Infrastructure Planning for Instant VM Recovery: Instant VM Recovery: Part 1
Everyone knows that backup is started so that you can restore the system after a failure or data corruption. Of course, speed is important here - because the faster the recovery occurs, the less downtime and losses for the business. For situations where it is necessary to resume the work of the virtual machine as quickly as possible, Veeam engineers have developed the Instant VM Recovery functionality. It is very popular among users, and today we offer you some useful tips for planning the appropriate infrastructure.
So, welcome under cat.
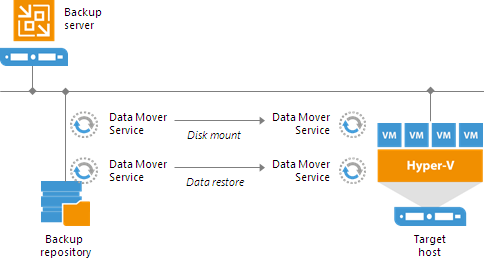
For those who are not familiar with the capabilities of Instant VM Recovery, there is a fairly detailed description in the documentation in Russian , in particular, here is the definition:
Instant VM Recovery technology allows you to start a virtual machine in seconds from a compressed and deduplicated backup that is stored in the repository.
')
The following guide describes the base usage scenario.
If your infrastructure is not very large, and you plan to restore a small number of VMs if necessary, then knowledge of the baseline scenario is sufficient.
However, among the real scenarios for using Instant VM Recovery there are also quite large infrastructures in which it was necessary to restore critical services after damage to the storage system, and in some cases after a virus attack. Even if the backups are not damaged (due to storage on a separate system, as the rule “3-2-1” dictates), recovery can take quite a long time. Therefore, when planning such scenarios, IT specialists aim to ensure high speed due to parallel recovery of several VMs, as well as compliance with the established recovery sequence.
And all this should work faster and be cheaper than the payment for the decryption key according to the results of the attack of the encryption virus. (Yes, everything rests on "time is money.") Naturally, you need to protect backup copies stored on the disk from possible attacks. Experts recommend using multifactor authentication to access repositories.
Or, say, you are a service provider, giving hundreds of or even thousands of VMs to consumers. There will be at least dozens of cars that machines that may need to be restored in no time. And here, of course, can not do without planning and preparation. After all, it will be necessary not only to quickly raise all the necessary machines from the backup, but also to ensure sufficient performance of these machines, and at the same time try to minimize the impact on the resources of the production infrastructure. Thus, high speed can be ensured when recovering from SAN Snapshots hardware snapshots created taking into account the operation of applications and replicated between arrays or stored on other media (for example, on magnetic tape).
In general, when designing an infrastructure, a balance should be at the forefront, aimed at optimizing both the backup process and the recovery process.
Of course, we always strive to ensure the fastest possible recovery of VMs and their operation without much loss of performance or impact on other machines. For this you need:
Of course, ideally, for instant recovery, you need to keep backups on high-speed storage, with a good data transfer channel. But this is not a cheap pleasure, so usually older backups are stored on the storage system easier and cheaper. SAN can be used simpler, S2D. The main thing is to keep the most recent backups on the storage system with a sufficiently high performance. This may be the last four backups for the past day, etc. - it all depends on the requirements and policies of the organization. If necessary, you can use SSD, and even NVMe.
You need to understand that while you are “raising” the machine, not only will the readable VM data be read from this storage system, but the running tasks will continue to record backups on the same storage system. That is why its performance is so important.
A medium-sized company uses a budget storage option; several storage levels are organized:
If the read-write speed and latency of the storage system for these operations are fine with you, you can add repositories to the SAN. If not, then you can increase the number of repositories as needed, i.e. perform horizontal scaling.
Note: Try not to use the same storage array for production and backups in order to minimize the risk of data loss due to bugs in the firmware.
It uses Storage Spaces Direct, which provides high availability, as well as several target systems with ReFS Multi-Resilient Volumes, providing data protection and parity with mirror acceleration ( mirror-accelerated parity ). You can configure it so that the “hot” (freshest) data is mirrored on the SSD before becoming “cold”, i.e. data that remained intact until hour X and went into the "second category of freshness." The “cold” data is moved to the storage level easier (cheaper). In this embodiment, there are opportunities for both horizontal and vertical scaling.

We build the backup infrastructure based on the fact that we need the 2nd level of storage only for those VMs that require the fastest possible backup and recovery.
To do this, you can use a pair of disk storage on 2TB SSD / NVMe, where they will record backup tasks with a sufficiently small number of stored recovery points. Then these backups will leave for the storage system simpler and cheaper - for long-term storage.
You can use different or the same repositories. In any case, it will be convenient to use the tasks of transferring backups of Veeam Backup Copy.

In any case, the level where the backup tasks are written directly will have a decent load, so you need to ensure high write performance, and preferably for longer.
So, if you have an AFA type storage with 60 SDDs for production VMs, then you can use MLCs for them, since read / write operations will be distributed across all disks. But if you plan to use it as the first level of storage of backups and, accordingly, to restore Instant VM Recovery, then keep in mind that the load will constantly fall on a small number of disks, and the resource can be exhausted quite quickly.
Next time we will look at what should be considered when planning the network connections and the target system - the one on which the recovery will be performed.
So, welcome under cat.
For those who are not familiar with the capabilities of Instant VM Recovery, there is a fairly detailed description in the documentation in Russian , in particular, here is the definition:
Instant VM Recovery technology allows you to start a virtual machine in seconds from a compressed and deduplicated backup that is stored in the repository.
')
The following guide describes the base usage scenario.
Why plan and optimize it?
If your infrastructure is not very large, and you plan to restore a small number of VMs if necessary, then knowledge of the baseline scenario is sufficient.
However, among the real scenarios for using Instant VM Recovery there are also quite large infrastructures in which it was necessary to restore critical services after damage to the storage system, and in some cases after a virus attack. Even if the backups are not damaged (due to storage on a separate system, as the rule “3-2-1” dictates), recovery can take quite a long time. Therefore, when planning such scenarios, IT specialists aim to ensure high speed due to parallel recovery of several VMs, as well as compliance with the established recovery sequence.
And all this should work faster and be cheaper than the payment for the decryption key according to the results of the attack of the encryption virus. (Yes, everything rests on "time is money.") Naturally, you need to protect backup copies stored on the disk from possible attacks. Experts recommend using multifactor authentication to access repositories.
Or, say, you are a service provider, giving hundreds of or even thousands of VMs to consumers. There will be at least dozens of cars that machines that may need to be restored in no time. And here, of course, can not do without planning and preparation. After all, it will be necessary not only to quickly raise all the necessary machines from the backup, but also to ensure sufficient performance of these machines, and at the same time try to minimize the impact on the resources of the production infrastructure. Thus, high speed can be ensured when recovering from SAN Snapshots hardware snapshots created taking into account the operation of applications and replicated between arrays or stored on other media (for example, on magnetic tape).
In general, when designing an infrastructure, a balance should be at the forefront, aimed at optimizing both the backup process and the recovery process.
First row - performance
Of course, we always strive to ensure the fastest possible recovery of VMs and their operation without much loss of performance or impact on other machines. For this you need:
- Quickly perform a read operation with storage backups. The faster the storage system that is being restored with, the better the performance of the VM being recovered.
- Have a good high-speed data transmission channel. Bandwidth - 10 Gb / s or higher recommended.
- Have a fast enough target system for recovery (this may be the one with which backups were made). The target storage system should have such performance to support all read-write operations on the recovered VM while you have not finalized the process (read about the final steps in the documentation ).
We select storage backup copies taking into account the planned recovery of Instant VM Recovery
Of course, ideally, for instant recovery, you need to keep backups on high-speed storage, with a good data transfer channel. But this is not a cheap pleasure, so usually older backups are stored on the storage system easier and cheaper. SAN can be used simpler, S2D. The main thing is to keep the most recent backups on the storage system with a sufficiently high performance. This may be the last four backups for the past day, etc. - it all depends on the requirements and policies of the organization. If necessary, you can use SSD, and even NVMe.
You need to understand that while you are “raising” the machine, not only will the readable VM data be read from this storage system, but the running tasks will continue to record backups on the same storage system. That is why its performance is so important.
Example 1
A medium-sized company uses a budget storage option; several storage levels are organized:
- at level 1 (small capacity) the most recent backups are stored - this is the so-called. “Highly available repository”, that is, a repository that provides high availability.
- Older backups are moved to level 2 (with a larger capacity) - this is the so-called. "Non-highly available repository", that is, ensuring accessibility is not very high, but simply satisfactory.
If the read-write speed and latency of the storage system for these operations are fine with you, you can add repositories to the SAN. If not, then you can increase the number of repositories as needed, i.e. perform horizontal scaling.
Note: Try not to use the same storage array for production and backups in order to minimize the risk of data loss due to bugs in the firmware.
Example 2
It uses Storage Spaces Direct, which provides high availability, as well as several target systems with ReFS Multi-Resilient Volumes, providing data protection and parity with mirror acceleration ( mirror-accelerated parity ). You can configure it so that the “hot” (freshest) data is mirrored on the SSD before becoming “cold”, i.e. data that remained intact until hour X and went into the "second category of freshness." The “cold” data is moved to the storage level easier (cheaper). In this embodiment, there are opportunities for both horizontal and vertical scaling.
Example 3
We build the backup infrastructure based on the fact that we need the 2nd level of storage only for those VMs that require the fastest possible backup and recovery.
To do this, you can use a pair of disk storage on 2TB SSD / NVMe, where they will record backup tasks with a sufficiently small number of stored recovery points. Then these backups will leave for the storage system simpler and cheaper - for long-term storage.
You can use different or the same repositories. In any case, it will be convenient to use the tasks of transferring backups of Veeam Backup Copy.
In any case, the level where the backup tasks are written directly will have a decent load, so you need to ensure high write performance, and preferably for longer.
So, if you have an AFA type storage with 60 SDDs for production VMs, then you can use MLCs for them, since read / write operations will be distributed across all disks. But if you plan to use it as the first level of storage of backups and, accordingly, to restore Instant VM Recovery, then keep in mind that the load will constantly fall on a small number of disks, and the resource can be exhausted quite quickly.
Next time we will look at what should be considered when planning the network connections and the target system - the one on which the recovery will be performed.
What else to read and see
- Instant Virtual Machine Recovery - User Manual Section (in Russian)
- Instant VM recovery in pictures (in English)
- An article on Habré about selecting storage for backup
Source: https://habr.com/ru/post/359166/
All Articles