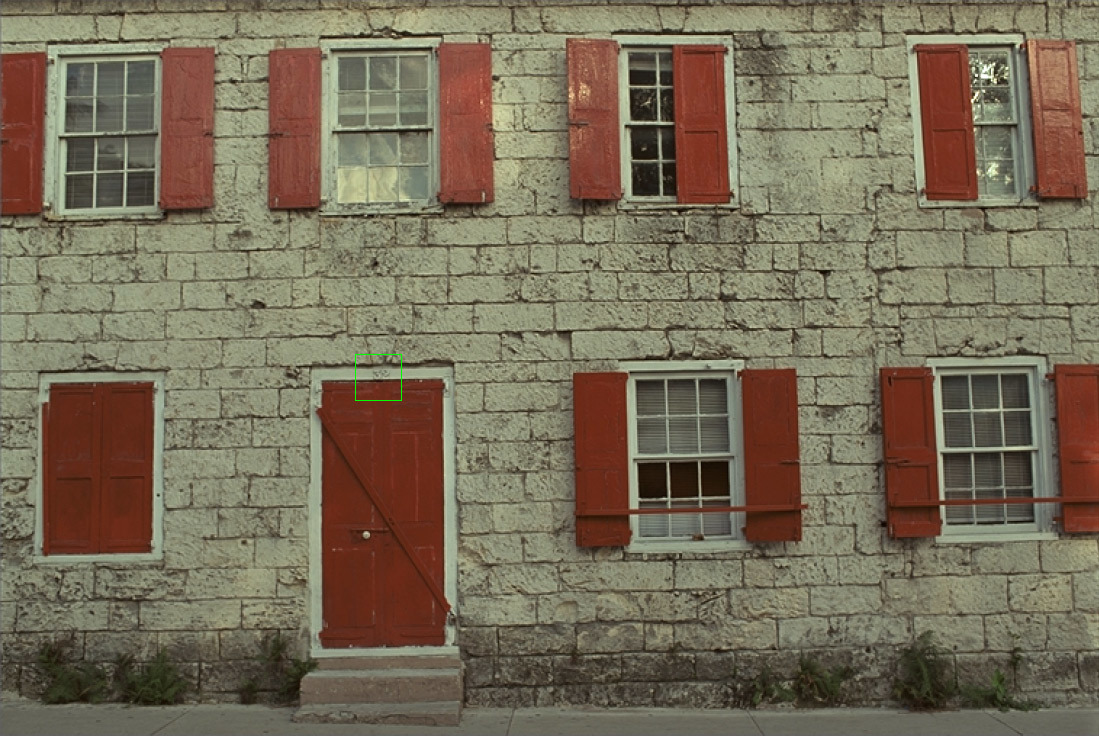
The original image, divided into fragments of 32 × 32 pixels. Illustration: Google

A fragment of 32 × 32 pixels of the original image compressed by different methods. Illustration: Google

The original image, divided into fragments of 32 × 32 pixels. Illustration: Google

A fragment of 32 × 32 pixels of the original image compressed by different methods. Illustration: Google
TensorFlow is a highly scalable machine learning system that can work on a simple smartphone as well as on thousands of nodes in data centers. Google uses TensorFlow for our entire spectrum of tasks, from speech recognition and Google Translate to Inbox answering machine and Google Photos search. This library is “faster, smarter and more flexible than our old system, so it is much easier to adapt it to new products and research,” Google said in November 2015, when it put TensorFlow library for general use under the free Apache 2.0 license .
Source: https://habr.com/ru/post/372607/
All Articles