How Yandex created the first device with Alice. Yandex.The station on the basis of technology IO

A few minutes ago at the YaC 2018 conference, we first talked about Yandex.Station . This is the first multimedia device with Alice, which plays music and movies, tells fairy tales to children, helps in everyday affairs, and also supports skills from third-party developers.
It may seem that to create such devices it is enough to take a voice assistant, add a simple microphone from a smartphone to it and hide it all in the case of an inexpensive audio speaker. In practice, the developers of such systems are facing serious technological problems, the solution of which at the Station we will tell today to the readers of Habr. You will also learn what exactly is the technological platform Yandex.IO, on the basis of which the device is created.
In a post about the creation of Alice, we talked about the development of computer interfaces: from the command line to mouse and voice control. The more accessible the computer became, the faster the technologies developed, the way of interaction with the device was simplified.
')
With other home devices, the development went the same way. Perhaps you remember the Soviet black-and-white TVs, in which even to switch channels it was necessary to put tangible physical effort. Now, in many models, we can switch channels by voice.
We believe that the time has come to teach home devices to communicate in the language of people, not buttons. It was this idea that formed the basis of Alice’s voice assistant and our first device based on it, Yandex.Station.
Says and shows
The station is the first Yandex device with voice assistant Alice. She will tell the weather, set the alarm, tell the news, read the story to the child or help with other daily activities. But the value of our device is not only in this. When we started working on the Station, we set ourselves the task of creating a home multimedia device, the capabilities of which would not be limited to the skills of a voice assistant. This task included two important requirements:
1. The station should play tracks from Yandex.Music or from any other device via Bluetooth.
2. The station must find and play video: as from the database of partner content, and videos from the network. There were even options with its own built-in screen, but they were quickly abandoned in favor of the HDMI connector for connecting to any TV.
And all this - with high-quality sound. Our device should handle the audio track better than the speakers of a typical TV (this applies to both deep bass and total power). At the same time, the Station should not only sound good, but also clearly understand the user's speech. And these tasks contradict each other a little. And here the fun begins.
Location matters

Take a look at the picture above. Smart home devices are often portrayed as if they are in the center of a room and reproduce sound in all directions. It looks beautiful in photos, but in reality almost no one uses them that way. Devices that need to hear voices from afar consume significant computational resources, so they work not from a battery, but from a network. Almost no one has the closest outlets in the center of the room, so devices usually stand against the walls. This means that it makes no sense to make a device with a circular arrangement of speakers. And it's not just about saving.
If you direct a part of the speakers to the wall, then the problem of sound wave interference arises, which would have to be compensated at the software level. No extra speakers - no problem. Therefore, in the Station we use two frontal speakers (including to maintain the stereo effect), one woofer and two passive radiators (for deep bass). But even with their location in the case is not so simple.

Usually, both tweeters (tweeters) and a woofer are directed toward the listener in order to achieve minimal sound distortion. But in our case, the woofer is pointing down. Why?
Remember, we said that the Station should not only produce high-quality sound, but also be able to hear voice commands? Human speech is predominantly midrange (although the full range is wider: 300-3400 Hz). We were faced with the task of reducing the effect of the sound emitted by the Station on the microphones, which should capture human speech. One solution to this problem is to increase the “echo-path” of sound in the spectrum of human speech from speakers to microphones. The woofer responds to the mids in the usual mode of the Station, so we sent it down. This increases the “echo path”, improves the quality of voice recognition and slightly affects the quality of sound reproduction.
In the previous paragraph, you might have noticed the mention of the normal Station mode. In short, we are talking about the volume level. The total power of all speakers in the Station is 50 watts. For a noisy party this is more than enough. But at high volume it is difficult to recognize the voice of the user. In the industry, this problem is solved by limiting the volume. We also thought about this option, but, fortunately, we decided not to spoil the good acoustics with limitations.
Adaptive Crossfade
The current volume level is visualized using a circular light at the top of the Station. As the volume increases, the color changes from green to yellow and red. Green and yellow is a conventional “normal mode”, in which the Station plays music well and responds to user voice commands. But the red color indicates a high volume. In this mode, the volume is so high that the device is almost unable to hear user commands.
At maximum volume, you no longer need to think about speech recognition, so we discarded the trade-offs and focused on the sound. No, the woofer does not turn towards the user, but we redirect the mids to tweeters. Above, we called them exclusively tweeters, but they are chosen to cope with the middle frequencies if necessary (they confidently hold from 2k to 20k Hz). And at high volume, the Station switches to stereo mode, which is disabled in normal mode due to its negative effect on speech recognition quality.
We called all this technology Adaptive rossfade, which, I want to believe, will appeal to fans of high-quality sound. By the way, some audiophiles from our team recommend also removing the outer casing to win a couple decibels (yes, it is removable).

Above, we talked about how the station reproduces sound. Now we will talk about the technology platform, thanks to which it understands users.
Yandex.IO
The speakers are an important part of the device, but far from the main one. The station is built around the Yandex.IO platform, which includes two components. First of all, this is the main board, which is responsible for the “brains” of the entire device: plays music and movies, and also ensures that Alice and all her skills work (including those that third-party developers can already create using the Dialogs service).
Brief specification:
- Quad-core ARM Cortex-A53 @ 1 GHz (12000 MIPS)
- RAM: 1 GB DDR3 SDRAM
- Flash storage: 8 GB eMMC
- WiFi: 802.11 b / g / n / ac, dualband, MIMO 2x2
- Bluetooth: BLE 4.1 with A2DP support
- Video: HDMI 1.4 + CEC. FullHD support (1080p)
- Audio input: 16-channel digital audio capturing (I2S with TDM)
- Audio output: 3-channel digital D-class amplifier 30 W + 2x10 W

A few words about the processor. We chose ARM Cortex-A53 not only because of the difficult task of playing streaming video, but also to work with voice. From the side it may seem that there are no special loads here: record the entire audio stream from the microphone and broadcast it to the cloud where the magic neural network recognizes everything. But this is not how it works, and the main station board carries a whole stack of technologies aimed at improving voice recognition. And here we go to the second important component of the IO platform.
Microphone array
The prevalence of smartphones with voice assistants creates the illusion that it is enough to take the same simple microphone and integrate it into a conventional refrigerator that will perfectly hear and understand your voice from any corner of the room. No, it will not. The sensitivity of simple microphones is such that they work only at short distances and in relatively quiet external conditions. There are professional microphones for special purposes that could solve this problem. But they cost hundreds of dollars, and no user device will pull such an increase in value.
In the industry, this problem is solved with the help of microphone arrays. One simple microphone does not cope with the task, but if we take a few and make them work in concert, according to the principle of phased antenna arrays, we will get a good directional microphone. So, the Station uses a microphone matrix of its own design, consisting of 7 microphones: 1 in the center and 6 around the circumference.

Moreover, they are connected to a separate power circuit, and when you press the Mute button on the case, the microphones are physically de-energized. The button does not depend on the software, so this logic cannot be “programmed” to break. Here is a diagram (a simpler flowchart here ):
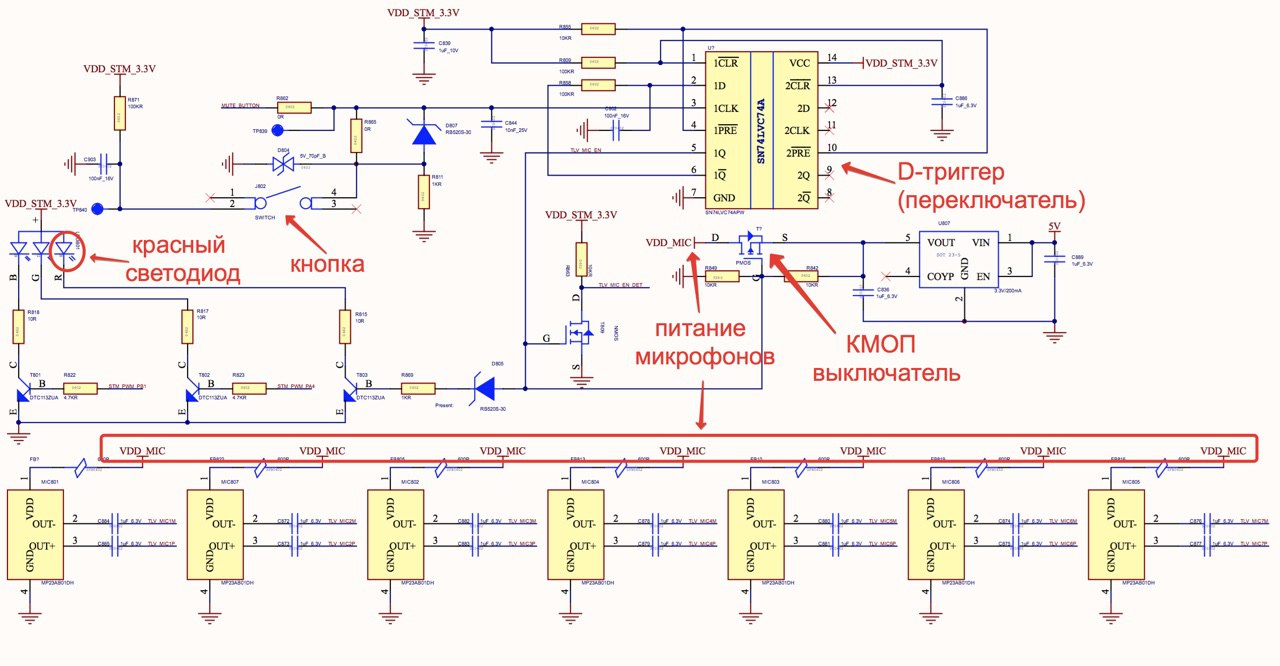
Microphones are not enough for full voice control. The device must be able to distinguish noise from speech and understand commands.
Voice activated
Speech recognition is a very resource-intensive process, so it only works in the cloud. But the Station cannot afford to send all the surrounding noise to the network: it impairs responsiveness, consumes traffic and energy, and provokes a shutdown of voice control. Therefore, our device begins to listen and send sound from microphones to the server only when the user has pronounced the keywords "Alice" or "Yandex." But how does it work without network access?
Keyword recognition is based on Phrase Spotting technology (voice activated). We train a small neural network to find specific keywords in the noise stream, for example, “Alice”. This requires about 100 thousand entries for each word, and for various acoustic conditions (a quiet room, a working television in the background, ...). Moreover, for the Station we needed to collect these records again, and not to use those that remained after the launch of Alice for smartphones. The reason is that voice samples must be recorded for a specific device, otherwise the final recognition quality will be lame.
A neural network trained for voice activation can recognize only a few words, but it works quickly and is built into the device itself, so it does not require an internet connection. Only after the station “heard” a key word in the audio stream, the user's speech begins to be sent to Alice’s server to analyze the request and prepare a response. But not at once.
Speech recognition
It makes no sense to send to the cloud audio stream recorded from 7 microphones. First you need to clear it from the noise and highlight it.
The Direction of Arrival algorithm is responsible for determining the direction in which the source of speech is located. As soon as the direction of speech is determined, the microphone array "turns around" in this direction and sends a "beam" to it. The Beamforming technology allows you to select the sound coming from the target direction, suppressing the sounds coming from other directions. At the same stage, the Noise Suppression and De-reverberation algorithms (reverberation elimination) work.

The source of sound that interferes with speech recognition may be the Station itself while playing music and movies. It would seem that the signal emitted by the Station is known and therefore it can be subtracted from the signal fed to the microphones. But not everything is so simple. This sound comes with repeated repetitions and non-linear distortions (for example, due to the reflections from the walls), and its removal is a non-trivial task. The Acoustic Echo Cancellation algorithm solves this problem.
All of these algorithms work locally on the mainboard of the IO platform. Only after the signal passes through all the stages of cleaning and extracting speech, is it sent to a Yandex server for full recognition by neural networks. You can imagine how hard it is to train them, if thousands of records are required to understand one word. This process is constantly being improved, but we have already managed to achieve speech recognition accuracy comparable to a live interlocutor.
Yandex.Station will soon go on sale - if you leave the address on the site , we will let you know when this happens. In this post, we did not begin to describe all the product capabilities of the device, but focused on the main technological challenges facing the developers of smart devices with voice control. I want to believe that in the near future we will be able to ask Alice to turn on the washing machine, buy tickets, or even feed the cat - and she will fulfill the request. Yandex.Station and IO technology is our first step towards this future.
Source: https://habr.com/ru/post/369353/
All Articles