Pokémon Go. Why “scaling work” is as important as “working on bugs”
For many years, a “bug fix” approach has been popular among DevOps. The idea was that many companies faced costly downtime, loss of profits and productivity due to problems with available capacity, so you had to create your own application infrastructure and its environment in order to work through all the errors and make sure that will not repeat.
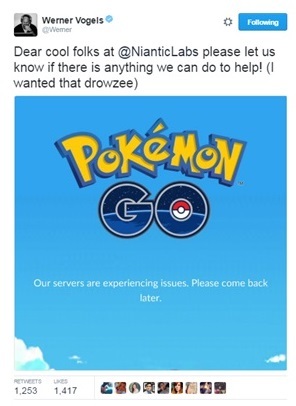
The result of the recent deafening success of the game Pokémon Go was a deafening disappointment for many. Especially for parents of hyperactive children who want to play right NOW, but cannot because the creation of accounts for the game was temporarily suspended and limited due to the great popularity of the game.

')
We can recall the proposal of Werner Vogels, Amazon’s technical director, to help the company solve problems with the available capacities, since they “did not implement cloud technologies,” and that was their main problem, which is not entirely clear to me. Indeed, according to Wikipedia 's information about the developer of augmented reality, the company processes "more than 200 million game actions per day as people interact with real and virtual objects in the real world." I think that we can forgive them, or those who understand the capabilities of modern information processing systems and its transmission over distances can forgive. As for the described “server issues”, we all know that “server” is the technical designation for “15 different components used in the application and network infrastructure”.
In any case, the conclusion is: cloud technologies do not necessarily behave better in case of unexpected project success. It may be, but not due to cloud computing. The fact is that cloud technologies are created not only to carry out "work on the bugs", but they are also created in order to scale.
I cannot say why Niantic Labs could not cope with the high demand for the game. It is possible that not enough capacity, in this case, it would be possible to take advantage of cloud technologies. Perhaps the fact is that the application and / or infrastructure do not support scaling; in this case, cloud technologies could be useless. The point is not that we should scold them for what they did / did not do. The fact is that they are an excellent example of what is happening in the world of applications - companies must prepare for both success and failure. And not only to success that comes gradually, but also to instant success, as was the case with the Pokémon Go.
Because if this happens, you will not want a successful failure to fill the entire Internet.
The main source of scalability issues are data sources. Older Twitter users will remember that when social networks appeared, problems with database scalability were observed. PayPal was one of the first and most ardent supporters of fragmentation as a scaling strategy, and this methodology was chosen as a general solution applied to databases, services and applications. The growth in popularity of NoSQL was due to a higher level of scalability compared to traditional relational databases.
Another source of scalability issues is infrastructure. Automatic scaling in cloud environments is based on the ability not only to add more computing resources, but also to increase the capacity of the entry point to the application. In any architecture, the use of scaling to increase capacity implies the use of a load balancing service. When computing power increases, it must be registered with the help of a load balancing service. This implies the use of application programming interfaces, scripts, automation and control functions. These components must be available before they are needed.
Enabling load balancing service in any - each - application architecture should be mandatory. The load balancing service is needed can help in the work on the bugs, because He is able to solve issues with incorrect application performance, but he also supports the need for “working on a mastabation.” But do not think that it comes down simply to placing the load balancing service in front of the applications. It is important to provide automation features (scripts) and controls (processes) that will automatically scale to meet the drastic demand when it appears. Scaling today is connected with architecture, and not with algorithms, it is very important to understand this in advance, before problems appear.
To be honest, Niantic Labs did a good job creating, so that it wouldn't work. Capacity issues were met with friendly messages, not an HTTP status code page, as is often the case. They treated it with humor and described the problems simply and clearly. For what they were not prepared, the company received an unexpected success. And it will be a good reminder that creating for scaling is just as important as working on bugs.
Because if you do not do this, someone else will do it.
The result of the recent deafening success of the game Pokémon Go was a deafening disappointment for many. Especially for parents of hyperactive children who want to play right NOW, but cannot because the creation of accounts for the game was temporarily suspended and limited due to the great popularity of the game.
')
We can recall the proposal of Werner Vogels, Amazon’s technical director, to help the company solve problems with the available capacities, since they “did not implement cloud technologies,” and that was their main problem, which is not entirely clear to me. Indeed, according to Wikipedia 's information about the developer of augmented reality, the company processes "more than 200 million game actions per day as people interact with real and virtual objects in the real world." I think that we can forgive them, or those who understand the capabilities of modern information processing systems and its transmission over distances can forgive. As for the described “server issues”, we all know that “server” is the technical designation for “15 different components used in the application and network infrastructure”.
In any case, the conclusion is: cloud technologies do not necessarily behave better in case of unexpected project success. It may be, but not due to cloud computing. The fact is that cloud technologies are created not only to carry out "work on the bugs", but they are also created in order to scale.
I cannot say why Niantic Labs could not cope with the high demand for the game. It is possible that not enough capacity, in this case, it would be possible to take advantage of cloud technologies. Perhaps the fact is that the application and / or infrastructure do not support scaling; in this case, cloud technologies could be useless. The point is not that we should scold them for what they did / did not do. The fact is that they are an excellent example of what is happening in the world of applications - companies must prepare for both success and failure. And not only to success that comes gradually, but also to instant success, as was the case with the Pokémon Go.
Because if this happens, you will not want a successful failure to fill the entire Internet.
The main source of scalability issues are data sources. Older Twitter users will remember that when social networks appeared, problems with database scalability were observed. PayPal was one of the first and most ardent supporters of fragmentation as a scaling strategy, and this methodology was chosen as a general solution applied to databases, services and applications. The growth in popularity of NoSQL was due to a higher level of scalability compared to traditional relational databases.
Another source of scalability issues is infrastructure. Automatic scaling in cloud environments is based on the ability not only to add more computing resources, but also to increase the capacity of the entry point to the application. In any architecture, the use of scaling to increase capacity implies the use of a load balancing service. When computing power increases, it must be registered with the help of a load balancing service. This implies the use of application programming interfaces, scripts, automation and control functions. These components must be available before they are needed.
Enabling load balancing service in any - each - application architecture should be mandatory. The load balancing service is needed can help in the work on the bugs, because He is able to solve issues with incorrect application performance, but he also supports the need for “working on a mastabation.” But do not think that it comes down simply to placing the load balancing service in front of the applications. It is important to provide automation features (scripts) and controls (processes) that will automatically scale to meet the drastic demand when it appears. Scaling today is connected with architecture, and not with algorithms, it is very important to understand this in advance, before problems appear.
To be honest, Niantic Labs did a good job creating, so that it wouldn't work. Capacity issues were met with friendly messages, not an HTTP status code page, as is often the case. They treated it with humor and described the problems simply and clearly. For what they were not prepared, the company received an unexpected success. And it will be a good reminder that creating for scaling is just as important as working on bugs.
Because if you do not do this, someone else will do it.
Source: https://habr.com/ru/post/369505/
All Articles