Experiments with kube-proxy and node unavailability in Kubernetes
Note trans. : This article, written by a technical consultant and a certified Kubernetes administrator from the UK - Daniele Polencic, clearly shows and tells what role kube-proxy plays in delivering user requests to the subs and when problems occur in one of the cluster nodes .
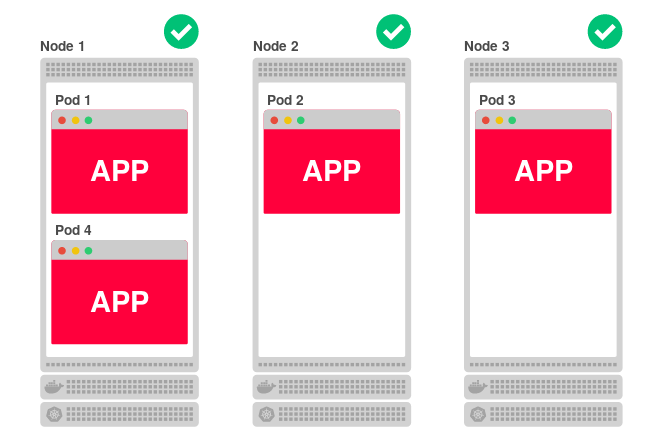
The code for applications deployed in Kubernetes runs on one or more work nodes. A node can be located either on a physical or virtual machine, or in AWS EC2 or Google Compute Engine, and the presence of many such sites means the ability to effectively launch and scale the application. For example, if a cluster consists of three nodes and you decide to scale the application into four replicas, Kubernetes will evenly distribute them among the nodes as follows:
')
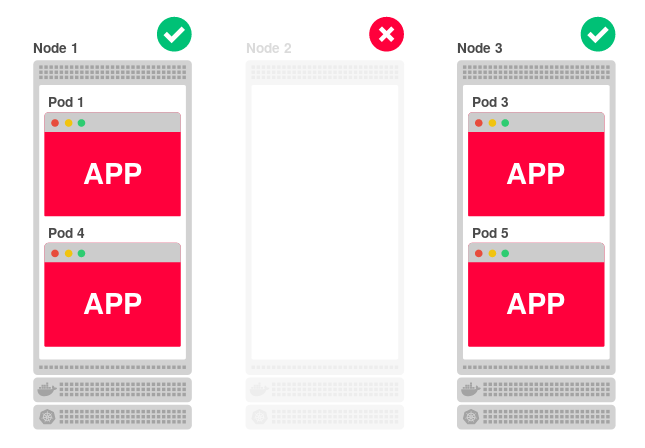
Such architecture copes well with falls. If one node is not available, the application will continue to work on the other two. Meanwhile, Kubernetes will reassign the fourth replica to another (available) node.
Moreover, even if all nodes are isolated, they can still serve requests. For example, reduce the number of application replicas to two:
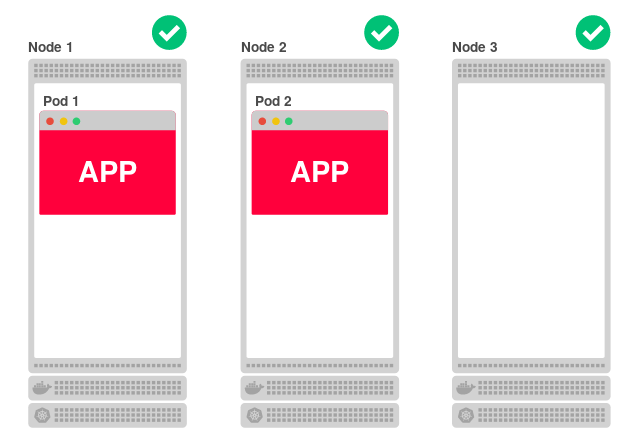
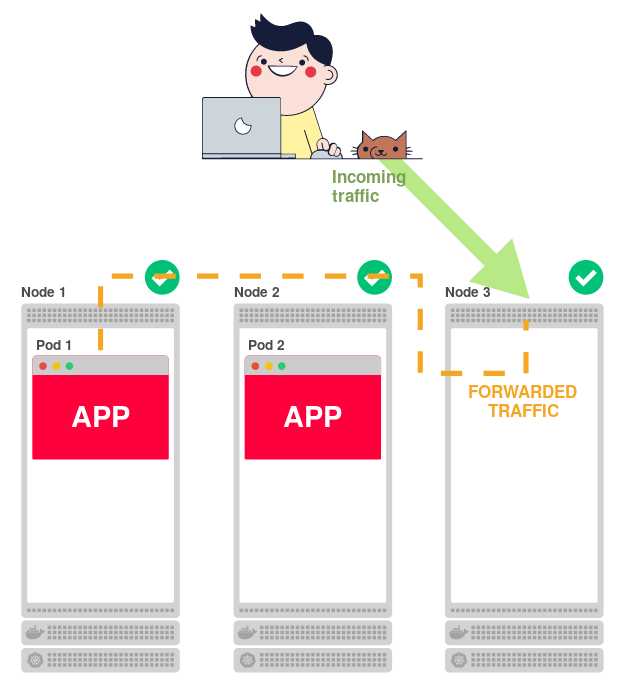
Since each node can serve the application, how does the third (Node 3) find out that the application is not running on it and it should redirect traffic to one of the other nodes?

Kubernetes has a
But how
He does not know.
But he knows about everything the main (master) node, which is responsible for creating a list of all the routing rules. And
It does not matter at all from which node the traffic comes:
Manabu Sakai had the same questions. And he decided to find out.
Suppose you have a cluster of two nodes in GCP:
And you deploy the Manabu app:
This is a simple application that displays on the web page the host name of the current hearth.
Scale it ( Deployment ) to ten replicas:
Ten replicas are evenly distributed over two nodes ( node1 and node2 ):

Service is created to load balance requests from ten replicas:
It is forwarded to the outside world through
Try sending a request to port 30,000 of one of the nodes:
Note : The node's IP address can be obtained with the command
The application responds with “Hello world!” And the host name of the container on which it runs:
If you re-request the same URL, sometimes the same answer will appear, and sometimes it will change. The reason -
What is interesting, it makes no difference to which node you are accessing: the answer will come from any hearth - even from those that are located on other nodes (not the ones you turned to).
The final configuration will require an external load balancer that distributes traffic across the nodes (on port 30000). This is how the final request flow diagram is obtained:
That is, the load balancer redirects incoming traffic from the Internet to one of two nodes. We clarify all this scheme - we summarize the principle of its work:
That's the whole scheme!
Now that we know how everything interacts, let's go back to the original question. What happens if we change the routing rules? Will the cluster still work? Will they serve requests?
Let's delete the routing rules, and in a separate terminal, monitor the application for the duration of the responses and the missed requests. For the latter, it is enough to write a cycle that will display the current time every second and make a request to the application:
At the output we will get columns with the time and text of the response from the submission:
So let's remove the routing rules from the site, but first we will figure out how to do this.
In iptables mode, the
Note : Note that the
If everything went according to plan, you'll see something like this:
As it is easy to see, from the moment of dropping the iptables rules to the next answer, it took about 27 seconds (from 10:14:43 to 10:15:10).
What happened during this time? Why did everything get well again after 27 seconds? Maybe this is just a coincidence?
Let's reset the rules again:
Now there is a pause of 29 seconds, from 11:29:56 to 11:30:25. But the cluster is back to work.
Why does it take 30 seconds to answer? Are requests coming to the node even without a routing table?
You can look at what is happening on the node during these 30 seconds. In another terminal, start a loop that makes requests to the application every second, but this time - contact the node, not the load balancer.
Again, reset the iptables rules. Such log will turn out:
It is not surprising that connections to the node end with a timeout after resetting the rules. But it's interesting that
But what if in the previous example the load balancer is waiting for new connections? This would explain the 30-second delay, however, it remains unclear why the node is ready to accept connections after a long enough wait.
So why is the traffic going again in 30 seconds? Who restores iptables rules?
Before resetting the iptables rules, you can view them:
Reset the rules and continue to execute this command - you will see that the rules are restored in a few seconds.
Is that you,
That is:
That's why it took about 30 seconds to make the node work again! It also explains how routing tables get from a master node to a worker. Their regular synchronization is handled by
So, we summarize how Kubernetes and
A wait of 30 seconds may be invalid for the application. In this case, you should think about changing the standard update interval in the
There is an agent on the node - kubelet , - and it is he who is responsible for starting
If you look at the kubelet process running on a node, you can see that it is running with the
What does this
Note : For the sake of simplicity, the incomplete file contents are shown here.
The mystery is solved! As you can see, the option
Resetting iptables rules is equivalent to making the node inaccessible. The traffic is still sent to the site, but it is not able to forward it further (i.e., under). Kubernetes can recover from this problem by tracking the routing rules and updating them if necessary.
A big thanks to Manabu Sakai for posting to a blog, which inspired this text in many ways, and also to Valentin Ouvrard for studying the issue of forwarding iptables rules from the wizard to other nodes.
Read also in our blog:
The code for applications deployed in Kubernetes runs on one or more work nodes. A node can be located either on a physical or virtual machine, or in AWS EC2 or Google Compute Engine, and the presence of many such sites means the ability to effectively launch and scale the application. For example, if a cluster consists of three nodes and you decide to scale the application into four replicas, Kubernetes will evenly distribute them among the nodes as follows:
')
Such architecture copes well with falls. If one node is not available, the application will continue to work on the other two. Meanwhile, Kubernetes will reassign the fourth replica to another (available) node.
Moreover, even if all nodes are isolated, they can still serve requests. For example, reduce the number of application replicas to two:
Since each node can serve the application, how does the third (Node 3) find out that the application is not running on it and it should redirect traffic to one of the other nodes?
Kubernetes has a
kube-proxy binary that runs on each node and is responsible for routing traffic to a specific one. It can be compared with the hotel receptionist sitting at the reception. Kube-proxy accepts all traffic coming to the site and forwards to the correct one.But how kube-proxy know where all the pods are located?
He does not know.
But he knows about everything the main (master) node, which is responsible for creating a list of all the routing rules. And
kube-proxy checks these rules and puts them into action. In the simple scenario described above, the list of rules is as follows:- The first replica of the application is available on node 1 (Node 1) .
- The second replica of the application is available on node 2 (Node 2) .
It does not matter at all from which node the traffic comes:
kube-proxy knows where it is necessary to redirect traffic in accordance with this list of rules.But what happens when kube-proxy crashes?
And what if the list of rules disappears?
What happens when there are no rules where to send traffic?
Manabu Sakai had the same questions. And he decided to find out.
Suppose you have a cluster of two nodes in GCP:
$ kubectl get nodes NAME STATUS ROLES AGE VERSION node1 Ready <none> 17h v1.8.8-gke.0 node2 Ready <none> 18h v1.8.8-gke.0 And you deploy the Manabu app:
$ kubectl create -f https://raw.githubusercontent.com/manabusakai/k8s-hello-world/master/kubernetes/deployment.yml $ kubectl create -f https://raw.githubusercontent.com/manabusakai/k8s-hello-world/master/kubernetes/service.yml This is a simple application that displays on the web page the host name of the current hearth.
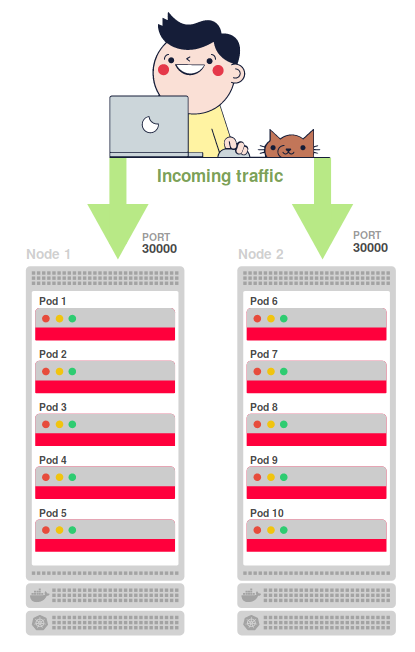
Scale it ( Deployment ) to ten replicas:
$ kubectl scale --replicas 10 deployment/k8s-hello-world Ten replicas are evenly distributed over two nodes ( node1 and node2 ):
$ kubectl get pods NAME READY STATUS NODE k8s-hello-world-55f48f8c94-7shq5 1/1 Running node1 k8s-hello-world-55f48f8c94-9w5tj 1/1 Running node1 k8s-hello-world-55f48f8c94-cdc64 1/1 Running node2 k8s-hello-world-55f48f8c94-lkdvj 1/1 Running node2 k8s-hello-world-55f48f8c94-npkn6 1/1 Running node1 k8s-hello-world-55f48f8c94-ppsqk 1/1 Running node2 k8s-hello-world-55f48f8c94-sc9pf 1/1 Running node1 k8s-hello-world-55f48f8c94-tjg4n 1/1 Running node2 k8s-hello-world-55f48f8c94-vrkr9 1/1 Running node1 k8s-hello-world-55f48f8c94-xzvlc 1/1 Running node2 Service is created to load balance requests from ten replicas:
$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE k8s-hello-world NodePort 100.69.211.31 <none> 8080:30000/TCP 3h kubernetes ClusterIP 100.64.0.1 <none> 443/TCP 18h It is forwarded to the outside world through
NodePort and is available on port 30000. In other words, each node opens port 30000 to the external Internet and starts to accept incoming traffic.But how is traffic routed from port 30,000 to pod?
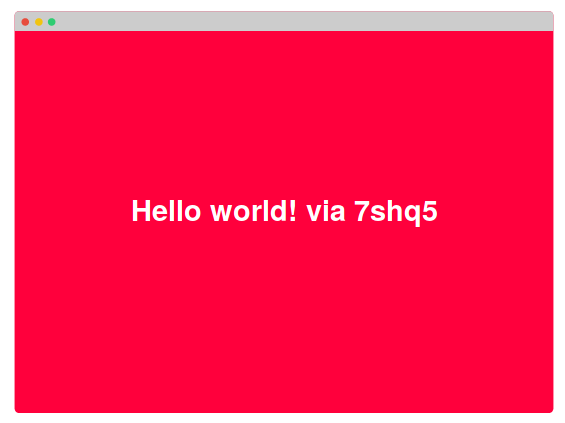
kube-proxy is responsible for setting the rules for incoming traffic from port 30,000 to one of ten pods.Try sending a request to port 30,000 of one of the nodes:
$ curl <node ip>:30000 Note : The node's IP address can be obtained with the command
kubectl get nodes -o wide .The application responds with “Hello world!” And the host name of the container on which it runs:
Hello world! via <hostname> Hello world! via <hostname> .If you re-request the same URL, sometimes the same answer will appear, and sometimes it will change. The reason -
kube-proxy works as a load balancer, checks the routing and distributes traffic to ten traffic.What is interesting, it makes no difference to which node you are accessing: the answer will come from any hearth - even from those that are located on other nodes (not the ones you turned to).
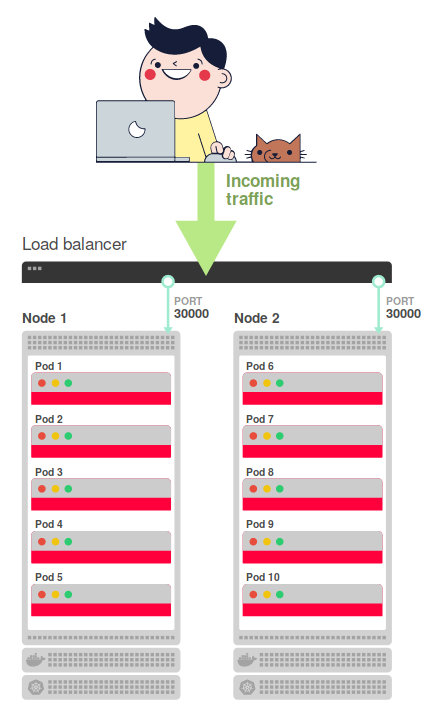
The final configuration will require an external load balancer that distributes traffic across the nodes (on port 30000). This is how the final request flow diagram is obtained:
That is, the load balancer redirects incoming traffic from the Internet to one of two nodes. We clarify all this scheme - we summarize the principle of its work:
- Coming from the Internet traffic is sent to the main load balancer.
- This balancer directs traffic to port 30,000 of one of the two nodes.
- The rules established by
kube-proxy, redirect traffic from the site to under. - Traffic hits on under.
That's the whole scheme!
It's time to break everything
Now that we know how everything interacts, let's go back to the original question. What happens if we change the routing rules? Will the cluster still work? Will they serve requests?
Let's delete the routing rules, and in a separate terminal, monitor the application for the duration of the responses and the missed requests. For the latter, it is enough to write a cycle that will display the current time every second and make a request to the application:
$ while sleep 1; do date +%X; curl -sS http://<your load balancer ip>/ | grep ^Hello; done At the output we will get columns with the time and text of the response from the submission:
10:14:41 Hello world! via k8s-hello-world-55f48f8c94-vrkr9 10:14:43 Hello world! via k8s-hello-world-55f48f8c94-tjg4n So let's remove the routing rules from the site, but first we will figure out how to do this.
kube-proxy can work in three modes: userspace , iptables and ipvs . The default mode since Kubernetes 1.2 is iptables . ( Note : the latest mode, ipvs , appeared in the release of K8s 1.8 and received beta status in 1.9 .)In iptables mode, the
kube-proxy lists the routing rules on a node using iptables rules. Thus, you can go to any node and delete these rules with the command iptables -F .Note : Note that the
iptables -F call can break the SSH connection.If everything went according to plan, you'll see something like this:
10:14:41 Hello world! via k8s-hello-world-55f48f8c94-xzvlc 10:14:43 Hello world! via k8s-hello-world-55f48f8c94-tjg4n # `iptables -F` 10:15:10 Hello world! via k8s-hello-world-55f48f8c94-vrkr9 10:15:11 Hello world! via k8s-hello-world-55f48f8c94-vrkr9 As it is easy to see, from the moment of dropping the iptables rules to the next answer, it took about 27 seconds (from 10:14:43 to 10:15:10).
What happened during this time? Why did everything get well again after 27 seconds? Maybe this is just a coincidence?
Let's reset the rules again:
11:29:55 Hello world! via k8s-hello-world-55f48f8c94-xzvlc 11:29:56 Hello world! via k8s-hello-world-55f48f8c94-tjg4n # `iptables -F` 11:30:25 Hello world! via k8s-hello-world-55f48f8c94-npkn6 11:30:27 Hello world! via k8s-hello-world-55f48f8c94-vrkr9 Now there is a pause of 29 seconds, from 11:29:56 to 11:30:25. But the cluster is back to work.
Why does it take 30 seconds to answer? Are requests coming to the node even without a routing table?
You can look at what is happening on the node during these 30 seconds. In another terminal, start a loop that makes requests to the application every second, but this time - contact the node, not the load balancer.
$ while sleep 1; printf %"s\n" $(curl -sS http://<ip of the node>:30000); done Again, reset the iptables rules. Such log will turn out:
Hello world! via k8s-hello-world-55f48f8c94-xzvlc Hello world! via k8s-hello-world-55f48f8c94-tjg4n # `iptables -F` curl: (28) Connection timed out after 10003 milliseconds curl: (28) Connection timed out after 10004 milliseconds Hello world! via k8s-hello-world-55f48f8c94-npkn6 Hello world! via k8s-hello-world-55f48f8c94-vrkr9 It is not surprising that connections to the node end with a timeout after resetting the rules. But it's interesting that
curl is waiting for a response for 10 seconds.But what if in the previous example the load balancer is waiting for new connections? This would explain the 30-second delay, however, it remains unclear why the node is ready to accept connections after a long enough wait.
So why is the traffic going again in 30 seconds? Who restores iptables rules?
Before resetting the iptables rules, you can view them:
$ iptables -L Reset the rules and continue to execute this command - you will see that the rules are restored in a few seconds.
Is that you,
kube-proxy ? Yes! In the official documentation of kube-proxy you can find two interesting flags:--iptables-sync-period- the maximum interval for which the iptables rules will be updated (for example: '5s', '1m', '2h22m'). Must be greater than 0. The default is 30s;--iptables-min-sync-period- minimum interval for which iptables rules must be updated when changes occur in endpoints and services (for example: '5s', '1m', '2h22m'). The default is 10s.
That is:
kube-proxy updates the iptables rules every 10-30 seconds. If we reset the iptables rules, it will take up to 30 seconds for kube-proxy to realize this and restore them.That's why it took about 30 seconds to make the node work again! It also explains how routing tables get from a master node to a worker. Their regular synchronization is handled by
kube-proxy . In other words, each time you add or remove a pod, the main node rewrites the route list, and kube-proxy regularly synchronizes the rules with the current node.So, we summarize how Kubernetes and
kube-proxy restored if someone kube-proxy iptables rules on a node:- The iptables rules have been removed from the site.
- The request is sent to the load balancer and routed to the node.
- The node does not accept incoming requests, so the balancer is waiting.
- After 30 seconds,
kube-proxyrestores iptables rules. - The node can receive traffic again. The iptables rules redirect the balancer request to the under.
- Sub responds to the load balancer with a total delay of 30 seconds.
A wait of 30 seconds may be invalid for the application. In this case, you should think about changing the standard update interval in the
kube-proxy . Where are these settings and how to change them?There is an agent on the node - kubelet , - and it is he who is responsible for starting
kube-proxy as a static hearth on each node. Documentation for static submissions assumes that kubelet checks the contents of a specific directory and creates all the resources from it.If you look at the kubelet process running on a node, you can see that it is running with the
--pod-manifest-path=/etc/kubernetes/manifests . Elementary ls opens the veil of secrecy: $ ls -l /etc/kubernetes/manifests total 4 -rw-r--r-- 1 root root 1398 Feb 24 08:08 kube-proxy.manifest What does this
kube-proxy.manifest ? apiVersion: v1 kind: Pod metadata: name: kube-proxy spec: hostNetwork: true containers: - name: kube-proxy image: gcr.io/google_containers/kube-proxy:v1.8.7-gke.1 command: - /bin/sh - -c -> echo -998 > /proc/$$$/oom_score_adj && exec kube-proxy --master=https://35.190.207.197 --kubeconfig=/var/lib/kube-proxy/kubeconfig --cluster-cidr=10.4.0.0/14 --resource-container="" --v=2 --feature-gates=ExperimentalCriticalPodAnnotation=true --iptables-sync-period=30s 1>>/var/log/kube-proxy.log 2>&1 Note : For the sake of simplicity, the incomplete file contents are shown here.
The mystery is solved! As you can see, the option
--iptables-sync-period=30s used to update iptables rules every 30 seconds. Here you can also change the minimum and maximum update time of rules on a specific node.findings
Resetting iptables rules is equivalent to making the node inaccessible. The traffic is still sent to the site, but it is not able to forward it further (i.e., under). Kubernetes can recover from this problem by tracking the routing rules and updating them if necessary.
A big thanks to Manabu Sakai for posting to a blog, which inspired this text in many ways, and also to Valentin Ouvrard for studying the issue of forwarding iptables rules from the wizard to other nodes.
PS from translator
Read also in our blog:
- “ An Illustrated Network Guide for Kubernetes ”;
- " How to ensure high availability in Kubernetes ";
- " Improving the reliability of Kubernetes: how to quickly notice that the node has fallen ";
- “What happens in Kubernetes when starting the kubectl run?”: Part 1 and part 2 ;
- “ How does the Kubernetes scheduler actually work? ";
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes) ;
- " Container Networking Interface (CNI) - network interface and standard for Linux-containers ."
Source: https://habr.com/ru/post/359120/
All Articles