Deep Learning: Critical Evaluation
Summary
Although the roots of in-depth learning go back into the past for decades, neither the term “deep learning” itself, nor this approach, was so popular until such a new life was breathed new life into this area five years ago as has already become a classic 2012 study. for the authorship of Krizhevsky, Sutxever and Hinton on the Imagenet deep network model (Krizhevsky, Sutskever, & Hinton, 2012).
What was discovered in this area over the following years? Against the backdrop of impressive progress in areas such as speech recognition, image recognition and games, as well as considerable enthusiasm in the popular press, I would like to consider ten problems of in-depth learning (GO), and state that for creating artificial intelligence of general purpose (ION) HE must be complemented by other technicians.
1. Is God approaching its limit?
Most of the tasks in which the GO proposed fundamentally new solutions (vision, speech), in 2016-2017, entered the zone of diminishing returns.
Francois Cholet, Google, author of the Keras Neural Networks Library
')
"The progress of science moves from one funeral to another." The future depends on the student who is very suspicious of what I am saying.
Joff Hinton, the grandfather of deep learning
Although the roots of in-depth learning go back into the past for decades, very little attention was paid to him until around 2012. But that year everything changed drastically. A series of extremely influential articles was published - for example, the article by the authors Krizhevsky, Sutxever and Hinton “ImageNet classification using deep convolutional neural networks ”, which achieved advanced results in pattern recognition in a project known as ImageNet. Other laboratories have already worked on similar projects [Cireşan, Meier, Masci, & Schmidhuber, 2012]. Before the end of the year, GO hit the first page of The New York Times and quickly became the most famous technology from the world of AI. And if the basic idea of training neural networks containing multiple layers was not new, GO for the first time became a practically applicable technology, thanks, in particular, to an increase in computing power and data sets.
Since then, GO has led to a number of advanced results in areas such as pattern recognition, speech recognition, translation between languages, and plays an important role in a wide range of current applications. Corporations have already invested billions of dollars in the struggle for the talents of civil society. One of the well-known supporters of GO, Andrew Un , even suggested that “if an ordinary person can solve a problem by thinking about it for less than a second, we can probably automate its solution using AI either now or in the near future.” A recent article in the New York Times Sunday Magazine, mainly devoted to civil society, claims that the technology is designed to "re-invent the computation process itself." However, GO may well be approaching its limit, as I predicted earlier, at the beginning of the revival of this topic, and as people like Hinton [Sabour, S., Frosst, N., & Hinton, GE (2017) began to say. Dynamic Routing Between Capsules] and Chole [Chollet, F. (2017). Deep Learning with Python. Manning Publications] lately.
What is GO, and what did it demonstrate to us about the nature of the intellect? What can we expect from him, and when can we expect his failure? How close or far are we from “general purpose artificial intelligence” (IONI), and the point at which machines will begin to show people-like flexibility in solving unknown tasks? The purpose of this work is to keep the irrational growth of this topic and consider what we need to bring to this area in order to move it further.
This work is written both for researchers in this field, and for a growing number of AI consumers, who are not technically savvy, but who want to understand where this field is heading. Therefore, I will start with a small, not very technical introduction, aimed at explaining that systems with HE do well and why (section 2), before going on to assess the weaknesses of HE (section 3) and some fears, appearing due to misunderstanding of the possibilities of civil defense (section 4), and then ending on the prospects of moving forward (section 5).
GO is unlikely to disappear, and it is not necessary. But after five years from the moment of the revival of the region, it is not bad to critically examine the achievements, as well as what GO could not achieve.
2. What is deep learning and what does it do well?
First of all, GO is a statistical technique for classifying patterns based on test data using multilayer neural networks.
Neural networks described in the GO literature usually consist of a set of input modules that accept data such as pixels or words, sets of hidden layers (the more layers, the deeper the network) containing hidden modules (also known as nodes or neurons), and a set of output modules, taking into account the presence of connections between different nodes. In a typical case, such a network can be trained, for example, on a large set of handwritten numbers (these are input data in the form of images) and tags (output data) that define the categories to which the input data belong (this image is 2, it is 3, and so on).
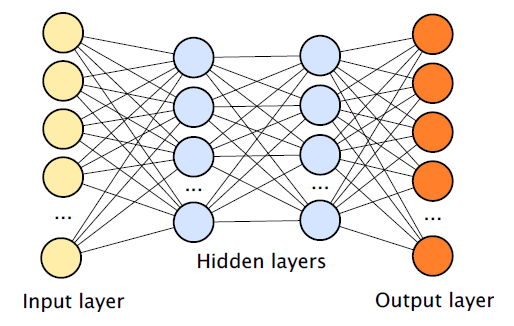
Over time, the error back-propagation algorithm allows the process, under the name of gradient descent, to correct connections between modules so that any input data leads to the output of the corresponding output data.
In general, the relationship between input and output, which the network studies, can be thought of as building a map of correspondence. Neural networks, especially those with many hidden layers, very well cope with the construction of the correspondence between input and output. These systems are usually described as neural networks, since input modules, hidden modules and output modules can be thought of as approximate models of biological neurons, albeit extremely simplified, and the connection between modules in some way represents the connections between neurons. A long-standing question that is outside the scope of this work concerns the degree of biological reliability of such artificial neural networks.
Most of the GO networks use a technology called “convolution”, which places such restrictions on network connections that they naturally have such a property as translational invariance. In essence, this idea is that an object can move around the image without losing its identity; the circle in the upper left corner can be considered the same object as the circle in the lower right corner (even without direct evidence of this).
In-depth training is also known for the ability to independently construct intermediate representations — for example, internal modules that respond to such things as horizontal lines or more complex image elements. In principle, with an infinite amount of data, GO systems can cope with any finite deterministic comparison between any input sets and the corresponding output, although in practice their ability to learn a certain comparison depends on many factors. One of the common problems is to please the local minimum, in which the system is stuck with a not quite optimal solution when there is no better solution in the number of nearby solutions. In practice, results with large data sets usually turn out quite good, and on a wide range of potential comparisons.
For example, in the field of speech recognition, a neural network learns to match a set of speech sounds and a set of tags (words or phonemes). When recognizing images, a neural network learns to match a set of images to a set of tags (for example, machine images are marked as machines). In the Atari game system being taught by the DeepMind network, neural networks learn the correspondence between pixels and joystick positions.
GO systems are most often used as classification systems, in the sense that the mission of a typical network is decisions about which set of categories (defined by the output modules of the neural network) this input belongs to. Using imagination, one can imagine that the possibilities of classification are enormous - the conclusion can be words, coordinates on the go board, and almost anything else. In the world of infinite data and infinite computing resources, other technologies are unlikely to be needed.
3. The boundaries of the possibilities of civil defense
The boundaries of civil society begin with denial: we live in a world in which there is no endless data. Systems that rely on GOs often need to generalize beyond the limits of certain data they have seen — be it a new pronunciation of a word or an image that is different from what the system has seen before. Where data is not infinitely much, the possibilities of formal evidence guaranteeing high quality of work are limited.
As discussed later in the article, a generalization can be of two kinds - interpolation between two well-known examples, and extrapolation, which requires going beyond the space of well-known training examples. In order for neural networks to generalize well, they usually require large amounts of data, and test data should be like training data, so that the new answers are interpolations between old ones. In the work of Krizhevsky, Satskever and Hinton, a convolutional neural network with nine layers, 60 million parameters and 650,000 nodes were trained on a million different examples, divided into a thousand categories.
This brute force approach worked well in the highly limited world of ImageNet, where all incentives can be diluted by a relatively small set of categories. It also works well in stable areas like speech recognition, in which patterns are consistently matched with a limited set of categories of speech sounds - but for many reasons, GO cannot be viewed (as is sometimes done in the popular press) as a general AI solution.
Here are ten problems that stand in the way of modern GO-systems.
3.1 The RP needs data
People are able to learn abstract connections several times. If I tell you that Smestre is a sister aged 10 to 21 years old, by giving you a single example, you can immediately figure out if you have Smestre, whether your best friend has one, or if your children have it. or parents and so on. (Most likely, your parents already don’t have it, even if it was, and you could understand that pretty quickly too).
Studying the notion of “smestre”, in this case - through a clear definition, you rely not on hundreds of thousands or millions of training examples, but on the ability to represent abstract connections between variables similar to algebraic ones. People are able to learn such abstractions, both through a precise definition, and through less obvious ones. Even seven-month-old babies are capable of this — they learn abstract rules, like language, based on a small number of unlabeled examples in just a couple of minutes (Marcus, Vijayan, Bandi, & Vishton, 1999). Subsequent work (Gervain and colleagues 2012) shows that babies are capable of similar calculations. At present, GO does not have a mechanism for learning abstractions through a direct definition given out loud, and it works better with thousands, millions or even billions of training examples, as DeepMind did with Atari games. According to Brenden Lake and colleagues in several recent papers, people learn complex rules much more effectively than GO systems (Lake, Salakhutdinov, & Tenenbaum, 2015; Lake, Ullman, Tenenbaum, & Gershman, 2016). On this topic, you can see more work (George et al 2017), and my own work with Steven Pinker on over-ordering errors in children compared to neural networks (Marcus et al., 1992).
Joff Hinton was also worried about how GO relied on a large number of marked examples, and expressed his concerns in a recent work on capsular networks with his co-authors (Sabour et al., 2017), noting that convolutional neural networks (the most popular GO architecture) can meet with “exponential inefficiency that can cause their death. A good candidate is the difficulties that convolutional networks encounter in generalizing new points of view (for example, a view of an object from a different perspective when visually recognizing patterns). The ability to cope with translational invariance is built into them, but with other typical transformations we have to choose between reproducing features detectors located on an exponentially growing lattice and increasing the size of the marked training set in a similar exponential way. ”
In tasks with a limited set of data, HE is often not the ideal solution.
3.2 In-depth training is still shallow and does not transfer the knowledge gained to other data.
Although GO is capable of some very surprising things, it is important to understand that the word “deep” refers to its technical, architectural feature (a large number of hidden layers used in modern neural networks, since their predecessors used only one layer), and not to conceptual (representation built in these networks cannot naturally be applied to any abstract concepts like "justice", "democracy" or "intervention").
Even more mundane things like "ball" or "opponent" may be inaccessible to the network. Consider an example of how DeepMind works with Atari games and reinforcement training , combining HE with reinforcement (the student tries to achieve the maximum reward). The results are supposedly fantastic: the system plays on an equal basis or beats people-experts on a wide range of games, using a single set of “hyper parameters” that control properties such as the rate of change of weights in the network, and not having preliminary knowledge of specific games and their rules. But these results are easy to interpret completely wrong. For example, according to one of the widely distributed videos about how the system learns to play Breakout, “after 240 minutes of training, the system realized that organizing a tunnel in the wall is the most effective way to achieve victory.”
But the system did not understand anything, it does not understand at all what a tunnel is and what a wall is. She simply learned certain actions for certain situations. Transfer tests - in which the GO system with reinforcements is put in situations slightly different from those on which the system has been trained, shows that GO solutions are often artificial. For example, a team of researchers from Vicarious showed that the more advanced descendant of the Atari system, the A3C [Asynchronous Advantage Actor-Critic], failed to cope with various non-critical changes in the Breakout game (Kansky et al., 2017), such as changing the vertical position of the platform, batting the ball, or the appearance of a wall in the middle of the screen. From these demonstrations it becomes clear that it is impossible to assign a system that uses HE with reinforcements, the ability to understand what a platform is or what a ball is. Such statements in comparative psychology are called attribution errors. The point is not that the Atari system in fact somehow understood the concept of the wall - the system simply artificially made its way through the wall within the framework of a small set of conditions for which it was trained.
My own team of researchers from a Geometric Intelligence startup (later purchased by Uber) found similar results in the context of a slalom game. In 2017, a team of researchers from Berkeley and OpenAI showed that in other games it is easy to create similar competitive examples that confuse not only the original algorithm DeepMind, DQN, but also its follower A3C and several other similar technologies (Huang, Papernot, Goodfellow, Duan, & Abbeel, 2017).
Recent experiments (Robin Jia and Percy Liang, 2017) come to the same conclusion in another area: language work. Various neural networks were trained to search for answers to questions in a problem known as SQuAD (Stanford Question Answering Database), in which the purpose is to highlight words in a certain phrase that correspond to a given question. For example, in one case, the trained system was impressively correct, determined the quarterback from the winning Super Bowl XXXIII team, like John Elway, on the basis of studying a small paragraph. But Gia and Liyan showed that simply inserting suggestions that were distracting from the topic (for example, about the alleged victory of Jeff Dean in another game of the series) led to a collapse in the quality of the system. In 16 models, the median success rates fell from 75% to 36%.
As is often the case, the patterns extracted by GO turned out to be much more artificial than it seems initially.
3.3 GO has no natural way of working with hierarchical structure.
The linguist Noam Chomsky would not be surprised at the problems described by Jia and Liyan. In fact, most of the current GO-based language models represent sentences in the form of sequences of words, despite the fact that Chomsky has long said that the language has a hierarchical structure in which larger constructions are recursively composed of smaller ones.For example, in the sentence “a teenager who previously crossed the Atlantic, set a record for round-the-world flights”, the main simple sentence in the complex will be “a teenager who has established a record of round-the-world flights”, and the additional sentence “previously crossed the Atlantic” will be built in, specifying teenager.
In the 1980s, in one paper (Fodor and Pylyshyn, 1988), similar problems with earlier versions of neural networks were described. In my work (Marcus, 2001), I suggested that simple recurrent networks (SRN is the forerunner of modern, more complex GO networks known as RNN) can hardly systematically present and expand the recursive structure of various types of unfamiliar sentences.
And in 2017, scientists (Brenden Lake and Marco Baroni, 2017) checked whether these pessimistic assumptions are true. As they wrote in the title of the work, modern neural networks "after all these years are still not systematic." RNNs can “summarize data fairly well with small differences in training and verification data, but when a synthesis requires systematic compositional skills, the RNN fail miserably.”
The same problems may appear in other areas, for example, when planning or controlling motor skills in which work with a complex hierarchical structure is necessary, especially if the system is doomed to face new situations. Indirect evidence of such situations can be seen in the problems with the transfer of Atari games mentioned above, and more generally in the field of robotics, in which systems usually do not cope with the generalization of abstract plans in unusual situations.
The main problem today is that GO is learning the correlations between a set of features that are “flat”, non-hierarchical in themselves — something like a simple, unstructured peer-to-peer list. Hierarchical structure (for example, syntactic trees that separate the main and subordinate sentences) in such systems are not represented either directly or internally. As a result, GO-systems are forced to use sets of various intermediaries that end up inadequate - for example, the position of a word in a sentence in order from the beginning.
Systems such as Word2Vec (Mikolov, Chen, Corrado, & Dean, 2013), representing individual words in the form of vectors, achieve modest success. Some systems that use ingenious stunts try to present complete sentences in vector spaces suitable for HO (Socher, Huval, Manning, & Ng, 2012). But, as Lake and Baroni’s experiments clearly demonstrated, recurrent networks remain limited in their ability to reliably represent and generalize rich structures.
3.4 HO still struggles with imprecisely defined concepts
If you cannot explain such nuances as the difference between “John promised Mary to leave” and “John promised to leave Mary”, you cannot draw conclusions about who leaves and who will be next. Today's machine-readable systems have achieved some success in tasks such as SQuAD, where the answer to this question is directly contained in the text, but much less success in problems in which the conclusions go beyond what is contained in the text — by combining or a few sentences ( multi-valued conclusions), or a combination of sentences with additional knowledge that are not indicated in this text sample. When reading a text, people often draw rather broad conclusions, not following from the text, on the basis of what is mentioned only indirectly - for example, conclusions about the character of a character made on the basis of an indirect dialogue.
And although the work of Bowman and colleagues (Bowman, Angeli, Potts, & Manning, 2015; Williams,
Nangia, & Bowman, 2017) made several important steps in this direction, there is currently no GO system capable of making unobvious conclusions based on knowledge of the real world with accuracy, somehow approaching the human.
3.5 HO is still not transparent
The relative transparency of the black box-based neural networks is one of the main topics discussed in the past few years (Samek, Wiegand, & Müller, 2017; Ribeiro, Singh, & Guestrin, 2016). In the current implementation, GO systems have millions and even billions of parameters defined by developers not in the form of some human-readable lists of variables used by canonical programmers (such as “last_character_typed”), but in the form of their geography within a complex network (the value of node i in layer j in the network module k). Although certain steps were taken to visualize the contributions of individual network nodes in complex networks (Nguyen, Clune, Bengio, Dosovitskiy, & Yosinski, 2016), most observers recognize that neural networks in general remain “black boxes”.
What it matters in the long run remains unclear (Lipton, 2016). If the systems themselves are sufficiently reliable and independent, this may not matter; if it is important to use them in contexts of more complex systems, it may be critical for the possibility of finding errors.
The problem of transparency, which has not been solved so far, is a potential vulnerability in the use of civil defense in areas such as financial transactions or medical diagnoses, in which people using them would like to understand exactly how this system arrived at this solution. As Catherine O'Neill (2016) pointed out, such opacity can also lead to serious distortions.
3.6 HO is poorly integrated with already existing knowledge.
The main approach to civil defense is interpretative, that is, self-sufficient and isolated from the other collected knowledge, which in principle could be useful. Working with civil engineering is to find a training database - a set of input data associated with relevant output data - and teach the network everything that is required to solve a problem, learning the relationships between input and output data using tricky architectural options and technologies. to clean and add data set. The application of previous knowledge available for this task, with rare exceptions (for example, convolutional restrictions of networks, LeCun, 1989), has been minimized.
Thus, for example, the system used in the work of Lerer and colleagues (Lerer et al, 2016), trying to learn the physics of falling towers, does not have previous knowledge of physics (except as defined in the roll-up). Newton's laws are not sewn into her program; instead, the system builds their approximation (within certain limitations), studying the consequences based on raw pixel data. As I note in my next work, GO researchers suffer from cognitive distortion that prohibits the use of previous knowledge, even when they are well known (as is the case with physics).
It is also unclear how you can integrate existing knowledge into the GO system in the general case; in particular, because the knowledge presented in such systems is mainly reduced to (mostly non-transparent) correlations between features, and not to abstractions of quantitative postulates (such as, for example, “all people are mortal”).
The related problem grows out of the culture that has developed in the field of Defense, encouraging competition in solving self-contained, closed problems that do not require general knowledge. This trend is well demonstrated by the MO competition platform called Kaggle, where participants compete to get the best results on a given set of data. All that they need to solve the problem is neatly assembled and packaged, along with all the relevant files for the input and output data. In such cases, excellent progress has been made - speech recognition and some features of image recognition can in principle be solved using the Kaggle paradigm.
The problem, however, is that life is not a Kaggle competition; children do not receive all the data they need, neatly placed in one directory of the disk. Learning in the real world involves a much more random data entry, and no one carefully packs tasks. GO works well with such tasks as speech recognition, where there are a lot of labeled examples, but hardly anyone knows how to apply GO to problems with fuzzy parameters. What is the best way to repair a bike that got a rope on the spokes? For what specialty should I go for a diploma, in mathematics or neuroscience? No set of training data will give us the answers.
Problems that are less associated with categorization and more - with common sense lie outside the scope of the applicability of HE, and so far, as far as I know, there is little that can offer to solve such problems. In a recent review of common sense, Ernie Davies and I began with a set of simple conclusions that people can easily draw without any direct training — for example, who is taller, Prince William or his baby son, Prince George? Can I make a salad from a synthetic T-shirt? If you stick a pin in a carrot, where does a hole appear - in a carrot or in a pin?
As far as I know, nobody tried to tackle such tasks with the help of GO. Such, at first glance, simple tasks require integrated knowledge from disparate sources, therefore they are so far removed from the cozy world of the GO classifications. They make you think that, in order to achieve human level of cognitive flexibility, along with HE, tools of a completely different kind are required.
3.7 HO is not yet able to automatically distinguish a causal link from a correlation
The fact that causation is not synonymous with correlation is a truism, but this difference seriously worries the specialists in the field of civil defense. Roughly speaking, GO learns the complex correlations between input and output features, but does not build representations of cause-effect relationships. GO can easily learn the correlation between growth and vocabulary in a population, but it will not be easy for him to imagine the way in which this correlation is derived from human growth and development (children grow up and learn more and more words, but this does not mean grow because of the learning of words). Causality was the basis in some other approaches to creating AI (Pearl, 2000), but probably GO is not adapted to such tasks, and almost no one tried to solve them in this area.
3.8 The HO represents a largely stable world, and in such a way that in some cases it may present problems.
The logic of the HO is such that it will rather work well in very stable worlds — for example, in the go game, whose rules do not change, and working worse in constantly changing systems like politics and economics. Regarding the use of HO for tasks such as stock pricing, there is a high probability that this approach will repeat the fate of the Google Flu Trends project, which originally predicted epidemiological data on search queries perfectly well, and then completely missed things like the peak of the 2013 flu season (Lazer , Kennedy, King, & Vespignani, 2014).
3.9 HO still works well as an approximation, but its answers can often not be completely trusted.
Partly as a result of the other problems described in this section, GO systems work well on a large part of the tasks in a selected area, but they are easily deceived.
A growing set of works demonstrates this vulnerability — from the linguistic examples of Gia and Liyang mentioned above to a wide range of computer vision demonstrations when GO systems confuse images colored in yellow-black stripes with school buses (Nguyen, Yosinski, & Clune, 2014), and the taped parking pointers with well-packed refrigerators (Vinyals, Toshev, Bengio, & Erhan, 2014) - despite the fact that in other cases the performance of the selected systems is impressive.
Of recent errors, we can mention slightly damaged stop signs from the real world, which the system confused with speed limit signs (Evtimov et al., 2017), and turtles printed on a 3D printer, which were confused with guns (Athalye, Engstrom, Ilyas, & Kwok, 2017). In recent news flashed a story about the problems of the British police, whose system is difficult to distinguish the image of nudity from the sand dunes.
The opportunity to deceive the GO system was probably first mentioned in the work of Tsegeda (Szegedy et al, 2013). Four years later, despite active research, no reliable solution to this problem was found.
3.10 In-depth training is difficult to use for applied purposes.
One more fact that follows from all the problems mentioned is that HE is not suitable for reliable solution of applied problems. As a team of authors from Google wrote in 2014, in the title of an important essay that was never answered (Sculley, Phillips, Ebner, Chaudhary, & Young, 2014), MO is “a credit card with technical debt and high percent, ”which means that systems that operate on a limited set of conditions are fairly easy (achieving short-term goals), but it’s very difficult to guarantee that they will work in other conditions with unknown data that may not resemble previous training data (long-term goals especially when one si theme is used as an element of another, larger).
In an important report at ICML, Leon Botto in 2015 compared the MO to the development of the aircraft engine, and noted that although the development of aircraft is based on building complex systems from many simple systems for which it is possible to obtain guarantees of reliable operation, the MO lacks the ability to give similar guarantees. As Peter Norvig from Google noted in 2016, the MO lacks the incrementality, transparency and the ability to find errors inherent in classical programming, and in the MO the certain simplicity of the work is changed to the presence of serious problems with reliability.
Henderson and colleagues recently expanded this view by concentrating on civil defense with reinforcements, and noting several serious problems in areas related to reliability and reproducibility (Henderson et al., 2017).
Although some progress has been made in automating the development of MO systems (Zoph, Vasudevan, Shlens, & Le, 2017), much remains to be done.
3.11 Discussion
Of course, deep learning, in itself, is just mathematics; The problems described above do not appear because the underlying mathematics is somehow mistaken. In general, GO is a great way to optimize complex systems to represent the relationship between input and output data on a fairly large data set. The real problem is misunderstanding of why GO fits well and for what it does not. The technique copes well with the problems of a clear classification, in which a wide range of potential signals must be marked out according to a limited number of categories, given that the system has enough data, and the test set resembles a training one.
But deviations from these assumptions can lead to problems; GO is only a statistical technology, and all statistical technologies suffer from deviations from the initial assumptions.
HO systems do not work as well anymore, if there is not very much data for training, or if the test set differs in important things from training, or if the set of test cases is wide and filled with completely new things. And some problems in the real world in general can not be attributed to the problems of classification. For example, the understanding of a natural language cannot be approached as a task of classifying the construction of correspondence between a large finite set of sentences and a large, finite set of other sentences. Rather, it is a markup of correspondence between a potentially infinite set of incoming sentences, and a set of meanings of the same size, many of which might not have been previously encountered. In such a task, GO becomes a square peg that is driven into a round hole — a rough approximation in the casewhen the solution must be somewhere else.
One good way to intuitively understand why something is missing is to consider a set of experiments that I conducted in 1997, when I tested some simplified aspects of language development in the neural network class that was then popular in cognitive science. The vintage networks of 1997 were, of course, simpler than today's models - they did not use more than three layers (the input nodes were connected to hidden nodes connected to the weekend), and they lacked convolutional technologies. But they also worked with backward propagation of errors, like today's, and also depended on the training data.
In language, the main thing is generalization. As soon as I hear a sentence like "John saw Mary's ball," I can conclude that it would be grammatically correct to say that "John saw Mary the ball, and Eliza saw the ball Aleku." In the same way, by concluding that the word “pickknight” means, I can understand the meaning of future sentences, even if I have not heard them before.
Reducing a wide range of language problems to a simple example, which, it seems to me, is still relevant today, I conducted a series of experiments in which I trained three-layer perceptrons (in today's jargon — completely related, without convolutions) to the identity function, f (x) = x, that is, for example, f (12) = 12.
Training examples were represented by a set of input nodes (and corresponding output), representing the numbers as binary numbers. The number 7, for example, was represented by the inclusion of input (and output) nodes representing 4, 2 and 1. As a test of generalization, I trained the network on different sets of even numbers, and checked on all possible data, both even and odd.
Every time I conducted an experiment with a wide range of parameters, the result was the same: the network (if not stuck in the local minimum) correctly applied the identity function to even numbers that I had met before (say, 2, 4, 8 and 12) , and to some other even numbers (suppose, 6 and 14), but did not cope with any odd number, giving, for example, f (15) = 14.
In general, the neural networks I tested could learn training examples and interpolate them for test examples located in the point cloud surrounding these examples in n-dimensional space (called my training space), but could not extrapolate beyond the training space.
Odd numbers were outside the training space, and the network could not generalize identity beyond this space. The increase in the number of hidden nodes did not help, as did the increase in the number of hidden layers. Simple multilayer perceptrons simply could not build generalizations outside the training space (Marcus, 1998a; Marcus, 1998b; Marcus, 2001).
The paper shows that the problems of generalization beyond the limits of the space of training examples remain with the current GO-networks, almost 20 years later. Many of the problems discussed in this article — greed for data, vulnerability to deception, problems with fuzzy conclusions and transference — can be considered an extension of the fundamental problem. Modern neural networks work well with tasks that do not go far away from the basic training data, but begin to act up in cases that are moving away to the periphery.
The popular addition of convolutions guarantees the solution of one particular class of problems similar to my identity problem: the so-called. translational invariance, in which the object retains its identity even when the location changes. But this decision is not common, as recent demonstrations of Lake show. Another way to solve problems with GO is to expand the data set, but such attempts work better in two-dimensional vision than with language.
Yet for GO, there is not yet a general solution to the problem of generalization outside the training space. And it is for this reason that we need to look for different solutions, if we want to achieve the creation of ION.
4. Potential risks of excessive hype
One of the greatest risks of current AI-related hype is another “winter of AI,” like the one that destroyed this area in the 1970s, after a report by Lighthill (1973), where it was assumed that AI is too fragile, narrowly focused, and artificial so that it can be used in practice. And although now there are more practical applications for AI than in the 1970s, the hype remains a cause for excitement. When an influential figure such as Andrew Eun, in the Harvard Business Review makes promises of imminent automation that does not correspond to reality, there is a risk of failure of expectations. Machines cannot, in fact, do a lot of things that ordinary people can do in a second, starting from a reliable awareness of the world and ending with an understanding of sentences. No healthy person will confuse a turtle with a gun, and a parking sign with a refrigerator.
Directors throwing investments in AI may be disappointed, especially given the poor state of the natural language understanding area. Already, many large projects are canceled, for example, the M project from Facebook, launched in August 2015, and widely advertised as a general-purpose personal assistant, and then relegated to a much smaller role as an assistant in a small set of well-defined tasks like adding an entry to the calendar.
You can confidently say that chatbot did not justify the hype that they received a couple of years ago. If, for example, robomobils also disappoint the public, and, in contrast to the hype, turn out to be unreliable after a massive market entry, or simply don’t turn out to be completely autonomous after so many promises, the whole area of AI can stop abruptly and lose popularity and funding. We can already see hints of such a development, as in an article in the magazine Wired entitled “After the peak of the hype robobomi fell into a failure of disappointment”.
There are other serious concerns, and not only apocalyptic (the latter, by the way, remains in the field of science fiction). Personally, I am most worried that the AI area may be stuck in a local minimum, too much deviated into the wrong part of the intellectual space, concentrating too much on a detailed class of available, but limited models based on solving easily accessible problems — ignoring the more risky deviations from the route that in the end, can lead us to a more reliable path.
I recall the famous (even if outdated) censure by Peter Thiel of the often too narrow-minded technology industry: " We wanted to see flying cars, but we received a limit of 140 characters"I still dream of Rosie-Robot [Dzhetsony of the mid-20th century / house robot from the mid-20th century / approx. Transl.] - a home robot capable of any work that would take care of my home. But for now, after six decades of AI development , our bots do almost nothing more serious than playing music, sweeping the floors and clicking on advertisements.
It’s a pity if progress doesn’t go further. The AI has risks, but also great potential benefits. In my opinion, the greatest contribution of AI to societies should be the automation of scientific discoveries, which, among rochego, will lead to the emergence of a much more complex medical care options than exist today. But for this we need to make sure that this area of research does not get stuck in a local minimum.
5. What can be improved?
Despite all the problems I have outlined, I do not think that GO should be cast. We need to change its concept: it is not a universal solvent , but simply one of many tools, a powerful screwdriver in a world where hammers, wrenches and pliers are needed, not to mention chisels, drills, voltmeters, logical probes and oscilloscopes. In the classification of perception, where there is a huge amount of data, GO will be a powerful tool; in other more affluent areas of cognitive science, it will not work as well. The question is, where else should we look? Here are some of the features.
5.1 Spontaneous learning
In an interview, both GO pioneers Geoff Hinton and Yann Lekun recently pointed to spontaneous learning as one of the ways to go beyond controlled education of GO, which is demanding to the amount of data.
I will specify that GO and CO are not opposed to each other. GO is usually used in a controlled context with marked up data, but there are ways to use GO and spontaneously. But undoubtedly, in many areas there are reasons for departing from a request for a massive amount of data usually required for a controlled entity.
The terms CO, or unsupervised learning, usually denote several types of systems. One common type “accumulates” together input data that has
similar properties, even if they are not clearly marked. The Google Cat Recognition Model (Le et al., 2012) may be the most famous example of this approach.
Another approach advertised by researchers (Luc, Neverova, Couprie,
Verbeek, & LeCun, 2017), not excluding the first one - replacing sets of labeled data with things like movies that change over time. The idea is that video-trained systems can use any pair of consecutive frames as an ersatz signal in training, the purpose of which is to predict the next frame; frame t becomes the prediction for frame t 1 , without any need for a person to put labels.
It seems to me that both of these approaches are useful, but by themselves do not solve the problems described in section 3. The system is still greedy for the data, it lacks explicit labels, and this approach does not offer something that could move us towards uncertain conclusions, interpretability or ease in finding errors.
There is, however, a different approach to unsupervised learning, which seems to me very interesting: the approach practiced by human children. Children often set themselves a new task - to build a tower of Lego cubes, to crawl through a small space, like my daughter recently tried to crawl through a chair - between the seat and the back. When solving problems of this kind, the study of space often uses self-assignment of tasks (what should I do?) And solving high-level problems (how can I stick my hand through a chair if everything else has already crawled through?) And the integration of abstract knowledge what sizes and tolerances different objects have, and so on). If we can create systems capable of setting our own goals, reasoning and solving problems on a more abstract level, very rapid and qualitative progress can follow.
5.2 Symbolic manipulation and the need for hybrid models
Another direction of the search should be the study of the classic, " symbolic AI ", which is sometimes called the GOFAI [Good Old-Fashioned AI - "good, old AI"]. Symbolic AI is based on an idea central to mathematics, logic and computer science - the representation of abstractions using symbols. Equations like F = ma allow us to calculate the output based on a wide range of input data, regardless of whether we have seen any particular values before; computer program lines do the same (if x is greater than y, perform step a).
By themselves, symbolic systems are often fragile, but they were mostly developed in an era when data and computing power was much less than today. Today, the right step would be to integrate HO, perfectly coping with perceptual classification, with symbolic systems that work well with conclusions and abstractions. This union can be considered an analogy to the brain; Perceptual input systems, like the somatosensory cortex, do something similar to GO, but there are other parts of the brain, such as the prefrontal cortex and Broca's center , that work, apparently, at the highest level of abstraction. The power and flexibility of the brain comes, in particular, from its ability to dynamically integrate direct sensory information with complex abstractions relating to objects and their properties, light sources, and so on.
There are already several seductive steps towards integration, including neurosymbolic modeling (Besold et al., 2017) and the recent trend towards creating systems such as differentiable neurocomputers (Graves et al., 2016), programming with differentiable interpreters (Bošnjak, Rocktäschel, Naradowsky , & Riedel, 2016), and neuroprogramming with discrete operations (Neelakantan, Le, Abadi, McCallum, & Amodei, 2016). And although these works have not yet reached full-scale ION, I have long argued (Marcus, 2001) that the integration of operations similar to what happens in microprocessors in a neural network can be extremely useful.
From the point of view that the brain can be viewed as “a wide range of reusable computing primitives — elementary processing modules, similar to a set of basic instructions in a microprocessor — perhaps connected together in parallel, as in a customizable integrated circuit, known as a programmable gate array , "as I described in another paper (Marcus, Marblestone, & Dean, 2014), the enrichment steps to a set of instructions that comprise our computational system must go on benefit.
5.3 More ideas from cognitive and developmental psychology
Another potentially fruitful place to look is human cognitive abilities (Davis & Marcus, 2015; Lake et al., 2016; Marcus, 2001; Pinker & Prince, 1988). Machines do not have to literally reproduce the human mind, which, generally speaking, is error-prone and not perfect. But there remain many areas, from understanding natural language to common sense, in which people have an advantage. Studying the mechanisms underlying these human strengths can lead to breakthroughs in AI, even if the goal is not, and should not, be accurate reproduction of the human mind.
For many, learning by example means neurobiology; from my point of view, this is a premature conclusion. We still do not know enough in the field of neurobiology to perform brain reengineering, and it may not be known for several decades in a row — probably until AI improves. AI can help us decipher the work of the brain, and not vice versa.
In any case, at this time it should be possible to use technologies and ideas drawn from cognitive and developmental psychology to create more reliable and comprehensive AI and models supported not only by mathematics, but also by certain properties of human psychology.
A good starting point can be an understanding of the internal mechanisms of the human mind, and using them as hypotheses to create mechanisms that may be useful for developing AI. In another article that I am still preparing, I present a selection of possibilities, some of which were obtained from my earlier studies (Marcus, 2001), and others from the works of Elizabeth Spelka (Spelke & Kinzler, 2007). The opportunities taken from my work focus on the representation and manipulation of information, such as character mechanisms, representing variables and differences between types and members of a class; Spelke borrowed a concentration on how babies can imagine such things as space, time, and object.
The second point of focus can be an understanding of common sense, how its workings out (a part of it can be innate, a rather large portion — learned), how it is presented, how it fits into the process of our interaction with the real world (Davis & Marcus, 2015). Lerer's recent work (Lerer et al, 2016), Watters with colleagues (Watters and colleagues, 2017), Tenenbaum with colleagues (Wu, Lu, Kohli, Freeman, & Tenenbaum, 2017) and mine with Davis (Davis, Marcus, & Frazier -Logue, 2017) offer some rival approaches to how to comprehend it, working in the field of everyday physical reasoning.
The third point may be a person's understanding of stories - this idea has long been suggested (Roger Schank and Abelson, 1977), and it is time to refresh it (Marcus, 2014; Kočiský et al., 2017).
5.4 More challenging tasks
Whether GO remains in its current form, turns into something new, or disappears altogether - in any case, it is necessary to consider a set of problems pushing systems to develop beyond what can be learned in the framework of the paradigm of controlled learning on large data sets. Here are a few considerations, some of which are taken from an article in AI Magazine, dedicated to going beyond the Turing test, which I edited with colleagues (Marcus, Rossi, Veloso - AI Magazine, & 2016, 2016):
- The task of comprehension (Paritosh & Marcus, 2016; Kočiský et al., 2017), which will require the system to view arbitrary videos (reading text, listening to a podcast) and answering fuzzy questions about what was contained in it. (Who is the main character? What is his motivation? What will happen if his rival succeeds?) No specially prepared set of training data can cover all possible cases; it will require the ability to draw conclusions and knowledge about the real world.
- Scientific reasoning and understanding, such as is given in the tasks of the Allen AI institute for the eighth grade (Schoenick, Clark, Tafjord, P, & Etzioni, 2017; Davis, 2016). And although the answers to some basic questions about science can simply be found on the Internet, others will require conclusions that are beyond what was directly announced and links to general knowledge.
- Participating in games of various kinds (Genesereth, Love, & Pell, 2005) with knowledge transfer between games (Kansky et al., 2017), so that, for example, knowledge gained from learning a first-person shooter game can improve in another similar game of a completely different appearance, with different equipment and so on. It is not suitable for a system capable of learning the game of many games separately, without transferring between them, as the Atari game system from DeepMind does - the point is to collect the accumulating knowledge that can be transferred.
- Physical testing of an AI-controlled robot for the construction of any things (Ortiz Jr, 2016), from tents to IKEA shelters, based on instructions and interaction with real-world objects, instead of a vast number of attempts to learn by trial and error.
Any one task will not be enough. Natural intelligence is multidimensional (Gardner, 2011), and, given the complexity of the world, ION should also be multidimensional.
Going beyond the perceptual classification, and moving into a wider integration of conclusions and knowledge, AI can move very forward.
6. Conclusion
To understand the progress that is taking place in this area, one can consider a rather pessimistic article that I wrote for The New Yorker 5 years ago, where the following conclusion was made: “HE is only part of the larger task of creating intelligent machines”, because “such technologies lack representations of cause-effect relationships (such as the relationship between diseases and their symptoms), and it will also be very difficult for them to cope with such abstract concepts as “close relatives” or “identity”. They have no obvious ways to build logical conclusions, and they are far from integrating abstract knowledge, such as what objects are, what they are for, how they are usually used. ”
As we have seen, many of these concerns remain relevant, despite the general progress in certain areas such as speech recognition, machine translation and board games, and impressive progress in the area of accessible computing infrastructure and data volume.
Interestingly, in the past year, more and more scientists began to rest on similar restrictions. Partial list includes Brenden Lake and Marco Baroni (2017), François Chollet (2017), Robin Jia and Percy Liang (2017), Dileep George and others at Vicarious (Kansky et al., 2017) and Pieter Abbeel and colleagues at Berkeley (Stoica et al., 2017).
Perhaps the most notable act will be the change of one’s own opinion by Joffin Hinton, who, in an interview on the Axios website, admitted that he had “deep doubts” about the effectiveness of the back-propagation method of error, a key feature of HE, which he himself helped to develop, since he was concerned about this dependence method from a set of labeled data. Instead, he suggested that "you may have to invent completely new methods."
I share with Hinton a joyful anticipation of future progress in this area.
List of works mentioned
- Athalye, A., Engstrom, L., Ilyas, A., & Kwok, K. (2017). Synthesizing Robust Adversarial Examples. arXiv, cs.CV.
- Besold, TR, Garcez, AD, Bader, S., Bowman, H., Domingos, P., Hitzler, P. et al. (2017). Neural-Symbolic Learning and Reasoning: A Survey and Interpretation. arXiv, cs.AI.
- Bošnjak, M., Rocktäschel, T., Naradowsky, J., & Riedel, S. (2016). Programming with a Differentiable Forth Interpreter. arXiv.
- Bottou, L. (2015). Two big challenges in machine learning. Proceedings from 32nd International Conference on Machine Learning.
- Bowman, SR, Angeli, G., Potts, C., & Manning, CD (2015). A large annotated corpus for learning natural language inference. arXiv, cs.CL.
- Chollet, F. (2017). Deep Learning with Python. Manning Publications.
- Cireşan, D., Meier, U., Masci, J., & Schmidhuber, J. (2012). Multi-column deep neural network traffic traffic traffic classification. Neural networks.
- Davis, E., & Marcus, G. (2015). Commonsense reasoning and commonsense knowledge in artificial intelligence. Communications of the ACM, 58 (9) (9), 92-103.
- Davis, E. (2016). How to Write Science Questions. AI magazine, 37 (1) (1), 13-22.
- Davis, E., Marcus, G., & Frazier-Logue, N. (2017). Commonsense reasoning about containers using radically incomplete information. Artificial Intelligence, 248, 46-84.
- Deng, J., Dong, W., Socher, R., Li, LJ, Li-Computer Vision and, K., & 2009 Imagenet: A large-scale hierarchical image database. Proceedings from Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on.
- Elman, JL (1990). Finding structure in time. Cognitive science, 14 (2) (2), 179-211.
- Evtimov, I., Eykholt, K., Fernandes, E., Kohno, T., Li, B., Prakash, A. et al. (2017). Robust Physical World Attacks on Deep Learning Models. arXiv, cs.CR.
- Fodor, JA, & Pylyshyn, ZW (1988). Connectionism and cognitive architecture: a critical analysis. Cognition, 28 (1-2) (1-2), 3-71.
- Gardner, H. (2011). Frames of mind: The theory of multiple intelligences. Basic books.
- Gelman, SA, Leslie, SJ, Was, AM, & Koch, CM (2015). Children's interpretations of general quantifiers, specific quantifiers, and generics. Lang Cogn Neurosci, 30 (4) (4), 448-461.
- Genesereth, M., Love, N., & Pell, B. (2005). General game playing: Overview of the AAAI competition. AI magazine, 26 (2) (2), 62.
- George, D., Lehrach, W., Kansky, K., Lázaro-Gredilla, M., Laan, C., Marthi, B. et al. (2017). A high-performance text-based CAPTCHAs. Science, 358 (6368) (6368).
- Gervain, J., Brent, I., & Werker, JF (2012). Binding at birth. J Cogn Neurosci, 24 (3) (3), 564-574.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
- Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwinska, A. et al. (2016). Hybrid computing using a neural network with dynamic external memory. Nature, 538 (7626) (7626), 471-476.
- Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., & Meger, D. (2017). Deep Reinforcement Learning that Matters. arXiv, cs.LG.
- Huang, S., Papernot, N., Goodfellow, I., Duan, Y., & Abbeel, P. (2017). Adversarial Attacks on Neural Network Policies. arXiv, cs.LG.
- Jia, R., & Liang, P. (2017). Adversarial Examples for Evaluating Reading Comprehension Systems. arXiv.
- Kahneman, D. (2013). Thinking, fast and slow (1st pbk. Ed. Ed.). New York: Farrar, Straus and Giroux.
- Kansky, K., Silver, T., Mély, DA, Eldawy, M., Lázaro-Gredilla, M., Lou, X. et al. (2017). Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics. arXIv, cs.AI.
- Kočiský, T., Schwarz, J., Blunsom, P., Dyer, C., Hermann, KM, Melis, G. et al. (2017). The NarrativeQA Reading Comprehension Challenge. arXiv, cs.CL.
- Krizhevsky, A., Sutskever, I., & Hinton, GE (2012). Imagenet classification with deep convolutional neural networks. In (pp. 1097-1105).
- Lake, BM, Salakhutdinov, R., & Tenenbaum, JB (2015). Human-level concept of learning through a probabilistic program induction. Science, 350 (6266) (6266), 1332-1338.
- Lake, BM, Ullman, TD, Tenenbaum, JB, & Gershman, SJ (2016). Building Machines. Behav Brain Sci, 1-101.
- Lake, BM, & Baroni, M. (2017). Still not having systematic recurrent networks. arXiv.
- Lazer, D., Kennedy, R., King, G., & Vespignani, A. (2014). Big data. The parable of Google Flu: traps in big data analysis. Science, 343 (6176) (6176), 1203-1205.
- Le, QV, Ranzato, M.-A., Monga, R., Devin, M., Chen, K., Corrado, G. et al. (2012). Building high-level features using large scale unsupervised learning. Proceedings from International Conference on Machine Learning.
- LeCun, Y. (1989). Generalization and network design strategies. Technical Report CRG-TR-89-4.
- Lerer, A., Gross, S., & Fergus, R. (2016). Learning Physical Intuition of Block Towers by Example. arXiv, cs.AI.
- Lighthill, J. (1973). Artificial Intelligence: A General Survey. Artificial Intelligence: a paper symposium.
- Lipton, ZC (2016). The Mythos of Model Interpretability. arXiv, cs.LG.
- Lopez-Paz, D., Nishihara, R., Chintala, S., Schölkopf, B., & Bottou, L. (2017). Discovering causal signals in images. Proceedings from Computer Vision and Pattern Recognition (CVPR).
- Luc, P., Neverova, N., Couprie, C., Verbeek, J., & LeCun, Y. (2017). Predicting Deeper into the Future of Semantic Segmentation. International Conference on Computer Vision (ICCV 2017).
- Marcus, G., Rossi, F., Veloso - AI Magazine, M., & 2016. (2016). Beyond the Turing Test. AI Magazine, Whole issue.
- Marcus, G., Marblestone, A., & Dean, T. (2014). The atoms of neural computation. Science, 346 (6209) (6209), 551-552.
- Marcus, G. (in prep). Innateness, AlphaZero, and Artificial Intelligence.
- Marcus, G. (2014). What Comes After the Turing Test? The New Yorker.
- Marcus, G. (2012). Is “Deep Learning” a Revolution in Artificial Intelligence? The New Yorker.
- Marcus, GF (2008). Kluge: the haphazard construction of the human mind. Boston: Houghton Mifflin.
- Marcus, GFGF (2001). The Algebraic Mind: Integrating Connectionism and cognitive science. Cambridge, Mass .: MIT Press.
- Marcus, GF (1998a). Rethinking eliminative connectionism. Cogn Psychol, 37 (3) (3), 243-282.
- Marcus, GF (1998b). Can connectionism save constructivism? Cognition, 66 (2) (2), 153-182.
- Marcus, GF, Pinker, S., Ullman, M., Hollander, M., Rosen, TJ, & Xu, F. (1992). Overregularization in language acquisition. Monogr Soc Res Child Dev, 57 (4) (4), 1-182.
- Marcus, GF, Vijayan, S., Bandi Rao, S., & Vishton, PM (1999). Rule learning by sevenmonth- old infants. Science, 283 (5398) (5398), 77-80.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, AA, Veness, J., Bellemare, MG et al. (2015). Human-level control through deep reinforcement learning. Nature, 518 (7540) (7540), 529-533.
- Neelakantan, A., Le, QV, Abadi, M., McCallum, A., & Amodei, D. (2016). Learning a Natural Language Interface with Neural Programmer. arXiv.
- Ng, A. (2016). What is Artificial Intelligence? Harvard Business Review.
- Nguyen, A., Clune, J., Bengio, Y., Dosovitskiy, A., & Yosinski, J. (2016). Plug & Play Generation Networks: Conditional Iterative Generation of Images in Latent Space. arXiv, cs.CV.
- Nguyen, A., Yosinski, J., & Clune, J. (2014). Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. arXiv, cs.CV.
- Norvig, P. (2016). State-of-the-Art AI: Building Tomorrow's Intelligent Systems. Proceedings from EmTech Digital, San Francisco.
- O'Neil, C. (2016). Weapons of math destruction: how big data increases inequality and threatens democracy.
- Ortiz Jr, CL (2016). Why we need a physically embodied Turing test and what it might look like. AI magazine, 37(1)(1), 55-63.
- Paritosh, P., & Marcus, G. (2016). Toward a comprehension challenge, using crowdsourcing as a tool. AI Magazine, 37(1)(1), 23-31.
- Pearl, J. (2000). Causality: models, reasoning, and inference /. Cambridge, UK; New York Cambridge University Press.
- Pinker, S., & Prince, A. (1988). On language and connectionism: analysis of a parallel distributed processing model of language acquisition. Cognition, 28(1-2)(1-2), 73-193.
- Ribeiro, MT, Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv, cs.LG.
- Sabour, S., Frosst, N., & Hinton, GE (2017). Dynamic Routing Between Capsules. arXiv, cs.CV.
- Samek, W., Wiegand, T., & Müller, K.-R. (2017). Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models. arXiv, cs.AI.
- Schank, RC, & Abelson, RP (1977). Scripts, Plans, Goals and Understanding: an Inquiry into Human Knowledge Structures. Hillsdale, NJ: L. Erlbaum.
- Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural networks.
- Schoenick, C., Clark, P., Tafjord, O., P, T., & Etzioni, O. (2017). Moving beyond the Turing Test with the Allen AI Science Challenge. Communications of the ACM, 60 (9)(9), 60-64.
- Sculley, D., Phillips, T., Ebner, D., Chaudhary, V., & Young, M. (2014). Machine learning: The high-interest credit card of technical debt. Proceedings from SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop).
- Socher, R., Huval, B., Manning, CD, & Ng, AY (2012). Semantic compositionality through recursive matrix-vector spaces. Proceedings from Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning.
- Spelke, ES, & Kinzler, KD (2007). Core knowledge. Dev Sci, 10(1)(1), 89-96.
- Stoica, I., Song, D., Popa, RA, Patterson, D., Mahoney, MW, Katz, R. et al. (2017). A Berkeley View of Systems Challenges for AI. arXiv, cs.AI.
- Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I. et al. (2013). Intriguing properties of neural networks. arXiv, cs.CV.
- Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2014). Show and Tell: A Neural Image Caption Generator. arXiv, cs.CV.
- Watters, N., Tacchetti, A., Weber, T., Pascanu, R., Battaglia, P., & Zoran, D. (2017). Visual Interaction Networks. arXiv.
- Williams, A., Nangia, N., & Bowman, SR (2017). A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. arXiv, cs.CL.
- Wu, J., Lu, E., Kohli, P., Freeman, B., & Tenenbaum, J. (2017). Learning to See Physics via Visual De-animation. Proceedings from Advances in Neural Information Processing Systems.
- Zoph, B., Vasudevan, V., Shlens, J., & Le, QV (2017). Learning Transferable Architectures for Scalable Image Recognition. arXiv, cs.CV.
Source: https://habr.com/ru/post/371179/
All Articles