Retrained neural networks in the wild and in humans
Imagine that you are designing a seagull chick. TK is - he has rather poor eyesight, a small brain, but he needs to eat as much as possible, otherwise he will die. A mum-gull brings him food. The main task - to recognize the mother-seagull and get her food. In the input stream of view comes, say, 320x200 px, and then 10 centimeters from the eye, it does not know how to focus. Nature decided so - it is necessary to mark the gull's beak with a bright orange rounded spot. Here it is:

In the course of reverse engineering seagulls in the 1950s, Niko Tinbergen conducted 2431 experiments with 503 chicks (part of his colleague Rita Weidmann sat out herself). It turned out that the chick reacts not only to the beak, but also to the cardboard rectangle with a round orange spot. And trying to get his food like a regular gull. It sounds logical, especially in the conditions of lack of computing resources of the chick, right? "Appears from above", "long" - this is important. But the highest value of the “orange on white” signal is overestimated as it evolves.
')
At the very end, an ultra-normal signal was suddenly found. If the chick shows a rectangle with three orange stripes, it recognizes it much faster, more accurately, and reacts many times more actively. That is, another image that is not found in nature is more recognizable.
If you think that we are not buried, you are mistaken. We humans have about the same example of retraining, well known to anime artists.
Historically it was assumed that we are looking at something and doing the following (everything is much more complicated and confusing, I simplify very, very much, so I apologize in advance for the rough model):
In fact, it turned out that the process is much more fun. It makes no sense to "load" the entire image in the primary processing, when you can greatly optimize this process. Therefore, we do the following:
To make it clear what speed it is - V.N. Panferov (under the guidance of A.A. Bodalev) determined the threshold of face recognition in a photo - it is 0.03-0.04 seconds. The hair and top of the head were processed within these limits, but the chin and nose were already recognized somewhere three times slower - by 0.1 s.
I repeat, the model is very approximate, but it shows the most important difference: we do not process what we saw the eye, but we control the eye so that it looks for familiar patterns. To not go far - here is an example of the implementation of this vulnerability:
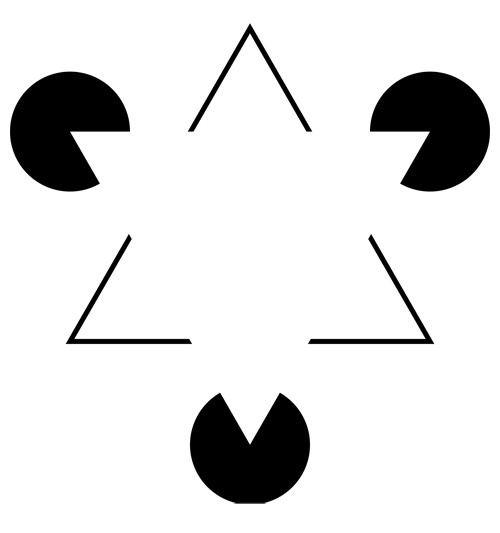
Here you can see the white triangle. Moreover, some may even "see" its boundaries.
But, which is much more important for us in terms of retraining our pattern-based neural networks, we recognize many objects by several reference points. For example, very simple drawings allow you to recognize objects faster than a photo containing much more information. Because in the simplified figure, the features that the artist’s neural network considered significant are already highlighted, and our neural network also took them as reference points.
Now back to the anime artists mentioned. If you think about it, then any comic-drawn image of a girl can not be more attractive than a lively girl. Well, let us have an idealized maiden in the anime and another one with the perfect makeup figure in the photo. Most of the anime is focused on ultra-normal signal - we recognize the supporting parts of the image and stop. Here, look:

This is not the best example, but this is the best I've found with a license to use and modify (uploaded to sketchport.com by Envynity)
We recognize this set of visual cues as perhaps quite a pretty maiden. However, if a real lady has eyes of the same size, a pimple instead of a nose, a strange mouth, translucent hair and generally similar anatomy, plus it will lay a naughty curl over the eye ... Well, some will grab an aspen.
The picture illustrates how the main objects for a neural network are allocated and the secondary ones are extinguished. Yes, yes, this is also our ultranormalny signal - fast for recognition, but in the real world it means a false positive response. Meet us, we just looked at the card with three stripes. Similarly, the chest of unreal size in some antique statues is not a physical error, but an artistic hyperbole emphasizing the desired quality.
Here is another example for those who did not see the pretty girl in the picture above:

Schyns PG, Oliva AJ Cognition - when loading parts, the first person is evil, the second is not. It is enough for me to take off my glasses, and you - maybe you will need to move away from the monitor or reduce the picture. With a sufficient level of blurring, our neural network will rest on other points altogether, and the expressions will be swapped.
The second bug of the same class (but much higher level) is a projection based on incomplete data. A series of experiments by Alan Miller and the already mentioned Bodalev proved that we are building a complete image of a person, on whom we rely before receiving new data, on the basis of extremely fragmentary pieces of information. For example, we are trained that all hairy spectacles are nerds (until we get one from the eye), all Chinese are low (until we see their representatives sent to the parade on May 9 past us - not less than 210 centimeters each) Further.
Turning to simpler implementations of this function, for example, it is worth remembering that rats get scared of any fluffy objects about the size of a cat, because the clearer a cat is recognized, the more important it is for survival. Accordingly, more FPR and a minimum of FRR - rats survive precisely by reducing false-negative statuses. You and I have such a nice bullshit - the generalization of fear. For example, if you purposely teach a child to be afraid of a plush rat, then he will be frightened at all by half of plush toys, since his neural network has been taken away not only by the main classifying attribute, but also by a bunch of auxiliary ones - and decided that a high FPR compared to the danger of not recognizing the signal is a valid victim .
Generalization works in animals. Moreover, it is perfectly combined with neuro training. If a rat is allowed to run in a labyrinth in a branch with a circle, a square and a rectangle with proportions of 2: 1, but feed only after it runs to the rectangle - the rat will learn to distinguish the rectangle from a couple of attempts and will run only to it. Replace the maze - instead of a circle, now the second square. Again runs to the rectangle on the first try. Now we change the maze - leave the square, the rectangle 2: 1 and the rectangle 3: 1. Logic assumes that the rat runs to the already familiar 2: 1. But no, she, it turns out, has learned that the more rectangular the better. And runs at 3: 1, believing that there is more food. Because on this rectangle its neural network "where food" gives a stronger trigger signal.
Another man exploit was found by Morten Kringelbach at Oxford, working with Chrysler. The experience brought to mind looks like this: we show women photos of something sweet, for example, babies. We fix what is happening in the brain. Now we are showing women photos of the new options for the exterior of the car, and are looking for the greatest fit to the previous pattern. We get the cutest possible car.
Compare "Matiz" and "Smart". Yes, we recognize the "cubs" and include the parental reaction in certain proportions of the face. For example, a puppy, a hare, a kitten, a baby bird and a baby will have clearly shortened and less prominent noses, large eyes. Do not believe the example of the car - look at the capybara cub, who was born recently in the Moscow Zoo. Here is the news about him - there is a series of photos. If you do not know in advance that this is a baby, you can take him as an adult. Because the nose is long, and out of our patterns of the parent reaction. And our neural network can navigate that it is a cub, only in overall size in comparison with another individual - or the news headline.
And finally - guppies recognize each other by shades of color. Males have a large yellow marker throughout the body. This yellow marker is sought by females who want to breed. So, biologists decided to check how the females achieved the required accuracy. As a result of the experiments, they painted the male bright blue. And - ta-dam! - it turned out that they really use the metric "the more blue the better." And the stickleback males (not to be confused with smelt) are generally caught on the red thread - for them all the stirring red is an instant trigger to launch the attack instinct. Because the male lures females back and forth with the red color of the belly. And the thread behaves even more “samtsovo” than real fish. We must bite this brazen thing, right? The jackdaws have a trigger “to attack if they drag something black dangling” - this is protection of the nesting site from those who steal chicks. Do not come to them with socks in their hands. The same seagulls throw out red eggs from the nest - the instinct of getting rid of thedirty cache of wounded chicks.
In general, I strongly advise - for example, studies of the 50s like “Man’s Perception by Man” (A. A. Bodalev) and the experiments described by N. Tinbergen in “Wasps, Birds, People” suddenly show the incredible fragility of the wind with which we are stitched. And make it clear how weird decision making neural networks.
In the course of reverse engineering seagulls in the 1950s, Niko Tinbergen conducted 2431 experiments with 503 chicks (part of his colleague Rita Weidmann sat out herself). It turned out that the chick reacts not only to the beak, but also to the cardboard rectangle with a round orange spot. And trying to get his food like a regular gull. It sounds logical, especially in the conditions of lack of computing resources of the chick, right? "Appears from above", "long" - this is important. But the highest value of the “orange on white” signal is overestimated as it evolves.
')
At the very end, an ultra-normal signal was suddenly found. If the chick shows a rectangle with three orange stripes, it recognizes it much faster, more accurately, and reacts many times more actively. That is, another image that is not found in nature is more recognizable.
If you think that we are not buried, you are mistaken. We humans have about the same example of retraining, well known to anime artists.
Model of our vision
Historically it was assumed that we are looking at something and doing the following (everything is much more complicated and confusing, I simplify very, very much, so I apologize in advance for the rough model):
- We get the input data array in the form of something like a bmp file
- We process this picture on visual receptors in order to convert them into impulses for the brain. That is, we translate this BMP into the internal format of the brain.
- We carry away from the sensors to the processing center, where we give the received picture the meaning, that is, we convert it into the following format - most likely, word-wise, because then it will involve associations.
- We understand the meaning of the image and show it to the conscious part of the mind.
In fact, it turned out that the process is much more fun. It makes no sense to "load" the entire image in the primary processing, when you can greatly optimize this process. Therefore, we do the following:
- We get the primary data loop, roughly speaking, a few percent of the entire touch input.
- Immediately we drive it into processing with the question of what to load next. Processing (outside the sensor, in the brain) is associated with a dictionary of form associations and says that we most likely see - that is, it gives control of the sensor to the hypothesis.
- Control of the sensor begins to “load” what can confirm or refute the most likely hypotheses - that is, we consistently take a few more percent of the data, give them immediately to processing and get the result, and look at what to look further.
- When there is only one hypothesis - having an incomplete file, we already know what is depicted on it. At this point, another conversion occurs already in a conscious format.
To make it clear what speed it is - V.N. Panferov (under the guidance of A.A. Bodalev) determined the threshold of face recognition in a photo - it is 0.03-0.04 seconds. The hair and top of the head were processed within these limits, but the chin and nose were already recognized somewhere three times slower - by 0.1 s.
I repeat, the model is very approximate, but it shows the most important difference: we do not process what we saw the eye, but we control the eye so that it looks for familiar patterns. To not go far - here is an example of the implementation of this vulnerability:
Here you can see the white triangle. Moreover, some may even "see" its boundaries.
But, which is much more important for us in terms of retraining our pattern-based neural networks, we recognize many objects by several reference points. For example, very simple drawings allow you to recognize objects faster than a photo containing much more information. Because in the simplified figure, the features that the artist’s neural network considered significant are already highlighted, and our neural network also took them as reference points.
Now back to the anime artists mentioned. If you think about it, then any comic-drawn image of a girl can not be more attractive than a lively girl. Well, let us have an idealized maiden in the anime and another one with the perfect makeup figure in the photo. Most of the anime is focused on ultra-normal signal - we recognize the supporting parts of the image and stop. Here, look:
This is not the best example, but this is the best I've found with a license to use and modify (uploaded to sketchport.com by Envynity)
We recognize this set of visual cues as perhaps quite a pretty maiden. However, if a real lady has eyes of the same size, a pimple instead of a nose, a strange mouth, translucent hair and generally similar anatomy, plus it will lay a naughty curl over the eye ... Well, some will grab an aspen.
The picture illustrates how the main objects for a neural network are allocated and the secondary ones are extinguished. Yes, yes, this is also our ultranormalny signal - fast for recognition, but in the real world it means a false positive response. Meet us, we just looked at the card with three stripes. Similarly, the chest of unreal size in some antique statues is not a physical error, but an artistic hyperbole emphasizing the desired quality.
Here is another example for those who did not see the pretty girl in the picture above:
Schyns PG, Oliva AJ Cognition - when loading parts, the first person is evil, the second is not. It is enough for me to take off my glasses, and you - maybe you will need to move away from the monitor or reduce the picture. With a sufficient level of blurring, our neural network will rest on other points altogether, and the expressions will be swapped.
The second bug of the same class (but much higher level) is a projection based on incomplete data. A series of experiments by Alan Miller and the already mentioned Bodalev proved that we are building a complete image of a person, on whom we rely before receiving new data, on the basis of extremely fragmentary pieces of information. For example, we are trained that all hairy spectacles are nerds (until we get one from the eye), all Chinese are low (until we see their representatives sent to the parade on May 9 past us - not less than 210 centimeters each) Further.
Turning to simpler implementations of this function, for example, it is worth remembering that rats get scared of any fluffy objects about the size of a cat, because the clearer a cat is recognized, the more important it is for survival. Accordingly, more FPR and a minimum of FRR - rats survive precisely by reducing false-negative statuses. You and I have such a nice bullshit - the generalization of fear. For example, if you purposely teach a child to be afraid of a plush rat, then he will be frightened at all by half of plush toys, since his neural network has been taken away not only by the main classifying attribute, but also by a bunch of auxiliary ones - and decided that a high FPR compared to the danger of not recognizing the signal is a valid victim .
Generalization works in animals. Moreover, it is perfectly combined with neuro training. If a rat is allowed to run in a labyrinth in a branch with a circle, a square and a rectangle with proportions of 2: 1, but feed only after it runs to the rectangle - the rat will learn to distinguish the rectangle from a couple of attempts and will run only to it. Replace the maze - instead of a circle, now the second square. Again runs to the rectangle on the first try. Now we change the maze - leave the square, the rectangle 2: 1 and the rectangle 3: 1. Logic assumes that the rat runs to the already familiar 2: 1. But no, she, it turns out, has learned that the more rectangular the better. And runs at 3: 1, believing that there is more food. Because on this rectangle its neural network "where food" gives a stronger trigger signal.
Another man exploit was found by Morten Kringelbach at Oxford, working with Chrysler. The experience brought to mind looks like this: we show women photos of something sweet, for example, babies. We fix what is happening in the brain. Now we are showing women photos of the new options for the exterior of the car, and are looking for the greatest fit to the previous pattern. We get the cutest possible car.
Compare "Matiz" and "Smart". Yes, we recognize the "cubs" and include the parental reaction in certain proportions of the face. For example, a puppy, a hare, a kitten, a baby bird and a baby will have clearly shortened and less prominent noses, large eyes. Do not believe the example of the car - look at the capybara cub, who was born recently in the Moscow Zoo. Here is the news about him - there is a series of photos. If you do not know in advance that this is a baby, you can take him as an adult. Because the nose is long, and out of our patterns of the parent reaction. And our neural network can navigate that it is a cub, only in overall size in comparison with another individual - or the news headline.
And finally - guppies recognize each other by shades of color. Males have a large yellow marker throughout the body. This yellow marker is sought by females who want to breed. So, biologists decided to check how the females achieved the required accuracy. As a result of the experiments, they painted the male bright blue. And - ta-dam! - it turned out that they really use the metric "the more blue the better." And the stickleback males (not to be confused with smelt) are generally caught on the red thread - for them all the stirring red is an instant trigger to launch the attack instinct. Because the male lures females back and forth with the red color of the belly. And the thread behaves even more “samtsovo” than real fish. We must bite this brazen thing, right? The jackdaws have a trigger “to attack if they drag something black dangling” - this is protection of the nesting site from those who steal chicks. Do not come to them with socks in their hands. The same seagulls throw out red eggs from the nest - the instinct of getting rid of the
In general, I strongly advise - for example, studies of the 50s like “Man’s Perception by Man” (A. A. Bodalev) and the experiments described by N. Tinbergen in “Wasps, Birds, People” suddenly show the incredible fragility of the wind with which we are stitched. And make it clear how weird decision making neural networks.
Source: https://habr.com/ru/post/370541/
All Articles