AI tried to understand the comics. Did not work out

Where did the snake come from in the last figure? Why does she bite a man? Are the same people depicted in the second and third drawings? The reader receives answers to these questions from a common understanding of the plot, interpreting the captions to the pictures, the phrases of the characters and the semantic transitions from one picture to another.
Neural networks demonstrate amazing success in various tasks. They bypassed a person by the accuracy of face recognition, lip reading, playing some board games, diagnosing certain diseases and driving a car in the dark. Every day the number of "victories" of neural networks over man is increasing. But there are specific tasks in which Artificial Intelligence cannot even get close to the human level, so that there is nothing left for it but to admit defeat - and retreat.
One of these overwhelming tasks is the understanding of comics, stories in pictures. This type of art is located at the intersection of literature and art. It differs in that it actively appeals to the reader’s imagination. A person should think about what is happening in the hand-drawn story. Optimistic scientists from the University of Colorado and the University of Maryland (USA) suggested that they could teach the neural network, but they miscalculated .
The stories in pictures - an ancient art genre, which leads its history from the Middle Ages. It became widespread in modern popular culture at the end of the 19th century and in the 20th century, becoming the prototype of animation and cinema. It is almost the same. As Scott McCloud, the author of The Essence of the Comic , said, the space for a comic means the same as time for a movie. In English, the word "cartoon" even means both cartoon and comics at the same time, because these concepts are close in meaning.
')

Page from Scott McCloud's The Essence of Comics
In the series of pictures, the author can tell any story from the beginning to the end, from the development of a three hundred year intergalactic war to a family dinner. The key feature of the comic book and the real skill of the artist is not what it shows, but what is hidden . The viewer has to guess. Imagination paints colorful pictures that the author of the comic book specially left for him, for imagination.

Just imagine what the heroine of this comic book saw!
This is the whole charm of comics. Imagination.
Researchers from the University of Colorado and the University of Maryland (USA) tried to teach the neural network to fill in the gutters between the individual pictures of the comics, as a person’s imagination does. For training the neural network made up an extensive database of comics: approximately 1.2 million drawings from 4,000 publicly available books with drawn stories. They all came out in 1938−1954. The assembled COMICS base of 120 GB in size in several days will be published in open access on GitHub . Apparently, this is the first ever set of data with comics for teaching neural networks.
Dataset statistics
Books - 3948
Pages - 198,657
Drawings - 1 229 664
Text fields - 2 498 657
To test the understanding of the context and plot of the comic, the researchers developed three tasks for predicting text and objects in the figures: text cloze , visual cloze and character coherence . Although the tasks differed in content, in all cases the tasks had the same format: the neural network received as a context several preceding drawings and had to evaluate the best option for predicting the next text (text cloze), picture (visual cloze) or matching the text to a specific character ( character coherence). The choice was made from three variants of the text and pictures and from two variants of matching the phrases to the character.
Understanding the meaning of comics was determined by the way the neural network predicts the next picture in the storyline and the text on it. Four models were developed for testing: Text-only , Image-only , NC-image-text and Image-text . The first neural network received information only about the text in the pictures. The second neural network received information only about the visual characteristics of the drawings. The third and fourth models differ only in details, but both of them received information about the text and about the visual characteristics of the drawings.
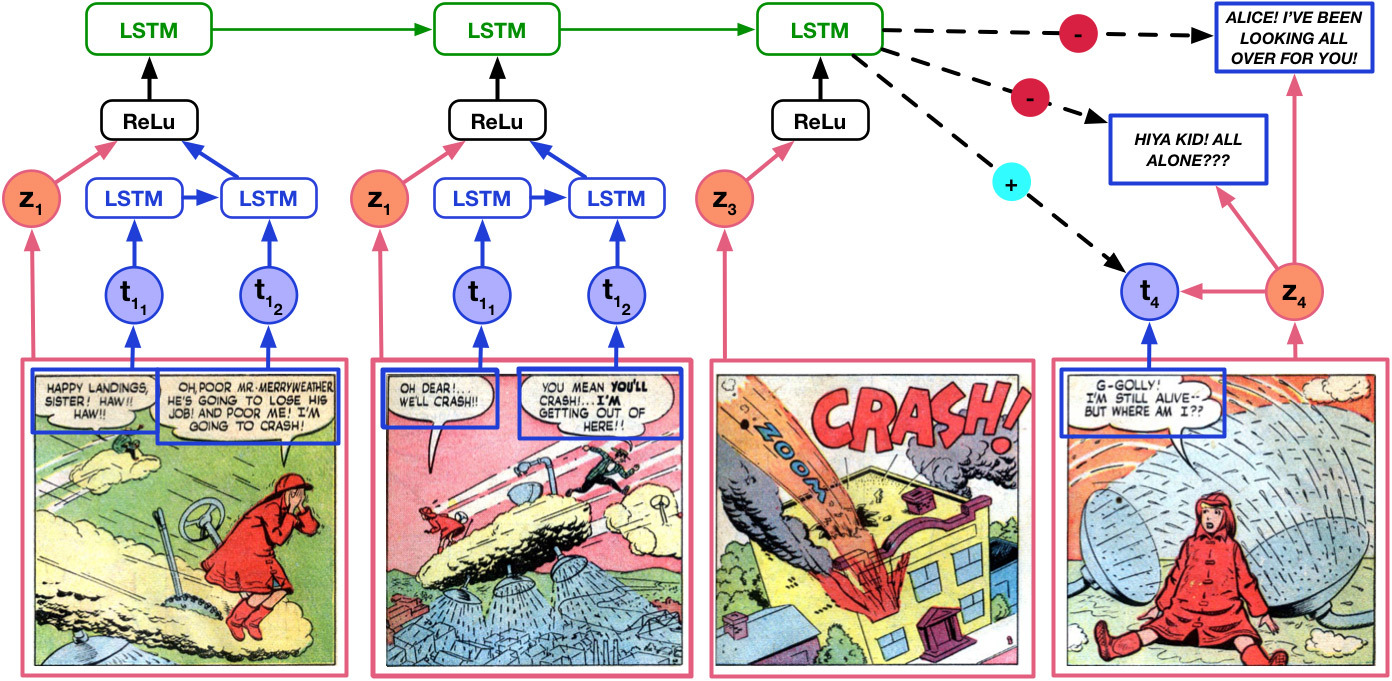
Applying the Image-text architecture to the text cloze task. Images that are pre-learned in the learning process are combined with text features in a hierarchical architecture to form a context view, which is then used to evaluate textual candidates, that is, to select the most appropriate of the three heroine phrase variants.
After learning, the neural networks were tested on the three aforementioned tasks for predicting the next pattern in the comic. As can be seen from the table with the results, the neural networks did very poorly with the task, showing a result much worse than that of a person, although higher than the random probability (33% and 50%, respectively).
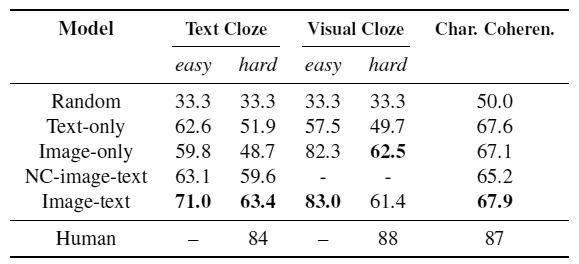
Apparently, understanding the meaning of comics and the characteristic semantic spaces between individual frames remains a unique task that only a person can solve. Artificial intelligence plays people into an intellectual quiz, chess and go, recognizes objects in video much better and processes speech, can predict sounds and generate works of art in the style of famous artists, but it is not yet able to understand the comics. He has no imagination.
The scientific work was published on November 16, 2016 in the open access on the site arXiv (arXiv: 1611.05118).
Source: https://habr.com/ru/post/369915/
All Articles