Pacemaker / corosync cluster without validol
Imagine the situation. Saturday evening. You are the PostgreSQL administrator, after a hard working week you left for the dacha 200 km from your favorite job and you feel great ... As long as your peace does not disturb the SMS from the Zabbix monitoring system. There was a failure on the DBMS server, the database is currently unavailable. To solve the problem is given a short time. And you have no choice but to saddle a service scooter with your heart and rush to work. Alas!

But it could be different. You receive an SMS from the monitoring system that a failure occurred on one of the servers. But the DBMS continues to work, since the PostgreSQL failover cluster has completed the loss of one node and continues to function. There is no need to urgently go to work and restore the database server. Clarification of the causes of failure and recovery work quietly transferred to the working Monday.
Anyway, it is worth thinking about technologies of fault-tolerant clusters with PostgreSQL DBMS. We will talk about building a PostgreSQL database failover cluster using Pacemaker & Corosync software.
')
Today, in IT systems of the “business critical” level, the demand for broad functionality is becoming secondary. In the first place comes the demand for reliability of IT systems For fault tolerance, it is necessary to introduce redundancy of system components. They are managed by special software.
An example of such software is Pacemaker, a solution from ClusterLabs , which allows you to organize a fault-tolerant cluster (OAK). Pacemaker runs under a wide range of operating Unix systems - RHEL, CentOS, Debian, Ubuntu .
This software was not created specifically to work with PostgreSQL or other DBMS. The scope of Pacemaker & Corosync is much wider. There are specialized solutions sharpened for PostgreSQL, for example multimaster , part of Postgres Pro Enterprise (Postgres Professional), or Patroni ( Zalando ). But the PostgreSQL cluster based on Pacemaker / Corosync, considered in the article, is quite popular and is suitable for a considerable number of situations in terms of simplicity and reliability to the cost of ownership. It all depends on the specific tasks. Comparing solutions is beyond the scope of this article.
So: Pacemaker is a brain and part-time cluster resource manager. His main task is to achieve maximum availability of the resources he manages and protect them from failures.
During the operation of the cluster, various events occur - failure, joining of nodes, resources, transition of nodes to service mode, and others. Pacemaker responds to these events in a cluster by performing actions it is programmed for, such as stopping resources, moving resources, and others.
In order to make it clear how Pacemaker works and works, let's consider what is inside and what it consists of.
So, let's go to the Pacemaker entities.
Figure 1. The pacemaker entities - cluster nodes
The first and most important entity is the nodes of the cluster. A node (
Nodes intended to provide the same services should have the same software configuration. That is, if the postgresql resource is supposed to run on
The next important Pacemaker entity group is cluster resources . In general, for Pacemaker, a resource is a script written in any language. Usually these scripts are written in
However, in our case, the PostgreSQL cluster, we add promote , demote, and other PostgreSQL-specific commands to these actions.
Examples of resources:
Resources have many attributes that are stored in Pacemaker’s XML configuration file. The most interesting of them are: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Consider them in more detail.
The priority attribute is the resource priority, which is taken into account if the node has reached the limit on the number of active resources (default is 0). If the cluster nodes are not equal in performance or availability, then you can increase the priority of one of the nodes so that it is always active when it is running.
The resource- stickiness attribute is resource stickiness (default is 0). Stickiness (stickiness) indicates how resource "wants" to remain where it is now. For example, after a node fails, its resources are transferred to other nodes (more precisely, they start on other nodes), and after the failed node recovers, the resources may return to it or not, and this behavior is described by the stickiness parameter.
In other words, stickiness shows how desirable or not desirable the resource is to return to the node restored after the failure.
Since the default stickiness of all resources is 0, then Pacemaker itself allocates resources on the nodes "optimally" at its discretion.
But this may not always be optimal from an administrator’s point of view. For example, in the case when the nodes in the failover cluster have unequal performance, the administrator will want to start the services on the node with higher performance.
Pacemaker also allows you to set different stickiness of a resource depending on the time of day and day of the week, which allows, for example, to ensure that the resource is transferred to the original node during off-hours.
The migration-threshold attribute — how many failures must occur for Pacemaker to decide that a node is unsuitable for this resource and transfer (migrate) it to another node. By default, this parameter is also 0, that is, with any number of failures, automatic transfer of resources will not occur.
But, in terms of fault tolerance, set this parameter correctly to 1, so that at the first failure Pacemaker moves the resource to another node.
The failure-timeout attribute is the number of seconds after a failure, before the expiration of which Pacemaker believes that a failure did not occur, and does not do anything, in particular, does not move resources. The default is 0.
The attribute multiple-active - instructs Pacemaker what to do with the resource if it is running on more than one node. It can take the following values:
By default, the cluster does not monitor after startup whether the resource is alive. To enable resource tracking, you need to add a
When a failure occurs on the primary node, Pacemaker “moves” resources to another node (in fact, Pacemaker stops resources on the failed node and starts resources on another). The process of "moving" resources to another node is quick and transparent to the end client.
Resources can be grouped together — lists of resources that must be started in a specific order, stopped in the reverse order and executed on one node. All group resources are started on one node and started sequentially according to the order in the group. But keep in mind that if one of the group's resources fails, the whole group will move to another node.
When you turn off any resource group, all subsequent resources of the group also turn off. For example, a PostgreSQL resource of type pgsql and a Virtual-IP resource of type IPaddr2 can be combined into a group.
The startup sequence in this group is as follows: PostgreSQL is first launched, and when it is successfully launched, the Virtual-IP resource is launched after it.
What is quorum? It is said that a cluster has a quorum with a sufficient number of “live” cluster nodes. The sufficiency of the number of "live" nodes is determined by the formula below.
n> N / 2 , where n is the number of living nodes, N is the total number of nodes in the cluster.
As can be seen from a simple formula, a cluster with a quorum is when the number of “live” nodes is more than half the total number of nodes in the cluster.
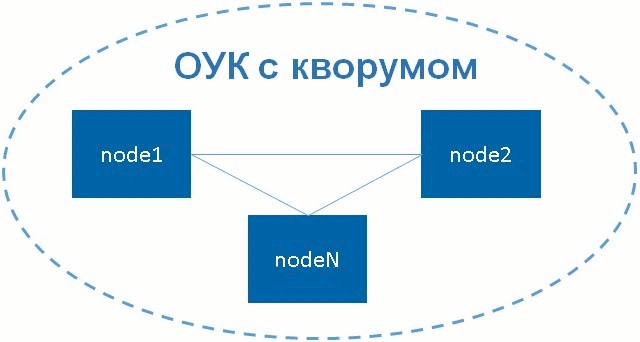
Figure 2 - Failover Cluster with Quorum
As you probably understand, in a cluster consisting of two nodes, if one of the 2 nodes fails, there will be no quorum. By default, if there is no quorum, Pacemaker stops resources.
To avoid this, when setting up Pacemaker, you need to tell it so that the presence or absence of a quorum is not taken into account. This is done using the no-quorum-policy = ignore option.
The architecture of Pacemaker consists of three levels:

Figure 3 - Pacemaker Levels
For a failover cluster to function properly, the following requirements must be met:
Consider these requirements in more detail.
Time synchronization - it is necessary that all nodes have the same time, usually this is done by installing a time server in the local network (
Name resolution is implemented by installing a DNS server in the local network. If you cannot install a DNS server, you need to make entries on the / etc / hosts file with host names and IP addresses on all nodes of the cluster.
Stability of network connections . It is necessary to get rid of false positives. Imagine that you have an unstable local network in which every 5-10 seconds there is a loss of link between the cluster nodes and the switch. In this case, Pacemaker will consider link failure to disappear for more than 5 seconds. Missing link, your resources "moved." Then the link was restored. But Pacemaker already considers the node in the cluster “failed”, it has already “transferred” resources to another node. At the next failure, Pacemaker will “transfer” resources to the next node, and so on, until all the nodes have run out and a denial of service occurs. Thus, due to false positives, the entire cluster may cease to function.
The presence of cluster power management functions / reboot using IPMI (ILO) for the organization of "fensing . " It is necessary in order to isolate it from the remaining nodes when a node fails. "Fensing" eliminates the situation of a split-brain (when there are simultaneously two nodes that perform the role of the PostgreSQL DBMS).
Allow traffic through protocols and ports . This is an important requirement, because in various organizations, security services often place restrictions on the passage of traffic between subnets or restrictions at the switch level.
The table below lists the protocols and ports that are required for a failover cluster to function.
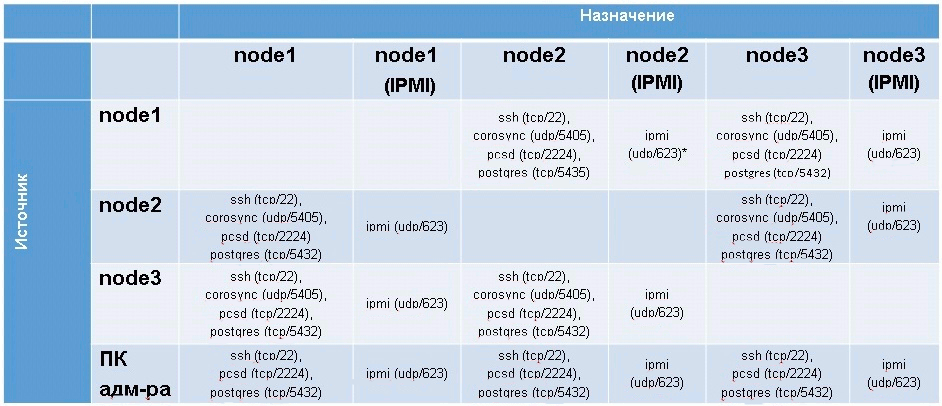
Table 1 - The list of protocols and ports required for the operation of the OAK
The table shows the data for the case of a failover cluster of 3 nodes -
As the table shows, it is necessary to ensure not only the availability of neighboring nodes in the local network, but also the availability of nodes in the IPMI network.
When using virtual machines to build fault-tolerant clusters, the following features should be considered.
When using PostgreSQL in failover clusters, the following features should be considered:
Here are some interesting Pacemaker management commands (all commands require the rights of the OS superuser). The main cluster management utility is pcs . Before setting up and first launching the cluster, you need to authorize the nodes in the cluster once.
Start / stop on one node:
Viewing Cluster Status with Corosync Monitor:
Crash counters clearing:
Pacemaker has a built-in cluster status monitoring utility. The system administrator can use it to see what is happening in the cluster, what resources on which nodes are currently located.
Using the crm_mon command, you can monitor the state of the PDM.
The screenshot shows a cluster status report.
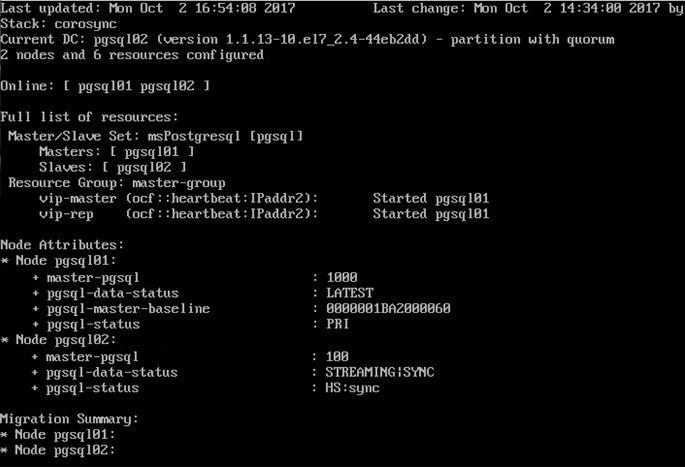
Figure 4 - Monitoring the status of the cluster using the crm_mon command
pgsql-status
pgsql-data-status
pgsql-master-baseline
Shows the time line. The time line changes every time after the promote command on a node replica. After this, the DBMS starts a new countdown.
What kinds of failures does a fail-safe cluster based on Pacemaker protect against?
To carry out maintenance work, it is necessary to periodically remove from the cluster the individual nodes:
Important! Before changing roles or decommissioning the Master, it is necessary to make sure that there is a synchronous replica in the cluster using the #crm_mon –Afr command . And the role of the Master is always assigned to a synchronous replica.
Since the purpose of this not so short article is to introduce you to one of the resiliency solutions of the PostgreSQL DBMS, the installation, configuration and configuration commands of the failover cluster are not considered.
The author of the article is Igor Kosenkov , Postgres Professional engineer.
Drawing - Natalia Lyovshina .
But it could be different. You receive an SMS from the monitoring system that a failure occurred on one of the servers. But the DBMS continues to work, since the PostgreSQL failover cluster has completed the loss of one node and continues to function. There is no need to urgently go to work and restore the database server. Clarification of the causes of failure and recovery work quietly transferred to the working Monday.
Anyway, it is worth thinking about technologies of fault-tolerant clusters with PostgreSQL DBMS. We will talk about building a PostgreSQL database failover cluster using Pacemaker & Corosync software.
')
Failover Cluster PostgreSQL DBMS Based on Pacemaker
Today, in IT systems of the “business critical” level, the demand for broad functionality is becoming secondary. In the first place comes the demand for reliability of IT systems For fault tolerance, it is necessary to introduce redundancy of system components. They are managed by special software.
An example of such software is Pacemaker, a solution from ClusterLabs , which allows you to organize a fault-tolerant cluster (OAK). Pacemaker runs under a wide range of operating Unix systems - RHEL, CentOS, Debian, Ubuntu .
This software was not created specifically to work with PostgreSQL or other DBMS. The scope of Pacemaker & Corosync is much wider. There are specialized solutions sharpened for PostgreSQL, for example multimaster , part of Postgres Pro Enterprise (Postgres Professional), or Patroni ( Zalando ). But the PostgreSQL cluster based on Pacemaker / Corosync, considered in the article, is quite popular and is suitable for a considerable number of situations in terms of simplicity and reliability to the cost of ownership. It all depends on the specific tasks. Comparing solutions is beyond the scope of this article.
So: Pacemaker is a brain and part-time cluster resource manager. His main task is to achieve maximum availability of the resources he manages and protect them from failures.
During the operation of the cluster, various events occur - failure, joining of nodes, resources, transition of nodes to service mode, and others. Pacemaker responds to these events in a cluster by performing actions it is programmed for, such as stopping resources, moving resources, and others.
In order to make it clear how Pacemaker works and works, let's consider what is inside and what it consists of.
So, let's go to the Pacemaker entities.
Figure 1. The pacemaker entities - cluster nodes
The first and most important entity is the nodes of the cluster. A node (
node ) of a cluster is a physical server or virtual machine with Pacemaker installed.Nodes intended to provide the same services should have the same software configuration. That is, if the postgresql resource is supposed to run on
node1, node2 , and it is located in non-standard installation paths, then these nodes should have the same configuration files, PostgreSQL installation paths, and of course, the same PostgreSQL version.The next important Pacemaker entity group is cluster resources . In general, for Pacemaker, a resource is a script written in any language. Usually these scripts are written in
bash , but nothing prevents you from writing them in Perl, Python, C or even PHP . The script controls the services in the operating system. The main requirement for scripts is to be able to perform 3 actions: start, stop, monitor and share some meta-information.However, in our case, the PostgreSQL cluster, we add promote , demote, and other PostgreSQL-specific commands to these actions.
Examples of resources:
- IP address;
- service launched in the operating system;
- block device
- file system;
- others.
Resources have many attributes that are stored in Pacemaker’s XML configuration file. The most interesting of them are: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Consider them in more detail.
The priority attribute is the resource priority, which is taken into account if the node has reached the limit on the number of active resources (default is 0). If the cluster nodes are not equal in performance or availability, then you can increase the priority of one of the nodes so that it is always active when it is running.
The resource- stickiness attribute is resource stickiness (default is 0). Stickiness (stickiness) indicates how resource "wants" to remain where it is now. For example, after a node fails, its resources are transferred to other nodes (more precisely, they start on other nodes), and after the failed node recovers, the resources may return to it or not, and this behavior is described by the stickiness parameter.
In other words, stickiness shows how desirable or not desirable the resource is to return to the node restored after the failure.
Since the default stickiness of all resources is 0, then Pacemaker itself allocates resources on the nodes "optimally" at its discretion.
But this may not always be optimal from an administrator’s point of view. For example, in the case when the nodes in the failover cluster have unequal performance, the administrator will want to start the services on the node with higher performance.
Pacemaker also allows you to set different stickiness of a resource depending on the time of day and day of the week, which allows, for example, to ensure that the resource is transferred to the original node during off-hours.
The migration-threshold attribute — how many failures must occur for Pacemaker to decide that a node is unsuitable for this resource and transfer (migrate) it to another node. By default, this parameter is also 0, that is, with any number of failures, automatic transfer of resources will not occur.
But, in terms of fault tolerance, set this parameter correctly to 1, so that at the first failure Pacemaker moves the resource to another node.
The failure-timeout attribute is the number of seconds after a failure, before the expiration of which Pacemaker believes that a failure did not occur, and does not do anything, in particular, does not move resources. The default is 0.
The attribute multiple-active - instructs Pacemaker what to do with the resource if it is running on more than one node. It can take the following values:
- block - set the unmanaged option, that is, deactivate
- stop_only - stop on all nodes
- stop_start - stop on all nodes and run only on one (default value).
By default, the cluster does not monitor after startup whether the resource is alive. To enable resource tracking, you need to add a
monitor operation when creating a resource, then the cluster will monitor the state of the resource. The interval parameter of this operation is the interval with which to do the check.When a failure occurs on the primary node, Pacemaker “moves” resources to another node (in fact, Pacemaker stops resources on the failed node and starts resources on another). The process of "moving" resources to another node is quick and transparent to the end client.
Resource groups
Resources can be grouped together — lists of resources that must be started in a specific order, stopped in the reverse order and executed on one node. All group resources are started on one node and started sequentially according to the order in the group. But keep in mind that if one of the group's resources fails, the whole group will move to another node.
When you turn off any resource group, all subsequent resources of the group also turn off. For example, a PostgreSQL resource of type pgsql and a Virtual-IP resource of type IPaddr2 can be combined into a group.
The startup sequence in this group is as follows: PostgreSQL is first launched, and when it is successfully launched, the Virtual-IP resource is launched after it.
Quorum (quorum)
What is quorum? It is said that a cluster has a quorum with a sufficient number of “live” cluster nodes. The sufficiency of the number of "live" nodes is determined by the formula below.
n> N / 2 , where n is the number of living nodes, N is the total number of nodes in the cluster.
As can be seen from a simple formula, a cluster with a quorum is when the number of “live” nodes is more than half the total number of nodes in the cluster.
Figure 2 - Failover Cluster with Quorum
As you probably understand, in a cluster consisting of two nodes, if one of the 2 nodes fails, there will be no quorum. By default, if there is no quorum, Pacemaker stops resources.
To avoid this, when setting up Pacemaker, you need to tell it so that the presence or absence of a quorum is not taken into account. This is done using the no-quorum-policy = ignore option.
Pacemaker architecture
The architecture of Pacemaker consists of three levels:
Figure 3 - Pacemaker Levels
- Cluster-independent level - resources and agents. At this level are the resources themselves and their scripts. The figure is indicated in green.
- The resource manager (Pacemaker) is the “brain” of the cluster. It responds to events occurring in a cluster: failure or connection of nodes, resources, transition of nodes to service mode, and other administrative actions. The figure is marked in blue.
- Information level (Corosync ) - at this level the network interaction of nodes is carried out, i.e. transfer of service commands (start / stop of resources, nodes, etc.), exchange of information on the completeness of the cluster (
quorum), etc. In the figure it is indicated in red.
What do you need to work Pacemaker?
For a failover cluster to function properly, the following requirements must be met:
- Time synchronization between nodes in a cluster
- Resolving node names in a cluster
- Network Connection Stability
- The presence of cluster power management / reboot functions using IPMI (ILO) for the organization of "fencing" (fencing - isolation) node.
- Allow traffic through protocols and ports
Consider these requirements in more detail.
Time synchronization - it is necessary that all nodes have the same time, usually this is done by installing a time server in the local network (
ntpd ).Name resolution is implemented by installing a DNS server in the local network. If you cannot install a DNS server, you need to make entries on the / etc / hosts file with host names and IP addresses on all nodes of the cluster.
Stability of network connections . It is necessary to get rid of false positives. Imagine that you have an unstable local network in which every 5-10 seconds there is a loss of link between the cluster nodes and the switch. In this case, Pacemaker will consider link failure to disappear for more than 5 seconds. Missing link, your resources "moved." Then the link was restored. But Pacemaker already considers the node in the cluster “failed”, it has already “transferred” resources to another node. At the next failure, Pacemaker will “transfer” resources to the next node, and so on, until all the nodes have run out and a denial of service occurs. Thus, due to false positives, the entire cluster may cease to function.
The presence of cluster power management functions / reboot using IPMI (ILO) for the organization of "fensing . " It is necessary in order to isolate it from the remaining nodes when a node fails. "Fensing" eliminates the situation of a split-brain (when there are simultaneously two nodes that perform the role of the PostgreSQL DBMS).
Allow traffic through protocols and ports . This is an important requirement, because in various organizations, security services often place restrictions on the passage of traffic between subnets or restrictions at the switch level.
The table below lists the protocols and ports that are required for a failover cluster to function.
Table 1 - The list of protocols and ports required for the operation of the OAK
The table shows the data for the case of a failover cluster of 3 nodes -
node1, node2, node3 . It also implies that cluster nodes and node power management interfaces (IPMI) are on different subnets.As the table shows, it is necessary to ensure not only the availability of neighboring nodes in the local network, but also the availability of nodes in the IPMI network.
Features of use of virtual computers for OAK
When using virtual machines to build fault-tolerant clusters, the following features should be considered.
- fsync. Fault tolerance PostgreSQL DBMS is very strongly tied to the ability to synchronize the recording in the permanent storage (disk) and the correct functioning of this mechanism. Different hypervisors implement caching of disk operations in different ways, some do not provide timely data dumping from the cache to the storage system.
- realtime corosync. The corosync process in a Pacemaker based PDA is responsible for detecting cluster node failures. In order for it to function correctly, it is necessary that the OS is guaranteed to schedule its execution on the processor (the OS allocates processor time). In this regard, this process has the priority of RT (
realtime). In a virtualized OS, there is no way to guarantee such process planning, which leads to false positives of cluster software. - fensing In a virtualized environment, the
fencingmechanism becomes more complex and multi-layered: at the first level, you need to turn off the virtual machine through the hypervisor, and at the second level, turn off the entire hypervisor (the second level works when the first fensing level did not work correctly). Unfortunately, some hypervisors do not have fencing. We recommend not using virtual machines when building an OAK.
Features of using PostgreSQL for OAK
When using PostgreSQL in failover clusters, the following features should be considered:
- Pacemaker when starting a cluster with PostgreSQL places the lock file LOCK.PSQL on the node with the DBMS master. Usually this file is located in the
/var/lib/pgsql/tmp. This is done with the intention of preventing the automatic launch of PostgreSQL in the event of a failure on the Wizard. Thus, after a failure on the wizard, the intervention of the DBA is always required to eliminate the causes of the failure. - Since a standard PostgreSQL Master-Slave scheme is used in OAK, with certain failures the situation of two Masters is possible - the so-called. split-brain . For example, failure The loss of network connectivity between any of the nodes and the other nodes (for all types of failures, see below). In order to avoid this situation, it is necessary to fulfill two important conditions when building fault-tolerant clusters:
- availability of quorum in OAK . This means that there must be at least 3 nodes in the cluster. Moreover, it is not necessary to have all three nodes with a DBMS, it is enough to have a Master and a Replica on two nodes, and the third node acts as a “voter”.
- The presence of fensing devices on the nodes with the database . In the event of a failure, the fensing devices isolate the failed node by sending a command to turn off the power or reboot (
powerofforhard-reset).
- WAL archives are recommended to be placed on
sharedstorage devices available to both the Wizard and the Replica. This will simplify the process of restoring the Master after a failure and transfer it toSlavemode. - To manage PostgreSQL DBMS, when setting up a cluster, you need to create a resource of type pgsql. When creating a resource, specific features of PostgreSQL are taken into account, such as the path to the data (for example,
pgdata="/var/lib/pgsql/9.6/data/"), the path to the command files (psql="/usr/pgsql-9.6/bin/psql"andpgctl="/usr/pgsql-9.6/bin/pg_ctl"), replica type (rep_mode="sync"), virtual ip-address for the Master (master_ip="10.3.3.3"), and also some parameters which are added to therecovery.conffile on the replica (restore_command="cp /var/lib/pgsql/9.6/pg_archive/%f %p"andprimary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5").
An example of creating a PostgreSQL resource of type pgsql in a cluster of three nodes: pgsql01, pgsql02, pgsql03:sudo pcs resource create PostgreSQL pgsql pgctl="/usr/pgsql-9.6/bin/pg_ctl" \ psql="/usr/pgsql-9.6/bin/psql" pgdata="/var/lib/pgsql/9.6/data/" \ rep_mode="sync" node_list=" pgsql01 pgsql02 pgsql03" restore_command="cp /var/lib/pgsql/9.6/pg_archive/%f %p" \ primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" master_ip="10.3.3.3" restart_on_promote='false'
Pacemaker Management Commands
Here are some interesting Pacemaker management commands (all commands require the rights of the OS superuser). The main cluster management utility is pcs . Before setting up and first launching the cluster, you need to authorize the nodes in the cluster once.
- sudo pcs cluster auth node1 node2 node3 -u hacluster -p 'password'
- Running the cluster on all nodes
- sudo pcs cluster start --all
Start / stop on one node:
- sudo pcs cluster start
- sudo pcs cluster stop
Viewing Cluster Status with Corosync Monitor:
- sudo crm_mon -Afr
Crash counters clearing:
- sudo pcs resource cleanup
Cluster state monitoring with crm_mon
Pacemaker has a built-in cluster status monitoring utility. The system administrator can use it to see what is happening in the cluster, what resources on which nodes are currently located.
Using the crm_mon command, you can monitor the state of the PDM.
- sudo crm_mon –Afr
The screenshot shows a cluster status report.
Figure 4 - Monitoring the status of the cluster using the crm_mon command
pgsql-status
PRI - master statusHS:sync - synchronous replicaHS:async - asynchronous replicaHS:alone - the replica can not connect to the masterSTOP - PostgreSQL stoppedpgsql-data-status
LATEST - a state inherent to the master. This node is a master.STREAMING:SYNC/ASYNC - shows replication status and replication type (SYNC/ASYNC)DISCONNECT - replica can not connect to the master. This usually happens when there is no connection from the replica to the master.pgsql-master-baseline
Shows the time line. The time line changes every time after the promote command on a node replica. After this, the DBMS starts a new countdown.
Types of failures on cluster nodes
What kinds of failures does a fail-safe cluster based on Pacemaker protect against?
- Power failure on the current master or replica. A power failure occurs when the power goes out and the server shuts down. This can be either a Master or one of the Replicas.
- PostgreSQL process crash . Primary PostgreSQL process crash - the system may terminate the postgres process for various reasons, such as low memory, insufficient file descriptors, or the maximum number of open files exceeded.
- Loss of network connectivity between any of the nodes and the rest of the nodes . This is the network unavailability of any site. For example, it could be caused by the failure of a network card or a switch port.
- Failure of the Pacemaker / Corosync process . The failure of the Corosync / pacemaker process is similar to the failure of the PostgreSQL process.
Kinds of scheduled maintenance
To carry out maintenance work, it is necessary to periodically remove from the cluster the individual nodes:
- The decommissioning of the Master or the Replica for the planned work is necessary in the following cases:
- replacement of failed equipment (which did not lead to failure);
- equipment upgrade;
- software update;
- other cases.
- . , , . , , PostgreSQL, , . . , .
Important! Before changing roles or decommissioning the Master, it is necessary to make sure that there is a synchronous replica in the cluster using the #crm_mon –Afr command . And the role of the Master is always assigned to a synchronous replica.
Since the purpose of this not so short article is to introduce you to one of the resiliency solutions of the PostgreSQL DBMS, the installation, configuration and configuration commands of the failover cluster are not considered.
The author of the article is Igor Kosenkov , Postgres Professional engineer.
Drawing - Natalia Lyovshina .
Source: https://habr.com/ru/post/359230/
All Articles