AMD Ryzen: Inside Look
The characteristics of AMD Ryzen processors and gaming stations based on them make it possible to cautiously suggest the end of a difficult period for an “alternative” chip maker and a claim for leadership. Without pretending to the ultimate truth, let us analyze some details - functional extensions of the basic set of x86 instructions in the AMD Family 17h processor family.

A list of technologies and instructions supported in the AMD 17h CPU family. Fragment of Software Optimization Guide for AMD Family 17h Processors.
The most complex devices, such as modern CPUs, can be viewed from various points of view, coming to diametrically opposite conclusions and comparison results. However, most of the technologies discussed below were previously implemented in Intel processors, with the exception of the AMD- specific CLZERO instruction .
')

The SMAP option affects the page translation engine and the virtual memory subsystem. Allows you to block access to the privileged code of the operating system (Kernel Mode) to the pages of the user level (User Mode).
This restriction, somewhat contrary to the classical hierarchy of memory protection (in which the status of the supervisor allows any type of access), in some cases helps to counter the actions of malicious code that unauthorizedly use the supervisor mode, as well as to simplify the identification of some errors leading to memory corruption.

The RDSEED instruction, as well as the previously existing RDRAND instruction, generates a random number. The difference is that for each generated number, RDSEED uses an analog entropy source (Enhanced non-deterministic random bit generator, NRBG). RDRAND uses a digital generator (Deterministic random bit generator, DRBG), periodically reloaded from an analog source of entropy. This reboot is called re-seed. The disadvantage of the RDRAND instruction is that several random numbers can be generated in the pauses between such reboots, in which case the generation of each next number in this group of numbers is the result of the digital automaton (DRBG) operation, rather than the analog entropy source (NRBG), which theoretically reduces cryptographic strength.
This official interpretation of the RDRAND and RDSEED differences is provided in the Intel documentation. Perhaps there are some Implementation-Specific differences between Intel and AMD. Simply put, we can give this recommendation: if the performance of a random number generator is in priority, you should use the RDRAND instruction, if the cryptographic strength is RDSEED.

The XSAVEC instruction is one of the optimized forms of the XSAVE context save instruction used to support multi-tasking operating systems. The XSAVEC instruction, unlike XSAVE, does not save components of the processor context, the state of which has not changed since initialization (init optimization).

The XSAVES instruction is one of the optimized forms of the XSAVE context save instruction used for running multi-tasking operating systems. The XSAVES instruction, unlike XSAVE, does not save components of the processor context, the state of which has not changed since the previous restoration of their state (modified optimization). This form of optimization is characteristic of the privileged procedures of the operating system.

The CLFLUSHOPT instruction declares an invalid cache line. If, before executing the instruction, the line contained data waiting for a delayed write to the RAM, that record is executed before the line is cleared. CLFLUSHOPT is an optimized version of a previously existing CLFLUSH instruction. Unfortunately, there is no clear formalization of the list of differences between CLFLUSH and CLFLUSHOPT in the Intel and AMD documentation.
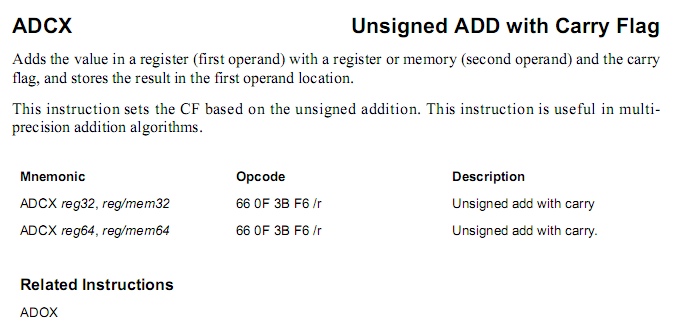
The ADCX and ADOX instructions perform the unsigned addition of two operands and are designed to process numbers whose bit depth exceeds the bit depth of one addition operation for several such operations. The sign of arithmetic transfer is taken into account when adding and is set in accordance with its results.
There are the following differences from the classic ADC instruction, which also performs addition using the carry flag:
The described atypical format of using flags allows to optimize the parallel execution of two operations of multi-digit addition, alternating instructions related to two branches. Using the classic ADC instruction, such an alternation of instructions of mutually independent branches in one thread would be impossible, due to the use of the common carry flag (CF).

The CLZERO instruction zeroes the contents of the specified cache line. It can be used to quickly reset cached memory areas as well as exclude additional transfers between cache memory and DRAM that occur in cases where the contents of the cache line are partially modified. Thus, interaction between Cache and DRAM is optimized.
To appreciate the effect of the AMD-exclusive CLZERO instruction, you need to thoroughly recall the theory: the information that the processor processes can be classified as temporal and non-temporal.
By default, most processor memory access instructions work in temporal mode, special instructions are used for non-temporal access, for example movntps and / or movntpd .
With that said, the processor performs the write operation differently:
The CLZERO instruction, which atomically executes a complete zeroing of the cache line, eliminates the need for additional loading of information from RAM when generating reliable line contents. This differs from typical write operations of lower bitness, which modify the cache string partially. In addition, an explicit data dimension of 64 bytes or 512 bits simplifies the write-combining optimization.
Note
For convenience, the cache line size is assumed to be 64 bytes. This is a typical value for modern Intel and AMD processors. In general, the programmer must detect the value of this parameter using the CPUID instruction, avoiding the use of predefined constants.
Analyzing the considered list of functional extensions, we can conclude that the focus of attention of developers turned out to protect user data, reduce the cost of processor cycles for context switching in a multitasking environment, optimize the interaction of cache memory and RAM, as well as basic arithmetic operations with integers of high resolution.
Information was collected from various sources, the process of refinement and verification is not completed at the moment, therefore, comments and additions are welcome, especially regarding the CLFLUSHOPT and CLZERO instructions and the Non-standardized Implementation-Specific documentation of the various processors.
A list of technologies and instructions supported in the AMD 17h CPU family. Fragment of Software Optimization Guide for AMD Family 17h Processors.
The most complex devices, such as modern CPUs, can be viewed from various points of view, coming to diametrically opposite conclusions and comparison results. However, most of the technologies discussed below were previously implemented in Intel processors, with the exception of the AMD- specific CLZERO instruction .
')
SMAP, Supervisor Mode Access Prevention
- Intel and AMD
The SMAP option affects the page translation engine and the virtual memory subsystem. Allows you to block access to the privileged code of the operating system (Kernel Mode) to the pages of the user level (User Mode).
This restriction, somewhat contrary to the classical hierarchy of memory protection (in which the status of the supervisor allows any type of access), in some cases helps to counter the actions of malicious code that unauthorizedly use the supervisor mode, as well as to simplify the identification of some errors leading to memory corruption.
RDSEED, Read Random Number (Re-Seed)
- Intel and AMD
The RDSEED instruction, as well as the previously existing RDRAND instruction, generates a random number. The difference is that for each generated number, RDSEED uses an analog entropy source (Enhanced non-deterministic random bit generator, NRBG). RDRAND uses a digital generator (Deterministic random bit generator, DRBG), periodically reloaded from an analog source of entropy. This reboot is called re-seed. The disadvantage of the RDRAND instruction is that several random numbers can be generated in the pauses between such reboots, in which case the generation of each next number in this group of numbers is the result of the digital automaton (DRBG) operation, rather than the analog entropy source (NRBG), which theoretically reduces cryptographic strength.
This official interpretation of the RDRAND and RDSEED differences is provided in the Intel documentation. Perhaps there are some Implementation-Specific differences between Intel and AMD. Simply put, we can give this recommendation: if the performance of a random number generator is in priority, you should use the RDRAND instruction, if the cryptographic strength is RDSEED.
XSAVEC, Extended Save with Compaction
- Intel and AMD
The XSAVEC instruction is one of the optimized forms of the XSAVE context save instruction used to support multi-tasking operating systems. The XSAVEC instruction, unlike XSAVE, does not save components of the processor context, the state of which has not changed since initialization (init optimization).
XSAVES Extended Save for Supervisor
- Intel and AMD
The XSAVES instruction is one of the optimized forms of the XSAVE context save instruction used for running multi-tasking operating systems. The XSAVES instruction, unlike XSAVE, does not save components of the processor context, the state of which has not changed since the previous restoration of their state (modified optimization). This form of optimization is characteristic of the privileged procedures of the operating system.
CLFLUSHOPT, Cache Line Flush Optimized
- Intel and AMD
The CLFLUSHOPT instruction declares an invalid cache line. If, before executing the instruction, the line contained data waiting for a delayed write to the RAM, that record is executed before the line is cleared. CLFLUSHOPT is an optimized version of a previously existing CLFLUSH instruction. Unfortunately, there is no clear formalization of the list of differences between CLFLUSH and CLFLUSHOPT in the Intel and AMD documentation.
ADCX, Add with Carry Flag for Multi-Precision
- Intel and AMD
The ADCX and ADOX instructions perform the unsigned addition of two operands and are designed to process numbers whose bit depth exceeds the bit depth of one addition operation for several such operations. The sign of arithmetic transfer is taken into account when adding and is set in accordance with its results.
There are the following differences from the classic ADC instruction, which also performs addition using the carry flag:
- The ADCX instruction does not modify the OF overflow flag.
- The ADOX instruction uses the overflow flag (OF) as a sign of arithmetic transfer and does not modify the CF transfer flag.
The described atypical format of using flags allows to optimize the parallel execution of two operations of multi-digit addition, alternating instructions related to two branches. Using the classic ADC instruction, such an alternation of instructions of mutually independent branches in one thread would be impossible, due to the use of the common carry flag (CF).
CLZERO, Cache Line Zero
- AMD only
The CLZERO instruction zeroes the contents of the specified cache line. It can be used to quickly reset cached memory areas as well as exclude additional transfers between cache memory and DRAM that occur in cases where the contents of the cache line are partially modified. Thus, interaction between Cache and DRAM is optimized.
To appreciate the effect of the AMD-exclusive CLZERO instruction, you need to thoroughly recall the theory: the information that the processor processes can be classified as temporal and non-temporal.
- The temporal type includes data that the processor intensively and repeatedly uses at the current time, while their total size is smaller than the cache size. Placing such data into a cache improves performance by eliminating the need to access RAM.
- Non-temporal type includes data that is useless and often harmful to cache. If the size of the processed block exceeds the size of the cache, or the next access to the data is planned over a long time, such data with high probability will be pushed out of the cache before the next access to it, which means that it will again need to read the RAM. In this example, caching doesn’t take up CPU cycles and the amount of cache memory.
By default, most processor memory access instructions work in temporal mode, special instructions are used for non-temporal access, for example movntps and / or movntpd .
With that said, the processor performs the write operation differently:
- Writing in temporal store mode involves pre-filling the cache line, for this, 64-byte RAM is read and cached, which is affected by the target write operation. Actually, the update of the data prescribed by the write instruction is already performed in the cache memory.
- Writing in the non-temporal store mode (streaming store) implies only writing to RAM, without prior “speculative” reading, although it allows combining a series of several write cycles of low bitness into a total cycle of total bit capacity (write combining).
The CLZERO instruction, which atomically executes a complete zeroing of the cache line, eliminates the need for additional loading of information from RAM when generating reliable line contents. This differs from typical write operations of lower bitness, which modify the cache string partially. In addition, an explicit data dimension of 64 bytes or 512 bits simplifies the write-combining optimization.
Note
For convenience, the cache line size is assumed to be 64 bytes. This is a typical value for modern Intel and AMD processors. In general, the programmer must detect the value of this parameter using the CPUID instruction, avoiding the use of predefined constants.
Instead of an afterword
Analyzing the considered list of functional extensions, we can conclude that the focus of attention of developers turned out to protect user data, reduce the cost of processor cycles for context switching in a multitasking environment, optimize the interaction of cache memory and RAM, as well as basic arithmetic operations with integers of high resolution.
Information was collected from various sources, the process of refinement and verification is not completed at the moment, therefore, comments and additions are welcome, especially regarding the CLFLUSHOPT and CLZERO instructions and the Non-standardized Implementation-Specific documentation of the various processors.
Source: https://habr.com/ru/post/370899/
All Articles