HTTP (S) traffic balancing
 Good afternoon,% username%. My name is Anton Reznikov, I am working on the Cloud Mail.Ru project. Today I want to talk about traffic balancing technologies, illustrating with a story about the development of a social network. All the characters are fictional, and the coincidences are almost random. Article review, compiled in the wake of the report at Highload Junior 2017. Some things may seem elementary, but the experience of interviewing shows that this is not entirely true. Something will be controversial, not without it.
Good afternoon,% username%. My name is Anton Reznikov, I am working on the Cloud Mail.Ru project. Today I want to talk about traffic balancing technologies, illustrating with a story about the development of a social network. All the characters are fictional, and the coincidences are almost random. Article review, compiled in the wake of the report at Highload Junior 2017. Some things may seem elementary, but the experience of interviewing shows that this is not entirely true. Something will be controversial, not without it.If interested, welcome under cat.
What is needed for balancing traffic? Strangely enough, these are not servers or network equipment, but, first of all, a source of traffic, efficient, legal. And without age restrictions. We are ideally suited seals, they even endorses the RKN.
Team
Next, we need a team of professionals.
')
Get to know Left is manager Mike. Ambition is his middle name. Pavel, a programmer on the right, is a little perfectionist and loves to write beautiful code, and rewrite it even more. In the center is administrator Tony, he is rather lazy, but he is responsible and professional.

Plan
And finally, we need a plan! We will talk about the launch of a social network for those who like to post and watch photos of net.cat seals. The plan is ambitious and quite simple.

We will start by launching the beta version by invite. Next, we will seize Moscow, through it we will go to Russia, and then hand in hand before world domination.
Beta
LAMP (Linux, Apache, MySQL and anything with the letter P) was chosen as the platform. In this case, we are most interested in Apache, because it uses the prefork model.

Why pre and why fork ? Each process processes only one user connection at a time. But it is not profitable for us to start the process during the connection setup, so the process starts in advance and processes several connections.
Many of you will say: "Yes, but Apache is not fashionable and not effective." But under Django or PHP FPM lies the same model.
How many workers (worker) can we run? It’s quite simple to get an estimate from above, you need to take the amount of free RAM, divide it by the maximum size of the worker, and we will get a certain N, which is highly undesirable.
How many RPS can we get from one server? We take the number of workers and divide by the average request processing time. It is easy to see that as the request processing time increases, for example, if your MySQL slows down a bit, the RPS drops.

First call
So, Paul launched a prototype network on his computer.

The page turned out quite light, but containing a large number of small files. Paul loved to put everything on the shelves. Then the site was uploaded to the test server to show it to the manager, who is vacationing in Thailand. Unfortunately, the site worked on a test server much slower than on a local computer. Let's see why.

Each browser has a limit on the number of connections to one HTTP host. This limit varies greatly, since until recently the RFC had an obvious limitation ( RFC 2616 8.1.4 ), and more recently, the wording has been replaced by a very streamlined one - “a reasonable number of connections”. This, for example, took advantage of the developers of Internet Explorer. But wait, we still have a 100 Mbps channel, which is not very cheap. Is the provider cheating on us?
No, not this time.
Let's look at the process of transferring a file using the example of the lapka.png file.

To transfer data over the network, the file must be divided into packets. In reality, this happens right when the HTTP server writes the data to the socket, but for the sake of a beautiful picture, we broke it in advance. The first thing a client should do is establish a connection. This happens in the form of the so-called three-step TCP handshake, and is spent on it for about one round-trip, or ping. Also at this stage the request itself is transmitted (in our example, the request is rather small).
Next, the server must send data. But how many packages to send? How wide is the client’s channel? We do not know this yet, so the server starts with a small number of packets, the so-called TCP windows, and sends them to the client.
In this case, two packages. In reality there are more of them. If I'm not mistaken, in modern Linux there is a value of 10. After receiving confirmation from the client, the server realizes that the channel is not overloaded, and sends more data, thereby expanding the window. At the last stage, it sends the last packet. After that, the connection must still be closed.

Something like the change in the width of a TCP window over time within a single connection. In this example, we assume that the losses are due only to channel overload. Therefore, over time, the size of the TCP-window reaches a maximum and fluctuates around this value. The shape of the oscillation depends on the window selection algorithm. This is the perfect case. In reality, very often the window size will squander due to the fact that somewhere on the main channels peak loads occur and packets are lost.
All of this results in a simple relationship: you cannot transfer over one data connection more than the length of a TCP window divided by ping.
That is why the site worked quickly from the local machine, and very slowly from Thailand. That is why all kinds of download managers who download large files in several streams are popular.
Tony quickly found a solution - Keepalive was turned on. But what has changed? For the first request, everything remains the same. We also establish a connection, we also transmit data, we also expand the TCP window, but do not close the connection.
And after a while, if the Keepalive timeout has not expired, the browser can again use this connection, already established, already heated, with a higher data transfer rate.
The attentive reader may notice that Keepalive in Apache is enabled by default in 99.9% of cases. It's like that. But everything is not so clear when your name is Tony and you have paws.

Keepalive is not a panacea
So, Mike was very pleased with the result and decided to start beta testing.

In vain. Something went wrong, and very soon users who received invites began to complain about problems with access to the site.
We still use Apache and the prefork model. With Keepalive turned on, users did not break the connection, as a result, even a small number of clients completely exhausted the number of workers, and new customers could not establish a connection.

Tony was very unhappy that Mike did not warn him about the launch, but he quickly found a solution. In fact, he had long wanted to install Nginx, but damn procrastination did not allow it.

What has changed? Nginx uses a different query processing model. One of his workers can pull thousands, even tens of thousands of connections, and you can run a lot of workers. And even slow clients who previously loaded our server will not cause us problems, since the response from Apache will be read into the Nginx buffer and given at the required speed. As a result, Nginx has turned many connections from users into the minimum required number of requests to Apache.

Moscow
Okay, it's time to go to Moscow. First you need to increase the number of servers. Tony chose a balancing scheme via DNS.
How does this happen? A user addresses our DNS server and asks: “And what is the address of this wonderful social network net.cat?”. The server gives it two IP addresses, after which the client randomly selects a server and sends requests. Due to the fact that there are a lot of clients and there is no particular pattern in the choice of server, we get a uniformly smeared load.

How many servers can you balance with such a scheme?
According to the current RFC 1123, the DNS server must support UDP and transmit data through it no larger than 512 bytes. It is desirable to support TCP, but not necessarily what many system administrators use. Actually, it is obligatory from 2016, but remember IPv6, and try to predict when this requirement of the standard will come true.

According to the same standard, we have to spend 16 bytes on one A-record, and about 100 bytes on a header. The result is a maximum of 25 servers using UDP.
But there is a nuance.
Clients almost never access our server directly. Usually there is a provider’s DNS server between our server and the client, the client’s router (the router in the original is pronounced [ˈruːtər] ), perhaps also a local caching DNS on his machine. Therefore, it is extremely rare for someone to scale this way over four or six addresses.

In addition, when balancing servers in this way, the question arose: what to do with pictures?

First, I would not want to store them in four copies, namely, four servers planned to be installed by Tony. In addition, when transferring pictures, the connections to the server were “blocked”, and small requests to the API were forced to wait for their turn long enough - the site became less responsive. Therefore, static and client content were transferred to a separate server. This not only allowed to save on disks, but also increased the speed of the site.

Mysterious glitch
So, the service worked on four servers that support the API, but one day early on Monday morning the delta server went away and never returned.
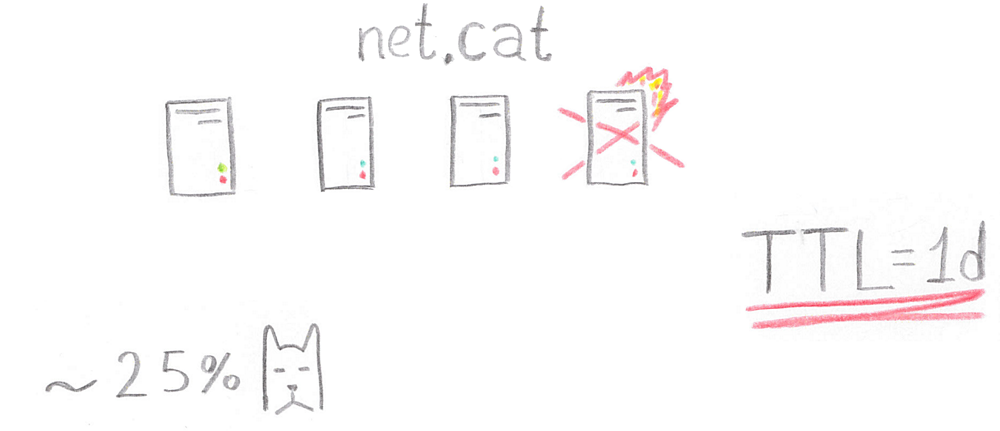
Worse, TTL (and this is the time during which customers can not re-request information about the site’s IP address) had a duration of one day. 25% of users began to experience problems accessing the site.
Tony called a specialist on duty from the data center and asked to raise any server with this IP address in order to proxy requests from the raised server to the working servers with Apache. But as soon as the server was raised, the problem immediately disappeared by itself.
What happened?
Any modern client is able to sort through all the addresses from the response from the DNS server. If your server lies down and does not respond, the client will wait for a connection timeout: what if the server responds to it. If, as in our case, the server is raised, but no web service is running on it, and no one accepts the connection on port 80, the client is rejected for almost the time equal to one ping. After that, the client is transparent to the user goes to another service.

Seals vs Dogs
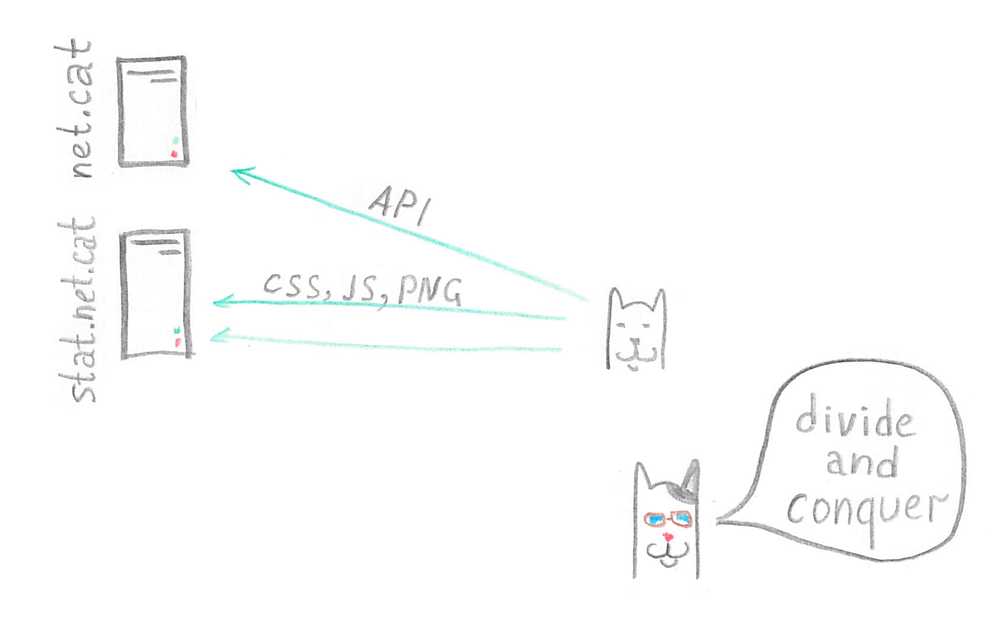
Dog breeders really disliked this social network. How is it: seals, seals, seals, and no dogs? And once they discovered that search queries are very slow. They thought: “What if we set Apache Benchmark (this utility to test the performance of your service) on this social network?”. After all, the utility does not ask if you are testing your site or not. So they did. Generated a large number of requests to the API Search method, and the servers became ill. MySQL slowed down, and everything went to the fact that the site soon had to completely "lie down". Worse, since a lot of statics were stored on the same servers - JS, CSS files - it was impossible to use limits on connections. Customers would not be able to quickly load statics.

In fact, with the netfilter it was possible to solve the problem, but what administrator can configure it early on Monday morning? Nginx also does not know how to work with path limits. And it’s too late to implement software limits when they try to install your server.

Therefore, Tony made a strong-willed decision: it’s better to lose one function than everything, and the search was turned off. And as a result of the incident, Tony and Pavel decided to transfer all the statistics to a separate server. This not only simplified Tony’s life, since now he could easily limit the number of requests, but also increased the speed of access to the site.
Conquer Russia
Let's start by moving to a new data center with a good SLA. Tony prudently set the TTL on the zone in five minutes, and expected that within 10, a maximum of 30 minutes, all users would switch from the IP addresses of the old data center to the IP addresses from the new data center.

As if not so.
A significant part of users continued to use old DNS servers, which, by the way, flew into a pretty penny. The manager, Mike, had to pay for two additional weeks of rent. And he demanded an explanation.

The story was simple and entertaining. The city had three popular providers.

One of them, Cat Telecom, did not make any changes to the traffic, and everything was fine with it. Evil Telecom saved on traffic, so all queries to the DNS were forcibly cached for one day. School Telecom saved on system administrators, so most of their configuration files were a compilation with Stack Overflow, and caching was mysteriously set up in one week.

Distribution of content
Also, the question arose with the servers of user content. There were many photos, and they could not be stored on one server, so it was decided to buy two more.
How to balance the load between them? Tony and Paul argued for a long time. Tony offered to distribute requests with redirects, because the server side knows where the file is located, we can direct the client to the necessary storage.

Pavel did not want to create a new service, he also reasonably noted that this method is not suitable for apload. He offered to give the client the full address of the picture, and the algorithm for choosing the storage on the client. The task of the algorithm is to pick up the list of servers available for downloading and select one to load the image, randomly or by hashing the client ID.
Tony politely reminded about the 307 redirect, but agreed that it works with POST requests on all clients. However, he was strongly opposed to the decision on JS. Tony needed the ability to move data, remove servers from the load and add new ones. In spite of the fact that Pavel promised to foresee all this, Tony refused to accept the code operating “somewhere out there” for a while. We can control only what the foot is reaching - said Tony.

Not enough time was spent, but friends came to a compromise. Servers with content were hidden behind the proxy layer, which “knew” where to go for a certain picture and which server is better to choose to save the new one. JS left the choice of a proxy server, their list was periodically requested from the server, which made it possible to quickly remove new connections from the proxy server and soon remove it from the load unnoticed by users. The scheme allowed, if necessary, adjust the cache for particularly hot content, as well as move to storing multiple copies of files. Tony was pleased to the tip of the tail.
API Balancing
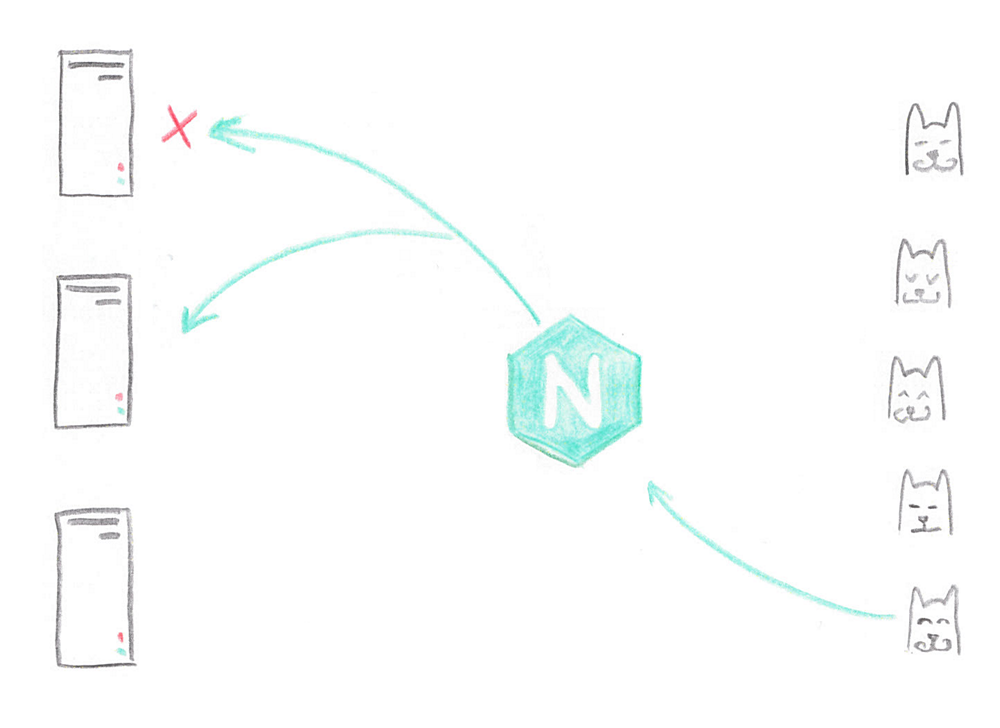
Also, there was a question about scaling servers under the API. Nobody wanted 20 servers to score DNS, so Tony singled out individual servers, calling them balancers, and put Nginx there.

Nginx evenly distributed requests between servers with Apache, everything went fine. Moreover, if for some reason one of the servers broke down, Nginx transparently for the user redirected the request to another working server. Tony liked it.
Query of DEATH
Often in high-load projects, heavy logic is implemented in lower level languages. So it was in our case. A special code for adding stickers to photos was written in C ++. Unfortunately, one of the exceptions was not handled, and, having received a “broken” jpeg, such code fell along with the worker.

What did Nginx do? Having decided that the server is bad, Nginx marked it for 10 seconds as unavailable, and moved on to the new server. The bug was remarkably reproduced on all servers in the cluster, while at least something worked. After that, the site became unavailable for 10 seconds.

Tony bit his elbows. He was very unhappy, but he understood that the point was not Nginx, but that he had not read the documentation carefully enough. It was necessary only to limit the number of attempts to access other servers. It was enough for two, a maximum of three. Why bypass the entire cluster? So Tony did. And also decided that after one error the server is still too early to mark as failed.
Reserve nginx
We still have one more point of failure - the server itself with Nginx.
If something goes wrong - the cleaner in the data center stumbles over the cable, or the power supply burns out - the site becomes inaccessible for about half of the users. Tony decided that VRRP would save the day.

This is a solution in which there is a so-called VIP (Virtual IP), which serves two servers: master and backup. Master serves requests always, backup - if something goes wrong.

Unfortunately, this scheme required an L2 network between servers, and Tony recently bought new Kisa equipment. Therefore, he decided to remake the scheme for working with IBGP . In fact, he could use another protocol, for example, OSPF . In this scheme, there was no need for an L2 network between servers, but there was also Virtual IP, which was announced by two servers with different metrics. If master worked, then traffic went to it, since it announced an IP with a smaller metric. If something went wrong, the backup took over the load.

Have you ever been to Rio?
Mike dreamed Rio de Janeiro. One and a half million people, and all polls in white pants! Therefore, they decided to start expansion with Brazil. To increase the responsiveness of the site, servers in Rio de Janeiro were raised, and traffic from users was distributed using geoDNS . Everything was going well, but some users from Russia got to Brazil. More precisely, not users got, they would not have objected to such a scenario. Got their requests. And the site they worked much slower than those whose requests fell into Russia. This was mainly caused by the use by clients of public DNS servers, but sometimes it happened because of an insufficiently rapid update of the geoDNS database.

The scheme is, in principle, working, but requires active support. Therefore, Tony, by virtue of his laziness, decided to apply a less troublesome solution.
An autonomous system was purchased. This is a set of IP addresses that are managed by a single administrator. Under the administrator does not mean the sysadmin, and some organization that buys this set of addresses.
The autonomous system rises in several places and is announced to neighbors, with whom we must agree on the purchase of channels. In this case, these are three points. After that, the client can contact any of the points where the desired IP address is raised. But the route from the client is not chosen by him, the route is chosen first by the provider. The provider uses all the same BGP (now without I), and its equipment builds routes for all addresses on the Internet. If the address is available from several places, the route with the lowest metric is chosen.

As a rule, this is the number of autonomous systems traversed between the source and the receiver. If the political conjuncture does not interfere, the traffic will take the shortest route. If the client is located somewhere in the Moscow region, then he has almost no chance to get to other servers outside of Moscow.
If you agree with the neighbors (neighboring autonomous systems), then the traffic through them can go from around the world. That was done. The autonomous system was raised at three points. With VIP, it was enough to give the client one HTML page, in which servers with API, statics and content were registered in Rio, Moscow or New York.
Users from Moscow began to get to the servers in Moscow, and users from Brazil to the servers in Rio de Janeiro. And if the data center in Moscow falls, the BGP sessions with neighbors will be broken, and more they will not see the route to the right IP in this place. Perhaps New York in this case is much closer than Brazil, and traffic will go there. Naturally, everything will work slower.
Epilogue
Michael led his team to the intended goal. And what have we come to? I will allow myself to sound a few simple truths, a bit boring, but as short as possible.
Do not look for a universal solution, the best enemy of the good.
Have a plan B, and better B, C, etc. Everything breaks, if it does not break with you, it breaks with neighbors, but they will learn about it from you ...
And do not neglect the documentation, no matter how trite it may sound.

Source: https://habr.com/ru/post/359316/
All Articles