Bigdata, machine learning and neural networks - for managers
If the manager tries to understand this area and get specific business answers, then, most likely, his head will ache terribly and his heart will be beaten by the sensation of every minute lost benefits.
"AlphaGo beat the champion of Go" for the first time in the history of mankind, soon our streets will be flooded with unmanned vehicles, face recognition and voices are now in the order of things, and tomorrow's AI-sex dolls with champagne under the arm and customizable level of intensity and duration of orgasm.
All this is true, but what to do right now. How to make money on this in the short term? How to lay a solid foundation for the future?
I will try to give exhaustive answers to all the questions that torment you, to open up the pitfalls and, most importantly, to reasonably assess the risks in AI and learn how to manage them correctly. After all, what we do not understand, we do not “dance”.
Many "dregs" and difficult words
This is perhaps the most terrible thing - when a businessman "gets into science."
If a person still has a headache from a quadratic equation in school and his right ear on his left leg is twitching, then the word “perceptron” can lead to loss of consciousness and uncontrolled urination.
Therefore, further - we speak only in clear words. To make it easier - imagine that we are sitting in the bathhouse, drinking beer and reasoning in human language.

Smart boxes with very high ambitions
What is the easiest way to understand how business learning models are applied to business? Imagine a robot, or a “smart” box with a claim to solve the most complicated tasks.
To solve such problems in the forehead is unreal. The car needs to literally prescribe millions of rules and exceptions - so nobody does this.
They do it differently - smart boxes train on data, for example about your customers. And if you already have BigData, the “smart” box can potentially become even “smarter” - ahead of the “boxes” of competitors or ordinary employees, not only in speed, but also in the quality of solutions.
So, we take a sip of beer and remember - the more data you can get, the more “smart” your robo-box will become.

How much data is needed?
It is funny, but humanity still does not have an exact answer to this question. But it is known that the more “quality” data, the better.
And only neural networks, as a rule, better than other methods currently known, can qualitatively extract information from this data.
On the fingers, it is considered that various algorithms NOT on neural networks are capable of learning in tens, hundreds and thousands (and even more) of examples. And even a good job. But teaching them on really large amounts of data is often meaningless and useless. Such algorithms are simply not able to “absorb” the knowledge, no matter how much we try to shove it.
Neural networks, especially the “deep” ones, contain cascades of neural layers and kilograms of difficult-to-explain algorithmic giblets. They are often much better “fed” hundreds of thousands and millions of examples from BigData. But ... dozens and hundreds of examples will not suit them - they will simply remember them and will not be able to adequately predict the future with new data.
Therefore. We take a sip of beer, hug the girl by the waist and remember - if there is not enough data, then it is NOT a neural network (and, for example, catboost ), if there is a lot of neural network, and if there is a lot of data, then ONLY the neural network. Difficult, interesting, attractive and "deep" ( deep learning ).

What data is needed?
Comical to tears, but so far there is no rational answer to this question either: collect all that is possible and impossible. There is no need to go far for an example: large vendors like Google, Facebook, Amazon, Yandex, Mail.ru have been doing this successfully for many years, almost without asking us. Further - it will be even worse.
The activity of people, interests, preferences, movements, acquaintances - all this is often recorded in a rather impersonal form. But ... with reference to the person's identifier.
Trite - according to cookies in the browser or by mobile phone number. And when someone on the Internet comes to your site, you can easily get a digital history of the traces of this person - no matter if it is Ivan Ivanovich or “abh4756shja” - he is interested in ritual axes, so let us show him all their varieties!
More specifically, for example, companies usually collect such statistics from customers:
- number of calls to tech support
- the number and duration of calls to the company for a certain period
- purchased goods and services
- search queries on the company's website
- requests and wishes
- data of the completed questionnaires
- all that can be collected in this spirit
Online stores usually record visited pages and their names. ordered products, search queries, support chat.
As a result, we climb on the shelf higher, where it is hotter in the bathhouse. For further it will be even hotter. And fix in your head - you need to collect / buy everything that is POSSIBLE about our customers. All that characterizes their activity, dynamics and interests.
The more biometrics and telemetry we collect, the better we can then train the smart box and then we can break away from our competitors.

Risks - data quality
Consider an example. Suppose we are trying to determine whether an employee of our company is pregnant? To do this, first collect several parameters:
- the number of visits to the company's doctor
- number of visits to the company's gym
- number of sick days in days
- customer call time in minutes
- the number of early leaving home from work
- time until the end of the working day in minutes
And in that spirit. No one knows what needs to be collected, but intuition tells us that everything will come in handy, even the phases of the moon and the numbers of the re-viewed seasons of the Game of Thrones.
If we collect dozens, and preferably hundreds (thousands) of examples, and they will not be damaged by programmer bugs, then, most likely, our predictive model will learn well. But if we decided to collect 500 parameters for each pregnancy, and we only have 10 real-life statistics on the behavior of pregnant employees, this will not work. Even a child will understand - so the "smart" box will not learn anything sensible, because the data will be heavily discharged.
And it also happens, especially in large companies. You are the big boss or the little boss who is responsible for the large increase in conversion (this also happens sometimes). Analysts bring you data about customers. But the eyes of the "givers" are hidden or run. Or bulging in insane courage. In general, you doubt the quality of this bigdaty. And it is right.
To recognize the catch - find out about the use of engineering practices in the development departments of the technical director:
Do programming teams write modular and integration tests to the code?
Unfortunately, it often happens this way: the programmer leaves, and those who remain do not understand “how it works”. And then the developers can easily break the code. In some moment. Until they find out about it from complaints from angry customers. Or you will learn about this when you cannot train a neuron because of the "curve" bigdaty.
Is automated testing and monitoring of the infrastructure that collects data about your customers configured? Is accurate accounting and error handling maintained? Or is it impossible to determine the percentage of lost data without an exorcist?
If all this is there, then, most likely, they have brought you high-quality bigdata, otherwise - there will be little sense from the collected data, but, nevertheless, it’s worth a try.

There is data. What's next?
Do you want to understand on the fingers that the predictive model trained on the collected data is able? In most cases, she can say yes or no, confidently or not confidently and ... everything. Be sure, right now, write the phrase "predictive" model several times on the back of a tanned girl sitting next to the bath shelf, then apply a few flips with an oak broom. Repeat.
Example. You are an Internet provider. You have a shareware client. Do you want to predict whether he will switch to a paid rate or not? After all, if you can know in advance the future and not yet shown inclinations of clients - you will be able to more effectively use the marketing budget, working with potential and not paying attention to those who will leave us soon.
“Neuron”, at best, after training on the data, will answer you with either a confident “yes”, or an uncertain “yes”, or a confident “no”, or an uncertain “no”. And here you need to very well understand how to work correctly with the concept of "confidence" of the classifier and practice.
Suppose you select only “confident” model responses - and here it may turn out that out of 100 of your clients, the machine will confidently determine the propensity to become paid only for 7 users. And in fact, you have 50 potentially paid customers. Those. The model, because of your caution, has not demonstrated its full predictive potential.
If you lower the threshold of “confidence” and begin to accept less confident answers of the model, it will most likely return you almost all of the really potentially paid customers, but also many others who are not paid - and what do you want to get by lowering the accuracy?
Those. either use high-precision weapons and hit 5% of villains without harming the civilian population, or bang cluster bombs, destroy all villains, but with them all the flora, fauna and low-flying UFOs.
And here we have rested against the understanding of the quality of the predictive model or the binary classifier. Without it, no further. You can choke on this phrase, but that's okay - it will only get worse;) It is important to understand that the better you have trained the model, the more adequate architecture you have chosen for the neural network, the more you get bigdata - the more accurate the predictive model will approach the ideal: predict correctly. In understanding this principle - the key to your success.
Take a sip of beer and analyze another example.
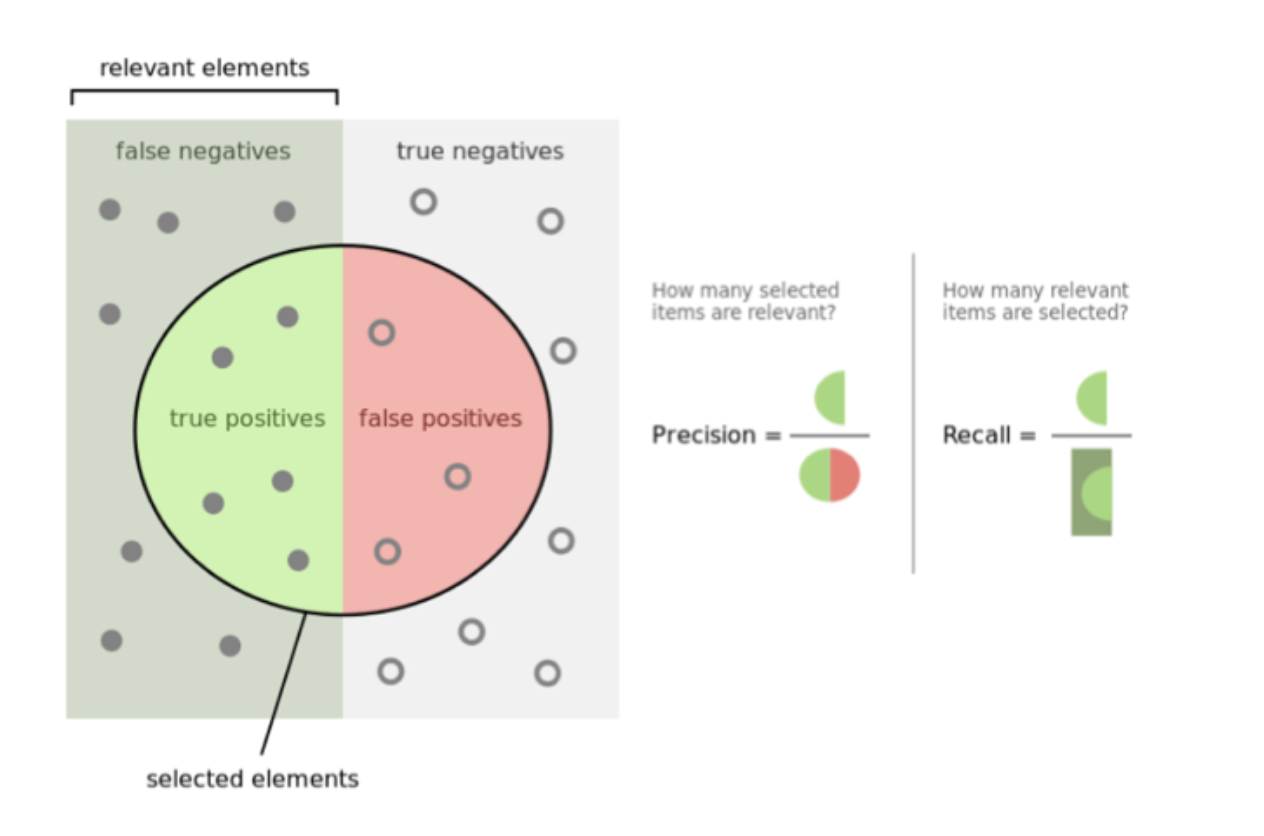
Binary Classifier Quality
Suppose you have collected data on 120 customers and you know for sure - 60 customers have become paid, 60 people have not bought anything. We take 100 examples for training models and 20 for control.
We are training the "smart" box with the help of free software and want to check - and how will it predict the behavior of NEW clients? Linger on this phrase and feel - the binary classifier has already been trained on statistics with an already known outcome. The client either became a “payer” or not. Your goal now is to apply it on new customers that Skynet has never seen before, and make him predict - will he buy your product or not?
Got an idea? You have oracle, his mother for his leg! It really works! This is the strength and essence of machine learning. Learn from historical data and predict the future!
So, back to the sinful earth.
You have trained “Neuron” on 100 clients. We take the remaining 20, which the “smart” box has not yet seen and check - what will it say?
You know in advance - 10 of the remaining customers became paid, and 10 did not.
Ideally, the classifier should “confidently” answer “yes” by 10 and “confidently” answer “no” by 10 remaining customers.
The threshold of "confidence" is set to> = 90% or> = 0.9 of 1.0.
At this stage, you can begin to “turn” the confidence threshold upwards, often receiving much less confident answers, but without errors (prediction of a payee when you really had to predict the freebie): 10 payouts from 10 were predicted, and only 4 were predicted.
And vice versa, if you turn the threshold of confidence down - the “box” will start making more predictions, but it will be more wrong and speak black and white and vice versa.
Once again: on the threshold of confidence, there are 2 options for "turning out the volume":
- AI will give you less answers, but with maximum "confidence" and accuracy = high-precision weapons
- We get more answers, but less accuracy - and false positives will begin = carpet bombing
In order not to go crazy in assessing the quality of binary classifiers, a simple parameter AUC was invented. The closer it is to 1, the closer your model is to the ideal. And the closer you are to the ideal prediction of customer purchases.
Once again, only easier, but now with KPI and bonuses:
- Developers "teach" your binary classifier
- If the output of his AUC is greater than 0.9 - people go on vacation with bonuses
- If AUC is less than 0.9 - “the night is not a hindrance to work” and everyone thinks about where to collect more customer data, how to choose the best architecture for the model and where there are still bugs in the data collection code and neural network training
In general, the simplest thing here is: set your team to the target KPI for the quality of the AUC classifier - get as close as possible to the indicator 1.0 and you will surely beat the competition!
The business application of "smart" boxes
Are you still alive? That's right, then the most interesting will be.
Plunging into the chilling water of mathematics and sobering up, I suggest we return to the girls and natural pleasures.
Now you know what you need to get high-quality "neurons." And where are they used now? Yes, wherever it is necessary to receive the answer “yes” or “no”:
- give a loan?
- Will the existing customer buy your new product?
- Will your free client be paid?
- Will your client go to a competitor?
- Does your employee quit?
- Is the customer satisfied with the quality of your service?
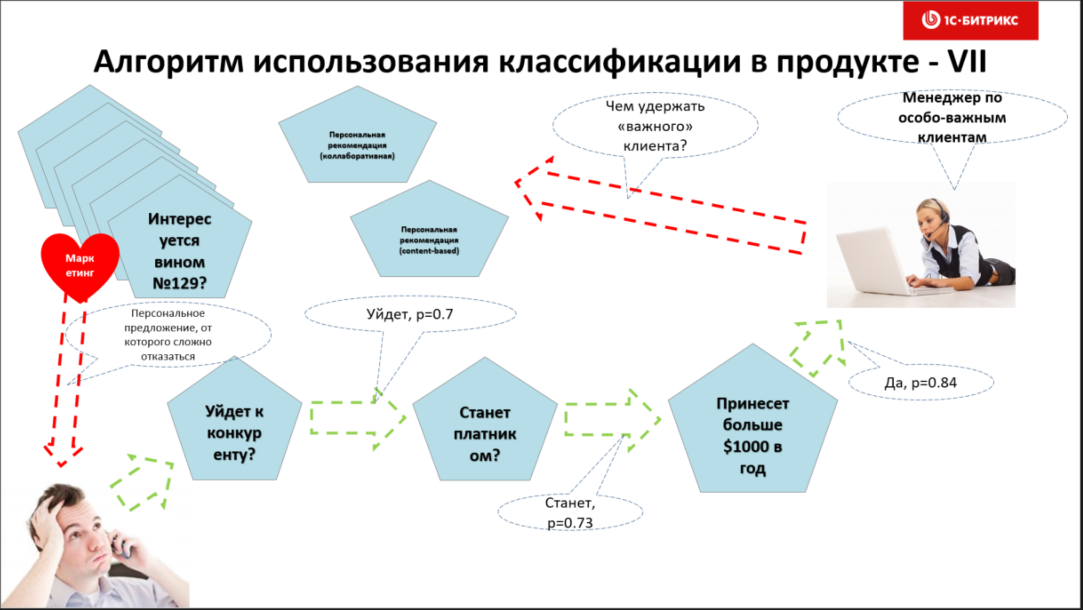
In Bitrix24, we have successfully applied and are using binary classifiers for predictions:
- Will the free client buy a paid Bitrix24 tariff?
- Will a paid client leave us?
- How long will he stay with us?
And all this high-tech is now actively used in the personalization of goods and services, and in the tasks of CRM and where it is not used and will continue to be worse.
Personalization of services and marketing automation
I lead you to one correct conclusion: why the pretzel do extra work with their own hands, if it can be automated? For this, programmers have been created and predictive models have been created for this.
Smart boxes and other types of predictive models can be easily implemented to automate the routine, for example, of the marketing department: auto-targeting promotional offers on the website or in an email newsletter.
So do it soon! Integrate a robot into your online store that will offer personalized products and services to your visitors.
The conversion and loyalty of your customers is guaranteed to grow.
The easiest way to do this is to train several binary classifiers for each product group. And even better - for each proposed service based on the bigdats of your customers' purchases.
Then, when the client returns to your site, the AI will immediately “understand” how it can be “hooked”. It's so easy.
See how many simple and effective ways to increase conversion appeared. So implement them soon.
What's the catch?
Yes, it's all simple. In fact.
Implement predictive models, increase the design capacity of marketing and conversion to CRM - really easy. Moreover, you may not have to buy anything at all. Software for learning "Skynets" is now completely free. And its full.
If absolutely laziness in a stump - you can raise a model in the cloud and pay only hosting, for example, in Amazon Machine Learning .
But why do we see such technologies mainly only in Western companies, solutions and products? The answer is simple - inertness, unwillingness of middle management to develop the effectiveness of the company. In the end, just ... do not care.
I am sincerely convinced that in the near future we will be overwhelmed by the flow of solutions based on predictive analytics and “neural” marketing. This is clearly seen in the speed of machine learning in Facebook, Google, Yandex and Mail.ru advertising services. Who does not implement - give way to competitors.
It is enough to recall the recent opportunities for uploading to Facebook or Google hashes from emails and phones of your clients and the mathematical expansion of the advertising audience to understand what will be next ... only better and more fun
Another reason - marketers often simply do not understand what machine learning gives them! How much time they have free up on creative, if you close the routine targeting and personalization of advertising offers and email-mailing with the help of Skynets!
That is why I write such detailed review articles for management. Who, besides top managers or initiative employees, will be able to promote such revolutionary projects in companies?
Action plan
Basically, now you know enough to effectively implement machine learning, predictive marketing, increase conversion and automate a bunch of routine.
Let me describe the specific steps to the goal:
Time. With the help of the development department or with the hands of one talented engineer - collect customer data or buy it. Start by collecting data on the website or in a mobile application. 5 lines of correctly working city ... but the code - and you will start receiving statistics after 72 hours
Duration: 2-3 days
Two. With the hands of one analyst you create several predictive models, they are also binary classifiers. You can not program anything at all, but immediately upload data to Amazon Machine Learning ( https://aws.amazon.com/aml/details/ ).
Duration: 2-3 days
Three. Embed Skynet into your business processes on the site and in the mobile application
Deadline: 7 days
Scene Collect feedback on the quality of the work of predictive models. For example, through statistics, voting, questionnaires. The goal is to make sure your trained AI works fine with real data.
There is a very simple rule - to update these models once, say, in PI (pi) - months. Someone more often, someone less.
If the conversion is higher than without using the models, then you can not update the models. Fell off - update.
Five. Direct the released resources from the marketing department to solve more pressing problems - for example, to prepare better-quality presentations, proofreading texts, creating beautiful texts for targeted advertising.
Now robots are engaged in targeting and personalization, and people are creating with creativity - as it was planned on the “first day of creation”.
Six. Enjoy efficiency, look for new business points where predictive binary classifiers can protect people from routine!
Friends, on this I have everything. Good luck, successful automation of the routine, obedient robots and good mood!
')
Source: https://habr.com/ru/post/359328/
All Articles