Laurel / Yanny: audio version of the blue-gold dress
Three years ago there was already discussing a dress that shared the Internet . A few days ago, a similar, even more interesting and more difficultly explainable illusion emerged. What name do you hear on this audio recording: “Jenny” or “Laurel”?
As it turned out, the results not only vary from person to person, but even for one person may depend on the audio equipment used. All week linguists argue about the causes of the illusion, intently looking at the spectrogram of this two-second fragment. Here she is:
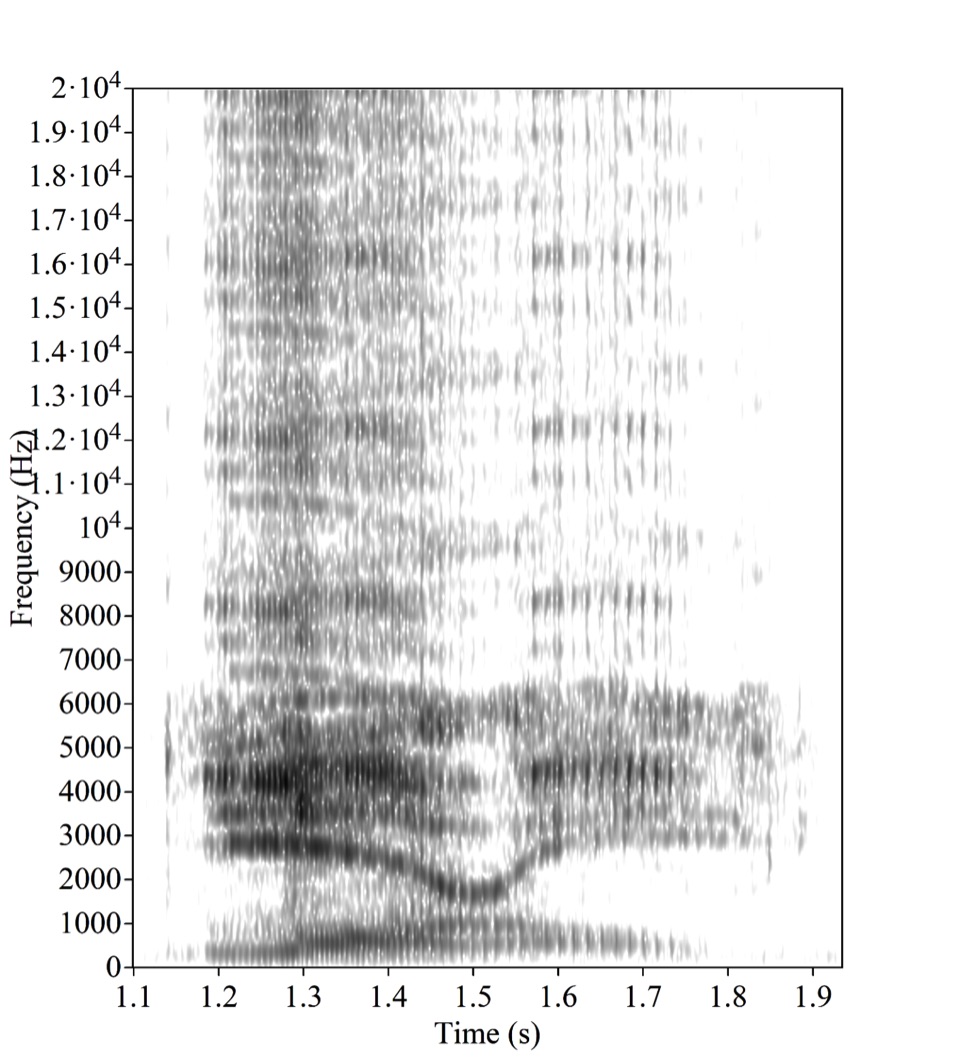
For those who see the spectrogram of sound for the first time: on the horizontal axis, time is plotted, on the vertical — frequency, the brightness of the point corresponds to the amplitude with which the “imaginary tuning fork” vibrates at the corresponding frequency at the appropriate time. On the spectrogram of speech, the " formants " are always visible - dark horizontal lines, tortuous and intermittent; each formant corresponds to one of the resonant frequencies of the speech apparatus, and their vertical oscillations, respectively, to changes in these resonant frequencies in the process of speech.
As Suzy Styles explains , in the low frequency section up to 5 kHz, there are three formant in human speech, which is usually enough to recognize the sounds being heard. These three formants correspond to the vertical (F1) and horizontal (F2) position of the tongue, and the position of the lips (F3). Suzy gives a link to the Max Planck Society video , where the announcer who is in the MRI camera, says all the vowels and all the consonants in turn, so that the position of his speech organs when pronouncing each sound can be monitored directly.
')
And with the release of formants, according to Suzy, problems arise: the dark areas on the yanni / laurel spectrogram form a pattern of more than three bands that branch and intersect:

In particular, the lower band (F1) can be recognized either by a “hump up” or a “hump down”:
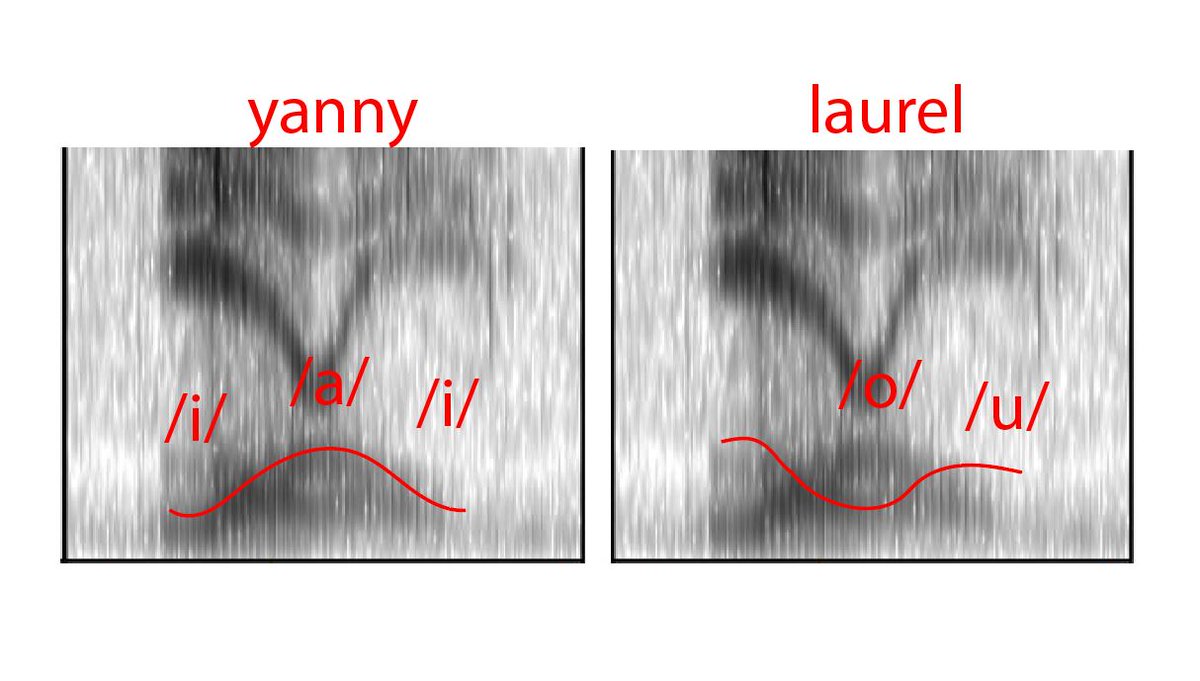
The first line corresponds to the high-low-high vowel sequence, i.e. [jæ-ɪ-]; the second is “low - high - medium”, i.e. [ao-ə-]. (In the figure of Suzy there is an obvious error: [u] is a high vowel, and cannot be at the end of the second sequence.) For F2, it is clear that the vowel sequence should be “front - middle - front”, i.e. again [jæ-ɪ-]. But if the listener's audio system suppresses frequencies between 2 and 3 KHz, then the listener “thinks” F2 based on F1, and receives a sequence of back-to-middle vowels, i.e. [-o-ə-]:

Suzy sums up her analysis: instead of three clear formant we see a confusion of dark spots that can be decrypted in one of two ways:
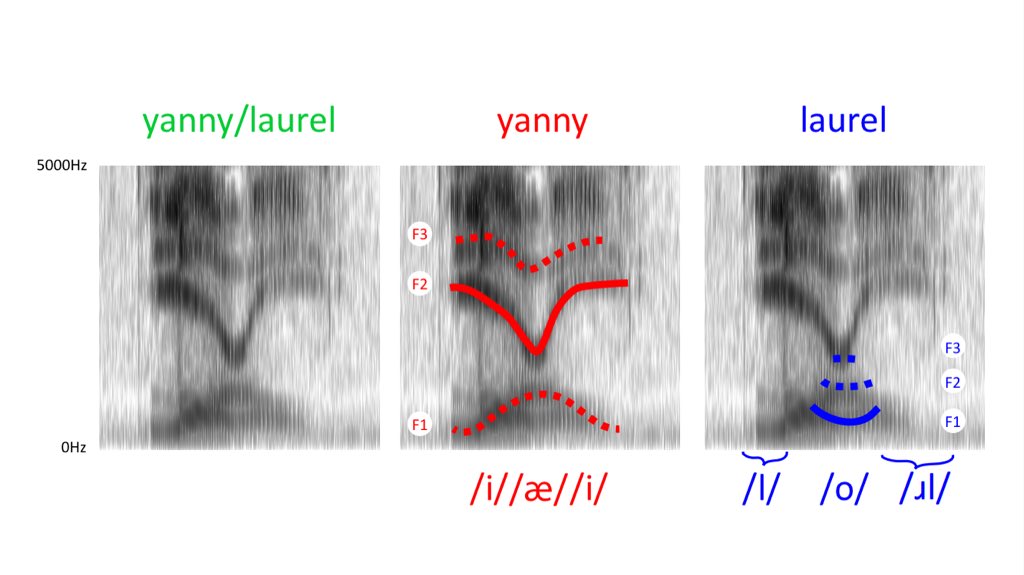
A slightly different analysis leads Carolyn MacGettigan. When it became known that the “ambiguous sound” was not designed by insidious linguists to bully normal people, but was taken from an online dictionary site , passed through not very high-quality speakers, and recorded with a not very high-quality microphone, then Carolyn compared the spectrograms of the original sound from the site , and the resulting "sound-illusion":

In the first sound, F1 and F2 are clearly visible, but very close; in the second, apart from adding weak noise, F1 and F2 merged into one formant, and the original F3 was perceived as F2. Carolyn notes that the “hump down” in F3 is the hallmark of English sound [ɹ]; and in the resulting sound, instead, it became perceived as a “hump down” in F2, i.e. as a sequence of vowels "front - middle - front" - notorious [jæ-ɪ-].
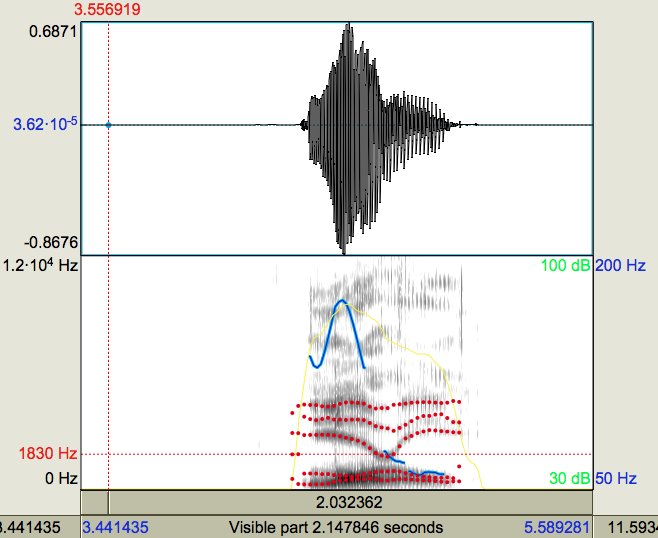
In addition to these two explanations of the illusion, linguists have suggested a few more. Benjamin Monsoon noticed that at high frequencies (5-9, 9-13, 13-17 KHz) weaker repeats F1-F3 are contained:

In human speech, such "repetitive formant" does not happen, so Benjamin blames them for the illusion. (This is most likely an artifact of audio compression used for “ambiguous sound.”)
NY Times - the discussion of illusion has even reached the point ! - also accuses of high-frequency amplification, which occurred during the dubbing:

Moreover, in their note they implemented an “interactive illusion” - a frequency filter, the setting of which can be smoothly changed by a slider so that anyone can be sure: if you amplify low frequencies and suppress high frequencies, then the sound turns into Laurel, if vice versa, then Yanny.
Using the occasion, I will mention here also my own acoustic-phonetic interactive piece , written on the knee under the inspiration of the long-standing quest from Meklon 'a. (I have never frontedder, and I will gladly accept PR with a more friendly UI.) This interactive piece allows you to draw on the spectrogram and listen in real time what kind of sound you get; in particular, you can take an existing sound and try to circle it with formants, or finish drawing new ones, or selectively erase any frequency range.
As it turned out, the results not only vary from person to person, but even for one person may depend on the audio equipment used. All week linguists argue about the causes of the illusion, intently looking at the spectrogram of this two-second fragment. Here she is:
For those who see the spectrogram of sound for the first time: on the horizontal axis, time is plotted, on the vertical — frequency, the brightness of the point corresponds to the amplitude with which the “imaginary tuning fork” vibrates at the corresponding frequency at the appropriate time. On the spectrogram of speech, the " formants " are always visible - dark horizontal lines, tortuous and intermittent; each formant corresponds to one of the resonant frequencies of the speech apparatus, and their vertical oscillations, respectively, to changes in these resonant frequencies in the process of speech.
As Suzy Styles explains , in the low frequency section up to 5 kHz, there are three formant in human speech, which is usually enough to recognize the sounds being heard. These three formants correspond to the vertical (F1) and horizontal (F2) position of the tongue, and the position of the lips (F3). Suzy gives a link to the Max Planck Society video , where the announcer who is in the MRI camera, says all the vowels and all the consonants in turn, so that the position of his speech organs when pronouncing each sound can be monitored directly.
')
And with the release of formants, according to Suzy, problems arise: the dark areas on the yanni / laurel spectrogram form a pattern of more than three bands that branch and intersect:
In particular, the lower band (F1) can be recognized either by a “hump up” or a “hump down”:
The first line corresponds to the high-low-high vowel sequence, i.e. [jæ-ɪ-]; the second is “low - high - medium”, i.e. [ao-ə-]. (In the figure of Suzy there is an obvious error: [u] is a high vowel, and cannot be at the end of the second sequence.) For F2, it is clear that the vowel sequence should be “front - middle - front”, i.e. again [jæ-ɪ-]. But if the listener's audio system suppresses frequencies between 2 and 3 KHz, then the listener “thinks” F2 based on F1, and receives a sequence of back-to-middle vowels, i.e. [-o-ə-]:
Suzy sums up her analysis: instead of three clear formant we see a confusion of dark spots that can be decrypted in one of two ways:
A slightly different analysis leads Carolyn MacGettigan. When it became known that the “ambiguous sound” was not designed by insidious linguists to bully normal people, but was taken from an online dictionary site , passed through not very high-quality speakers, and recorded with a not very high-quality microphone, then Carolyn compared the spectrograms of the original sound from the site , and the resulting "sound-illusion":
In the first sound, F1 and F2 are clearly visible, but very close; in the second, apart from adding weak noise, F1 and F2 merged into one formant, and the original F3 was perceived as F2. Carolyn notes that the “hump down” in F3 is the hallmark of English sound [ɹ]; and in the resulting sound, instead, it became perceived as a “hump down” in F2, i.e. as a sequence of vowels "front - middle - front" - notorious [jæ-ɪ-].
In addition to these two explanations of the illusion, linguists have suggested a few more. Benjamin Monsoon noticed that at high frequencies (5-9, 9-13, 13-17 KHz) weaker repeats F1-F3 are contained:
In human speech, such "repetitive formant" does not happen, so Benjamin blames them for the illusion. (This is most likely an artifact of audio compression used for “ambiguous sound.”)
NY Times - the discussion of illusion has even reached the point ! - also accuses of high-frequency amplification, which occurred during the dubbing:
Moreover, in their note they implemented an “interactive illusion” - a frequency filter, the setting of which can be smoothly changed by a slider so that anyone can be sure: if you amplify low frequencies and suppress high frequencies, then the sound turns into Laurel, if vice versa, then Yanny.
Using the occasion, I will mention here also my own acoustic-phonetic interactive piece , written on the knee under the inspiration of the long-standing quest from Meklon 'a. (I have never frontedder, and I will gladly accept PR with a more friendly UI.) This interactive piece allows you to draw on the spectrogram and listen in real time what kind of sound you get; in particular, you can take an existing sound and try to circle it with formants, or finish drawing new ones, or selectively erase any frequency range.
Source: https://habr.com/ru/post/371519/
All Articles